C++11 Atomic Types and Memory Model
Table of Contents
1. C++原子类型
C++11 之前,C/C++程序中主要使用 POSIX 线程(Pthread)和 OpenMP 编译器指令来实现多线程。在 C++11 中,增加了对多线程的支持。这使得 C/C++语言在进行多线程编程时,不必依赖第三方库和标准了。而 C/C++对线程的支持,一个最为重要的部分,就是原子操作中引入了原子类型的概念。
本文主要摘自:深入理解 C++11:C++11 新特性解析与应用,6.3 节,原子类型与原子操作
1.1. 原子操作与原子类型
所谓原子操作,就是多线程程序中“最小的且不可并行化的”的操作。通常对一个共享资源的操作是原子操作的话,意味着多个线程访问该资源时,有且仅有唯一一个线程在对这个资源进行操作。那么从线程(处理器)的角度看来,其他线程就不能够在本线程对资源访问期间对该资源进行操作,因此原子操作对于多个线程而言,就不会发生有别于单线程程序的意外状况。
通常情况下,原子操作都是通过“互斥”(mutual exclusive)的访问来保证的。实现互斥通常需要平台相关的特殊指令,这在 C++11 标准之前,这常常意味着需要在 C/C++代码中嵌人内联汇编代码。对程序员来讲,就必须了解平台上与同步相关的汇编指令。当然,如果只是想实现粗粒度的互斥,借助 POSIX 标准的 pthread 库中的互斥锁(mutex)也可以做到。比如下面是使用 pthread 进行原子操作的例子:
#include <pthread.h>
#include <iostream>
using namespace std;
static long long total = 0;
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
void* func (void *) {
long long i;
for (i = 0; i <100000000LL; i++) {
pthread_mutex_lock(&m);
total += i;
pthread_mutex_unlock(&m);
}
}
int main () {
pthread_t thread1, thread2;
if (pthread_create(&thread1, NULL, &func, NULL)) {
throw;
}
if (pthread_create (&thread2, NULL, &func, NULL)) {
throw;
}
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
cout << total << endl; // 输出 9999999900000000
return 0;
}
在上面例子中,为了保证 total += i 语句的原子性,我们创建了一个 pthread_mutex_t 类型的互斥锁 m ,并且在语句的前后使用加锁(pthread_mutex_lock)和解锁(pthread_mutex_unlock)两种操作来确保该语句只有单一线程可以访问。如果将加锁/解锁操作的代码都注释掉的话,在我们的实验机上,total 的结果将由于线程间对数据的竞争(contention)而不再准确。因此,为了防止数据竞争问题,我们总是需要确保对 total 的操作是原子操作。
不过显而易见地,上面基于 pthread 的方法虽然可行,但代码编写却很麻烦。程序员需要为共享变量创建互斥锁,并在进入临界区前后进行加锁和解锁的操作。对于习惯了在单线程情况下编程的程序员而言,互斥锁的管理无疑是种负担。不过在 C++11 中,通过对并行编程更为良好的抽象,要实现同样的功能就简单了很多。下面的例子实现了同样的功能,而且代码更加简单:
#include <atomic>
#include <thread>
#include <iostream>
using namespace std;
atomic_llong total {0}; // total被定义为原子数据类型
void func(int) {
for(long long i = 0; i < 100000000LL; ++i) {
total += i;
}
}
int main() {
thread t1(func, 0);
thread t2(func, 0);
t1.join();
t2.join();
cout << total << endl; // 输出 9999999900000000
return 0;
}
在上面代码中,我们将变量 total 定义为一个“原子数据类型”: atomic_llong ,该类型长度等同于内置类型 long long 。在 C++11 中, 程序员不需要为原子数据类型显式地使用互斥锁,线程就能够对原子变量(如上面例子中的 total)互斥地进行访问。
1.1.1. C++11 和 C11 中的原子类型
C++11(头文件 atomic 中)和 C11(头文件 stdatomic.h 中)都支持原子类型,如表 1 和表 2 所示。
| C++11 Type alias | C++11 Definition |
|---|---|
| std::atomic_bool | std::atomic<bool> |
| std::atomic_char | std::atomic<char> |
| std::atomic_schar | std::atomic<signed char> |
| std::atomic_uchar | std::atomic<unsigned char> |
| std::atomic_short | std::atomic<short> |
| std::atomic_ushort | std::atomic<unsigned short> |
