Hadoop
Table of Contents
1. Hadoop 简介
Hadoop 起源于开源的网络搜索引擎 Apache Nutch。利用 Hadoop,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop 不是缩写,是它一个生造出来的词,它是 Hadoop 之父 Doug Cutting 的儿子给一个棕黄色的玩具大象起的名字。
Hadoop 生态圈中的核心组件 HDFS、MapReduce、HBase 都有 Google 的影子。Google 发表了几篇技术学术论文,分别介绍 GFS、MapReduce、BigTable,但它们都没有开源;而 Doug Cutting 根据 Google 论文分别实现为了 HDFS(对应于 GFS)、MapReduce、HBase(对应于 BigTable)。
本文主要摘自:《Hadoop 权威指南(第 4 版)》或者其英文原版 Hadoop - The Definitive Guide, 4th
1.1. 数据存储和分析(Hadoop 产生背景)
我们生活在数据大爆炸时代,每天产生的数据越来越多。我们面临数据存储和分析的困境: 硬盘存储容量在不断提升,但硬盘数据的读取速度却没有与时俱进。 1990 年,一个普通硬盘可以存储 1370MB 数据,传输速度为 4.4MB/s(这些规格对应的是希捷的 ST-41600n 硬盘),因此只需要 5 分钟就可以读完整个硬盘中的数据。20 年过去了,1TB 的硬盘已然成为主流,但其数据传输速度约为 100MB/s,读完整个硬盘中的数据至少得花 2.5 个小时。
一个很简单的减少读取时间的办法是同时从多个硬盘上读数据。试想,如果我们有 100 个硬盘,每个硬盘存储 1%的数据,并行读取,那么不到两分钟就可以读完所有数据。 仅使用硬盘容量的 1%似乎很浪费。但是我们可以存储 100 个数据集,每个数据集 1 TB,并实现共享硬盘的读取。可以想象,用户肯定很乐于通过硬盘共享来缩短数据分析时间;并且,从统计角度来看,用户的分析工作都是在不同时间点进行的,所以彼此之间的干扰并不太大。
虽然如此,但要对多个硬盘中的数据并行进行读写数据,还有更多问题要解决。第一个需要解决的是硬件故障问题。一旦开始使用多个硬件,其中个别硬件就很有可能发生故障。为了避免数据丢失,最常见的做法是复制(replication):系统保存数据的复本(replica),一旦有系统发生故障,就可以使用另外保存的复本。例如,冗余硬盘阵列(RAID)就是按这个原理实现的,另外,Hadoop 的文件系统(HDFS,Hadoop Distributed FileSystem)也是一类,不过它采取的方法稍有不同,详见后文的描述。
第二个问题是大多数分析任务需要以某种方式结合大部分数据来共同完成分析,即从一个硬盘读取的数据可能需要与从另外 99 个硬盘中读取的数据结合使用。各种分布式系统允许结合不同来源的数据进行分析,但保证其正确性是一个非常大的挑战。 MapReduce 提出一个编程模型,该模型抽象出这些硬盘读写问题并将其转换为对一个数据集(由键值对组成)的计算。 后文将详细讨论这个模型,这样的计算由 map 和 reduce 两部分组成,而且只有这两部分提供对外的接口。
简而言之, Hadoop 为我们提供了一个可靠的共享存储和分析系统。HDFS 实现数据的存储,MapReduce 实现数据的分析和处理。虽然 Hadoop 还有其他功能,但 HDFS 和 MapReduce 是它的核心价值。
1.2. 相较于其他系统的优势
1.2.1. 和关系型数据库的比较
为什么不能用数据库来对大量硬盘上的大规模数据进行批量分析呢?我们为什么需要 MapReduce?关系型数据库和 MapReduce 的比较参考表 1。
| Traditional RDBMS | MapReduce | |
|---|---|---|
| Data size | Gigabytes | Petabytes |
| Access | Interactive and batch | Batch |
| Updates | Read and write many times | Write once, read many times |
| Transactions | ACID | None |
| Structure | Schema-on-write | Schema-on-read |
| Integrity | High | Low |
| Scaling | Nonlinear | Linear |
1.2.2. 和网格计算的比较
高性能计算(High Performance Computing,HPC)和网格计算(Grid Computing)组织多年以来一直在研究大规模数据处理,主要使用类似于消息传递接口(Message Passing Interface,MPI)的 API。从广义上讲, 高性能计算采用的方法是将作业分散到集群的各台机器上,这些机器访问存储区域网络(SAN)所组成的共享文件系统。 这比较适用于计算密集型的作业,但如果节点需要访问的数据量更庞大(高达几百 GB,MapReduce 开始施展它的魔法),很多计算节点就会因为网络带宽的瓶颈问题不得不闲下来等数据。
MapReduc 尽量在计算节点上存储数据,以实现数据的本地快速访问。数据本地化(data locality)特性是 MapReduce 的核心特征,并因此而获得良好的性能。
虽然 MPI 赋予程序员很大的控制权,但需要程序员显式控制数据流机制,包括用 C 语言构造底层的功能模块(例如套接字)和高层的数据分析算法。而 MapReduce 则在更高层次上执行任务,即程序员仅从键值对函数的角度考虑任务的执行,而且数据流是隐含的。
2. MapReduce
MapReduce 是一种可用于数据处理的编程模型。
2.1. NCDC 气象数据集
下面是美国国家气候数据中心(National Climatic Data Center,简称 NCDC)的数据实例(数据可以从 http://hadoopbook.com/code.html 下载)。我们的任务是从中找出每年全球气温的最高记录是多少?
这些数据以行为单位,使用 ASCII 格式存储,每行就是一条记录。数据放在目录 all 中,每年的数据在一个以年份命名的 gz 压缩包中,比如 1901 年的数据保存在 1901.gz 中,其部分实例(前 20 条)如下:
# 下面是1901.gz中的前20条记录,(可通过 `gunzip -c all/1901.gz | head -n 20` 得到输出)
0029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
0029029070999991901010113004+64333+023450FM-12+000599999V0202901N008219999999N0000001N9-00721+99999102001ADDGF104991999999999999999999
0029029070999991901010120004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9-00941+99999102001ADDGF108991999999999999999999
0029029070999991901010206004+64333+023450FM-12+000599999V0201801N008219999999N0000001N9-00611+99999101831ADDGF108991999999999999999999
0029029070999991901010213004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9-00561+99999101761ADDGF108991999999999999999999
0029029070999991901010220004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9-00281+99999101751ADDGF108991999999999999999999
0029029070999991901010306004+64333+023450FM-12+000599999V0202001N009819999999N0000001N9-00671+99999101701ADDGF106991999999999999999999
0029029070999991901010313004+64333+023450FM-12+000599999V0202301N011819999999N0000001N9-00331+99999101741ADDGF108991999999999999999999
0029029070999991901010320004+64333+023450FM-12+000599999V0202301N011819999999N0000001N9-00281+99999101741ADDGF108991999999999999999999
0029029070999991901010406004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9-00331+99999102311ADDGF108991999999999999999999
0029029070999991901010413004+64333+023450FM-12+000599999V0202301N008219999999N0000001N9-00441+99999102261ADDGF108991999999999999999999
0029029070999991901010420004+64333+023450FM-12+000599999V0202001N011819999999N0000001N9-00391+99999102231ADDGF108991999999999999999999
0029029070999991901010506004+64333+023450FM-12+000599999V0202701N004119999999N0000001N9+00001+99999101821ADDGF104991999999999999999999
0029029070999991901010513004+64333+023450FM-12+000599999V0202701N002119999999N0000001N9+00061+99999102591ADDGF104991999999999999999999
0029029070999991901010520004+64333+023450FM-12+000599999V0202301N004119999999N0000001N9+00001+99999102671ADDGF104991999999999999999999
0029029070999991901010606004+64333+023450FM-12+000599999V0202701N006219999999N0000001N9+00061+99999102751ADDGF103991999999999999999999
0029029070999991901010613004+64333+023450FM-12+000599999V0202701N006219999999N0000001N9+00061+99999102981ADDGF100991999999999999999999
0029029070999991901010620004+64333+023450FM-12+000599999V0203201N002119999999N0000001N9-00111+99999103191ADDGF100991999999999999999999
0029029070999991901010706004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9-00331+99999103341ADDGF100991999999999999999999
0029029070999991901010713004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9-00501+99999103321ADDGF100991999999999999999999
---------------------------------------------------------------------------------------||||||-----------------------------------------
我们只关心这6列(88到93列)
每行记录中第 88 列到第 92 列是气温值(如-0078 表示零下 7.8 度,如果数据缺失则用+9999 表示),第 93 列是 quality code(仅当该列为 0/1/4/5/9 时认为气温值是有效的)。由于我们只需要统计最高气温,所以仅关心第 88 列到第 93 列即可,其它列(如记录日期、经伟度、风向等等)都不用关心。
下面我们将分别使用 Unix 传统工具和 Hadoop 来计算每年全球气温的最高记录。
2.2. 方法一:使用 Unix 工具来分析数据
找出前面数据中,每年全球气温的最高记录是多少?用 awk 容易实现:
#!/usr/bin/env bash
for year in all/*
do
echo -ne `basename $year .gz`"\t"
gunzip -c $year | \
awk '{ temp = substr($0, 88, 5) + 0;
q = substr($0, 93, 1);
if (temp != 9999 && q ~ /[01459]/ && temp > max) max = temp }
END { print max }'
done
假设上面程序名为 max_temperature.sh,则运行它可以得到:
% ./max_temperature.sh 1901 317 1902 244 1903 289 1904 256 1905 283 ...
