Database Memo
Table of Contents
1. SQL
SQL stands for Structured Query Language.
1.1. SQL 标准及不同实现
SQL 标准如表 1 所示。
| Year | Name | Alias | Comments |
|---|---|---|---|
| 1986 | SQL-86 | SQL-87 | First formalized by ANSI. |
| 1989 | SQL-89 | FIPS127-1 | Minor revision, in which the major addition were integrity constraints. Adopted as FIPS 127-1. |
| 1992 | SQL-92 | SQL2, FIPS 127-2 | Major revision (ISO 9075), Entry Level SQL-92 adopted as FIPS 127-2. |
| 1999 | SQL:1999 | SQL3 | Added regular expression matching, recursive queries (e.g. transitive closure),triggers, support for procedural and control-of-flow statements, non-scalar types, and some object-oriented features (e.g. structured types). Support for embedding SQL in Java (SQL/OLB) and vice-versa (SQL/JRT). |
| 2003 | SQL:2003 | SQL 2003 | Introduced XML-related features (SQL/XML), window functions, standardized sequences, and columns with auto-generated values (including identity-columns). |
| 2006 | SQL:2006 | SQL 2006 | ISO/IEC 9075-14:2006 defines ways in which SQL can be used in conjunction with XML. It defines ways of importing and storing XML data in an SQL database, manipulating it within the database and publishing both XML and conventional SQL-data in XML form. In addition, it enables applications to integrate into their SQL code the use of XQuery, the XML Query Language published by the World Wide Web Consortium (W3C), to concurrently access ordinary SQL-data and XML documents. |
| 2008 | SQL:2008 | SQL 2008 | Legalizes ORDER BY outside cursor definitions. Adds INSTEAD OF triggers. Adds the TRUNCATE statement. |
| 2011 | SQL:2011 | Adds temporal data (PERIOD FOR). Enhancements for window functions and FETCH clause. | |
| 2016 | SQL:2016 | Adds row pattern matching, polymorphic table functions, JSON. |
注:1992 发布的 SQL2 可以认为是 SQL 的第一个统一标准。
三个主要的 SQL 商业实现:
Oracle 对 SQL 的实现——PL/SQL(stands for "Procedural Language extenstions to SQL")
IBM DB2 对 SQL 的实现——SQL PL
Microsoft SQL Server 和 Sybase 对 SQL 的实现——Transact-SQL(简称 T-SQL)
1.2. 基本格式
SQL 语言大小写不敏感。
1.2.1. 注释
单行注释:以两个连字符(--)开始到行尾。
块注释为:/* */之间的内容。
在 Oracle 中,可以在注释中写 Hints,Hint 一般以/*+开始,以*/结束。
Hints are comments in a SQL statement that pass instructions to the Oracle Database optimizer.
hint 举例,如:
SELECT /*+ NO_USE_HASH_AGGREGATION */ a,COUNT(*) AS num FROM tab1 GROUP BY a;
说明:
Hint 是 Oracle 提供的一种 SQL 语法,它允许用户在 SQL 语句中插入相关的语法(作为注释的一部分),从而影响 SQL 的执行方式。因为 Hint 的特殊作用,所以对于开发人员不应该在代码中使用它,Hint 更像是 Oracle 提供给 DBA 用来分析问题的工具。在 SQL 代码中使用 Hint,可能导致非常严重的后果,因为数据库的数据是变化的,在某一时刻使用这个执行计划是最优的,在另一个时刻,却可能很差。
参考:https://docs.oracle.com/database/121/TGSQL/tgsql_influence.htm
1.3. 表基本操作
1.3.1. 创建表
CREATE TABLE foo (a integer, b varchar(10), c varchar(10))
1.3.1.1. 基于存在表创建新表
Oracle 中:
CREATE TABLE new_table AS (SELECT * FROM old_table);
上面命令不仅会创建新表,还会复制表 old_table 中的所有数据到 new_table 中。
如果只想复制表的结构,而不复制表中的内容,可以使用下面语句:
CREATE TABLE new_table AS (SELECT * FROM old_table WHERE 0=1);
DB2 LUW 中:
CREATE TABLE new_table LIKE old_table
上面语句不会复制 old_table 里的记录到 new_table 中。
如果要复制所有记录,可以使用下面语句:
INSERT INTO new_table SELECT * FROM old_table
1.3.2. 查询表定义
Oracle 中:
DESCRIBE table_name DESC table_name --Oracle中,DESCRIBE可简写为DESC
DB2 for LUW 中:
DESCRIBE TABLE table_name --DB2 LUW中,必须有TABLE关键字,且DESCRIBE不能简写为DESC
DB2 for z/OS 中:
在 DB2 for z/OS 中,不支持 describe table 命令查看表的结构。
可通过查询系统内置表 sysibm.syscolumns 得到表的定义信息。
如,查询 TAB1 的定义:
db2 => select name, coltype, length from sysibm.syscolumns where tbname='TAB1'
1.3.3. 修改表定义
使用 ALTER TABLE 语句(如图 1 所示)可以修改表定义,即实现下面任务:
- 向表中添加字段;
- 修改字段的默认值;
- 删除表的字段;
- 添加或删除表的主键/外键/唯一性约束/检验约束。
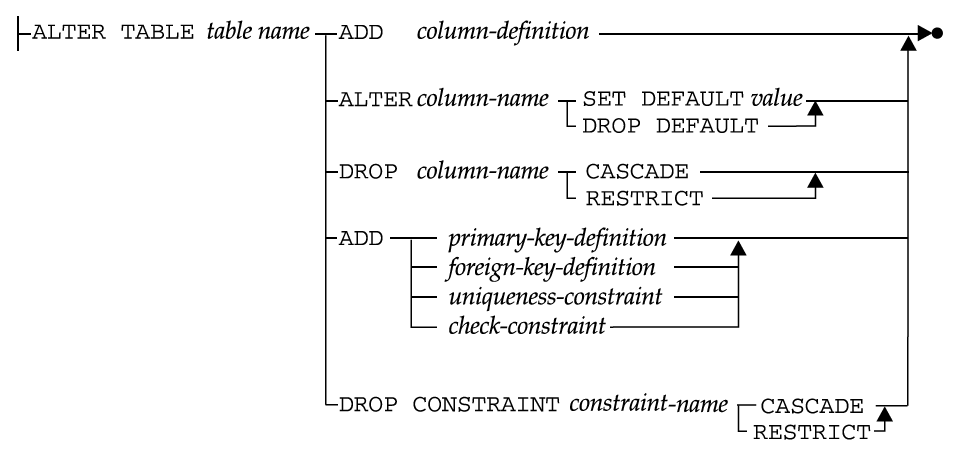
Figure 1: ALTER TABLE 语句
1.3.4. 删除、清空表
删除表:
DROP TABLE table_name
清空表时,仅表中记录没了,表不会被删除。
Oracle 中:
TRUNCATE TABLE table_name
DB2 LUW 中:
TRUNCATE TABLE table_name IMMEDIATE --DB2 LUW中,必须有关键字IMMEDIATE
1.4. 增删改记录
1.4.1. 插入记录(insert)
INSERT INTO table_name (column1, column2) VALUES (value1, value2) INSERT INTO table_name VALUES (value1, value2) --不引起岐义时列名也可以省略 INSERT INTO table_name VALUES (value11, value12), (value21, value22) --插入多条记录,DB2支持,但Oracle不支持!
