Go Concurrency
Table of Contents
1. Go 并发简介
本文介绍 Go 的并发编程,主要参考“Concurrency in Go”,推荐直接阅读原书。
1.1. Race Conditions(竞争条件)
下面是一段存在竞争条件的代码:
1: // 警告:下面代码存在竞争条件! 2: package main 3: 4: import "fmt" 5: 6: func main() { 7: var data int 8: 9: go func() { 10: data++ 11: }() 12: 13: if data == 0 { 14: fmt.Printf("the value is %v.\n", data) 15: } 16: }
上面代码存在竞争条件,有 3 个可能输出(尽管你每次可能得到相同输出):
1、什么都没有输出,这个情况下,第 10 行执行在第 13 行前。
2、输出了"the value is 0",这个情况下,第 13 行和第 14 行执行在第 10 行前。
3、输出了"the value is 1",这个情况下,第 13 行执行在第 10 行前,同时第 10 行执行在第 14 行前。
1.1.1. Race Detection(-race)
在 Go 1.1 中,给大部分 go 命令引入了 -race 参数,可以检测竞争条件。
$ go test -race mypkg # test the package $ go run -race mysrc.go # compile and run the program $ go build -race mycmd # build the command $ go install -race mypkg # install the package
下面是测试上一节代码中的竞争条件的例子:
$ go run -race bad.go # 增加 -race 参数可检测竞争条件
the value is 0.
==================
WARNING: DATA RACE
Write at 0x00c4200a4008 by goroutine 6:
main.main.func1()
/Users/cig01/test/bad.go:9 +0x4e
Previous read at 0x00c4200a4008 by main goroutine:
main.main()
/Users/cig01/test/bad.go:12 +0x88
Goroutine 6 (running) created at:
main.main()
/Users/cig01/test/bad.go:8 +0x7a
==================
Found 1 data race(s)
exit status 66
注 1: -race 不是银弹, 只有当 Race Conditions 已经发生的情况下 -race 才能检测出来。
注 2:默认检测报告输出在 stderr 中,可以通过在环境变量 GORACE 中指定 log_path 把检测报告保存到文件中,如:
$ GORACE="log_path=/tmp/go_race_report" go run -race bad.go the value is 0. exit status 66
这样,检测报告会保存到文件“/tmp/go_race_report.pid”中。
1.2. sync VS. channel
如何在 sync 库和 channel 之间选择呢?图 1 可以帮你决策。关于这个图的详细说明可参考:Concurrency in Go, Chapter 2
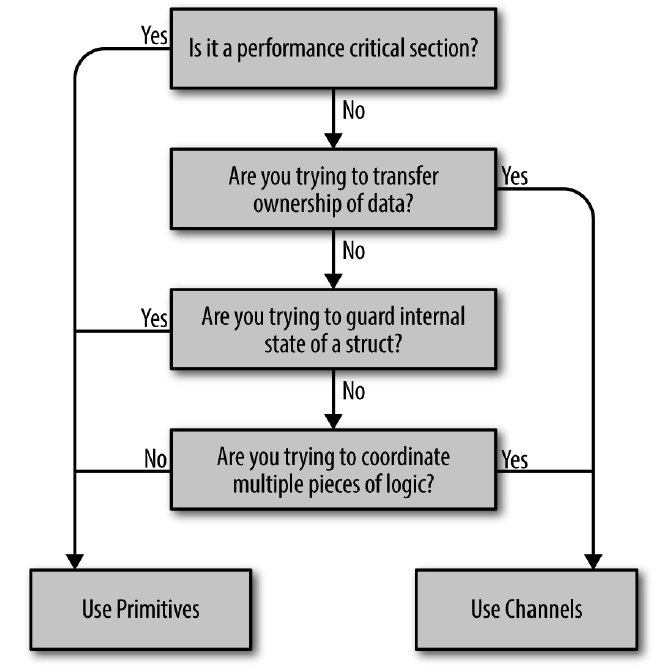
Figure 1: Decision tree for sync and channel
2. sync 包
Go 中的 sync 库提供了一些基本的同步原语。除了 Once 类型和 WaitGroup 类型外,包中的大多数其它类型(如 Mutex,Cond 等)都是为底层函数库程序准备的,高层次的同步最好还是通过 channel 来完成。
2.1. sync.Once(全局唯一性操作)
对于从全局的角度只需要运行一次的代码,比如全局初始化操作,Go 语言提供了一个 Once 类型来保证全局的唯一性操作,具体代码实例如下:
var a string
var once sync.Once
func setup() {
a = "hello, world"
}
func doprint() {
once.Do(setup) // 可保证setup方法只会被调用一次,就算多次调用doprint
print(a)
}
func twoprint() {
go doprint()
go doprint()
}
2.2. sync.WaitGroup
可以认为 WaitGroup 内部维护着一个并发安全的计数器,调用 Add(n) 时会把计数器增加 n ,调用 Done() 时会把计数器减少 1。调用 Wait() 会阻塞执行直到计数器变为 0。
下面是使用 sync.WaitGroup 的例子:
package main
import (
"net/http"
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
var urls = []string{
"http://www.golang.org/",
"http://www.google.com/",
"http://www.somestupidname.com/",
"http://nosuch/",
}
for _, url := range urls {
// Increment the WaitGroup counter.
