JVM (Java Virtual Machine)
Table of Contents
- 1. JVM 简介
- 2. Garbage Collection (GC)
- 2.1. 分代收集:新生代(Young)和老年代(Old/Tenured)
- 2.2. 哪些对象可回收
- 2.3. 垃圾收集算法
- 2.4. HotSpot 的算法实现
- 2.5. GC 调优的目标(“高吞吐率”或“低响应时间”)
- 2.6. 各种垃圾回收器
- 2.7. 理解 GC 日志
- 2.8. 用 jstat 查看 GC 状态
- 3. JIT Compiler
- 4. Tips
1. JVM 简介
Java virtual machine (JVM)是 Java 程序的运行环境。尽管有很多 JVM 实现,但 Oracle 的 HotSpot VM 是使用最广泛的 JVM,这里仅讨论 HotSpot VM。
HotSpot VM 由三个主要部分组成:Garbage Collector,JIT Compiler,VM Runtime,如图 1 所示。
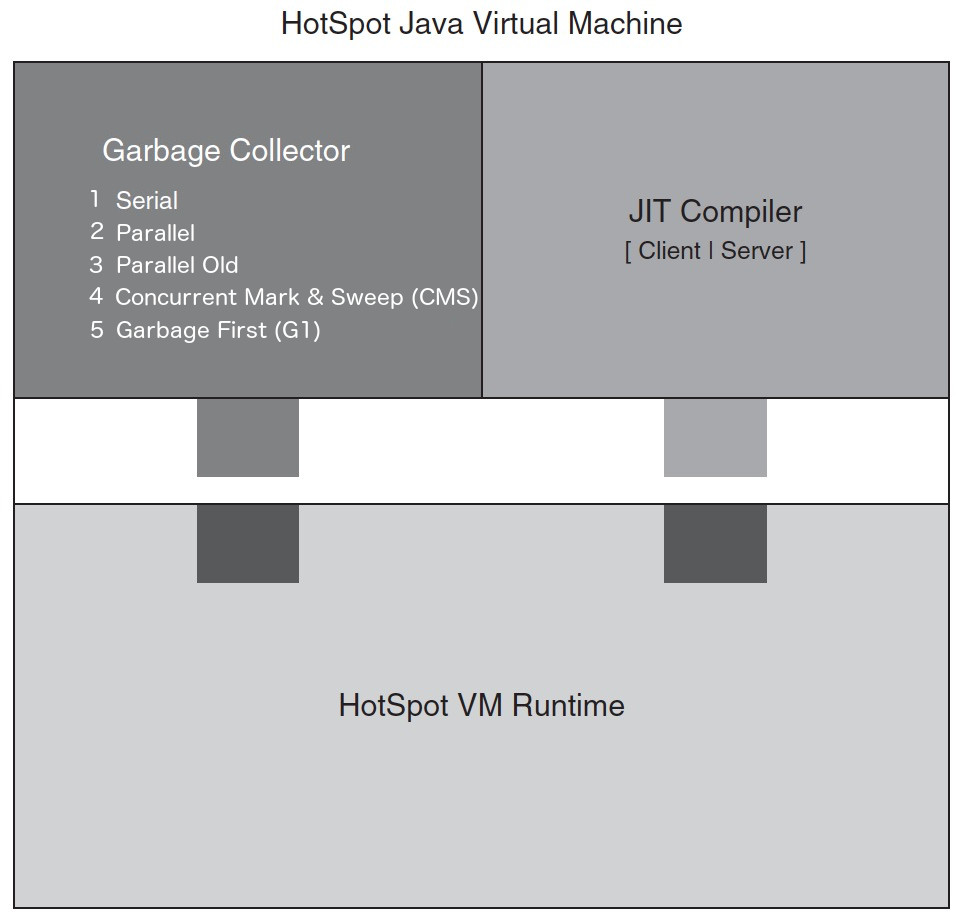
Figure 1: HotSpot VM high level architecture
参考:Java Performance, Chapter 3 JVM Overview
1.1. 命令行选项(标准选项、非标准选项、开发者选项)
java 命令行选项可分为下面三类:
(1) 标准选项:所有的 JVM 实现都应用支持的选项;
(2) 非标准选项:以 -X 为前缀的选项, 可以使用命令 java -X 列出所有的非标准选项;
(3) 开发者选项:以 -XX 为前缀的选项。
对于开发者选项,都以“-XX:”为前缀,可分为两种类型:
(1) “开关”类型的选项。这时, 在选项名字前面指定“-”表示禁止该选项,选项名字前面指定“+”表示打开该选项。 比如:“-XX:+AggressiveOpts”表示启用额外的性能优化,而“-XX:-AggressiveOpts”表示禁止额外的性能优化。
(2) 非开关类型的选项。其格式为 -XX:<name>=<value> 。
参考:
HotSpot VM 的所有开发者选项的说明:Java HotSpot VM Options
1.1.1. Tips: 显示所有选项的默认值
用命令 java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal -version 可以显示 jvm 所有选项的默认值。例如:
$ java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal -version
[Global flags]
uintx AdaptivePermSizeWeight = 20 {product}
uintx AdaptiveSizeDecrementScaleFactor = 4 {product}
uintx AdaptiveSizeMajorGCDecayTimeScale = 10 {product}
uintx AdaptiveSizePausePolicy = 0 {product}
uintx AdaptiveSizePolicyCollectionCostMargin = 50 {product}
uintx AdaptiveSizePolicyInitializingSteps = 20 {product}
uintx AdaptiveSizePolicyOutputInterval = 0 {product}
uintx AdaptiveSizePolicyWeight = 10 {product}
uintx AdaptiveSizeThroughPutPolicy = 0 {product}
uintx AdaptiveTimeWeight = 25 {product}
bool AdjustConcurrency = false {product}
bool AggressiveOpts = false {product}
intx AliasLevel = 3 {product}
intx AllocatePrefetchDistance = -1 {product}
intx AllocatePrefetchInstr = 0 {product}
intx AllocatePrefetchLines = 1 {product}
intx AllocatePrefetchStepSize = 16 {product}
intx AllocatePrefetchStyle = 1 {product}
bool AllowJNIEnvProxy = false {product}
bool AllowUserSignalHandlers = false {product}
......
