C++
Table of Contents
- 1. C++ 简介
- 2. 变量和基本类型
- 3. 函数
- 4. 类的基本概念
- 5. 类的复制控制
- 6. 重载操作符与转换
- 7. 面向对象编程
- 8. 模板与泛型编程
- 9. 异常处理
- 10. STL
- 10.1. STL containers
- 10.2. STL iterators
- 10.3. STL algorithms
- 10.4. 智能指针(Smart Pointer)
- 11. 其它
- 12. 不常用技术
- 13. C++ Tips
- 14. C++ 新特性
1. C++ 简介
C++ was developed by Bjarne Stroustrup at Bell Labs since 1979, as an extension of the C language as he wanted an efficient and flexible language similar to C, which also provided high-level features for program organization.
In 1983, it was renamed from C with Classes to C++.
参考:
最权威的书籍:The C++ Programming Language, by Bjarne Stroustrup
比较好的入门书籍:C++ Primer, by Stanley B. Lippman (本文主要摘自该书)
深入理解 C++11
Scott Meyer 的 Effective 系列书籍:《Effective C++》,《More Effective C++》,《Effective STL》,《Effective Modern C++, 2014》
Herb Sutter 的 Exceptional 系列书籍:《Exceptional C++》,《More Exceptional C++》,《Exceptional C++ Style》,其在线版本可参考 Guru of the Week: http://www.gotw.ca/gotw/
Inside the C++ Object Model, by Stanley B. Lippman, 1996.
在线参考资料:
Tutorials to help you master C++: http://www.learncpp.com/
Standard C++ Library reference: http://www.cplusplus.com/reference/
C++ reference: http://en.cppreference.com/w/
1.1. C++ Standardization
C++ 标准如表 1 所示。
| Year | C++ Standard | Informal name | Note |
|---|---|---|---|
| 1998 | ISO/IEC 14882:1998 | C++98 | first standardization |
| 2003 | ISO/IEC 14882:2003 | C++03 | bug fixes only |
| 2011 | ISO/IEC 14882:2011 | C++11, C++0x | many new features |
| 2014 | ISO/IEC 14882:2014 | C++14, C++1y | minor release |
| 2017 | ISO/IEC 14882:2017 | C++17, C++1z | minor release |
| 2020 | to be determined | C++20, C++2a |
参考:
主流编译器对各个 C++ 版本的支持情况:https://en.cppreference.com/w/cpp/compiler_support
The C++ Standards Committee - ISOCPP: http://www.open-std.org/jtc1/sc22/wg21/
Last publicly available Committee Draft of "ISO/IEC IS 14882 – Programming Languages – C++": http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2011/n3242.pdf
First draft after the C++11 standard, contains the C++11 standard plus minor editorial changes: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2012/n3337.pdf
1.1.1. C++ 标准中预定义的宏
下面的总结基于 C++11。
预定义的宏:
__cplusplus __DATE__ __FILE__ __LINE__ __STDC_HOSTED__ __TIME__
还有一些由实现决定:
__STDC__ __STDC_MB_MIGHT_NEQ_WC__ __STDC_VERSION__ __STDC_ISO_10646__ __STDCPP_STRICT_POINTER_SAFETY__ __STDCPP_THREADS__
参考:ISO&IEC 14882 C++11, 16.8 Predefined macro names
C++11 从 C99 中引入了函数名相关的变量
__func__
参考:ISO&IEC 14882 C++11, 8.4.1 In general
1.2. C++ ABI
参考:
C++ ABI Summary: http://mentorembedded.github.io/cxx-abi/
ABI Policy and Guidelines: http://gcc.gnu.org/onlinedocs/libstdc++/manual/abi.html
2. 变量和基本类型
C++ 支持 C 中的各种基本类型,新增了引用类型。此外,可通过类来自定义数据类型。
2.1. 引用类型(对象别名)
引用就是对象的另一个名字。在实际程序中,引用主要用作函数的形式参数,使用引用可“避免实参到形参的拷贝”,函数体内对引用形参的修改直接反映到实参中。
可以通过在变量名前添加“&”符号来定义引用。引用必须用与该引用同类型的对象初始化。
当引用初始化后,只要该引用存在,它就保持绑定到初始化时指定的对象。不可能将引用绑定到另一个对象。
int ival = 1024; int &refVal = ival; // ok int &refVal2; // error: a reference must be initialized int &refVal3 = 10; // error: initializer must be an object
函数体内对引用形参的修改直接反映到实参中。如:
#include <iostream>
using namespace std;
void fun1(int &num) { // 函数形参为引用
num += 1; // 函数体内对引用的修改会反映到实参
}
void swap(int &num1, int &num2) { // 函数形参为引用
int temp = num1; // 函数体内对引用的修改会反映到实参
num1 = num2;
num2 = temp;
}
int main() {
int a = 100;
int b = 200;
fun1(a);
cout << a << endl; // 输出 101
swap(a, b);
cout << a << " " << b << endl; // 输出 200 101
return 0;
}
注:C++11 中新增加了一种引用:“右值引用(Rvalue reference)”,我们将在节 5.5.2 中讨论它。严格来说,当我们使用术语“引用(reference)”时,指的其实是“左值引用”(即本节介绍的这种引用)。
2.1.1. 通过引用传递数组时,数组的大小是参数的一部分
和其他类型一样,数组形参可声明为数组的引用。如果形参是数组的引用,编译器不会将数组实参转化为指针,而是传递数组的引用本身。在这种情况下,数组大小成为形参与实参类型的一部分,编译器检查数组实参的大小与形参的大小是否匹配。
void printValues(int (&arr)[10]) { /*......*/ } // &arr两边的圆括号是必需的,因为下标操作符具有更高的优先级
int main() {
int k[10] = {0,1,2,3,4,5,6,7,8,9};
printValues(k); //ok: argument is an array of 10 ints
int i=0, j[2]={0, 1};
printValues( &i ); //error: argument is not an array of 10 ints
printValues( j ); //error: argument is not an array of 10 ints
return 0;
}
参考:《C++ Primer 第四版》7.2 节
2.2. 变量的初始化方法(复制初始化和直接初始化)
变量在定义的同时,可以为对象提供初始值。C++ 支持两种初始化变量的形式:复制初始化(copy-initialization)和直接初始化(direct-initialization)。
复制初始化语法用等号(=),直接初始化则把初始化式放在括号中。如下面两种用法变量 ival 都被初始化为 1024。
int ival = 1024; // copy-initialization int ival(1024); // direct-initialization
对于内置基本类型,复制初始化和直接初始化是一样的。
当用于类类型对象时,直接初始化直接调用与实参匹配的构造函数;复制初始化首先使用指定构造函数创建一个临时对象,然后用复制构造函数将那个临时对象复制到正在创建的对象中。
2.2.1. Uniform Initialization(Brace Initialization)
在 C++98 中,我们可以使用花括号 {} 对数组元素进行初始化,比如:
int arr[5] = {0};
string s[] = {"foo", "bar"};
不过,标准库中 vector 、 map 等容器、用户自定义类型却无法享受这样便利的初始化方式。如 C++98 并不支持下面形式的初始化:
vector<int> i1 = {1, 3, 4}; // C++98中报错
vector<string> v1 = { "foo", " bar" }; // C++98中报错
在 C++11 中,增加了对上面初始化形式的支持,称为“Uniform Initialization(或者 Brace Initialization)”,花括号 {} 称为初始化列表(“Initializer List”)。 而且其中的等号是可以省略的,如:
// 下面是使用Initializer List进行变量初始化的例子
string s1[] = {"foo", "bar"}; // C++98中合法,C++11中合法
string s2[] {"foo", "bar"}; // C++98中报错,C++11中合法(和上一样,只是省略了等号)
vector<int> i1 = {1, 3, 4}; // C++98中报错,C++11中合法
vector<int> i2 {1, 3, 4}; // C++98中报错,C++11中合法(和上一样,只是省略了等号)
vector<string> v1 = { "foo", " bar" }; // C++98中报错,C++11中合法
vector<string> v2 { "foo", " bar" }; // C++98中报错,C++11中合法(和上一样,只是省略了等号)
map<int, float> m1 = {{1, 1.0f}, {2, 2.0f}}; // C++98中报错,C++11中合法
map<int, float> m2 {{1, 1.0f}, {2, 2.0f}}; // C++98中报错,C++11中合法(和上一样,只是省略了等号)
2.2.1.1. 自定义类型使用 Initializer List
用户自定义类型也可以使用 Initializer List 对其进行初始化,方法是:声明一个以 initializer_list<T> 模板类为参数的构造函数。例子如下:
// 下面例子摘自:《深入理解C++11》3.5.1 初始化列表
#include <iostream>
#include <vector>
#include <initializer_list>
enum Gender {boy, girl};
class People {
public:
People(std::initializer_list<std::pair<std::string, Gender>> l) { //initializer_list的构造函数
for (auto i = l.begin(); i != l.end(); ++i) {
data.push_back(*i);
}
}
private:
std::vector<std::pair<std::string, Gender>> data;
};
int main() {
People ship2002 = {{"Jack", boy}, {"Kitty", girl}}; // 使用Initializer List初始化自定义类型
return 0;
}
2.2.1.2. 函数形参使用 Initializer List
前一节介绍了构造函数参数使用 Initializer List 的情况,这一节介绍一下普通函数参数列表使用 Initializer List 的情况。实例代码:
#include <iostream>
#include <initializer_list>
using namespace std;
void fun1(initializer_list<int> iv) { // 这里定义了一个可以接受初始化列表的函数
for (auto it = iv.begin(); it != iv.end(); ++it) {
cout << *it << endl;
}
}
int main() {
fun1({1, 2}); // 使用Initializer List作为参数调用函数
fun1({}); // 使用Initializer List(空)作为参数调用函数
return 0;
}
2.2.1.3. 函数返回值使用 Initializer List
初始化列表可以用于函数返回的情况。返回一个初始化列表,通常会导致构造一个临时变量,临时变量的类型是依据函数返回类型的。比如:
vector<int> fun1() {
return {1, 3};
}
deque<int> fun2() {
return {3, 5};
}
上面例子中,fun1 的返回值就是以 vector<int> 列表初始化构造函数而构造的,而 fun2 的返回值就是以 deque<int> 列表初始化构造函数构造的。
2.2.1.4. 防止类型收窄(使用 Initializer List 的优点)
使用列表初始化可以防止类型收窄。所谓类型收窄是指一些使得数据变化或者精度丢失的隐式类型转换。下面是类型收窄的典型情况:
- 从浮点数隐式地转换为整数。例如
int a = 1.2中 a 实际保存的值是整数 1。 - 从高精度的浮点数转换为低精度的浮点数,例如从
long double隐式地转换为double,或者从double转换为float,如果这些转换导致精度降低,都可以视为类型收窄。 - 从整型转换为浮点型,如果整型大到浮点数无法精确地表示,则也是类型收窄。
- 从较宽的整型转换为较窄的整形,例如
unsigned char x = 1024中 2014 显然不能被一般长度为 8 位的unsigned char所容纳,所以这也是类型收窄。
发生类型收窄通常是危险的。 在 C++11 中,使用初始化列表进行初始化时,编译器会检查是否会发生类型收窄,并在发生类型收窄时提示错误,这增加了类型使用的安全性。
int x = 1024;
char a = x; // 类型收窄,这是普通的变量初始化,可以通过编译
char b = {x}; // 类型收窄,这是使用初始化列表进行初始化,无法通过编译
2.3. 变量的初始化规则
当定义没有初始化式的变量时,系统按下面规则帮我们初始化变量:
规则一:内置类型变量是否自动初始化取决于变量定义的位置。在函数体外定义的变量都初始化为它们的默认值,在函数体里定义的内置类型变量不进行自动初始化。
规则二:类类型变量在没有提供初始化式时,不管在哪里定义,总是使用默认构造函数进行初始化。
注 1:数组同样遵循上面描述的规则,即如果数组元素是内置类型,则在函数体外定义时会初始化为它们的默认值,在函数体内定义时不会初始化;如果数组元素是类类型,则不管在哪里定义默认构造函数都会被使用。
注 2:初始化时的默认值是什么呢?
基本类型的默认值都是 0。
参考:Section 6.7.8 Initialization of C99 standard (n1256)
- if it has pointer type, it is initialized to a null pointer;
- if it has arithmetic type, it is initialized to (positive or unsigned) zero;
- if it is an aggregate, every member is initialized (recursively) according to these rules;
- if it is a union, the first named member is initialized (recursively) according to these rules.
2.3.1. 函数体内的内置类型变量不会自动初始化
上面规则一中提到:函数体内的内置类型变量不会自动初始化。
为什么这样设计呢?这是基于效率的考虑。
char buf[100*1024]; //函数体内这样的大buffer如果自动初始化,会影响性能。
2.4. constexpr 变量和常量表达式
常量表达式(const expression)是指值不会改变并且在编译过程就能得到计算结果的表达式。
在一个复杂系统中,很难分辨一个初始值到底是不是常量表达式。当然可以定义一个 const 变量并所它的初始值设为我们认为的某个常量表达式,但在实际使用时,尽管要求如此却常常发现初始值并非常量表达式的情况。
C++11 标准中,允许将变量声明为 constexpr 类型以便由编译器来验证变量的值是否是一个“常量表达式”。声明为 constexpr 的变量一定是一个常量,而且必须用常量表达式初始化:
constexpr int mf = 20; // 20是常量表达式 constexpr int limit = mf + 1; // mf + 1 是常量表达式 constexpr int sz = size(); // 仅当size()是一个constexpr函数时才是一条正确的声明语句
注:关于 constexpr 函数,后文将介绍。
最优实践: 如果你认定变量是一个常量表达式,那就把它声明为 constexpr 类型。
2.4.1. 字面值类型
常量表达式的值需要在编译时就得到计算,因此对声明 constexpr 时用到的类型必须有所限制。由于这些类型一般比较简单,值也显而易见,容易得到,我们把它们称为“字面值类型”(literal type)。
内置算术类型、引用和指针等都是字面值类型,而 IO 库、string 类等不属于字面值类型。用户自定义类满足一定条件时,可以是字面值类型。
2.4.2. 指针和 constexpr
在 constexpr 声明中如果定义了一个指针,限定符 constexpr 仅对指针有效,与指针所指的对象无关:
const int *p = nullptr; // p是一个指向整型常量的“指针” constexpr int *q = nullptr; // q是一个指向整数的“常量指针”
2.5. 处理类型
2.5.1. 类型别名新方式(using)
2.5.2. decltype 类型指示符
C++11 中引入了类型说明符 decltype ,它的作用是选择并返回操作数的数据类型。在此过程中,编译器分析表达式并得到它的类型(即在编译期间确定类型),却不实际计算表达式的值:
decltype(f()) sum = x; // sum的类型就是函数f的返回类型
上面例子中,编译器并不实际调用函数 f 。
如果 decltype 使用的表达式不是一个变量,则 decltype 返回表达式结果对应的类型。如果表达式的内容是解引用操作,则 decltype 将得到引用类型。如:
int main() {
int i = 42, *p = &i, &r = i;
decltype(r) a; // 报错,r是引用,所以a必须初始化
decltype(r) a2 = i; // 正确
decltype(r + 0) b; // 正确,表达式 r+0 不是变量,它的结果是具体值,而非引用
decltype(*p) c; // 报错,表达式内容是解引用操作,将得到引用类型,c必须初始化
decltype(*p) c2 = i; // 正确
decltype(*p + 0) d; // 正确,表达式 *p+0 的结果是int
return 0;
}
2.5.2.1. decltype 推导四规则
大多数时候, decltype 的使用看起来非常容易,但有时我们也会落入一些令人疑惑的陷阱。如:
int i; decltype(i) a; // a类型为int decltype((i)) b; // 无法通过编译,事实上b类型为引用类型int &,所以需要初始化
上面例子中,仅多了一对圆括号, decltype 所推导出的类型居然发生了变化(变为了引用类型)。
C++11 中 decltype 推导返回类型的规则比我们想象的要复杂。编译器将依次判断以下四规则:
1、如果 e 是一个没有带括号的标记符表达式(id-expression)或者类成员访问表达式,那么 decltype(e) 就是 e 所命名的实体的类型。此外,如果 e 是一个被重载的函数,则会导致编译时错误。
2、否则,假设 e 的类型是 T ,如果 e 是一个将亡值(xvalue),那么 decltype(e) 为 T&& 。
3、否则,假设 e 的类型是 T ,如果 e 是一个左值,那么 decltype(e) 为 T& 。
4、否则,假设 e 的类型是 T ,则 decltype(e) 为 T 。
这里我们要解释一下标记符表达式(id-expression)。基本上,所有除去关键字、字面量等编译器需要使用的标记之外的程序员自定义的标记(token)都可以是标记符(identifier)。而单个标记符对应的表达式就是标记符表达式。比如程序员定义了:
int arr[4];
那么 arr 是一个标记符表达式,而 arr[3] + 0, arr[3] 等,则都不是标记符表达式。
回到前面介绍的例子 decltype((i)) b 中,记 e=(i) ,由于 (i) 不是一个标记符表达式,但却是一个左值表达式(可以有具名的地址),因此,按照 decltype 推导规则 3,其类型应该是 int & 。
上面 4 条规则看起来比较复杂,但在实际应用中, decltype 类型推导规则中最容易引起迷惑的只有规则 1 和规则 3。我们可以通过下面代码再加深一直理解。
#include <iostream>
using namespace std;
void Overloaded(int);
void Overloaded(char); // 重载的函数
int && RvalRef();
const bool Func(int);
int main() {
int i = 4;
int arr[5] = {0};
int *ptr = arr;
struct S { double d; } s;
// 规则1:单个标记符表达式以及访问类成员,推导为本类型
decltype(arr) var1; // int[5], 标记符表达式
decltype(ptr) var2; // int*, 标记符表达式
decltype(s.d) var4; // double, 成员访问表达式
decltype(Overloaded) var5; // 无法通过编译,是个重载的函数
// 规则2:将亡值,推导的类型的右值引用
decltype(RvalRef()) var6 = 1; // int &&
// 规则3:左值,推导为类型的引用
decltype(true ? i : i) var7 = i; // int &, 三元运算符,这里返回一个i的左值
decltype((i)) var8 = i; // int &, 带圆括号的左值
decltype(++i) var9 = i; // int &, ++i返回i的左值
decltype(arr[3]) var10 = i; // int &, []操作返回左值
decltype(*ptr) var11 = i; // int &, *操作返回左值
decltype("lval") var12 = "lval"; // const char(&) [9], 字符串字面常量为左值
// 规则4:以上都不是,推导为本类型
decltype(1) var13; // int, 除字符串外字面常量为右值
decltype(i++) var14; // int, i++返回右值
decltype((Func(1))) var15; // const bool, 圆括号可以忽略
return 0;
}
参考:《深入理解 C++》4.3.3 节
2.6. 强制类型转换(cast)
C++ 中有下面几种形式的强制类型转换:
static_cast <new_type> (expression) const_cast <new_type> (expression) reinterpret_cast <new_type> (expression) dynamic_cast <new_type> (expression)
它们的应用场景如下
(1) static_cast 的应用场景:Static cast is used to cast between the integer types. 'e.g.' char->long, int->short etc. Static cast is also used to cast pointers to related types, for example casting void* to the appropriate type.
(2) const_cast 的应用场景:const_cast(expression) is used to add/remove const attribute of a variable.
(3) reinterpret_cast 的应用场景:reinterpret_cast 强制转换过程仅仅只是比特位的拷贝,使用时需要特别谨慎。比如,将指针或引用转换为一个足够长的整型、将整型转换为指针或引用类型。
(4) dynamic_cast 的应用场景:Dynamic cast is used to convert pointers and references at run-time, generally for the purpose of casting a pointer or reference up or down an inheritance chain (inheritance hierarchy).
说明:前三种转换都在“编译时”完成,只有 dynamic_case 是在“运行时”处理的。
2.6.1. Traditional Type-casting
C++ 还支持旧式强制转换,旧式强制转换符号有下面两种形式:
(new_type) expression // C-language-style cast notation new_type (expression) // Function-style cast notation
3. 函数
3.1. 参数传递
C++ 中,函数的非引用类型的参数是“值传递”(会复制参数),引用类型的参数是“引用传递”(不会复制参数)。
3.1.1. 非指针非引用的普通形参
对于非指针非引用的普通形参,可以向非 const 形参传递 const 或非 const 实参,也可以向 const 形参传递 const 或非 const 实参。
下面程序能正常编译(没有任何警告信息)和运行:
#include<stdio.h>
void fun1(int i) {
printf("%d\n", i);
}
void fun2(const int i) {
printf("%d\n", i);
}
int main()
{
int a = 1;
const int b = 2;
fun1(a);
fun1(b);
fun2(a);
fun2(b);
}
3.1.2. 指针形参(尽量用 const 指针)
在 C++ 中,可以将指向 const 对象的指针初始化为指向非 const 对象,但不可以让指向非 const 对象的指针指向 const 对象。
下面程序无法用 C++ 编译器编译:
#include<stdio.h>
void fun1(int *ip) {
printf("%d\n", *ip);
}
void fun2(const int *ip) { /* 不能通过ip修改指针所指向的对象 */
printf("%d\n", *ip);
}
int main()
{
int a = 1;
const int b = 2;
int * ap = &a;
const int * bp = &b;
fun1(ap);
fun1(bp); // 用C++编译器会提示编译错误(invalid conversion from 'const int*' to 'int*'),用C编译器可成功编译(仅有警告)
fun2(ap);
fun2(bp);
}
说明:上面的行为和 C 是不兼容的,用 C 编译器可以成功编译上面程序,仅会提示警告信息。
总结:const 指针形参(如上例中 fun2 所示)的使用更加方便,可以接受 const 或非 const 指针实参。
3.1.3. 引用形参(尽量用 const 引用)
引用形参直接关联到其所绑定的对象,而并非这些对象的副本。这可以避免对参数的复制。
如,下面函数比较两个 string 的长短,由于 string 可能很长,我们可以用引用来避免参数的复制。
bool isShorter(const string &s1, const string &s2) {
return s1.size() < s2.size();
}
非 const 引用形参与 const 引用形参在接受参数时有区别,下面程序无法用 C++ 编译器正常编译:
#include<stdio.h>
void fun1(int &i) {
printf("%d\n", i);
}
void fun2(const int &i) { /* 由于引用参数由const修饰,故函数内不能修改i */
printf("%d\n", i);
}
int main()
{
int a = 1;
const int b = 2;
fun1(a);
fun1(b); //编译错误(invalid initialization of reference of type 'int&' from expression of type 'const int')
fun2(a);
fun2(b);
}
总结:const 引用形参(如上例中 fun2 所示)的使用更加方便,可以接受 const 或非 const 对象;非 const 引用形参只能与完全同类型的非 const 对象关联
3.1.4. 可变形参(省略符形参)
省略符形参是为了便于 C++ 程序访问某些特殊的 C 代码而设置的。通常,省略符形参不应用于其它目的。特别应该注意的是,大多数类类型的对象在传递给省略符形参时都无法正确拷贝。
省略符形参只能出现在形参列表的最后一个位置,它的形式无外乎以下两种:
void foo(parm_list, ...); void foo(...);
3.2. 默认实参
默认实参是通过给形参提供明确的初始化表达式来指定的。
注:一个形参具有默认实参,则它后面的所有形参都必须有默认实参。
#include<stdio.h>
void fun1(int i=0, int j=1); //声明时指定了默认实参
int main() {
fun1(); //output: i=0, j=1
fun1(4); //output: i=4, j=1
fun1(7,8); //output: i=7, j=8
return 0;
}
void fun1(int i, int j) { //声明时指定了默认实参,定义时不能再指定!
printf("i=%d, j=%d\n", i, j);
}
注:一般地,我们仅在声明时指定默认实参(这种情况下定义时不能再指定)。也可以在声明时不指定默认实参,而仅在定义时指定默认实参。但这样有个限制——只有在包含该函数定义的源文件中默认实参才有效,所以不推荐这么做。
#include<stdio.h>
void fun1(int i, int j); //声明时不指定默认实参
void fun1(int i=0, int j=1) { //定义时指定默认实参,只有在包含该函数定义的源文件中默认实参才有效
printf("i=%d, j=%d\n", i, j);
}
int main() {
fun1(); //output: i=0, j=1
fun1(4); //output: i=4, j=1
fun1(7,8); //output: i=7, j=8
return 0;
}
3.2.1. 默认实参可指定为函数
函数的默认实参可以是表达式或另一个函数,在调用函数时才求解该表达式或调用另一个函数。
下面演示一个不正确的用法:fun1 有个默认实参为 fun2,而 fun2 又调用 fun1,形成了死循环,会导致程序异常终止。
#include<stdio.h>
int count;
int fun2();
void fun1(int i=0, int j=fun2()) { //fun1()中参数j的默认实参为函数fun2(),在调用fun1()时会调用fun2()
printf("i=%d, j=%d\n", i, j);
}
int fun2() { //fun2()中又调用了fun1(),这样形成了一个死循环!
printf("call %d times\n", count++);
fun1();
return 1;
}
int main() {
fun1();
return 0;
}
3.3. 函数返回值
3.3.1. 值是如何被返回的
返回一个值的方式和初始化一个变量或形参的方式完全一样:返回的值用于初始化调用点的一个临时量,该临时量就是函数调用的结果。
例如:
string append_xxx(const string &str) {
return str + "xxx";
}
该函数的返回类型是 string ,意味着返回值将被复制到调用点。
同其他引用类型一样,如果函数返回引用,则该引用仅是它所引对象的一个别名。例如:
const string & shorterString(const string &s1, const string &s2) {
return s1.size() <= s2.size() ? s1 : s2;
}
该函数的返回类型是 const string 的引用,函数返回时不会复制字符串。
3.3.2. 不要返回局部对象的引用或指针
函数完成后,它所占用的存储空间也随之被释放掉。因此,函数终止意味着局部变量的引用将指向不再有效的内存区域:
// 下面代码是错误的:这个函数试图返回局部对象的引用
const string &manip() {
string ret;
// 以某种方式改变一下变量ret
if (!ret.empty()) {
return ret; // 错误:返回局部对象的引用!
