Scala
Table of Contents
- 1. Scala 简介
- 2. Scala 入门
- 3. 类和对象
- 4. 基础类型和操作
- 5. 函数式对象
- 6. 内置的控制结构
- 7. 函数和闭包
- 8. 控制抽象
- 9. 类继承
- 10. Scala 的继承关系
- 11. 特质(trait)
- 12. 包和引入
- 13. Case Classes and Pattern Matching
- 14. 类型参数化(Type Parameterization)
- 15. 隐式转换和隐式参数
- 16. 提取器(Extractor)
- 17. 参考
1. Scala 简介
Scala 是一种多范式编程语言,它结合了面向对象编程和函数式编程,它运行于 Java 虚拟机之上。和 Java 一样,Scala 是一种“强类型”、“静态类型”的语句。
Scala 语言规范可参考:Scala Language Specification
SCALA BOOK:https://docs.scala-lang.org/overviews/scala-book/introduction.html
1.1. sbt(Scale 编译工具)
1.1.1. Hello World 工程
下面通过 Hello World 工程来介绍 sbt 的基本使用。
首先,创建工程目录:
$ cd /tmp/ $ mkdir foo-build $ cd foo-build $ touch build.sbt # 这是 sbt 的编译说明文件,暂时为空即可
准备 Scala 源文件 src/main/scala/example/Hello.scala,其内容如下:
package example
object Hello extends App {
println("Hello")
}
启动 sbt 交互式 shell:
$ sbt [info] Updated file /tmp/foo-build/project/build.properties: set sbt.version to 1.1.4 [info] Loading project definition from /tmp/foo-build/project [info] Loading settings from build.sbt ... [info] Set current project to foo-build (in build file:/tmp/foo-build/) [info] sbt server started at local:///Users/eed3si9n/.sbt/1.0/server/abc4fb6c89985a00fd95/sock sbt:foo-build>
在 sbt 中执行 compile 命令,以编译源码:
sbt:foo-build> compile [info] Compiling 1 Scala source to /tmp/foo-build/target/scala-2.12/classes ... [info] Done compiling. [success] Total time: 2 s, completed May 6, 2018 3:53:42 PM
在 sbt 中执行 run 命令,以运行代码:
sbt:foo-build> run [info] Packaging /tmp/foo-build/target/scala-2.12/foo-build_2.12-0.1.0-SNAPSHOT.jar ... [info] Done packaging. [info] Running example.Hello Hello [success] Total time: 1 s, completed May 6, 2018 4:10:44 PM
要退出 sbt 交互式 shell,可以执行 Ctrl+D (Unix) 或者 Ctrl+Z (Windows);也可以执行 exit 命令来退出:
sbt:foo-build> exit
1.1.2. Scala REPL
在 sbt 中执行 console 命令,可以进入 Scala 的交互式解释器(REPL),如:
sbt:foo-build> console
[info] Starting scala interpreter...
Welcome to Scala 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_66).
Type in expressions for evaluation. Or try :help.
scala> 1 + 2
res0: Int = 3
scala> println("Hello, world!")
Hello, world!
1.1.3. 工程目录结构
默认地,sbt 采用和 Maven 一样的目录结构,如:
src/
main/
resources/
<files to include in main jar here>
scala/
<main Scala sources>
scala-2.12/
<main Scala 2.12 specific sources>
java/
<main Java sources>
test/
resources
<files to include in test jar here>
scala/
<test Scala sources>
scala-2.12/
<test Scala 2.12 specific sources>
java/
<test Java sources>
2. Scala 入门
2.1. 变量定义
Scala 中变量分为两种:val 和 var。
val 跟 Java 的 final 变量类似,一旦初始化就不能被重新赋值。而 var 则不同,类似于 Java 的非 final 变量,可以被重新赋值。如:
scala> val msg = "Hello, world!" // 定义常量 msg,利用“类型推导”系统自动推导类型
msg: String = Hello, world!
scala> val msg1: java.lang.String = "Hello, world!" // 定义常量 msg1,显式标注了类型
msg1: String = Hello, world!
scala> val msg2: String = "Hello, world!" // 定义常量 msg2,省略 java.lang,显式标注了类型
msg2: String = Hello, world!
scala> msg = "Other" // val 声明为常量后,不能再修改了
<console>:12: error: reassignment to val
msg = "Other"
^
scala> var msg3 = "Hello, world" // 用 var 定义变量 msg3
msg3: String = Hello, world
scala> msg3 = "Other" // msg3 还可以被修改
msg3: String = Other
2.2. 函数定义
Scala 中用 def 定义函数,如:
def max(x: Int, y: Int): Int = {
if (x > y) x
else y
}
函数的每个参数后面必须加上以冒号开始的类型标注,因为 Scala 编译器不会推断函数参数的类型。函数返回结果的类型当编译器可以推断出来时,可以省写。 mac 还可以写为下面形式:
def max(x: Int, y: Int) = { if (x > y) x else y } // 省略了结果类型(编译器可以推断出来时)
def max(x: Int, y: Int) = if (x > y) x else y // 函数体只有一个语句,花括号也可以省略
如果函数参数个数是零,在调用该函数时可以省略括号。如:
def f1(): Int = {
100
}
println(f1()) // 输出 100
println(f1) // 同上。省略了函数调用的括号
2.3. 编写 Scala 脚本
Scala 既可以构建大型软件系统,也适用于编写脚本。
假设有下面文件(hello.scala):
println("Hello, world, from a script!")
然后执行:
$ scala hello.scala
可以看到下面的输出:
Hello, world, from a script!
