Event-Driven Architecture
Table of Contents
1. 事件驱动架构
在分布式应用(如微服务)中,事件驱动 是一种常见的架构。在这种架构中,当某件重要事情发生时,微服务(如 A)会发布一个事件,例如更新一个业务实体;当订阅这类事件的微服务(如 B)接收此事件时,就可以更新自己的业务实体,也可能会引发更多的事件发布。
1.1. 事件发布的潜在风险
下面以用户在购物网站下订单为例介绍一下事件驱动架构。假设服务 A 是“订单服务”、而服务 B 是“商品服务(库存服务)”,不同服务有各自独立的数据库。
用户下单时,订单服务必须向 order 表插入一行,然后发布“order created”事件,这两个操作需要原子性。 库存服务收到“order created”消息后,减少其库存。
订单服务的相关代码(注:这个代码是有问题的)如下:
public void trans() {
try {
// 1. 操作数据库(如创建订单)
bool result = dao.update(mode1); // 操作数据库失败,会抛出异常
// 2. 如果第一步成功,则操作消息队列(如投递创建订单的消息)
if(result) {
mq.append(mode1); // 如果mq.append方法执行失败,会抛出异常
}
} catch (Exception e) {
roolback(); // 如果发生异常,就回滚
}
}
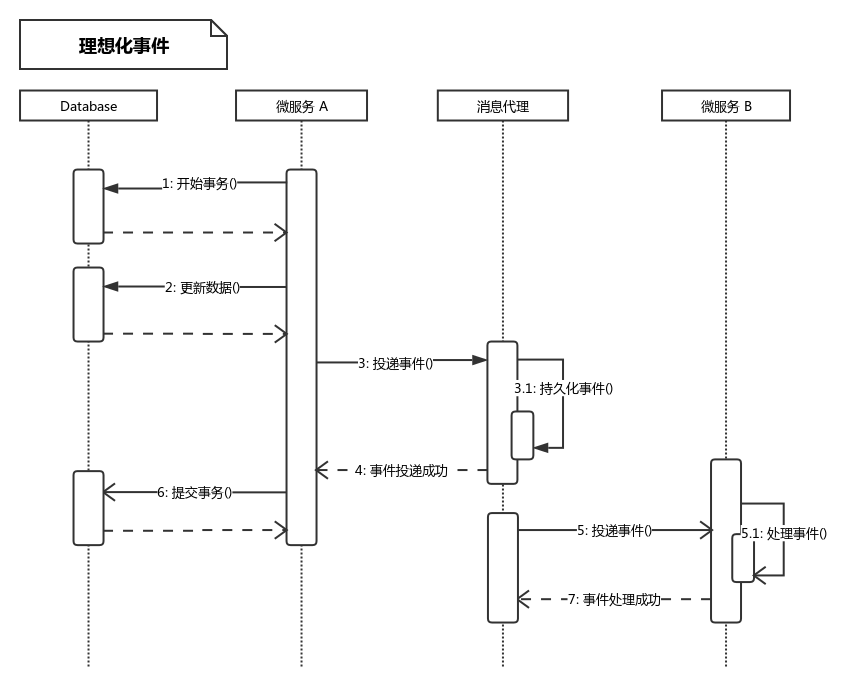
Figure 1: 理想化的情况
根据上面代码和时序图 1 ,理想化的情况会出现 3 种情况:
- 操作数据库成功,向消息代理投递事件也成功;
- 操作数据库失败,不会向消息代理中投递事件了;
- 操作数据库成功,但是向消息代理中投递事件时失败,向外抛出了异常,刚刚执行的更新数据库的操作将被回滚。
不过,还有其它情况可能导致“创建订单”和发布“order created”事件不具有原子性,其中最容易出现的错误就是网络 I/O 和服务器宕机。
网络 I/O 异常如图 2 所示。
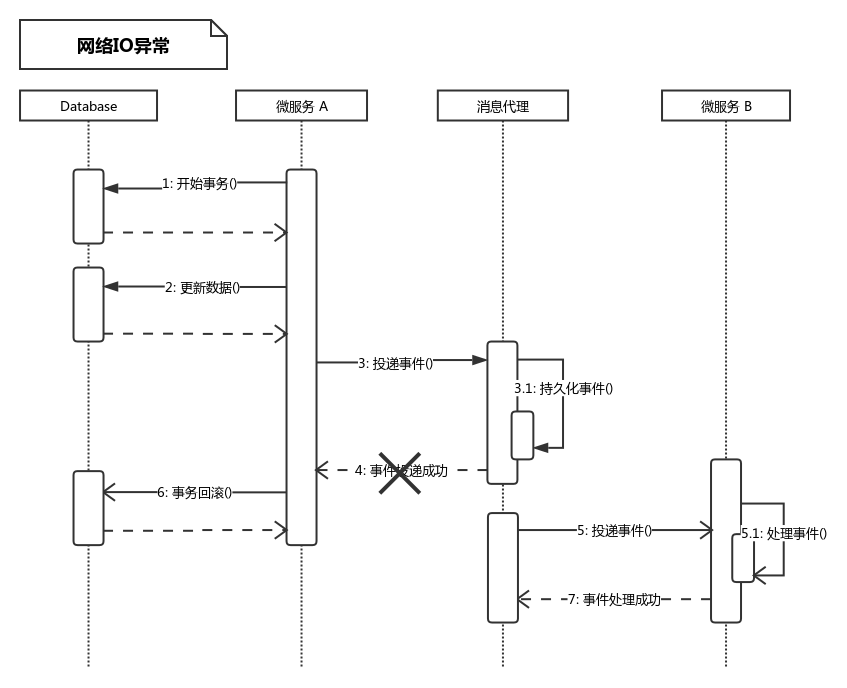
Figure 2: 网络 I/O 异常
微服务 A 投递事件时,消息代理已经接收到消息,并进行持久化成功,即消息发送至消息代理,需要向微服务 A 返回响应的时候,网络发生异常,即 4 出现错误,代码中的 mq.append()方法抛出异常,最终结果是事件投递成功,但是数据库被回滚。
服务器宕机如图 3 所示。
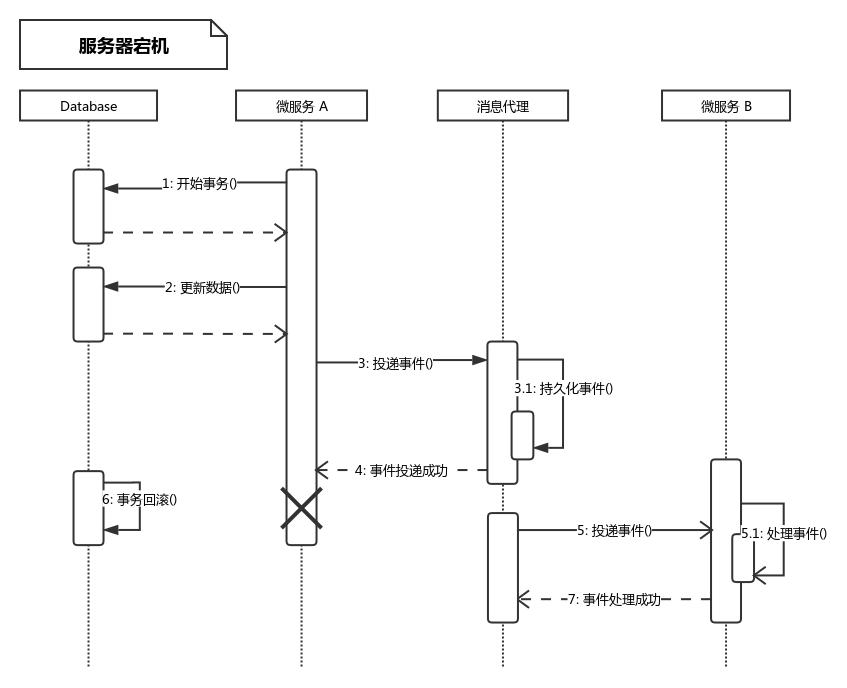
Figure 3: 服务器宕机