} else {
return "Empty"; // 错误:"Empty"是一个局部临时量
{
}
上面的两条 return 语句都将返回未定义的值,也就是说,试图使用 manip 函数的返回值将引发未定义的行为。对于第一条 return 语句来说,显然它返回的是局部对象的引用。在第二条 return 语句中,字符串字面值转换成一个局部临时 string 对象,对于 manip 来说,该对象和 ret 一样都是局部的。当函数结束时临时对象占用的空间也就随之释放掉了,所以两条 return 语句都指向了不再可用的内存空间。
同样,返回局部对象的指针也是错误的。一旦函数完成,局部对象被释放,指针将指向一个不存在的对象。
3.3.3. 返回引用得到左值,返回其它类型得到右值
函数的返回类型决定函数调用是否是左值。 调用一个返回引用的函数得到左值,其它返回类型得到右值。 可以像使用其他左值那样使用返回引用的函数的调用,特别是,我们能为返回类型是非常量引用的函数的结果赋值,如:
1: #include <iostream> 2: #include <string> 3: 4: using namespace std; 5: 6: char &get_val(string &str, string::size_type ix) { 7: return str[ix]; // get_val假设索引值是有效的 8: } 9: 10: int main() { 11: string s("a value"); 12: cout << s << endl; // 输出 a value 13: get_val(s, 0) = 'A'; // 将 s[0] 的值改为 A 14: cout << s << endl; // 输出 A value 15: return 0; 16: }
上面代码中第 13 行,把函数调用放在赋值语句的左侧可能看起来有点奇怪,但其实这没什么特别的。返回值是引用,因此调用是个左值,和其他左值一样它也能出现在赋值运算符的左侧。
如果返回类型是常量引用,我们不能给调用的结果赋值。
3.3.4. 返回数组指针
因为数组不能被拷贝,所以函数不能返回数组。不过,函数可以返回数组的指针或引用。
如何声明一个函数接收一个整数参数,返回值是“含有 10 个整数的数组”的指针呢?
方式一:
int (*fun1(int i))[10];
我们来分别一下上面的声明:
1、 fun1(int i) 表示调用 fun1 函数时需要一个 int 类型的实参。
2、 (*fun1(int i)) 表示我们可以对函数调用结果执行解引用操作。
3、 (*fun1(int i))[10] 表示解引用 func1 的调用将得到一个大小是 10 的数组。
4、 int (*fun1(int i))[10] 表示数组中的元素是 int 类型。
方式二(定义类型别名之 typedef):
typedef int arrT[10]; arrT* fun1(int i);
方式三(C++11 新增,定义类型别名这 using):
using arrT = int[10]; arrT* fun1(int i);
方式四(C++11 新增,使用尾值返回类型):
auto fun1(int i) -> int(*)[10];
3.3.5. 尾值返回类型
如果一个函数模板的返回类型依赖于实际的入口参数类型,那么该返回类型在模板实例化之前可能都无法确定,这样的话我们在定义该函数模板时就会遇到麻烦。比如:
template<typename T1, typename T2>
decltype(t1 + t2) Sum(T1 & t1, T2 & t2) { // 编译器报错,提示t1和t2未定义
return t1 + t2;
}
上面的写法看上去不错,但对编译器来说有些小问题。编译器在推导 decltype(t1 + t2) 时,表达式中 t1 和 t2 都未声明(虽然所在咫尺,编译器却只会从左往右地读入符号)。按照 C/C++ 编译器的规则,变量使用前必须已经声明,因此,为了解决这个问题,C++11 引入了新语法——尾值返回类型,来声明和定义这样的函数。如:
template<typename T1, typename T2>
auto Sum(T1 & t1, T2 & t2) -> decltype(t1 + t2) {
return t1 + t2;
}
3.4. 函数重载(Overloaded function)
出现在相同作用域中的两个函数,如果具有相同的名字而形参表不同,则称为重载函数。
函数不能仅仅基于不同的返回类型而实现重载,如果有两个函数的形参表相同而返回类型不同,编译器报“重定义”错误。
3.4.1. Overload Resolution
重载确定(Overload resolution)是将函数调用与重载函数集合中最匹配的一个函数进行关联的过程。
可以用下面 3 个步骤来确定重载函数:
第一步,找候选函数(Candidate functions),候选函数是与被调用函数同名,且在调用点上其声明可见的函数。
第二步,找可行函数(Viable functions),可行函数满足两个条件:第一,函数的形参个数与该调用的实参个数相同;第二,每一个实参的类型必须与对应形参的类型匹配,或者可被隐式转换为对应的形参类型。
第三步,找最佳的可行函数(Best viable function)。
一个形参时如何确定最佳的可行函数?
为了确定最佳的可行函数,编译器将实参类型到相应形参类型的转换划分等级。转换等级以降序排序如下:
- 精确匹配(Exact Match)。实参与形参类型相同。
- 通过类型提升(Promotion)实现的匹配。如比 int 小的整数会提升为 int。
- 通过标准转换(Standard Conversion)实现的匹配。如浮点数到整数的转换。
- 通过类类型转换(Class-type Conversion)实现的匹配。
对转换等级的具体分类可参考表 2(摘自:C++11 standard. 13.3.3 Best viable function)
| Conversion | Rank |
|
No conversions required Lvalue-to-rvalue conversion Array-to-pointer conversion Function-to-pointer conversion Qualification conversions |
Exact Match |
|
Integral promotions Floating point promotion |
Promotion |
|
Integral conversions Floating point conversions Floating-integral conversions Pointer conversions Pointer to member conersions Boolean conversions |
Conversion |
多个形参时如何确定最佳的可行函数?
如果函数调用使用了两个或两个以上的实参,则编译器依次检查每一个实参来决定哪个函数的匹配是最佳的。
有且仅有一个函数满足下列条件时,则认为它就是最佳匹配:
- 其每个实参的匹配都不劣于其他可行函数需要的匹配;
- 至少有一个实参的匹配优于其他可行函数提供的匹配。
参考:
C++ Primer, 4th Edition. 7.8.3 The Three Steps in Overload Resolution
C++11 standard. 13.3 Overload resolution
3.4.1.1. 重载确定实例 1——优先使用精确匹配
假设有下面几个函数:
void f(); void f(int); void f(int, int); void f(double, double = 3.14);
调用下面函数时,会使用哪个重载函数呢?
f(5.6); // call f(double, double)
第一步,确定候选函数。4个名为 f 的函数都为候选函数。
第二步,确定可行函数,f(int)和 f(double, double)这两个函数为可行函数。
第三步,确定最佳的可行函数,f(double, double)属于精确匹配,所以它是最佳的可行函数。
3.4.1.2. 重载确定实例 2——多个参数的最佳匹配函数不一样
还是使用前面的例子,调用下面函数时,会使用哪个重载函数呢?
f(1, 2.56); // 编译器报错,有二义性。
第一步,确定候选函数。4个名为 f 的函数都为候选函数。
第二步,确定可行函数,f(int, int)和 f(double, double)这两个函数为可行函数。
第三步,确定最佳的可行函数。对于多个形参的情况,编译器依次检查每一个实参来决定哪个函数的匹配是最佳的。
先考虑第一个实参,f(int, int)属于精确匹配;再考虑第二个实参,f(double, double)属于精确匹配。不能决定哪个函数更好,编译器将产生“二义性”错误。
为了解决这个二义性,可以使用强制类型转换,如:
f(static_cast<double>(1), 2.56); // call f(double, double) f(1, static_cast<int>(2.56)); // call f(int, int)
3.4.1.3. 重载确定实例 3——不唯一的标准转换
void manip(long); void manip(float); mainip(3.14); // 编译器报错,有二义性。
字面值常量 3.14 的类型为 double,这种类型既可以转为 long 型又可转为 float 型,都是合法的标准转换,没有哪个标准转换比其它标准转换具有更高的优先级。所以调用具有二义性。
3.4.2. const 形参和重载
形参是否为 const,能否实现函数的重载?
这个要看情况,总结如下:
对于非指针非引用的普通形参,无法通过对参数是否使用 const 来进行函数重载。
void fun1(int i) { /* */ }
void fun1(const int i) { /* */ } //C和C++编译器都会提示“重定义”错误!
对于指针形参,可以通过对参数是否使用 const 来进行函数重载。
void fun1(int *ip) { /* */ }
void fun1(const int *ip) { /* */ } //C++中,这是合法的函数重载;但C中,会报“重定义”错误!
注意:不能基于指针本身是否为 const 来实现函数的重载。 如:
void fun1(int *ip) { /* */ }
void fun1(int *const ip) { /* */ } //C++和C中,都会报“重定义”错误!
对于引用形参,可以通过对参数是否使用 const 来进行函数重载。
void fun1(int &i) { /* */ }
void fun1(const int &i) { /* */ } //合法的函数重载。
3.5. constexpr 函数
constexpr 函数是指能用于常量表达式(参见 2.4 )的函数。定义 constexpr 函数的方法与其他函数类似,在 C++11 中它要遵循几项约定:函数的返回类型及所有形参的类型都得是字面值类型(参见 2.4 ),而且函数体中必须有且只有一条 return 语句(这个限制太严格,C++14 中放宽了这个限制)。
下面是 constexpr 函数的例子:
constexpr int new_sz() { return 42; }
constexpr int foo = new_sz(); // 正确,foo是一个常量表达式
上面例子中,执行 foo 的初始化任务时,编译器把对 constexpr 函数的调用替换成其结果值。 为了能在编译过程中随时展开, constexpr 函数被隐式地指定为内联函数。
下面是另一个 constexpr 函数的例子:
// 注:
// C++11 中编译会出错,因为C++11 规则 constexpr函数体中只能有一条return语句!
// C++14 中可以通过编译,因为 C++14 放宽了限制
constexpr int new_sz() {
int i = 41;
i += 1;
return i;
}
我们允许 constexpr 函数的返回值不是常量。如:
// 如果 arg 是常量表达式,则 scale(arg) 也是常量表达式
constexpr int new_sz() { return 42; }
constexpr size_t scale(size_t cnt) { return new_sz() * cnt; } // 这里scale返回值不是常量,但它是合法的constexpr函数
3.6. lambda 函数
C++11 中新引入了 lambda 函数,下面是 lambda 函数的一个例子:
#include<iostream>
int main() {
int girls = 3, boys = 4;
auto totalChild = [] (int x, int y) -> int { return x + y; }; // lambda函数
std::cout << totalChild(girls, boys) << std::endl;
return 0;
}
lambda 函数的语法为:
[capture](parameters) mutable -> return-type { statement }
上面语法中,“参数列表”和“返回类型”都是可选的,而“捕捉列表”和“函数体”都可能为空,所以最简略的 lambda 函数为:
[]{}; // 最简单的lambda函数
不过,上面 lambda 函数不能做任何事情。
3.6.1. 捕捉列表
语法上,捕捉列表由多个捕捉项组成,并以逗号分割。捕捉列表有如下几种形式:
[var]表示值传递方式捕捉变量 var。[=]表示值传递方式捕捉所有 Enclosing Scope 的变量(包括 this)。[&var]表示引用传递捕捉变量 var。[&]表示引用传递捕捉所有 Enclosing Scope 的变量(包括 this)。
通过一些组合,捕捉列表可以表示更复杂的意思。比如:
[=, &a, &b]表示以引用传递的方式捕捉变量 a 和 b,值传递方式捕捉其他所有变量。[&, a, this]表示以值传递的方式捕捉变量 a 和 this,引用传递方式捕捉其他所有变量。
利用上面规则,上文例子中的 lambda 函数还可以写为:
#include<iostream>
int main() {
int girls = 3, boys = 4;
// auto totalChild = [] (int x, int y) -> int { return x + y; };
auto totalChild = [=] () -> int { return girls + boys; };
std::cout << totalChild() << std::endl;
return 0;
}
通过捕捉列表 [=] ,lambda 函数的父作用域(上面例子即 main 函数)中所有自动变量都被 lambda 依照传值的方式捕捉了。
3.6.1.1. Dangling references
If a non-reference entity is captured by reference, implicitly or explicitly, and the function call operator of the closure object is invoked after the entity's lifetime has ended, undefined behavior occurs.
3.6.2. 值传递捕捉 VS. 引用传递捕捉
值传递捕捉和引用传递捕捉有什么不同呢?看下面例子:
#include <iostream>
using namespace std;
int main () {
int j = 12;
auto by_val_lambda = [=] { return j + 1; }; // 值传递捕捉
auto by_ref_lambda = [&] { return j + 1; }; // 引用传递捕捉
cout << "by_val_lambda: " << by_val_lambda() << endl;
cout << "by_ref_lambda: " << by_ref_lambda() << endl;
j++;
cout << "by_val_lambda:" << by_val_lambda() <<endl;
cout << "by_ref_lambda:" << by_ref_lambda() <<endl;
}
运行上面程序,会输出:
by_val_lambda: 13 by_ref_lambda: 13 by_val_lambda:13 by_ref_lambda:14
第一次调用 by_val_lambda 和 by_ref_lambda 时,其运算结果并没有不同。两者均计算的是 12+1=13。但在第二次调用 by_val_lambda 的时候,其计算的是 12+1=13, 相对地,第二次调用 by_ref_lambda 时计算的是 13+1=14。这个结果的原因是由于在 by_val_lambda 中, j 被视为了一个常量,一旦初始化后不会再改变(可以认为之后只是一个跟父作用域中 j 同名的常量)而在 by_ref_lambda 中, j 仍在使用父作用域中的值。
3.6.2.1. 捕捉 this
struct MyObj {
int value {123};
auto getValueCopy() {
return [*this] { return value; }; // this 的值传递捕捉,C++17 开始支持
}
auto getValueRef() {
return [this] { return value; }; // this 的引用传递捕捉,C++11 支持
}
};
MyObj mo;
auto valueCopy = mo.getValueCopy();
auto valueRef = mo.getValueRef();
mo.value = 321;
valueCopy(); // 123
valueRef(); // 321
3.6.3. 泛型 lambda
#include <iostream>
using namespace std;
int main() {
auto lambda = [](auto x, auto y) {return x + y;};
std::cout << lambda(1, 2) << std::endl;
std::cout << lambda(1.1, 2.1) << std::endl;
return 0;
}
C++11 中,需要明确指定 lambda 参数的类型,所以上面的例子用 C++11 实现的话,要编写多个:
auto lambda1 = [](int x, int y) {return x + y;};
auto lambda2 = [](double x, double y) {return x + y;};
3.6.4. Lambda capture initializers
在捕捉变量的同时可以使用“任意表达式”对变量进行初始化。“初始化表达式”是在定义 lambda 时执行,而不是执行 lambda 时执行。
int factory(int i) { return i * 10; }
auto f = [x = factory(4)] { return x; }; // x 初始化为表达式 factory(4) 的值
auto generator = [x = 0] () mutable {
// this would not compile without 'mutable' as we are modifying x on each call
return x++;
};
auto a = generator(); // == 0
auto b = generator(); // == 1
auto c = generator(); // == 2
再看一个例子:
auto x = 1;
auto f = [&r = x, x = x * 10] {
++r;
return r + x;
};
f(); // sets x to 2 and returns 12
参考:https://github.com/AnthonyCalandra/modern-cpp-features#lambda-capture-initializers
4. 类的基本概念
C++ 用类来定义自己的抽象数据类型。
4.1. 类的定义
定义类以关键字 class 开始,其后是该类的名字标识符。类体位于花括号里面,花括号后面必须要跟一个分号。类的成员可以是数据、函数和类型别名(typedef 定义)。
在实践中我们往往将类定义分成两个文件:一个头文件用来定义类的基本结构,包含类的数据成员和类成员函数的声明等等;另一个仅文件名后缀不同的.cpp 文件用来定义类的成员函数。这是比较好的软件工程实践,分离了类的接口和实现,对类的用户来说无需关心类成员函数的具体实现。
//file Rectangle.h
#ifndef RECTANGLE_H
#define RECTANGLE_H
class Rectangle {
int width, height;
public:
Rectangle (int,int);
Rectangle ();
int area ();
};
#endif
//file Rectangle.cpp
#include "Rectangle.h"
Rectangle::Rectangle (int a, int b) {
width = a;
height = b;
}
Rectangle::Rectangle () {
width = 0;
height = 0;
}
int Rectangle::area () {
return width * height;
}
定义了一个类类型后,可以按下面两种方式来使用:
一,将类的名字直接用作类型名;
二,指定关键字 class 或 struct,后面跟着类的名字。
如:
Rectangle obj1; //定义类型为Rectangle的对象obj1 class Rectangle obj1; //同上。这种用法从C中继承而来。
4.1.1. 类的访问标号 (public, protected 和 private)
类的访问标号及其含义如表 3 所示。
| 访问标号 | 可以从类外访问 | 可以从派生类访问 |
|---|---|---|
| public | Yes | Yes |
| protected | No | Yes |
| private | No | No |
4.2. 构造函数
构造函数的工作是保证每个对象的数据成员具有合适的初始值。创建类类型的新对象时,会自动执行构造函数。
构造函数的名字与类的名字相同,它不能指定返回类型(void 也不行)。构造函数可以被重载,实参决定了使用哪个构造函数。
4.2.1. 默认构造函数(无参或所有参数都有默认实参)
A default constructor is a constructor which can be called with no arguments (either defined with an empty parameter list, or with default arguments provided for every parameter).
用下面的方法可以使用默认构造函数来定义一个对象:
Rectangle obj1; // 注意:Rectangle obj1();是定义对象的错误写法,这种方式是声明一个函数!千万要小心! Rectangle obj1=Rectangle(); // 效果同上。创建并初始化一个Rectangle对象,然后用它来按值初始化obj1(会调用复制构造函数,但往往会被编译器优化为不调用复制构造函数)。
使用默认构造函数来动态创建对象:
Rectangle *p_obj1 = new Rectangle(); Rectangle *p_obj1 = new Rectangle; // 同上。
4.2.1.1. Synthesized Default Constructor
当且仅当一个类没有定义构造函数时,编译器会自动生成一个默认构造函数。 只要定义了构造函数,不管它是不是默认构造函数,编译器将不再自动生成默认构造函数。
编译器生成的这个函数称为合成的默认构造函数(synthesized default constructor)。
合成的默认构造函数按下面方式来初始化类的成员:
一、类类型的成员通过运行各自的默认构造函数来进行初始化;
二、内置类型成员不进行初始化。
#include <iostream>
using namespace std;
class Date
{
private:
int m_nMonth;
int m_nDay;
int m_nYear;
public:
void display () { cout<< "Year:" << m_nYear << " Month:" << m_nMonth << " Day:" << m_nDay <<endl; }
};
int main()
{
Date cDate; // Date中没有默认构造函数,编译器会生成一个synthesized default constructor
cDate.display(); // 合成的默认构造函数中,内置类型成员不进行初始化。display的输出每次都不一样。
return 0;
}
4.2.2. 构造函数初始化列表
与一般的成员函数不同,构造函数可以包含一个构造函数初始化列表。
构造函数初始化列表以一个冒号开始,接着是一个以逗号分隔的数据成员列表,每个数据成员后面跟一个放在圆括号中的初始化式。
构造函数初始化列表仅指定初始化成员的值,并不指定这些初始化执行的次序。成员被初始化的次序就是定义成员的次序。
构造函数初始化列表在定义时指定,而不是在声明中指定。
在构造函数初始化列表中没有显式提及的每个成员,使用与初始化变量相同的规则来进行初始化:类类型调用默认构造函数,内置类型取决于它的作用域(类作用域中不会自动初始化)。
构造函数初始化列表实例:
class Rectangle {
int width, height;
public:
Rectangle (int,int);
};
Rectangle::Rectangle (int a, int b): width(a), height(b) { }
省略初始化列表,在构造函数体内对数据成员赋值也能达到相同的目标。如:
Rectangle::Rectangle (int a, int b) {
width = a;
height = b;
}
上面 Rectangle 构造函数的两个版本具有同样的效果。不同之处在于,使用构造函数初始化列表的版本 初始化 数据成员,没有定义初始化列表的构造函数版本在构造函数的函数体中对数据成员 赋值 。这是“初始化”和“赋值”的区别,这个区别的重要性取决于数据成员的类型。
4.2.2.1. 必须用构造函数初始化列表的情况
三种成员的初始化必须在构造函数初始化列表中进行:
一:没有默认构造函数的类类型的成员;
二:const 成员;
三:引用类型的成员。
实例 1:没有默认构造函数的类类型的成员的初始化
class A {
int value;
public:
A(int i) {value = i;}
};
class B {
A obj1; //obj1为类类型成员,如果不在构造函数初始化列表中,会自动调用默认构造函数进行初始化。
//但obj1所属的类没有默认构造函数,所以类成员obj1的初始化只能在构造函数初始化列表中进行!
public:
B(int i) : obj1(i) {} //对obj1的初始化只能在构造函数初始化列表中进行。
//B(int i) { obj1=A(i); } //这行会报错,因为对obj1的初始化只能在构造函数初始化列表中进行。
};
int main() {
B obj2(10);
return 0;
}
实例 2:const 成员和引用类型的成员的初始化
class ConstRef {
private:
int i;
const int ci;
int &ri;
public:
ConstRef (int ii);
};
ConstRef::ConstRef(int ii) {
i = ii; // ok
ci = ii; // error: const成员的初始化必须在构造函数初始化列表中
ri = i; // error: 引用成员的初始化必须在构造函数初始化列表中
}
正确的方法是在构造函数初始化列表中对 const 成员和引用类型的成员进行初始化,如:
ConstRef::ConstRef(int ii): i(ii), ci(i), ri(ii) {}
4.2.3. Brace Initialization
节 2.2.1 中已经介绍过了 Brace Initialization,这节再介绍一下如何用它初始化自定义类。
规则 1:当类没有显式构造函数时,使用 Brace Initialization 时必需按照类中成员变量的声明顺序进行初始化:
#include <iostream>
#include <vector>
#include <string>
using namespace std;
class ClassA {
public:
float m_float;
string m_string;
char m_char;
void print_obj() const {
cout << "m_float: " << m_float << ", m_string: " << m_string << ", m_char: " << m_char << endl;
}
};
int main()
{
// ClassA 没有显式构造函数,使用 Brace Initialization 时必需按照类中成员变量的声明顺序进行初始化
ClassA d1{};
d1.print_obj();
ClassA d2{ 4.5 };
d2.print_obj();
ClassA d3{ 4.5, "abcd" };
d3.print_obj();
ClassA d4{ 4.5, "abcd", 'c' }; // 先浮点数,再字符串,再字符。必需按照类中成员变量的声明顺序进行初始化。
d4.print_obj();
// ClassA d5{ "abcd", 'c', 2.0 }; // compiler error 编译出错是因为指定的顺序和类中成员变量的声明顺序不一样
}
规则 2:当类有构造函数时,使用 Brace Initialization 时必需按照构造函数中参数的顺序进行初始化:
#include <iostream>
#include <string>
using namespace std;
class ClassB {
public:
ClassB() {}
ClassB(string str) : m_string{ str } {}
ClassB(string str, double dbl) : m_string{ str }, m_double{ dbl } {}
double m_double;
string m_string;
};
int main()
{
ClassB c1{};
ClassB c1_1;
ClassB c2{ "ww" };
ClassB c2_1("xx");
// order of parameters is the same as the constructor
ClassB c3{ "yy", 4.4 }; // 必需是先字符串,再浮点数。因为有构造函数时要和构造函数的参数顺序一致,而不用和成员变量的声明顺序一致
ClassB c3_1("zz", 5.5);
}
规则 3:如果默认构造函数被显式声明但标记为已删除,则不能使用空括号初始化:
#include <vector>
#include <string>
using namespace std;
class ClassC {
public:
ClassC() = delete; // 默认构造函数被显式声明但标记为已删除,后面不能使用空括号初始化
ClassC(string x): m_string { x } {}
string m_string;
};
int main()
{
ClassC cf{ "hello" };
ClassC cf1{}; // compiler error C2280: attempting to reference a deleted function
}
4.3. const 成员函数
将关键字 const 加在形参表之后,可以将成员函数声明为常量。如:
double avg_price() const;
const 成员函数不能改变其所操作的对象的数据成员。 const 关键字必须同时出现在声明和定义中,若只出现在其中一处,会出现编译时错误。
4.3.1. 基于成员函数是否为 const 的重载
基于成员函数是否为 const,可以重载一个成员函数。
class A {
int fun1 ();
int fun1 () const; /* 基于成员函数是否为const,可以重载函数。 */
};
在调用时,只有 A 类的 const 对象才能调用 const 版本的 fun1 函数;而类 A 的非 const 对象可以调用任意一种,但非 const 版本的 fun1 是一个更好的匹配。
4.4. 友元
友元机制允许一个类将对其非公有成员的访问权授予指定的函数或类。友元的声明以关键字 friend 开始。
友元可以是普通的非成员函数,或前面定义的其他类的成员函数,或整个类。
将一个类设为友元,友元类的所有成员函数都可以访问授予友元关系的那个类的非公有成员。
参考:http://www.learncpp.com/cpp-tutorial/813-friend-functions-and-classes/
4.4.1. 友元实例——普通的非成员函数作为友元
下面是一个普通的非成员函数作为友元的实例:
class Value
{
private:
int m_nValue;
public:
Value(int nValue) { m_nValue = nValue; }
friend bool IsEqual(const Value &cValue1, const Value &cValue2);
};
bool IsEqual(const Value &cValue1, const Value &cValue2)
{
return (cValue1.m_nValue == cValue2.m_nValue); //如果没有友元声明,私有成员m_nValue不能被访问。
}
4.4.2. 友元实例——类作为友元
下面是整个类作为友元的实例:
#include<iostream>
class Storage
{
private:
int m_nValue;
double m_dValue;
public:
Storage(int nValue, double dValue)
{
m_nValue = nValue;
m_dValue = dValue;
}
// Make the Display class a friend of Storage
friend class Display;
};
class Display
{
private:
bool m_bDisplayIntFirst;
public:
Display(bool bDisplayIntFirst) { m_bDisplayIntFirst = bDisplayIntFirst; }
void DisplayItem(Storage &cStorage) //友元类的所有成员函数都可以访问授予友元关系的那个类的非公有成员
{
if (m_bDisplayIntFirst)
std::cout << cStorage.m_nValue << " " << cStorage.m_dValue << std::endl;
else // display double first
std::cout << cStorage.m_dValue << " " << cStorage.m_nValue << std::endl;
}
};
int main()
{
Storage cStorage(5, 6.7);
Display cDisplay(false);
cDisplay.DisplayItem(cStorage); //输出: 6.7 5
return 0;
}
4.5. static 类成员
对于特定类类型的全体对象而言,访问一个全局对象有时是必要的。但全局对象会破坏封装。
我们还有另外一个更好的选择——使用 static 数据成员。
4.5.1. static 数据成员
static 数据成员独立于该类的任意对象而存在:每个 static 数据成员与类关联,并不与该类的对象相关联。
一般地,类的 static 数据成员和普通的数据成员一样,不能在类的定义体中初始化。static 数据成员通常在定义时才初始化。
// file foo1.h
class foo1
{
private:
static int i;
};
// file foo1.cpp
int foo1::i = 10; // static数据成员在定义时才初始化。static关键字只能出现在类定义体内部的声明中,定义时不能标示为static。
这个规则的一个例外是:只是初始化式是一个常量表达式,整型 const static 数据成员就可以在类的定义体中进行初始化:
// file foo2.h
class foo2
{
private:
static const int i = 10; //类的定义体中进行初始化要满足三个要求:1. static, 2. const, 3. int类型
};
// file foo2.cpp
const int foo2::i; //整型const static数据成员在类内部提供了初始化式时,在定义时不必再指定初始值。
//整型const static数据成员在类内部提供了初始化式时,有些编译器可以省略它的定义。
4.5.2. static 成员函数
类似的,static 成员函数是类的组成部分,不是任何对象的组成部分。
static 成员函数有下面性质:
static 成员函数没有 this 指针(static 不关联到某个对象,所以没有 this 指针);
static 成员函数不能被声明为 const(static 不关联到某个对象,不存在能不能修改某个对象的情况);
static 成员函数不能被声明为虚函数。
class Date {
int d, m, y;
static Date default_date;
public:
Date(int dd =0, int mm =0, int yy =0);
// ...
static void set_default(int dd, int mm, int yy); // set default_date to Date(dd,mm,yy)
};
5. 类的复制控制
当定义一个新类型的时候,需要显式或隐式地指定复制、移动、赋值和撤销该类型的对象时会发生什么——这是通过定义 5 种特殊的成员:复制构造函数(copy constructor)、复制赋值操作符(copy-assignment operator)、移动构造函数(move constructor)、移动赋值运算符(move-assignment operator)和析构函数(destructor)来达到的。我们将这些操作称为“复制控制”操作。
注:移动构造函数(move constructor)和移动赋值运算符(move-assignment operator)这两个成员是在 C++11 中引入的,C++11 前,复制控制只涉及其它 3 个成员;在 C++11 前,由于没有移动赋值运算符,“复制赋值操作符”往往直接称为“赋值操作符”。
5.1. 复制构造函数
只有单个形参,而且该形参是对本类类型对象的引用(常用 const 修饰),这样的构造函数称为复制构造函数。
复制构造函数可用于:
• 根据另一个同类型的对象显式或隐式初始化一个对象;
• 复制一个对象,将它作为实参传给一个函数;
• 从函数返回时复制一个对象;
• 初始化顺序容器中的元素。
5.1.1. 复制构造函数使用场景——根据对象初始化另一对象
回忆一下,C++ 支持两种初始化形式:直接初始化(将初始化式放入圆括号中)和复制初始化(使用等号)。
当用于类类型对象时,初始化的复制形式和直接形式有所不同:直接初始化直接调用与实参匹配的构造函数;复制初始化首先使用指定构造函数创建一个临时对象,然后用复制构造函数将那个临时对象复制到正在创建的对象。
string null_book = "9-999-99999-9"; // copy-initialization string dots(10, '.'); // direct-initialization string empty_copy = string(); // copy-initialization string empty_direct; // direct-initialization
5.1.2. Copy elision(避免不必要复制的优化手段)
Copy elision is a compiler optimization technique that avoids unnecessary copying of objects.