1.4.2. 删除记录(delete)
DELETE FROM table_name WHERE column1=value1; DELETE FROM foo WHERE a=7;
1.4.3. 修改记录(update)
UPDATE table_name SET column1=new_val1, column2=new_val2 WHERE some_column=some_value UPDATE foo SET a=999 WHERE b ='max';
1.4.4. merge
merge 操作不是标准是 SQL 语句,Oracle 和 DB2 都支持它(但语法有差异)。
用 merge 操作容易实现:当匹配上则更新表的数据,没有匹配上则插入记录到表中。
Oracle 中 merge 实例:
The following example uses the bonuses table in the sample schema oe with a default bonus of 100. It then inserts into the bonuses table all employees who made sales, based on the sales_rep_id column of the oe.orders table. Finally, the human resources manager decides that employees with a salary of $8000 or less should receive a bonus. Those who have not made sales get a bonus of 1% of their salary. Those who already made sales get an increase in their bonus equal to 1% of their salary. The MERGE statement implements these changes in one step:
CREATE TABLE bonuses (employee_id NUMBER, bonus NUMBER DEFAULT 100);
INSERT INTO bonuses(employee_id)
(SELECT e.employee_id FROM employees e, orders o
WHERE e.employee_id = o.sales_rep_id
GROUP BY e.employee_id);
SELECT * FROM bonuses ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------- ----------
153 100
154 100
155 100
156 100
158 100
159 100
160 100
161 100
163 100
MERGE INTO bonuses D
USING (SELECT employee_id, salary, department_id FROM employees
WHERE department_id = 80) S
ON (D.employee_id = S.employee_id)
WHEN MATCHED THEN UPDATE SET D.bonus = D.bonus + S.salary*.01
DELETE WHERE (S.salary > 8000)
WHEN NOT MATCHED THEN INSERT (D.employee_id, D.bonus)
VALUES (S.employee_id, S.salary*.01)
WHERE (S.salary <= 8000);
SELECT * FROM bonuses ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------- ----------
153 180
154 175
155 170
159 180
160 175
161 170
179 620
173 610
165 680
166 640
164 720
172 730
167 620
171 740
参考:http://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_9016.htm
1.5. 查询记录
查询记录用 SELECT ,它是 SQL 中最复杂的语句之一。
1.5.1. 去掉重复记录(SELECT DISTINCT colunm1, column2 FROM tab1)
The SQL DISTINCT keyword is used in conjunction with SELECT statement to eliminate all the duplicate records and fetching only unique records.
假设表 CUSTOMERS 如下所示:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | +----+----------+-----+-----------+----------+
其中有两条记录的 SALARY 字段相同(为 2000.00),用 SELECT DISTINCT SALARY 可以对该列去重。如:
SQL> SELECT SALARY FROM CUSTOMERS
ORDER BY SALARY; -- 不使用 DISTINCT 时
+----------+
| SALARY |
+----------+
| 1500.00 |
| 2000.00 |
| 2000.00 |
| 4500.00 |
| 6500.00 |
| 8500.00 |
| 10000.00 |
+----------+
SQL> SELECT DISTINCT SALARY FROM CUSTOMERS
ORDER BY SALARY; -- 使用 DISTINCT 时
+----------+
| SALARY |
+----------+
| 1500.00 |
| 2000.00 |
| 4500.00 |
| 6500.00 |
| 8500.00 |
| 10000.00 |
+----------+
如果要找出表中列 AGE 和列 SALARY 的所有可能组合(且排除重复情况),可以使用 SELECT DISTINCT AGE, SALARY 。如:
SQL> SELECT DISTINCT AGE, SALARY FROM CUSTOMERS
ORDER BY AGE;
+-----+----------+
| AGE | SALARY |
+-----+----------+
| 22 | 4500.00 |
| 23 | 2000.00 |
| 24 | 10000.00 |
| 25 | 1500.00 |
| 25 | 6500.00 |
| 27 | 8500.00 |
| 32 | 2000.00 |
+-----+----------+
如果要排除所有字段完全重复的记录(上面表中 ID 为 5 的记录有两条,且一模一样),可以使用 SELECT DISTINCT * 。如:
SQL> SELECT DISTINCT * FROM CUSTOMERS; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
参考:http://www.tutorialspoint.com/sql/sql-distinct-keyword.htm
1.5.2. ORDER BY 语句
ORDER BY 语句能对结果集进行排序。它默认按照升序( ASC )对记录进行排序;如果希望按照降序对记录进行排序,可以在排序表达式后指定 DESC 关键字。
1.5.3. GROUP BY 语句(分组查询)
GROUP BY 是分组查询,常常和聚合函数(Aggregate Function,如 SUM, MIN, MAX 等)一起使用。它的作用是 通过一定的规则将一个数据集划分成若干个小组,然后针对若干个小组进行数据处理。
在介绍 GROUP BY 之前,先交待一下两个测试表的内容:
SQL> select * from customers; +---------+-----------------+----------------+ | CUST_ID | CUST_FIRST_NAME | CUST_LAST_NAME | +---------+-----------------+----------------+ | 1 | Steven | King | | 2 | Neena | Kochhar | | 3 | David | Austin | +---------+-----------------+----------------+ SQL> SELECT * FROM sales; +---------+---------+-------------+ | PROD_ID | CUST_ID | AMOUNT_SOLD | +---------+---------+-------------+ | 1000 | 1 | 10 | | 1000 | 1 | 20 | | 1001 | 1 | 10 | | 1002 | 2 | 60 | | 1003 | 2 | 10 | | 1000 | 3 | 30 | +---------+---------+-------------+
如何得到对每个客户的销量呢?查询表 sales,对列 cust_id 进行 GROUP BY 即可:
SQL> SELECT cust_id, SUM(amount_sold)
FROM sales
GROUP BY cust_id;
+---------+------------------+
| cust_id | SUM(amount_sold) |
+---------+------------------+
| 1 | 40 |
| 2 | 70 |
| 3 | 30 |
+---------+------------------+
那些 cust_id 相同的行会被当做同一组数据,再进行聚合函数的处理。
此外, GROUP BY 语句可以指定多列,如指定 GROUP BY c1,c2,c3 时,表示 c1,c2,c3 三列中只要有一个不同就会再分一个组。
1.5.3.1. GROUP BY 限制
前面介绍的例子中,如果我们想在得到的结果中还包含客户的 LastName(即列 cust_last_name),这时需要查询 customers 表,我们可能这样写:
SQL> SELECT c.cust_id, c.cust_last_name, SUM(amount_sold) -- 想同时得到 cust_last_name
FROM customers c, sales s
WHERE s.cust_id = c.cust_id
GROUP BY c.cust_id;
ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause......