微服务 A 在投递成功后,向数据库提交 commit 请求之前发生宕机,数据库因为连接异常关闭而回滚。最终结果还是事件被投递,数据库却被回滚。
在单服务器情况下,上面提到的两种异常发生概览不大,但是在当前多服务器、网络情况复杂的环境中,发生的概率被大大放大,由于是异步处理,一旦问题发生,排错将变得更加困难。
下文将介绍两种方法,他们可以让服务 A 中“创建订单”和发布“order created”事件这两个操作具有原子性。这两种方法在文章 Event-Driven Data Management for Microservices 中都有介绍。
这里提前打个招呼, 如果“订单服务”和“库存服务”是两个独立的服务,尽管我们可以保证数据最终一致,但却不能严格地实现“没有库存就不会生成订单”这个要求, 参见 3
1.2. 保证原子性:使用本地事件表(把待发布事件先持久化到本地数据库中)
本地事件表方法将事件和业务数据保存在同一个数据库中,使用一个额外的“事件恢复”服务来恢复事件, 由本地事务保证更新业务(如创建订单)和发布事件的原子性。 考虑到事件恢复可能会有一定的延时,服务在完成本地事务后可立即向消息代理发布一个事件。
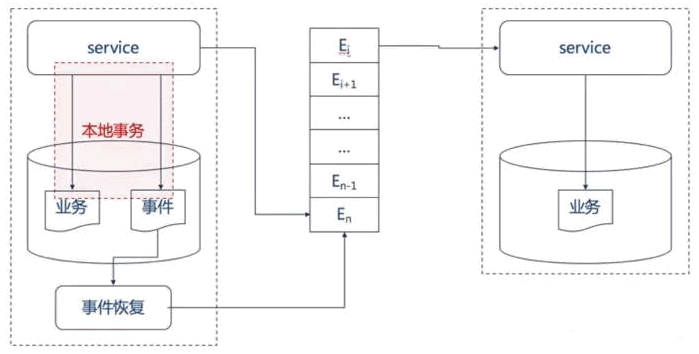
Figure 4: event_driven_004
这种思想很简单, 就是先把需要投递的事件持久化到本地数据库一个表(称为本地事件表)中。利用数据库的本地事务来保证业务涉及的数据库操作和发布事件的原子性。
- 微服务在同一个本地事务中记录业务数据和事件数据。
- 微服务实时发布一个事件关联业务服务中,如果事件发布成功立即删除记录的事件,这样能够保证事件投递的实时性。
- 事件恢复服务定时从事件表中恢复未发布成功的事件,重新发布,重新发布成功后删除记录的事件,这样能够保证事件一定能够被投递。
这样能够很好的解决上面提到的网络 I/O 异常和服务器宕机的问题,但它也有不足:业务系统和事件耦合在一起,额外的事件数据操作给数据库带来压力,也成为异步事件机制的一个瓶颈。
1.3. 保证原子性:挖掘数据库日志
还有一种办法可以实现前面例子中服务 A 业务逻辑(创建订单)和发布“order created”事件两个动作的原子性。
使用数据库(MySQL)的 Binlog 跟踪数据库的变更通知。 订阅 MySQL Binlog 的项目有 LinkedIn 的 Databus 和阿里的 Canal 等等。从 Databus/Canal 中读取消息,如果当前消息是“创建订单”的消息,就发布“order created”事件,发布事件成功后再从 Databus/Canal 中删除当前消息。
这种办法的优点是:简化了服务 A 的业务逻辑,不用创建一个额外的“本地事件表”,把“事件发布”过程解耦到单独的组件了。