实例 1:
// file copy_elision.cpp
#include <iostream>
using namespace std;
class A {
public:
A(const char* str = "\0") { // default constructor
cout << "Constructor called" << endl;
}
A(const A &a) { // copy constructor
cout << "Copy constructor called" << endl;
}
};
int main() {
A obj1 = "test"; // 编译器会优化后效果类似于:A obj1("test");
return 0;
}
理论上讲,构造 obj1 时,会先使用能接受"test"为参数的构造函数创建一个临时对象,再调用复制构造函数将临时对象复制到正在创建的对象中。
但测试时,运行的结果为:
$ g++ copy_elision.cpp $ ./a.out Constructor called
复制构造函数竟然没有被调用,这时因为现代编译器默认进行了优化,避免了不必要复制。在 GCC 中可以使用 -fno-elide-constructors 禁止相关优化。
$ g++ -fno-elide-constructors copy_elision.cpp $ ./a.out Constructor called Copy constructor called
5.1.3. 复制构造函数使用场景——非引用的形参与返回值
我们知道,当形参为非引用类型的时候,将复制实参的值。类似地,以非引用类型作返回值时,将返回 return 语句中的值的副本。
5.1.4. 复制构造函数使用场景——初始化容器元素
复制构造函数可用于初始化顺序容器中的元素。
如:
// default string constructor and five string copy constructors invoked vector<string> svec(5);
上例中,编译器首先使用 string 默认构造函数创建一个临时值来初始化 svec,然后使用复制构造函数将临时值复制到 svec 的每个元素。
除非你想使用容器元素的默认初始值,更有效的办法是,分配一个空容器并将已知元素的值加入容器。如:
vector<string> svec; // empty vector svec.push_back(string1); // append string1 into vector svec svec.push_back(string2); // append string2 into vector svec
5.1.5. Synthesized Copy Constructor
如果我们没有定义复制构造函数,编译器就会为我们自动生成一个,称为合成复制构造函数(Synthesized Copy Constructor)。
合成复制构造函数的行为是,执行逐个成员初始化,将新对象初始化为原对象的副本。所谓“逐个成员”,指的是编译器将现在对象的每个非 static 成员,依次复制到正创建的对象。对于内置类型成员合成复制构造函数直接复制其值,对于类类型成员使用该类的复制构造函数进行复制。对于数组成员,合成复制构造函数将复制数组的每一个元素。
假设有下面类:
class Sales_item {
private:
std::string isbn;
int units_sold;
double revenue;
};
编译器自动生成的合成复制构造函数如下所示:
Sales_item::Sales_item(const Sales_item &orig):
isbn(orig.isbn), // uses string copy constructor
units_sold(orig.units_sold), // copies orig.units_sold
revenue(orig.revenue) // copy orig.revenue
{ } // empty body
5.1.6. 何时要定义自己的复制构造函数(Shallow vs. Deep Copy)
合成复制构造函数只完成必要的工作,对于简单的情况也能很好的工作。
但有些类必须对复制对象时发生的事情加以控制。这样的类经常有一个数据成员是指针(合成复制构造函数仅会复制指针的值,不会复制指针指向的内存空间,这会导致两个成员指针指向同一块内存,这样在分别 delete 释放时会出现问题),或者有成员表示在构造函数中分配的其他资源。而另一些类在创建新对象时必须做一些特定工作。这两种情况下,都必须定义复制构造函数。
合成复制构造函数所做的工作是浅拷贝,如果需要深拷贝则应该定义自己的复制构造函数。
参考:https://en.wikipedia.org/wiki/Object_copying#Shallow_copy
5.1.7. 禁止复制
有些类需要完全禁止复制。例如,iostream 类就不允许复制。
为了防止复制,类必须显式声明其复制构造函数为 private。如果复制构造函数是私有的,将不允许用户代码复制该类类型的对象,编译器将拒绝任何进行复制的尝试。然而,类的友元和成员仍可以进行复制。如果想要连友元和成员中的复制也禁止,就可以声明一个 private 的复制构造函数但不对其定义。声明而不定义成员函数是合法的,使用未定义成员的任何尝试将导致链接失败。
通过声明(但不定义)一个 private 的复制构造函数,可以禁止任何复制类类型对象的尝试:用户代码中复制尝试将在编译时报错,而成员函数和友元中的复制尝试将在链接时报错。
C++11 中可以通过“=delete”来实现禁止复制,可参考节 5.6.2
5.2. 复制赋值操作符
与类要控制初始化对象的方式一样,类也可以控制该类型对象赋值时会发生什么:
Sales_item trans, accum; trans = accum; // 使用 Sales_item 的复制赋值操作符
在介绍复制赋值操作符之前,需要简单了解一下重载操作符(overloaded operator)。
重载操作符是一些函数,其名字为 operator 后跟着所定义的操作符的符号。因此,通过定义名为 operator=的函数,我们可以对赋值进行定义。像任何其他函数一样,操作符函数有一个返回值和一个形参表。形参表必须具有与该操作符数目相同的形参(如果操作符是一个类成员,则包括隐式 this 形参)。赋值是二元运算,所以该操作符函数有两个形参:第一个形参对应着左操作数,第二个形参对应右操作数。
大多数操作符可以定义为成员函数或非成员函数。当操作符为成员函数时,它的第一个操作数隐式绑定到 this 指针。有些操作符(包括复制赋值操作符)必须是定义自己的类的成员。因为赋值必须是类的成员,所以 this 绑定到指向左操作数的指针。因此, 复制赋值操作符接受单个形参,且该形参是同一类类型的对象。右操作数一般作为 const 引用传递。
为了与内置类型赋值(内置类型的赋值运算的结果是它的左侧运算对象,结果的类型就是左侧运算对象的类型)保持一致, 复制赋值操作符通常返回对同一类类型的引用。
从语法正确性的角度来说,类 MyClass 的复制赋值操作符可声明为:
1: MyClass& operator=( const MyClass& rhs ); // 这是推荐形式 2: MyClass& operator=( MyClass& rhs ); 3: MyClass& operator=( MyClass rhs ); 4: const MyClass& operator=( const MyClass& rhs ); 5: const MyClass& operator=( MyClass& rhs ); 6: const MyClass& operator=( MyClass rhs ); 7: MyClass operator=( const MyClass& rhs ); 8: MyClass operator=( MyClass& rhs ); 9: MyClass operator=( MyClass rhs );
上面声明中,(2),(5),(8)形式(其参数为“非 const 引用”)是需要避免的,比如有代码:
MyClass c1; c1 = MyClass(5, 'a', "Hello World" ); // assuming this constructor exists
上面代码中,赋值语句的右边是一个临时对象(它没有名字),C++ 中禁止把临时对象传递给“非 const 引用”。
5.2.1. Synthesized Copy-Assignment Operator
与复制构造函数类似,如果类没有定义自己的复制赋值操作符,则编译器会合成一个。
合成复制赋值操作符(Synthesized Copy-Assignment Operator)与合成复制构造函数的操作类似。它会执行逐个成员赋值:右操作数对象的每个成员赋值给左操作数对象的对应成员。除数组之外,每个成员用所属类型的常规方式进行赋值。对于数组,给每个数组元素赋值。
假设有下面类:
class Sales_item {
private:
std::string isbn;
int units_sold;
double revenue;
};
编译器自动生成的合成复制赋值操作符如下所示:
// equivalent to the synthesized copy-assignment operator
Sales_item&
Sales_item::operator=(const Sales_item &rhs) {
isbn = rhs.isbn; // calls string::operator=
units_sold=rhs.units_sold; // uses built-in int assignment
revenue = rhs.revenue; // uses built-in double assignment
return *this;
}
5.3. 析构函数
析构函数是个成员函数,它的名字是在类名字之前加上一个代字号(~),它没有返回值,没有形参。因为不能指定任何形参,所以不能重载析构函数。
一般用析构函数来释放在其构造函数中分配的资源。
5.3.1. 何时析构函数自动被调用
撤销类对象时会自动调用析构函数。
对于动态分配的对象当对其指针使用 delete 时会被撤销;对于局部变量,当其超出作用域时会被撤销。
// p points to default constructed object
Sales_item *p = new Sales_item;
{ // new scope
Sales_item item(*p); // copy constructor copies *p into item
delete p; // destructor called on object pointed by p
} // exit local scope; destructor called on item
变量(如 item)在超出作用域时应该自动撤销。因此,当遇到右花括号时,将运行 item 的析构函数。
动态分配的对象只有在指向该对象的指针被删除时才撤销。如果没有删除指向动态对象的指针,则不会运行该对象的析构函数,对象就一直存在。从而导致内存泄漏。
又如:
// pointer is destroyed because it goes out of scope,
// but not the object it pointed to. MEMORY LEAK!!!
if (1) {
Foo *myfoo = new Foo("foo");
}
// pointer is destroyed because it goes out of scope,
// object it points to is deleted. no memory leak
if(1) {
Foo *myfoo = new Foo("foo");
delete myfoo;
}
// no memory leak, object goes out of scope
if(1) {
Foo myfoo("foo");
}
参考:
http://stackoverflow.com/questions/10081429/when-is-a-c-destructor-called
5.3.1.1. 容器中的元素总是按逆序撤销
撤销一个容器(不管是标准库容器还是内置数组)时,也会运行容器中的类类型元素的析构函数:
{
Sales_item *p = new Sales_item[10]; // dynamically allocated
vector<Sales_item> vec(p, p + 10); // local object
// ...
delete [] p; // array is freed; destructor run on each element pointed by p
} // vec goes out of scope; destructor run on each element in vec
容器中的元素总是按逆序撤销:首先撤销下标为 size() - 1 的元素,最后撤销下标为 0 的元素。
5.3.2. 栈展开时是否撤销局部对象
栈展开时是否撤销局部对象(即调用析构函数)要分情况讨论。
5.3.2.1. Unwind Stack by longjmp(不会调用析构函数,避免在 C++ 中使用 longjmp)
前面说到撤销类对象时会自动调用析构函数,对于局部变量,当其超出作用域时会被撤销。
调用 longjmp 时,setjmp 和 longjmp 之间的栈上的局部对象可以认为是超出作用域,它们会被撤销吗?
答案是不会(VC++ 会撤销,但不要依赖它)。测试如下:
#include <iostream>
#include <setjmp.h>
using namespace std;
class A
{
public:
A() { cout << "A constructor called" << endl; }
~A() { cout << "A destructor called" << endl; }
};
class B
{
public:
B() { cout << "B constructor called" << endl; }
~B() { cout << "B destructor called" << endl; }
};
jmp_buf env;
void func1();
int main() {
int val;
val = setjmp (env);
if (val) {
cerr << "Error " << val << " happened" << endl;
return -1;
}
func1();
return 0;
}
void func1() {
A obja;
B objb;
longjmp (env, 101);
}
在 Linux 中运行上面程序,输出:
A constructor called B constructor called Error 101 happened
从上面结果中可知,局部对象 obja 和 objb 没有被撤销(A和 B 的析构函数并没有被调用),这会有潜在的资源泄露问题。
5.3.2.2. Unwind Stack by throw(会调用析构函数)
C++ 要求因异常而退出函数时,编译器保证撤销在异常发生前创建的局部对象。
测试如下:
#include <iostream>
using namespace std;
class A
{
public:
A() { cout << "A constructor called" << endl; }
~A() { cout << "A destructor called" << endl; }
};
class B
{
public:
B() { cout << "B constructor called" << endl; }
~B() { cout << "B destructor called" << endl; }
};
void func1();
int main() {
int val;
try {
func1();
} catch (int e) {
cerr << "Error " << e << " happened" << endl;
}
return 0;
}
void func1() {
A obja;
B objb;
throw 101;
}
运行上面程序,输出:
A constructor called B constructor called B destructor called A destructor called Error 101 happened
从上面结果中可知,局部对象 obja 和 objb 被撤销(A和 B 的析构函数被调用了)。
5.3.3. Synthesized Destructor(总会生成,总会运行)
与复制构造函数或赋值操作符不同,编译器总是会为我们合成一个析构函数。
合成析构函数(Synthesized Destructor)按对象创建时的逆序撤销每个非 static 成员,因此,它按成员在类中声明次序的逆序撤销成员。对于类类型的每个成员,合成析构函数调用该成员的析构函数来撤销对象。合成析构函数并不删除指针成员所指向的对象。
析构函数与复制构造函数或赋值操作符之间的一个重要区别是,即使我们编写了自己的析构函数,合成析构函数仍会运行(在执行完自己定义的析构函数后将运行合成析构函数)。
假如有下面的程序:
#include <iostream>
using namespace std;
class A
{
public:
A() { cout << "A constructor called" << endl; }
~A() { cout << "A destructor called" << endl; }
};
class B
{
public:
B() { cout << "B constructor called" << endl; }
~B() { cout << "B destructor called" << endl; }
};
class Test
{
A obj1;
B obj2;
public:
Test() { cout << "Test constructor called" << endl; }
~Test() { cout << "Test destructor called" << endl; }
};
int main()
{
Test foo;
return 0;
} // foo goes out of scope here
运行上面程序会输出:
A constructor called B constructor called Test constructor called Test destructor called B destructor called A destructor called
说明:
在 Test 的构造函数中并没有显式调用 A 和 B 的构造函数,为什么 A constructor called 和 B constructor called 会被输出?
这是因为在构造函数初始化列表中没有显式提及的每个成员,将使用与初始化变量相同的规则来进行初始化。
在 Test 的析构函数中并没有显式调用 A 和 B 的析构函数,为什么 A destructor called 和 B destructor called 会被输出?
这是因为合成析构函数会在执行完自己定义的析构函数后运行。
5.3.4. 何时要定义析构函数
分配了资源的类一般需要定义析构函数以释放那些资源。
5.4. 三/五法则
在 C++11 之前,如果类需要析构函数,则它往往也需要复制构造函数和复制赋值操作符,这是一个有用的经验法则。这个规则常称为三法则(rule of three)。C++11 中新增了移动构造函数和移动赋值运算符,这个法则变为了五法则。
5.5. 对象移动
很多情况下,都会发生对象复制。 在其中某些情况下,对象复制后就立即被销毁了;在这些情况下,移动而非复制对象会大幅度提升性能。为此,C++11 中增加了移动语义。
5.5.1. 左值、将亡值、纯右值
在 C、C++98 中,我们常常会提起左值(lvalue)、右值(rvalue)这样的称呼。通常, 可以取地址的、有名字的就是“左值”;反之,不能取地址的、没有名字的就是“右值”。 如,有下面赋值表达式:
a = b + c;
取地址 &a 是允许的操作,但 &(b + c) 这样的操作则不会通过编译。因此, a 是一个左值, b+c 是一个右值。
在 C++11 中,右值分别两类:“将亡值(xvalue,eXpiring Value)”和“纯右值(prvalue,Pure Rvalue)”。 其中,纯右值就是 C++98 中右值的概念。一些运算表达式,比如 1+3 产生的临时变量值是纯右值;而不跟对象关联的字面量值,比如 2, 'c', true 等也是纯右值。此外,类型转换函数的返回值、lambda 表达式等也都是纯右值。
而“将亡值”则是 C++11 新增的跟“右值引用”(后文将介绍)相关的表达式,这样的表达式通常是将要被移动的对象(移为它用),比如 std::move 的返回值,返回右值引用 T&& 的函数的返回值等都是“将亡值”。
在 C++11 程序中,所有的值必属于左值、将亡值、纯右值三者之一。
5.5.2. 右值引用(Rvalue reference,增加临时对象的生命期)
所谓右值引用(Rvalue reference)就是绑定到右值的引用。我们通过 && 而不是 & 来获得右值引用。
为了区别于 C++98 中的引用类型,我们称 C++98 中的引用为“左值引用”。右值引用和左值引用都属于引用类型,都必须立即进行初始化。
下面是右值引用的例子:
int i = 42; int&& rr1 = i; // 编译出错:不能用左值初始化一个右值引用。rvalue reference to type 'int' cannot bind to lvalue of type 'int' int&& rr2 = i * 42; // 正确:将右值引用 rr2 绑定到乘法结果(右值)上 int&& rr3 = 42; // 正确:字面常量是右值
右值引用的一个重要作用是“增加临时对象的生命期”;我们知道常量左值引用也可以“增加临时对象的生命期”,不过你不能修改它(因为它是常量)。 比如:
#include <iostream>
#include <string>
int main() {
std::string s1 = "Test";
const std::string& r2 = s1 + s1; // okay: 常量左值引用可以“增加临时对象的生命期”
// r2 += "Test"; // error: 不能修改它(因为是 const 的)
std::string&& r3 = s1 + s1; // okay: 右值引用可以“增加临时对象的生命期”
r3 += "Test"; // okay: 可以修改它
std::cout << r3 << '\n';
}
根据函数参数是否为右值引用,可以重载函数,如:
#include <iostream>
#include <utility>
void f(int& x) {
std::cout << "lvalue reference overload f(" << x << ")\n";
}
void f(const int& x) {
std::cout << "lvalue reference to const overload f(" << x << ")\n";
}
void f(int&& x) {
std::cout << "rvalue reference overload f(" << x << ")\n";
}
int main() {
int i = 1;
const int ci = 2;
f(i); // calls f(int&)
f(ci); // calls f(const int&)
f(3); // calls f(int&&)
// would call f(const int&) if f(int&&) overload wasn't provided
f(std::move(i)); // calls f(int&&)
// rvalue reference variables are lvalues when used in expressions
int&& x = 1;
f(x); // calls f(int& x)
f(std::move(x)); // calls f(int&& x)
}
5.5.2.1. std::move 函数
右值引用只能绑定到一个将要销毁的对象,不能直接绑定到一个左值上。使用 std::move 函数可以“获得绑定到左值上的右值引用”, std::move 调用告诉编译器:我们有一个左值,但我们希望像一个右值一样处理它。所以,我们必须认识到,调用 std::move 后,我们不能对移后源对象的值做任何假设(即源对象可能已经变了)。
int i = 42; //int &&rr1 = i; // 错误:不能将一个右值引用绑定到一个左值上 int &&rr1 = std::move(i); // 注:后面不要再使用源对象的值了(这里是i)
下面例子展示了使用 std::move(str) 后, str 指向的对象已经变了:
#include <iostream>
#include <utility>
#include <vector>
#include <string>
int main()
{
std::string str = "Hello";
std::vector<std::string> v;
// uses the push_back(const T&) overload, which means
// we'll incur the cost of copying str
v.push_back(str);
std::cout << "After copy, str is \"" << str << "\"\n";
// uses the rvalue reference push_back(T&&) overload,
// which means no strings will be copied; instead, the contents
// of str will be moved into the vector. This is less
// expensive, but also means str might now be empty.