......this is incompatible with sql_mode=only_full_group_by
但是,上面语句会报错。当然也有 RDBMS 不报错的,如 MySQL 5.7.5 之前版本,但严格说它并不是合法的 SQL。报错原因是 GROUP BY 语句有个要求:对于 SELECT 后面的所有列中,那些没有使用聚合函数的列,都必须出现在 GROUP BY 语句后面。 这个例子中, cust_last_name 出现在 SELECT 中,但没有出现在 GROUP BY 后面。
解决办法 1:对列 cust_last_name 使用函数 ANY_VALUE (它不是 SQL 的标准函数,如 Oracle/MySQL 中存在,而 MariaDB 中不存在):
SQL> SELECT c.cust_id, ANY_VALUE(c.cust_last_name) AS LAST_NAME, SUM(amount_sold)
FROM customers c, sales s
WHERE s.cust_id = c.cust_id
GROUP BY c.cust_id;
+---------+-----------+------------------+
| cust_id | LAST_NAME | SUM(amount_sold) |
+---------+-----------+------------------+
| 1 | King | 40 |
| 2 | Kochhar | 70 |
| 3 | Austin | 30 |
+---------+-----------+------------------+
解决办法 2:修改 RDBMS 的配置。当然这需要 RDBMS 的支持,如 MySQL 中,把 only_full_group_by 从 sql_mode 中去掉后,前面报错的语句可以正常执行。
解决办法 3:把 SQL 改为内连接语句(参考节 1.6.1),如:
SQL> SELECT c.cust_id, c.cust_last_name AS LAST_NAME, s.sold
FROM customers c
LEFT JOIN (SELECT cust_id, SUM(amount_sold) AS sold
FROM sales
GROUP BY cust_id) s ON s.cust_id = c.cust_id;
+---------+-----------+------+
| cust_id | LAST_NAME | sold |
+---------+-----------+------+
| 1 | King | 40 |
| 2 | Kochhar | 70 |
| 3 | Austin | 30 |
+---------+-----------+------+
1.5.3.2. GROUP BY 后接 Alias 和表达式
在 SQL 标准中, GROUP BY 后面不能指定列的 Alias,这不是很方便。不过,很多 RDBMS 的实现去除了这个限制,如 MySQL 就支持对列 Alias 进行 GROUP BY 。
假设有下面数据(这个数据在节 1.7.1 中也会用到):
SQL> create table tbl1 (id int, timestamp datetime, price int); SQL> insert into tbl1 (id, timestamp, price) values (1, '2000-04-01 16:55:44', 10); SQL> insert into tbl1 (id, timestamp, price) values (2, '2000-04-01 17:01:41', 50); SQL> insert into tbl1 (id, timestamp, price) values (3, '2000-04-01 17:10:24', 20); SQL> insert into tbl1 (id, timestamp, price) values (4, '2000-04-01 17:11:14', 40); SQL> insert into tbl1 (id, timestamp, price) values (5, '2000-04-01 17:22:00', 30); SQL> insert into tbl1 (id, timestamp, price) values (6, '2000-04-01 17:30:00', 10); SQL> insert into tbl1 (id, timestamp, price) values (7, '2000-04-01 17:33:11', 40); SQL> insert into tbl1 (id, timestamp, price) values (8, '2000-04-01 17:45:00', 60);
我们需要从表 tbl1 中得到每 15 分钟的最低价格和最高价格。没有这样的列可以直接进行分组,怎么办?对列 timestamp 加工再创建 Alias 即可,如:
MySQL> SELECT FLOOR(UNIX_TIMESTAMP(timestamp)/(15 * 60)) AS timekey,
min(price),
max(price)
FROM tbl1
GROUP BY timekey;
+---------+------------+------------+
| timekey | min(price) | max(price) |
+---------+------------+------------+
| 1060643 | 10 | 10 |
| 1060644 | 20 | 50 |
| 1060645 | 30 | 30 |
| 1060646 | 10 | 40 |
| 1060647 | 60 | 60 |
+---------+------------+------------+
如果我们不关心 timekey 列,则可以把表达式直接写到 GROUP BY 后面,如:
mysql> SELECT
min(price),
max(price)
FROM tbl1
GROUP BY FLOOR(UNIX_TIMESTAMP(timestamp)/(15 * 60));
+------------+------------+
| min(price) | max(price) |
+------------+------------+
| 10 | 10 |
| 20 | 50 |
| 30 | 30 |
| 10 | 40 |
| 60 | 60 |
+------------+------------+
1.5.3.3. ROLLUP(向上归纳)
GROUP BY 时指定 ROLLUP 可以得到向上归纳的数据。假设 GROUP BY 结果为:
mysql> SELECT year, SUM(profit) AS profit
FROM sales
GROUP BY year;
+------+--------+
| year | profit |
+------+--------+
| 2000 | 4525 |
| 2001 | 3010 |
+------+--------+
现在,增加 WITH ROLLUP ,则会得到:
mysql> SELECT year, SUM(profit) AS profit
FROM sales
GROUP BY year WITH ROLLUP;
+------+--------+
| year | profit |
+------+--------+
| 2000 | 4525 |
| 2001 | 3010 |
| NULL | 7535 | <-- 这里多了“向上归纳的数据”
+------+--------+
不同的 RDBMS 对 ROLLUP 的实现语法可能不一样,MySQL/SQL Server 中为 GROUP BY column WITH ROLLUP ;Oracle 中为 GROUP BY ROLLUP (column) 。
1.5.4. HAVING 语句