2.3.1. 遍历命令行参数
命令行参数可以通过名为 args 的 Scala 数组获取。 Scala 的数组下标从 0 开始,可以通过“圆括号”指定下标来访问对应下标的元素。
假设有下面文件(printargs.scala):
var i = 0
while (i < args.length) { // 在循环中输出每个命令行参数
println(args(i)) // 注1:Scala 数组通过“圆括号”指定下标
i += 1 // 注2:Scala 中不支持 i++ 或者 ++i 的自增语法
}
测试上面程序:
$ scala printargs.scala 1 2 1 2
需要特别说明的两点:
1、 Scala 数组通过“圆括号”(而不是像 Java 中那样用方括号)指定下标。 至于为什么这样设计,请参考节 2.6.2 。
2、 Scala 中不支持 i++ 或者 ++i 的自增语法。
2.4. 用 foreach 遍历
前面介绍了用 while 遍历命令行参数。它还可以用 foreach 实现得更简单:
args.foreach(arg => println(arg)) // 输出每个命令行参数
在这段代码中,对 args 执行 foreach 方法,传入一个(匿名)函数,这个函数接收一个名为 arg 的参数,函数体为 println(arg) 。
Scala 解释器可以推断出参数 arg 的类型是 String ,因为 String 是调用 foreach 那个数组的元素类型。当然,你也可以明确地指定参数的类型:
args.foreach((arg: String) => println(arg)) // 输出每个命令行参数
在 Scala 中,如果匿名函数只是一个接收单个参数的语句,可以不必给出参数名和参数本身。 这样,前面的例子可以简化为:
args.foreach(println) // 输出每个命令行参数
2.5. 初见 for 表达式
为了鼓励和引导大家使用更函数式的编程风格,Scala 并不支持 Java(或 C)中我们熟知的那个 for 循环语句。Scala 只支持函数式风格的 for 表达式,下面是它的一个例子:
for (arg <- args) // 输出每个命令行参数 println(arg)
上面中 arg <- args 是一种“生成器(Generator)语法”,它将遍历 args 的元素,每次迭代,一个新的名为 arg 的 val (常量)都会被初始化成一个元素的值。
注:上面例子中 arg 看上去像是 var (变量),因为每一次迭代都会拿到新的值。但它确实是 val (常量),因为在 for 表达式的循环体内它是不能被重新赋值的。实际情况是,对于 args 数组中的每一个元素,一个新的名为 arg 的 val (常量)会被创建出来,初始化成元素的值后, for 表达式的循环体才被执行。
Scala 的 for 表达式是用于选代的瑞士军刀,这里仅介绍了它最简单的用法。
2.6. 用类型“参数化”数组
在 Scala 中,可以用 new 来实例化对象或类的实例。当你用 Scala 实例化对象时,可以用值和类型来对其进行参数化(parameterize)。参数化的意思是在创建实例时对实例做“配置”。可以用值来参数化一个实例,做法是在构造方法的括号中传入对象参数。例如,如下 Scala 代码将实例化一个新的 java.math.BigInteger ,并用值“12345”对它进行参数化:
val big = new java.math.BigInteger("12345")
也可以用类型来参数化一个实例,做法是在“方括号”里给出一个或多个类型(如下面方括号中的 String ):
val greetStrings = new Array[String](3) greetStrings(0) = "Hello" // Scala 数组通过“圆括号”(而不是方括号)指定下标 greetStrings(1) = ", " greetStrings(2) = "world!\n" for (i <- 0 to 2) print(greetStrings(i))
上面例子中、 greetStrings 的类型为 Array[String] (即字符串数组),它被初始化成长度为 3 的数组。
如果你想更明确地表达你的意图,也可以显式地给出 greetStrings 的类型:
val greetStrings: Array[String] = new Array[String](3)
需要注意的是, greetStrings 的类型是 Array[String] ,而不是 Array[String](3) 。
下面介绍一下关于 val 的一个重要概念: 当你用 val 定义一个变量时,变量本身不能被重新赋值,但它指向的那个对象是有可能发生改变的。 在本例中,不能将 greetStrings 重新赋值成另一个数组, greetStrings 水远指向那个跟初始化时相同的 Array[String] 实例。不过“可以”改变那个 Array[String] 的元素(如 greetStrings(0) = "Hello" ),因此数组本身是可变的。
2.6.1. 单参数方法可以省略点号和括号
前面代码的最后两行代码包括一个 for 表达式,作用是将 greetStrings 数组中的各个元素依次打印出来:
for (i <- 0 to 2) print(greetStrings(i))
这个 for 表达式的第一行展示了 Scala 的另一个通行的规则: 如果一个方法只接收一个参数,在调用它的时候,可以不使用英文点号或圆括号。 本例中的 to 实际上是 Int 对象上一个接收 Int 参数的方法。代码 0 to 2 会被转换为 (0).to(2) 。
注意这种方式仅在显式地给出方法调用的目标对象时才有效。如不能直接写为: println 10 ,但可以写为:
Console println 10 // 相当于 Console.println(10)
2.6.2. 操作符即方法
Scala 从技术上讲并没有操作符重载(operator overloading) , 因为它实际上并没有传统意义上的操作符。类似 +, -, *, / 这样的字符可以被用作方法名。因此,当你在 Scala 解释器中键入 1 + 2 时,实际上是调用了 Int 对象 1 上名为 + 的方法,将 2 作为参数传入。如图 1 所示,也可以用更传统的方法调用方式来写 1 + 2 这段代码: (1).+(2) 。
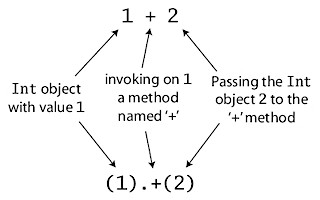
Figure 1: Scala 中所有操作都是方法调用
前面介绍过,Scala 数组通过“圆括号”(而不是方括号)指定下标。为什么这样设计呢?和 Java 相比 Scala 的持例更少。数组不过是类的实例,这一点和其他 Scala 实例没有本质区别。 当你用一组圆括号将一个或多个值包起来,并将其应用(apply)到某个对象时,Scala 会将这段代码转换成对这个对象的一个名为 apply 的方法的调用。 所以,在前面例子中, greetStrings(i) 会被转换成 greetStrings.apply(i) 。因此,在 Scala 中访问一个数组的元素就是一个简单的方法调用,跟其它方法调用一样。
同理, 当我们尝试通过圆括号应用了一个或多个参数的变量进行赋值时,编译器会将代码转换成对 update 方法的调用,这个 update 方法接收两个参数:圆括号括起来的值,以及等号右边的对象。 例如:
greetStrings(0) = "Hello"
会被转换成:
greetStrings.update(0, "Hello")
2.6.3. 更简单的方式初始化数组
Scala 还提供了一种更精简的方式来创建和初始化数组:
val numNames = Array("zero", "one", "two")
这段代码会创建一个长度为 3 的新数组,并用传入的字符串“zero”、“one 和“two“初始化。由于你传给它的是字符串,编译器推断出数组的类型为 Array[String] 。
在上面例子中,不用写 new 关键字,实际上是调用了一个名为 apply 的工厂方法,这个方法创建并返回了新的数组。这个 apply 方法接收一个变长的参数列表,该方法定义在 Array 的伴生对象(companion object)中。后文会介绍更多关于伴生对象的内容。 如果你是个 Java 程序员,可以把这段代码想象成是调用了 Array 类的一个名为 apply 的静态方法。 同样是调用 apply 方法但是更啰嗦的写法如下:
val numNames2 = Array.apply("zero", "one", "two")