由于源文件中的气温值被放大了 10 倍,所以 1901 年的最高气温是 31.7 度。在亚马逊的 EC2 High-CPU Extra Large Instance 运行这个程序,处理一个世纪的气象数据,找到每年最高气温,需要 42 分钟。
2.3. 方法二:使用 Hadoop 来分析数据
2.3.1. map 和 reduce 处理过程的原理性介绍
MapReduce 任务过程分为两个处理阶段:map 阶段和 reduce 阶段。每个阶段都将“键/值对”作为输入,键值对的类型可以由程序员选择。
以前面求最高气温的实例为例子。map 阶段的输入是美国国家气候数据中心的原始数据。为了简单全面地描述处理过程,仅考虑输入数据的下面 5 条样本记录:
$ cat input/ncdc/sample.txt 0067011990999991950051507004+68750+023550FM-12+038299999V0203301N00671220001CN9999999N9+00001+99999999999 0043011990999991950051512004+68750+023550FM-12+038299999V0203201N00671220001CN9999999N9+00221+99999999999 0043011990999991950051518004+68750+023550FM-12+038299999V0203201N00261220001CN9999999N9-00111+99999999999 0043012650999991949032412004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+01111+99999999999 0043012650999991949032418004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+00781+99999999999
把这 5 行记录以“键/值对”的方式作为 map 函数的输入:
(0, 0067011990999991950051507004+68750+023550FM-12+038299999V0203301N00671220001CN9999999N9+00001+99999999999)
(106, 0043011990999991950051512004+68750+023550FM-12+038299999V0203201N00671220001CN9999999N9+00221+99999999999)
(212, 0043011990999991950051518004+68750+023550FM-12+038299999V0203201N00261220001CN9999999N9-00111+99999999999)
(318, 0043012650999991949032412004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+01111+99999999999)
(424, 0043012650999991949032418004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+00781+99999999999)
---------------------||||--------------------------------------------------------------------||||||------------
年份 气温信息(第88-92列是气温值,第93列是quality code)
其中,key 是记录在文件中的行号(从 0 开始),我们并不关心,将其忽略即可。map 函数的功能是提取年份和气温信息, map 函数的输出为:
(1950, 0) (1950, 22) (1950, −11) (1949, 111) (1949, 78)
map 函数输出经由 MapReduce 框架中进行进一步的处理后,主要需要根据键对键/值对进行排序和分组。经过这一番处理之后, reduce 函数看到的输入为:
(1949, [111, 78]) (1950, [0, 22, −11])
reduce 函数所需要做的工作是遍历这些数据,找出最大值,产生最终的输出结果。所以 reduce 函数的输出为:
(1949, 111) (1950, 22)
这个结果就是从 5 行样本数据中得到的每一个全球最高气温,即:1949 年的最高气温是 11.1 度,1950 年最高气温是 2.2 度。
整个数据流如图 1 所示。
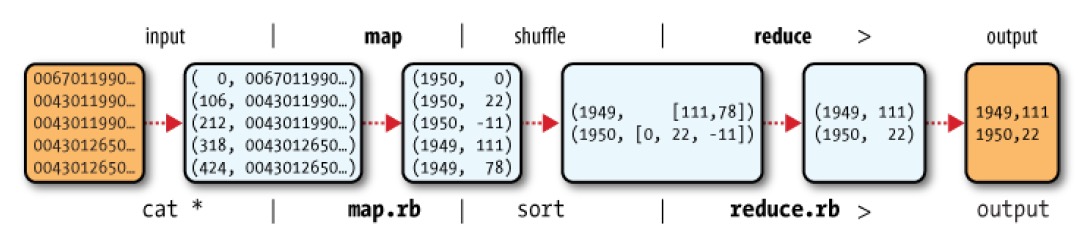
Figure 1: MapReduce 的逻辑数据流
在图 1 的底部是 Unix 管道,用于模拟整个 MapReduce 的流程,这部分内容将在后面讨论 Hadoop Straming 时再次涉及。
2.3.2. Java MapReduce
前面介绍了 MapReduce 的工作原理,现在我们用代码实现它。我们需要三样东西:map 函数、reduce 函数、用来运行 MapReduce 作业的 main 函数。
2.3.2.1. map 函数
map 函数是由一个 Mapper 接口来实现的,其中声明了一个 map() 虚方法。在求最高气温的例子中,map 函数的实现如下:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) { // 其逻辑和前面的awk脚本类似
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
这个 Mapper 接口是一个泛型类型,它有 4 个形参类型,由它们来指定 map 函数的“输入键”、“输入值”、“输出键”和“输出值的类型”。 就前面这个实例来说,输入键是一个长整数偏移量,输入的值是一行文本,输出键是年份,输出值是气温(整数)。Hadoop 规定了自己的一套可用于网络序列优化的基本类型,而不直接使用内置的 Java 类型。这些类型都可以在 org.apache.hadoop.io 包中找到。这里使用 LongWritable 类型(相当于 Java 的 Long 类型)、Text 类型(相当于 Java 的 String 类型)和 IntWritable 类型(相当于 Java 的 Integer 类型)。
map() 方法有 3 个参数。前两个参数为 map() 方法输入,需要传入一个键和一个值。我们将一个包含 Java 字符串输入行的 Text 值转换成 Java 的 String 类型,然后利用其 substring() 方法提取我们感兴趣的列。map() 方法还提供了一个 Context 实例用于写入输出内容。在这个例子中,我们将年份数据是“输出键”,所以把它按 Text 对象进行写入,将气温值封装在 IntWritable 类型中。
2.3.2.2. reduce 函数
类似地,reduce 函数是由一个 Reducer 接口来实现的,其中声明了一个 reduce() 虚方法。在求最高气温的例子中,reduce 函数的实现如下:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
Reducer 接口是一个泛型类型,它有 4 个形参类型用于指定 reduce 过程的输入和输出类型。 reduce 过程的输入类型必须和 map 过程的输出类型(即 Text 类型和 IntWritable 类型)匹配。在求最高气温的例子中,reduce 过程的输出类型也正好为 Text 类型和 IntWritable 类型,分别表示年份及最高气温。
2.3.2.3. 运行 MapReduce 作业的 main 函数
最后一部分代码是用来运行 MapReduce 作业。如下所示:
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxTemperature {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1); // job.submit();