HAVING 语句常常和 GROUP BY 语句同时使用。在 SQL 中增加 HAVING 子句原因是, WHERE 关键字无法与聚合函数一起使用。
1.5.4.1. HAVING 实例
下面看一个使用 HAVING 语句的例子:
SQL> SELECT * FROM foo; NAME GRADE ---------- ---------- allen A smith B jones A scott A blake C SQL> SELECT grade, COUNT(name) AS nums FROM foo GROUP BY grade; -- 按 grade 分组查询 GRADE NUMS ---------- ---------- B 1 A 3 C 1 SQL> SELECT grade, COUNT(name) AS nums FROM foo GROUP BY grade HAVING COUNT(name) > 2; GRADE NUMS ---------- ---------- A 3
增加 HAVING COUNT(name) > 2 后可以仅获得人数大于 2 的等级的相关分组。
注: HAVING 语句和 WHERE 关键字的作用类似,但 WHERE 无法在上面场景中使用,后面用了聚合函数 COUNT 。
1.6. JOIN(“横向”合并)
JOIN 用来按指定条件“横向”合并两个或多个表,基本语法为:
joined-table:
.-INNER-----.
>>-+-table-reference--+-----------+--JOIN--table-reference--ON--join-condition-+-><
| '-| outer |-' |
+-table-reference--CROSS JOIN--table-reference------------------------------+
'-(--joined-table--)--------------------------------------------------------'
outer:
.-OUTER-.
|--+-LEFT--+--+-------+-----------------------------------------|
+-RIGHT-+
'-FULL--'
1.6.1. 内联接
下面将以实例形式展示内联接基本含义,先准备两个数据表 persons 和 orders:
create table persons (id_p integer, lastname char(10), firstname char(10), city char(10)) insert into persons values (1, 'Adams', 'John', 'London') insert into persons values (2, 'Bush', 'George', 'New York') insert into persons values (3, 'Carter', 'Thomas', 'Beijing') create table orders (id_o integer, orderno integer, id_p integer) insert into orders values (1, 77895, 3) insert into orders values (2, 44678, 3) insert into orders values (3, 22456, 1) insert into orders values (4, 24562, 1) insert into orders values (5, 34764, 65)
执行完上面语句后,测试数据表已准备好。
db2 => select * from persons
ID_P LASTNAME FIRSTNAME CITY
----------- ---------- ---------- ----------
1 Adams John London
2 Bush George New York
3 Carter Thomas Beijing
3 record(s) selected.
db2 => select * from orders
ID_O ORDERNO ID_P
----------- ----------- -----------
1 77895 3
2 44678 3
3 22456 1
4 24562 1
5 34764 65
5 record(s) selected.
如何查询谁定购了产品,定购了什么产品?用内联接(INNER JOIN ... ON ...)可解决问题:
db2 => SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo \ db2 (cont.) => FROM (Persons INNER JOIN Orders ON Persons.Id_P = Orders.Id_P) LASTNAME FIRSTNAME ORDERNO ---------- ---------- ----------- Carter Thomas 77895 Carter Thomas 44678 Adams John 22456 Adams John 24562 4 record(s) selected.
说明 1:上面语句中的 INNER 关键字和小括号可以省略。
说明 2:不用内联接,用 where 同样可以解决问题。
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons, Orders WHERE Persons.Id_P = Orders.Id_P
1.6.2. 内联接和各种外联接的区别
内联接和外联接的区别如表 2 所示。
| type of join | description |
|---|---|
| tab1 [INNER] JOIN tab2 ON ... | 按 ON 指定的条件找左右表中的关联数据 |
| tab1 LEFT [OUTER] JOIN tab2 ON ... | 左表(tab1)一定会在结果表中 |
| tab1 RIGHT [OUTER] JOIN tab2 ON ... | 右表(tab2)一定会在结果表中 |
| tab1 FULL [OUTER] JOIN tab2 ON ... | 左右表都在结果表中 |
各种内联接和外联接的测试如下:
db2 => SELECT * FROM Persons JOIN Orders ON Persons.Id_P = Orders.Id_P
ID_P LASTNAME FIRSTNAME CITY ID_O ORDERNO ID_P
----------- ---------- ---------- ---------- ----------- ----------- -----------
3 Carter Thomas Beijing 1 77895 3
3 Carter Thomas Beijing 2 44678 3
1 Adams John London 3 22456 1
1 Adams John London 4 24562 1
4 record(s) selected.
db2 => SELECT * FROM Persons LEFT JOIN Orders ON Persons.Id_P = Orders.Id_P
ID_P LASTNAME FIRSTNAME CITY ID_O ORDERNO ID_P
----------- ---------- ---------- ---------- ----------- ----------- -----------
1 Adams John London 3 22456 1
1 Adams John London 4 24562 1
2 Bush George New York - - -
3 Carter Thomas Beijing 1 77895 3
3 Carter Thomas Beijing 2 44678 3
5 record(s) selected.