2. Garbage Collection (GC)
Java 语言中,不用写 delete(delete 在 Java 中是没有使用的保留字)来释放 new 操作申请的内存。JVM 提供了自动内存管理机制,可回收不再需要的内存。
参考:
深入理解 Java 虚拟机——JVM 高级特性与最佳实践(第 2 版),周志明,第 3 章 垃圾收集器与内存分配策略
HotSpot Virtual Machine Garbage Collection Tuning Guide
2.1. 分代收集:新生代(Young)和老年代(Old/Tenured)
Java 中对象实例和数组一般都在“堆”上分配,Java 堆是垃圾回收器管理的主要区域。 现代垃圾回收器采用“分代收集”算法,Java 堆可细分为二部分:新生代(Young generatioin)和老年代(Old/Tenured generation),如图 2 所示。
之所以要分代是基于下面的事实:
(1)大多数分配对象的存活时间很短;
(2)存活时间久的对象很少引用存活时间短的对象。
这样, 如果把新创建的对象放入一个代(新生代)中,存活时间久的对象放入另一个代(老年代)中,从而可以在不同的代中采用不同的回收策略,从而实现更好的回收效果。
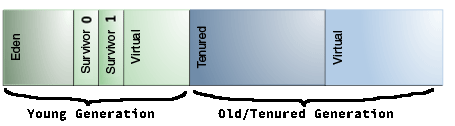
Figure 2: Java 堆中的“新生代”(可再分为三个部分:“Eden/Survivor 0/Survivor 1”空间)和“老年代”
说明 1:图示中的“Virtual”空间是什么呢?用户可以通过参数 -Xms<size> 指定整个 Java 堆的初始大小,通过参数 -Xmx<size> 指定整个 Java 堆的最大大小。图 2 中每一个代中的“Virtual”空间表示 JVM 可以向操作系统申请但还没有真正申请的内存,当 Java 堆的“初始大小”和“最大大小”设置为相同值时,将没有“Virtual”空间,JVM 会把所有可以申请的内存一次申请完。
说明 2:在 Java 8 之前的 HotSpot VM 中,还有一个“永久代(Permanent generation)”,不过在 Java 8 的 HotSpot VM 中永久代已经被废弃了,参见 JEP 122: Remove the Permanent Generation,和 http://www.infoq.com/cn/articles/Java-PERMGEN-Removed
2.1.1. 设置 Java 堆的大小(-Xms<size>/-Xmx<size>)
Java 堆的大小就是新生代和老年代之和。可以通过下面参数控制:
| 参数 | 说明 |
|---|---|
| -Xms<size> | 设置 Java 堆的最小大小(初始大小) |
| -Xmx<size> | 设置 Java 堆的最大大小 |
| -XX:MinHeapFreeRatio=40 | Java 堆中空闲内存比例小于指定值(如 40%)时,JVM 会增大 Java 堆的大小。当 Xms==Xmx 时无效 |
| -XX:MaxHeapFreeRatio=70 | Java 堆中空闲内存比例大于指定值(如 70%)时,JVM 会缩小 Java 堆的大小。当 Xms==Xmx 时无效 |
说明:为了阻止 JVM 增大或缩小 Java 堆内存,在服务器程序中经常设置 Java 堆的最小大小和最大大小为相同值,如 -Xms10g -Xmx10g 。
2.1.2. 设置新生代/老年代的大小(-Xmn<size>)
Java 堆的大小就是新生代和老年代之和。前面介绍了如何设置 Java 堆大小,只要设置了新生代的大小,就能推断出老年代的大小。
| 参数 | 说明 |
|---|---|
| -Xmn<size> | 设置 Java 堆中新生代大小为指定的值 |
| -XX:NewRatio=ratio | 设置新生代和老年代的比率,如 -XX:NewRatio=3 表示新生代和老年代的比率为 1:3 |
| -XX:NewSize=<size> | 设置新生代的最小大小 |
| -XX:MaxNewSize=<size> | 设置新生代的最大大小 |
说明 1:指定 -Xmn512m 相当于同时指定 -XX:NewSize=512m -XX:MaxNewSize=512m 。
说明 2:前面介绍的多种方式都可以设置新生代的大小,只用选取其中的一种即可,如果指定了多种冲突的参数,优先采用 -Xmn<size> 的设置。
2.1.2.1. 设置新生代中 Survivor 空间和 Eden 空间的比例(-XX:SurvivorRatio)
可以用 -XX:SurvivorRatio=ratio 来设置新生代中“一个 Survivor 空间”和 Eden 空间的比率。如 -XX:SurvivorRatio=6 表示新生代中“一个 Survivor 空间”和 Eden 空间的比率为 1:6,由于一共有两个 Survivor 空间,从而 Eden 空间占整个新生代的 6/8,“Survivor 0 空间”占用整个新生代的 1/8,“Survivor 1 空间”占用整个新生代的 1/8。
2.2. 哪些对象可回收
GC 的一个基本问题是“判断哪些对象已死(不会再被使用),可以安全地被回收”。
2.2.1. 引用计数(Reference Counting)算法
引用计数(Reference Counting)算法基本思路:每个对象有一个引用计数器,每当有一个地方引用它时,计数器值就加 1;当引用失效时,计数器值就减 1;任何时刻计数器为 0 的对象就是不可能再被使用的。但引用计数算法有个缺点:它无法解决循环引用的问题。比如对象 objA 和 objB 都有字段 instance,赋值令 objA.instance = objB 和 objB.instance = objA,这就形成一个循环引用,objA 和 objB 的引用计数永远不会为 0。
2.2.2. 可达性分析(Reachability Analysis)算法
Java 语言(还包含 Lisp,C#等语言)采用“可达性分析(Reachability Analysis)”来判断对象是否存活。
可达性分析的基本思路是: 通过一系列称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到 GC Roots 没有任何引用链相连时(即从 GC Roots 到这个对象不可达),则此对象是不可用的。 如图 3 所示。
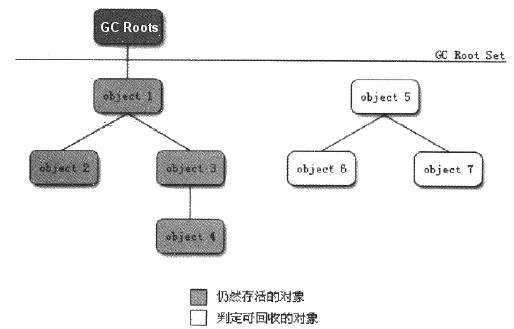