}
}
Job 对象指定作业执行规范。我们可以用它来控制整个作业的运行。我们在 Hadoop 集群上运行这个作业时,要把代码打包成一个 JAR 文件(Hadoop 在集群上发布这个文件)。不必明确指定 JAR 文件的名称,在 Job 对象的 setJarByClass() 方法中传递一个类即可,Hadoop 利用这个类来查找包含它的 JAR 文件,进而找到相关的 JAR 文件。
构造 Job 对象之后,需要指定输入和输出数据的路径。调用 FileInputFormat 类的静态方法 addInputPath() 来定义输入数据的路径,这个路径可以是单个的文件、一个目录(此时,将目录下所有文件当作输入)或符合特定文件模式的一系列文件。由函数名可知,可以多次调用 addInputPath() 来实现多路径的输入。
调用 FileOutputFormat 类中的静态方法 setOutputPath() 来指定输出路径(只能有一个输出路径)。这个方法指定的是 reduce 函数输出文件的写入目录。在运行作业前该目录是不应该存在的,否则 Hadoop 会报错并拒绝运行作业。这种预防措施的目的是防止数据丢失(长时间运行的作业如果结果被意外覆盖,肯定是非常恼人的)。
接着,通过 setMapperClass() 和 setReducerClass() 指定 map 类型和 reduce 类型。
setOutputKeyClass() 和 setOutputValueClass() 控制 map 和 reduce 函数的输出类型,正如本例所示,这两个输出类型一般都是相同的。如果不同,则通过 setMapOutputKeyClass() 和 setMapOutputValueClass() 来设置 map 函数的输出类型。
输入的类型通过 InputFormat 类来控制,我们的例子中没有设置,因为使用的是默认的 TextInputFormat(文本输入格式)。
在设置定义 map 和 reduce 函数的类之后,可以开始运行作业。Job 中的 waitForCompletion() 方法提交作业并等待执行完成。该方法中的布尔参数是控制是否输出详细信息的标识,例子中为 true,所以作业会把进度写到控制台。除 waitForCompletion() 外,调用 Job 的 submit() 方法也可以提交作业,它会在提交成功后马上返回,而不等待作业执行完成。
waitForCompletion() 方法返回一个布尔值,表示执行的成(true)败(false),这个布尔值被转换成程序的退出代码 0 或者 1。
程序的运行测试参见附录 7.2。
2.4. Hadoop Streaming
Hadoop 提供了 MapReduce 的 API,允许你使用非 Java 的其他语言来写自己的 map 和 reduce 函数。 Hadoop Streaming 使用 Unix 标准流作为 Hadoop 和应用程序之间的接口,所以我们可以使用任何编程语言(如 Ruby,Python 等等)通过标准输入/输出来写 MapReduce 程序。
Streaming 天生适合用于文本处理。map 的输入数据通过标准输入流传递给 map 函数,并且是一行一行地传输,最后将结果行写到标准输出。map 输出的键/值对是以一个制表符分隔的行,并且写入标准输出 reduce 函数的输入格式与之相同(通过制表符来分隔的键/值对)并通过标准输入流进行传输。reduce 函数从标准输入流中读取输入行,该输入已由 Hadoop 框架根据键排过序,最后将结果写入标准输出。
下面使用 Streaming 来重写按年份查找最高气温的 MapReduce 程序。
2.4.1. Ruby 版本
每年全球气温的最高记录的例子。用 Ruby 编写的 map 函数:
#!/usr/bin/env ruby
STDIN.each_line do |line|
val = line
year, temp, q = val[15,4], val[87,5], val[92,1]
puts "#{year}\t#{temp}" if (temp != "+9999" && q =~ /[01459]/)
end
用 Ruby 编写的 reduce 函数:
#!/usr/bin/env ruby
last_key, max_val = nil, -1000000
STDIN.each_line do |line|
key, val = line.split("\t")
if last_key && last_key != key
puts "#{last_key}\t#{max_val}"
last_key, max_val = key, val.to_i
else
last_key, max_val = key, [max_val, val.to_i].max
end
end
puts "#{last_key}\t#{max_val}" if last_key
可以直接在 Unix 管道上进行测试,过程如下:
$ cat input/ncdc/sample.txt | ./max_temperature_map.rb 1950 +0000 1950 +0022 1950 -0011 1949 +0111 1949 +0078 $ cat input/ncdc/sample.txt | ./max_temperature_map.rb | sort | ./max_temperature_reduce.rb 1949 111 1950 22
在 Hadoop 环境中的测试如下:
$ rm -rf output $ hadoop jar $HADOOP_INSTALL/share/hadoop/tools/lib/hadoop-streaming-2.7.1.jar \ -input input/ncdc/sample.txt \ -output output \ -mapper ./max_temperature_map.rb \ -reducer ./max_temperature_reduce.rb
运行结束后,在 output 目录中会生成结果文件:
$ cat output/part-00000 1949 111 1950 22
3. HDFS (Hadoop Distributed File System)
当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并存储到若干台单独的计算机上。管理网络中跨多台计算机存储的文件系统称为分布式文件系统(Distributed Filesystem)。该系统架构于网络之上,势必会引入网络编程的复杂性,因此分布式文件系统比普通磁盘文件系统更为复杂。例如,使文件系统能够容忍节点故障且不丢失任何数据,就是一个极大的挑战。
Hadoop 有一个称为 HDFS (Hadoop Distributed File System) 的分布式系统,它是 Hadoop 的旗舰级文件系统(注:Hadoop 也可以集成其他文件系统的方法,如本地文件系统,如 Amazon S3 系统等等)。
3.1. HDFS 应用场景
3.1.1. HDFS 适合场景
HDFS 适合于下面场景:
1、 存储超大文件。 “超大文件”在这里指具有几百 MB、几百 GB 甚至几百 TB 大小的文件。目前已经有存储 PB 级数据的 Hadoop 集群了。
2、 流式数据访问。 HDFS 的构建思路是这样的:“一次写入、多次读取”是最高效的访问模式。数据集通常由数据源生成或从数据源复制而来,接着长时间在此数据集上进行各种分析。毎次分析都将涉及该数据集的大部分数据甚至全部,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。
3、 普通商用硬件。 Hadoop 并不需要运行在昂贵且高可靠的硬件上。它是设计运行在商用硬件(在各种零售店都能买到的普通硬件)的集群上的,因此至少对于庞大的集群来说,节点故障的几率还是非常高的。HDFS 遇到上述故障时,被设计成能够继续运行且不让用户察觉到明显的中断。