2.7. 使用列表(不可变对象)
前面说过,Scala 数组是一个拥有相同类型的对象的“可变序列”。例如一个 Arrar[String] 只能包含字符串。虽然无法在数组实例化以后改变其长度,却可以改变它的元素值。因此,数组是可变的对象。
对于需要拥有相同类型的对象的“不可变序列”的场景,我们可以使用 Scala 中的 List 类。不过 Scala 中的 List(即 scala.List )跟 Java 的 java.util.List 的不同在于 Scala 的 List 是不可变的,而 Java 的 List 是可变的。
下面是创建 scala.List 的例子:
val oneTwoThree = List(1, 2, 3)
上面示例中,创建一个新的名为 oneTwoThree 的 val ,并将其初始化成一个新的拥有整型元素 1,2,3 的 List[Int] 。不用写 new 关键字,实际上是调用了 List 伴生对象的 apply 方法,它创建并返回 List。
由于 List 是不可变的,它们的行为有点类似于 Java 的字符串:当你调用列表的某个方法,而这个方法的名字看上去像是会改变列表的时候,它实际上是创建并返回一个带有新值的新列表。
List 中的方法 ::: 用于列表的拼接;方法 :: (读作“cons”)用于在已有列表的最前面添加一个新的元素;方法 :+ 用于在已有列表的末尾追加一个新的元素; List() 或者 Nil 表示空列表。如:
val a = List(1, 2) val b = List(3, 4) val c = a ::: b println(c) // List(1, 2, 3, 4) val d = 0 :: a println(d) // List(0, 1, 2) val e = a :+ 3 println(e) // List(1, 2, 3) val f = 1 :: 2 :: 3 :: Nil println(f) // List(1, 2, 3)
注:Scala 中很少使用 :+ ,因为往往列表的末尾追加一个新的元素所需要的时间随着列表的大小线性增加。如果想通过追加元素的方式高效地构建列表,可以依次在头部添加完成后,再调用 reverse 。也可以用 ListBuffer ,这是个可变的列表,支持追加操作,完成后调用 toList 即可。
2.7.1. 在右操作元上调用
在 Scala 中,如果方法名的最后一个字符是冒号 : ,则该方法的调用会发生在它的右操作元上。 所以,上面例子中的 val c = a ::: b 和 val d = 0 :: a 分别相当于:
val c = b.:::(a) // 相当于 val c = a ::: b val d = a.::(0) // 相当于 val d = 0 :: a
2.8. 使用元组(不可变对象)
元组(Tuple)和 List 类似,元组也是不可变的,不过和 List 不同的是,元组可以容纳不同类型的元素。
元组用起来很简单:要实例化一个新的元组,只需要将对象放在圆括号当中,用逗号隔开即可。一旦实例化好一个元组,可以用英文点号、下划线和从 1 开始的序号来访问每一个元素。如:
val pair = (99, "Luftballons") println(pair._1) // 输出 99 println(pair._2) // 输出 Luftballons
元组的实际类型取决于它包含的元素以及元素的类型。因此, (99, "Luftballons") 这个元组的类型是 Tuple2[Int, String] ,而元组 ('u', 'r', "the", 1, 4, "me") 的类型是 Tuple6[Char, Char, String, Int, Int, String] 。
你也许正好奇为什么不能像访间列表元素,也就是 “pair(0)” 那样访问元组的元素。背后的原因是列表的 apply 方法水远只返回同种类型,但元组里的元素可以是不同类型的: _1 可能是一种类型, _2 可能是另一种,等等。这些 _N 表示的字段名是从 1 开始而不是从 0 开始的,这是由其他同样支持静态类型元组的语言设定的传统,比如 Haskell 和 ML。
2.9. 使用集和映射
前面介绍过,在 Scala 中数组永远是可变的,列表永远是不可变的。
不过对于“集”(set)和“映射”(map),Scala 提供了可变和不可变两个版本,通过类继承关系来区分可变和不可变版本。
Scala 的 API 包含了一个基础的特质(trait)来表示“集”,它有两个子特质:一个用于表示“可变集”,另一个用于表示“不可变集”。 “特质”有点像 Java 中的接口。
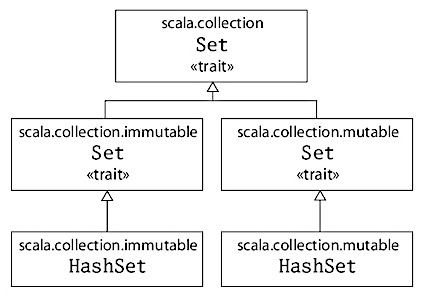
Figure 2: Scala 中“集”的类继承关系
从图 2 中可以看到,这三个特质都叫作 Set。不过它们的完整名称并不相同,因为它们分别位于不同的包。
2.9.1. 不可变集
下面是创建和初始化一个不可变集的实例:
var jetSet = Set("Boeing", "Airbus")
jetSet += "Lear" // 是 jetSet = jetSet + "Lear" 的缩写,所以 jetSet 必须定义为 var
println(jetSet.contains("Cessna")) // 输出 false
Scala 中可以像创建数组和列表那样创建集:通过调用 Set 伴生对象的名为 apply 的工厂方法。在上面例子中,实际上调用了 scala.collection.immutable.Set 的伴生对象的 apply 方法,返回一个默认的、不可变的 Set 对象。
要向集(可变集或者不可变集)添加新元素,可以对集调用 + 方法,传入一个新元素, + 方法都会创建并返回一个新的包含了新元素的集。
此外,可变集提供了方法 += ,不可变集没有这个方法。不过,不可集也可以使用 += , jetSet += "Lear" 相当于是下面代码的简写:
jetSet = jetSet + "Lear" // jetSet 必须是 var(不能是 val)
因此,实际上是将 jetSet 这个 var 重新赋值成了一个包含 "Boeing", "Airbus", "Lear" 的新集。
2.9.2. 可变集
如果你想要的是一个可变集,需要做一次引入(import),如:
import scala.collection.mutable
val movieSet = mutable.Set("Hitch", "Poltergeist")
movieSet += "Shrek"
println(movieSet)
上面例子中第一行,引入了可变的 Set。跟 Java 类似, import 语句让你在代码中使用简单名字,而不是更长的完整名 scala.colection.mutable.Set 。
将 movies 初始化成一个新的包含字符串“Hitch”和“Poltergeist“的新的可变集。接下来的一行通过调用可变集的 += 方法将“Shrek”添加到可变集里。当然,你也可以写为:
movieSet.+=("Shrek") // 相当于 movieSet += "Shrek"
注:这里 movieSet += "Shrek" 不是 movieSet = movieSet + "Shrek" 的简写, movieSet 定义为了 val ,不能再修改了。
2.9.3. 不可变映射
下面是不可变映射的例子:
val romanNumeral = Map( 1 -> "I", 2 -> "II", 3 -> "III", 4 -> "IV", 5 -> "V" ) println(romanNumeral(4)) // 输出 IV
2.9.4. 可变映射
下面是可变映射的例子:
import scala.collection.mutable val treasureMap = mutable.Map[Int, String]() treasureMap += (1 -> "Go to island.") treasureMap += (2 -> "Find big X on ground.") treasureMap += (3 -> "Dig.") println(treasureMap(2)) // 输出 Find big X on ground.
下面我们来具体分析一下 treasureMap += (1 -> "Go to island.") 这行代码。Scala 编译器会将二元的操作,比如 1 -> "Go to island." ,转换成标准的方法调用,即:
(1).->("Go to island.")