| std::atomic_int | std::atomic<int> |
| std::atomic_uint | std::atomic<unsigned int> |
| std::atomic_long | std::atomic<long> |
| std::atomic_ulong | std::atomic<unsigned long> |
| std::atomic_llong | std::atomic<long long> |
| std::atomic_ullong | std::atomic<unsigned long long> |
| C11 Typedef name | C11 Full type name |
|---|---|
| atomic_bool | _Atomic _Bool |
| atomic_char | _Atomic char |
| atomic_schar | _Atomic signed char |
| atomic_uchar | _Atomic unsigned char |
| atomic_short | _Atomic short |
| atomic_ushort | _Atomic unsigned short |
| atomic_int | _Atomic int |
| atomic_uint | _Atomic unsigned int |
| atomic_long | _Atomic long |
| atomic_ulong | _Atomic unsigned long |
| atomic_llong | _Atomic long long |
| atomic_ullong | _Atomic unsigned long long |
参考:
https://en.cppreference.com/w/cpp/atomic/atomic
https://en.cppreference.com/w/c/atomic
1.2. 原子类型支持的操作
原子类型支持的操作如表 3 所示,针对原子类型的操作都是原子操作。
| Operation | atomic_flag | atomic<bool> | atomic<T*> | atomic<integral-type> | atomic<other-type> |
|---|---|---|---|---|---|
| test_and_set | ✓ | ||||
| clear | ✓ | ||||
| is_lock_free | ✓ | ✓ | ✓ | ✓ | |
| load | ✓ | ✓ | ✓ | ✓ | |
| store | ✓ | ✓ | ✓ | ✓ | |
| exchange | ✓ | ✓ | ✓ | ✓ | |
| compare_exchange_weak, compare_exchange_strong | ✓ | ✓ | ✓ | ✓ | |
| fetch_add, += | ✓ | ✓ | |||
| fetch_sub, -= | ✓ | ✓ | |||
| fetch_or, |= | ✓ | ||||
| fetch_and, &= | ✓ | ||||
| fetch_xor, ^= | ✓ | ||||
| ++, -- | ✓ | ✓ |
注 1: atomic_flag 和 atomic_bool 类似,不过 atomic_flag 一定是 lock-free 的(所以它不支持 is_lock_free 方法)。
对于线程而言,原子类型通常属于“资源型”的数据,这意味着多个线程通常只能访问单个原子类型的拷贝。因此在 C++11 中,原子类型只能从其模板参数类型中进行构造,标准不允许原子类型进行拷贝构造、移动构造等等,以防止发生意外。比如:
atomic <float> af {1.2f};
atomic <float> af1 {af}; // 无法通过编译,因为原子类型没有拷贝构造函数
其中, af1 {af} 的构造方式在 C++11 中是不允许的(事实上,atomic 模板类的拷贝构造函数、移动构造函数等总是默认被删除的)。
不过从 atomic<T> 类型的变量来构造其模板参数类型 T 的变量则是可以的。比如:
atomic <float> af {1.2f};
float f=af;
float f1 {af};
这是由于 atomic 类模板总是定义了从 atomic<T> 到 T 的类型转换函数的缘故。在需要时,编译器会隐式地完成原子类型到其对应的类型的转换。
1.2.1. atomic_flag 实例:实现自旋锁
使用 atomic_flag 可以在用户代码(而非内核代码)中实现自旋锁,如:
#include <thread>
#include <vector>
#include <iostream>
#include <atomic>
std::atomic_flag lock = ATOMIC_FLAG_INIT;
void f(int n)
{
while (lock.test_and_set()) // acquire lock
; // spin
std::cout << "Output from thread " << n << '\n'; // 对标准输出是存在竞争的
lock.clear(); // release lock
}
int main()
{
std::vector<std::thread> v;
for (int n = 0; n < 200; ++n) {
v.emplace_back(f, n);
}
for (auto& t : v) {
t.join();
}
}
上面程序一定会输出规整的 200 行内容:
Output from thread 0 Output from thread 2 Output from thread 4 ...<exactly 200 lines>...