3.1.2. HDFS 不适合场景
HDFS 不适合于下面场景:
1、 低时间延迟的数据访问。 要求低时间延迟数据访问的应用,例如几十毫秒范围,不适合在 HDFS 上运行。记住,HDFS 是为高数据吞吐量应用优化的,这可能会以提高时间延迟为代价。目前,对于低延迟的访问需求,Hbase 是更好的选择。
2、 大量的小文件。 由于 namenode 将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于 namenode 的内存容量。根据经验,每个文件、目录和数据块的存储信息大约占 150 字节。因此,举例来说,如果有一百万个文件,且每个文件占数据块,那至少需要 300 MB 的内存。尽管存储上百万个文件是可行的,但是存储数十亿个文件就超出了当前硬件的能力。
3、 多用户写入,任意修改文件。 HDFS 中的文件只有一个写入者,而且写操作总是将数据添加在文件的末尾。它不支持具有多个写入者的操作,也不支持在文件的任意位置进行修改。可能以后会支持这些操作,但它们相对比较低效。
3.2. HDFS 基本架构
HDFS 采用典型的「主从架构」,它有三个角色:NameNode(名称节点)、DataNode(数据节点)和 Client(客户端),如图 2 所示。
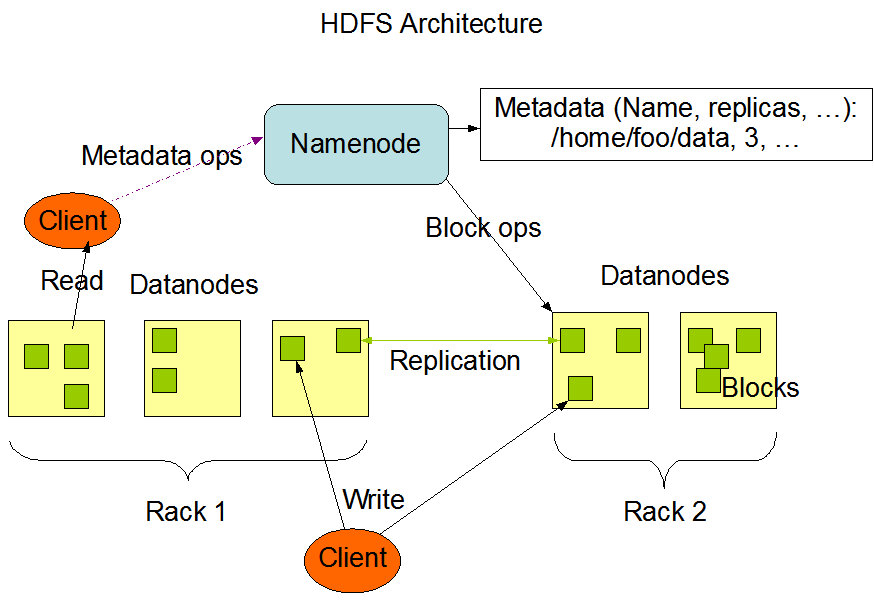
Figure 2: HDFS Architecture
1、NameNode 是文件系统的「管理节点」,管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。 NameNode 也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时根据数据节点信息重建。
2、DataNode 是文件系统的「工作节点」。它们根据需要存储并检索数据块(受客户端或 NameNode 调度),并且定期向 NameNode 发送它们所存储的块的列表。
3、Client(客户端)代表用户通过与 NameNode 和 DataNode 交互来访问整个文件系统。它负责把大文件切分为数据块;与 NameNode 交互,获得文件位置信息;与 DataNode 交互,读取和写入数据。 客户端提供一个类似于 POSIX 的文件系统接口,因此用户在编程时无需知道 NameNode 和 DataNode 也可实现其功能。
NameNode 在系统中至关重要。没有 NameNode,文件系统将无法使用。事实上,如果运行 NameNode 服务的机器毁坏,文件系统上所有的文件将会丢失因为我们不知道如何根据 DataNode 的块重建文件。因此, 对 NameNode 实现容错非常重要,是实现 HDFS 高可用的关键。
3.2.1. 数据块
每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位。构建于单个磁盘之上的文件系统通过磁盘块来管理该文件系统中的块,该文件系统块的大小可以是磁盘块的整数倍。文件系统块一般为几千字节(如 4kB),而磁盘块一般为 512 字节。这些信息(文件系统块大小)对于需要读/写文件的文件系统用户来说是透明的。尽管如此,系统仍然提供了一些工具(如 df 和 fsck)来维护文件系统,由它们对文件系统中的块进行操作。
HDFS 同样也有块(block)的概念,但是大得多,默认为 128MB 与单一磁盘上的文件系统相似,HDFS 上的文件也被划分为块大小的多个分块(chunk),作为独立的存储单元。
块非常适合用于数据备份进而提供数据容错能力和提高可用性。将每个块复制到几个物理上相互独立的机器上(默认复本数量为 3 个),可以确保在块、磁盘或机器发生故障后数据不会丢失。如果发现一个块不可用,系统会从其他地方读取另一个复本,而这个过程对用户是透明的。 一个因损坏或机器故障而丢失的块可以从其他候选地点复制到另一台可以正常运行的机器上,以保证复本的数量回到正常水平。
与磁盘文件系统相似,HDFS 中 fsck 指令可以显示块信息。例如,执行以下命令将列出文件系统中各个文件由哪些块构成:
$ hdfs fsck / -files -blocks
3.2.2. 读写流程
3.2.2.1. 写入流程
下面介绍一下 HDFS 的数据写入流程,如图 3 (摘自:https://www.zhihu.com/question/23036370 )所示。
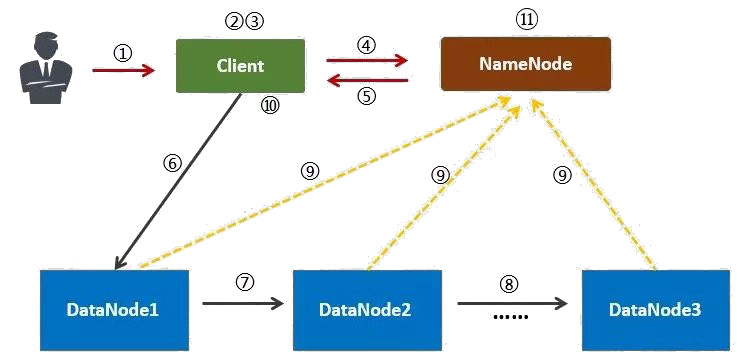
Figure 3: HDFS 的数据写入流程
1、用户向 Client 提出请求。例如,需要写入 200MB 的数据。
2、Client 制定计划:将数据按照 64MB 为块,进行切割;所有的块都保存三份。
3、Client 将大文件切分成块(block)。
4、针对第一个块, Client 告诉 NameNode,请帮助我,将 64MB 的块复制三份。
5、NameNode 告诉 Client 三个(数据节点)的地址,并且将它们根据到 Client 的距离,进行了排序。
6、Client 把数据和清单发给第一个 DataNode。
7、第一个 DataNode 将数据复制给第二个 DataNode。
8、第二个 DataNode 将数据复制给第三个 DataNode。
9、如果某一个块的所有数据都已写入,就会向 NameNode 反馈已完成。
10、对第二个块,也进行相同的操作。
11、所有块都完成后,关闭文件。 NameNode 会将数据持久化到磁盘上。
3.2.3. 读取流程
下面介绍一下 HDFS 的数据读取流程,如图 4 (摘自:https://www.zhihu.com/question/23036370 )所示。
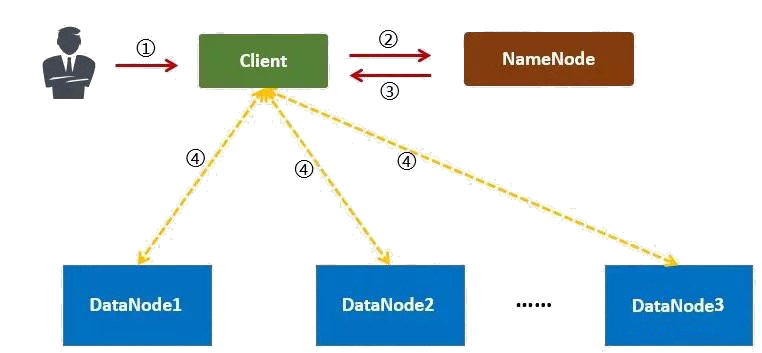
Figure 4: HDFS 的数据读取流程
1、用户向 Client 提出读取请求。
2、Client 向 NameNode 请求这个文件的所有信息。
3、NameNode 将给 Client 这个文件的块列表,以及存储各个块的数据节点清单(按照和客户端的距离排序)。
4、Client 从距离最近的数据节点下载所需的块。
注:以上只是简化的描述,实际过程会更加复杂。
3.2.3.1. 命令行接口
HDFS 有很多接口(如 Java 接口等),但命令行接口( hadoop fs )是最简单的。
HDFS 命令行接口的详细说明可参考:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html
下面是它的帮忙信息:
$ hadoop fs -help Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>] [-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...] [-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>] ......
假设 HDFS 已经搭建好,下面演示一下通过 HDFS 命令行接口存取文件:
$ hadoop fs -copyFromLocal input/docs/quangle.txt hdfs://localhost/user/tom/quangle.txt $ hadoop fs -copyToLocal hdfs://localhost/user/tom/quangle.txt quangle.copy.txt
使用 -copyFromLocal 可以把文件从本地得到到 HDFS 指定路径中;而 -copyToLocal 可以把文件从 HDFS 路径复制到本地。
如果我们在配置文件 core-site.xml 中已经指定默认主机 URI,则可以省略 hdfs://localhost 部分,即上面两条命令可简写为:
$ hadoop fs -copyFromLocal input/docs/quangle.txt /user/tom/quangle.txt # 省略 hdfs://localhost $ hadoop fs -copyToLocal /user/tom/quangle.txt quangle.copy.txt # 省略 hdfs://localhost
我们还可以进一步把 HDFS 的 home 目录(上面例子是 /user/tom)也省略,即上面两条命令可进一步简写为:
$ hadoop fs -copyFromLocal input/docs/quangle.txt quangle.txt # 省略 HDFS 的 home 目录 $ hadoop fs -copyToLocal quangle.txt quangle.copy.txt # 省略 HDFS 的 home 目录
此外,也可以使用 -put 和 -get 分别代替 -copyFromLocal 和 -copyToLocal ,如:
$ hadoop fs -put input/docs/quangle.txt quangle.txt # -put 和 -copyFromLocal 类似 $ hadoop fs -get quangle.txt quangle.copy.txt # -get 和 -copyToLocal 类似
使用 -mkdir 可以创建目录; -ls 可以查看目录,如:
$ hadoop fs -mkdir books $ hadoop fs -ls . Found 2 items drwxr-xr-x - tom supergroup 0 2014-10-04 13:22 books -rw-r--r-- 1 tom supergroup 119 2014-10-04 13:21 quangle.txt
4. YARN
Apache YARN(Yet Another Resource Negotiator 的缩写)是 Hadoop 的集群资源管理系统。YARN 从 Hadoop2 被引入,最初是为了改善 MapReduce 的实现,但它具有足够的通用性,同样可以支持其他的分布式计算模式。
YARN 提供请求和使用集群资源的 API,但这些 API 很少直接用于用户代码。相反,用户代码中用的是分布式计算框架提供的更高层 API,这些 API 建立在 YARN 之上且向用户隐藏了资源管理细节。图 5 对此进行了描述,一些分布式计算框架(MapReduce,Spark 等等)作为 YARN 应用运行在集群计算层(YARN)和集群存储层(HDFS 和 HBase)上。
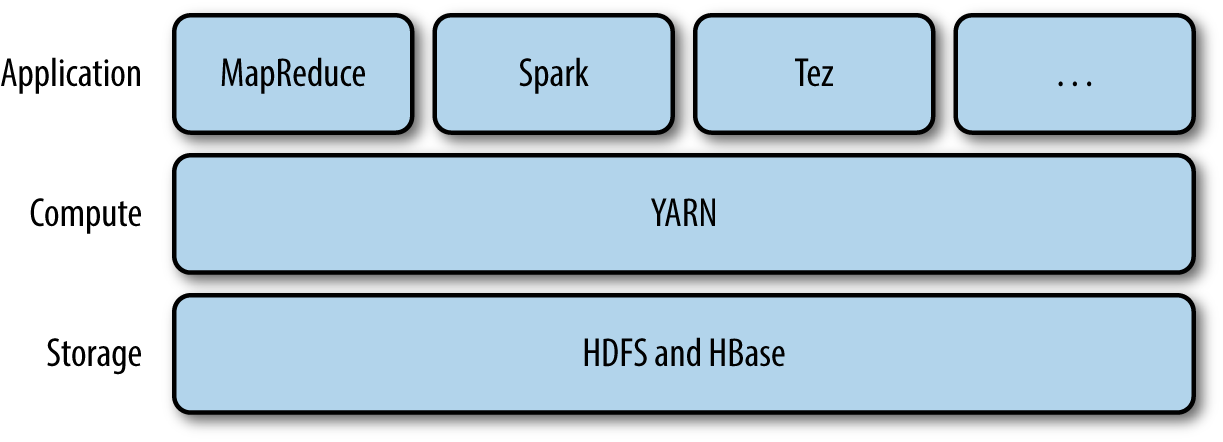
Figure 5: YARN
还有一层应用是建立在图 5 所示的框架之上。如 Pig,Hive 和 Crunch 都是运行在 MapReduce,Spark 或 Tez(或三个都可)之上的处理框架,它们不和 YARN 直接打交道。如图 6 (图片摘自:https://www.zhihu.com/question/23036370 )所示。
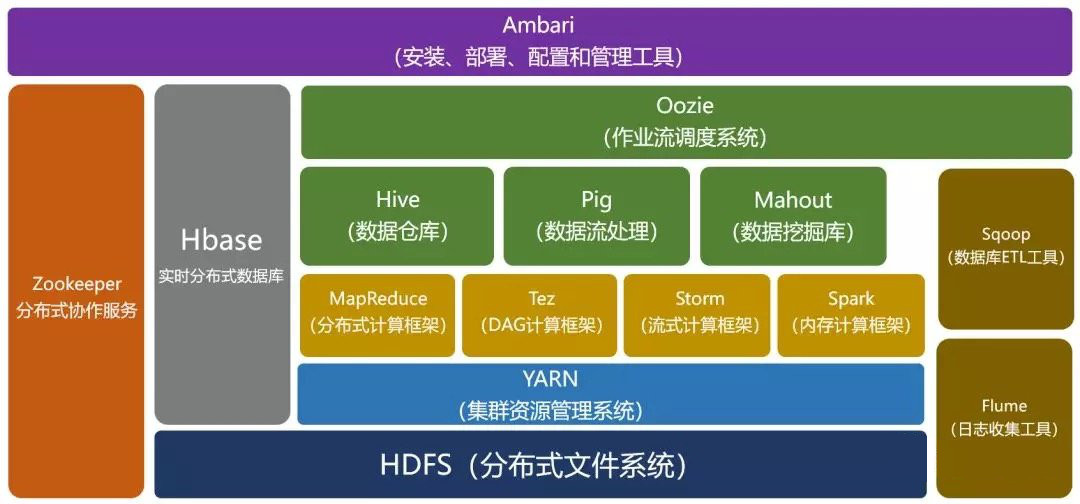
Figure 6: YARN 在 Hadoop 生态中的位置
4.1. YARN 应用的运行机制
YARN 通过两类长期运行的守护进程提供自己的核心服务:1、管理集群上资源使用的“资源管理器”(resource manager),2、运行在集群中所有节点上且能够启动和监控容器(container)的“节点管理器”(node manager)。
上面提到的容器是“用来执行特定应用程序的进程”,每个容器都有资源限制(内存、CPU 等)。一个容器可以是一个 Unix 进程,也可以是一个 Linux cgroup,取决于 YARN 的配置。图 7 描述了 YARN 是如何运行一个应用的。
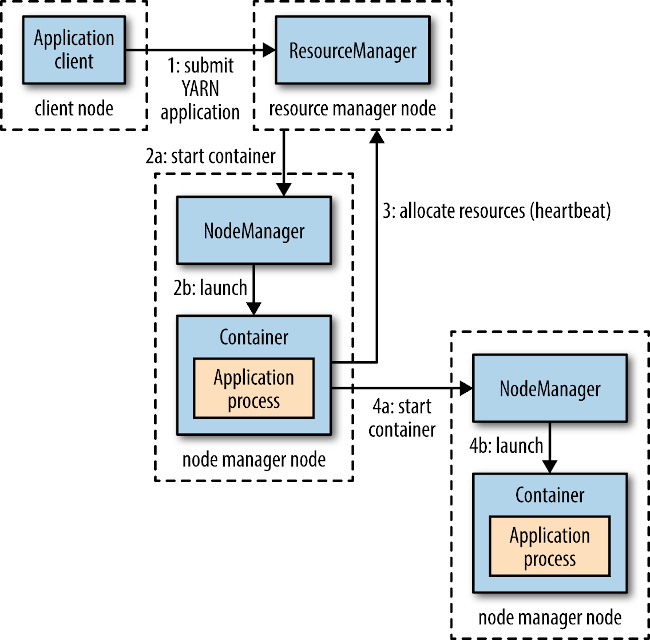
Figure 7: YARN 应用的运行机制
为了在 YARN 上运行一个应用,首先,客户端联系资源管理器,要求它运行一个 application master 进程(图 7 中的步骤 1)然后,资源管理器找到一个能够在容器中启动 application master 的节点管理器(步骤 2a 和 2b)。准确地说,application master 一旦运行起来后能做些什么依赖于应用本身。有可能是在所处的容器中简单地运行一个计算,并将结果返回给客户端;或是向资源管理器请求更多的容器(步骤 3),以用于运行一个分布式计算(步骤 4a 和 4b)。
注意,从图 7 可看出,YARN 本身不会为应用的各部分(客户端、 master 和进程)彼此间通信提供任何手段。大多数重要的 YARN 应用使用某种形式的远程通信机制(例如 Hadoop 的 RPC 层)来向客户端传递状态更新和返回结果,但是这些通信机制都是专属于各应用的。
4.1.1. 资源请求
YARN 有一个灵活的资源请求模型。当请求多个容器时,可以指定每个容器需要的计算机资源数量(内存和 CPU),还可以指定对容器的本地限制要求。
本地化对于确保分布式数据处理算法高效使用集群带宽非常重要,因此,YARN 允许一个应用为所申请的容器指定本地限制。本地限制可用于申请位于指定节点或机架,或集群中任何位置(机架外)的容器。
有时本地限制无法被满足,这种情况下要么不分配资源,或者可选择放松限制。例如,一个节点由于已经运行了别的容器而无法再启动新的容器,这时如果有应用请求该节点,则 YARN 将尝试在同一机架中的其他节点上启动一个容器,如果还不行,则会尝试集群中的任何一个节点。
通常情况下,当启动一个容器用于处理 HDFS 数据块(为了在 MapReduce 中运行一个 map 任务)时,应用将会向这样的节点申请容器:存储该数据块三个复本的节点,或是存储这些复本的机架中的一个节点。如果都申请失败,则会集群中的任意节点申请容器。
YARN 应用可以在运行中的任意时刻提出资源申请。例如,可以在最开始提出所有的请求,或者为了满足不断变化的应用需要,采取更为动态的方式在需要更多资源时提出请求。Spark 采用了上述第一种方式,在集群上启动固定数量的执行器。MapReduce 则分两步走,在最开始时申请 map 任务容器,reduce 任务容器的启用则放在后期。同样,如果任何任务出现失败,将会另外申请容器以重新运行失败的任务。
4.1.2. 应用生命期
YARN 应用的生命期差异性很大:有几秒的短期应用,也有连续运行几天甚至几个月的长期应用。与其关注应用运行多长时间,不如按照应用到用户运行的作业之间的映射关系对应用进行分类更有意义。
最简单的模型是一个用户作业对应一个应用,这也是 MapReduce 采取的方式。
第二种模型是,作业的每个工作流或每个用户对话(可能并无关联性)对应一个应用。这种方法要比第一种情况效率更高,因为容器可以在作业之间重用,并且有可能缓存作业之间的中间数据。 Spark 采取的是这种模型。
第三种模型是,多个用户共享一个长期运行的应用。这种应用通常是作为一种协调者的角色在运行。例如,Impala 使用这种模型提供了一个代理应用,Impala 守护进程通过该代理请求集群资源。由于避免了启动新 application master 带来的开销,一个总是开启(always on)的 application master 意味着用户将获得非常低延迟的查询响应。
4.1.3. 构建 YARN 应用
从无到有编写一个 YARN 应用是一件相当复杂的事,但在很多情况下不必这样。有很多现成的应用,在符合要求的情况下通常可以直接使用。例如,如果你有兴趣运行一个作业的有向无环图,那么 Spark 或 Tez 就很合适;如果对流处理有兴趣,Spark、Samza 或 Storm 能提供帮助。
假如你的应用包含着复杂的调度需求(或者其它变态需求),你发现现成的项目(如 Spark、Tex、Samza、Storm 等)都无法满足你的需求,你想自己动手写一个 YARN 应用,那么 YARN 自带的 distributed shell 例子做了一个示范。该例子演示了如何使用 YARN 客户端 API 来处理客户端或 application master 与 YARN 守护进程之间的通信。