因此,当你写 1 -> "Go to island." 时,实际上是对这个值为 1 的整数调用 -> 方法,传入字符串 "Go to island." 。 可以在 Scala 的任何对象上调用这个 -> 方法(“隐式转换”,节 15.3.2 中会介绍相关细节),它将返回包含键和值两个元素的元组。 然后,这个元组传给了 treasureMap 指向的那个映射对象的 += 方法。
2.10. 从文件读取文本行
那些执行小的日常任务的脚本通常需要处理文件中的文本行。下面脚本,将从文件读取文本行,并将它们打印出来,在每一行前面带上当前行的字符数:
import scala.io.Source
if (args.length > 0) {
for (line <- Source.fromFile(args(0)).getLines())
println(line.length.toString + " " + line)
}
else
Console.err.println("Please enter filename")
上面例子中,表达式 Source.fromFile(args(0)) 尝试打开指定的文件并返回一个 Source 对象,在这个对象上,继续调用 getLines 方法。 getLines 方法返回一个迭代器 Iterator[String] ,每次迭代都给出一行内容(去掉了最后的换行符)。
3. 类和对象
3.1. 类、字段和方法
类是对象的蓝本(blueprint)。ー旦你定义好一个类,就可以用 new 关键字从这个类蓝本创建对象。例如,有了下面这个类定义:
class ChecksumAccumulator { // 类
private var sum = 0 // 字段
def add(b: Byte): Unit = { // 方法
sum += b
}
def checksum(): Int = { // 方法
return ~(sum & 0xFF) + 1 // 往往省略 return,因为默认返回方法体内最后一个表达式的值
}
}
就可以用如下代码创建 ChecksumAccumulator 的对象:
val c1 = new ChecksumAccumulator c1.add(1) c1.add(2) println(c1.checksum()) // 输出 -3
字段 sum 前面有 private 关键字,我们无法在外部直接访问它。如果省略 sum 前的 private ,则可以在外部直接访问它,如 c1.sum = 100 。方法也一样,私有方法用 private 修饰关键字。 公共访问是 Scala 的默认访问级别。
Scala 中方法的参数都是 val (而不是 var ),也就是说你不能对参数重新赋值 ,下面代码无法通过编译:
def add(b: Byte): Unit = {
b = 1 // This won't compile, because b is a val
sum += b
}
Scala 和 Java 的区别之一是 Java 要求你将公共的类放入跟类同名的文件中(例如需要将 SpeedRacer 类放到 SpeedRacer.java 中),而在 Scala 中没有这样的要求,可以放到任意命名 .scala 文件。不过,通常对于那些非脚本的场景,把类放入以类名命名的文件是推荐的做法,以便程序员能够更容易地根据类名定位到对应的文件。
3.2. 单例对象(伴生对象)
和 Java 不同,Scala 的类不允许有静态(statie)成员。对此类使用场景,Scala 提供了单例对象(singleton obiect)。单例对象的定义看上去跟类定义很像,只不过 class 关键字被换成了 object 关键字:
import scala.collection.mutable
object ChecksumAccumulator { // 和 class ChecksumAccumulator 定义在同一文件中
private val cache = mutable.Map.empty[String, Int]
def calculate(s: String): Int =
if (cache.contains(s))
cache(s)
else {
val acc = new ChecksumAccumulator
for (c <- s)
acc.add(c.toByte)
val cs = acc.checksum()
cache += (s -> cs)
cs
}
}
这个单例对象名叫 ChecksumAccumulator ,跟前一个例子中的类名一样。 当单例对象跟某个类共用同一个名字时,它被称作这个类的“伴生对象”(companion object)。必须在“同一个源码文件”中定义类和类的伴生对象。同时,类又叫作这个单例对象的伴生类(companion class)。类和它的伴生对象可以互相访同对方的私有成员。
如果你是 Java 程序员,可以把单例对象当作是用于放置那些用 Java 时打算编写的静态方法。可以用类似的方式来访问单例对象的方法:单例对象名、英文点和方法名。如:
ChecksumAccumulator.calculate("Every value is an object.")
类和单例对象的一个区别是单例对象不接收参数,而类可以。由于你设法用 new 实例化单例对象,也就没有任何手段来向它传参。每个单例对象都是通过一个静态变量引用合成类(symthetie class)的实例来实现的,因此单例对象从初始化的语义上跟 Java 的静态成员是一致的。尤其体现在,单例对象在有代码首次访问时才被初始化。
没有同名的伴生类的单例对象称为孤立对象(standalone object)。孤立对象有很多种用途,包括将工具方法归集在起,或定义 Scala 应用程序的入口等。下一节我们将展示这样的用法。
3.3. Scala 应用程序
要运行一个 Scala 程序,必须提供个独立对象的名称。这个独立对象需要包含一个 main 方法,该方法接收个 Array[String] 作为参数,结果类型为 Unit 。任何带有满足正确签名的 main 方法的独立对象都能被用作应用程序的入口。如:
// In file Summer.scala
import ChecksumAccumulator.calculate
object Summer {
def main(args: Array[String]) = {
for (arg <- args)
println(arg + ": " + calculate(arg))
}
}
3.4. App Trait
Scala 中提供了一个名为 App 的特质,在单例对象名后面加上 extends App ,可以省写 main 方法了, main 中的代码可以直接写在单例对象的花括号中,如上节的例子可以写为:
import ChecksumAccumulator.calculate
object Summer extends App {
for (arg <- args)
println(arg + ": " + calculate(arg))
}
4. 基础类型和操作
4.1. 一些基础类型
表 1 列出了 Scala 的一些基础类型和这些类型的实例允许的取值范围。
| Basic type | Range |
|---|---|
| Byte | 8-bit signed two's complement integer (\(-2^7\) to \(2^7 - 1\), inclusive) |
| Short | 16-bit signed two's complement integer (\(-2^{15}\) to \(2^{15} - 1\), inclusive) |
| Int | 32-bit signed two's complement integer (\(-2^{31}\) to \(2^{31} - 1\), inclusive) |
| Long | 64-bit signed two's complement integer (\(-2^{63}\) to \(2^{63} - 1\), inclusive) |
| Char | 16-bit unsigned Unicode character (\(0\) to \(2^{16} - 1\), inclusive) |
| Float | 32-bit IEEE 754 single-precision float |
| Double | 64-bit IEEE 754 double-precision float |
| Boolean | true or false |
| String | a sequence of Chars |
Byte、Short、Int、Long 和 Char 类型统称为整数类型(integral types)。整数类型加上 Float 和 Double 称为数值类型(numeric types)。
表 1 中除了 String(来自 java.lang.String )外,其它所有类型都是 scala 包的成员。例如,Int 的完整名称是 scala.Int 。
4.2. 字符串插值
Scala 包括了一个灵活的机制来支持字符串插值,允许你在字符串字面量中嵌人表达式。如:
val name = "reader" println(s"Hello, $name!")
Scala 中,双引号前面的 s 表示使用字符串插值器来处理该字面量。插值器会对内嵌的每个表达式求值,对求值结果调用 toString ,替换掉字面量中的那些表达式。因此, s"Hello, $name!" 会得到 "Hello, reader!" ,跟 "Hello, " + name + "!" 的结果一样。
在“s 字符串插值器”中,可以随时用美元符 $ 开始一个“表达式”。如:
scala> s"The answer is ${6 * 7}."
res0: String = The answer is 42.