db2 => SELECT * FROM Persons RIGHT JOIN Orders ON Persons.Id_P = Orders.Id_P
ID_P LASTNAME FIRSTNAME CITY ID_O ORDERNO ID_P
----------- ---------- ---------- ---------- ----------- ----------- -----------
3 Carter Thomas Beijing 1 77895 3
3 Carter Thomas Beijing 2 44678 3
1 Adams John London 3 22456 1
1 Adams John London 4 24562 1
- - - - 5 34764 65
5 record(s) selected.
db2 => SELECT * FROM Persons FULL JOIN Orders ON Persons.Id_P = Orders.Id_P
ID_P LASTNAME FIRSTNAME CITY ID_O ORDERNO ID_P
----------- ---------- ---------- ---------- ----------- ----------- -----------
3 Carter Thomas Beijing 1 77895 3
3 Carter Thomas Beijing 2 44678 3
1 Adams John London 3 22456 1
1 Adams John London 4 24562 1
- - - - 5 34764 65
2 Bush George New York - - -
6 record(s) selected.
注:在外联接中,往往会有 NULL 值出现,上面例子中的连字符就是 NULL 值。
1.6.3. 交叉联接(笛卡尔积,CROSS JOIN)
交叉联接(CROSS JOIN)的结果集是两个表中所有行的每种可能组合,如一个表有 10 条记录,另一个表有 20 条记录,则交叉联接后的结果表会有 200 条记录。交叉联接不需也不能指定 ON 条件。
交叉联接的开销很大,常用来生成测试数据,实际应用很少。
db2 => SELECT * FROM Persons CROSS JOIN Orders
ID_P LASTNAME FIRSTNAME CITY ID_O ORDERNO ID_P
----------- ---------- ---------- ---------- ----------- ----------- -----------
1 Adams John London 1 77895 3
1 Adams John London 2 44678 3
1 Adams John London 3 22456 1
1 Adams John London 4 24562 1
1 Adams John London 5 34764 65
2 Bush George New York 1 77895 3
2 Bush George New York 2 44678 3
2 Bush George New York 3 22456 1
2 Bush George New York 4 24562 1
2 Bush George New York 5 34764 65
3 Carter Thomas Beijing 1 77895 3
3 Carter Thomas Beijing 2 44678 3
3 Carter Thomas Beijing 3 22456 1
3 Carter Thomas Beijing 4 24562 1
3 Carter Thomas Beijing 5 34764 65
15 record(s) selected.
1.7. Window 函数(分析函数)
在标准 SQL:2003 中引入了 Window Function(窗口函数,也称为分析函数)。
假设 sales 表的内容如下:
mysql> SELECT * FROM sales ORDER BY country, year, product; +------+---------+------------+--------+ | year | country | product | profit | +------+---------+------------+--------+ | 2000 | Finland | Computer | 1500 | | 2000 | Finland | Phone | 100 | | 2001 | Finland | Phone | 10 | | 2000 | India | Calculator | 75 | | 2000 | India | Calculator | 75 | | 2000 | India | Computer | 1200 | | 2000 | USA | Calculator | 75 | | 2000 | USA | Computer | 1500 | | 2001 | USA | Calculator | 50 | | 2001 | USA | Computer | 1500 | | 2001 | USA | Computer | 1200 | | 2001 | USA | TV | 150 | | 2001 | USA | TV | 100 | +------+---------+------------+--------+
我们可以用聚合函数和 GROUP BY 求得“总利润”以及“每个国家的利润”。如:
mysql> SELECT SUM(profit) AS total_profit
FROM sales;
+--------------+
| total_profit |
+--------------+
| 7535 |
+--------------+
mysql> SELECT country, SUM(profit) AS country_profit
FROM sales
GROUP BY country
ORDER BY country;
+---------+----------------+
| country | country_profit |
+---------+----------------+
| Finland | 1610 |
| India | 1350 |
| USA | 4575 |
+---------+----------------+
窗口函数也能实现类似功能。和 GROUP BY 所不同的是,窗口函数不会合并结果,它为每一行都产生结果,如:
mysql> SELECT
year, country, product, profit,
SUM(profit) OVER() AS total_profit,
SUM(profit) OVER(PARTITION BY country) AS country_profit
FROM sales
ORDER BY country, year, product, profit;
+------+---------+------------+--------+--------------+----------------+
| year | country | product | profit | total_profit | country_profit |
+------+---------+------------+--------+--------------+----------------+
| 2000 | Finland | Computer | 1500 | 7535 | 1610 |
| 2000 | Finland | Phone | 100 | 7535 | 1610 |
| 2001 | Finland | Phone | 10 | 7535 | 1610 |
| 2000 | India | Calculator | 75 | 7535 | 1350 |
| 2000 | India | Calculator | 75 | 7535 | 1350 |
| 2000 | India | Computer | 1200 | 7535 | 1350 |
| 2000 | USA | Calculator | 75 | 7535 | 4575 |
| 2000 | USA | Computer | 1500 | 7535 | 4575 |
| 2001 | USA | Calculator | 50 | 7535 | 4575 |
| 2001 | USA | Computer | 1200 | 7535 | 4575 |
| 2001 | USA | Computer | 1500 | 7535 | 4575 |
| 2001 | USA | TV | 100 | 7535 | 4575 |
| 2001 | USA | TV | 150 | 7535 | 4575 |
+------+---------+------------+--------+--------------+----------------+
上面操作中,SUM 后面有 OVER 语句,SUM 在这里是“窗口函数”。上面例子中,第一个 OVER 语句是“空语句”,也就是把所有行作为一个 Partition,所以结果是“总利润”;而第二个 OVER 语句指定每个 country 都是一个 Partition,所以结果是“每个国家的利润”。
参考:https://dev.mysql.com/doc/refman/8.0/en/window-functions-usage.html
1.7.1. 对窗口命名(WINDOW)
当我们要重复引用一个窗口时,可以使用 WINDOW 语句对窗口进行命名。如下面例子:
mysql> SELECT *,
MIN(price) OVER(PARTITION BY FLOOR(UNIX_TIMESTAMP(timestamp)/(15 * 60))) AS min_price,