v.push_back(std::move(str));
std::cout << "After move, str is \"" << str << "\"\n";
std::cout << "The contents of the vector are \"" << v[0]
<< "\", \"" << v[1] << "\"\n";
}
5.5.3. 移动构造函数和移动赋值运算符
移动构造函数的语法为:
ClassA (ClassA &&) // 移动构造函数语法
先考虑下面程序(没有创建移动构造函数):
#include <iostream>
#include <string>
using namespace std;
class HasPtrMem {
private:
int * d;
static int n_cstr;
static int n_dstr;
static int n_cptr;
public:
HasPtrMem() : d(new int(100)) {
cout << "Construct:" << ++n_cstr << endl;
}
HasPtrMem(const HasPtrMem &h) : d(new int(*h.d)) {
cout << "Copy construct: " << ++n_cptr << endl;
}
~HasPtrMem() {
cout << "Destruct: " << ++n_dstr << endl;
}
};
int HasPtrMem::n_cstr = 0;
int HasPtrMem::n_dstr = 0;
int HasPtrMem::n_cptr = 0;
HasPtrMem GetTemp() { return HasPtrMem(); }
int main() {
HasPtrMem a = GetTemp();
return 0;
}
在上面代码中,我们声明了一个返回 HasPtrMem 变量的函数。为了记录构造函数、复制构造函数,以及析构函数调用的次数,我们使用了一些静态变量。在 main 函数中,我们简单地声明了一个 HasPtrMem 的变量 a ,要求它使用 GetTemp 的返回值进行初始化。编译运行该程序,我们可以看到下面的输出:
$ c++ -fno-elide-constructors file1.cpp -o file1 $ ./file1 Construct:1 Copy construct: 1 Destruct: 1 Copy construct: 2 Destruct: 2 Destruct: 3
从上面输出中可知,构造函数被调用了一次,这是在 GetTemp 函数中 HasPtrMem() 表达式显式地调用了构造函数而打印出来的。而复制构造函数则被调用了两次。这两次中一次是从 GetTemp 函数中 HasPtrMem() 生成的变量上复制构造出一个临时值,以用作 GetTemp 的返回值,而另外一次则是由临时值构造出 main 中变量 a 调用的。对应地,构造函数也就调用了 3 次。这个过程如图 1 所示。
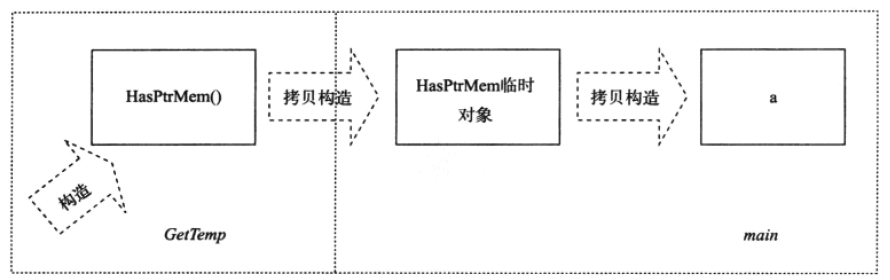
Figure 1: 函数返回时的临时变量与复制
让我们感到不安的是复制构造函数的调用。如果 HasPtrMem 的指针成员指向非常大的堆内存数据的话,那么复制构造的过程就会非常昂贵,从而导致 a 的初始化表达式的执行速度将相当堪忧。其实,这两个复制构造过程没有什么意义,因为它们生成的临时对象马上又被构造了。
C++11 中,引用了“移动语义”来处理这种情况。直接看下面代码:
#include <iostream>
#include <string>
using namespace std;
class HasPtrMem {
private:
int * d;
static int n_cstr;
static int n_dstr;
static int n_cptr;
static int n_mvtr; // 记录移动构造函数调用次数
public:
HasPtrMem() : d(new int(100)) {
cout << "Construct:" << ++n_cstr << endl;
}
HasPtrMem(const HasPtrMem &h) : d(new int(*h.d)) { // 复制构造函数中有“申请堆内存的过程”
cout << "Copy construct: " << ++n_cptr << endl;
}
// 下面是移动构造函数
HasPtrMem(HasPtrMem && h) : d(h.d) { // 用临时值的指针成员(h.d)初始化新对象的指针成员(d),这里没有“申请堆内存的过程”,只是新指针指向了旧指针对应的堆内存
h.d = nullptr; // 必须将临时值的指针成员置空,这样临时值被构造时不会释放底层的堆内存
cout << "Move construct: " << ++n_mvtr << endl;
}
~HasPtrMem() {
cout << "Destruct: " << ++n_dstr << endl;
}
};
int HasPtrMem::n_cstr = 0;
int HasPtrMem::n_dstr = 0;
int HasPtrMem::n_cptr = 0;
int HasPtrMem::n_mvtr = 0;
HasPtrMem GetTemp() { return HasPtrMem(); }
int main() {
HasPtrMem a = GetTemp();
return 0;
}
上面代码比前面代码中多了一个构造函数 HasPtrMem(HasPtrMem &&) ,这个就是我们所谓的“移动构造函数”。与复制构造不同,移动构造函数接受一个“右值引用”参数。我们编译上面程序,运行结果如下:
$ c++ -std=c++11 -fno-elide-constructors file1.cpp -o file1 $ ./file1 Construct:1 Move construct: 1 Destruct: 1 Move construct: 2 Destruct: 2 Destruct: 3
可以看到,这里没有调用复制构造,而是调用了两次移动构造函数,移动构造的结果是, GetTemp 中 h 的指针成员 h.d 和 main 函数中的 a 的指针成员 a.d 的值是相同的,即 h.d 和 a.d 都指向了相同的堆内存。该堆内存在函数返回的过程,成功地逃避了被析构的“厄运”,取而代之地,成为了赋值表达式中的变量 a 的资源。如果堆内存不是一个 int 长度的数据,而是以 MByte 为单位的堆空间,那么这样的移动带来的性能提升将非常惊人。
参考:《深入理解 C++11》,3.3 节
5.5.3.1. 移动语义不是新概念
事实上,移动语义并不是什么新概念。在 C++98/03 的语言和库中,它已经存在了,比如:
- 在某些情况下复制构造函数的省略(copy constructor elision in some contexts)
- 智能指针的拷贝(auto_ptr “copy”)
- 链表拼接(list::splice)
- 容器内的转换(swap on containers)
以上这些操作都包含了从一个对象向另一个对象的资源转换(至少概念上)的过程,唯一欠缺的是统一的语法和语义的支持,来使我们可以使用通用的代码移动任意的对象。
5.5.3.2. 何时会调用移动构造函数
5.5.3.3. 移动赋值运算符
这里不重点介绍移动赋值运算符,下面直接给出一个实例:
class Resource {
public:
Resource& operator=(Resource&& other) { // 移动赋值运算符
if (this != &other) { // If the object isn't being called on itself
delete this->data; // Delete the object's data
this->data = other.data; // "Move" other's data into the current object
other.data = nullptr; // Mark the other object as "empty"
}
return *this; // return *this
}
void* data;
};
5.6. 默认函数的控制
5.6.1. 类的默认函数
在 C++ 中声明自定义的类,编译器会默认帮助程序员生成一些他们未定义的成员函数。这样的函数版本被为“默认函数”。这包括了以下一些自定义类型的成员函数:
- 构造函数
- 复制构造函数
- 复制赋值操作符
- 移动构造函数
- 移动赋值运算符
- 析构函数
此外,C++ 编译器还会为以下这些自定义类型提供全局默认操作符函数:
operator ,operator &operator &&operator *operator ->operator ->*operator newoperator delete
在 C++ 语言规则中,一旦程序员实现了这些函数的自定义版本,则编译器不会再为该类自动生成默认版本。
5.6.2. “=default”和“=delete”
C++11 中允许用户通过指定“=default”或者“=delete”来显式地控制默认函数的“生成”或者“不生成”。
1: class A 2: { 3: public: 4: A(int a){}; 5: A() = default; // 明确要求编译器生成默认构造函数 6: }; 7: 8: int main() { 9: A a; // 如果注释掉第5行代码,编译器会报错。因为用户编译了构造函数后,默认构造函数将默认不生成 10: return 0; 11: }
下面是使用“=delete”来实现禁止复制:
class X {
// ...
X& operator=(const X&) = delete; // Disallow copying
X(const X&) = delete;
};
5.6.2.1. “=delete”的其它场景
我们可以通过显式删除来禁止类型转换。如:
void func1(int i) {};
void func1(char c) = delete; // 显式删除 char 版本
int main() {
func1(3);
func1('a'); // 本句无法通过编译
return 0;
}
6. 重载操作符与转换
C++ 允许我们重定义操作符用于类类型对象时的含义。明智地使用操作符重载可以使类类型的使用像内置类型一样直观和方便。
重载操作符是具有特殊名称的函数:保留字 operator 后接需定义的操作符号。像任意其他函数一样,重载操作符具有返回类型和形参表。
6.1. 至少一个参数为类类型或枚举类型
重载操作符必须具有至少一个类类型或枚举类型的操作数。
这条规则强制重载操作符不能重新定义用于内置类型对象的操作符的含义。
如,下面的重载操作符是非法的:
int operator+(int, int); /* 会报错。重载操作符需要至少一个类类型或枚举类型的操作 */
6.2. 可重载和不可重载的操作符
除下面 6 个操作符不能被重载外,其他的操作符都可以被重载。
. (member selection) .* (member selection with pointer-to-member) :: (scope resolution) ?: (conditional) sizeof (object size information) typeid (object type information)
通过连接其他合法符号可以创建新的操作符。例如,定义一个 operator** 以提供求幂运算是合法的。
参考:
Why can't I overload dot, ::, sizeof, etc.? http://www.stroustrup.com/bs_faq2.html#overload-dot
6.3. 重载操作符为类成员与非类成员函数的经验原则
为类设计重载操作符的时候,必须选择是将操作符设置为类成员还是普通非成员函数。在某些情况下,程序员没有选择,操作符必须是成员;在另一些情况下,有些经验原则可指导我们做出决定。
操作符定义为类成员函数时,其形参看起来比操作数数目少 1。因为作为成员函数的操作符有一个隐含的 this 形参,且限定为第一个操作数。
操作符定义为非成员函数时,通常必须将它们设置为所操作类的友元。因为在这种情况下,操作符通常需要访问类的私有部分。
下面是一些指导原则,有助于决定将操作符设置为类成员还是普通非成员函数:
• 赋值(=)、下标([])、调用(())和成员访问箭头(->)等操作符必须定义为成员,将这些操作符定义为非成员函数将在编译时标记为错误。
• 像赋值一样,复合赋值操作符通常应定义为类的成员,与赋值不同的是,不一定非得这样做,如果定义非成员复合赋值操作符,不会出现编译错误。
• 改变对象状态或与给定类型紧密联系的其他一些操作符,如自增、自减和解引用,通常就定义为类成员。
• 对称的操作符,如算术操作符、相等操作符、关系操作符和位操作符,最好定义为非成员函数。
• 输入输出操作符(>>和<<)必须为非成员函数。
6.3.1. 类成员与非类成员实例:重载+和-操作符
下面演示一个重载操作符实例,重载类 Box 的加号(定义为成员函数)和减号操作符(定义非成员函数):
#include <iostream>
using namespace std;
class Box {
public:
double getVolume(void) { return length * breadth * height; }
void setLength( double len ) { length = len; }
void setBreadth( double bre ) { breadth = bre; }
void setHeight( double hei ) { height = hei; }
Box operator+(const Box& b) { // 重载+操作符为成员函数。
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
friend Box operator-(const Box &, const Box &);
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
Box operator-(const Box &a, const Box &b) { // 重载-操作符为非成员函数。
Box box;
box.setLength(a.length - b.length); // 通常要将非成员函数重载操作符设置为所操作类的友元。这样可以直接使用访问私有成员a.length
box.setBreadth(a.breadth - b.breadth);
box.setHeight(a.height - b.height);
return box;
}
int main() {
Box Box1, Box2, Box3, Box4;
double volume = 0.0;
// box 1 specification
Box1.setLength(6.0);
Box1.setBreadth(7.0);
Box1.setHeight(5.0);
// box 2 specification
Box2.setLength(12.0);
Box2.setBreadth(13.0);
Box2.setHeight(10.0);
// volume of box 1
volume = Box1.getVolume();
cout << "Volume of Box1 : " << volume <<endl; //Volume of Box1 : 210
// volume of box 2
volume = Box2.getVolume();
cout << "Volume of Box2 : " << volume <<endl; //Volume of Box2 : 1560
// Add two object as follows:
Box3 = Box1 + Box2; // 操作符+为成员函数。
// 还可以写为Box3 = Box1.operator+(Box2);的形式,但不能写为Box3 = operator+(Box1, Box2);
// volume of box 3
volume = Box3.getVolume();
cout << "Volume of Box3 : " << volume <<endl; //Volume of Box3 : 5400
Box4 = Box2 - Box1; // 操作符-为非成员函数。
// 还可以写为Box4 = operator-(Box2, Box1);的形式。
// volume of box 4
volume = Box4.getVolume();
cout << "Volume of Box4 : " << volume <<endl; //Volume of Box4 : 180
return 0;
}
说明:上面例子仅为演示使用,实际编程时,算术操作符一般都设置为普通非成员函数。
6.4. 重载输入输出操作符(>>和<<)
输入操作符(>>)和输出操作符(<<)必须为非成员函数。否则,左操作数只能是该类类型的对象。这与已定义的其他类的输入输出操作符的使用形式不一致,如:
// 把输出操作符<<重载为成员函数的错误例子 A obj; obj << cout; // 由于把<<重载为成员函数,则只能这样使用。这与通常<<的使用形式不一致。
说明:
为了与 I/O 标准库一致,操作符应接受 ostream&作为第一个形参,对类类型 const 对象的引用作为第二个形参,并返回对 ostream 形参的引用。
为了与 I/O 标准库一致,操作符应接受 istream&作为第一个形参,对类类型对象的引用作为第二个形参,并返回对 istream 形参的引用。
和输出操作符不同,输入操作符必须处理输入期间的错误。
6.4.1. 实例:重载输入输出操作符
下面演示重载输入输出操作符:
#include <iostream>
using namespace std;
class Distance
{
private:
int feet;
int inches;
public:
Distance(){
feet = 0;
inches = 0;
}
Distance(int f, int i) {
feet = f;
inches = i;
}
friend ostream &operator<<(ostream &output, const Distance &D) { // 第一个形参为ostream&,第二个形参为const对象引用
output << "Feet : " << D.feet << " Inches : " << D.inches;
return output;
}
friend istream &operator>>(istream &input, Distance &D) { // 第一个形参为istream&,第二个形参为对象引用
input >> D.feet >> D.inches; // 仅是demo,没有处理输入期间的错误(如输出值和期待的类型不同)。
return input;
}
};
int main() {
Distance D1(11, 10), D2(5, 11), D3;
cout << "Enter the value of object : " << endl;
cin >> D3;
cout << "First Distance : " << D1 << endl;
cout << "Second Distance :" << D2 << endl;
cout << "Third Distance :" << D3 << endl;
return 0;
}
编译并测试运行如下:
$ ./a.out $ ./4 Enter the value of object : 14 8 First Distance : Feet : 11 Inches : 10 Second Distance :Feet : 5 Inches : 11 Third Distance :Feet : 14 Inches : 8
参考:http://www.tutorialspoint.com/cplusplus/input_output_operators_overloading.htm
6.5. 重载赋值操作符
赋值操作符只能定义为成员函数。
我们知道,如果类没有定义自己的赋值操作符,则编译器会合成一个。
可以为一个类定义许多附加的赋值操作符,这些赋值操作符会因右操作符类型不同而不同。
如 string 类包含好几个重载的赋值操作符:
// illustration of assignment operators for class string
class string {
public:
string& operator=(const string &); // s1 = s2;
string& operator=(const char *); // s1 = "str";
string& operator=(char); // s1 = 'c';
// ....
};
6.6. 重载下标操作符
下标操作符只能定义为成员函数。
类定义下标操作符时,一般需要定义两个版本:一个为非 const 成员并返回引用,另一个为 const 成员并返回 const 引用。
class Foo {
public:
int &operator[] (const size_t);
const int &operator[] (const size_t) const;
// other interface members
private:
vector<int> data;
// other member data and private utility functions
};
下标操作符看起来像这样:
int& Foo::operator[] (const size_t index) {
return data[index]; // no range checking on index
}
const int& Foo::operator[] (const size_t index) const {
return data[index]; // no range checking on index
}
6.7. 重载自增、自减操作符
根据经验原则,自增、自减操作符会改变对象状态,一般重载为类成员函数。
对内置类型而言,自增操作符和自减操作符有前缀和后缀两种形式。我们也可以给自己的类定义自增操作符和自减操作符的前缀和后缀版本。同时定义前缀式操作符和后缀式操作符存在一个问题:它们的形参数目和类型相同,普通重载不能区别所定义的前缀式操作符还是后缀式操作符。
为了解决这一问题,后缀式操作符函数接受一个额外的(即无用的)int 型形参,它的唯一目的是使后缀函数与前缀函数区别开来。
说明:
为了与内置类型的操作符一致,前缀式操作符应返回被增量或减量对象的引用。
为了与内置类型的操作符一致,后缀式操作符应返回旧值(即尚未自增或自减的值),并且应作为值返回,而不是返回引用。
6.7.1. 实例:重载前缀式和后缀式自增操作符
#include <iostream>
using namespace std;
class Time
{
private:
int hours; // 0 to 23
int minutes; // 0 to 59
public:
Time() {
hours = 0;
minutes = 0;
}
Time(int h, int m) {
hours = h;
minutes = m;
}
void displayTime() {
cout << "H: " << hours << " M:" << minutes <<endl;
}
// overloaded prefix ++ operator
Time operator++ () {
++minutes; // increment this object
if(minutes >= 60) {
++hours;
minutes -= 60;
}
return *this; // 前缀形式返回被增量对象的引用
}
// overloaded postfix ++ operator
Time operator++(int) { // 后缀形式有额外的int型形参
// save the orignal value
Time T(hours, minutes);
// increment this object
++minutes;
if(minutes >= 60) {
++hours;
minutes -= 60;
}
// return old original value
return T; // 后缀形式返回尚未自增的旧值
}
};
int main() {
Time T1(11, 59), T2(10,40);
++T1; // increment T1
T1.displayTime(); // display T1
++T1; // increment T1 again
T1.displayTime(); // display T1
T2++; // increment T2
T2.displayTime(); // display T2
T2++; // increment T2 again
T2.displayTime(); // display T2
return 0;
}
参考:http://www.tutorialspoint.com/cplusplus/increment_decrement_operators_overloading.htm
6.8. 不要重载逗号、取地址、逻辑与、逻辑或操作符
默认情况下,取地址操作符(&)和逗号操作符(,)在类类型对象上的执行,与在内置类型对象上的执行一样。取地址操作符返回对象的内存地址,逗号操作符从左至右计算每个表达式的值,并返回最右边操作数的值。
内置逻辑与(&&)和逻辑或(||)操作符使用短路求值。如果重新定义该操作符,将失去操作符的短路求值特征。
总结:重载逗号、取地址、逻辑与、逻辑或等等操作符通常不是好做法。这些操作符具有有用的内置含义,如果我们定义了自己的版本,就不能再使用这些内置含义。
6.9. 重载函数调用操作符(函数对象)
可以为类类型的对象重载函数调用操作符。
#include <iostream>
using namespace std;
struct absInt {
int operator() (int val) {
return val < 0 ? -val : val;
}
};
int main() {
int i = -42;
absInt absObj;
unsigned int ui = absObj(i);
cout << ui << endl;
return 0;
}
尽管 absObj 是一个对象而不是函数,我们仍然可以“调用”该对象,效果是运行由 absObj 对象定义的重载调用操作符,该操作符接受一个 int 值并返回它的绝对值。
函数对象和函数的使用方式是一样的,能用函数的地方也可以使用函数对象。
6.9.1. 函数对象说明(Function Objects or Functors)
定义了调用操作符的类,其对象常称为函数对象(即它们是行为类似函数的对象)。函数对象经常用作通用算法的实参。
Function Objects 又称为 Functors。
Functors are functions with a state. In C++ you can realize them as a class with one or more private members to store the state and with an overloaded operator () to execute the function. Functors can encapsulate C and C++ function pointers employing the concepts templates and polymorphism. You can build up a list of pointers to member functions of arbitrary classes and call them all through the same interface without bothering about their class or the need of a pointer to an instance. All the functions just have got to have the same return-type and calling parameters. Sometimes functors are also known as closures. You can also use functors to implement callbacks.
6.9.2. 实例:函数对象代替函数
先看一个普通的函数指针的例子:
#include <iostream>
#include <string>
#include <vector>
using namespace std;
bool GT6(const string &s) {
return s.size() >= 6;
}
bool GT7(const string &s) {
return s.size() >= 7;
}
int main() {
vector<string> words;
words.push_back("abc");
words.push_back("abcdef");
words.push_back("abcdefg");
words.push_back("qwertyuiop");
cout << count_if(words.begin(), words.end(), GT6)
<< " words 6 characters or longer" << endl; // 3 words 6 characters or longer
cout << count_if(words.begin(), words.end(), GT7)
<< " words 7 characters or longer" << endl; // 2 words 7 characters or longer
return 0;
}
再看使用函数对象的例子:
#include <iostream>
#include <string>
#include <vector>
using namespace std;
class GT_cls {
public:
GT_cls(size_t val = 0): bound(val) { }
bool operator()(const string &s) {
return s.size() >= bound;
}
private:
string::size_type bound;
};
int main() {
vector<string> words;
words.push_back("abc");
words.push_back("abcdef");
words.push_back("abcdefg");
words.push_back("qwertyuiop");
cout << count_if(words.begin(), words.end(), GT_cls(6)) // 把函数指针GT6换成了函数对象GT_cls(6)
<< " words 6 characters or longer" << endl;
cout << count_if(words.begin(), words.end(), GT_cls(7)) // 把函数指针GT7换成了函数对象GT_cls(7)
<< " words 7 characters or longer" << endl;
return 0;
}
在上面使用函数对象的例子中,count_if 调用传递一个 GT_cls 类型的临时对象(用整型值 6 或 7 来初始化那个临时对象)而不再是名为 GT6 或 GT7 的函数。现在,count_if 每次调用它的函数形参时,它都使用 GT_cls 的调用操作符。
从上面的例子中可知, 函数对象比函数更加灵活,不再需要多个功能类似的函数(如例子中 GT6 和 GT7 等等)。
注:我们也可以通过增加一个参数来统一 GT6 和 GT7 等函数,如下:
bool GTn(const string &s, size_t n) {
return s.size() >= n;
}
如何把参数 n 传递给 count_if 呢?通过全局变量来传递显然不太合适,可能的办法是“改进”count_if 函数,让 count_if 也增加一个参数来接收 n。这种方法可行,但也不好,如果我们要计算长度大于 6 而小于 10 的元素个数,是不是又要给 count_if 增加另一个参数呢?显然不合适。
6.9.3. 实例:函数对象可保存状态
下面演示多次调用同一函数对象的例子:
#include <iostream>
class myFunctor1 {
public:
myFunctor1 (int x) : _x(x) {}
int operator() (int y) { return _x + y; }
private:
int _x;
};
class myFunctor2 {
public:
myFunctor2 (int x) : _x(x) {}
int operator() (int y) { _x=_x + y; return _x; } // 重载调用操作符时,修改了对象的状态(数据域)。
private:
int _x;
};
int main() {
myFunctor1 addFive1(5);
std::cout << addFive1(1) << std::endl;
std::cout << addFive1(1) << std::endl;
myFunctor2 addFive2(5);
std::cout << addFive2(1) << std::endl;
std::cout << addFive2(1) << std::endl;
return 0;
}
编译运行上面程序,可得到下面输出:
6 6 6 7
上面程序中,以相同参数多次调用函数对象 addFive1 时,得到的结果相同;而以相同参数多次调用函数对象 addFive2 时,得到的结果不同。这取决于如何重载调用操作符。
6.9.4. 标准库定义的函数对象
标准库定义了一组算术、关系与逻辑函数对象类。这些标准库函数对象类型是在 functional 头文件中定义的,如表 4 所示。
| 函数对象 | 所应用的操作符 |
|---|---|
| plus<Type> | + |
| minus<Type> | - |
| multiplies<Type> | * |
| divides<Type> | / |
| modulus<Type> | % |
| negate<Type> | - |
| equal_to<Type> | == |
| not_equal_to<Type> | != |
| greater<Type> | > |
| greater_equal<Type> | >= |
| less<Type> | < |
| less_equal<Type> | <= |
| logical_and<Type> | && |
| logical_or<Type> | || |
| logical_not<Type> | ! |
实例如下:
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int main() {
vector<string> words;
words.push_back("yabc");
words.push_back("xabcde");
words.push_back("znm");
sort(words.begin(), words.end(), greater<string>()); // 按降序对words进行排序
for (std::vector<string>::const_iterator i = words.begin(); i != words.end(); ++i) {
cout << *i << endl;
}
return 0;
}
上面程序会输出:
znm yabc xabcde
例子中,sort 的第三个实参是一个函数对象(即 greater<string>类型的临时对象)。
6.9.4.1. 函数适配器(Function Adapter)
标准库提供了一组函数适配器,用于特化和扩展一元和二元函数对象。函数适配器分为如下两类:
- 绑定器:它通过将一个操作数绑定到给定值而将二元函数对象转换为一元函数对象。
- 求反器:它将谓词函数对象的真值求反。
标准库定义了两个绑定器适配器:bind1st 和 bind2nd。bind1st 将给定值绑定到二元函数对象的第一个实参,bind2nd 将给定值绑定到二元函数对象的第二个实参。
标准库还定义了两个求反器:not1 和 not2。not1 将一元函数对象的真值求反,not2 将二元函数对象的真值求反。
7. 面向对象编程
面向对象编程基于三个基本概念:数据抽象、继承和动态绑定。在 C++ 中,用类进行数据抽象,用类派生从一个类继承另一个:派生类继承基类的成员。动态绑定使编译器能够在运行时决定是使用基类中定义的函数还是派生类中定义的函数。
7.1. 继承(inheritance)
利用继承可以把相关事物公共的东西共享起来,仅仅特化不同的东西。这样可以减少代码重复。
7.1.1. 继承的例子
// 书店关于书的类
#include <string>
#include <iostream>
using namespace std;
class Item_base {
public:
Item_base(const std::string &book = "", double sales_price = 0.0):
isbn(book), price(sales_price) { }
std::string book() const { return isbn; }
virtual double net_price(std::size_t n) const { return n * price; }
virtual ~Item_base() { }
private:
std::string isbn; // identifier for the item
protected:
double price; // normal, undiscounted price
};
// Bulk为批量购买相关的类
class Bulk : public Item_base {
public:
Bulk(): min_qty(0), discount(0.0) { }
Bulk(const std::string& book, double sales_price,
std::size_t qty = 0, double disc_rate = 0.0):
Item_base(book, sales_price),
min_qty(qty), discount(disc_rate) { }
// redefines base version so as to implement bulk purchase discount policy
double net_price(std::size_t cnt) const {
if (cnt >= min_qty)
return cnt * (1 - discount) * price;
else
return cnt * price;
}
private:
std::size_t min_qty; // 享受折扣的最少购买量
double discount; // 折扣
};
// 输出n本书的价格
void print_total(ostream &os, const Item_base &item, size_t n) {
os << "ISBN: " << item.book() // calls Item_base::book
<< "\tnumber sold: " << n << "\ttotal price: "
<< item.net_price(n) << endl;
// virtual call: which version of net_price to call is resolved at run time
}
int main() {
Item_base base("0-391-85410-4", 10); // 每本10元
Bulk bulk("0-201-82470-1", 10, 50, 0.2); // 每本10元,满50本打8折
print_total(cout, base, 30);
print_total(cout, base, 90);
print_total(cout, bulk, 30);
print_total(cout, bulk, 90);
return 0;
}
/* 程序输出:
ISBN: 0-391-85410-4 number sold: 30 total price: 300
ISBN: 0-391-85410-4 number sold: 90 total price: 900
ISBN: 0-201-82470-1 number sold: 30 total price: 300
ISBN: 0-201-82470-1 number sold: 90 total price: 720
*/
说明:
在 C++ 中,基类必须指出希望派生类重写哪些函数。定义为 virtual 的函数(虚函数)是基类期待派生类重新定义的,基类希望派生类继承的函数不能定义为虚函数。
关于 print_total 有两点值得注意:
第一,虽然这个函数的第二形参是 Item_base 的引用但可以将 Item_base 对象或 Bulk 对象(其类继承自 Item_base)传给它。
第二,因为形参是引用且 net_price 是虚函数,所以对 net_price 的调用将在运行时确定。调用哪个版本的 net_price 将取决于传给 print_total 的实参。
7.1.2. 期望派生类重定义的函数在基类中应声明为虚函数
基类应将期待派生类重定义的函数定义为虚函数。如前面例子中,派生类重定义了 net_price 虚函数。
除构造函数外,任意非 static 成员函数都可以是虚函数。
一旦函数在基类中声明为虚函数,它就一直为虚函数,派生类无法改变该函数为虚函数这一事实。派生类重定义虚函数时,可以使用或者省略 virtual 保留字。
7.1.2.1. 构造函数不能为虚函数
前面说到:除构造函数外,任意非 static 成员函数都可以是虚函数。也就是说构造函数不能为虚函数,如下面的例子是错误的:
class A {
virtual A(); /* 错误的用法(编辑器会报错)!构造函数不能是虚函数。 */
};
为什么构造函数不能为虚函数呢?
A virtual call is a mechanism to get work done given partial information. In particular, "virtual" allows us to call a function knowing only an interfaces and not the exact type of the object. To create an object you need complete information. In particular, you need to know the exact type of what you want to create. Consequently, a "call to a constructor" cannot be virtual.
摘自:Bjarne Stroustrup's C++ Style and Technique FAQ, Why don't we have virtual constructors?