Figure 3: 可达性分析算法判定对象是否可回收
在 Java 语言中,可作为 GC Roots 的对象包括:
- 虚拟机栈中引用的对象;
- 方法区中类静态字段引用的对象;
- 方法区中常量引用的对象;
- 本地方法栈中 JNI(Java Native Interface)引用的对象。
2.3. 垃圾收集算法
2.3.1. 标记-清除算法(Mark-Sweep 算法)
“标记-清除(Mark-Sweep)”是最基础的收集算法。如同它的名字一样,算法分为“标记”和“清除”两个阶段: 先“标记”出所有需要回收的对象,在标记完成后统一“清除”所有被标记的对象。 算法示意图如 4 所示。
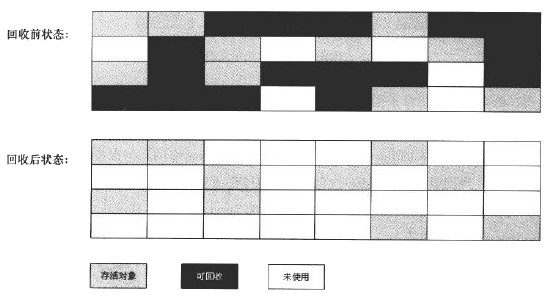
Figure 4: “标记-清除”算法示意图
“标记-清除”算法主要有两点不足:
一个是效率问题,标记和清除两个过程的效率都不高;另一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
2.3.2. 复制算法(Copying 算法),常用于新生代回收
为了解决标记-清除算法的效率问题,一种称为“复制(Copying)”的收集算法出现了, 该算法将内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。 这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将可用内存缩小为了原来的一半,利用率不高。复制算法的执行过程如图 5 所示。
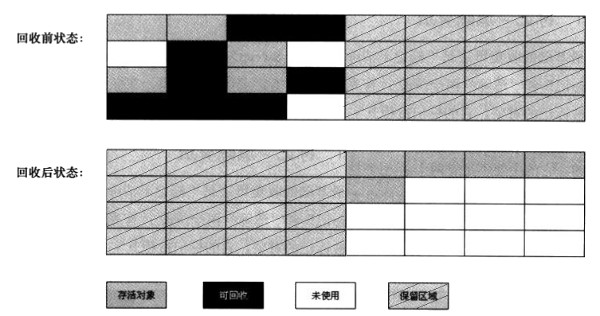
Figure 5: “复制”算法示意图
JVM 一般使用“复制”算法来回收新生代,但它并不按照 1:1 的比例来划分内存空间,而是将内存分为一块较大的 Eden 空间和两块较小的 Survivor 空间, 每次使用 Eden 空间和其中一块 Survivor。当进行回收时,将 Eden 和 Survivor 中还存活着的对象一次性地复制到另外一块 Survior 空间上,最后清理掉 Eden 和刚才用过的 Surivor 空间。 HotSpot 虚拟机默认 Eden 和一个 Surivor 的大小比例是 8:1,也就是每次新生代中可用内存空间为整个新生代容量的 90%,只有 10%的内存会被“浪费”。但回收时,如果存活对象所占内存多于 10%,一个 Surivor 不够用,那怎么办呢?这时,需要使用老年代进行“分配担保”。即: 如果另外一块 Survivor 空间没有足够空间存放上一次新生代收集下来的存活对象时,这些无法存放的对象将直接通过分配担保机制进入老年代。
2.3.3. 标记-整理算法(Mark-Compact 算法)
复制收集算法在对象存活率较高时需要进行较多的复制操作,效率将会变低。另外,如果不想浪费 50%的空间,就需要额外的空间进行分配担保,以应对被使用的内存中所有对象都存活的极端情况。所以,老年代中不适合选择复制收集算法。
“标记-整理”算法是另一种回收算法,它适合于老年代回收。“标记-整理”算法和“标记-清除”算法类似,不过它不是直接对可回收对象进行清理,而是 让所有存活对象都向一端移动 ,然后直接清理掉边界以外的内存。“标记-整理”算法的示意图如图 6 所示。
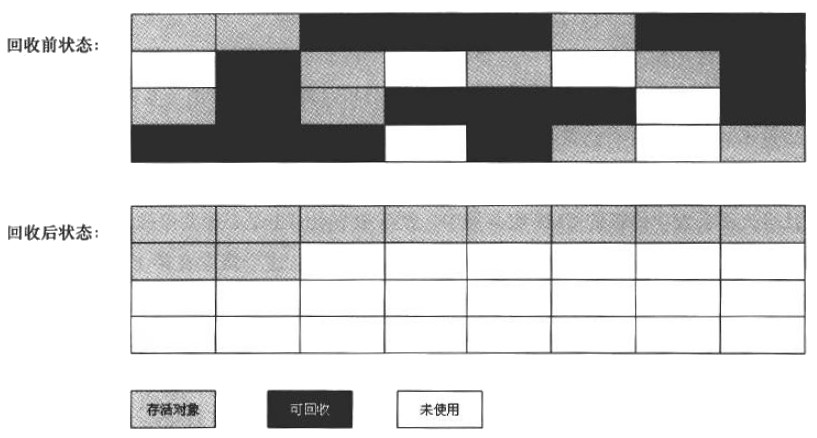
Figure 6: “标记-整理”算法示意图
2.3.4. 分代收集算法(新生代使用复制算法,老年代使用标记-清除或标记-整理算法)
分代收集算法没有什么新思想,只是根据对象存活周期的不同,将内存划分为:新生代,老年代。
因为新生代死亡率高,所以在新生代使用“复制算法”;而在老年代中的对象死亡率低、没有额外空间对它进行分配担保,所以在老年代就用“标记-清除”或者“标记-整理”算法。
2.4. HotSpot 的算法实现
2.4.1. Stop-The-World
进行 GC 时,需要“查找存活对象”,这项工作必须在一个能够确保一致性的快照中进行——这里“一致性”的意思是指整个分析期间整个执行系统看起来就像被冻结在某个时间点上,不能出现分析过程中对象引用关系还有不断变化的情况,否则“查找存活对象”的准确性无法得到保证。这就是导致 GC 进行时必须停顿所有 Java 执行线程(这件事情被称为 Stop-The-World, STW)的一个重要原因。
当 HotSpot VM 位于 Stop-The-World 状态时,Java 线程都处于“Blocked"状态(如果线程正在执行 Native code,则暂时阻止它回到 Java code 中)。
2.4.1.1. 除 GC 外,还有其它事件会导致 STW
除 GC 外,还有其它事件会导致 Stop-The-World,如“撤销偏向锁”等操作,参考:https://plumbr.eu/blog/performance-blog/logging-stop-the-world-pauses-in-jvm
下面是“撤销偏向锁”导致 STW 的实例:
import java.util.concurrent.locks.LockSupport;
import java.util.stream.Stream;
public class BiasedLocksSTW {
private static synchronized void contend() {
LockSupport.parkNanos(100_000);
}
// Run with: -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCDetails
// Notice that there are a lot of stop the world pauses, but no actual garbage collections
// This is because PrintGCApplicationStoppedTime actually shows all the STW pauses
// To see what's happening here, you may use the following arguments:
// -XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1
// It will reveal that all the safepoints are due to biased lock revocations.