MAX(price) OVER(PARTITION BY FLOOR(UNIX_TIMESTAMP(timestamp)/(15 * 60))) AS max_price
FROM tbl1;
+------+---------------------+-------+-----------+-----------+
| id | timestamp | price | min_price | max_price |
+------+---------------------+-------+-----------+-----------+
| 1 | 2000-04-01 16:55:44 | 10 | 10 | 10 |
| 2 | 2000-04-01 17:01:41 | 50 | 20 | 50 |
| 3 | 2000-04-01 17:10:24 | 20 | 20 | 50 |
| 4 | 2000-04-01 17:11:14 | 40 | 20 | 50 |
| 5 | 2000-04-01 17:22:00 | 30 | 30 | 30 |
| 6 | 2000-04-01 17:30:00 | 10 | 10 | 40 |
| 7 | 2000-04-01 17:33:11 | 40 | 10 | 40 |
| 8 | 2000-04-01 17:45:00 | 60 | 60 | 60 |
+------+---------------------+-------+-----------+-----------+
这个例子中,两个 OVER 中的语句是相同的,下面例子中把它命名成了窗口 w :
mysql> SELECT *,
MIN(price) OVER w AS min_price,
MAX(price) OVER w AS max_price
FROM tbl1
WINDOW w AS (PARTITION BY FLOOR(UNIX_TIMESTAMP(timestamp)/(15 * 60))); -- 同上
1.8. UNION(和集),MINUS(EXCEPT,差集),INTERSECT(并集)
进行这些操作时,前后两个表必须具有相同的列数,且对应每列的类型必须兼容。
默认地,进行 UNION 操作时,结果集中的重复记录只会显示一条,如果想保留重复记录可以使用 UNION ALL ,如:
SQL> SELECT 123 FROM DUAL UNION SELECT 123 FROM DUAL;
123
----------
123
SQL> SELECT 123 FROM DUAL UNION ALL SELECT 123 FROM DUAL;
123
----------
123
123
说明:对于差集运算,Oracle 只能使用 MINIS 关键字,DB2 可以使用 EXCEPT 或 MINUS 关键字。
1.9. BLOB, CLOB
BLOB, CLOB 都是大字段类型,其中 BLOB 是用来存储大型二进制数据(Binary Large OBject);CLOB 用来存储大型文本数据(Character Large OBject)。
2. DB2 VS Oracle
2.1. Differents between DB2 and Oracle
Oracle 官方文档(迁移 DB2 到 Oracle):
http://docs.oracle.com/cd/E35137_01/nav/portal_booklist.htm
http://docs.oracle.com/cd/E35137_01/doc.32/e18460/oracle_db2_compared.htm
IBM 官方文档(迁移 Oracle 到 DB2):
Oracle to DB2 Conversion Guide for Linux, UNIX, and Windows
http://www.redbooks.ibm.com/abstracts/sg247048.html
DB2 and Oracle – An Architectural Comparison
ftp://ftp.software.ibm.com/software/data/db2/9/labchats/20110331-slides.pdf
第三方公司(sqlines)的文档:
IBM DB2 to Oracle Migration
http://www.sqlines.com/db2-to-oracle ,这里是它的一个 备份 。
2.2. Oracle 和 DB2 中 instance 概念的区别
Oracle terms "instance" & "database" often used interchangeably by DBAs and users, however:
- "instance" is logical (or temporal) and related to memory and processes.
- "database" is persistent and related to files.
Oracle database 中(非 RAC 环境),一个实例对应一个数据库(由 CREATE DATABASE 创建),实例和数据库的区别有点像操作系统中 process 和 program 的区别。
DB2 中,instance 是指 database manager,一个实例可以管理很多数据库(由 CREATE DATABASE 创建)。
An instance is a logical database manager environment where you catalog databases and set configuration parameters.
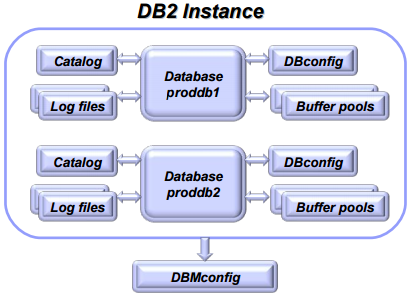
Figure 2: DB2 实例可管理多个数据库
参考:
http://db2commerce.com/2013/02/04/db2-basics-what-is-an-instance/
http://www-01.ibm.com/support/knowledgecenter/SSEPGG_9.7.0/com.ibm.db2.luw.admin.dbobj.doc/doc/c0004900.html
ftp://ftp.software.ibm.com/software/data/db2/9/labchats/20110331-slides.pdf
2.3. dual 表和 sysibm.sysdummy1 表
dual 表是 Oracle 中的内置表,Oracle 保证 dual 表中只有一条记录。
sysibm.sysdummy1 表是 DB2 中的内置表,DB2 保证 sysibm.sysdummy1 表中只有一条记录。
利用它们只有一条记录的特点,可以用它们来做计算,或查询系统的配置。
SQL> select (4+3) from dual;
(4+3)
----------
7
SQL> select user from dual;
USER
------------------------------
SCOTT
db2 => select (4+3) from sysibm.sysdummy1
1
-----------
7
1 record(s) selected.
db2 => select user from sysibm.sysdummy1
1
-----------
DB2INST1
1 record(s) selected.
2.4. WITH Queries (Common Table Expressions)
Common Table Expression 以 WITH 开头,也称为“WITH Queries”。它的用处如下:
Creating a common table expression saves you the overhead of creating and dropping a regular view that you need to use only once.
2.4.1. DB2 中的 common-table-expression
common-table-expression 以 WITH 打头,语法如下:
select-statement:
>>-+-----------------------------------+--fullselect--●--------->
| .-,-----------------------. |
| V | |
'-WITH----common-table-expression-+-'
>--+------------------+--●--+---------------------+--●---------->
+-read-only-clause-+ '-optimize-for-clause-'
'-update-clause----'
>--+------------------+--●-------------------------------------->
'-isolation-clause-'
>--+-------------------------------------+--●------------------><
'-concurrent-access-resolution-clause-'
common-table-expression:
>>-table-name--+---------------------------+-------------------->
| .-,-----------. |
| V | (1) |
'-(----column-name-+--)-----'
>--AS--(--fullselect--)----------------------------------------><
Notes:
1. If a common table expression is recursive, or if the fullselect results in duplicate column names, column names must be specified.