wg.Add(1)
// Launch a goroutine to fetch the URL.
go func(url string) {
// Decrement the counter when the goroutine completes.
defer wg.Done()
// Fetch the URL.
response, err := http.Get(url)
if err != nil {
fmt.Printf("Error=%s\n", err)
} else {
fmt.Printf("StatusCode=%d, url=%s\n", response.StatusCode, url)
}
}(url)
}
// Wait for all HTTP fetches to complete.
wg.Wait()
}
运行上面程序,可能得到下面输出:
StatusCode=502, url=http://nosuch/ StatusCode=200, url=http://www.google.com/ StatusCode=200, url=http://www.somestupidname.com/ StatusCode=200, url=http://www.golang.org/
下面是使用 sync.WaitGroup 的另一个例子:
package main
import (
"fmt"
"sync"
)
func main() {
hello := func(wg *sync.WaitGroup, id int) {
defer wg.Done()
fmt.Printf("Hello from %v!\n", id)
}
const numGreeters = 5
var wg sync.WaitGroup
wg.Add(numGreeters)
for i := 0; i < numGreeters; i++ {
go hello(&wg, i+1)
}
wg.Wait()
}
运行上面程序,可能得到下面输出:
Hello from 5! Hello from 3! Hello from 1! Hello from 4! Hello from 2!
2.3. sync.Mutex, sync.RWMutex(锁)
下面是使用 sync.RWMutex 实现一个并发安全计数器的例子:
package main
import (
"fmt"
"sync"
"time"
)
// SafeCounter is safe to use concurrently.
type SafeCounter struct {
value int
mux sync.RWMutex
}
// Inc increments the counter
func (c *SafeCounter) Inc() {
c.mux.Lock() // 加锁(“写锁”)
c.value++
c.mux.Unlock()
}
// Value returns the current value of the counter for the given key.
func (c *SafeCounter) GetValue() int {
c.mux.RLock() // 加“读锁”
defer c.mux.RUnlock()
return c.value
}
func main() {
counter := SafeCounter{value: 0}
for i := 0; i < 1000; i++ { // 启动1000个goroutine,每个都对counter增加1
go counter.Inc()
}
time.Sleep(1 * time.Second) // 等待1000个goroutine结束,这里仅简单地等待1秒
fmt.Println(counter.GetValue()) // 输出counter的值
}
2.4. sync.Cond(条件变量)
条件变量用来更好地管理“获得了锁,但由于某些条件未满足而无事可做的 goroutine”。
下面先介绍不使用条件变量的例子(生产者往队列 items 中添加元素,而消费者删除 items 中的元素):
1: package main 2: 3: import ( 4: "fmt" 5: "math/rand" 6: "sync" 7: "time" 8: ) 9: 10: func main() { 11: 12: var mutex sync.Mutex // 写为 var mutex = new(sync.Mutex) 也行 13: var items []int 14: 15: go func() { 16: // 消费者代码(删除队列items中的元素) 17: for { 18: mutex.Lock() 19: for len(items) > 0 { // 消耗队列items中所有元素 20: lastIndex := len(items) - 1 21: lastItem := items[lastIndex] 22: items = items[:lastIndex] // 删除最后一个元素 23: fmt.Printf("consume %d\n", lastItem) 24: } 25: mutex.Unlock() 26: 27: // 必需Sleep,否则当队列items为空时CPU占用会很高 28: time.Sleep(10 * time.Millisecond) // 很难决定Sleep多久合适! 29: } 30: }() 31: 32: // 生产者代码(往队列items中增加元素) 33: for { 34: newItem := rand.Intn(10000) 35: 36: mutex.Lock() 37: items = append(items, newItem) 38: fmt.Printf("produce %d\n", newItem) 39: mutex.Unlock() 40: 41: // Other works 42: time.Sleep(time.Duration(rand.Intn(10)) * time.Second) 43: } 44: }
在消费者代码相关片断中,如果队列 items 一直为空,则第 19 行的 for 循环条件不会满足,则消费者就在不停地 Lock/Unlock/Sleep,白白浪费 CPU 资源, 第 28 行 Sleep 多久是很难决定的(Sleep 太短了,很可能浪费更多的 CPU 资源;Sleep 太长了,队列中的元素不会被及时地消费掉)。
条件变量可以解决上面的问题:可实现当队列中有元素了,由生产者通知消费者!具体实现参考下表右半部分。
| 不用条件变量 | 使用条件变量(更好) |
2.5. sync.Pool(临时对象池)
Go 1.3 在 sync 包中增加了 Pool,它主要用来保存和复用临时对象,以减少内存分配,降低 GC 压力。
调用 Get() 方法当 Pool 中有对象时会返回 Pool 中的任意一个对象,且在返回给调用者前从 Pool 中删除相应的对象。如果 Pool 为空,则调用 New 返回一个新创建的对象;如果没有设置 New,则返回 nil。调用 Put(x) 方法可以把对象 x 放入到 Pool 中。