此外,构造函数不应该调用虚函数(从语法角度来说编译器不会报错,但是不建议这么使用),如果构造函数调用了虚函数,那么将会使用构造函数所在类的版本(没有动态绑定)。
参考:https://stackoverflow.com/questions/962132/calling-virtual-functions-inside-constructors
7.1.3. protected 成员可以被派生类访问
派生类中可以直接访问基类的 protected 成员。类访问标号的含义如表 5 所示。
| 访问标号 | 可以从类外访问 | 可以从派生类访问 |
|---|---|---|
| public | Yes | Yes |
| protected | No | Yes |
| private | No | No |
注意:派生类只能通过派生类对象访问其基类的 protected 成员,派生类对其基类类型对象的 protected 成员没有特殊访问权限。
如下面实例,memfcn 是派生类成员函数,也不能通过 b(基类类型对象)来访问 price(基类的 protected 成员)。
void Bulk::memfcn(const Bulk_item &d, const Item_base &b) {
double ret = price; // ok: 直接使用基类中的protected成员
ret = d.price; // ok: 通过派生类对象使用基类中的protected成员
ret = b.price; // error: no access to price from an Item_base
}
7.1.4. 公用、受保护和私有继承
为了定义派生类,使用类派生列表指定基类。类派生列表指定了一个或多个基类(多个基类之间用逗号分开),具体如下形式:
class classname: access-label base-class [, access-label base-class]
这里 access-label 是 public、protected 或 private,分别代表公用、受保护和私有继承。其中公用继承的使用最常见。
- 如果是公用继承,基类成员保持自己的访问级别:基类的 public 成员为派生类的 public 成员,基类的 protected 成员为派生类的 protected 成员。
- 如果是受保护继承,基类的 public 和 protected 成员在派生类中为 protected 成员。
- 如果是私有继承,基类的的所有成员在派生类中为 private 成员。
公用、受保护和私有继承对派生类的影响如表 6 所示。
| 基类成员 | 公用继承 | 受保护继承 | 私有继承 |
|---|---|---|---|
| public | public | protected | private |
| protected | protected | protected | private |
| private | 不被继承 | 不被继承 | 不被继承 |
7.1.5. 派生类对象包含基类对象作为子对象
派生类对象由多个部分组成:派生类本身定义的成员加上由基类成员组成的子对象。
如果基类定义 static 成员,则整个继承层次中只有一个这样的成员。无论从基类派生出多少个派生类,每个 static 成员只有一个实例。
7.1.6. 友元关系不能继承
每个类控制对自己的成员的友元关系。友元关系不能继承。
第一,基类的友元对派生类的成员没有特殊访问权限;
第二,如果基类被授予友元关系,则只有基类具有特殊访问权限,该基类的派生类不能访问授予友元关系的类。
如:
class Base {
friend class Frnd;
protected:
int i;
};
// Frnd has no access to members in D1
class D1 : public Base {
protected:
int j;
};
class Frnd {
public:
int mem(Base b) { return b.i; } // ok: Frnd is friend to Base
int mem(D1 d) { return d.i; } // error: 基类的友元对派生类的成员没有特殊访问权限
};
// D2 has no access to members in Base
class D2 : public Frnd {
public:
int mem(Base b) { return b.i; } // error: 如果基类被授予友元关系,则只有基类具有特殊访问权限,该基类的派生类不能访问授予友元关系的类。
};
7.2. 动态绑定(虚函数+基类引用或指针)
动态绑定使编译器能够在运行时决定是使用基类中定义的函数还是派生类中定义的函数。
C++ 中的函数调用默认不使用动态绑定。要触发动态绑定,满足两个条件:
第一,只有指定为虚函数的成员函数才能进行动态绑定,成员函数默认为非虚函数,非虚函数不进行动态绑定;
第二,必须通过基类类型的引用或指针进行函数调用。
如前面例子中的 print_total 函数中对 item.net_price 的调用会使用动态绑定,因为 item 形参是一个基类引用且 net_price 是虚函数。
void print_total(ostream &os, const Item_base &item, size_t n) {
os << "ISBN: " << item.book() // calls Item_base::book
<< "\tnumber sold: " << n << "\ttotal price: "
<< item.net_price(n) << endl;
// virtual call: which version of net_price to call is resolved at run time
}
7.2.1. 强制使用虚函数特定版本(作用域操作符)
在某些情况下,希望覆盖虚函数机制并强制函数调用使用虚函数的特定版本,这时可以使用基类类名加上作用域操作符:
Item_base *baseP = &derived; // calls version from the base class regardless of the dynamic type of baseP double d = baseP->Item_base::net_price(42); // 强制将net_price调用确定为Item_base中定义的版本
在派生类虚函数调用其基类版本时,常常显式使用作用域操作符。
7.3. 派生类中的构造函数和复制控制
构造函数和复制控制成员不能继承,每个类定义自己的构造函数和复制控制成员。像任何类一样,如果类不定义自己的默认构造函数和复制控制成员,就将使用编译器自动合成的版本。
7.3.1. 派生类构造函数
每个派生类构造函数除了初始化自己的数据成员之外,还要初始化基类。
7.3.1.1. 合成的派生类默认构造函数
派生类的合成默认构造函数与非派生的构造函数只有一点不同:除了初始化派生类的数据成员之外,它还初始化派生类对象的基类部分。基类部分由基类的默认构造函数初始化。
对于前面例子中 Bulk 类,合成的默认构造函数会这样执行:
首先:调用 Item_base 的默认构造函数,将 isbn 成员初始化空串,将 price 成员初始化为 0。
然后:用常规变量初始化规则初始化 Bulk 的成员,也就是说,内置类型成员 qty 和 discount 会是未初始化的。
7.3.1.2. 定义默认构造函数
因为 Bulk 具有内置类型成员,所以应定义自己的默认构造函数:
class Bulk : public Item_base {
public:
Bulk(): min_qty(0), discount(0.0) { }
// as before
};
这个构造函数使用构造函数初始化列表初始化 min_qty 和 discount 成员,由于没有在初始化列表中指定基类的构造函数,该构造函数还会 隐式调用 Item_base 的默认构造函数 初始化对象的基类部分。如果在初始化列表中指定了基类的构造函数,则调用指定的基类构造函数(可能不是默认构造函数)。
7.3.1.3. 只能初始化直接基类
一个类只能初始化自己的直接基类。直接就是在派生列表中指定的类。如果类 C 从类 B 派生,类 B 从类 A 派生,则 B 是 C 的直接基类。虽然每个 C 类对象包含一个 A 类部分,但 C 的构造函数不能直接初始化 A 部分。相反,需要类 C 初始化类 B,而类 B 的构造函数再初始化类 A。
7.3.2. 复制控制和继承
类是否需要定义复制控制成员完全取决于类自身的直接成员。基类可以定义自己的复制控制而派生类使用合成版本,反之亦然。
只包含类类型或内置类型数据成员、不含指针的类一般可以使用合成操作,复制、赋值或撤销这样的成员不需要特殊控制。具有指针成员的类一般需要定义自己的复制控制来管理这些成员。
7.3.2.1. 定义派生类复制构造函数(应显式负责基类部分)
如果派生类显式定义自己的复制构造函数或赋值操作符,则该定义将完全覆盖默认定义。
如果派生类定义了自己的复制构造函数,该复制构造函数应显式使用基类复制构造函数初始化对象的基类部分。 如:
class Base { /* ... */ };
class Derived: public Base {
public:
// Base::Base(const Base&) not invoked automatically
Derived(const Derived& d):
Base(d) /* other member initialization */ { /*... */ }
};
初始化函数 Base(d)将派生类对象 d 转换为它的基类部分的引用,并调用基类复制构造函数。
7.3.2.2. 定义派生类赋值操作符(应显式负责基类部分)
赋值操作符通常与复制构造函数类似:如果派生类定义了自己的赋值操作符,则该操作符必须对基类部分进行显式赋值。
// Base::operator=(const Base&) not invoked automatically
Derived &Derived::operator=(const Derived &rhs) {
if (this != &rhs) {
Base::operator=(rhs); // assigns the base part
// do whatever needed to clean up the old value in the derived part
// assign the members from the derived
}
return *this;
}
7.3.2.3. 派生类析构函数(只需负责自身部分)
析构函数的工作与复制构造函数和赋值操作符不同:派生类析构函数不负责撤销基类对象的成员。编译器总是显式调用派生类对象基类部分的析构函数。每个析构函数只负责清除自己的成员。
7.3.3. 虚析构函数
为什么要有虚析构函数?
如果删除基类指针,则需要运行基类析构函数并清除基类的成员,如果对象实际是派生类型的,则没有定义该行为。
这种情况下(即当通过基类指针删除派生类对象时),为了保证运行适当的析构函数,基类中的析构函数必须为虚函数。
像其他虚函数一样,析构函数的虚函数性质都将继承。即如果层次中根类的析构函数为虚函数,则派生类析构函数也将是虚函数,无论派生类显式定义析构函数还是使用合成析构函数,派生类析构函数都是虚函数。
总结:如果一个类用作基类,那么它的析构函数应该声明为虚函数。
7.3.3.1. 三法则的例外情况
三法则指出,如果类需要析构函数,则它往往也需要复制构造函数和赋值操作符。
基类析构函数是三法则的一个重要例外。
即使析构函数没有工作要做,继承层次的根类也应该定义一个虚析构函数。但这并不表示也需要赋值操作符或复制构造函数。
7.3.4. 构造函数或析构函数中调用虚函数(动态绑定会无效)
如果在构造函数或析构函数中调用(或通过其它函数间接调用)虚函数,则动态绑定会无效,运行的是构造函数或析构函数自身类型定义的版本。
为什么编译器要这样做?
运行构造函数或析构函数的时候,对象都是不完整的(可能还没构造好,可能已经部分撤消)。
考虑如果从基类构造函数(或析构函数)调用虚函数的派生类版本会怎么样。虚函数的派生类版本很可能会访问派生类对象的成员。但是,对象的派生部分的成员不会在基类构造函数运行期间初始化。
7.4. 纯虚函数和抽象基类
A pure virtual function is a virtual function whose declaration ends in "= 0":
class Base {
// ...
virtual void f() = 0; // pure virtual funciton
// ...
};
int main() {
Base obj; // 出错。因为不能实例化抽象基类!
return 0;
}
含有(或继承)一个或多个纯虚函数的类称为抽象基类(abstract base class)。抽象基类不能实例化。
纯虚函数的用处:
Pure virtual helps ensure the derived classes do not forget to redefine functions that the base class was expecting them to.
7.5. 覆盖(override)、重载(overload)和隐藏(hide)的区别
覆盖(override)是指派生类中函数覆盖基类中的虚函数。特征如下:
一、不同的范围(分别位于派生类与基类中);
二、函数名字相同;
三、参数相同;
四、基类函数必须有 virtual 关键字。
备注:要实现基于虚函数的多态就必须在派生类中覆盖基类的虚函数。为什么取名为覆盖(override)呢?参见节 7.7.1
重载(overload)函数是指在同一个作用域中的多个函数,它们具有相同的名字而形参表不同。特征如下:
一、相同的范围(如同一个类中);
二、函数名字相同;
三、参数不同;
四、virtual 关键字可有可无。
隐藏(hide)是指派生类的函数屏蔽了与其同名的基类函数。特征如下:
一、如果派生类的函数与基类的函数同名,但是参数不同。此时无论有无 virtual 关键字,基类的函数将被隐藏(注意不要与重载混淆);
二、如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有 virtual 关键字,此时,基类的函数被隐藏(注意不要与覆盖混淆)。
备注:我们要尽量避免出现隐藏。出现隐藏时,可以使用作用域操作符访问被隐藏的基类函数(或数据成员)。
7.6. 多重继承和虚继承
大多数应用程序使用单个基类的公用继承,但是,在某些情况下单继承是不够用的。
多重继承示例图,如:
+-------------+ +------------+
| Bear | | Endangered |
+-------------+ +------------+
^ ^
| |
| |
+-------------+
| Panda |
+-------------+
7.6.1. 虚继承(解决 The Diamond Problem)
在常规多重继承下,一个基类可以在派生层次中出现多次。
如果 IO 类型使用常规继承,则每个 iostream 对象可能包含两个 ios 子对象:一个包含在它的 istream 子对象中,另一个包含在它的 ostream 子对象中,从设计角度讲这个是错误的:因为 iostream 类仅想对单个缓冲区进行读和写。
在 C++ 中,通过使用虚继承解决这类问题。虚继承是一种机制,类通过虚继承指出它希望共享其虚基类的状态。 在虚继承下,对给定虚基类,无论该类在派生层次中作为虚基类出现多少次,只继承一个共享的基类子对象。 共享的基类子对象称为虚基类(virtual base class)。
通过用关键字 virtual 修改声明,可将基类指定为通过虚继承派生,这时派生类中它们的公共基类部分仅有一个。
// the order of the keywords public and virtual is not significant
class istream : public virtual ios { ... };
class ostream : virtual public ios { ... };
// iostream inherits only one copy of its ios base class
class iostream: public istream, public ostream { ... };
参考:
https://en.wikipedia.org/wiki/Multiple_inheritance#The_diamond_problem
7.7. 利用虚函数表实现动态绑定
A virtual method table (or virtual function table, virtual call table, dispatch table, vtable, or vftable) is a mechanism used in a programming language to support dynamic dispatch (or run-time method binding).
说明:关于虚函数表的具体实现不同编译器很可能不一样,下面的说明仅是“原理性的”。
如果一个类含有虚函数,则这个类会有一个虚函数表,它保存着当前类所有虚函数的地址。
假设类 B 的声明如下:
class B {
public:
virtual int f1();
virtual void f2(int);
virtual int f3(int);
};
那么,类 B 对象的内存模型如图 2 所示。其中,bp 是类 B 对象的指针,vtbl 就是虚函数表,而 vptr 是指向虚函数表的指针。
Figure 2: 类 B 对象的内存模型
“A virtual table is per class.” 同一类型的对象可以共用一个虚函数表,没必要为每个对象生成一个虚函数表(不过,严格来说依赖于实现)。
对虚函数的调用会查找 vtbl,如:
B *bp = new B; bp->f3(12);
会被编译器翻译为类似下面的代码:
B *bp = new B; (*(bp->vptr)[2])(bp, 12); // f3在vtbl中的下标为2
上面介绍了虚函数表的基本概念,如何利用它来实现动态绑定呢?请看下文。
参考:
Gotcha #78: Failure to Grok Virtual Functions and Overriding: http://www.icodeguru.com/cpp/CppGotchas/0321125185_ch07lev1sec10.html
7.7.1. 单继承下的虚函数表
考虑下面继承关系。
class B {
public:
virtual int f1();
virtual void f2(int);
virtual int f3(int);
};
class D : public B {
int f1(); // override
virtual void f4();
int f3(int); // override
};
类 D 对象的内存模型如图 3 所示。
Figure 3: 类 D 对象(它单继承于类 B)的内存模型
注意, 基类 B 中没有被子类 D 覆盖的虚函数(如 f2)会直接出现在子类 D 的虚函数表中。
对虚函数的调用是通过查找 vtbl,如:
B *bp = new D; bp->f2(11); bp->f3(12);
会被编译器翻译为类似下面的代码:
B *bp = new D; (*(bp->vptr)[1])(bp, 11); // 在这个例子的虚函数表中,对应函数B::f2 (*(bp->vptr)[2])(bp, 12); // 在这个例子的虚函数表中,对应函数D::f3
当然,下面的写法看起来更像多态。
B *bp = getSomeSortOfB(); // 这里,并不知道bp会指向B的哪个子类对象(比如D1或D2等等),或者基类B的对象。
bp->f2(11); // 不过,不管bp指向B的哪个子类对象,通过这个对象的虚函数表总可以找到合适的f2。
// 编译时,函数bp->f2的地址就确定了,这个例子中是虚函数表中下标为1的位置;
// 虚函数表中下标为1的位置上具体是哪个函数在编译时是不确定的,它可能是B::f2,
// 也可能是B类的任意子类中的虚函数f2。这就是虚函数表实现动态绑定的原理。
bp->f3(12); // 和上面分析类似。
通过上面的分析,我们可以知道多态中“覆盖(override)”这个名词的形象解释:
Mechanically speaking, overriding is the process of replacing the address of a base class member function with the address of a derived class member function when constructing a virtual function table for a derived class.
7.7.2. 多继承下的虚函数表
关于多继承下的虚函数表,这里不介绍,请参考:Gotcha #78: Failure to Grok Virtual Functions and Overriding
8. 模板与泛型编程
所谓泛型编程就是以独立于任何特定类型的方式编写代码。模板是泛型编程的基础。
8.1. 函数模板
模板定义以关键字 template 开始,后接模板形参表,模板形参表是用尖括号括住的一个或多个模板形参的列表,形参之间以逗号分隔。
使用函数模板时,编译器会推断哪个(或哪些)模板实参绑定到模板形参。一旦编译器确定了实际的模板实参,就称它实例化了函数模板的一个实例。
#include<iostream>
using namespace std;
// implement strcmp-like generic compare function
// returns 0 if the values are equal, 1 if v1 is larger, -1 if v1 is smaller
template <typename T> // 也可写为 template <class T>
int compare(const T &v1, const T &v2) {
if (v1 < v2) return -1;
if (v2 < v1) return 1;
return 0;
}
int main () {
// T is int;
// compiler instantiates int compare(const int&, const int&)
cout << compare(1, 0) << endl;
// T is string;
// compiler instantiates int compare(const string&, const string&)
string s1 = "hi", s2 = "world";
cout << compare(s1, s2) << endl;
return 0;
}
说明:在函数模板中,编译器一般能根据函数实参确定模板实参,所以调用时不用为模板形参指定实参。
但显式指定也是合法的,如:
int main () {
cout << compare<int>(1, 0) << endl; // 显示指定了函数模板的实参为int
string s1 = "hi", s2 = "world";
cout << compare<string>(s1, s2) << endl; // 显示指定了函数模板的实参string
return 0;
}
8.2. 类模板
就像可以定义函数模板一样,也可以定义“类模板”。
#ifndef MYARRAY_H
#define MYARRAY_H
template <typename T, size_t N> // 也可写为 template <class T, size_t N>
class MyArray {
private:
T m_ptData[N];
public:
T& operator[](int nIndex) {
return m_ptData[nIndex];
}
int GetBuffer(); // templated GetBuffer() function defined below
};
template <typename T, size_t N>
int MyArray<T,N>::GetBuffer() { return m_ptData; }
#endif
与调用函数模板不同,使用类模板时,必须为模板形参显式指定实参:
MyArray<int, 12> anArray;
参考:http://www.learncpp.com/cpp-tutorial/143-template-classes/
8.3. 类型别名模板
节 2.5.1 中介绍了“类型别名”,“类型别名”也可以模板化,如:
template <typename T> using Vec = std::vector<T>; // Vec 是类型别名 Vec<int> v; // 相当于 std::vector<int>
8.4. 变量模板
8.5. 模板声明
像其他任意函数或类一样,模板也可以只声明而不定义。声明必须指出函数或类是一个模板:
// declares compare but does not define it template <class T> int compare(const T&, const T&);
8.6. 模板特化(Template Specialization)
为什么需要模板特化?
我们并不总是能够写出对所有可能被实例化的类型都最合适的模板。某些情况下,通用模板定义对于某个类型可能是完全错误的,通用模板定义也许不能编译或者做错误的事情;另外一些情况下,可以利用关于类型的一些特殊知识,编写比从模板实例化来的函数更有效率的函数。
通过模板特化,可以使编译器优先使用我们对指定类型模板形参的特化版本。函数模板特化和类模板特化比较类似,下面仅介绍函数模板特化。
8.6.1. 函数模板特化
函数模板特化的形式如下:
- 关键字 template 后面接一对空的尖括号(<>);
- 再接模板名和一对尖括号,尖括号中指定这个特化定义的模板形参;
- 函数形参表;
- 函数体。
如:
template <>
int compare<const char*>(const char* const &v1, // 尖括号中指定这个特化定义的模板形参
const char* const &v2) {
return strcmp(v1, v2);
}
现在,当调用 compare 函数的时候,传给它两个字符指针,编译器将调用特化版本。编译器将为任意其他实参类型(包括普通 char*)调用泛型版本。
const char *cp1 = "world", *cp2 = "hi"; int i1, i2; compare(cp1, cp2); // calls the specialization compare(i1, i2); // calls the generic version instantiated with int
8.7. 可变参数模板(Variadic Template)
可变参数模板(variadic template)就是一个接受“可变数目参数”的模板函数或模板类。 可变数目的参数被称为参数包(parameter packet)。存在两种参数包:1、模板参数包(template parameter packet),表示零个或多个模板参数;2、函数参数包(function parameter packet),表示零个或多个函数参数。
Parameter Packet 使用三个点( ... )来表示。如:
#include <iostream> template <typename T, typename... Args> // Args 表示零个或多个模板类型参数,也可以是 class... Args void foo(const T &t, const Args& ... rest); // rest 表示零个或多个函数参数
声明了 foo 是一个可变参数函数模板,它有一个名为 T 的类型参数,和一个名为 Args 的模板参数包,这个包表示零个或多个额外的类型参数。 foo 的函数参数列表包含一个 const & 类型的参数,指向 T 的类型,还包含一个名为 rest 的函数参数包,此包表示零个或多个函数参数。
给定下面的调用:
int i = 0; double d = 3.14; std::string s = "how now brown cow";
foo(i, s, 42, d); // parameter packet 中有三个参数
foo(s, 42, "hi"); // parameter packet 中有两个参数
foo(d, s); // parameter packet 中有一个参数
foo("hi"); // parameter packet 是空包
编译器会为 foo 实例化出四个不同的版本:
void foo(const int&, const string&, const int&, const double&); void foo(const string&, const int&, const char[3]&); void foo(const double&, const string&); void foo(const char[3]&);
在每个实例中, T 的类型是从第一个实参的类型推断出来的,剩下的实参提供函数额外实参的数目和类型。
8.7.1. sizeof... 运算符
当我们需要知道包中有多少元素时,可以使用 sizeof... 运算符。类似 sizeof , sizeof... 也返回一个常量表达式,而且不会对其实参求值:
#include <iostream>
template <typename T, typename... Args>
void foo(const T &t, const Args& ... rest) {
std::cout << "func foo called" << std::endl;
std::cout << "sizeof...(Args)=" << sizeof...(Args) << std::endl;
std::cout << "sizeof...(rest)=" << sizeof...(rest) << std::endl;
}
int main() {
int i = 0; double d = 3.14; std::string s = "how now brown cow";
foo(i, s, 42, d);
foo(d, s);
return 0;
}
8.7.2. 编写可变参数函数模板
下面介绍如何编写可变参数函数模板。我们以一个名为 print 的函数为例进行介绍,它在一个给定的流上打印给定实参列表的内容。
在 C++11 中,可变参数函数通常是递归的。第一步调用处理包中的第一个实参,然后用剩余实参调用自身。我们的 print 函数也是这样的模式,每次递归调用将第二个实参打印到第一个实参表示的流中。为了终止递归,我们还需要定义一个非可变参数的 print 函数,它接受一个流和一个对象:
// 用来终止递归并打印最后一个元素的函数
// 此函数必须在可变参数版本的 print 定义之前声明
template<typename T>
ostream &print(ostream &os, const T &t) {
return os << t ; // 包中最后一个元素之后不打印分隔符
}
// 包中除了最后一个元素之外的其他元素都会调用这个版本的 print
template <typename T, typename... Args>
ostream &print(ostream &os, const T &t, const Args&... rest) {
os << t <<","; // 打印第一个实参
return print(os, rest...); // 递归调用,打印其他实参。 rest... 是展开 packet,后面会介绍
}
我们的可变参数版本的 print 函数接受三个参数:一个 ostream& ,一个 const T& 和个参数包。而此调用只传递了两个实参。其结果是 rest 中的第一个实参被绑定到 t ,剩余实参形成下一个 print 调用的参数包。因此,在每个调用中,包中的第一个实参被移除,成为绑定到 t 的实参。比如,给定
print(cout, i, s, 42); // parameter packet 中有两个参数
递归会执行如下:
call t rest...
----------------------------------------------------
print(cout, i, s, 42); i s, 42
print(cout, s, 42); s 42
print(cout, 42); 调用非可变参数版本的 print
前两个调用只能与可变参数版本的 print 匹配,非可变参数版本是不可行的,因为这两个调用分别传递四个和三个实参,而非可变参数 print 只接受两个实参。
对于最后一次递归调用 print(cout, 42) ,两个 print 版本都是可行的。对于最后一个调用,两个函数提供同样好的匹配。但是, 非可变参数模板比可变参数模板更特例化,因此编译器选择非可变参数版本。
8.7.3. 展开 parameter packet
对于一个参数包,除了获取其大小外,我们能对它做的唯一的事情就是展开(expand)它。展开一个包就是将它分解为构成的元素,对每个元素应用模式,获得展开后的列表。我们通过在模式右边放一个省略号( ... )来触发展开操作。如上节介绍的 print 例子包含两个展开:
template <typename T, typename... Args>
ostream &print(ostream &os, const T &t, const Args&... rest) { // 展开 Args
os << t <<",";
return print(os, rest...); // 展开 rest
}
8.7.4. 转发 parameter packet
我们可以组合使用可变参数模板与 forward 机制来编写函数,实现将其“实参”不变地传递给其他函数。
8.7.5. Fold expression
在 C++17 中,增加了 Fold expression,可以大大简化“可变参数函数模板”的编写。
在 C++11 中,要编写一个求和的“可变参数函数模板”,你必须同时也定义一个非可变参数的函数。如,可以这样写:
auto SumCpp11() {
return 0;
}
template<typename T1, typename... Args>
auto SumCpp11(T1 s, Args... ts) {
return s + SumCpp11(ts...);
}
在 C++17 中,由于引入了 Fold expression,上面的代码可以简化为:
template<typename ...Args>
auto sum(Args ...args) {
return (args + ... + 0);
}
或者:
template<typename ...Args>
auto sum2(Args ...args) {
return (args + ...);
}
一共有表 7 所示的 4 种形式的 Fold expression。
| Fold expression | Becomes | |
|---|---|---|
| unary right fold | ( E op ...) | \((E_1 op (... op (E_{N-1} op E_{N})))\) |
| unary left fold | ( ... op E ) | \((((E_1 op E_2) op ...) op E_N)\) |
| binary right fold | ( E op ... op I) | \((E_1 op (... op (E_{N−1} op (E_N op I))))\) |
| binary left fold | ( I op ... op E ) | \(((((I op E_1) op E_2) op ...) op E_N)\) |
如果 parameter packet 为空,则有表 8 所示规则。
| OPERATOR | DEFAULT VALUE |
|---|---|
| && | true |
| || | false |
| , | void() |
如:
#include <iostream>
template<typename... Args>
bool all(Args... args) {
return (... && args); // parameter packet 为空的话, && 会为 false
}
template<typename... Args>
bool any(Args... args) {
return (... || args); // parameter packet 为空的话, || 会为 false
}
int main() {
std::cout << std::boolalpha;
std::cout << all(true, true, true, false) << std::endl;
std::cout << any(true, true, true, false) << std::endl;
std::cout << all() << std::endl; // true
std::cout << any() << std::endl; // false
return 0;
}
9. 异常处理
通过异常我们能够将问题的检测和问题的解决分离。
使用异常的好处:Using exceptions for error handling makes your code simpler, cleaner, and less likely to miss errors.