Scala 默认还提供了另外两种字符串插值器: raw 和 f。
“raw 字符串插值器”的行为跟“s 字符串插值器”类似,不过它并不识别字符转义序列。举例来说,如下语句将打印出四个反斜杠,而不是两个:
println(raw"No\\\\escape!") // 打印出 No\\\\escape!
“f 字符串插值器”允许你给内嵌的表达式加上 printf 风格的指令。需要将指令放在表达式之后,以百分号 % 开始,使用 java.util.Formatter 中给出的语法。比如,可以这样来格式化 \(\pi\) :
scala> f"${math.Pi}%.5f"
res1: String = 3.14159
在 Scala 中,字符串插值是通过编译期重写代码来实现的。
4.3. 对象相等性
Scala 中可以使用 == 或 != 来测试两个对象是否相等。如:
scala> 1 == 2 res31: Boolean = false scala> 1 != 2 res32: Boolean = true scala> 2 == 2 res33: Boolean = true
这些操作实际上可以被应用于所有的对象,并不仅仅是基础类型。比如,可以用 == 来比较列表:
scala> List(1, 2, 3) == List(1, 2, 3) res34: Boolean = true scala> List(1, 2, 3) == List(4, 5, 6) res35: Boolean = false
继续沿着这个方向,还可以比较不同类型的两个对象:
scala> 1 == 1.0 res36: Boolean = true scala> List(1, 2, 3) == "hello" res37: Boolean = false
甚至可以拿对象跟 null 做比较,或者跟可能为 null 的对象做比较。不会抛出异常:
scala> List(1, 2, 3) == null res38: Boolean = false scala> null == List(1, 2, 3) res39: Boolean = false
可以看到, == 的实现很用心,大部分场合都能返回给你需要的相等性比较的结果。 这背后的规则很简单:首先检查左侧是否为 null ,如果不为 null ,调用 equals 方法。由于 equals 是个方法,你得到的确切比较逻辑取决于左侧参数的类型。
这种比较逻辑对于不同的对象,只要它们的内容一致,且 equals 方法的实现也是完全基于内容的情况下,都会得到 true 答案。举例来说,以下是针对两个碰巧拥有同样的五个字母的字符串的比较:
scala> ("he" + "llo") == "hello"
res40: Boolean = true
Scala 中的 == 和 Java 中的含义不一样。我们知道,Java 中的 == 是“引用相等性”测试,意思是测试两个变量是否指向 JVM 的堆上的同一个对象。
4.4. 富包装类
前面提到的每个基础类型,都有一个对应的“富包装类”,提供了额外的方法。通过“隐式转换”,基础类型可以直接调用其“富包装类”中的方法。所以,要了解基础类型的所有方法,你应该去看一下每个基础类型的富包装类的 API 文档。
表 2 列出了这些富包装类。
| Basic type | Rich wrapper |
|---|---|
| Byte | scala.runtime.RichByte |
| Short | scala.runtime.RichShort |
| Int | scala.runtime.RichInt |
| Long | scala.runtime.RichLong |
| Char | scala.runtime.RichChar |
| Float | scala.runtime.RichFloat |
| Double | scala.runtime.RichDouble |
| Boolean | scala.runtime.RichBoolean |
| String | scala.collection.immutable.StringOps |
5. 函数式对象
5.1. Rational 类的规范定义
有理数是可以用比例 \(\frac{n}{d}\) 表示的数,其中 \(n\) 和 \(d\) 是整数,但 \(d\) 不能为 0。跟浮点数相比,有理数的优势是小数是精确展现的,而不会舍入或取近似值。
后面将要设计一个类,对有理数的各项行为进行建模、包括允许它们被加、减、乘、除。完成后,可以像下面这样使用它:
scala> val oneHalf = new Rational(1, 2) oneHalf: Rational = 1/2 scala> val twoThirds = new Rational(2, 3) twoThirds: Rational = 2/3 scala> (oneHalf / 7) + (1 - twoThirds) res0: Rational = 17/42
5.2. 构建 Rational(类参数,主构造方法)
我们打算把有理数实现为“不可变”的(不可变的优点参见节 5.2.1),构造实例的时候提供所有需要的数据(即分子和分母),以后就不再改变了。
我们从如下的设计开始:
class Rational(n: Int, d: Int)
关于这段代码,首先要注意的一点是如果一个类没有定义体,并不需要给出空的花括号(加了也没问题)。类名 Rational 后的圆括号中的标识符 n 和 d 称作“类参数”(class parameter)。Scala 编译器将会采集到这两个类参数,并且自动创建一个“主构造方法”(primary constructor),它接收同样的这两个参数。
Scala 编译器会将你在类定义体中“除字段或方法定义外的代码”编译进类的主构造方法中。 举例来说,可以像这样来打印一条调试消息:
class Rational(n: Int, d: Int) {
println("Created " + n + "/" + d)
}
对这段代码,Scala 编译器会将 println 调用放在 Rational 的主构造方法中。这样一来,每当你创建一个新的 Rational 实例时,都会打印出相应的调试消息:
scala> new Rational(1, 2) Created 1/2 res0: Rational = Rational@2591e0c9
5.2.1. 不可变对象 VS 可变对象
首先,不可变对象通常比可变对象更容易推理,因为它们没有随着时间变化而变化的复杂的状态空间。其次,可以相当自由地传递不可变对象,而对于可变对象,在传递给其他代码之前,你可能需要对它们做保护式的拷贝。再次,假如有两个并发的线程同时访问某个不可变对象,它们没有机会在对象正确构造以后破坏其状态,因为没有线程可以改变某个不可变对象的状态。最后,不可变对象可以被安全地用作哈希表里的键。举例来说,如果某个可变的对象在被加到 HashSet 以后被改变了,当你下次再检索该 HashSet 的时候,你可能就找不到这个对象了。
不可变对象的主要劣势是它们有时候会需要拷贝一个大的对象图,而实际上也许一个局部的更新也能满足要求。在某些场景下,不可变对象可能用起来比较别扭,同时还带来性能瓶颈。因此,类库对于不可变的类也提供可变的版本这样的做法并不罕见。例如,StringBuilder 类就是对不可变的 String 类的一个可变的替代。
5.3. 方法重写(override)
当我们在前一例中创建 Rational 实例时,解释器打印了“Rational@2591e0c9”。解释器是通过对 Rational 对象调用 toString 来获取到这个看上去有点奇怪的字符串的。Rational 类默认继承了 java.lang.Object 类的 toString 实现。这个默认的实现没有输出有理数的分子和分母的任何线索。
下面将重写(override)方法 toString 的默认实现:
class Rational(n: Int, d: Int) {
override def toString = n.toString + "/" + d.toString
}
由于 Rational 现在可以漂亮地显示了,我们移除了先前版本的 Rational 中那段用于调试的 println 语句,可以在解释器中测试 Rational 的新行为:
scala> val r = new Rational(1, 2) r: Rational = 1/2
5.4. 检查前置条件(require)
我们不能允许有理数的分母为 0。解决这个问题的最佳方式是对主构造方法定义一个“前置条件”(precondition),前置条件是对传入方法或构造方法的值的结束,这是方法调用者必须要满足的。
实现前置条件的一种方式是用 require (它是定义在 Predef 这个独立对象中的方法,可以直接使用):
class Rational(n: Int, d: Int) {
require(d != 0)
override def toString = n.toString + "/" + d.toString
}
require 的参数为 false 时,会抛出 IllegalArgumentException 来阻止对象的构建。
5.5. 添加字段(实现有理数加法)