实例:
WITH
paylevel AS
(SELECT empno, YEAR(hiredate) AS hireyear, edlevel,
salary+bonus+comm AS total_pay
FROM employee
WHERE edlevel > 16
),
paybyed (educ_level, year_of_hire, avg_total_pay) AS
(SELECT edlevel, hireyear, AVG(total_pay)
FROM paylevel
GROUP BY edlevel, hireyear
)
SELECT empno, edlevel, year_of_hire, total_pay, avg_total_pay
FROM paylevel, paybyed
WHERE edlevel=educ_level
AND hireyear = year_of_hire
AND total_pay < avg_total_pay;
其中,paylevel 和 paybyed 是临时创建的表,仅在这个语句中使用。
2.4.2. Oracle 中的 subquery_factoring_clause
Oracle 中也有和 DB2 中 common-table-expression 对应的概念,就是 subquery_factoring_clause

Figure 3: subquery_factoring_clause in Oracle
2.5. Oracle 和 DB2 中 tablespace 概念的区别
Table space 在 DB2 和 Oracle 中的含义有所不同。
A DB2® table space is a set of volumes on disks that hold the data sets in which tables are actually stored. All tables are kept in table spaces. A table space can have one or more tables.
As a general rule, you should have only one table in each table space. (IBM 不推荐在 1 个 table space 中放多个 table,在 z/OS db2 中创建 table 时,如果不指定 table space,会自动创建一个和 table 名相同的 table space)
An Oracle database consists of one or more tablespaces. Tablespaces provide logical storage space that links a database to the physical disks hold the data. A tablespace is created from one or more datafiles. Datafiles are files in the file system or an area of disk space specified by a device. A tablespace can be enlarged by adding more datafiles.
参考:http://docs.oracle.com/cd/E35137_01/doc.32/e18460/oracle_db2_compared.htm
说明:DB2 中 table space 是物理存储概念;而 Oracle 中的 table space 是逻辑存储概念,datafile 才是物理存储的概念。
做数据库迁移时,它们是怎么的对应关系呢?请参考:
http://docs.oracle.com/cd/E35137_01/doc.32/e18460/oracle_db2_compared.htm#autoId8
3. Common Schema Objects
3.1. View
视图(view)是另一种察看一张或多张表中数据的方式。它就像在一个幻灯片上放一个覆盖物,以允许人们只能看到该幻灯片的一部分内容。例如,您可以在部门表上创建一个视图,使得用户只能去访问特定部门并更新其工资信息。您不希望让用户看到其他部门的工资信息。您创建的表的视图使用户只能去访问一个部门,而用户像使用表一样地使用该视图。因此,视图的使用是出于安全性的原因。大多数公司并不允许用户直接访问表,而是利用一个视图来完成它。用户通过视图来访问。对于缺乏经验的用户而言,视图可以被用来简化复杂的查询。
Use the CREATE VIEW statement to define a view, which is a logical table based on one or more tables or views. A view contains no data itself.
参考:
http://docs.oracle.com/cd/E11882_01/server.112/e41084/statements_8004.htm#SQLRF01504
http://www-01.ibm.com/support/knowledgecenter/SSEPGG_10.5.0/com.ibm.db2.luw.sql.ref.doc/doc/r0000935.html?cp=SSEPGG_10.5.0%2F2-12-7-117&lang=en
3.1.1. with check option
with check option 可以用来限制对视图的操作。
我们来看下面的例子:
CREATE VIEW testview AS SELECT empno,ename FROM emp WHERE ename LIKE 'M%' WITH CHECK OPTION;
这里我们创建了一个视图,并使用了 with check option 来限制了视图。先查看视图的内容:
SQL> select * from testview EMPNO ENAME ----- ----- 7654 MARTIN 7934 MILLER
用下面语句更新其中一条记录:
UPDATE testview SET ename = 'Mike' WHERE empno = 7654;
这条更新语句可以成功执行,再执行另一条更新语句:
UPDATE testview SET ename = 'Robin' WHERE empno = 7654;
这条更新语句会出现错误“ORA-01402: view WITH CHECK OPTION where-clause violation”。这是因为前面我们在创建视图时指定了 witch check option 关键字,也就是说,更新后的每一条数据仍然要满足创建视图时指定的 where 条件,不满足就报错。
3.2. Trigger
数据库中出现特定的事件时,触发器会自动执行。在 SQL:2003 标准中定义了触发器,但标准推出的时间太晚,导致各个 RDBMS 产品中触发器语法都不同。
3.2.1. trigger 例子
要求:创建一个 trbu_product 触发器,每当 product 表中的 prod_price_n 值发生改变时,该触发器就把一行插入到专门的审核表 product_audit 中。记录信息包括被修改行的主键、新的和旧的价格、修改该记录的用户名以及时间戳。
Oracle 中方法如下:
CREATE OR REPLACE TRIGGER trbu_product
BEFORE UPDATE OF prod_price_n ON product
FOR EACH ROW
BEGIN
INSERT INTO product_audit
VALUES (:NEW.prod_id_n,
:OLD.prod_price_n,
:NEW.prod_price_n,
USER,
SYSDATE);
END;
DB2 中方法如下:
CREATE TRIGGER trbu_product
AFTER UPDATE OF prod_price_n ON product
REFERENCING NEW AS NNN OLD AS OOO
FOR EACH ROW MODE DB2SQL
BEGIN ATOMIC
INSERT INTO product_audit
VAULES (NNN.prod_id_n,
OOO.prod_price_n,
NNN.prod_price_n,
USER,
CURRENT DATE);
END
说明 1:Oracle 和 DB2 都支持语句 REFERENCING NEW AS NNN OLD AS OOO 来定制修改前和修改后的列值标记。
说明 2:Oracle 中可以直接使用:OLD 和:NEW 标记修改前和修改后的列值;而 DB2 中必须显式定制,例子中使用 OOO 和 NNN。
说明 3:触发器在 Oracle 中不能用一般的 SQL 语句定义,而是用 PL/SQL 定义。
参考:
SQL 宝典,原书第二版,14.5.1 CREATE TRIGGER 语法
http://docs.oracle.com/cd/E11882_01/appdev.112/e25519/create_trigger.htm#LNPLS01374
3.3. Sequence
Sequence 是数据库中按照一定规则自动增加的数字序列,这个序列一般作为代理主键。
Oracle、DB2、PostgreSQL 等数据库有 Sequence;且用 currval, nextval 分别表示 Sequence 的当前值和下一个值。
注:MySQL、SQL Server、Sybase 等数据库没有 Sequence 对象。
3.3.1. MySQL,SQL Server 的自增
MySQL 使用关键字 AUTO_INCREMENT 指定某列自增,SQL Server 使用关键字 IDENTITY 指定某列自增。
说明:
Sequence 是数据库系统中的一个对象,可以在整个数据库中使用,和表没有任何关系。
MySQL 中的 AUTO_INCREMENT 或者 SQL Server 中的 IDENTITY 仅仅是指定在表中某一列上,作用范围只是这个表。
3.4. Partition
A partition is a division of a logical database or its constituent elements into distinct independent parts. Database partitioning is normally done for manageability, performance or availability reasons.