参考:
Exceptions and Error Handling: https://isocpp.org/wiki/faq/exceptions
9.1. throw 表达式和 try/catch 块
throw 表达式用来引发(raise)异常条件,错误检测部分使用它来说明遇到了不可处理的错误。
try/catch 块用来捕获和处理异常,在 try 块中执行的代码所抛出的异常,通常会被其中一个 catch 子句处理。
try/catch 块的通用语法形式为:
try {
program-statements
} catch (exception-specifier) {
handler-statements
} catch (exception-specifier) {
handler-statements
}
实例:
#include <iostream>
using namespace std;
void func1() {
throw 101;
}
int main() {
int val;
try {
func1();
} catch (int e) {
cerr << "Error " << e << " happened" << endl;
}
return 0;
}
// 程序会输出: Error 101 happened
9.2. 异常处理过程
抛出异常的时候(异常由 throw 引发),将停止当前函数的执行,开始查找匹配的 catch 子句。首先检查 throw 本身是否在 try 块内部,如果是,检查与该 catch 相关的 catch 子句,看是否其中之一与抛出对象相匹配。如果找到匹配的 catch,就处理异常;如果找不到,就退出当前函数(释放当前函数的内存并撤销局部对象,自动调用析构函数),并且继续在调用函数(caller)中按类似的方式查找。直到为异常找到一个匹配的 catch 子句(这个过程称为 stack unwinding)。找到后就进入该 catch 子句,并在该处理代码中继续执行。如果异常发生时,在当前函数及函数调用链中更上层的函数中都找不到匹配的 catch 语句,则程序会调用库函数 std::terminate 。
抛出异常后,控制权不会再回到抛出异常的地方。
9.2.1. 查找匹配的 catch 子句
在查找匹配的 catch 期间,找到的 catch 不必是与异常最匹配的那个 catch,相反,将选中第一个找到的可以处理该异常的 catch。因此,在 catch 子句列表中,最特殊的 catch 必须最先出现。
异常与 catch 异常说明符匹配的规则比匹配实参和形参类型的规则更严格 ,大多数转换都不允许——除下面几种可能的区别之外,异常的类型与 catch 说明符的类型必须完全匹配:
• 允许从非 const 到 const 的转换。也就是说,非 const 对象的 throw 可以与指定接受 const 引用的 catch 匹配。
• 允许从派生类型型到基类类型的转换。
• 将数组转换为指向数组类型的指针,将函数转换为指向函数类型的适当指针。
在查找匹配 catch 的时候,不允许其他转换。具体而言,既不允许标准算术转换,也不允许为类类型定义的转换。
9.2.2. 抛出类类型的异常
异常是通过 throw 对象而引发的。由于在处理异常时会释放局部存储,所以被抛出的对象就不能再局部存储,而是用 throw 表达式初始化一个称为异常对象的特殊对象。异常对象由编译器管理,而且保证驻留在可能被激活的任意 catch 都可以访问的空间。这个对象由 throw 创建,并被初始化为被抛出的表达式的副本。异常对象将传给对应的 catch,并且在完全处理了异常之后撤销。
异常对象通过复制被抛出表达式的结果创建,该结果必须是可以复制的类型。
9.2.3. 重新抛出异常(空 throw 语句)
catch 语句中可以通过重新抛出将异常传递给函数调用链中更上层的函数。重新抛出的语法是一个空 throw 语句:
throw;
注意:空 throw 语句中能出现在 catch 或者从 catch 调用的函数中,如果在异常处理代码不活动时遇到空 throw 语句,将调用 terminate 函数。
9.2.4. 捕获所有异常(catch 三个点)
捕获所有异常的 catch 子句形式为(...),如:
// matches any exception that may be thrown
catch(...) {
//
}
9.3. 析构函数不要抛出异常
我们知道异常处理时,在栈展开时会撤销局部对象(自动调用析构函数),如果这个过程中执行析构函数时又抛出异常。应该怎么处理呢?是忽略析构函数中的异常接着处理之前未处理完的异常?还是忽略之前异常,处理析构函数中的异常?显然都不合适。
在为某个异常进行栈展开的时候,析构函数如果又抛出自己的未经处理的另一个异常,将会导致调用 std::terminate 函数。一般而言,std::terminate 函数将调用 std::abort 函数,强制从整个程序非正常退出。
测试如下:
include <iostream>
using namespace std;
class A
{
public:
A() { cout << "A constructor called" << endl; }
~A() {
cout << "A destructor called" << endl;
throw 202; // 在析构函数中抛出异常,这是危险的用法!
}
};
void func1();
int main() {
int val;
try {
func1();
} catch (int e) {
cerr << "Error " << e << " happened" << endl;
}
return 0;
}
void func1() {
A obja; // 这个局部对象会在异常处理时,进行栈展开时被撤销。
throw 101;
}
上面程序在处理异常(throw 101)时会撤销局部对象 obja,调用析构函数~A(),但析构函数又抛出了异常(throw 202),这会导致程序异常中止:
A constructor called A destructor called terminate called after throwing an instance of 'int' Aborted
所以,在实践中要求析构函数永远不要抛出异常。标准库类型都保证它们的析构函数不会引发异常。
9.4. 构造函数抛出异常前要释放资源
与析构函数不同,构造函数内部所做的事情经常会抛出异常。如果在构造函数对象的时候发生异常,则该对象可能只是部分被构造,它的一些成员可能已经初始化,而另一些成员在异常发生之前还没有初始化。
如果对象没有完全构造出来,只是部分被构造,C++ 不会为它调用析构函数。 因为这很难做到,可能的办法是在每个对象里加入一些字节来标记构造函数执行了多少步,析构函数检测这些字节来判断该执行哪些操作。但这会影响到效率,C++ 没有这么做。
所以,我们在构造函数中出现异常,导致对象无法完整地被构造时,需要在继续传递异常前自己释放已经分配的资源。
如:
BookEntry::BookEntry() {
try {
theImage = new Image();
theAudioClip = new AudioClip();
}
catch (...) { // 捕获所有异常
delete theImage;
delete theAudioClip;
throw; // 继续传递异常
}
}
参考:More Effective C++, Item M10:在构造函数中防止资源泄漏
9.5. 异常声明
9.5.1. 用 throw 声明异常类型(已过时的特性)
In older C++ code, you may find exception specifications. For example:
void f(int) throw(Bad, Worse); // 声明抛出Bad或者Worse类型的异常 void g(int) throw(); // 声明不抛出异常
This feature has not been a success and is deprecated in C++11. Don’t use it.
9.5.2. noexcept 修饰符(阻止异常的扩散)
C++11 中,废弃了上一节中介绍的使用 throw 来声明函数可能抛出异常的方式。引入了 noexcept 修饰符,表示其修饰的函数不会抛出异常。 如果 noexcept 修饰的函数抛出了异常,编译器可以选择直接调用 std::terminate() 函数来终止程序的运行。
从语法上讲, noexcept 修饰符有两种形式,一种就是简单地在函数声明后加上 noexcept 关键字,比如:
void excpt_func() noexcept;
还有一种形式是 noexcept 可以接受一个常量表达式作为参数,如:
void excpt_func() noexcept(常量表达式);
常量表达式的结果会被转换成一个 bool 类型的值,如果该值为 true ,表示函数不会抛出异常,反之,则有可能抛出异常。前面介绍的 不带常量表达式的 noexcept 相当于声明了 noexcept(true) ,即不会抛出异常。
在通常情况下,在 C++11 中使用 noexcept 可以有效地阻止异常的传播与扩散。请看下面例子:
1: #include <iostream> 2: 3: using namespace std; 4: 5: void NoBlockThrow() { 6: throw 1; 7: } 8: 9: void BlockThrow() noexcept { 10: throw 1; 11: } 12: 13: int main() { 14: try { 15: throw 1; 16: } catch(...) { 17: cout << "Found throw, line: " << __LINE__ << endl; 18: } 19: 20: try { 21: NoBlockThrow(); 22: } catch(...) { 23: cout << "Found throw, line: " << __LINE__ << endl; 24: } 25: 26: try { 27: BlockThrow(); // BlockThrow 用 noexcept 修饰了,但它却拋出了异常,这将导致程序调用 28: // std::terminate 而退出 29: } catch(...) { // 这个catch语句中的代码不会执行,因为上一行会导致程序调用 std::terminate 30: // 中断程序的执行,从而阻止了异常的继续传播 31: cout << "Found throw, line: " << __LINE__ << endl; 32: } 33: 34: return 0; 35: }
编译运行上面程序,测试如下:
$ c++ -std=c++11 test.cpp -o test $ ./test Found throw, line: 17 Found throw, line: 23 libc++abi.dylib: terminating with uncaught exception of type int Abort trap: 6
虽然 noexcept 修饰的函数抛出异常时通过 std::terminate 的调用来结束程序的执行的方式可能会带来很多问题,比如无法保证对象的析构函数的正常调用,无法保证栈的自动释放等,但很多时候,“暴力”地终止整个程序确实是很简单有效的做法。事实上, noexcept 被广泛地、系统地应用在 C++11 的标准库中,用于提高标准库的性能,以及满足一些阻止异常扩散的需求。
C++11 中,类的析构函数默认是 noexcept(true) 的。当然,如果程序员显式地为析构函数指定了 noexcept(false) ,或者类的基类成员有 noexcept(false) 的析构函数,析构函数就不会再保持默认值。
9.5.3. noexcept 操作符
noexcept 除了是个修饰符外(noexcept specifier),还可以是操作符(noexcept operator)。
当 noexcept 用作操作符时,它接受一个表达式作为参数,如果表达式是可能抛出异常的表达式,则操作符的返回值是 false ,反之为 true 。如:
#include <iostream>
void fun1 ();
void fun2 () noexcept;
int main() {
std::cout << std::boolalpha << noexcept(fun1()) << std::endl; // 输出 false
std::cout << std::boolalpha << noexcept(fun2()) << std::endl; // 输出 true
return 0;
}
当 noexcept 作为一个操作符时,通常用于模板。如:
template <class T>
void fun() noexcept(noexcept(T())) {}
// ^ ^
// | |
// 是修饰符 是操作符
9.6. Function try-Blocks(可以捕获初始化列表中的异常)
The body of a function can be a try-block. For example:
int main() try
{
// ... do something ...
}
catch (...) {
// ... handle exception ...
}
对于普通函数来说上面形式没太多用。 对于构造函数来说它很有用,因为它可以捕获初始化列表中的异常!
class X {
vector<int> vi;
vector<string> vs;
// ...
public:
X(int,int);
// ...
};
X::X(int sz1, int sz2)
try
:vi(sz1), // construct vi with sz1 ints
vs(sz2), // construct vs with sz2 strings
{
// ...
}
catch (std::exception& err) { // exceptions thrown for vi and vs are caught here
// ...
}
参考:The C++ Programming Language, by Bjarne Stroustrup, 4th Edition, 13.5.2.4 Function try-Blocks
9.7. C++ Standard Exceptions
类 exception 的 hierarchy 如下:
std::exception <exception> interface (debatable if you should catch this)
std::bad_alloc <new> failure to allocate storage
std::bad_array_new_length <new> invalid array length
std::bad_cast <typeinfo> execution of an invalid dynamic-cast
std::bad_exception <exception> signifies an incorrect exception was thrown
std::bad_function_call <functional> thrown by "null" std::function
std::bad_typeid <typeinfo> using typeinfo on a null pointer
std::bad_weak_ptr <memory> constructing a shared_ptr from a bad weak_ptr
std::logic_error <stdexcept> errors detectable before the program executes
std::domain_error <stdexcept> parameter outside the valid range
std::future_error <future> violated a std::promise/std::future condition
std::invalid_argument <stdexcept> invalid argument
std::length_error <stdexcept> length exceeds its maximum allowable size
std::out_of_range <stdexcept> argument value not in its expected range
std::runtime_error <stdexcept> errors detectable when the program executes
std::overflow_error <stdexcept> arithmetic overflow error.
std::underflow_error <stdexcept> arithmetic underflow error.
std::range_error <stdexcept> range errors in internal computations
std::regex_error <regex> errors from the regular expression library.
std::system_error <system_error> from operating system or other C API
std::ios_base::failure <ios> Input or output error
exception 类所定义的唯一操作是一个名为 what 的虚函数,该函数返回 const char*对象,它一般返回用来在抛出位置构造异常对象的信息。由于 what 是虚函数,如果捕获了基类类型引用,对 what 的调用将执行适合异常对象的动态类型的版本。
logic_error 和 runtime_error 是最主要的两种异常。logic_error 是程序中可以避免的(如通过检测函数的参数),而 runtime_error 是其它所有异常。
参考:
http://stackoverflow.com/questions/11938979/what-exception-classes-are-in-the-standard-c-library
http://www.cplusplus.com/reference/exception/
http://www.cplusplus.com/reference/stdexcept/
http://en.cppreference.com/w/cpp/error/exception
9.7.1. 标准库会抛出哪些异常
标准库抛出的异常如表 9 所示。
| Standard-Library Exceptions | |
|
bitset iostream regex string vector new T dynamic_cast typeid() thread call_once() mutex condition_variable async() packaged_task future and promise |
Throws invalid_argument, out_of_range, overflow_error Throws ios_base::failure Throws regex_error Throws length_error, out_of_range Throws out_of_range Throws bad_alloc if it cannot allocate memory for a T Throws bad_cast if it cannot convert the reference r to a T Throws bad_typeid if it cannot deliver a type_info Throws system_error Throws system_error Throws system_error Throws system_error Throws system_error Throws system_error Throws future_error |
参考:The C++ Programming Language, by Bjarne Stroustrup, 4th Edition, 30.4.1 Exceptions
9.8. 避免 C++ 函数向 C 函数抛出异常
在 C 语言中调用 C++ 函数时,要注意避免 C++ 中的异常向 C 语言抛出。 如果 C++ 中的异常抛出到 C 函数中,由于 C 语言中不支持 catch 语句,异常无法被处理,这将导致程序异常终止。
下面对此进行测试。假设有如下 C++ 程序:
// file cpp_func1.cpp
extern "C" int cpp_func1(void);
int cpp_func1(void) {
// code
throw 101;
// code
return 0;
}
在下面 C 程序中调用 C++ 实现的函数:
// file main.c
int cpp_func1(void);
int main() {
cpp_func1(); /* C++实现的函数cpp_func1会抛出异常 */
return 0;
}
编译程序测试如下:
$ g++ -c cpp_func1.cpp -o cpp_func1.o $ gcc -c main.c -o main.o $ g++ -o main main.o cpp_func1.o $ ./main terminate called after throwing an instance of 'int' Aborted
解决办法——在 C++ 函数内用 try/catch 捕获并吞下所有异常。如:
extern "C" int cpp_func1(void);
int cpp_func1(void)
try {
// code
throw 101;
// code
return 0;
} catch (...) { /* 捕获所有异常 */
return -1;
}
参考:Binary Hacks 黑客秘笈 100 选,Hack#18 在链接 C 程序和 C++ 程序时要注意的问题
9.9. Exception safety
There are several levels of exception safety (in decreasing order of safety):
- No-throw guarantee, also known as failure transparency: Operations are guaranteed to succeed and satisfy all requirements even in exceptional situations. If an exception occurs, it will be handled internally and not observed by clients.
- Strong exception safety, also known as commit or rollback semantics: Operations can fail, but failed operations are guaranteed to have no side effects, so all data retain their original values.
- Basic exception safety, also known as a no-leak guarantee: Partial execution of failed operations can cause side effects, but all invariants are preserved and no resources are leaked. Any stored data will contain valid values, even if they differ from what they were before the exception.
- No exception safety: No guarantees are made.
Usually, at least basic exception safety is required to write robust code.
参考:
https://en.wikipedia.org/wiki/Exception_safety
Exception Safety: Concepts and Techniques http://www.stroustrup.com/except.pdf
9.9.1. 实现异常安全之——RAII(Resource Acquisition Is Initialization)
Resource Acquisition Is Initialization is a C++ programming technique which binds the life cycle of a resource (allocated memory, open socket, open file, mutex, database connection - anything that exists in limited supply) to the lifetime of an object with automatic storage duration.
RAII is a strange name for a simple but awesome concept. Better is the name Scope Bound Resource Management (SBRM).
参考:
http://en.cppreference.com/w/cpp/language/raii
http://stackoverflow.com/questions/395123/raii-and-smart-pointers-in-c
9.9.1.1. 如何实现 RAII
RAII can be summarized as follows:
第一步: encapsulate each resource into a class, where
- the constructor acquires the resource and establishes all class invariants or throws an exception if that cannot be done
- the destructor releases the resource and never throws exceptions
第二步: always use the resource via an instance of a RAII-class that either
- has automatic storage duration
- is a non-static member of a class whose instance has automatic storage duration
Classes with open()/close(), lock()/unlock(), or init()/copyFrom()/destroy() member functions are typical examples of non-RAII classes.
9.9.1.2. RAII 可实现 Java 中 finally 语句的功能
C++ 中没有 finally 语句,利用 RAII 我们可以实现同样的目的。
如:正确使用下面的 RAII 类可保证 fclose 在异常发生时被调用。
class File_handle {
FILE* p;
public:
File_handle(const char* n, const char* a)
{ p = fopen(n,a); if (p==0) throw Open_error(errno); }
File_handle(FILE* pp)
{ p = pp; if (p==0) throw Open_error(errno); }
~File_handle() { fclose(p); }
operator FILE*() { return p; }
// ...
};
void f(const char* fn)
{
File_handle f(fn,"rw"); // open fn for reading and writing
// use file through f // 发生异常时,局部对象f会被撤销,它的析构函数会自动调用!
}
9.9.1.3. Limitation of RAII
用 RAII 技术可以很好地管理 stack-allocated objects, 但无法管理 dynamically allocated objects.
对于 dynamically allocated objects 我们可以使用 Smart pointer 来进行管理。
9.9.2. 实现异常安全之——Smart pointer
C++98 中实现了智能指针:std::auto_ptr
C++11 introduces following smart pointers:
std::shared_ptr
std::weak_ptr
std::unique_ptr
后文将介绍智能指针。
9.9.3. 实现异常安全之——函数调用
// In some header file: void f( T1*, T2* ); // At some call site: f( new T1, new T2 );
再考虑下面代码,它是异常安全的吗?
// In some header file:
void f( std::unique_ptr<T1>, std::unique_ptr<T2> );
// At some call site:
f( std::unique_ptr<T1>{ new T1 }, std::unique_ptr<T2>{ new T2 } );
上面两个例子,它们都不是异常安全,可能导致内存泄露。应该使用下面的形式:
// In some header file: void f( std::unique_ptr<T1>, std::unique_ptr<T2> ); // At some call site: f( std::make_unique<T1>(), std::make_unique<T2>() );
9.10. Tips
9.10.1. 什么时候不要用异常
有些时候不应该使用异常,如:
- 对实时性要求很高的嵌入式系统中;
- 大量使用 naked pointer 这种原始方式来进行资源管理的老系统中。
参考:The C++ Programming Language, by Bjarne Stroustrup, 4th Edition, 13.1.5 When You Can't Use Exceptions
9.10.2. 确保程序异常都被处理的
要捕获程序中所有异常,往往写如下代码:
int main()
try {
// code
}
catch (My_error& me) { // a My_error (user-defined exception class) happened
//
}
catch (runtime_error& re) { // a runtine_error happened
// we can use re.what()
}
catch (exception& e) { // some standard-library exception happened
// we can use e.what()
}
catch (...) { // Some unmentioned exception happened
//
}
10. STL
The Standard Template Library (STL) consists of the iterator, container, algorithm, and function object parts of the standard library.
10.1. STL containers
The Containers library is a generic collection of class templates and algorithms that allow programmers to easily implement common data structures like queues, lists and stacks. There are three classes of containers -- sequence containers, associative containers, and unordered associative containers -- each of which is designed to support a different set of operations.
这里有个较好的 STL containers 总结:http://en.cppreference.com/w/cpp/container
10.1.1. 各种 Containers 总结
可以把 Containers 分为四大类:Sequence containers/Associative containers/Unordered associative containers/Container adaptors,下面一一介绍它们。
Sequence containers (see table 10) implement data structures which can be accessed sequentially.
| Sequence Container | Comments |
|---|---|
| array | static contiguous array (sine C++11) |
| vector | dynamic contiguous array |
| deque | double-ended queue |
| forward_list | singly-linked list (sine C++11) |
| list | doubly-linked list |
Associative containers (see table 11) implement sorted data structures that can be quickly searched (O(log n) complexity).
| Associative Container | Comments |
|---|---|
| set | collection of unique keys, sorted by keys |
| map | collection of key-value pairs, sorted by keys, keys are unique |
| multiset | collection of keys, sorted by keys |
| multimap | collection of key-value pairs, sorted by keys |
Unordered associative containers (see table 12) implement unsorted (hashed) data structures that can be quickly searched (O(1) amortized, O(n) worst-case complexity).
| Unordered (hashed) Container | Comments |
|---|---|
| unordered_set | collection of unique keys, hashed by keys (sine C++11) |
| unordered_map | collection of key-value pairs, hashed by keys, keys are unique (sine C++11) |
| unordered_multiset | collection of keys, hashed by keys (sine C++11) |
| unordered_multimap | collection of key-value pairs, hashed by keys (sine C++11) |
Container adaptors (see table 13) provide a different interface for sequential containers.
| Container adaptors | Comments |
|---|---|
| stack | adapts a container to provide stack (LIFO data structure) |
| queue | adapts a container to provide queue (FIFO data structure) |
| priority_queue | adapts a container to provide priority queue |
10.1.2. vector 简单实现
下面是 vector 类的一个简单实现。
#include<iostream>
template <class T>
class myVector
{
private:
T* _data;
int _capacity;
int _size;
public:
myVector() {
_data = NULL;
_capacity = _size = 0;
}
myVector(int capacity) {
_data = new T[capacity];
_capacity = capacity;
_size = 0;
}
T& operator[](int index) {
return _data[index];
}
void push_back(const T & item) {
if(_size == _capacity) {
size_t new_capacity = _capacity * 2 + 1;
T* newData = new T[new_capacity];
for (size_t i = 0; i < _size; i++) {
newData[i] = _data[i];
}
// 上面for循环可以copy代替: std::copy(_data, _data + _size, newData);
// 但不要用memcpy代替: memcpy(newData, _data, _size *sizeof(T)); 代替,
// 因为如果类定义了“赋值操作符”/“复制构造函数”,memcpy并不会调用它们进行相应操作。
_capacity = new_capacity;
delete []_data;
_data = newData;
}
_data[_size++] = item;
}
int size() { return _size; }
};
class A{
private:
int _member;
public:
A() { _member = 0 ; }
A(int i): _member(i){}
A& operator=(const A &rhs) {
_member = rhs._member;
//std::cout << "Assignment Operator called" << std::endl;
return *this;
}
};
int main() {
myVector<A> v;
v.push_back(A(10));
v.push_back(A(20));
v.push_back(A(30));
std::cout << "size is " << v.size() << std::endl; //output: size is 3
return 0;
}
10.2. STL iterators
Iterators are the glue that ties standard-library algorithms to their data. Conversely, you can say that iterators are the mechanism used to minimize an algorithm’s dependence on the data structures on which it operates (see table 4).