注: 我们不能自由控制 Pool 中元素的数量,且放进 Pool 中的对象在每次 GC 发生时都会被清理掉。 如果用它来实现数据库连接池有点心有余而力不足,比如:在高并发时一旦 Pool 中的连接被 GC 清理掉,后面操作数据库需要重新建立连接,代价太大。
下面是 sync.Pool 的一个例子:
1: package main 2: 3: import ( 4: "fmt" 5: "sync" 6: "runtime" 7: ) 8: 9: func main() { 10: myPool := &sync.Pool{ 11: New: func() interface{} { 12: fmt.Println("Creating new instance.") 13: return struct{}{} 14: }, 15: } 16: 17: fmt.Println("line 17") 18: myPool.Get() // myPool中没对象,调用Get()会触发New() 19: fmt.Println("line 19") 20: myPool.Get() // myPool中没对象,调用Get()会触发New() 21: fmt.Println("line 21") 22: myPool.Get() // myPool中没对象,调用Get()会触发New() 23: fmt.Println("line 23") 24: myPool.Put(myPool.New()) // 加入一个对象到myPool中 25: fmt.Println("line 25") 26: myPool.Put(myPool.New()) // 加入一个对象到myPool中 27: fmt.Println("line 27") 28: myPool.Get() // myPool中有两个对象,调用Get()会取出其中一个对象,Pool中还剩下一个对象 29: fmt.Println("line 29") 30: runtime.GC() // 执行GC时会清除myPool中所有对象 31: myPool.Get() // 此时,myPool中没对象,调用Get()会触发New() 32: fmt.Println("line 32") 33: }
运行上面程序,将得到下面输出:
line 17 Creating new instance. line 19 Creating new instance. line 21 Creating new instance. line 23 Creating new instance. line 25 Creating new instance. line 27 line 29 Creating new instance. line 32
下面是官方文件中介绍的 sync.Pool 的应用举例:
An example of good use of a Pool is in the fmt package, which maintains a dynamically-sized store of temporary output buffers. The store scales under load (when many goroutines are actively printing) and shrinks when quiescent.
2.6. sync.Map(并发安全的 Map)
Go 中 map 不是并发安全的。假设有 10 个 goroutines,它们“同时”写入某一个 map 中不同的 key,这种场景“按理说”由于每个 goroutine 访问的 key 不同,不会有竞争条件。但 Go 中这种场景并不是并发安全的。同时写不同的 key 可能同时操作 map 内部维护的公共状态,从而导致竞争条件。参考:https://groups.google.com/g/golang-nuts/c/_XHqFejikBg
package main
import (
"log"
"strconv"
"sync"
)
func main() {
var myMap = make(map[int]string)
// 并发写入 map
var wg sync.WaitGroup
for i := 0; i <= 99; i++ {
wg.Add(1)
go func(key int) {
defer wg.Done()
value := "value" + strconv.Itoa(key)
myMap[key] = value // 尽管每个 goroutine 访问 map 的 key 不同,但这在 Go 中存在竞争条件!
}(i)
}
wg.Wait()
// 依次输出每个 key
for i := 0; i <= 99; i++ {
result, ok := myMap[i]
if ok {
log.Printf("%v=%v", i, result)
} else {
log.Printf("value not found for key: %v", i)
}
}
}
Go 1.9 在 sync 包中增加了并发安全的 Map 。使用方法 Store/Load/Delete 可分别实现并发安全地增加、获取、删除 Map 中的元素。
下面是使用 sync.Map 解决上面例子中的竞争条件的例子:
package main
import (
"log"
"strconv"
"sync"
)
func main() {
var myMap sync.Map
// 并发写入 map
var wg sync.WaitGroup
for i := 0; i <= 99; i++ {
wg.Add(1)
go func(key int) {
defer wg.Done()
value := "value" + strconv.Itoa(key)
myMap.Store(key, value) // 并发安全,无竞争条件
}(i)
}
wg.Wait()
// 依次输出每个 key
for i := 0; i <= 99; i++ {
result, ok := myMap.Load(i)
if ok {
log.Printf("%v=%s", i, result.(string))
} else {
log.Printf("value not found for key: %v", i)
}
}
// 使用 Range 也可以遍历 Map 中的每个 key-value 对
myMap.Range(func(k, v interface{}) bool {
log.Printf("%v=%s", k, v.(string))
return true
})
}
不过,使用 Load 读取出来的数据的类型是 any 类型(即 interface{} 类型),需要进行一次 Type assertion 才能得到具体的类型,有点不方便。
3. sync/atomic 包
Go 中 sync/atomic 包提供了一些可用于实现同步算法的原子内存原语。
下面是使用 atomic.AddUint64 实现计算器的例子:
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
// We'll use an unsigned integer to represent our
// (always-positive) counter.
