Golang Scheduler
Table of Contents
1. Golang Scheduler
Golang Scheduler 的任务就是把 goroutine 分配到操作系统的线程上。
1.1. 理论模型(1:1 VS. M:N)
最简单的调度模型是 1:1 模型,即“1 个线程对应执行 1 个 goroutine”。这种方式很简单,不过无法支持上百万的 goroutine,因为创建线程的代价相对比较高,在操作系统中在创建这么多的线程是不现实的。
M:N 模型是指“M 个线程执行 N 个 goroutine”。从操作系统角度,它只理解线程,对 goroutine 是一无所知的。Go runtime 需要维护 goroutine 的运行状态,以方便 Scheduler 进行调度。goroutine 的运行状态可简化为(省略了一些与调度关系不大的状态)下面 3 种:
- Running – 这类 goroutine 正在线程上运行;
- Runnable – 这类 goroutine 具体运行条件,但目前没有运行,正在等待线程来运行;
- Blocked – 这类 goroutine 等待某些条件的发生,如阻塞在 channel 操作上、阻塞在系统调用上,阻塞在互斥锁上等等。
图 1 展示了 3 个线程执行 9 个 goroutine(其中 Running 状态 3 个,Runnable 状态 4 个,Blocked 状态 2 个)的情况。

Figure 1: 3 个线程执行 9 个 goroutine
Go 语言中的 G-M 模型和 G-P-M 模型都属于 M:N 模型,后文将介绍它们。
2. G-M 模型
在 Go 1.0 的调试器中,只有代表 goroutine 的 G(Goroutine 缩写)结构,和代表操作系统线程的 M(Machine 缩写)结构,我们把它称为 G-M 模型。
2.1. 结合源码看流程
下面调度器相关源码摘自 Golang 1.0.1(注:没有找到 Golang 1.0 源码的 git tag):
// Go scheduler
//
// The go scheduler's job is to match ready-to-run goroutines (`g's)
// with waiting-for-work schedulers (`m's). If there are ready g's
// and no waiting m's, ready() will start a new m running in a new
// OS thread, so that all ready g's can run simultaneously, up to a limit.
// For now, m's never go away.
......
// One round of scheduler: find a goroutine and run it.
// The argument is the goroutine that was running before
// schedule was called, or nil if this is the first call.
// Never returns.
static void
schedule(G *gp)
{
......
schedlock(); // 1.
if(gp != nil) {
......
switch(gp->status){
case Grunnable:
case Gdead:
// Shouldn't have been running!
runtime·throw("bad gp->status in sched");
case Grunning:
gp->status = Grunnable; // 2.
gput(gp); // 3.
break;
}
......
// Find (or wait for) g to run. Unlocks runtime·sched.
gp = nextgandunlock(); // 4.
gp->readyonstop = 0;
gp->status = Grunning; // 5.
m->curg = gp;
gp->m = m;
......
runtime·gogo(&gp->sched, 0); // 6.
}
上面源码中的核心操作如下:
- 通过
schedlock()拿到全局锁; - 把当前 goroutine 从 Running 状态改为 Runnable 状态;
- 通过
gput(gp)保存当前 goroutine 的执行信息; - 通过
nextgandunlock()寻找下一个可运行 goroutine,并对全局锁进行解锁; - 把找到的下一个待运行 goroutine 的状态修改为 Running;
- 通过