public static void main(String[] args) throws InterruptedException {
Thread.sleep(5_000); // Because of BiasedLockingStartupDelay
Stream.generate(() -> new Thread(BiasedLocksSTW::contend))
.limit(10)
.forEach(Thread::start);
}
}
2.4.2. 安全点(Safepoint)
安全点(Safepoint)就是可能发生 Stop-The-World 的地方。
Safepoint 的选定不能太少(这样 GC 不至于要等待太长的时间),也不能过多(它会增加运行时负荷)。一般,在方法调用、循环跳转、异常跳转等指令处会产生 Safepoint。
如何在 GC 发生时让所有线程(不包括执行 JNI 调用的线程)都“跑”到最近的安全点位置停顿下来呢?有两种方案:抢先式中断(Preemptive Suspension)和主动式中断(Voluntary Suspension)。
抢先式中断不需要线程的执行代码主动去配合,在 GC 发生时,首先把所有线程全部中断,如果发现有线程中断的地方不在安全点上,就恢复线程,让它“跑”到安全点上。不过,几乎没有 JVM 采用抢先式中断来暂停线程从而响应 GC 事件。
JVM 中采用主动式中断。主动式中断的思想是当 GC 需要中断线程时,不直接对线程操作,仅仅简单地设置一个标志,各个线程执行时主动去轮询这个标志,发现中断标志为真时就自己中断挂起。轮询标志的地方和安全点是重合的,另外再加上创建对象需要分配内存的地方。
2.4.3. 安全区域(Safe region)
Safepoint 机制保证了程序执行时,在不太长的时间内就会遇到可进入 GC 的 Safepoint。但是,程序“不执行”的时候呢?所谓的程序不执行就是没有分配到 CPU 时间,典型的例子就是线程处于 Sleep 状态或者 Blocked 状态,这时候线程无法响应 JVM 的中断请求,无法运行到 Safe Point 处进行挂起,针对这种情况,可以使用安全区域(Safe Region)进行解决。
Safe Region 是指在一段代码片段之中,对象的引用关系不会发生变化,在这个区域中的任何位置开始 GC 都是安全的。
1、当线程运行到 Safe Region 的代码时,首先标识已经进入了 Safe Region,如果这段时间内发生 GC,JVM 会忽略标识为 Safe Region 状态的线程;
2、当线程即将离开 Safe Region 时,会检查 JVM 是否已经完成 GC,如果完成了,那线程继续运行,否则它就必须等待直到收到可以安全离开 Safe Region 的信号为止。
2.5. GC 调优的目标(“高吞吐率”或“低响应时间”)
一般来说,GC 调优时有两个考量:吞吐率(throughput)和响应时间。
吞吐率=运行用户代码时间/(运行用户代码时间+垃圾收集时间)。比如,虚拟机总共运行了 100 分钟,其中垃圾收集花掉了 1 分钟,那么吞吐率就是 99%。
“高吞吐率”和“低响应时间”是 GC 调优的终极目标,不过鱼和熊掌一般不可兼得。
2.6. 各种垃圾回收器
2.6.1. 基本概念
2.6.1.1. 并行(Parallel)收集器和并发(Concurrent)收集器
并行(Parallel)和并发(Concurrent)这两个名字是并发编程中的概念。和并发编程中的概念不同,在谈论垃圾收集器的上下文中,它们的含义如下:
并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序运行于另一个 CPU 上。
2.6.1.2. Minor GC, Major GC, Full GC
Minor GC 指发生在新生代的 GC。 因为 Java 对象大多都具备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快。
Major GC 指发生在老年代的 GC。 常常伴随有 Minor GC 的发生。Major GC 的速度一般会比 Minor GC 慢 10 倍以上。
Full GC 指 Minor GC 和 Major GC,由于 Major GC 常伴随有 Minor GC 的发生,所以往往不区分 Full GC 和 Major GC。
2.6.2. Serial/Serial Old 收集器
Serial 收集器(复制算法)是新生代收集器,它是单线程收集器。它进行垃圾回收时,必须暂停其他所有的用户工作线程,直到垃圾回收结束。
Serial Old 收集器是 Serial 收集器的老年代版本,它使用“标记-整理”算法。
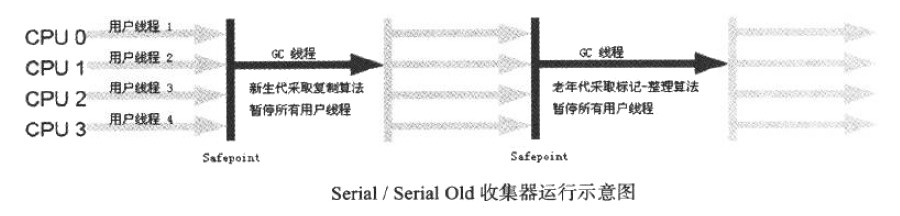
Figure 7: Serial/Serial Old 收集器运行示意图
2.6.3. ParNew 收集器
ParNew 收集器是 Serial 收集器的多线程版本,用于新生代。ParNew 存在的主要意义是与 CMS 收集器(CMS 是第一款 Concurrent 收集器,后文将介绍它)配合工作。
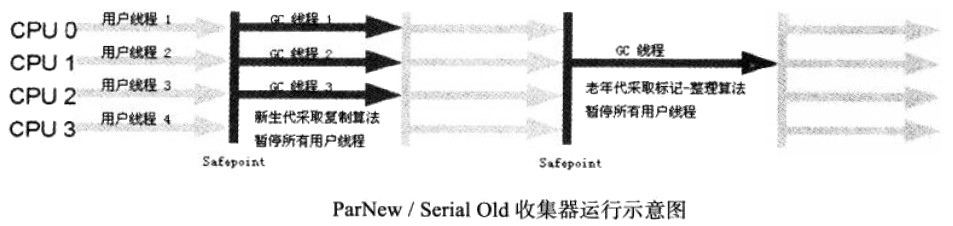
Figure 8: ParNew/Serial Old 收集器运行示意图
2.6.4. Parallel Scavenge/Parallel Old 收集器(它们是“吞吐率优先”收集器)
Parallel Scavenge 收集器是一个多线程的新生代收集器,Parallel Scavenge 收集器的目标是达到一个可控制的吞吐量。Parallel Old 是 Parallel Scavenge 收集器的老年代版本,使用多线程和“标记-整理”算法。
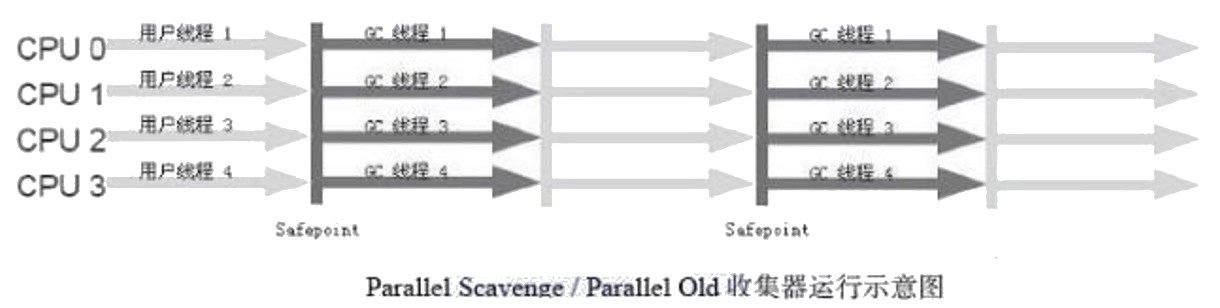
Figure 9: Parallel Scavenge/Parallel Old 收集器运行示意图