var ops uint64
// A WaitGroup will help us wait for all goroutines
// to finish their work.
var wg sync.WaitGroup
// We'll start 50 goroutines that each increment the
// counter exactly 1000 times.
for i := 0; i < 50; i++ {
wg.Add(1)
go func() {
for c := 0; c < 1000; c++ {
// To atomically increment the counter we
// use `AddUint64`, giving it the memory
// address of our `ops` counter with the
// `&` syntax.
atomic.AddUint64(&ops, 1)
}
wg.Done()
}()
}
// Wait until all the goroutines are done.
wg.Wait()
// It's safe to access `ops` now because we know
// no other goroutine is writing to it. Reading
// atomics safely while they are being updated is
// also possible, using functions like
// `atomic.LoadUint64`.
fmt.Println("ops:", ops) // 输出 ops: 50000
}
上面代码中,ops 是所有 goroutine 都可以访问的变量,对它进行加 1 操作需要使用 atomic.AddUint64(&ops, 1) ,这样能保证 ops 最终的值为 50000。如果在 goroutine 中简单地使用 op++ 来它进行加 1 操作,则会出现竞争条件,导致 ops 最终的值不一定为 50000(可能每次不一样)。
4. golang.org/x/sync 包
golang.org/x/sync 包提供了其它一些同步工具:
- semaphore(信号量)
- singleflight(将一组相同的请求合并成一个请求,实际上只会请求一次,然后对所有的请求返回相同的结果。可用于避免 Cache penetration)
- errgroup(在 WaitGroup 的基础上实现子协程错误传递,同时使用 context 控制协程的生命周期)
5. Concurrency Patterns in Go
5.1. Confinement
5.1.1. Ad hoc confinement
所谓 Ad hoc confinement,就是通过一些约定(比如社区的约定,开发小组的约定)来实现的并发安全。但这些约定是很脆弱的,随着开发者的变化,很可能一不小心就打破了约定。 我们应该避免 Ad hoc confinement。
比如,下面代码对 data 的访问是安全的,因为只有 loopData 访问了它(可以认为这是一个约定)。但 loopData 以外的其它代码也是可以访问 data 的,而一旦 loopData 外的代码修改了 data,则程序的行为可以变得不确定。
data := make([]int, 4)
loopData := func(ch chan<- int) {
defer close(ch)
for i := range data {
ch <- data[i]
}
}
handleData := make(chan int)
go loopData(handleData)
for num := range handleData {
fmt.Println(num)
}
5.1.2. Lexical confinement
Lexical confinement 是指通过“词法作用域来限制数据的访问,从而实现并发安全”。它比 Ad hoc confinement 要安全,推荐使用。如:
package main
import "fmt"
func main() {
chanOwner := func() <-chan int { // chanOwner返回一个read-only channel
results := make(chan int, 5) // results是chanOwner的局部变量
go func() { // 仅chanOwner函数里定义的closure才能往results中写内容
defer close(results) // 正确情况下,chanOwner外代码无法往results中写内容
for i := 0; i <= 5; i++ {
results <- i
}
}()
return results
}
consumer := func(results <-chan int) { // 对results仅有读的权限
for result := range results {
fmt.Printf("Received: %d\n", result)
}
fmt.Println("Done receiving!")
}
results := chanOwner()
consumer(results)
}
5.2. Error Handling
在并发程序中,恰当的错误处理不是一件容易的事。“Who should be responsible for handling the error?”这是一个较难回复的问题。
我们考虑下面程序:
1: package main 2: 3: import ( 4: "fmt" 5: "net/http" 6: ) 7: 8: func main() { 9: checkStatus := func(urls ...string) <-chan *http.Response { 10: responses := make(chan *http.Response) 11: go func() { 12: defer close(responses) 13: for _, url := range urls { 14: resp, err := http.Get(url) 15: if err != nil { // 在这里处理错误不合适,后面介绍更好的方式 16: fmt.Println(err) 17: continue 18: } 19: responses <- resp 20: } 21: }() 22: return responses 23: } 24: 25: urls := []string{"https://www.bing.com", "https://badhost"} 26: for response := range checkStatus(urls...) { 27: fmt.Printf("Response: %v\n", response.Status) 28: } 29: }
上面程序中错误处理在第 15 行到第 18 行。但放在这个位置处理其实不太合适, 我们应该把错误留给对整个程序了解更全面的 goroutine 来处理。这样,方便我们根据错误做出进一步的决策。
下面是一种更好的处理方式:
package main
import (
"fmt"
"net/http"
)
type Result struct {
Error error
Response *http.Response
}
func main() {
checkStatus := func(urls ...string) <-chan Result {
results := make(chan Result)
go func() {
defer close(results)
for _, url := range urls {
resp, err := http.Get(url)
results <- Result{Error: err, Response: resp} // 把错误从当前goroutine中propagate出去
}
}()
return results
}
errCount := 0
urls := []string{"https://www.bing.com", "https://badhost"}
for result := range checkStatus(urls...) {
if result.Error != nil { // 在这里处理错误更合适。这个位置掌握了更多的信息,比如可以方便地统计错误总数等
fmt.Printf("error: %v\n", result.Error)
errCount++
continue
}
fmt.Printf("Response: %v\n", result.Response.Status)
}
}
5.3. Explicit Cancellation (The done channel)
goroutine 很轻量级,占用内存很少。不过,处理不当也可能造成 goroutine 不退出,从而导致内存泄漏。
If a goroutine is responsible for creating a goroutine, it is also responsible for ensuring it can stop the goroutine.