runtime·gogo运行下一个 goroutine。
函数 schedule() 是永远不会返回的,因为 schedule() 中运行下一个 goroutine 时就把控制权交给了下一个 goroutine 代码。那么下一次的调度在什么时候发生呢?即由谁来再次调用 schedule() 函数呢?答案是由用户的 goroutine 代码来调用,详情请参考节 4.1。
结合上面的源码分析,之前介绍的图 1 可以更具体地表示为图 2 了。

Figure 2: G-M 模型
2.2. 系统调用的处理
如果 goroutine 发起了一个“阻塞的系统调用”,那么运行当前 gorountine 的线程会被操作系统放入到内核中某个队列中,等待内核调度,这不受 Go runtime 的控制。 这会导致在系统调用返回前,其他的 goroutine 都没有机会在这个线程上运行了。
为了使其它 goroutine 能被线程及时运行,在当前 gorountine 进入阻塞的系统调用时,Go 会唤醒另一个空闲线程来执行其它的 gorountine。 我们可以通过 SetMaxThreads 来设置最大的线程数(默认为 10000)。
2.3. G-M 模型的缺点
2012 年 Google 工程师 Dmitry Vyukov 在 Scalable Go Scheduler Design Doc 一文中指出了当时调度器(G-M 模型)的可伸缩性(Scalability)不好,尤其是对那些有高吞吐或并行计算需求的服务程序。他提到了对 Vtocc(一个 Go 实现的服务程序)进行性能分析后发现有 14% 的 CPU 都消耗在拿锁操作 runtime.futex() 上。
具体来说,Dmitry Vyukov 指出当时调度器(G-M 模型)的实现有下面四点不足:
- 存在单一全局互斥锁和集中状态。全局锁保护所有 goroutine 相关操作(如:创建、完成、重新调度等),导致锁竞争问题严重;
- goroutine 传递问题:经常在 M 之间传递“可运行”的 goroutine,这导致调度延迟增大;
- 每个线程 M 都需要做内存缓存(M.mcache),导致内存占用过高,且数据局部性较差;
- 系统调用频繁地阻塞和解除阻塞正在运行的线程,导致额外的性能损耗。
3. G-P-M 模型
为了克服 G-M 模型的缺点,Dmitry Vyukov 在 Go 1.1 中加入了一个新的结构 P(Logical Processor 的缩写),在 P 之上实现了 Work Stealing 算法。
G、P、M 的关系如下(摘自 https://povilasv.me/go-scheduler/ ):
Each goroutine is described by a struct called G, which contains fields necessary to keep track of its stack and current status. So, G = goroutine.
Runtime keeps track of each G and maps them onto Logical Processors, named P. P can be seen as a abstract resource or a context, which needs to be acquired, so that OS thread (called M, or Machine) can execute G.
3.1. 增加 P 后的模型
增加 P 后的模型被称为 G-P-M 模型,如图 3 所示。

Figure 3: G-P-M 模型
当 G(即 Goroutine)关联了 P(Logical Processor),且映射到 M(OS thread)后,G 才会被执行。
说明 1:每个 P 关联着一个“本地可运行队列”(Local Queue),这样把 G-M 模型中的全局可运行队列(Global Queue)去中心化了,对 Global Queue 的访问锁竞争会大大减少。
说明 2:如果 P 的 Local Queue 为空,则会从 Global Queue 及其它 P 的 Local Queue 中窃取任务(即可运行的 goroutine),这就是任务窃取算法(Work Stealing,节 3.4 中将详细介绍它)。
说明 3:P 的数量等于变量 GOMAXPROCS 所设置的值。
说明 4:M 的数量可能远大于 P 的数量(节 2.2 提到过 M 最大值为 10000),M2 关联着处于 syscall 状态的 goroutine(它们不会关联 P),细节参考节 3.3。
3.2. 为什么要有 P
如果我们直接把“本地可运行队列”(Local Queue)关联到 M 上,这样也可以实现 Global Queue 的去中心化,也可以实现任务窃取算法。为什么要额外地增加逻辑处理器 P 呢?