下一步,我们将给 Rational 类定义一个 add 方法,接收另一个 Rational 作为参数。为了保持 Rational 不可变,这个 add 方法不能将传入的有理数加到自己身上,它必须创建并返回一个新的持有这两个有理数的和的 Rational 对象。
你可能会认为这样写 add 就行了:
class Rational(n: Int, d: Int) { // This won't compile
require(d != 0)
override def toString = n.toString + "/" + d.toString
def add(that: Rational): Rational =
new Rational(n * that.d + that.n * d, d * that.d)
}
上面代码是无法通过编译的,因为 Rational 类中没有名为 d 和 n 的字段,所以 that.d 和 that.n 会报错。解决这个问题的办法就是在 Rational 类中添加两个字段分别保存分子和分母。如:
class Rational(n: Int, d: Int) {
require(d != 0)
val numer: Int = n
val denom: Int = d
override def toString = numer.toString + "/" + denom.toString
def add(that: Rational): Rational =
new Rational(
numer * that.denom + that.numer * denom,
denom * that.denom
)
}
这个新版本测试如下:
scala> val oneHalf = new Rational(1, 2) oneHalf: Rational = 1/2 scala> val twoThirds = new Rational(2, 3) twoThirds: Rational = 2/3 scala> oneHalf add twoThirds // 即 oneHalf.add(twoThirds) res2: Rational = 7/6
5.6. 自引用(this)
关键字 this 指向当前执行方法的调用对象。如:
def max(that: Rational) = if (this.numer * that.denom < that.numer * this.denom) that else this
上面例子中,一共有三个 this ,只有前面两个 this 可以省略。最后一个 this 不写的话,就没有可返回的结果了。
5.7. 辅助构造方法
在 Scala 中,主构造方法之外的构造方法称为“辅助构造方法”(auxiliary constructor)。例如,一个分母为 1 的有理数可以被更紧凑地直接用分子表示,比如可以简单地写成 5。因此,如果 Rational 的使用方可以直接写 Rational(5) 而不是 Rational(5,1) 也是件好事。这需要我们给 Rational 添加一个额外的辅助构造方法,只接收个参数,即分子,而分母被预定义为 1。如:
class Rational(n: Int, d: Int) {
require(d != 0)
val numer: Int = n
val denom: Int = d
def this(n: Int) = this(n, 1) // 辅助构造方法
override def toString = numer.toString + "/" + denom.toString
def add(that: Rational): Rational =
new Rational(
numer * that.denom + that.numer * denom,
denom * that.denom
)
}
Scala 的辅助构造方法以 def this(...) 开始。在 Scala 中,每个助构造方法都必须首先调用同一个类的另一个构造方法。 换句活说,Scala 每个辅助构造方法的第一条语句都必须是这样的形式 this(...) 。
强加这个约束的好处是 Scala 的每个构造方法最终都会调用到该类的主构造方法。这样一来,主构造方法就是类的单一入口。
5.8. 定义操作符
对于整数和浮点数,可以写:
x + y
但对于有理数,暂时还只能:
x add y // 或者 x.add(y)
在 Scala 中 + 是一个合法的标识符。可以简单地定义一个名为 + 的方法,也可以像整数和浮点数那样进行加法计算了。如:
class Rational(n: Int, d: Int) {
require(d != 0)
val numer: Int = n
val denom: Int = d
def this(n: Int) = this(n, 1) // auxiliary constructor
override def toString = numer.toString + "/" + denom.toString
def +(that: Rational): Rational =
new Rational(
numer * that.denom + that.numer * denom,
denom * that.denom
)
def *(that: Rational): Rational =
new Rational(numer * that.numer, denom * that.denom)
}
它的测试如下:
scala> val x = new Rational(1, 2) x: Rational = 1/2 scala> val y = new Rational(2, 3) y: Rational = 2/3 scala> x + y res7: Rational = 7/6 scala> x + x * y res1: Rational = 10/12 scala> (x + x) * y res2: Rational = 8/12
注:按照 Scala 操作符优先级, * 方法会比 + 方法绑得更紧。换句话说,涉及 Rational 的 + 和 * 操作,其行为会按照我们预期的那样。比如, x + x * y 会被当作 x + (x * y) 执行,而不是 (x + x) * y 。
5.9. Scala 中的标识符
Scala 中有四种标识符:
1、字母数字组合标识符(alphanumeric identifier)。以字母或下划线打头,可以包含更多的字母、数字或下划线。字符 $ 也算作字母,不过它预留给那些由 Scala 编译器生成的标识符。
2、操作符标识符(operator identifier)。由一个或多个操作字符构成。操作字符指的是那些可以被打印出来的 ASCII 字符,比如 +, :, ?, ~, # 等。以下是一些操作标识符举例:
+ ++ ::: <?> :->
Scala 编泽器会在内部将操作标识用内嵌 $ 的方式转成合法的 Java 标识符。比如 :-> 这个操作标识符会在内部表示为 $colon$minus$greater 。如果你打算从 Java 代码中访问这些标识符,就需要使用这种内部形式。
3、混合标识符(mixed identifier)。由一个字母数字组合标识符、一个下划线和一个操作符标识符组成。例如, unary_+ 或者 myvar_= 等都是混合标识符。
4、字面标识符(literal identifier)。用反引号 `` 括起来的任意字符串。这样一来,可以把 Scala 中的保留字也用作标识符了。如 Java 的 Thread 类的静态方法 yield 。不能直接写 Thread.yield() ,因为 yield 是 Scala 的保留字,正确的写法为: Thread.`yield`() 。
5.10. 方法重载(overload)
前面例子中定义了操作符 +, * 后,对于有理数 r ,我们可以这样使用它: r * new Rational(2) ,但目前还不能写为 r * 2 ,因为 * 的操作元必须都是 Rational。
要让 Rational 用起来更方便,我们将添加两个新的方法来对有理数和整数做加法和乘法。这就是“重载”(overload),每个方法名都被用于多个方法。
class Rational(n: Int, d: Int) {
require(d != 0)
val numer: Int = n
val denom: Int = d
def this(n: Int) = this(n, 1) // auxiliary constructor
override def toString = numer.toString + "/" + denom.toString
def +(that: Rational): Rational =
new Rational(
numer * that.denom + that.numer * denom,
denom * that.denom
)
def +(i: Int): Rational =
new Rational(numer + i * denom, denom)
def *(that: Rational): Rational =
new Rational(numer * that.numer, denom * that.denom)
def *(i: Int): Rational =