PARTITION 技术常用于构建数据仓库。PARTITION 语句在 CREATE TABLE 语句里指定。
3.4.1. Oracle 分区
Oracle 为构建数据仓库提供了 4 种类型的分区方法:Range Partition, Hash Partition, List Partition, Composite Partition.
Range Partition
这是最常用的分区方法,基于列的值范围做分区,最常见的是基于时间字段的数据的范围的分区,比如:对于 SALE 表,可以对销售时间按照月份做一个 Range Partition。
CREATE TABLE sales_range
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
COMPRESS
PARTITION BY RANGE(sales_date)
(PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','DD/MM/YYYY')),
PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','DD/MM/YYYY')),
PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('04/01/2000','DD/MM/YYYY')),
PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('05/01/2000','DD/MM/YYYY')));
分区的好处:如果要查询 2000 年 2 月的数据,将直接找到 2000 年 2 月的分区,避免了大量不必要的数据扫描。
3.4.2. DB2 分区
DB2 分区语法和 Oracle 有差异。如,DB2 采用 ENDING AT 关键字,而不是 Oracle 的 VALUES LESS THAN 。当分区特征列为数字类型时,DB2 中的 ENDING AT (n) 相当于 Oracle 中的 VALUES LESS THAN (n+1) 。
参考:
http://www-01.ibm.com/support/knowledgecenter/SSEPGG_10.5.0/com.ibm.db2.luw.sql.ref.doc/doc/r0000927.html?cp=SSEPGG_10.5.0%2F2-12-7-101&lang=en
http://www.ibm.com/developerworks/cn/data/library/techarticles/dm-0608mcinerney/
3.5. Constraint 和 Index 区别
约束(Constraint)是关系模型理论中的部分,属于逻辑层面的概念,有主键(Primary Key),外键(Foreign Key)等,用于保证数据完整性、唯一性等用途。
而索引(Index)则处于实现层面,比如可以对表的任意列建立索引。如果建立索引的列处于 SQL 语句中的 Where 条件中时,就可以得到快速的数据定位,从而进行更快的检索。
说明:对于 Oracle database,会自动对主键和唯一键建立索引。
4. Dynamic SQL
What is Dynamic SQL?
Dynamic SQL is a programming technique that enables you to build SQL statements dynamically at runtime. You can create more general purpose, flexible applications by using dynamic SQL because the full text of a SQL statement may be unknown at compilation. For example, dynamic SQL lets you create a procedure that operates on a table whose name is not known until runtime.
However, some applications must accept (or build) and process a variety of SQL statements at run time. For example, a general-purpose report writer must build different SELECT statements for the various reports it generates. In this case, the statement's makeup is unknown until run time. Such statements can, and probably will, change from execution to execution. They are aptly called dynamic SQL statements.
如:程序中嵌入 SQL 语句时,表名和字段名保存在程序的变量中,既然在变量中,则运行时表名和字段名才有具体的值,这时就要用 Dynamic SQL 了。
参考:http://docs.oracle.com/cd/B10501_01/appdev.920/a96590/adg09dyn.htm
5. Referential integrity
引用完整性(referential integrity)是指为两个表中存在一定的联系,从而保证数据的完整性。例如:班级和学生,学生所在班级一定是在班级表中所存在的,不然就会出现不准确。引用完整性可以通过“外键”约束来实现。
参考:
http://en.wikipedia.org/wiki/Referential_integrity
http://www.databasejournal.com/features/db2/article.php/3870031/Referential-Integrity-Best-Practices-for-IBM-DB2.htm
http://www.cnblogs.com/zhengcheng/p/4177669.html
6. Deadlocks
A deadlock is created when two applications lock data that is needed by the other, resulting in a situation in which neither application can continue executing.
For example, in Figure 4, there are two applications running concurrently: Application A and Application B. The first transaction for Application A is to update the first row in Table 1, and the second transaction is to update the second row in Table 2. Application B updates the second row in Table 2 first, and then the first row in Table 1. At time T1, Application A locks the first row in Table 1. At the same time, Application B locks the second row in Table 2. At time T2, Application A requests a lock on the second row in Table 2. However, at the same time, Application B tries to lock the first row in Table 1. Because Application A will not release its lock on the first row in Table 1 until it can complete an update to the second row in Table 2, and Application B will not release its lock on the second row in Table 2 until it can complete an update to the first row in Table 1, a deadlock occurs. The applications wait until one of them releases its lock on the data.
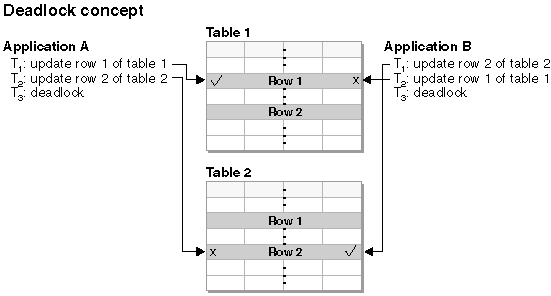
Figure 4: Deadlock between applications