5.3.1. 读 channel 可能导致 goroutine 不退出
看下面程序:
// 下面程序是一个反例(goroutine不退出)
package main
import (
"fmt"
)
func main() {
doWork := func(strings <-chan string) <-chan interface{} {
completed := make(chan interface{})
go func() {
defer fmt.Println("doWork exited.")
defer close(completed)
for s := range strings {
// Do something interesting
fmt.Println(s)
}
}()
return completed
}
doWork(nil)
// 下面两行代码(已经注释掉了)会导致deadlock!
// completed := doWork(nil)
// <-completed // 让main goroutine等待doWork中创建的goroutine
// Perhaps more work is done here
fmt.Println("Done.")
}
运行上面程序,会输出(注:并不会输出“doWork exited.”):
Done.
上面程序,在 main goroutine 中传递了 nil 给 doWork ,这样 doWork 中的通道 strings 永远读取不到字符串,从而 doWork 中的那个 goroutine 永远不会自动结束(它的生命期会维持到整个程序结束。就这个例子而言,由于 main 很快就结束了,问题并不大。不过,真实的服务器程序很可能会运行很长时间,这时问题就严重了)。
可以用一个 done 通道来解决上面 goroutine 不会结束的问题,代码如下:
package main
import (
"fmt"
"time"
)
func main() {
doWork := func(done <-chan interface{}, strings <-chan string) <-chan interface{} {
completed := make(chan interface{})
go func() {
defer fmt.Println("doWork exited.")
defer close(completed)
for {
select {
case s := <-strings:
// Do something interesting
fmt.Println(s)
case <-done: // 注:往done通道写任意内容,或者关闭done,都会进入这个分支
return
}
}
}()
return completed
}
done := make(chan interface{})
completed := doWork(done, nil)
// Cancel the operation after 1 second.
time.Sleep(1 * time.Second)
fmt.Println("Canceling doWork goroutine...")
// 关闭done会使doWork中启动的goroutine退出
// 往done通道里写任意内容(如done<- "anything")也会使doWork中启动的goroutine退出
close(done)
<-completed
time.Sleep(1 * time.Second)
// Perhaps more work is done here
fmt.Println("Done.")
}
运行上面程序,会输出:
Canceling doWork goroutine... doWork exited. Done.
5.3.2. 写 channel 可能导致 goroutine 不退出
看下面程序:
// 下面程序是一个反例(goroutine不退出)
package main
import (
"fmt"
"time"
"math/rand"
)
func main() {
newRandStream := func() <-chan int {
randStream := make(chan int)
go func() {
defer fmt.Println("newRandStream closure exited.")
defer close(randStream)
for {
randStream <- rand.Int()
}
}()
return randStream
}
randStream := newRandStream()
fmt.Println("3 random ints:")
for i := 1; i <= 3; i++ {
fmt.Printf("%d: %d\n", i, <-randStream)
}
// Simulate other ongoing work
time.Sleep(1 * time.Second)
}
运行上面程序,会输出(注:并不会输出“newRandStream closure exited.”):
3 random ints: 1: 5577006791947779410 2: 8674665223082153551 3: 6129484611666145821
在上面程序中,newRandStream 中启动的 goroutine 不会退出(它会一直存在,直到整个程序结束)。
和上一节类似,可以用一个 done 通道来解决 newRandStream 中启动的 goroutine 不会结束的问题,代码如下:
package main
import (
"fmt"
"time"
"math/rand"
)
func main() {
newRandStream := func(done <-chan interface{}) <-chan int {
randStream := make(chan int)
go func() {
defer fmt.Println("newRandStream closure exited.")
defer close(randStream)
for {
select {
case randStream <- rand.Int():
case <-done:
return
}
}
}()
return randStream
}
done := make(chan interface{})
randStream := newRandStream(done)
fmt.Println("3 random ints:")
for i := 1; i <= 3; i++ {
fmt.Printf("%d: %d\n", i, <-randStream)
}
close(done)
// Simulate other ongoing work
time.Sleep(1 * time.Second)
}
运行上面程序,会输出:
3 random ints: 1: 5577006791947779410 2: 8674665223082153551 3: 6129484611666145821 newRandStream closure exited.
5.4. Pipelines
A pipeline is nothing more than a series of things that take data in, perform an operation on it, and pass the data back out. We call each of these operations a stage of the pipeline.