我们知道 M 的数量往往大于 P 的数量,这是因为执行“阻塞的系统调用”时,M 会被操作系统内核阻塞,为了更快地为其它 goroutine 提供服务,不得不启动新的 M。如果每个 M 都关联着一个 Local Queue,那么下面问题会出现:
- 当 M 执行“阻塞的系统调用”时,为了使 M 关联的 Local Queue 中的任务尽快地被处理,我们需要及时地分配它们到其它的 M 中去执行。这大大增加了“可运行”的 goroutine 在 M 之间的传递。
- Local Queue 可能变得很多(回忆一下节 2.2 提到过 M 的默认最大值是 10000),这会导致任务窃取的效率变低。
引入 P 后,把 Local Queue 关联到 P 上,这些问题就不存在了。
3.3. 系统调用的处理
节 2.2 中提到,如果 goroutine 要执行“阻塞的系统调用”,G-M 模型中它会唤醒另一个空闲线程; 在 G-P-M 模型中,goroutine 要执行“阻塞的系统调用”时,还会把当前的 M 和 P 分离,这样,唤醒的新线程可以接着执行被分离出来的 P 所关联的 Local Queue 中的任务了,相关的实现细节参考节 3.3.1。 系统调用是如此特别,Go runtime 专门为 goroutine 定义了一个名为 syscall 的状态,表示其正在执行系统调用。
执行系统调用的情况如图 4 所示。M3 是唤醒的新线程,它会关联以前属于 M2 的 P。图 4 的右边子图描述的是系统调用返回后的一种处理情况:G1 被放到了 Global Queue 中。不过,系统调用返回后如果有空闲的 P,M2 关联上这个空闲 P 后可以接着执行 G1(它没必要进入到 Global Queue 中了)。

Figure 4: 执行系统调用的示意图
3.3.1. 实现细节
下面介绍一下 Go runtime 是如何把正在执行系统调用的 P 和 M(这个 M 直到系统调用返回时才被操作系统调度)分离,这样 P 关联另一个 M 后就可以执行其它 gorountine 了。
Go runtime 会启动一个名为 sysmon 的线程(称为“监控线程”),它无需绑定 P 就可运行。它的任务之一就是分离因系统调用而长时间阻塞的 P,且启动新 M 和这个 P 关联。当然它还有很多其它的工作,如 GC 相关任务等,这里不介绍。
sysmon 会在一个死循环中不断地调用函数 retake ,下面是简化的 retake 源码(摘自 Go 1.14):
func retake(now int64) uint32 {
......
for i := 0; i < len(allp); i++ { // 遍历所有的 P
_p_ := allp[i]
......
s := _p_.status
......
if s == _Psyscall { // 如果 _p_ 正在执行系统调用
......
// On the one hand we don't want to retake Ps if there is no other work to do,
// but on the other hand we want to retake them eventually
// because they can prevent the sysmon thread from deep sleep.
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue // 若 _p_ 的 Local Queue 为空,且 syscall 执行时间未超过 10ms,则先不交出 _p_
}
......
if atomic.Cas(&_p_.status, s, _Pidle) {
......
handoffp(_p_) // 把 _p_ 和当前 M 分离;handoffp 中会调用 startm,它会启用新的 M 和 _p_ 关联
}
......
}
}
......
}
可见, retake 在满足一定条件下,会把正在执行系统调用的 P 和 M 分离,且启动新 M 和分离的 P 关联。
3.4. Work Stealing
在介绍 Work Stealing 前,先介绍一下 Fork-Join 框架,因为 Work Stealing 算法是实现 Fork-Join 框架的主流方式。
3.4.1. Fork-Join
很多语言中都有 Fork-Join 框架,比如 Cilk,Java。图 5 是 Fork-Join 框架的示意图(图片摘自:A Primer on Scheduling Fork-Join Parallelism with Work Stealing)。
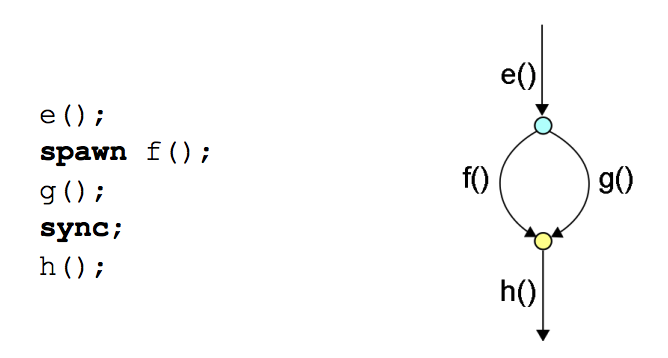
Figure 5: Fork-Join 示意图(spawn/sync 来自 Cilk 语言)
在图 5 的记号中,spawn/sync 分别代表 Fork/Join。 在 Go 语言中,用关键字 go 启动 goroutine 就是 Fork,而通过 channel 或者 sync 包把多个 goroutines 进行同步则属于 Join。 下面代码演示了 Go 的 Fork-Join:
func worker(done chan bool) {
fmt.Print("working...")