4.2. YARN 中的调度
理想情况下,YARN 应用发出的资源请求应该立刻给予满足。然而现实中资源是有限的,在一个繁忙的集群上,一个应用经常需要等待才能得到所需的资源。YARN 调度器的工作就是根据既定策略为应用分配资源。调度通常是一个难题,并且没有一个所谓“最好”的策略,这也是为什么 YARN 提供了多种调度器和可配置策略供我们选择的原因。接下来我们将探讨这个问题。
4.2.1. 三种调度器
YARN 中有三种调度器可用:FIFO 调度器(FIFO Scheduler),容量调度器(Capacity Scheduler)和公平调度器(Fair Scheduler)。
图 8 描述了这三种调度器之间的差异性。
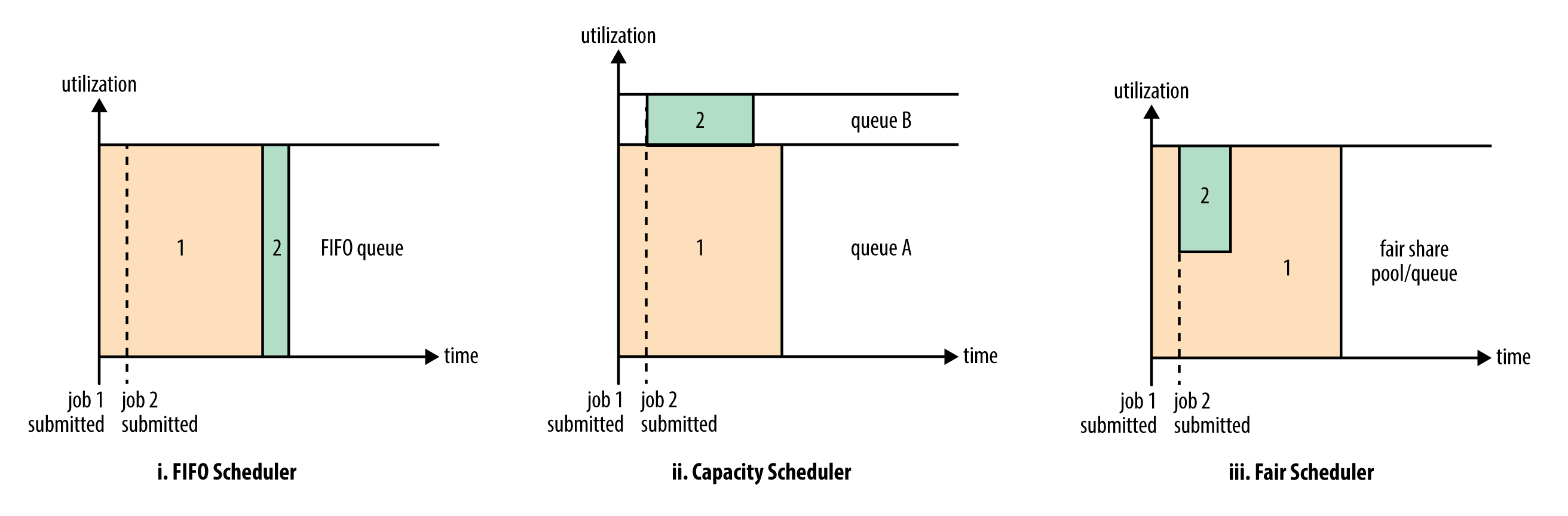
Figure 8: :YARN 三种调度器:FIFO 调度器、容量调度器、公平调度器
FIFO 调度器将应用放置在一个队列中,然后按照提交的顺序(先进先出)运行应用。FIFO 调试器的缺点是可能出现小作业一直被阻塞,直至大作业完成的情况。FIFO 调度器不适合共享集群,大的应用会占用集群中的所有资源。
容量调度器,有一个独立的专门队列(如图 8 中的 queue B)保证小作业一提交就可以启动。由于队列容量是为那个队列中的作业所保留的,因此这种策略是以整个集群的利用率为代价的。这意味着与使用 FIFO 调度器相比,大作业执行的时间要长。
公平调度器,不需要预留一定量的资源,因为调度器会在所有运行的作业之间动态平衡资源。如图 8 中的 iii 子图,第一个(大)作业启动时,它也是唯一运行的作业,因而获得集群中所有的资源。当第二个(小)作业启动时,它被分配到集群的一半资源,这样每个作业都能公平共享资源。
5. MapReduce 的工作机制
5.1. MapReduce 作业运行机制
通过 Job 对象的 submit() 或者 waitForCompletion() 方法可以提交一个 MapReduce 作业。但它们背后有哪些细节呢?
整个过程描述如图 9 所示。在最高层,有以下 5 个独立的实体:
- 客户端,提交 MapReduce 作业。
- YARN 资源管理器,负责协调集群上计算机资源的分配。
- YARN 节点管理器,负责启动和监视集群中机器上的计算容器。
- MapReduce 的 application master,负责协调运行 MapReduce 作业的任务。它和 Map Reduce 任务在容器中运行,这些容器由资源管理器分配并由节点管理器进行管理。
- 分布式文件系统(一般为 HDFS),用来与其他实体间共享作业文件。
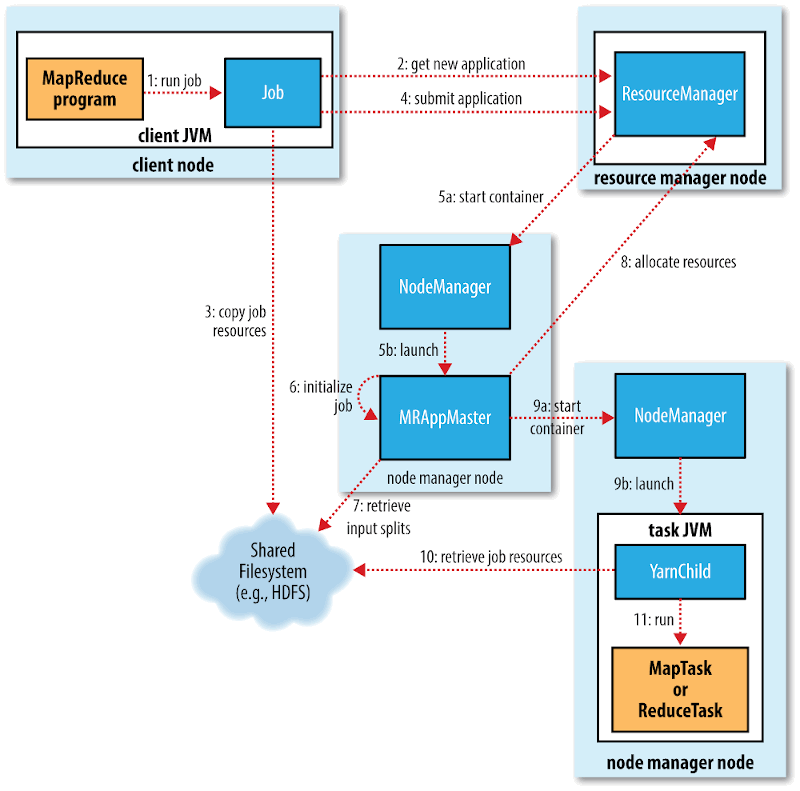
Figure 9: Hadoop 运行 MapReduce 作业的工作原理
5.2. Shuffle and Sort
MapReduce 确保每个 Reducer 的输入都是按键排序的,从 map 产生输出到 reduce 接受输入还有很多工作要做。我们把 从 map 产生输出到 reduce 消化输入的整个过程称为 shuffle。shuffle 过程是 MapReduce 的核心,也被称为奇迹发生的地方。 shuffle 属于不断被优化和改进的地方,代码可能经常变化。
5.2.1. map 端
map 函数开始产生输出时,并不是简单地将它写到磁盘。这个过程很复杂,它利用缓冲的方式写到内存,并出于效率的考虑进行预排序。图 10 左边子图展示了这个过程。
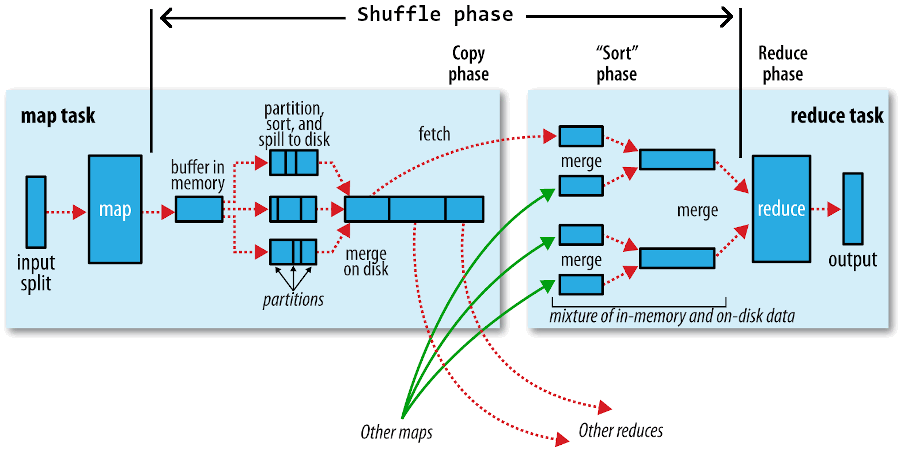
Figure 10: Shuffle and sort in MapReduce
每个 map 任务都有一个环形内存缓冲区用于存储任务输出。在默认情况下,缓冲区的大小为 100MB,这个值可以通过改变 mapreduce.task.io.sort.mb 属性来调整。一旦缓冲内容达到阈值( mapreduce.map.sort.spill.percent ,默认为 0.80,或 80%),一个后台线程便开始把内容溢出(spill)到磁盘。在溢出写到磁盘过程中,map 输出继续写到缓冲区,但如果在此期间缓冲区被填满,map 会被阻塞直到写磁盘过程完成。溢出写过程按轮询方式将缓冲区中的内容写到 mapreduce.cluster.local.dir 属性在作业特定子目录下指定的目录中。
在写磁盘之前,线程首先根据数据最终要传的 reducer 把数据划分成相应的分区(partition)。 在每个分区中,后台线程按键进行内存中排序,如果有一个 combiner 函数,它就在排序后的输出上运行。运行 combiner 函数使得 map 输出结果更紧凑,因此减少写到磁盘的数据和传递给 reducer 的数据。
每次内存缓冲区达到溢出阈值,就会新建一个溢出文件(spill file),因此在 map 任务写完其最后一个输出记录之后,会有几个溢出文件。在任务完成之前,溢出文件被合并成一个已分区且已排序的输出文件。配置属性 mapreduce.task.io.sort.factor 控制着一次最多能合并多少流,默认值是 10。
如果至少存在 3 个溢出文件(通过 mapreduce.map.combine.minspills 属性设置)时,则 combiner 就会在输出文件写到磁盘之前再次运行。前面曾讲过, combiner 可以在输入上反复运行,但并不影响最终结果。如果只有 1 或 2 个溢出文件,那么由于 map 输出规模减少,因而不值得调用 combiner 带来的开销,因此不会为该 map 输出再次运行 combiner。
Reducer 通过 HTTP 得到输出文件的分区。用于文件分区的工作线程的数量由任务的 mapreduce.shuffle.max.threads 属性控制,此设置针对的是每一个节点管理器,而不是针对每个 map 任务。默认值 0 将最大线程数设置为机器中处理器数量的两倍。
5.2.2. reduce 端
现在转到处理过程的 reduce 部分。map 输出文件位于运行 map 任务的 tasktracker 的本地磁盘(注意,尽管 map 输出经常写到 map tasktracker 的本地磁盘,但 reduce 输出并不这样),现在,tasktracker 需要为分区文件运行 reduce 任务。并且,reduce 任务需要集群上若干个 map 任务的 map 输出作为其特殊的分区文件。每个 map 任务的完成时间可能不同,因此在每个任务完成时, reduce 任务就开始复制其输出。这就是 reduce 任务的复制阶段。reduce 任务有少量复制线程,因此能够并行取得 map 输出。默认值是 5 个线程,但这个默认值可以通过设置 mapreduce.reduce.shuffle.parallelcopies 属性修改。
如果 map 输出相当小,会被复制到 reduce 任务 JVM 的内存(缓冲区大小由 mapreduce.reduce.shuffle.input.buffer.percent 属性控制,指定用于此用途的堆空间的百分比),否则,map 输出被复制到磁盘。一旦内存缓冲区达到阈值大小(由 mapreduce.reduce.shuffle.merge.percent 决定)或达到 map 输出阈值(由 mapreduce.reduce.merge.inmem.threshold 控制),则合并后溢出写到磁盘中。如果指定 combiner,则在合并期间运行它以降低写入硬盘的数据量。
随着磁盘上副本增多,后台线程会将它们合并为更大的、排好序的文件。这会为后面的合并节省一些时间。注意,为了合并,压缩的 map 输出(通过 map 任务)都必须在内存中被解压缩。
复制完所有 map 输出后, reduce 任务进入排序阶段(更恰当的说法是合并阶段,因为排序是在 map 端进行的),这个阶段将合并 map 输出,维持其顺序排序。 这是循环进行的。比如,如果有 50 个 map 输出,而合并因子是 10(10 为默认设置,由 mapreduce.task.io.sort.factor 属性设置,与 map 的合并类似),合并将进行 5 趟。每趟将 10 个文件合并成一个文件,因此最后有 5 个中间文件。