new Rational(numer * i, denom)
}
下面是这个新版本的测试:
scala> val r = new Rational(2, 3) r: Rational = 2/3 scala> r * new Rational(2) res1: Rational = 4/3 scala> r * 2 res2: Rational = 4/3
你将会看到,被调用的 * 方法具体是哪一个,取决于右操作元的类型。
5.11. 隐式转换
现在你已经可以写 r * 2 ,但目前还不能写为 2 * r 。因为, 2 * r 等价于 2.*(r) ,因此这是一个对 2 这个整数的方法调用。但 Int 类并没有一个接收 Rational 参数的乘法方法。它没法有这样个方法,因为 Rational 类并不是 Scala 类库中的标准类。
不过,Scala 有另外一种方式来解决这个问题:可以创建一个“隐式转换”(implicit conversion),在需要时自动将整数转换成有理数。可以往解释器里添加行:
scala> implicit def intToRational(x: Int) = new Rational(x)
这时, 2 * r 不再会报错了:
scala> val r = new Rational(2,3) r: Rational = 2/3 scala> 2 * r res15: Rational = 4/3
隐式转换不能定义在 Rational 类的内部。上面例子是直接在解释器中定义的,后文将介绍如何把隐式的方法定义放到 Rational 的伴生对象中,让使用 Rational 的程序员更容易地获取到这些隐式转换。
6. 内置的控制结构
Scala 只有为数不多的几个内置的控制结构,这些控制结构包括: if, while, for, try, match 和函数调用。
不同于在基础语法中不断地添加高级控制结构这种做法, Scala 倾向于在类库中(而不是基础语法中)增加支持。
Scala 所有的控制结构都返回某种值作为结果。这是函数式编程语言采取的策略,程序被认为是用来计算出某个值,因此程序的各个组成部分也应该计算出某个值。
6.1. if 表达式
Scala 的 if 跟很多其他语言一样。首先测试某个条件,然后根据条件是否满足来执行两个不同代码分支当中的一个。如:
val filename = if (!args.isEmpty) args(0) else "default.txt" println(filename)
6.2. while 循环(返回 Unit)
Scala 的 while 循环跟其他语言用起来没多大差别。它包含了一个条件检查和一个循环体,只要条件检查为真,循环体就会一遍接着一遍地执行。如使用 while 循环计算最大公约数:
def gcdLoop(x: Long, y: Long): Long = {
var a = x
var b = y
while (a != 0) {
val temp = a
a = b % a
b = temp
}
b
}
Scala 也有 do-while 循环,它跟 while 循环类似,只不过它是在循环体之后执行条件检查而不是在循环体之前。如用 do-while 来复述从标准输入读取的文本行,直到读到空行为止:
var line = ""
do {
line = readLine()
println("Read: " + line)
} while (line != "")
while 和 do-while 这样的语法结构,我们称之为“循环”而不是表达式,因为它们并不会返回一个有意义的值。它们的返回值的类型是 Unit 。这种类型的值只有一个,叫作“单元值”(unit value),记作 () 。
scala> def greet() = { println("hi") }
greet: ()Unit
scala> () == greet()
hi
res0: Boolean = true
函数 greet() 的返回类型为 Unit , greet() 会返回单元值 () 。下一行的测试印证了这一点。
注意: Scala 中赋值语句的结果永远是单元值 () ,这一点和 Java 是不同的(Java 中赋值语句的结果就是被赋的值)。考虑 Scala 代码:
var line = ""
while ((line = readLine()) != "") // This doesn't work!
println("Read: " + line)
由于赋值语句的结果永远是单元值,所以 line = readLine() 将永远返回 () ,它永远不等于 "" ,导致 while 循环将无法终止。
由于 while 循环没有返回值,纯函数式编程语言通常都不支持。这些语言有表达式,而不是循环。尽管如此, Scala 还是包括了 while 循环,因为有时候指令式的解决方案更易读。
一般来说,在函数式编程中,应该减少 while 循环的使用。下面是用递归重新实现计算最大公约数的例子(没有使用 while 循环):
def gcd(x: Long, y: Long): Long = if (y == 0) x else gcd(y, x % y)
6.3. for 表达式
Scala 的 for 表达式是用于迭代的瑞士军刀,它让你以不同的方式组合一些简单的因子来表达各式各样的迭代。它可以帮助我们处理诸如遍历整数序列的常见任务,也可以通过更高级的表达式来遍历多个不同种类的集合,根据任意条件过滤元素,产出新的集合。
6.3.1. 遍历集合
用 for 能做的最简单的事,是遍历某个集合的所有元素。例如:
val filesHere = (new java.io.File(".")).listFiles
for (file <- filesHere)
println(file)
上面例子中,首先对当前目录(“.”)创建个 Java.io.File 对象,然后调用它的 listFiles 方法。这个方法返回一个包含 File 对象的数组,这些对象分别应当前目录中的每个子目录或文件。我们将结果数组保存在 filesHere 变量中。通过 file <- filesHere 这样的“生成器”(generator)语法,我们将遍历 filesHere 的元素。每一次迭代,一个新的名为 file 的 val 都会被初始化为一个元素的值。注意,这个 file 是 val ,这意味着你不能在 for 代码块中对其重新赋值。
下面介绍一下用 for 遍历 Range 的例子:
scala> for (i <- 1 to 4)
println("Iteration " + i)
Iteration 1
Iteration 2
Iteration 3
Iteration 4
scala> for (i <- 1 until 4) // until 和 to 的区别在于:until 不包含上界
println("Iteration " + i)
Iteration 1
Iteration 2
Iteration 3
6.3.2. 过滤
有时你并不想完整地遍历集合,你想把它过滤成一个子集。这时可以给 for 表达式添加“过滤器”。过滤器是 for 表达式的圆括号中的一个 if 子句。例如,仅列出当前目录中以“.scala”结尾的那些文件:
val filesHere = (new java.io.File(".")).listFiles
for (file <- filesHere if file.getName.endsWith(".scala"))
println(file)
可以随意包含更多的过滤器,直接添加多个 if 子句即可。如:
for (
file <- filesHere
if file.isFile
if file.getName.endsWith(".scala")
) println(file)
6.3.3. 嵌套迭代
如果你添加多个 <- 子句,你将得到嵌套的“循环”。如:
for (
x <- 1 to 2
y <- 'a' to 'c'
) println("(" + x + ", " + y + ")")
上面代码会输出:
(1, a) (1, b) (1, c) (2, a) (2, b) (2, c)
下面再看一个例子:
val filesHere = (new java.io.File(".")).listFiles
def fileLines(file: java.io.File) =
scala.io.Source.fromFile(file).getLines().toList
def grep(pattern: String) =
for (
file <- filesHere
if file.getName.endsWith(".scala"); // 这里必须加分号
line <- fileLines(file)
if line.trim.matches(pattern)
) println(file + ": " + line.trim)
grep(".*gcd.*")
上面代码中, for 表达式有两个嵌套迭代。外部循环遍历 filesHere ,内部循环遍历每个以“.scala”结尾的 file 的 fileLines(file) 。
需要注意的是, for 表达式内第一个 if 后面必须有分号,否则会提示语法错误。如果 for 表达式使用“花括号”,则这个分别可以省略:
def grep(pattern: String) =