time.Sleep(time.Second)
done <- true
}
func main() {
done := make(chan bool, 1)
go worker(done) // 这是Fork点
// other work
<-done // 这是Join点(这是通过channel同步,通过其它方式同步也都属于Join)
// other work
}
3.4.2. Work Stealing 算法
Work Stealing 算法的基本思想为:
- 每个执行体关联着一个任务队列;
- 在 Fork 点,执行体把新任务(如图 5 中的函数 f)放入自己的任务队列中(这是 Child Stealing 策略,后面将介绍);
- 如果执行体在 Join 点还需要等待其它任务执行完成才能继续,则执行体就从自己的任务队列中拿出任务来执行;
- 如果执行体自己的任务队列为空,则从其它执行体的任务队列中“窃取”任务来执行。
上面所说的“执行体”在 Go 中就是逻辑处理器 P,而在 Cilk 中就直接对应线程了。
3.4.3. Child Stealing VS. Continuation Stealing
有两种“任务窃取”策略:Child Stealing 和 Continuation Stealing(也称为 Parent Stealing)。以图 5(为方便查看将其复制为图 6)为例进行说明, 如果在 Fork 点,把函数 f 放入自己的任务队列中(它可能被其它执行体“窃取”),而当前执行体接着执行函数 g,则称为 Child Stealing;如果在 Fork 点,把 Continuation(即从 spawn 下一句开始的所有代码)放入自己的任务队列中(它可能被其它线程“窃取”),而当前执行体接着执行函数 f,则称为 Continuation Stealing。
Figure 6: Fork-Join 两种“任务窃取”策略
Intel TBB 和 Microsoft PPL 采用 Child Stealing 策略,Intel Cilk 采用 Continuation Stealing 策略,而 OpenMP 默认采用 Child Stealing 策略,但可以设置为 Continuation Stealing 策略。
参考:A Primer on Scheduling Fork-Join Parallelism with Work Stealing
3.4.4. Go 采用 Continuation Stealing 策略
Go 语言采用的是 Continuation Stealing 策略。这是因为(摘自“Concurrency in Go”):
Consider this: when creating a goroutine, it is very likely that your program will want the function in that goroutine to execute. It is also reasonably likely that the continuation from that goroutine will at some point want to join with that goroutine. And it’s not uncommon for the continuation to attempt a join before the goroutine has finished completing. Given these axioms, when scheduling a goroutine, it makes sense to immediately begin working on it.
Continuation Stealing 策略使得 Fork-Join 看起来像函数调用:如果任务不被“窃取”,图 6 左边所示代码的执行顺序为: e() -> f() -> g() -> ... ,这是不是有点像函数调用?
4. 抢占方式
现代操作系统一般采用“基于定时器中断的抢占式调度”来实现任务调用,当前任务执行完分配给自己的时间片后,会被其它任务抢占。
4.1. 协作式抢占
Go 1.13 及以前的调度器采用的是一种“协作式抢占(Cooperative Preemption)”,它并不是基于定时器中断来实现抢占的。Go 在库函数、系统调用等等很多地方自动增加了一些 hook 点,在这些位置上会检测某个标记(即 P 结构上的 preempt 字段,这个标记可由 sysmon 线程来设置,比如发现 P 执行超过 10ms 就把 P 的 preempt 字段设置为 true),如果发现标记(preempt)被设置上,则调用 schedule() ,从而实现其它 goroutine 的抢占。
一般情况下,真实程序中的 goroutine 中往往都会包含引入 hook 点的代码,所以不用太担心某 goroutine 不执行 schedule() ,从而一直霸占资源的情况。当然,也有意外,请看下节。
4.1.1. 协作式抢占的陷阱
有一些特殊的场景可导致 goroutine 一直执行不到 hook 点,或者根本就没有 hook 点,从而当前 goroutine 一直霸占着线程(该线程没机会执行其它 goroutine)。下面我们构造没有 hook 点的 goroutine:
package main
import "fmt"
import "time"
import "runtime"
func main() {
var x int
threads := runtime.GOMAXPROCS(0) // GOMAXPROCS(0) 返回运行时使用的执行上下文个数
fmt.Println("threads =", threads)
for i := 0; i < threads; i++ { // 解决办法 1: i < threads - 1;
go func() { // 这个 go 启动的 goroutine,没有 hook 点
for {
x++
// time.Sleep(0) // 解决办法 2
// runtime.Gosched() // 解决办法 3
}
}()
}
time.Sleep(time.Second) // goroutine main 在 sleep 1 秒后,打印 x,并退出
fmt.Println("x =", x)
}
上面程序在“go 1.13 及以前版本”中,语句 fmt.Println("x =", x) 是永远不会被执行到的。为什么会这样呢?