5.4.1. pipeline 实例
下面是 pipeline 的一个实例,功能是对每个数据乘以 2,再加上 1,再乘以 2,然后输出。
package main
import "fmt"
func main() {
generator := func(done <-chan interface{}, integers ...int) <-chan int {
intStream := make(chan int)
go func() {
defer close(intStream)
for _, i := range integers {
select {
case <-done:
return
case intStream <- i:
}
}
}()
return intStream
}
// 下面是pipeline的一个stage
multiply := func(
done <-chan interface{},
intStream <-chan int,
multiplier int,
) <-chan int {
multipliedStream := make(chan int)
go func() {
defer close(multipliedStream)
for i := range intStream {
select {
case <-done:
return
case multipliedStream <- i * multiplier:
}
}
}()
return multipliedStream
}
// 下面是pipeline的另一个stage
add := func(
done <-chan interface{},
intStream <-chan int,
additive int,
) <-chan int {
addedStream := make(chan int)
go func() {
defer close(addedStream)
for i := range intStream {
select {
case <-done:
return
case addedStream <- i + additive:
}
}
}()
return addedStream
}
done := make(chan interface{})
defer close(done)
intStream := generator(done, 1, 2, 3, 4)
// pipeline组合了多个stages
pipeline := multiply(done, add(done, multiply(done, intStream, 2), 1), 2)
for v := range pipeline {
fmt.Println(v)
}
}
运行上面程序,会输出:
6 10 14 18
使用 pipeline 时,每个值进入不同 channel 的时机如表 1 所示。
| Iteration | Generator | Multiply | Add | Multiply | Value |
|---|---|---|---|---|---|
| 0 | 1 | ||||
| 0 | 1 | ||||
| 0 | 2 | 2 | |||
| 0 | 2 | 3 | |||
| 0 | 3 | 4 | 6 | ||
| 1 | 3 | 5 | |||
| 1 | 4 | 6 | 10 | ||
| 2 | (closed) | 4 | 7 | ||
| 2 | (closed) | 8 | 14 | ||
| 3 | (closed) | 9 | |||
| 3 | (closed) | 18 |
完成前面程序功能,不用 Pipeline 也行。比如,下面代码也能得到相同的输出,但它比使用 pipeline 的版本要慢。
// 没有使用pipeline,比使用pipeline的版本要慢
// 每次迭代结束后,才进行下一次迭代;使用pipeline时,只要有数据,就会进入下一个stage,所以更快
package main
import "fmt"
func main() {
multiply := func(values []int, multiplier int) []int {
multipliedValues := make([]int, len(values))
for i, v := range values {
multipliedValues[i] = v * multiplier
}
return multipliedValues
}
add := func(values []int, additive int) []int {
addedValues := make([]int, len(values))
for i, v := range values {
addedValues[i] = v + additive
}
return addedValues
}
ints := []int{1, 2, 3, 4}
for _, v := range multiply(add(multiply(ints, 2), 1), 2) {
fmt.Println(v)
}
}
5.5. Fan-Out, Fan-In
在 Pipeline 中,如果某个 stage 的处理速度太慢,则会响应到整个 Pipeline 的处理速度。这时,我们可以使用“Fan-Out, Fan-In”来加快某个 stage 的处理速度。 “多个函数从同一个 channel 读取数据同时进行处理叫 Fan-Out(减少 channel 中数据的处理时间);一个函数从多个 channel 读取并把处理结果发送(合并)到一个 channel 中,称之为 Fan-In”。
下面是 Fan-Out, Fan-In 的例子(代码摘自:https://blog.golang.org/pipelines ):
package main
import (
"fmt"
"sync"
)
func gen(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
func merge(cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// Start an output goroutine for each input channel in cs. output
// copies values from c to out until c is closed, then calls wg.Done.
output := func(c <-chan int) {
for n := range c {
out <- n
}
wg.Done()
}
wg.Add(len(cs))
for _, c := range cs {
go output(c)
}
// Start a goroutine to close out once all the output goroutines are
// done. This must start after the wg.Add call.
go func() {
wg.Wait()
close(out)
}()
return out
}
func main() {
in := gen(2, 3)
// Distribute the sq work across two goroutines that both read from in.
c1 := sq(in)
c2 := sq(in)
// Consume the merged output from c1 and c2.
for n := range merge(c1, c2) {
fmt.Println(n) // 4 then 9, or 9 then 4
}
}
上面程序中的下面片断:
c1 := sq(in) c2 := sq(in)
就是“Fan-Out”;而 merge(c1, c2) 就是“Fan-In”。
5.6. The context Package
在节 5.3 中介绍了通过 done 通道来显式地取消 goroutine。但有时我们需要传递其它一些额外的上下文信息(如为什么 goroutine 被取消等等)。如果有一个通用的机制可以取消 goroutine,以及传递额外信息该多好。为此,Google 为我们提供一个解决方案: context 包(Go 1.7 中把 context 包纳入了标准库中)。
准确地说,context 包的功能是“store and retrieve request-scoped data”。 使用 context 包的例子有很多,如官方 http 包使用 context 传递请求的上下文数据,gRPC 使用 context 来终止某个请求产生的 goroutine 树。
使用 context 实现上下文功能需要在你的方法的第一个参数传入一个 context.Context 类型的变量。context.Context 类型的定义如下:
// A Context carries a deadline, cancelation signal, and request-scoped values
// across API boundaries. Its methods are safe for simultaneous use by multiple
// goroutines.
type Context interface {
// Done returns a channel that is closed when this Context is canceled
// or times out.