在最后阶段,即把数据输入 reduce 函数。并没有直接将这 5 个中间文件合并成一个已排序的文件,而是混合了内存和磁盘的数据,只要能保证输入 reduce 函数的数据是按键排序的即可。
在 reduce 阶段,对已排序输出中的每个键调用 reduce 函数。 此阶段的输出直接写到输出文件系统,一般为 HDFS。如果采用 HDFS,由于节点管理器也运行数据节点,所以第一个块复本将被写到本地磁盘。
5.2.2.1. 从哪台机器取得 map 输出
Reducer 如何知道要从哪台机器取得 map 输出呢?
map 任务成功完成后,它们会使用“心跳机制”通知它们的 application master。因此,对于指定作业, application master 知道 map 输出和主机位置之间的映射关系。 Reducer 中的一个线程定期询问 master 以便获取 map 输出主机的位置,直到获得所有输出位置。
由于第一个 Reducer 可能失败,因此主机并没有在第一个 Reducer 检索到 map 输出时就立即从磁盘上删除它们。相反,主机会等待,直到 application master 告知它删除 map 输出,这是作业完成后执行的。
5.2.3. Mapper、Partition、Reducer 的数量
Mapper 的数量由客户端分片情况决定,客户端获取到输入路径的所有文件,依次对每个文件执行分片,分片大小通过最大分片大小、最小分片大小、HDFS 的 blocksize 综合确定,分片结果写入 job.split 文件中,提交给 YARN,对每个分片分配一个 Mapper。
Partition 的数量由 PartitionerClass 中的逻辑确定,默认情况下使用的 HashPartitioner 中使用了 hash 值与 reducerNum(Reducer 数目)的余数,即 默认情况下,Partition 数量由 Reducer 的数量决定。 如果是自定义 PartitionerClass,则 Partition 的数量可能与 Reducer 数目无关。
Reducer 的数量默认为 1,可以通过 Job 类的方法 setNumReducerTasks(num) 来设置 Reducer 数量。
6. HBase
HBase 是一个在 HDFS 上开发的“面向列”(Column-oriented)的分布式数据库。表 2 总结了一些开源的“面向列”的数据库系统。
| Database Name | Language Implemented in |
|---|---|
| Apache Cassandra | Java |
| Apache HBase | Java |
| Apache Kudu | C++ |
| Calpont InfiniDB | C++ |
| ClickHouse | C++ |
| CrateDB | Java |
| C-Store | |
| Druid | Java |
| Greenplum Database | C |
| PostgreSQL cstore_fdw, vops2 | C |
| MariaDB Column Store | C & C++ |
| MapD | C++ |
| Metakit | C++ |
| MonetDB | C |
| RCFile | |
| Scylla (database) OpenSource | C++ |
6.1. 数据模型的“旋风之旅”
数据存在在表中,表由行和列组成。表格的“单元格“(cell)由行和列的坐标交叉决定,是有版本的。默认情况下,版本号是自动分配的,为 HBase 插入单元格时的时间戳。单元格的内容是未解释的字节数组。例如,图 11 所示为用于存储照片的 HBase 表。
表中的行根据 row key(也就是表的主键)进行排序。所有对表的访问都要通过表的主键。HBase 不支持对表中的其他列建立索引(即一般 HBase 是没有辅助索引的)。不过,有几种策略可用于支持辅助索引提供的查询类型,每种策略在存储空间、处理负载和查询执行时间之间存在不同的利弊权衡。
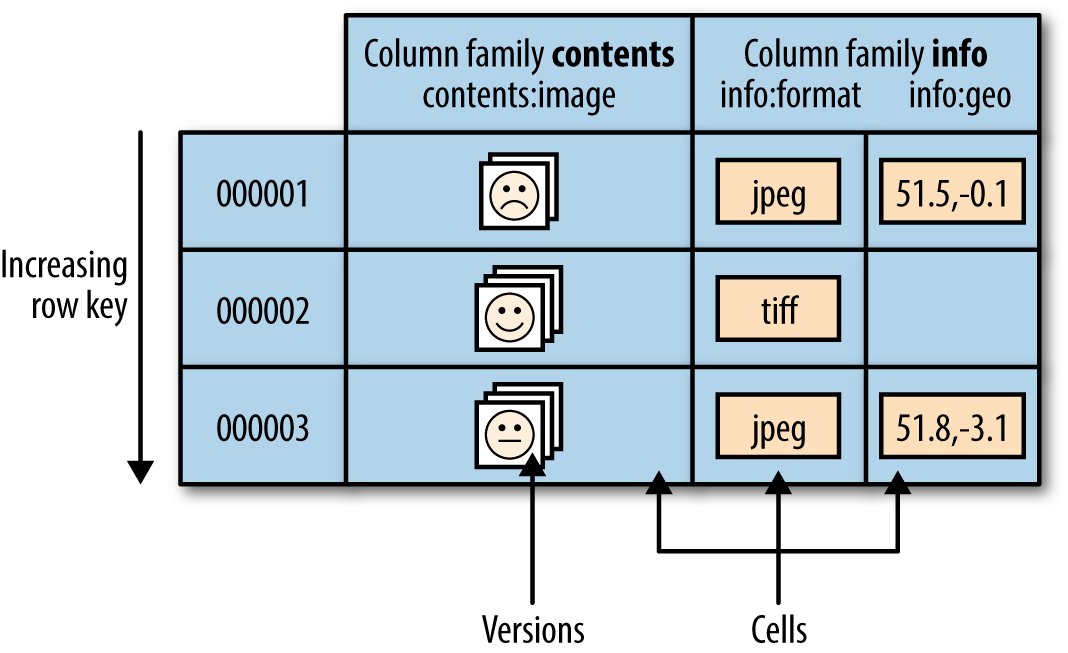
Figure 11: The HBase data model, illustrated for a table storing photos
行中的列被分成“列族”(column family)。同一个列族的所有成员具有相同的前缀(前缀和后面部分用冒号分隔)。因此,像列 info:format 和 info:geo 都是列族 info 的成员,而 contents:image 则属于 contents 族。列族的前缀必须由“可打印的”(printable)字符组成。
一个表的列族必须作为表模式定义的一部分预先给出,但是新的列族成员可以随后按需要加入。例如,只要目标表中已经有了列族 info,那么客户端就可在更新时提供新的列 info:camera ,并存储它的值。
物理上,所有的“列族成员”都一起存放在文件系统中。 所以,虽然我们前面把 HBase 描述为一个面向列的存储器,但实际上更准确的说法是:它是一个面向列族的存储器。由于调优和存储都是在列族这个层次上进行的,所以最好使所有列族成员都有相同的访问模式(access pattern)和大小特征。
下面总结一下 HBase 表和 RDBMS 表的不同:
1、HBase 表的单元格有版本;
2、HBase 表中的行是排序的;
3、只要列族预先存在,客户端随时可以把列添加到列族中去。
6.2. HBase Shell 基本使用
假设 hbase-site.xml 已经配置好。下面以创建图 12 所示数据为例演示一下 HBase Shell 的基本操作。
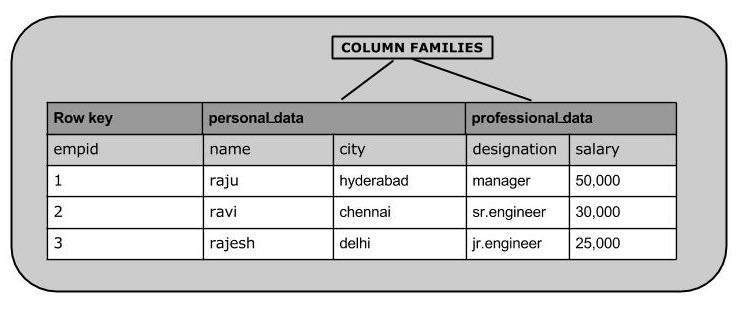
Figure 12: HBase 样例数据
连接 HBase:
$ ./bin/hbase shell hbase(main):001:0>
执行 create 命令创建一个表,需要指定表名和列族(Column Family)的名字。下面创建一个表,表名为 emp,两个列族分别为“personal_data”和“professional_data”:
hbase(main):002:0> create 'emp', 'personal_data', 'professional_data' 0 row(s) in 1.1300 seconds => Hbase::Table - emp
执行 list 命令可列出刚刚创建的表:
hbase(main):002:0> list TABLE emp 2 row(s) in 0.0340 seconds
执行 put 命令把数据存入表中:
hbase(main):005:0> put 'emp','1','personal_data:name','raju' 0 row(s) in 0.6600 seconds hbase(main):006:0> put 'emp','1','personal_data:city','hyderabad' 0 row(s) in 0.0410 seconds hbase(main):007:0> put 'emp','1','professional_data:designation','manager' 0 row(s) in 0.0240 seconds hbase(main):007:0> put 'emp','1','professional_data:salary','50000' 0 row(s) in 0.0240 seconds
用同样的方法,可以插入图 12 中的其它数据。
执行 scan 命令可显示表中数据:
hbase(main):022:0> scan 'emp' ROW COLUMN+CELL 1 column=personal_data:city, timestamp=1417524216501, value=hyderabad 1 column=personal_data:name, timestamp=1417524185058, value=ramu 1 column=professional_data:designation, timestamp=1417524232601, value=manager 1 column=professional_data:salary, timestamp=1417524244109, value=50000 2 column=personal_data:city, timestamp=1417524574905, value=chennai 2 column=personal_data:name, timestamp=1417524556125, value=ravi 2 column=professional_data:designation, timestamp=1417524592204, value=sr:engg 2 column=professional_data:salary, timestamp=1417524604221, value=30000 3 column=personal_data:city, timestamp=1417524681780, value=delhi 3 column=personal_data:name, timestamp=1417524672067, value=rajesh 3 column=professional_data:designation, timestamp=1417524693187, value=jr:engg 3 column=professional_data:salary, timestamp=1417524702514, value=25000
执行 get 命令可查看某行数据:
hbase(main):012:0> get 'emp', '1' COLUMN CELL personal_data: city timestamp = 1417521848375, value = hyderabad personal_data: name timestamp = 1417521785385, value = ramu professional_data: designation timestamp = 1417521885277, value = manager professional_data: salary timestamp = 1417521903862, value = 50000 4 row(s) in 0.0270 seconds
参考:https://www.tutorialspoint.com/hbase/hbase_create_table.htm
7. 附录
7.1. 附录 1:安装 Hadoop
这里仅介绍在单机上安装 Hadoop(以版本 2.7.1 为例)的过程。
首先,从官网 http://hadoop.apache.org/releases.html#Download 下载稳定版的发布包(如 hadoop-2.7.1.tar.gz,大小约 201MB),然后解压到本地文件系统中。
$ tar xzf hadoop-2.7.1.tar.gz $ ls hadoop-2.7.1/ LICENSE.txt README.txt etc lib sbin NOTICE.txt bin include libexec share
然后,配置 JAVA_HOME/HADOOP_INSTALL/PATH 三个环境变量,通常在 shell 启动文件(如~/.bash_profile)中设置。
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_66.jdk/Contents/Home/ export HADOOP_INSTALL=/Users/cig01/hadoop-2.7.1/ export PATH=$PATH:$HADOOP_INSTALL/bin
最后,执行命令 hadoop version 来测试是否安装成功。如:
$ hadoop version Hadoop 2.7.1 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a Compiled by jenkins on 2015-06-29T06:04Z Compiled with protoc 2.5.0 From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a This command was run using /Users/cig01/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar
7.2. 附录 2:Maven 搭建 Hadoop 工程(从 NCDC 数据集中求每年的最高气温)
下面介绍如何用 Maven 搭建 Hadoop 工程,从 NCDC 数据集中求每年的最高气温。
第一步,生成一个简单的 Hello World 工程。
$ mvn archetype:generate -DarchetypeArtifactId=maven-archetype-quickstart -DgroupId=com.mycompany.app -DartifactId=my-hadoop-app -DinteractiveMode=false
第二步,添加 Hadoop 依赖包。
一个简单的 Hadoop 工程,可能需要下面几个包:
hadoop-common hadoop-hdfs hadoop-mapreduce-client-core hadoop-mapreduce-client-jobclient hadoop-mapreduce-client-common
对应地,把下面依赖增加到 pom.xml 中。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.1</version>
</dependency>
第三步,实现 map 函数、reduce 函数、用来运行 MapReduce 作业的 main 函数。
删除第一步自动生成的文件 App.java 和 AppTest.java。把之前介绍的 MaxTemperatureMapper/MaxTemperatureReducer/MaxTemperature 三个类,放入到包 com.mycompany.app 中。
$ cd my-hadoop-app $ find . ./pom.xml ./src ./src/main ./src/main/java ./src/main/java/com ./src/main/java/com/mycompany ./src/main/java/com/mycompany/app ./src/main/java/com/mycompany/app/MaxTemperature.java ./src/main/java/com/mycompany/app/MaxTemperatureMapper.java ./src/main/java/com/mycompany/app/MaxTemperatureReducer.java
第四步,测试运行。
$ mvn clean package $ rm -rf out/ $ hadoop jar target/my-hadoop-app-1.0-SNAPSHOT.jar com.mycompany.app.MaxTemperature input/ncdc/sample.txt out
运行结束后,在 out 目录中会有名为 part-xxx 的结果文件,如:
$ cat out/part-r-00000 1949 111 1950 22
即在样本数据集中,1949 年的最高气温是 11.1 度,1950 年最高气温是 2.2 度。
8. 参考
本文主要摘自:《Hadoop 权威指南(第 4 版)》