2.6.4.1. ParNew VS. Parallel Scavenge
Parallel Scavenge 收集器是一个多线程的新生代收集器,看上去和 ParNew 一样,那它有什么特别之处呢?
ParNew 和 Parallel Scavenge 的不同主要在:
- ParNew 可以和 CMS 收集器配合使用,而 Parallel Scavenge 不能和 CMS 收集器配合使用。
- ParNew 不支持 GC 自适应的调节策略(GC Ergonomics),而 Parallel Scavenge 支持 GC 自适应的调节策略(Parallel Scavenge 收集器有一个参数-XX:+UseAdaptiveSizePolicy,当这个参数打开之后,就不需要手工指定新生代的大小、Eden 与 Survivor 区的比例、晋升老年代对象年龄等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量)。
2.6.5. CMS(Concurrent Mark Sweep)收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的 Java 应用集中在互联网站或者 B/S 系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。CMS 收集器就非常符合这类应用的需求。
CMS 收集器是基于“标记—清除”算法实现的,它的运作过程分为下面几个步骤:
- 初始标记(Initial mark):初始标记是标记一下 GC Roots 能直接关联到的对象,速度很快,需要“Stop The World”。
- 并发标记(Concurrent mark):并发标记是 GC Roots Tracing 的过程。
- 重新标记(Remark):重新标记是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短,这个过程需要“Stop The World”。
- 并发清除(Concurrent sweep):并发地清除可回收对象。
- 重置(Resetting):消除数据结构,为下一次收集做准备。
在 CMS 收集器的步骤中,“并发标记”和“并发清除”这 2 个步骤的耗时比较长,但这两个步骤不会“Stop The Work”,它们都可以与用户线程一起工作,所以,从总体上说,CMS 收集器的内存回收过程与用户线程是并发执行的。图 10 是 CMS 收集器运行示意图。
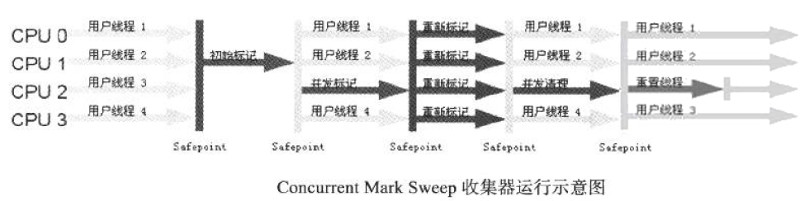
Figure 10: CMS 收集器运行示意图
2.6.5.1. CMS 优缺点
CMS 收集器的主要优点为:并发收集、低停顿。
但 CMS 不完美,它有下面 3 个主要缺点:
CMS 收集器缺点 1: CMS 收集器对 CPU 资源非常敏感(即总吞吐量会降低)。 在并发阶段,它虽然不会导致用户线程停顿,但是会因为占用了一部分线程(或者说 CPU 资源)而导致应用程序变慢,总吞吐量会降低。CMS 默认启动的回收线程数是(CPU 数量+3)/ 4,也就是当 CPU 在 4 个以上时,并发回收时垃圾收集线程不少于 25%的 CPU 资源,并且随着 CPU 数量的增加而下降。但是当 CPU 不足 4 个(譬如 2 个)时,CMS 对用户程序的影响就可能变得很大。
CMS 收集器缺点 2: CMS 收集器无法处理浮动垃圾 ,可能出现“Concurrent Mode Failure”失败而导致另一次 Full GC 的产生。由于 CMS 并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS 无法在当次收集中处理掉它们,只好留待下一次 GC 时再清理掉。这一部分垃圾就称为“浮动垃圾”。
CMS 收集器缺点 3: CMS 是基于“标记-清除”算法实现的收集器,从而容易出现大量不连续的内存碎片 ,当需要分配较大对象时,很可能由于无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
2.6.6. G1(Garbage-First)收集器
G1(Garbage-First)收集器是当今垃圾收集器技术发展的最前沿成果之一。
在 G1 之前的其他收集器进行收集的范围都是整个新生代或者老年代,而 G1 不再是这样。使用 G1 收集器时,Java 堆的内存布局与就与其他收集器有很大差别,它将整个 Java 堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分 Region(不需要连续)的集合。
G1 跟踪各个 Region 里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region(这也就是 Garbage-First 名称的来由)。 这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 G1 收集器在有限的时间内获可以获取尽可能高的收集效率。
参考:http://www.infoq.com/cn/articles/jdk7-garbage-first-collector
2.6.7. 各种垃圾回收器总结
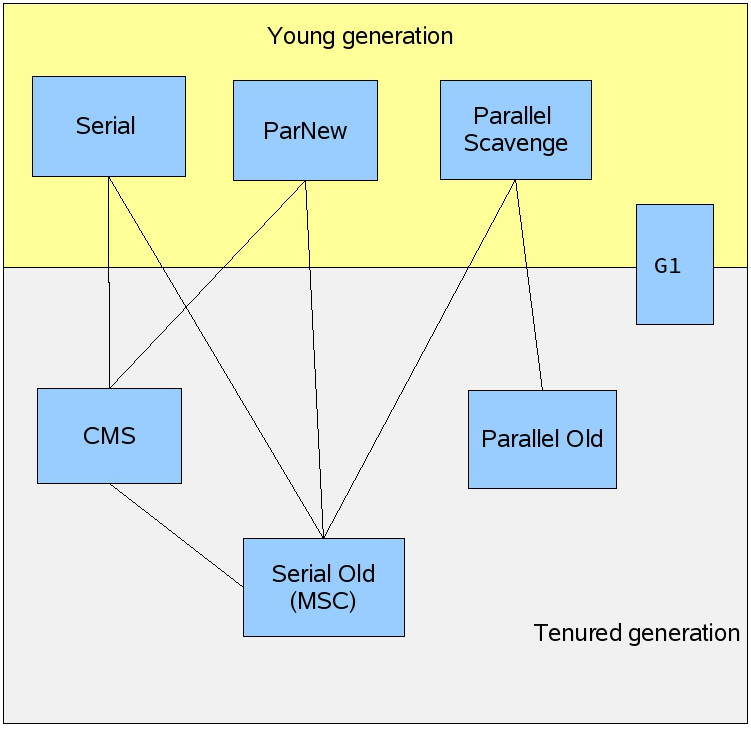
Figure 11: HotSpot VM 中垃圾回收器总结(如果两个收集器存在连线表示可以搭配使用,摘自:https://blogs.oracle.com/jonthecollector/entry/our_collectors)
| 参数 | 含义 |
|---|---|
| -XX:+UseSerialGC | 新生代使用 Serial,老年代使用 Serial Old。这是 client 模式的默认值。 |