下面假定变量 threads 的值为 8(其它值也无所谓)进行分析。程序创建了 8 个 goroutines 再加上隐含的 goroutine main,一共有 9 个 goroutines。但是 8 个 goroutine 代码很简单,仅一个死循环,并没有调用库函数等可能增加 hook 点的代码,这样只要它们开始执行就不会主要让出 CPU 了! 而这个例子中,runtime 最多使用 8 个执行上下文,前面介绍过 Go 采用“Continuation Stealing”策略,也就是说用 go 启动的 goroutine 会先执行,这样 goroutine main 已经没有执行上下文可用了,所以 goroutine main 没有机会再执行了,从而程序不会结束。
如何使上面程序可以正常结束呢?下面任何一种方法都行:
- 仅显式地创建
threads - 1个 goroutine,goroutine main 就有机会执行,程序可以正常结束; - 在 goroutine 的
for循环里调用可以增加 hook 点的函数,比如time.Sleep(0),goroutine main 就有机会执行,程序可以正常结束; - 在 goroutine 的
for循环里调用runtime.Gosched(),主动让出 CPU,goroutine main 就有机会执行,程序可以正常结束。
需要说明的是:上面程序存在竞争条件,就算可以正常结束, fmt.Println 输出的"x"值可能每次不一样。
4.2. 非协作式(基于信号)抢占
协作式抢占可能导致 gorountine 一直霸占着某个线程,在节 4.1.1 中有一个“协作式抢占”导致 main 得不到执行的例子。在 Go 1.14 中引入了“基于信号”的抢占,以解决协作式抢占的不足。
基于信号的抢占的基本原理如下:程序启动时注册 SIGURG 信号的处理函数 runtime.doSigPreempt ;而 sysmon 线程在满足一定条件下会发送 SIGURG 信号,这样操作系统会中断线程的执行,去调用对应的信号处理函数 runtime.doSigPreempt 。需要说明的是,信号处理函数是由内核调用的,在其执行结束后,内核会返回用户态并继续执行信号发生时被中断的代码,这意味着我们无法直接在信号处理函数内去调用 schedule() 完成任务切换。怎么办呢?Go 的实现技巧是: 在信号处理函数中修改寄存器 SP(栈顶指针)和寄存器 PC(下一条机器指令的内存地址)的值,以确保内核返回用户态时执行另外一个函数 runtime.asyncPreempt (而不再是信号发生时被中断代码的下一条指令),而函数 runtime.asyncPreempt 会去调用 schedule() ,从而完成任务切换。
参考:https://github.com/golang/proposal/blob/master/design/24543-non-cooperative-preemption.md
4.2.1. 实现细节
前面介绍了基于信号的抢占的基本原理,这里以源码 Go 1.14 为例介绍一下其实现细节。
信号处理函数 doSigPreempt 源码为:
1: // doSigPreempt handles a preemption signal on gp. 2: func doSigPreempt(gp *g, ctxt *sigctxt) { 3: // Check if this G wants to be preempted and is safe to 4: // preempt. 5: if wantAsyncPreempt(gp) && isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()) { 6: // Inject a call to asyncPreempt. 7: ctxt.pushCall(funcPC(asyncPreempt)) // 修改 SP 和 PC,目的是让内核返回到用户态后执行 asyncPreempt,而不再执行中断恢复位置的用户代码 8: } 9: 10: // Acknowledge the preemption. 11: atomic.Xadd(&gp.m.preemptGen, 1) 12: }
说明:信号处理函数可能由内核在任意时刻被调用;不过,GC 要能正常工作,并不是每个位置都可以被打断,那些能被安全打断的位置称为 GC Safe-Point ,上面源码中第 5 行的 isAsyncSafePoint 用于检测当前是不是 Safe-Point,如果是 Safe-Point 才去修改 SP 和 PC,否则放弃这次任务切换。
runtime.asyncPreempt 最终会调用 schedule() ,这里不贴出具体源码,仅说明一下其调用链:
runtime.asyncPreempt --> runtime.asyncPreempt2 --> runtime.preemptPark --> runtime.schedule