Done() <-chan struct{}
// Err indicates why this context was canceled, after the Done channel
// is closed.
Err() error
// Deadline returns the time when this Context will be canceled, if any.
Deadline() (deadline time.Time, ok bool)
// Value returns the value associated with key or nil if none.
Value(key interface{}) interface{}
}
我们不用自已实现 context.Context 接口,context 包已经提供了两个函数可以返回 Context 实例: context.Background() 和 context.TODO() 。这两个函数返回的实例都是空 Context。
5.6.1. context.WithValue 实例:传递 request-scoped data
context.WithValue 的原型为: func WithValue(parent Context, key, val interface{}) Context ,通过它可以在 Context 对象中设置一些属性,然后使用 context.Context 接口中的 Value(key interface{}) 方法可以读取到属性的值。下面例子演示了它的使用:
package main
import (
"context"
"fmt"
)
func main() {
f := func(ctx context.Context) {
if v := ctx.Value("USERID"); v != nil {
fmt.Println("found userid:", v)
} else {
fmt.Println("not found userid")
}
if v := ctx.Value("AUTHTOKEN"); v != nil {
fmt.Println("found authtoken:", v)
} else {
fmt.Println("not found authtoken")
}
}
fmt.Println("first test...")
ctx1 := context.WithValue(context.Background(), "USERID", "user1") // key为内置类型,不好!
ctx1 = context.WithValue(ctx1, "AUTHTOKEN", "token123") // key为内置类型,不好!
f(ctx1)
fmt.Println("second test...")
ctx2 := context.WithValue(context.Background(), "USERID", "user2") // key为内置类型,不好!
f(ctx2)
}
运行上面程序,会输出:
first test... found userid: user1 found authtoken: token123 second test... found userid: user2 not found authtoken
说明: WithValue 的第二个参数(即 key)是 interface{} ,意味着可以是任意类型,不过我们最好不使用内置类型。因为当 key 是内置类型时,容易出现 Collisions,例如(伪代码):
Fun1(ctx) { // 位于包package1中
ctx = context.WithValue(ctx, "key1", "value1")
Fun2(ctx)
}
Fun2(ctx) { // 位于包package2中
ctx = context.WithValue(ctx, "key1", "value2") // 这和Fun1中的"key1"发生了Collisions
Fun3(ctx) // Fun3中已经无法通过"key1"得到"value1"了
}
上面伪代码中,由于 package2 中的函数 Fun2“不小心”把"key1"设置到了 ctx 中,这会导致 Fun3 无法访问 Fun1 中对"key1"的设置。下面将介绍如何避免这种情况发生。
5.6.1.1. 为 key 自定义类型(Avoid Collisions Between Packages)
通过自定义 key 的类型可以避免上节提到的 Collisions 现象。
我们先回顾一下下面的知识点。假设有代码:
type foo int
type bar int
m := make(map[interface{}]int)
m[foo(1)] = 20 // 把1转换为foo类型(底层类型是int),作为key保存到m中
m[bar(1)] = 30 // 把1转换为bar类型(底层类型也是int),作为key保存到m中
fmt.Printf("%v", m) // 注:会输出 map[1:20 1:30] ,而不是 map[1:30]
会输出“map[1:20 1:30]”,而不是“map[1:30]”,为什么呢?这是因为尽管 foo 和 bar 的底层类型相同(都为 int),但 Go 也认为它们是不同的。
下面程序演示了避免 Collisions 的技巧:
package main
import (
"context"
"fmt"
)
// 最好为context.WithValue的第2个参数定义一个类型(如后面的类型ctxKey),且让这个类型在其它
// 包中不可见!这样可以避免Collisions。不过,由于这个类型在其它包中不可见,我们不得不export
// 一些辅助函数,来设置或获取Context中key对应的值,如后面的函数UserID/AuthToken/SetUserID/
// SetAuthToken (首字母大写的函数对其它包是可见的)
// 这样,其它包中的代码无法直接设置或者访问Context了,从而避免不小心的Collisions。
type ctxKey string
const ctxUserId ctxKey = "USERID"
const ctxAuthToken ctxKey = "AUTHTOKEN"
func UserID(c context.Context) (string, bool) {
userId, ok := c.Value(ctxUserId).(string)
return userId, ok
}
func AuthToken(c context.Context) (string, bool) {
authToken, ok := c.Value(ctxAuthToken).(string)
return authToken, ok
}
func main() {
// 为简单起见,这个例子中,f定义在同一个包中。真实环境中,f往往定义在其它包中。
f := func(ctx context.Context) {
if v, ok := UserID(ctx); ok == true {
fmt.Println("found userid:", v)
} else {
fmt.Println("not found userid")
}
if v, ok := AuthToken(ctx); ok == true {
fmt.Println("found authtoken:", v)
} else {
fmt.Println("not found authtoken")
}
}
fmt.Println("first test...")