如果去掉 lock 相关代码,则输出可能会乱掉。
为使用方便,可以把自旋锁封装为:
void Lock(std::atomic_flag& lock) {
while (lock.test_and_set())
;
}
void Unlock(std::atomic_flag& lock) {
lock.clear();
}
上面代码,还可以进一步优化为(参见节 2.4.1 ):
void Lock(std::atomic_flag& lock) {
while (lock.test_and_set(std::memory_order_acquire))
;
}
void Unlock(std::atomic_flag& lock) {
lock.clear(std::memory_order_release);
}
1.2.2. Storing a new value depending on the current value (compare_exchange_xxx)
This new operation is called compare/exchange, and it comes in the form of the compare_exchange_weak() and compare_exchange_strong() member functions. The compare/exchange operation is the cornerstone of programming with atomic types; it compares the value of the atomic variable with a supplied expected value and stores the supplied desired value if they’re equal. If the values aren’t equal, the expected value is updated with the actual value of the atomic variable. The return type of the compare/exchange functions is a bool, which is true if the store was performed and false otherwise.
下面是 compare_exchange_strong() 的使用实例(摘自 https://en.cppreference.com/w/cpp/atomic/atomic/compare_exchange ):
#include <atomic>
#include <iostream>
std::atomic<int> ai;
int tst_val= 4;
int new_val= 5;
bool exchanged= false;
void valsout()
{
std::cout << "ai= " << ai
<< " tst_val= " << tst_val
<< " new_val= " << new_val
<< " exchanged= " << std::boolalpha << exchanged
<< "\n";
}
int main()
{
ai= 3;
valsout();
// 由于 tst_val != ai 所以 ai is not modified, tst_val is set to ai
exchanged= ai.compare_exchange_strong( tst_val, new_val );
valsout();
// 由于 tst_val == ai 所以 ai is set to new_val
exchanged= ai.compare_exchange_strong( tst_val, new_val );
valsout();
}
编译运行上面程序,会得到下面输出:
ai= 3 tst_val= 4 new_val= 5 exchanged= false ai= 3 tst_val= 3 new_val= 5 exchanged= false ai= 5 tst_val= 3 new_val= 5 exchanged= true
注:一般情况下使用 compare_exchange_strong() 即可。 compare_exchange_weak() 和 compare_exchange_strong() 的区别可参考:https://stackoverflow.com/questions/25199838/understanding-stdatomiccompare-exchange-weak-in-c11
1.3. 任意 TriviallyCopyable 类型都有对应的原子类型
前面介绍过,C++中的类型 std::atomic_bool 其实就是 std::atomic<bool> 的别名。
更为普遍地, 当用户自定义类型 T 是 TriviallyCopyable 类型(可以通过 std::is_trivially_copyable 进行检测,可简单地理解为这个类的对象可安全使用 memcpy 进行复制,即 memcpy-able)时,程序员可以使用 std::atomic 类模板创建出 T 的原子类型 ,即:
std::atomic<T> t;
这一类原子类型支持表 3 最后一列中所标记支持的方法。
1.3.1. 使用实例
自定义原子类型的使用模式为:先复制要修改的变量,然后修改复制后的变量,再“测试并修改”原变量。
下面例子中,没有明确地使用锁,也可以保证方法 increment()对全局变量 g 的修改是安全的:
#include <thread>
#include <iostream>
#include <atomic>
struct T { int b; };
struct S : public T {
S(int n) { a = n; b = n; }
void increment() { a++; b++; }
private:
int a;
};
std::atomic<S> g {5}; // global variable
int main()
{
// how a thread might update the global variable without losing any
// other thread's updates.