Figure 4: STL iterators
10.2.1. iterator 什么情况下会失效
迭代器(iterator)是一个可以对其执行类似指针的操作的对象,我们可以将它理解成为一个指针。
下面以 vector 的插入操作来讨论迭代器失效的问题。
我们知道,vector 元素在内存中是顺序存储,如果当前容器中有 10 个元素,现在又要添加一个元素到容器中,但是内存中紧跟在这 10 个元素后面没有一个空闲空间,而 vector 的元素必须顺序存储以便索引访问,所以我们不能在内存中随便找个地方存储这个元素。于是 vector 必须重新分配存储空间,用来存放原来的元素以及新添加的元素:存放在旧存储空间的元素被复制到新的存储空间里,接着插入新的元素,最后撤销旧的存储空间。这种情况发生,一定会导致 vector 容器的所有迭代器都失效。
#include<vector>
#include <iostream>
using namespace std;
int main()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
vector<int>::iterator iter1 = v.begin();
v.push_back(3); // 在vector中插入元素可能导致其重新分配存储空间,从而导致迭代器 iter1 失效!
for(; iter1 != v.end(); iter1++) { // Wrong!!! 不能使用iter1了!它可能失效了!
std::cout << *iter1 << std::endl;
}
return 0;
}
一个解决办法是重新获取迭代器,即把 for 循环那行代码修改为:
for(iter1 = v.begin(); iter1 != v.end(); iter1++) {
说明:在 C++ 标准(ISO&IEC-14882-2003(E))中有对迭代器失效的说明,但比较分散,没有总结。
这里有一个比较好的总结:Iterator Invalidation Rules: http://kera.name/articles/2011/06/iterator-invalidation-rules/
10.3. STL algorithms
10.4. 智能指针(Smart Pointer)
本节主要摘自:C++ Primer Plus 第 6 版,16.2 智能指针模板类
10.4.1. 为什么需要智能指针
为什么需要智能指针呢?是为了防止内存泄露。考虑下面代码:
void remodel(std::string & str)
{
std::string * ps = new std::string(str);
//...
if (weird_thing())
throw exception(); // throw前没有写delete ps,可能有内存泄露
delete ps; // 如果忘记写delete ps,也会导致内存泄露
return;
}
上面代码中,如果函数 weird_thing() 返回真,那么会抛出异常,return 语句前的 delete 不会被执行,从而导致内存泄露。
当然,一个直观的解决解法是在抛出异常前增加 delete 语句:
if (weird_thing()) {
delete ps;
throw exception();
}
但问题在于我们经常会忘记这么写!不仅如此,return 语句前的 delete 也经常被忘记。这都会导致内存泄露。
如果当函数 remodel() 终止(不管是正常返回,还是出现了异常而终止)时,指针 ps 指向的内存自动被释放,那该多好啊。
10.4.2. 智能指针思想
在前面例子中,如果 ps 有一个析构函数(其功能是释放它指向的内存),我们知道析构函数会在 ps 过期时(局部变量超出作用域时会过期)自动被调用,这样就不用担心内存泄露了。问题在于 ps 只是一个常规指针,不是有析构函数的类对象。 智能指针的基本思想是:智能指针本身是一个对象,这样当智能指针过期时,它的析构函数(功能为删除它所指向的内存)会自动被调用,这样不用担心智能指针所指向的内存会泄露。
10.4.3. 智能指针基本使用
C++ 内置有智能指针的实现。C++98 中有 auto_ptr(已经过时),C++11 中有 unique_ptr,shared_ptr 和 weak_ptr。
智能指针对象在很多方面都类似于普通指针。例如,假设 ps 是一个智能指针对象,则可以用 *ps 对它执行解除引用操作,用 ps->member 访问结构成员。
下面来介绍前三种智能指针的基本使用。
// smrtptrs.cpp -- using three kinds of smart pointers
// requires support of C++11 shared_ptr and unique_ptr
#include <iostream>
#include <string>
#include <memory>
class Report
{
private:
std::string str;
public:
Report(const std::string s) : str(s)
{ std::cout << "Object created!\n"; }
~Report() { std::cout << "Object deleted!\n"; }
void comment() const { std::cout << str << "\n"; }
};
int main()
{
{
std::auto_ptr<Report> ps1 (new Report("using auto_ptr"));
(*ps1).comment();
ps1->comment();
} // 大括号结束了一个作用域,ps1对象会过期,ps1析构函数会被调用(它会删除相应的Report对象)。
{
auto ps2 = std::make_shared<Report>("using shared_ptr"); // 同 std::shared_ptr<Report> ps2 (new Report("using shared_ptr"));
ps2->comment();
} // 大括号结束了一个作用域,ps2对象会过期,ps2析构函数会被调用(它会删除相应的Report对象)。
{
auto ps3 = std::make_unique<Report>("using unique_ptr"); // 同 std::unique_ptr<Report> ps3 (new Report("using unique_ptr"));
ps3->comment();
} // 大括号结束了一个作用域,ps3对象会过期,ps3析构函数会被调用(它会删除相应的Report对象)。
return 0;
}
上面程序将输出:
Object created! using auto_ptr using auto_ptr Object deleted! Object created! using shared_ptr Object deleted! Object created! using unique_ptr Object deleted!
10.4.4. 智能指针注意事项(auto_ptr 的缺点)
为什么有这么多智能指针(auto_ptr, unique_ptr, shared_ptr 等 )呢?为什么 auto_ptr 会 deprecated 呢?
先考虑下面的赋值语句:
auto_ptr<string> ps (new string("I reigned lonely as a cloud."));
auto_ptr<string> vocation;
vocation = ps;
上述赋值语句将完成什么工作呢?如果 ps 和 vocation 是常规指针,则两个指针将指向同一个 string 对象。这对智能指针来说是不可接受的,因为程序将试图删除同一个对象两次——一次是 ps 过期时,另一次是 vocation 过期时。要避免这种问题,有多种方法:
方法一:定义赋值运算符,使之执行深拷贝。这样两个指针将指向不同的对象,其中的一个对象是另一个对象的副本。
方法二:建立所有权(ownership)概念,对于特定的对象,只能有一个智能指针可拥有它,这样只有拥有对象的智能指针的构造函数会删除该对象。然后, 让赋值操作“转让所有权”。这就是用于 auto_ptr 和 unique_ptr 的策略 ,但 unique_ptr 的策略更严格。
方法三:创建智能更高的指针,跟踪引用特定对象的智能指针数。这称为引用计数(reference counting)。例如,赋值时,计数将加 1,而指针过期时,计数将减 1。 仅当最后一个指针过期时,才调用 delete。这是 shared_ptr 采用的策略。
上面考虑的是赋值操作符,显然同样的策略也适用于复制构造函数。
auto_ptr 和 unique_ptr 采用的都是“转让所有权”策略,但 auto_ptr 已经被 deprecated。我们通过实例来说明 auto_ptr 存在的问题。
// fowl.cpp -- auto_ptr a poor choice
#include <iostream>
#include <string>
#include <memory>
int main()
{
using namespace std;
auto_ptr<string> films[5] =
{
auto_ptr<string> (new string("Fowl Balls")),
auto_ptr<string> (new string("Duck Walks")),
auto_ptr<string> (new string("Chicken Runs")),
auto_ptr<string> (new string("Turkey Errors")),
auto_ptr<string> (new string("Goose Eggs"))
};
auto_ptr<string> pwin;
pwin = films[2]; // films[2] loses ownership
cout << "The nominees for best avian baseball film are\n";
for (int i = 0; i < 5; i++)
cout << *films[i] << endl; // 访问 *films[2] 时会 Segmentation fault
cout << "The winner is " << *pwin << "!\n";
cin.get();
return 0;
}
上面程序的输出为:
The nominees for best avian baseball film are Fowl Balls Duck Walks Segmentation fault
导致 Segmentation fault 的原因是下面语句将所有权从 films[2] 转让给 pwin:
pwin = films[2]; // films[2] loses ownership
从此, films[2] 不再引用该字符串,后面用 for 循环打印它时,发现它是空指针,导致了程序 Segmentation fault。
这就是 废弃 auto_ptr 的主要原因:避免潜在的非法内存访问。
如果把前面程序中的 auto_ptr 换为 shared_ptr,则程序会正常运行。因为 shared_ptr 仅当引用计数为 0 时,才真正调用引用对象的析构函数。
我们知道,和 auto_ptr 一样,unique_ptr 采用的也是“转让所有权”策略,把前面例子中的 auto_ptr 换为 unique_ptr 会是什么结果呢?答案是:程序无法通过编译,编译器会禁止赋值语句 pwin = films[2]; ,在编译阶段就报错了(这显然比在运行阶段报错要更好),便于你发现。
什么情况下可以对 unique_ptr 对象赋值呢?请看下节内容。
10.4.5. unique_ptr 为何优于 auto_ptr
请看下面的语句:
auto_ptr<string> p1(new string("auto"); //#1
auto_ptr<string> p2; //#2
p2 = p1; //#3
在语句 #3 中,p2 接管 string 对象的所有权后,p1 的所有权将被剥夺。前面说过,这是件好事,可防止 p1 和 p2 的析构函数试图删除同一个对象;但如果程序随后试图使用 p1,这将是件坏事,因为 p1 不再指向有效的数据。
下面来看使用 unique_ptr 的情况:
unique_ptr<string> p3(new string("auto"); //#4
unique_ptr<string> p4; //#5
p4 = p3; //#6
编译器认为语句 #6 非法,避免了 p3 不再指向有效数据的问题。因此,unique_ptr 比 auto_ptr 更安全(编译阶段错误比潜在的程序崩溃更安全)。
但有时候,将一个智能指针赋给另一个并不会留下危险的悬挂指针。假设有如下函数定义:
unique_ptr<string> demo(const char * s)
{
unique_ptr<string> temp(new string(s));
return temp;
}
并假设编写了如下代码:
unique_ptr<string> ps;
ps = demo("Uniquely special");
demo() 返回一个临时 unique_ptr,然后 ps 接管了原本归返回的 unique_ptr 所有的对象,而返回的 unique_ptr 被销毁。这没有问题,因为 ps 拥有了 string 对象的所有权。但这里的另一个好处是,demo() 返回的临时 unique_ptr 很快被销毁,没有机会使用它来访问无效的数据。换句话说,没有理由禁止这种赋值,神奇的是,编译器确实允许这种赋值!
总之, 程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果源 unique_ptr 将存在一段时间,编译器将禁止这么做(这就是 unique_ptr 比 auto_ptr 更安全之处)。 如:
using namespace std; unique_ptr<string> pu1(new string "Hi ho!"); unique_ptr<string> pu2; pu2 = pu1; //#1 not allowed unique_ptr<string> pu3; pu3 = unique_ptr<string>(new string "Yo!"); //#2 allowed
上面的语句 #1 中,会留下悬挂的智能指针 pu1,编译器在编译阶段会报错。语句 #2 中,不会留下悬挂的智能指针,编译器允许这种赋值。
10.4.5.1. unique_ptr 可用于数组
相比于 auto_ptr,unique_ptr 还有另一个优点,它有一个可用于数组的变体。
std::unique_ptr<double[]> pda (new double[5]); // 删除时将使用delete[]
说明:auto_ptr 和 shared_ptr 都不能用于数组。
10.4.5.2. 用 std::move 强制转移 unique_ptr 指向内存的所有权
用 std::move 强制转移 unique_ptr 指向内存的所有权,如:
#include <iostream>
#include <memory>
int main() {
std::unique_ptr<int> p1(new int(5));
//std::unique_ptr<int> p2 = p1; // 编译阶段报错,禁止了p1成为悬挂指针
std::unique_ptr<int> p3 = std::move(p1); // 可用std::move强制转移所有权,现在那块内存归p3所有,p1成为了悬挂指针
std::cout << *p3 <<std::endl;
// std::cout << *p1 <<std::endl; // p1是悬挂指针,在对p1重新赋值前,不要访问p1
}
10.4.6. 选择智能指针
应使用哪种智能指针呢?
如果程序要使用多个指向同一个对象的指针,应选择 shared_ptr。 这样的情况包括:(1) 有一个指针数组,并使用一些辅助指针来标示特定的元素,如最大的元素和最小的元素;(2) 两个对象包含都指向第三个对象的指针;(3) STL 容器包含指针。
如果程序不需要多个指向同一个对象的指针,则可使用 unique_ptr。
10.4.7. shared_ptr 的“循环引用”问题及其解决办法(weak_ptr 使用)
前面介绍过,shared_ptr 采用“引用计数”策略来处理 shared_ptr 对象间的赋值问题。赋值时计数加 1,智能指针过期时,计数将减 1,当最后一个智能指针过期时才调用 delete。
但当出现“循环引用”情况时,会出现内存泄露。 “循环引用”是指两个对象互相使用一个 shared_ptr 成员变量指向对方。循环引用出现的可能场景:如二叉树中父节点与子节点的循环引用,容器与元素之间的循环引用等。
// shared_ptr “循环引用”演示实例
#include <iostream>
#include <memory>
using namespace std;
class parent;
class children;
class parent
{
public:
shared_ptr<children> children;
~parent() { std::cout <<"destroying parent\n"; }
};
class children
{
public:
shared_ptr<parent> parent;
~children() { std::cout <<"destroying children\n"; }
};
void test()
{
shared_ptr<parent> father(new parent());
shared_ptr<children> son(new children());
father->children = son; // 这一行和下一行导致了“循环引用”
son->parent = father;
}
int main()
{
std::cout<<"begin test...\n";
test();
std::cout<<"end test.\n";
return 0;
}
运行上面程序,会输出:
begin test... end test.
从输出中,可看出 parent 和 children 的析构函数在 test 函数返回后并没有被调用。这就是由于 parent 对象和 children 对象互相引用,它们的引用计数都是 1,不能自动释放,但此时(退出函数 test 后),这两个对象再也无法访问到了。这引起了“内存泄漏”。
怎么解决 shared_ptr 中的“循环引用”问题?可以使用弱引用 weak_ptr 解决这个问题, 弱引用 weak_ptr 只引用,不计数。若某块内存被 shared_ptr 和 weak_ptr 同时引用,当所有 shared_ptr 过期之后,不管还有没有 weak_ptr 引用该内存,内存也会被释放。所以 weak_ptr 不保证它指向的内存一定是有效的,在使用之前需要检查 weak_ptr 是否为空指针(使用 expired 方法)。
10.4.7.1. 利用 weak_ptr 打破循环引用
只要把循环引用的一方使用弱引用,即可解除循环引用。对于上面的例子,只要把 children 的定义改为如下方式,即可解除循环引用:
class children
{
public:
weak_ptr<parent> parent;
~children() { std::cout <<"destroying children\n"; }
};
最后值得一提的是,虽然通过弱引用指针可以有效的解除循环引用,但这种方式必须在程序员能预见会出现循环引用的情况下才能使用,也可以是说这个仅仅是一种编译期的解决方案,如果程序在运行过程中出现了循环引用,还是会造成内存泄漏的。
例子摘自:http://www.cnblogs.com/TianFang/archive/2008/09/20/1294590.html
10.4.8. 智能指针的简单实现
下面给出一个基于引用计数(类似于 shared_ptr)的智能指针的简单实现。
// file my_smart_ptr.h
template <typename T>
class my_smart_ptr {
private:
int count; // 保存引用计数
T *ptr; // 保存底层保管的指针
public:
my_smart_ptr(T*); // 构造函数,普通指针初始化智能指针
my_smart_ptr(my_smart_ptr &); // 拷贝构造函数(会对参数进行修改,没有声明为const)
T* operator->(); // 重载指针运算符
T& operator*(); // 重载解引用运算符
my_smart_ptr& operator=(my_smart_ptr &); // 重载赋值运算符(会对参数进行修改,没有声明为const)
~my_smart_ptr(); // 析构函数
};
// file my_smart_ptr.cpp
// 构造函数
template <typename T>
my_smart_ptr<T>::my_smart_ptr(T *p): count(1), ptr(p) { }
// 拷贝构造函数
template <typename T>
my_smart_ptr<T>::my_smart_ptr(my_smart_ptr &sp): count(++sp.count), ptr(sp.ptr) { }
// 重载指针运算符
template <typename T>
T* my_smart_ptr<T>::operator->() {
return ptr;
}
// 重载解引用运算符
template <typename T>
T& my_smart_ptr<T>::operator*() {
return *ptr;
}
// 重载赋值运算符:左边的计数减1,右边计数加1,当左边计数为0时,释放内存。
template <typename T>
my_smart_ptr<T>& my_smart_ptr<T>::operator=(my_smart_ptr& sp) {
++sp.count;
if (--count == 0) { //自我赋值也能保证正确
delete ptr;
}
this->ptr = sp.ptr;
this->count = sp.count;
return *this;
}
// 析构函数
template <typename T>
my_smart_ptr<T>::~my_smart_ptr() {
if (--count == 0) {
delete ptr;
}
}
10.4.9. 智能指针的简单总结
C++ 智能指针简单总结,如表 14 所示。
| Name | 说明 |
|---|---|
| std::auto_ptr | C++98 中引入,现在已经 Deprecated. |
| std::unique_ptr | C++11 中引入,对 unique_ptr 对象赋值会“转移所有权” |
| std::shared_ptr | C++11 中引入,对 shared_ptr 对象赋值会增加引用计数,有“循环引用”问题 |
| std::weak_ptr | C++11 中引入,和 shared_ptr 配合使用,可解决“循环引用”问题 |
11. 其它
11.1. 命名空间和 using 声明
C++ 中可以用关键字 namespace 来创建一个命名空间,这样可以把符号限定在指定空间内,以减少命名冲突。
命名空间可以不连续:命名空间是累积的,一个命名空间可以在一个文件中不连续,也可以分散在多个文件中。
命名空间实例:
namespace MyNamespace {
class MyClass {
};
}
使用时,要加上命名空间名字(方法一):
MyNamespace::MyClass obj;
也可以用 using 先声明命名空间中的符号(方法二):
using MyNamespace::MyClass; MyClass obj;
或者用 using namespace 引入命名空间的所有符号(方法三):
using namespace MyNamespace; MyClass obj;
11.1.1. 全局命名空间
定义在全局作用域的名字(在任意类、函数或命名空间外部声明的名字)是定义在全局命名空间中的。
全局作用域是隐含的,没有名字,可以用记号::member_name 来引用全局命名空间的成员。
#include<iostream>
int a = 1; // 这个a定义在全局命名空间中。
int main() {
int a = 2;
std::cout << a << std::endl;
std::cout << ::a << std::endl; // 可以用 ::a 来引用全局命名空间中的a。
}
11.1.2. 嵌套命名空间
11.1.3. 未命名的命名空间(可代替 C 中的 static)
命名空间可以是未命名的。
未命名的命名空间与其他命名空间不同,未命名的命名空间的定义局部于当前文件,从不跨越多个程序文件(每个文件都有自己的未命名的命名空间)。
未命名的命名空间中定义的名字只在包含该命名空间的文件中可见,这和 C 语言中的 static 声明类似。
#include<iostream>
namespace { // unnamed namespace
int a = 1; // 其它文件中不能引用它,相当于 static int a = 1;
}
// int a = 2; // ambiguous !!
int main() {
std::cout << a << std::endl; // 输出 1
std::cout << ::a << std::endl; // 输出 1
}
未命名的命名空间可以嵌套在另一个命名空间内部。如:
#include<iostream>
namespace A {
namespace {
int a = 1;
}
}
int main() {
std::cout << A::a << std::endl;
}
11.1.4. 命名空间别名(Namespace aliases)
可以用命名空间别名为命名空间再取一个名字。
语法如下:
namespace A = ABCDEF; // 其中命名空间ABCDEF必须已定义。 namespace B = X::Y::Z; // 用命名空间别名引用嵌套的命名空间。
下面是一个实例:
#include <iostream>
namespace foo {
namespace bar {
namespace baz {
int qux = 42;
}
}
}
namespace fbz = foo::bar::baz; // Namespace aliases
int main()
{
std::cout << fbz::qux << '\n'; // Output 42
}
11.1.5. 头文件中不要使用 using 声明
头文件的内容会被预处理器复制到程序中,如果在头文件中放置 using 声明,就相当于包含这个头文件的每个程序中都放置了同一 using 声明,无论该程序是否需要 using 声明。
头文件通常只应该定义确定必要的东西,所以不要在头文件中使用 using 声明。 头文件中请直接使用全名,如 std::string。
11.2. string 类
11.2.1. sring 类的 Copy-On-Write
下面例子展示了 C++ 中 string 类 Copy-On-Write 技术:
#include <string>
#include <stdio.h>
using namespace std;
int main(void)
{
string str1 = "hello world";
string str2 = str1;
printf ("Sharing the memory:\n");
printf ("\tstr1's address: %p\n", str1.c_str() );
printf ("\tstr2's address: %p\n", str2.c_str() );
str1[1]='q'; /* modify str1 */
str2[1]='w'; /* modify str2 */
printf ("After Copy-On-Write:\n");
printf ("\tstr1's address: %p\n", str1.c_str() );
printf ("\tstr2's address: %p\n", str2.c_str() );
return 0;
}
g++ 4.9.2 中测试结果:
Sharing the memory: str1's address: 0x13b8028 str2's address: 0x13b8028 After Copy-On-Write: str1's address: 0x13b8058 str2's address: 0x13b8028
修改 str1 和 str2 前,它们的地址是一样的,修改 str1 和 str2 后,有一个 str1 地址变了,str2 地址没变。在这个例子中如果仅修改 str1 或 str2 中的一个,也会有一个地址变化。
参考:
http://coolshell.cn/articles/12199.html
http://blog.csdn.net/haoel/article/details/24058
11.2.2. c_str() vs data()
从 C++ 标准上的解释来看,c_str() 和 data() 只有一点区别:c_str() 返回的指针保证指向一个 size() + 1 长的空间,而且最后一个字符肯定 "\0";而 data()返回的指针则保证指向一个 size() 长度的空间,有没有 null-terminate 不保证,可能有,可能没有,取决于库的实现。
11.2.3. 实现 trim()
C++ 中没有现成的函数对 string 进行 trim 操作。
/*
* Trim string. Both leading and trailing spaces(" \t\n\v\f\r") are removed.
*/
static string& trim(string& str){
const char* white_space = " \t\n\v\f\r"; //isspace().
str.erase(0, str.find_first_not_of(white_space)); // leading trim
str.erase(str.find_last_not_of(white_space) + 1); // tailing trim
return str;
}
11.2.4. operator""s
C++14 中定义了以 s 结尾的 string literal,如 "abcd"s ,参考:https://en.cppreference.com/w/cpp/string/basic_string/operator%22%22s
下面是一个实例:
#include <string>
#include <iostream>
int main()
{
using namespace std::string_literals;
std::string s1 = "abc\0\0def";
std::string s2 = "abc\0\0def"s;
std::cout << "s1: " << s1.size() << " \"" << s1 << "\"\n";
std::cout << "s2: " << s2.size() << " \"" << s2 << "\"\n";
}
下面是一个可能的输出(不同系统对 \0 的展示可能不一样):
s1: 3 "abc" s2: 8 "abc^@^@def"
11.2.5. string 类的简单实现
已知类 String 的原型如下所示,请实现类 String 的这些基本函数。
class String {
public:
String(const char *str = "");
String(const String &other);
~String();
String & operator=(const String &other);
bool operator==(const String &str);
friend ostream & operator<<(ostream& o,const String &str);
private:
char * m_data;
};
其实现和基本测试程序如下:
#include<iostream>
using std::ostream;
// 普通构造函数
String::String(const char *str) {
if (str == NULL) {
m_data = new char[1];
*m_data = '\0';
} else {
int len = strlen(str);
m_data = new char[len + 1];
strcpy(m_data, str);
}
}
// 析构函数
String::~String() {
delete [] m_data;
}
// 拷贝构造函数
String::String(const String &other) {
int len = strlen(other.m_data);
m_data = new char[len + 1];
strcpy(m_data, other.m_data);
}
// 赋值函数
String & String::operator=(const String &other) {
// 检查自我赋值
if (this != &other) {
// 要先分配内存,再释放原有的内存资源
// 这时基于异常安全的考虑(new失败时以前数据不会被破坏)
char *temp = new char[strlen(other.m_data) + 1];
strcpy(temp, other.m_data);
delete [] m_data;
m_data = temp;
}
return *this;
}
bool String::operator==(const String &str) {
return strcmp(m_data,str.m_data) == 0;
}
ostream & operator<<(ostream &o,const String &str) {
o << str.m_data;
return o;
}
int main()
{
String s = "cplusplus";
String s1 = s;
String s2 = "cplusplus";
std::cout<<"s1 = "<<s1<< std::endl;
std::cout<<"s2 = "<<s2<< std::endl;
std::cout<< std::boolalpha<<(s1 == s2)<< std::endl;
return 0;
}
11.3. 静态断言(static_assert)
我们知道,断言 assert 宏只有在程序运行时才能起作用。
考虑下面代码:
#include <cassert>
#include <cstring>
#include <iostream>
using namespace std;
template <typename T, typename U>
int bit_copy(T& a, U& b) {
assert(sizeof(a) == sizeof(b)); // assert在运行时才起作用
memcpy(&a, &b, sizeof(b));
}
int main() {
int a = 0x2468;
double b;
bit_copy(a, b);
return 0;
}
上面代码中的 assert 是要保证 a 和 b 两种类型的长度一致,这样 bit_copy 才能够保证复制操作不会遇到越界等问题。不过 assert 在运行时(不是编译时)才起作用,如果 bit_copy 不被调用,我们将无法触发该断言。就这个例子来说,更好的断言时机应该在模板实例化时(编译时),因为错误越早发现越好。
在 C++11 中,引入了关键字 static_assert ,它的作用是在编译时进行断言。在上面例子中,把 assert(sizeof(a) == sizeof(b)); 改为:
static_assert(sizeof(a) == sizeof(b), "the parameters of bit_copy must have same width.");
这样,在编译时就会提示错误。
显然, static_assert 的断言表达式的结果必须是在编译期间可以计算的表达式,即必须是常量表达式。如果读者使用了变量,则会导致错误,如:
int positive(const int n) {
static_assert(n > 0, "value must >0"); // 编译会失败,因为断言表达式在编译期间不可计算
}
11.3.1. static_assert 可用于任何名字空间
assert 必须写在函数体内。 static_assert 可用于任何名字空间,比如可以独立于任何调用之外运行,如:
static_assert(sizeof(int) == 8, "This 64-bit machine should follow this!");
int main() {
return 0;
}
11.4. 右值引用其它知识点
C++ 11 中增加了“右值引用”的概念,在节 5.5.2 中我们对其进行了介绍。这些再介绍右值引用的其它知识点。
11.4.1. 引用折叠(Reference Collapsing)
References are not objects; they do not necessarily occupy storage, although the compiler may allocate storage if it is necessary to implement the desired semantics (e.g. a non-static data member of reference type usually increases the size of the class by the amount necessary to store a memory address).
Because references are not objects, there are no arrays of references, no pointers to references, and no references to references.
参考:https://en.cppreference.com/w/cpp/language/reference
C++ 中没有引用数组,没有引用指针,没有引用的引用。
int& a[3]; // error,因为不存在引用数组 int&* p; // error,因为不存在引用指针 int& &r; // error,因为不存在引用的引用
由于 C++ 中不允许引用的引用,所以一个引用最终要么是“左值引用”,要么是“右值引用”,这称为“引用折叠”(Reference Collapsing)。
“引用折叠”的规则是:右值引用的右值引用是“右值引用”;其它情况都是“左值引用”。
下面例子中, r1, r2, r3, r4 哪些是左值引用,哪些是右值引用?
typedef int& lref; typedef int&& rref; int n; lref& r1 = n; // type of r1 is int& lref&& r2 = n; // type of r2 is int& rref& r3 = n; // type of r3 is int& rref&& r4 = 1; // type of r4 is int&&
根据“引用折叠”的规则,我们知道只有 r4 是“右值引用”。
11.4.2. 万能引用(Universal Reference)
我们先看一个例子:
#include <iostream>
void addOneAndPrint(int& param) { // 参数是左值引用
param = param + 1;
std::cout << param << std::endl;
}
void addOneAndPrint(int&& param) { // 参数是右值引用
param = param + 1;
std::cout << param << std::endl;
}
int main() {
int num = 2019;
addOneAndPrint(num); // 调用 addOne(int& param)
addOneAndPrint(2019); // 调用 addOne(int&& param)
return 0;
}
上面例子中,两个 addOneAndPrint 的实现只有参数类型不一样,一个接收左值引用,另一个接收右值引用。有没有办法统一一下,也就是让函数参数既可以接收左值,又可以接收右值呢?我们知道函数参数是 const 左值引用时,既可以接收左值,又可以接收右值。但在这个例子中,不符合要求(因为 addOneAndPrint 会对参数进行加 1 操作,这违背 const 语义)。
“万能引用”(Universal Reference) T&& 可以解决上面的问题,函数参数是万能引用时即可以接收左值,又可以接收右值。
注:“万能引用”的语法和“右值引用”相同。 只有发生类型推导(Type Deduction)时, T&& 才表示万能引用,否则,表示右值引用。
#include <iostream>
template<typename T>
void addOneAndPrint(T&& param) { // 参数是万能引用
param = param + 1;
std::cout << param << std::endl;
}
int main() {
int num = 2019;
addOneAndPrint(num); // 实参是左值
addOneAndPrint(2019); // 实参是右值
return 0;
}
特别说明,“万能引用”对形式 T&& 要求很严格。比如,增加一个 const 修饰后,则它不再是“万能引用”,而是右值引用:
template<typename T> void f(const T&& param); // “&&” 这里表示右值引用!