ctx1 := context.WithValue(context.Background(), ctxUserId, "user1")
ctx1 = context.WithValue(ctx1, ctxAuthToken, "token123")
f(ctx1)
fmt.Println("second test...")
ctx2 := context.WithValue(context.Background(), ctxUserId, "user2")
f(ctx2)
}
运行上面程序(和上一节代码类似,只是增加了一些封装),会输出:
first test... found userid: user1 found authtoken: token123 second test... found userid: user2 not found authtoken
5.6.2. context.WithCancel 实例:避免 goroutine leak
下面是使用 context.WithCancel 的例子(代码摘自https://golang.org/pkg/context/#example_WithCancel)。
package main
import (
"context"
"fmt"
)
func main() {
// gen generates integers in a separate goroutine and
// sends them to the returned channel.
// The callers of gen need to cancel the context once
// they are done consuming generated integers not to leak
// the internal goroutine started by gen.
gen := func(ctx context.Context) <-chan int {
dst := make(chan int)
n := 1
go func() {
for {
select {
case <-ctx.Done():
return // returning not to leak the goroutine
case dst <- n:
n++
}
}
}()
return dst
}
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // cancel when we are finished consuming integers
for n := range gen(ctx) {
fmt.Println(n)
if n == 5 {
break
}
}
}
5.6.3. context.WithTimeout 实例:设置 goroutine 的 timeout 时间
下面例子演示了如何设置 goroutine 的 timeout 时间:
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 50*time.Millisecond)
// 上面这行代码等价于下面两行:
// d := time.Now().Add(50 * time.Millisecond)
// ctx, cancel := context.WithDeadline(context.Background(), d)
defer cancel()
select {
case <-time.After(1 * time.Second):
fmt.Println("overslept")
case <-ctx.Done():
fmt.Println(ctx.Err()) // prints "context deadline exceeded"
}
}
上面代码会输出:
context deadline exceeded
注:context.WithTimeout 和 context.WithDeadline 的关系如下:
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}
5.6.4. context 包的使用约定
使用 context 包的程序需要遵循如下的约定来满足接口的一致性以便于静态分析:
- Context 变量需要作为第一个参数使用,一般命名为 ctx;
- 即使方法允许,也不要传入一个 nil 的 Context ,如果你不确定你要用什么 Context 的时候可以传入 context.TODO;
- Value 方法只应该用于传递“request-scoped data”,不要用它来传递一些可选的函数参数;
- 同一个 Context 可以用来传递到不同的 goroutine 中,Context 在多个 goroutine 中是安全的。
6. Go Memory Model
和 Java 类似,Go 语言也定义了自己的内存模型。 Go 语言的内存模型规定了一个 goroutine 可以“看到”另外一个 goroutine 修改同一个变量的值的条件。
Happens before 是指在 Go 程序多个操作执行的一种偏序关系。如果操作 e1 先于 e2 发生,我们说 e2 happens after e1;如果 e1 操作既不先于 e2 发生又不晚于 e2 发生,我们说 e1 操作与 e2 操作并发执行。
下文将介绍部分 Happens before 原则,详情可参考:The Go Memory Model
6.1. 初始化
Program initialization runs in a single goroutine(从而,不同包的 init 函数是不会并发执行的).
If a package p imports package q, the completion of q's init functions happens before the start of any of p's.
The start of the function main.main happens after all init functions have finished.
6.2. Goroutine 的创建
The go statement that starts a new goroutine happens before the goroutine's execution begins.
比如,下面例子:
1: var a string 2: 3: func f() { 4: print(a) 5: } 6: 7: func hello() { 8: a = "hello, world" 9: go f() 10: }
执行函数 hello() 时,go 语句(即第 9 行)执行前,它之前的语句(即第 8 行)一定先执行了。编译器保证不会由于“指令重排序优化”等原因而出现第 8 行还没执行,就先执行第 9 行的现象。
6.3. Goroutine 的结束
The exit of a goroutine is not guaranteed to happen before any event in the program.
比如,下面例子:
1: var a string 2: 3: func hello() { 4: go func() { a = "hello" }() 5: print(a) 6: }
goroutine 中对 a 的赋值(第 4 行)可能不会被其他的 goroutine 看到(第 5 行可能什么都不会输出,就算你提前 sleep 好几秒),一些激进的编译器可能直接删除整个 go 语句。
If the effects of a goroutine must be observed by another goroutine, use a synchronization mechanism such as a lock or channel communication to establish a relative ordering.