S s = g.load();
S new_s = s;
do {
new_s = s;
new_s.increment(); // whatever modifications you want
} while (!g.compare_exchange_strong(s, new_s));
}
2. C++内存模型
如果只是简单地想在线程间进行数据的同步的话,原子类型已经为程序员提供了一些同步的保障。 为了进一步发挥线程的性能,我们有必要了解一下 C++内存模型。
2.1. 指令重排序
介绍 C++内存模型前,我们先看看下面代码:
1: #include <thread> 2: #include <atomic> 3: #include <iostream> 4: 5: int a = 0; //std::atomic <int> a {0}; 6: int b = 0; //std::atomic <int> b {0}; 7: 8: void ValueSet () { 9: int t = 1; 10: a = t; 11: b = 2; 12: } 13: 14: void Observer () { 15: std::cout << "(" << a << ", " << b << ")" << std::endl; // 可能有多种输出 16: } 17: 18: int main() { 19: std::thread t1(ValueSet); 20: std::thread t2(Observer); 21: 22: t1.join(); 23: t2.join(); 24: 25: std::cout << "Got (" << a << ", " << b << ") " << std::endl; // Got (1,2) 26: }
上面代码中,我们创建了两个线程 t1 和 t2,分别的执行 ValueSet 和 Observer 函数。第 15 行可能有多种输出,可能是 (0, 0) 或者 (1, 2) ,甚至是 (1, 0) 。
试问,第 15 行可能输出 (0, 2) 吗?乍一看,这不合理,因为函数 ValueSet 中 a 的赋值语句 a=t 位于 b 的赋值语句 b=2 之前。不过事实上,如果编译器认定 a、b 的赋值语句的执行顺序对输出结果没有任何影响的话,则可能将指令重排序以提高性能。也就是说第 15 行可能输出 (0, 2) !
如果我们把变量 a 和 b 换为原子变量,即把第 5、6 行换为:
std::atomic <int> a {0};
std::atomic <int> b {0};
则第 15 行一定不会输出 (0, 2) 了。这是因为: 在 C++中,默认会禁止原子类型变量间的重排序优化。
2.2. 处理器内存模型
指令重排序不仅仅出现于编译器中,还可能出现于处理器中。
通常情况下,内存模型是一个硬件上的概念,表示的是机器指令(或者读者将其视为汇编语言指令也可以)是以什么样的顺序被处理器执行的。 现代处理器并不是逐条处理机器指令的,我们可以看看下面这段伪汇编代码:
1: Loadi reg3, 1; # 将立即数1放入寄存器reg3 2: Move reg4, reg3; # 将reg3的数据放入reg4 3: Store reg4, a; # 将寄存器reg4中的数据存入内存地址a 4: Loadi reg5, 2; # 将立即数2放入寄存器reg5 5: Store reg5, b; # 将寄存器reg5中的数据存入内存地址b
上面演示了 t = 1; a = t; b = 2; 这段 C++代码的伪汇编表示。按照通常的理解,指令总是按照 1->2->3->4->5 这样顺序执行,如果处理器的执行顺序是这样的话,我们通常称这样的内存模型为强顺序的(strong ordered)。可以看到,在这种执行方式下,指令 3 的执行(a的赋值)总是先于指令 5(b 的赋值)发生。
不过这里我们看到,指令 1、2、3 和指令 4、5 运行顺序上毫无影响(使用了不同的寄存器,以及不同的内存地址),一些处理器就有可能将指令执行的顺序打乱,比如按照 1->4->2->5->3 这样顺序(通常这样的执行顺序都是超标量的流水线,即一个时钟周期里发射多条指令而产生的)。如果指令是按照这个顺序被处理器执行的话,我们通常称之为弱顺序的(weak ordered)。而在这种情况下,指令 5(b 的赋值)的执行可能就被提前到指令 3(a 的赋值)完成之前完成(注:事实上,一些弱内存模型的构架比如 PowerPC,其写回操作是不能够被乱序的,这里只是一个帮助读者理解的示例,并非事实)。