又比如,下面例子也不是“万能引用”,而是右值引用:
template<typename T> void f(std::vector<T>&& param); // “&&” 这里表示右值引用!
除了模板函数的参数 T&& 外,声明变量时 auto&& 也是万能引用,如:
int i = 100; int& r1 = i; int&& r2 = 200; auto&& r3 = r1; // auto&& 是万能引用 auto&& r4 = r2; // auto&& 是万能引用
11.4.3. 转发引用(Forwarding Reference)
考虑下面代码:
#include <iostream>
void addOneAndPrint(int& param) { // 参数是左值引用
param = param + 1;
std::cout << "传入参数为左值" << std::endl;
std::cout << param << std::endl;
}
void addOneAndPrint(int&& param) { // 参数是右值引用
param = param + 1;
std::cout << "传入参数为右值" << std::endl;
std::cout << param << std::endl;
}
template<typename T>
void wrapper(T&& param) { // 参数是万能引用
addOneAndPrint(param);
}
int main() {
int num = 2019;
wrapper(num); // 传入左值 num
wrapper(2019); // 传入右值 2019
return 0;
}
会输出:
传入参数为左值 2020 传入参数为左值 2020
是不是有点小意外,竟然再次调用的都是 addOneAndPrint 参数为左值引用的版本。
wrapper() 函数的形参是“万能引用”,即可以接受左值又可以接受右值;第一次调用 wrapper() 时实参是左值,第二次调用 wrapper() 函数时实参是右值,为什么两次都调用 addOneAndPrint() 的左值版本了呢?这是因为在 wrapper() 函数内部,右值引用类型变为了左值: wrapper() 的参数有名称,我们通过变量名取得变量地址。
如何在函数调用过程中,保持引用类型的不变呢?在 C++11 中通过 std::forward 函数来实现。 即把 wrapper() 函数修改为下面版本即可:
template<typename T>
void wrapper(T&& param) {
addOneAndPrint(std::forward<T>(param));
}
做完这个修改,再次运行上面程序,可以得到下面结果:
接收参数为左值 2020 接收参数为右值 2020
12. 不常用技术
12.1. 嵌套类(Nested class)
可以在另一个类内部定义一个类,这样的类是嵌套类(Nested class),也称为嵌套类型(Nested type)。
嵌套类是独立的类,基本上与它的外围类不相关。嵌套类型的对象不具备外围类所定义的成员,同样,外围类的成员也不具备嵌套类所定义的成员。
12.2. 局部类(Local class)
可以在函数体内部定义类,这样的类称为局部类(Local class)。
int a, val;
void foo(int val)
{
static int si;
enum Loc { a = 1024, b };
// Bar is local to foo
class Bar { // 类Bar定义在函数foo内部,它是局部类。
public:
Loc locVal; // ok: uses local type name
int barVal;
void fooBar(Loc l = a) // ok: default argument is Loc::a
{
barVal = val; // error: val is local to foo
barVal = ::val; // ok: uses global object
barVal = si; // ok: uses static local object
locVal = b; // ok: uses enumerator
}
};
// ...
}
13. C++ Tips
13.1. C++ Pitfalls
13.2. By Defalut, const Objects Are Local to a File in C++
C++ 中,在全局作用域声明的 const 变量是定义该对象的文件的局部变量。此变量只存在于那个文件中,不能被其他文件访问。通过指定 const 变量为 extern,就可以在整个程序中(其它编译单元)中访问 const 对象。
先看一个普通的例子(不同编译单元中的非 const 的全局变量):
// file_1.cpp
int bufSize = 1024; //definition
// file_2.cpp
#include <iostream>
extern int bufSize; //declaration
int main()
{
std::cout << bufSize <<std::endl;
}
上面例子可以成功编译(g++ file_2.cpp file_1.cpp)。
但我们想保护变量 bufSize,防止它被修改,在它前面加个 const 限定符:
// There is linker error when resolve symbol (bufSize) in file_2.cpp
// file_1.cpp
const int bufSize = 1024; //By Defalut, const Objects Are Local to a File
// file_2.cpp
#include <iostream>
extern const int bufSize;
int main()
{
std::cout << bufSize <<std::endl;
}
编译上面程序时(g++ file_1.cpp file_2.cpp),提示链接错误:
/tmp/ccmJrgV0.o: In function `main': file_2.cpp:(.text+0x6): undefined reference to `bufSize' collect2: error: ld returned 1 exit status
这是因为:使用 const 限制符定义的全局变量,默认只能在其定义的文件(file_1.cpp)中访问。
Resolution:
在定义 const 全局变量时,加上 extern 关键字,这样就可以在其它文件(file_2.cpp)中访问它:
// file_1.cpp
extern const int bufSize = 1024;
// file_2.cpp
#include <iostream>
extern const int bufSize;
int main()
{
std::cout << bufSize <<std::endl;
}
参考:
C++ Primer, 4th, 2.4 const Qualifier
The C++ Programming Language, by Bjarne Stroustrup, 4th Edition, 15.2 Linkage
注意:
规则"By Defalut, const Objects Are Local to a File"仅限于 C++,在 C 语言中不是这样的。 In C, a global const by default has external linkage.
下面两个 C 源码(和前面例子的 C++ 源码类似),可以成功编译(gcc file_1.c file_2.c)。
// file_1.c
const int bufSize = 1024; //
// file_2.c
#include<stdio.h>
extern const int bufSize;
int main()
{
printf("%d\n", bufSize);
}
13.3. placement new
Placement new allows you to construct an object on memory that's already allocated. This is useful when building a memory pool, a garbage collector or simply when performance and exception safety are paramount (there's no danger of allocation failure since the memory has already been allocated, and constructing an object on a pre-allocated buffer takes less time):
char *buf = new char[sizeof(string)]; // pre-allocated buffer
string *p = new (buf) string("hi"); // placement new
string *q = new string("hi"); // ordinary heap allocation
参考:
http://stackoverflow.com/questions/222557/what-uses-are-there-for-placement-new
https://isocpp.org/wiki/faq/dtors#placement-new
http://www.stroustrup.com/bs_faq2.html#placement-delete
http://www.cplusplus.com/reference/new/operator%20new/
13.4. new char(n) 和 new char[n] 的区别
new char(10) 和 new char[10] 有什么区别?
new char(10) 相当于只申请一个字节的空间,它的值为 ASCII 为 10 的字符;而 new char[10] 是申请 10 个字符的空间。
13.5. delete 指针后赋值 NULL
delete 指针后赋值 NULL 是比较好的编程习惯。
C++ 标准规定:delete 空指针是合法的,没有副作用。
但是,delete p 后,p并不会自动被置为 NULL
问题来了,对一个非空指针 delete 后,若没有赋 NULL,若被再次 delete 的话,有可能出现问题。
如下代码:
int *p = new int(3); delete p; delete p;
用编译后运行将出现问题。现将其改为:
int *p = new int(3); delete p; p = NULL; delete p;
则不会出现问题(因为 delete 空指针是合法的),所以,为了避免出现问题,指针被 delete 之后应该赋值 NULL。
总结:delete 之后,如果不对原指针赋 NULL,它就是个“野指针”(指向一块已被系统回收的内存)。而如果赋了 NULL,即使它再多次被 delete,也不会导致异常。
13.6. istream::getline vs std::getline
istream::getline 更低级,处理的是 naked character;更推荐使用 std::getline 。
下面是 istream::getline 的例子:
// istream::getline example
// http://www.cplusplus.com/reference/istream/istream/getline/
#include <iostream> // std::cin, std::cout
int main () {
char name[256], title[256];
std::cout << "Please, enter your name: ";
std::cin.getline (name,256);
std::cout << "Please, enter your favourite movie: ";
std::cin.getline (title,256);
std::cout << name << "'s favourite movie is " << title;
return 0;
}
下面是 std::getline 的例子:
// extract to string
// http://www.cplusplus.com/reference/string/string/getline/
#include <iostream>
#include <string>
main ()
{
std::string name;
std::cout << "Please, enter your full name: ";
std::getline (std::cin,name);
std::cout << "Hello, " << name << "!\n";
return 0;
}
13.7. 分析 CSV 文本
用 std::getline 即可,它的第 3 个参数可以指定分隔符。
例子:分析 CSV 文件的一行内容。
#include <iostream>
#include <sstream>
#include <string>
using namespace std;
int main() {
string line = "a;b;c";
istringstream iss(line);
string tok;
char delim = ';';
while (getline(iss, tok, delim)) {
cout << tok <<endl;
}
}
运行上面程序,将输出:
a b c
13.8. C++ 成员函数指针是 16 字节
一般地,64 位机器上,指针占 8 个字节。但有个例外:C++ 成员函数的指针。如,下面例子中对成员函数的指针求 sizeof,结果会是 16:
// 请在64位机器上测试
#include <iostream>
void fun1() {}
struct Foo {
void bar() const { }
};
int main() {
std::cout << sizeof(&fun1) << std::endl; // 输出 8 (普通函数指针大小)
std::cout << sizeof(&Foo::bar) << std::endl; // 输出 16 (成员函数指针大小)
}
为什么 C++ 成员函数的指针是 16 字节?请参考:http://www.oschina.net/translate/wide-pointers
13.9. C 和 C++ 的不兼容处
一般地,C 和 C++ 是兼容的;但也有很多地方 C 和 C++ 的行为是不同的。
如:对字符常量用 sizeof 运算的结果,在 C 语言中和 sizeof(int) 相同,而在 C++ 中和 sizeof(char) 相同。
#include<stdio.h>
int main()
{
char var1='a';
printf("%zu\n", sizeof(var1)); // 输出1
printf("%zu\n", sizeof('a')); // 用C编译器编器,会输出1;用C++编译器编译,会输出4
}
Bjarne Stroustrup 在"The C++ Programming Language, 44.3 C/C++ Compatibility"中列举了很多 C 和 C++ 不兼容的地方。
14. C++ 新特性
参考:
https://github.com/AnthonyCalandra/modern-cpp-features
https://en.wikipedia.org/wiki/C%2B%2B11
https://en.wikipedia.org/wiki/C%2B%2B14
https://en.wikipedia.org/wiki/C%2B%2B17
14.1. C++11 新特性
这里介绍部分的 C++11 新特性,前面内容中已经介绍过了很多 C++11 新特性。
参考:
C++11 - the new ISO C++ standard: http://www.stroustrup.com/C++11FAQ.html
C++ Primer Plus 第 6 版,第 18 章 探讨 C++新标准
14.1.1. 语言新特性
14.1.1.1. auto 自动推导类型
在 C++11 之前,auto 关键字用来指定变量的存储期。C++11 用 auto 关键字来指示“自动推导类型”。
如:
auto x = 7; // same as: int x = 7;
auto 可以使代码看起来更简单。如,在 C++11 中可以这样写:
template<class T> void printall(const vector<T>& v)
{
for (auto p = v.begin(); p!=v.end(); ++p)
cout << *p << "\n";
}
而在 C++11 前,你需要烦琐地写为:
template<class T> void printall(const vector<T>& v)
{
for (typename vector<T>::const_iterator p = v.begin(); p!=v.end(); ++p)
cout << *p << "\n";
}
14.1.1.2. Range-for statement
C++11 中增强了 for 语句。直接看实例,前面介绍的例子可以进一步简化为:
template<class T> void printall(const vector<T>& v)
{
for (auto x: v)
cout << x << "\n";
}
下面再看一个 Range-for statement 的例子:
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v = {0, 1, 2, 3, 4, 5};
for (auto &r : v) { // 要修改v中的元素值,循环控制变量必须声明为引用类型
r *= 2;
}
for (auto i: v) {
std::cout << i << ' '; // 输出 0 2 4 6 8 10
}
return 0;
}
14.1.1.3. nullptr -- a null pointer literal
nullptr is a literal denoting the null pointer; it is not an integer:
char* p = nullptr; int* q = nullptr; char* p2 = 0; // 0 still works and p==p2 void f(int); void f(char*); f(0); // call f(int) f(nullptr); // call f(char*) void g(int); g(nullptr); // error: nullptr is not an int int i = nullptr; // error nullptr is not an int
14.1.1.4. Lambda(匿名函数对象)
参见节:3.6 。
14.1.1.5. Variadic templates (Parameter pack)
参见节:8.7 。
14.1.1.6. Attribute
C++11 中支持 attribute,语法是两个中括号。可以代替 G++ 的 __attribute__ 或者 Microsoft 编译器的 __declspec 。
C++11 中定义了两个 attribute: noreturn 和 carries_dependency 。下面是 noreturn 的例子:
// `noreturn` attribute indicates `f` doesn't return.
[[ noreturn ]] void f() {
throw "error";
}
C++14 中新增加了一个 attribute: deprecated 。C++17 中新增加了三个 attribute: fallthrough, nodiscard, maybe_unused 。
14.1.2. 库的增强
14.1.2.1. Tuple(std::make_tuple,std::tie)
C++11 中增加了对 Tuple 的支持,使用 std::make_tuple 可以构造一个 Tuple,如:
// `playerProfile` has type `std::tuple<int, const char*, const char*>`. auto playerProfile = std::make_tuple(51, "Frans Nielsen", "NYI"); std::get<0>(playerProfile); // 51 std::get<1>(playerProfile); // "Frans Nielsen" std::get<2>(playerProfile); // "NYI"
除了使用 std::get 获取 Tuple 中的元素外,还可以使用 std::tie 获得 Tuple 中元素,如:
// With tuples...
std::string playerName;
std::tie(std::ignore, playerName, std::ignore) = std::make_tuple(91, "John Tavares", "NYI");
// With pairs...
std::string yes, no;
std::tie(yes, no) = std::make_pair("yes", "no");
注:在 C++17 中,使用 Structured bindings 可以实现和 std::tie 相同的功能,而且 Structured bindings 更加简单。
14.1.2.2. 增加了 std::thread, std::future, std::promise 等并行编程设施
14.1.2.3. std::ref, std::cref, std::reference_wrapper
std::ref 用于创建 std::reference_wrapper 类型的对象。
#include <iostream> // std::cout
#include <functional> // std::ref
int main () {
int foo (10);
std::reference_wrapper<int> bar = std::ref(foo);
++bar;
std::cout << foo << '\n'; // 输出 11
// bar 的类型是 std::reference_wrapper<int>
// bar.get() 的类型是 int&
std::cout<< std::boolalpha;
std::cout<< std::is_same<int&, decltype(bar)>::value << std::endl; // false
std::cout<< std::is_same<int&, decltype(bar.get())>::value << std::endl; // true
return 0;
}
有了 int& ,为什么还要有 std::reference_wrapper<int> 呢?这是因为:引用类型(如 int& )在创建的时间必须初始化,我们不能创建引用容器或引用数组,如下面是非法的:
int& arr[]; // 这是非法的,没有引用数组 std::vector<int&> vec; // 这是非法的,没有引用 vector
有了 std::reference_wrapper ,我们可以把“引用”放入数组或者 vector 里面了,如:
#include <iostream> // std::cout
#include <functional> // std::ref
#include <vector>
int main () {
auto val = 99;
auto _ref = std::ref(val); // _ref 是 std::reference_wrapper<int> 类型
_ref++;
std::vector<std::reference_wrapper<int>>vec;
vec.push_back(_ref); // 把“引用”放入了 vector 中
std::cout << val << std::endl; // prints 100
std::cout << vec[0] << std::endl; // prints 100
return 0;
}
std::cref 和 std::ref 类似,只是 std::cref 是“常量引用”。
14.2. C++14 新特性
C++11 中的新特性很多,但 C++14 是一个改动很小的版本,新特性比较少。
14.2.1. 语言新特性
14.2.1.1. Binary literal
C++14 中引入了 Binary literal,使用 0b 开头,中间可以使用单引号 ' 分隔,如:
#include <iostream>
using namespace std;
int main() {
auto a = 0b110; // == 6
auto b = 0b11'11'11'11; // == 255
auto c = 0b1111'1111; // == 255
std::cout << a << std::endl;
std::cout << b << std::endl;
std::cout << c << std::endl;
return 0;
}
14.2.1.2. 泛型 lambda
参见节 3.6.3 。
14.2.1.3. Lambda capture initializers
参见节 3.6.4 。
14.2.1.4. Variable templates
参见节 8.4 。
14.2.2. 库的增强
14.2.2.1. std::make_unique
C++14 中引入了 std::make_unique,用于创建 std::unique_ptr 的实例,引入它的主要目的是为了异常安全,参见节 9.9.3 。
14.2.2.2. std::exchange
std::exchange(x, y) 作用是把 y 赋值给 x ,返回 x 的旧值。这个语义和 std::swap(x, y) 不一样, y = std::exchange(x, y) 和 std::swap(x, y) 的语义类似。
14.2.2.3. std::quoted
N3654 中提了一个关于引用字符串的 Proposal。
它为字符串在流中的往返而设计,考虑代码:
std::stringstream ss; std::string original = "foolish me"; std::string round_trip; ss << original; ss >> round_trip; std::cout << original; // outputs: foolish me std::cout << round_trip; // outputs: foolish assert(original == round_trip); // assert will fire
为了使 original 和 round_trip 相同,可以使用下面代码:
std::stringstream ss; std::string original = "foolish me"; std::string round_trip; ss << std::quoted(original); ss >> std::quoted(round_trip); std::cout << original; // outputs: foolish me std::cout << round_trip; // outputs: foolish me assert(original == round_trip); // assert will not fire
下面是关于 std::quoted 另外一个例子:
#include <iostream>
#include <iomanip>
int main() {
std::cout << "She said \"Hi!\"" << std::endl; // She said "Hi!"
std::cout << std::quoted("She said \"Hi!\"") << std::endl; // "She said \"Hi!\""
std::cout << std::quoted("She said \"Hi!\"", '\"', '\\') << std::endl; // "She said \"Hi!\""
std::cout << std::quoted("She said YYHi!YY", 'X', 'Y') << std::endl; // XShe said YYYYHi!YYYYX
return 0;
}
14.3. C++17 新特性
14.3.1. 语言新特性
14.3.1.1. Class template argument deduction (CTAD)
C++17 中引入了,类模板参数推导,可以简化代码。如:
std::pair<int, double> p(2, 4.5); // C++14 std::pair p(2, 4.5); // C++17,同上
参考:https://en.cppreference.com/w/cpp/language/class_template_argument_deduction
14.3.1.2. Fold expression
参见节:8.7.5 。
14.3.1.3. Structured bindings
C++17 中引入了 Structured bindings,语法为:
auto [a, b] = getTwoReturnValues();
下面是 Structured bindings 的一个例子:
#include <iostream>
std::pair<int, int> origin() {
return std::pair<int, int>{0, 0};
}
int main() {
int x, y;
std::tie(x, y) = origin(); // C++11, x=0, y=0
const auto [ i, j ] = origin(); // C++17 Structured bindings, i=0, j=0
return 0;
}
下面再看一个 Structured bindings 的例子:
std::unordered_map<std::string, int> mapping {
{"a", 1},
{"b", 2},
{"c", 3}
};
// Destructure by reference.
for (const auto& [key, value] : mapping) { // Structured bindings [key, value]
// Do something with key and value
}
14.3.1.4. Selection statements with initializer
C++17 中增强了 if 和 switch 语句,使它们可以包含初始语句,语法为: if (init; condition) 和 switch (init; condition) 。
使用这个新语法可以简化代码,如:
+------------------------------------------+---------------------------------------------------------+
| Before C++17 | C++17 |
+------------------------------------------+---------------------------------------------------------+
| void safe_init() { | void safe_init() { |
| { | if (std::lock_guard<std::mutex> lk(mx_); v.empty()) { |
| std::lock_guard<std::mutex> lk(mx_); | v.push_back(kInitialValue); |
| if (v.empty()) | } |
| v.push_back(kInitialValue); | // ... |
| } | } |
| } | |
| // ... | |
| } | |
+------------------------------------------+---------------------------------------------------------+
| { | switch (Foo gadget(args); auto s = gadget.status()) { |
| Foo gadget(args); | case OK: gadget.zip(); break; |
| switch (auto s = gadget.status()) { | case Bad: throw BadFoo(s.message()); |
| case OK: gadget.zip(); break; | } |
| case Bad: throw BadFoo(s.message()); | |
| } | |
| } | |
+------------------------------------------+---------------------------------------------------------+
参考:http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0305r1.html
14.3.1.5. Lambda capture this by value
C++17 中,对 this 可以进行值传递捕捉,参见节:3.6.2.1 。
14.3.1.6. Inline variables
C++17 中,变量也可以标记为 inline 。
14.3.1.7. Nested namespaces
C++17 增加了嵌套命令空间定义的新语法,参见节:11.1.2 。
14.3.2. 库的增强
14.3.2.1. std::variant
std::variant 可以认为是类型安全的联合体。下面是它的使用实例:
#include <iostream>
#include <variant>
int main() {
std::variant<int, double, bool> v {12};
std::cout << std::get<int>(v) << std::endl; // == 12
std::cout << std::get<0>(v) << std::endl; // == 12
v = 10.5;
std::cout << std::get<double>(v) << std::endl; // == 10.5
std::cout << std::get<1>(v) << std::endl; // == 10.5
v = true;
std::cout << std::get<bool>(v) << std::endl; // 1 (true 默认输出为 1)
std::cout << std::get<2>(v) << std::endl; // 1 (true 默认输出为 1)
}
14.3.2.2. std::optional
std::optional 用于表示一个“可选值”,如 std::optional<std::string> 表示 std::string 或者“不存在”。
#include <string>
#include <iostream>
#include <functional>
#include <optional>
std::optional<std::string> create(bool b) {
if (b)
return "Godzilla";
return {}; // return std::nullopt; // 也表示返回空
}
int main () {
auto str1 = create(true);
auto str2 = create(false);
std::cout << *str1 << std::endl; // 输出 Godzilla
std::cout << str1.value() << std::endl; // 输出 Godzilla
std::cout << str1.value() << std::endl; // 输出 Godzilla
std::cout << *str2 << std::endl; // 空输出
//std::cout << str2.value() << std::endl; // 报错
std::cout << str2.value_or("Not present") << std::endl; // 输出 Not present
// std::optional 可以放在 if 或者 while 条件判断中
if (auto str = create(true)) {
std::cout << "create(true) returned " << *str << '\n';
} else {
std::cout << "create(true) not present" << '\n';
}
return 0;
}
14.3.2.3. std::any
std::any 用于表示任意值。如:
#include <any>
#include <iostream>
int main()
{
std::cout << std::boolalpha;
// any type
std::any a = 1;
std::cout << a.type().name() << ": " << std::any_cast<int>(a) << '\n';
a = 3.14;
std::cout << a.type().name() << ": " << std::any_cast<double>(a) << '\n';
a = true;
std::cout << a.type().name() << ": " << std::any_cast<bool>(a) << '\n';
// bad cast
try
{
a = 1;
std::cout << std::any_cast<float>(a) << '\n';
}
catch (const std::bad_any_cast& e)
{
std::cout << e.what() << '\n';
}
// has value
a = 1;
if (a.has_value())
{
std::cout << a.type().name() << '\n';
}
// reset
a.reset();
if (!a.has_value())
{
std::cout << "no value\n";
}
// pointer to contained data
a = 1;
int* i = std::any_cast<int>(&a);
std::cout << *i << "\n";
}
上面代码输出:
i: 1 d: 3.14 b: true bad any cast i no value 1
14.3.2.4. std::invoke, std::apply
std::invoke 可以调用一个 Callable 对象,如:
#include <functional>
#include <iostream>
struct Foo {
Foo(int num) : num_(num) {}
void print_add(int i) const { std::cout << num_+i << '\n'; }
int num_;
};
void print_num(int i)
{
std::cout << i << '\n';
}
struct PrintNum {
void operator()(int i) const
{
std::cout << i << '\n';
}
};
int main()
{
// invoke a free function
std::invoke(print_num, -9);
// invoke a lambda
std::invoke([]() { print_num(42); });
// invoke a member function
const Foo foo(314159);
std::invoke(&Foo::print_add, foo, 1);
// invoke (access) a data member
std::cout << "num_: " << std::invoke(&Foo::num_, foo) << '\n';
// invoke a function object
std::invoke(PrintNum(), 18);
}
std::apply 也可以调用 Callable 对象,但指定参数时是以 tuple 的形式,如:
auto add = [](int x, int y) {
return x + y;
};
std::apply(add, std::make_tuple(1, 2)); // 3
14.3.2.5. std::filesystem
std::filesystem 可以操作文件系统中的目录或文件等,参考:https://en.cppreference.com/w/cpp/filesystem
14.3.2.6. std::string_view
std::string_view 是字符串视图,不会涉及内存分配。如:
#include <iostream>
int main()
{
std::string str {" trim me"};
std::string_view v {str};
v.remove_prefix(std::min(v.find_first_not_of(" "), v.size())); // remove_prefix 仅修改了 string_view 的数据指向,不修改指向的数据
std::cout << str << std::endl; // " trim me"
std::cout << v << std::endl; // "trim me"
}
14.3.2.7. std::byte
std::byte 表示字节,只能进行位运算,不能进行算术运算。如:
#include <iostream>
#include <cstddef>
int main()
{
std::byte a {0x2A}; // 同 b{42};
std::cout << std::to_integer<int>(a) << "\n";
// std::byte 只能进行位算,不能用算术运算,a *= 2 会报错
a <<= 1;
std::cout << std::to_integer<int>(a) << "\n";
}
上面代码输出:
42 84