但它也有一些不足:1、Binlog 的格式不同数据库不一样,同一个数据库的不同版本其 Binlog 也可能不一样。Databus/Canal 可能只支持特定版本的数据库。2、有时可能很难从底层的数据库变化推断出高层的业务逻辑。尽管前面介绍的例子比较简单,我们容易反向推断出“创建订单”这个业务逻辑。其它场景却不一定可方便地推断出高层的业务逻辑。
2. 事件驱动架构的优缺点
事件驱动架构的优点:
- 可以解耦不同模块,尽管交易跨多个服务,但可提供“最终一致性”。
- 没有使用强一致性,它可以提供更好的性能,适用于“抢购”等场景。
事件驱动架构也有缺点:
- 编程模式比传统 ACID 交易模式更加复杂。
- 并不是严格一致性,如果失败需要补偿性措施。如有两个操作 X(创建订单)和 Y(减少库存)。X 操作(创建订单)成功后,但 Y 操作(减少库存)却一直无法成功地执行(库存不足,无法减少了),那么一致性也会被破坏,需要考虑一些兜底方案,如库存服务发布“库存不足”事件,订单服务修改订单为“库存不足”。
3. 对用户体验的改变
使用事件驱动后(这里主要指把“订单服务”和“库存服务”拆为两个独立服务的微服务架构),用户的体验有可能会有改变。比如原来同步架构(单体架构)的时候没有库存,就马上告诉你条件不满足无法下单,不会生成订单;但是改了事件机制,订单是立即生成的,很可能过了一会系统通知你订单被取消掉。就像抢购“小米手机”一样,几十万人在排队,排了很久告诉你没货了,明天再来吧。如果希望用户立即得到结果,可以在前端想办法,在 BFF(Backend For Frontend)使用 CountDownLatch 这样的锁把后端的异步转成前端同步,当然这样 BFF 消耗比较大。
产品经理说用户的体验必须是“没有库存就不会生成订单”,怎么办?那就把订单服务和库存服务合在一起吧,一个服务两个聚合根。我并不是一个理想主义者,解决当前的问题是我首先要考虑的,我们设计微服务的目的是本想是解决业务并发量。而现在面临的却是用户体验的问题,所以架构设计也是需要妥协的(但是至少分析完了,我知道我妥协在什么地方,为什么妥协,未来还有可能改变。)
4. 参考
Event-Driven Data Management for Microservices: https://www.nginx.com/blog/event-driven-data-management-microservices/
微服务架构下的数据一致性:可靠事件模式: https://blog.csdn.net/liuxinghao/article/details/51924877
多研究些架构,少谈些框架(3)-- 微服务和事件驱动: https://juejin.im/entry/594a27728d6d8109de294006