那么在多线程情况下,强顺序和弱顺序又意味着什么呢?对于共享内存的处理器而言,强顺序意昧着:看到内存中的数据被改变的顺序与机器指令中的一致。反之,如果线程间看到的内存数据被改变的顺序与机器指令中声明的不一致的话,则是弱顺序的。比如在我们的伪汇编中,假设运行的平台遵从的是一个弱顺序的内存模型的话,那么可能线程 A 所在的处理器看到指令执行顺序是先 3 后 5,而线程 B 以为指令执行的顺序依然是先 5 后 3。
在现实中,x86 以及 SPARC(TSO 模式)都被看作是采用强顺序内存模型的平台。对于任何一个线程而言,其看到原子操作(这里都是指数据的读写)都是顺序的。而对于是采用弱顺序内存模型的平台,比如 Alpha、PowerPC、Itanlium、ArmV7 这样的平台而言,如果要保证指令执行的顺序,通常需要由在汇编指令中加人一条所谓的内存栅栏(memory barrier)指令。 比如在 PowerPC 上,就有一条名为 sync 的内存栅栏指令。该指令迫使已经进入流水线的指令都完成后处理器才执行 sync 以后指令(排空流水线)。这样一来, sync 之前运行的指令总是先于 sync 之后的指令完成。比如我们可以这样来保证伪汇编中的指令 3 的执行先于指令 5:
1: Loadi reg3, 1; # 将立即数1放入寄存器reg3 2: Move reg4, reg3; # 将reg3的数据放入reg4 3: Store reg4, a; # 将寄存器reg4中的数据存入内存地址a 4: Sync # 内存栅栏 5: Loadi reg5, 2; # 将立即数2放入寄存器reg5 6: Store reg5, b; # 将寄存器reg5中的数据存入内存地址b
不过, sync 指令对高度流水化的 PowerPC 处理器的性能影响很大(会使其性能降低),去掉 sync 可以提高流水线吞吐率。
2.3. 强弱内存模型比较
强弱内存模型比较如图 1 所示(摘自http://preshing.com/20120930/weak-vs-strong-memory-models/)。
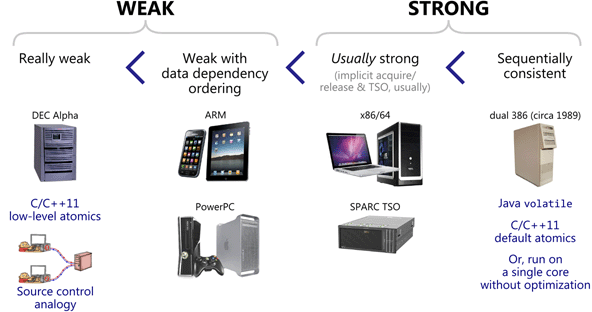
Figure 1: 各种强弱内存模型比较
2.4. C++内存模型和处理器内存模型的关系
C++11 中定义的内存模型跟硬件的内存模型有着什么样的联系呢?事实上,在高级语言和机器指令间还有一层隔离,这层隔离是由编译器来完成的。如我们之前描述的,编译器出于代码优化的考虑,会将指令前后移动,已获得最佳的机器指令的排列及产生最佳的运行时性能。那么对于 C++11 中的内存模型而言,要保证代码的顺序一致性,就必须同时做到以下几点:
- 编译器保证原子操作的指令间顺序不变,即保证产生的读写原子类型的变量的机器指令与代码编写者看到的是一致的。
- 处理器对原子操作的汇编指令的执行顺序不变。这对于 x86 这样的强顺序的体系结构而言,并没有任何的问题;而对于 PowerPC 这样的弱顺序的体系结构而言,则要求编译器在每次原子操作后加人内存栅栏。
在前面例子中,函数 ValueSet 中 a、b 赋值语句谁先发生其实无关紧要,如果 a、b 是原子变量,由于 atomic 默认的顺序一致性则会在对 a、b 的赋值语句间(即赋值语句 a=t 和 b=2 之间)加人内存栅栏,并阻止编译器优化,这无疑会增加并行开销(内存栅栏尤其如此)。那么解除这样的性能约束也势在必行。
在 C++11 中,设计者给出的解决方案是让程序员为原子操作指定所谓的内存顺序(memory_order)。比如,前面例子中,我们就可以采用一种松散的内存模型(relaxed memory model)来放松对原子操作的执行顺序的要求,下表中右边部分:
| 采用默认内存模型为 memory_order_seq_cst | 采用松散的内存模型 |
|