| -XX:+UseParallelGC | 新生代使用 Parallel Scavenge,老年代使用 Parallel Old(说明:在 JDK 7u4 之前,指定“-XX:+UseParallelGC ”时老年代会使用 Serial Old)。 |
| -XX:+UseConcMarkSweepGC | 新生代使用 ParNew,老年代使用 CMS+Serial Old(其中 Serial Old 作为 CMS 出现 Concurrent Mode Failure 后的备用收集器)。 |
| -XX:+UseG1GC | 使用 Garbage First (G1)收集器。 |
2.6.8. 如何选择合适的垃圾收集器
一般来说,VM 自动会选择一个合适的垃圾收集器(Java 5 HotSpot 中引入了名为 ergonomics 的 feature,它会根据机器环境自动选择垃圾回收器)。只有当默认行为不满足你的需求时,你才需要定制垃圾回收器。下面是手动选择垃圾收集器时的一些基本指南:
(1) 如果应用程序使用的数据集比较少(少于 100MB),那么选择“-XX:+UseSerialGC”;
(2) 如果运行在单处理机器上,那么选择“-XX:+UseSerialGC”;
(3) 如果更关心“吞吐率”,而对响应时间没有特别要求,则选择“-XX:+UseParallelGC”;
(4) 如果“响应时间”比吞吐率更重要,那么选择“-XX:+UseConcMarkSweepGC”或者“-XX:+UseG1GC”。
参考:
HotSpot Virtual Machine Garbage Collection Tuning Guide, Selecting a Collector
2.7. 理解 GC 日志
不同的 JVM 的 GC 日志格式可能有差异,下面的测试均基于 HotSpot JVM 1.8。
2.7.1. 简单的 gc 日志(-verbose:gc 或者-XX:+PrintGC)
假设有下面 java 程序:
public class FirstSample {
public static void main(String[] args) {
System.out.println("Hello World!");
System.gc(); // 为测试gc而增加的
}
}
运行程序时指定-verbose:gc 或者-XX:+PrintGC 即可打开简单 gc 日志模式。
$ java -verbose:gc FirstSample Hello World! [GC (System.gc()) 2621K->440K(251392K), 0.0005687 secs] [Full GC (System.gc()) 440K->273K(251392K), 0.0029363 secs]
上面实例中,输出了两条 gc 日志,我们以第二条(Full GC)为例说明它的含义:
“Full GC (System.gc())”表示 gc 的类型(gc 日志中,只有同种类型 Full GC 和 GC);
“440K”表示 gc 前的堆大小;
“273K”表示 gc 后的堆大小;
“251392K”表示“当前堆的容量”;
“0.0029363 secs”表示本次 gc 所消耗的时间。
2.7.2. 详细的 gc 日志(-XX:+PrintGCDetails)
还是使用前面的 java 实例程序 FirstSample,如果想得到详细的 gc 日志,可以指定-XX:+PrintGCDetails,如:
$ java -XX:+PrintGCDetails FirstSample Hello World! [GC (System.gc()) [PSYoungGen: 2621K->432K(76288K)] 2621K->440K(251392K), 0.0008369 secs] [Times: user=0.00 sys=0.01, real=0.00 secs] [Full GC (System.gc()) [PSYoungGen: 432K->0K(76288K)] [ParOldGen: 8K->273K(175104K)] 440K->273K(251392K), [Metaspace: 2594K->2594K(1056768K)], 0.0029149 secs] [Times: user=0.01 sys=0.00, real=0.00 secs] Heap PSYoungGen total 76288K, used 655K [0x000000076ab00000, 0x0000000770000000, 0x00000007c0000000) eden space 65536K, 1% used [0x000000076ab00000,0x000000076aba3ee8,0x000000076eb00000) from space 10752K, 0% used [0x000000076eb00000,0x000000076eb00000,0x000000076f580000) to space 10752K, 0% used [0x000000076f580000,0x000000076f580000,0x0000000770000000) ParOldGen total 175104K, used 273K [0x00000006c0000000, 0x00000006cab00000, 0x000000076ab00000) object space 175104K, 0% used [0x00000006c0000000,0x00000006c00446f8,0x00000006cab00000) Metaspace used 2601K, capacity 4486K, committed 4864K, reserved 1056768K class space used 284K, capacity 386K, committed 512K, reserved 1048576K
和前面介绍的简单 gc 日志格式不同,详细 gc 日志格式中还包含了垃圾回收器的具体名字和相关信息。如摘取第二条 gc 日志如下:
Full GC (System.gc()) [PSYoungGen: 432K->0K(76288K)] [ParOldGen: 8K->273K(175104K)] 440K->273K(251392K)
\ /
\_______________________ ______________________________/
\/
这些信息仅在“详细gc日志”中有,在“简单gc日志”中没有
其中[PSYoungGen: 432K->0K(76288K)]的各个部分的含义如下:
PSYoungGen: 垃圾回收器的名字(PSYongGen 表示 Parallel Scavenge 收集器,工作于新生代);
432K:回收前的该内存区域(新生代)已使用容量;
0K:回收后的该内存区域(新生代)已使用容量;
76288K:该内存区域(新生代)的总容量。
[ParOldGen: 8K->273K(175104K)]的各个部分的含义如下:
ParOldGen:垃圾回收器的名字(ParOldGen 表示 Parallel Old 收集器,工作于老年代);
8K:回收前的该内存区域(老年代)已使用容量;
273K:回收后的该内存区域(老年代)已使用容量;
175104K:该内存区域(老年代)的总容量。
注:运行上面程序时没有显式地指定垃圾回收器,但通过 gc 的日志输出,我们可以知道新生代使用的是 Parallel Scavenge 收集器,而老年代使用的是 Parallel Old 收集器。如果我们指定其它垃圾回收器(如使用 CMS),则会得到相应垃圾回收器的 gc 日志。如:
$ java -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails FirstSample Hello World! [Full GC (System.gc()) [CMS: 0K->277K(174784K), 0.0244993 secs] 2798K->277K(253440K), [Metaspace: 2594K->2594K(1056768K)], 0.0245852 secs] [Times: user=0.01 sys=0.02, real=0.02 secs] Heap par new generation total 78720K, used 700K [0x00000006c0000000, 0x00000006c5560000, 0x00000006e9990000) eden space 70016K, 1% used [0x00000006c0000000, 0x00000006c00af218, 0x00000006c4460000) from space 8704K, 0% used [0x00000006c4460000, 0x00000006c4460000, 0x00000006c4ce0000) to space 8704K, 0% used [0x00000006c4ce0000, 0x00000006c4ce0000, 0x00000006c5560000) concurrent mark-sweep generation total 174784K, used 277K [0x00000006e9990000, 0x00000006f4440000, 0x00000007c0000000) Metaspace used 2601K, capacity 4486K, committed 4864K, reserved 1056768K class space used 284K, capacity 386K, committed 512K, reserved 1048576K
2.7.3. 增加 gc 日志的时间信息(-XX:+PrintGCTimeStamps 和-XX:+PrintGCDateStamps)
使用-XX:+PrintGCTimeStamps,可以在 gc 日志前面增加“时间信息(JVM 启动以来的秒数)”。如:
$ java -XX:+PrintGCTimeStamps -verbose:gc FirstSample Hello World! 0.067: [GC (System.gc()) 2621K->408K(251392K), 0.0005662 secs] 0.068: [Full GC (System.gc()) 408K->273K(251392K), 0.0031604 secs]
gc 日志前面的数字 0.067 和 0.068 表示 gc 发生的时间,具体含义是 JVM 启动以来的秒数。
使用-XX:+PrintGCDateStamps,可以在 gc 日志前面增加“日期信息”。如:
$ java -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -verbose:gc FirstSample Hello World! 2016-01-10T23:24:14.121-0800: 0.067: [GC (System.gc()) 2621K->456K(251392K), 0.0007529 secs] 2016-01-10T23:24:14.122-0800: 0.068: [Full GC (System.gc()) 456K->273K(251392K), 0.0030102 secs]
2.7.4. 把 gc 日志输出到文件(-Xloggc:<file>)
默认地,GC 日志时输出到终端的,使用 -Xloggc:<file> 可以把其输出到指定的文件。
说明:-Xloggc:<file>隐式的设置了参数-XX:+PrintGC 和-XX:+PrintGCTimeStamps,但为了以防在新版本的 JVM 中有任何变化,最好还是显式地设置这些参数。
$ java -Xloggc:1.log -XX:+PrintGC -XX:+PrintGCTimeStamps FirstSample Hello World!