#include "thread" | #include "thread" #include "atomic" | #include "atomic" #include "iostream" | #include "iostream" | std::atomic std::atomic | void ValueSet () { | void ValueSet () { int t = 1; | int t = 1; a = t; // 相当于 a.store(t, std::memory_order_seq_cst); | a.store(t, std::memory_order_relaxed); b = 2; // 相当于 b.store(2, std::memory_order_seq_cst); | b.store(2, std::memory_order_relaxed); } | } | void Observer () { | void Observer () { std::cout << "(" << a << ", " << b << ")" | std::cout << "(" << a << ", " << b << ")" << std::endl; | << std::endl; } | } | int main() { | int main() { std::thread t1(ValueSet); | std::thread t1(ValueSet); std::thread t2(Observer); | std::thread t2(Observer); | t1.join(); | t1.join(); t2.join(); | t2.join(); | std::cout << "Got (" << a << ", " << b << ") " | std::cout << "Got (" << a << ", " << b << ") " << std::endl; | << std::endl; } | } |
上面左右两边的不同仅在于第 10、11 行,左边部分采用原子默认内存模型(memory_order_seq_cst);右边部分采用松散的内存模型(memory_order_relaxed),可能任意重排序。这将导致下面的不同:
- 对于第 15 行,左边代码不可能输出
(0, 2)这样的结果,而右边则可能。 - 左边代码的性能可能不如右边代码。
2.4.1. memory_order 枚举值
C++11 中的 memory_order 枚举值如表 4 所示。
| 枚举值 | 定义规则 |
|---|---|
| memory_order_relaxed | 不对执行顺序做任何保证 |
| memory_order_acquire | 本线程中,所有后续的读操作必须在本条原子操作完成后执行 |
| memory_order_release | 本线程中,所有之前的写操作完成后才能执行本条原子操作 |
| memory_order_acq_rel | 同时包含 memory_order_acquire 和 memory_order_release 标记 |
| memory_order_consume | 本线程中,所有后续的本有本原子类型的操作,必须在本条原子操作完成之后执行 |
| memory_order_seq_cst | 全部存取都按顺序执行(这是所有 atomic 原子操作的默认值) |
值得注意的是,并非每种 memory_order 都可以被 atomic 的成员使用。通常情况下,我们可以把 atomic 成员函数可使用的 memory_order 值分为以下 3 组:
- 原子存储操作(store)可以使用
memorey_order_relaxed,memory_order_release,memory_order_seq_cst - 原子读取操作(load)可以使用
memorey_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_seq_cst - RMW 操作(read-modify-write),即一些需要同时读写的操作,比如 atomic_flag 类型的
test_and_set()操作。又比如 atomic 类模板的compare_exchange_weak(),compare_exchange_strong()操作等都是需要同时读写的。RMW 操作可以使用memorey_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_seq_cst