1.log 的内容如下:
$ cat 1.log Java HotSpot(TM) 64-Bit Server VM (25.66-b17) for bsd-amd64 JRE (1.8.0_66-b17), built on Oct 6 2015 16:09:13 by "java_re" with gcc 4.2.1 (Based on Apple Inc. build 5658) (LLVM build 2336.11.00) Memory: 4k page, physical 16777216k(568988k free) /proc/meminfo: CommandLine flags: -XX:InitialHeapSize=268435456 -XX:MaxHeapSize=4294967296 -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC 0.068: [GC (System.gc()) 2621K->456K(251392K), 0.0006586 secs] 0.069: [Full GC (System.gc()) 456K->273K(251392K), 0.0030264 secs]
2.8. 用 jstat 查看 GC 状态
使用 jstat(Java Virtual Machine Statistics Monitoring Tool)可以方便查看运行 jvm 的 GC 状态。如:
$ jstat -gc 1448 S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 0.0 9216.0 0.0 9216.0 102400.0 18432.0 150528.0 116736.0 113536.0 103878.8 16256.0 13230.5 11 0.194 0 0.000 0.194
上面输出中:
YGC:从应用程序启动到采样时发生 Young GC 的次数;
YGCT:从应用程序启动到采样时 Young GC 所用的时间(单位秒);
FGC:从应用程序启动到采样时发生 Full GC 的次数;
FGCT:从应用程序启动到采样时 Full GC 所用的时间(单位秒);
GCT:从应用程序启动到采样时用于垃圾回收的总时间(单位秒),它的值等于 YGC+FGC。
3. JIT Compiler
Java 虚拟机字节码可以直接被 JVM 解释执行,但为提高性能,字节码也可以编译为本地机器码后再执行。JVM 中把字节码编译为本地机器码的组件被称为即时编译器(JIT Compiler)。 不过,并不是所有 JVM 都包含即时编译器,如 Sun Classic VM 就只存在解释器(字节码只能解释执行),而没有即时编译器。
3.1. 监视 JIT Compiler (-XX:+PrintCompilation, -XX:+CITime)
可以通过指定“-XX:+PrintCompilation”来监视 JIT Compiler。打开这个选项后,JIT Compiler 的所有编译活动都会产生一条输出日志。
下面是“-XX:+PrintCompilation”选项的测试实例:
$ java -version
java version "1.8.0_66"
Java(TM) SE Runtime Environment (build 1.8.0_66-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.66-b17, mixed mode)
$ cat Test.java
public class Test {
public static void main(String[] args) {
System.out.println("Hello Java.");
}
}
$ javac Test.java
$ java -XX:+PrintCompilation Test
54 1 3 java.lang.String::hashCode (55 bytes)
55 2 3 java.lang.String::charAt (29 bytes)
55 3 3 java.lang.String::length (6 bytes)
57 4 3 java.lang.String::indexOf (70 bytes)
58 5 n 0 java.lang.System::arraycopy (native) (static)
58 6 3 java.lang.String::equals (81 bytes)
58 8 3 java.lang.Object::<init> (1 bytes)
58 9 3 java.lang.Math::min (11 bytes)
58 7 3 java.lang.AbstractStringBuilder::ensureCapacityInternal (16 bytes)
58 10 3 java.lang.String::<init> (82 bytes)
59 11 3 java.lang.AbstractStringBuilder::append (50 bytes)
59 12 3 java.lang.String::getChars (62 bytes)
64 13 1 java.lang.ref.Reference::get (5 bytes)
65 14 3 java.lang.StringBuilder::append (8 bytes)
66 15 3 java.lang.String::indexOf (7 bytes)
Hello Java.
3.1.1. 查看编译所占时间(-XX:+CITime)
如果指定“-XX:+CITime”,则在程序执行结束,退出 JVM 前会输出编译过程所花的时间。
$ java -XX:+PrintCompilation -XX:+CITime Test
55 1 3 java.lang.String::hashCode (55 bytes)
57 2 3 java.lang.String::charAt (29 bytes)
57 3 3 java.lang.String::length (6 bytes)
59 4 3 java.lang.String::indexOf (70 bytes)
59 5 n 0 java.lang.System::arraycopy (native) (static)
59 6 3 java.lang.String::equals (81 bytes)
59 8 3 java.lang.Object::<init> (1 bytes)
59 9 3 java.lang.Math::min (11 bytes)
59 7 3 java.lang.AbstractStringBuilder::ensureCapacityInternal (16 bytes)
60 10 3 java.lang.AbstractStringBuilder::append (50 bytes)
61 11 3 java.lang.String::getChars (62 bytes)
65 12 1 java.lang.ref.Reference::get (5 bytes)
66 13 3 java.lang.StringBuilder::append (8 bytes)
67 14 3 java.lang.String::indexOf (7 bytes)
Hello Java.
Accumulated compiler times (for compiled methods only)
------------------------------------------------
Total compilation time : 0.002 s
Standard compilation : 0.002 s, Average : 0.000
On stack replacement : 0.000 s, Average : nan
Detailed C1 Timings
Setup time: 0.000 s ( 0.0%)
Build IR: 0.001 s (34.9%)
Optimize: 0.000 s ( 2.9%)
RCE: 0.000 s ( 1.2%)
Emit LIR: 0.001 s (38.1%)
LIR Gen: 0.000 s (12.1%)
Linear Scan: 0.001 s (25.2%)
LIR Schedule: 0.000 s ( 0.0%)
Code Emission: 0.000 s (15.8%)
Code Installation: 0.000 s (11.2%)
Instruction Nodes: 355 nodes
Total compiled methods : 13 methods
Standard compilation : 13 methods
On stack replacement : 0 methods
Total compiled bytecodes : 423 bytes
Standard compilation : 423 bytes
On stack replacement : 0 bytes
Average compilation speed: 186900 bytes/s
nmethod code size : 6656 bytes
nmethod total size : 11304 bytes
3.2. 两种 JIT Compiler(C1/C2 编译器,对应 client/server 模式)
The HotSpot VM has two JIT compilers. To HotSpot engineers, the JIT compilers are known as “C1”(the -client JIT compiler) and “C2”(the -server JIT compiler).
当希望程序启动更快时,建议使用 C1 编译器(即指定为 client 模式);当程序用于后台服务器时建议 C2 编译器(即指定为 Server 模式)。
4. Tips
4.1. 抛出 NullPointerException,但无 stack 信息(-XX:-OmitStackTraceInFastThrow 可保留)
有时,Java 程序抛出 java.lang.NullPointerException,但没有 stack 信息。
下面是一个例子:
// 下面例子改自 http://jawspeak.com/2010/05/26/hotspot-caused-exceptions-to-lose-their-stack-traces-in-production-and-the-fix/
// 原例子中迭代次数是100000,在Java 8中无法重现问题(总是输出2)
// 把迭代次数增大10倍,即改为1000000 后,重现了问题(开始输出2,后面输出0)
public class NpeThief {
public void callManyNPEInLoop() {
for (int i = 0; i < 1000000; i++) {
try {
((Object)null).getClass();
} catch (Exception e) {
// This will switch from 2 to 0 (indicating our problem is happening)
System.out.println(e.getStackTrace().length);
}
}
}
public static void main(String... args) {
NpeThief thief = new NpeThief();
thief.callManyNPEInLoop();
}
}
运行上面程序,你可能看到程序的输出由2变为了0(在我测试环境下,前115714行为2,后884286行为0)。如:
$ javac NpeThief.java && java -classpath . NpeThief 2 2 ...... 0 0 0 ......
这是由于编译器可能优化掉stack信息(这会增大定位问题的难度),使用选项 -XX:-OmitStackTraceInFastThrow 可以禁止编译器的这项优化功能。 如:
$ javac NpeThief.java && java -XX:-OmitStackTraceInFastThrow -classpath . NpeThief 2 2 ......
你会看到它会输出1000000行2(不会输出0,stack信息没有被优化掉)。
参考:https://stackoverflow.com/questions/2411487/nullpointerexception-in-java-with-no-stacktrace