for { // Scala 编译器会“自动推断花括号中的分号”
file <- filesHere
if file.getName.endsWith(".scala")
line <- fileLines(file)
if line.trim.matches(pattern)
} println(file + ": " + line.trim)
这是因为 Scala 编译器会“自动推断花括号中的分号”,而圆括号中并不会自动推断分号。
6.3.4. 中途(mid-stream)变量绑定
上节介绍的例子中, line.trim 调用了两次(一次在 if 条件中,另一次在 println 参数中)。这并不是一个很轻的计算。因此你可能想最好只调用一次 line.trim 。可以用 = 来将表达式的结果绑定到新的变量上。被绑定的这个变量引人和使用起来都跟 val 一样,只不过去掉了 val 关键字。如:
def grep(pattern: String) =
for {
file <- filesHere
if file.getName.endsWith(".scala")
line <- fileLines(file)
trimmed = line.trim // trimmed 是中途变量,暂存了 line.trim 的结果
if trimmed.matches(pattern)
} println(file + ": " + trimmed)
6.3.5. 产出一个新的集合(yield)
虽然目前为止所有示例都是对遍历到的值进行操作然后忘掉它们,也的可以在每次这代中生成一个可以被记住的值。具体做法是在 for 表达式的代码体之前加上关键字 yield 。例如:
val filesHere = (new java.io.File(".")).listFiles
def scalaFiles = // yield 产生的 java.io.File 集合,赋值给了 scalaFiles
for {
file <- filesHere
if file.getName.endsWith(".scala")
} yield file
scalaFiles.foreach(println)
for 表达式的代码体每次被执行,都会产出一个值,本例中就是 file 。当 for 表达式执行完毕后,其结果将包含所有得到的值,包含在一个集合当中。
6.4. 用 try 表达式实现异常处理
Scala 的异常处理跟其他语言类似。方法除了正常地返回某个值外,也可以通过抛出异常终止执行。方法的调用方要么捕获并处理这个异常,要么自我终止,让异常传播到更上层调用方。异常通过这种方式传播,逐个展开调用栈,直到某个方法处理该异常或者再没有更多方法了为止。
6.4.1. 抛出异常
Scala 中使用 throw 关键字抛出异常。如:
val half =
if (n % 2 == 0)
n / 2
else
throw new RuntimeException("n must be even")
Scala 中 throw 是一个有结果类型的表达式。从技术上讲, 抛出异常这个表达式的类型是 Nothing 。 关于 Nothing 类型可参考节:10.2
6.4.2. 捕获异常
可以使用 try-catch 捕获异常。如:
import java.io.FileReader
import java.io.FileNotFoundException
import java.io.IOException
try {
val f = new FileReader("input.txt")
// Use and close file
} catch {
case ex: FileNotFoundException => // Handle missing file
case ex: IOException => // Handle other I/O error
}
这个 try-catch 表达式跟其他带有异常处理的语言一样,首先代码体会被执行,如果抛出异常,则会依次尝试每个 catch 子句。在本例中,如果异常的类型是 FileNotFoundException ,第一个子句将被执行。如果异常类型是 IOException ,那么第二个子句将被执行。而如果异常既不是 FileNotFoundException 也不是 IOException , try-catch 将会终止,异常将向上继续传播。
你会注意到一个 Scala 跟 Java 的区别,Scala 并不要求你捕获受检异常(checked exception)或在 throws 子句里声明。当然,也可以选择用 throws 注解来声明一个 throws 子句,但这并不是必须的。
6.4.3. try 表达式的返回值
跟 Scala 的大多数其他控制结构一样, try-catch-finally 最终返回一个值。如果没有异常抛出:整个表达式的结果就是 try 子句的结果;如果有异常抛出并且被捕获时,整个表达式的结果就是对应的 catch 子句的结果;而如果有异常抛出但没有被捕获,整个表达式就没有结果。
下面例子展示了如何做到解析 URL,但当 URL 格式有问题时返回一个默认的值:
import java.net.URL
import java.net.MalformedURLException
def urlFor(path: String) =
try {
new URL(path)
} catch {
case e: MalformedURLException =>
new URL("http://www.scala-lang.org")
}
注: finally 子句一般都是执行清理工作,比如关闭文件。通常来说,它们不应该改变主代码体或 catch 子句中计算出来的值。
6.5. match 表达式
Scala 的 match 表达式让你从若干可选项中选择,就像其他语言中的 switch 语句那样。如:
val firstArg = if (!args.isEmpty) args(0) else ""
val friend =
firstArg match {
case "salt" => "pepper"
case "chips" => "salsa"
case "eggs" => "bacon"
case _ => "huh?"
}
println(friend)
match 表达式中 break 是隐含的,并不会出现某个可选项执行完继续执行下一个可选项的情况,这通常是我们预期的。
6.6. 没有 break 和 continue
Scala 去掉了 break 和 continue。它们和函数式编程风格不搭。不过别担心,就算没有了 break 和 continue,一样有很多其他方式来编程。
假定你要检索参数列表,找个以“.scala”结尾但不以连字符开头的字符串。用 Java 的话你可能会这样写:
int i = 0; // This is Java
boolean foundIt = false;
while (i < args.length) {
if (args[i].startsWith("-")) {
i = i + 1;
continue;
}
if (args[i].endsWith(".scala")) {
foundIt = true;
break;
}
i = i + 1;
}
Scala 中没有 break 和 continue,也容易实现上面的功能。如:
var i = 0
var foundIt = false
while (i < args.length && !foundIt) {
if (!args(i).startsWith("-")) {
if (args(i).endsWith(".scala"))
foundIt = true
}
i = i + 1
}
如果你觉得你确实需要使用 break,Scala 标准类库也提供了帮助。 scala.util.control 包的 Breaks 类给出了一个 break 方法,可以被用来退出包含它的用 breakable 标记的代码块。下面是个例子:
import scala.util.control.Breaks._
import java.io._
val in = new BufferedReader(new InputStreamReader(System.in))
breakable {
while (true) {
println("? ")
if (in.readLine() == "") break
}
}
这段代码将不断反复地从标准输入读取非空的文本行。而一旦用户输入空行,控制流就会从外层的 breakable 代码块退出, while 循环也随之退出。
7. 函数和闭包
Scala 中,函数是一等公民。不仅可以定义函数并调用它们,还可以用函数字面量(匿名函数)来编写函数并将它们作为值(value)进行传递。
函数字面量被编译成类,并在运行时实例化成函数值(function value)。因此,“函数字面量”和“函数值”的区别在于,函数字面量存在于源码,而函数值以对象形式存在于运行时。这跟类(源码)与对象(运行时)的区别很相似。
7.1. 局部函数
函数可以定义在另一个函数体内,这称为局部函数。如:
import scala.io.Source
object LongLines {
def processFile(filename: String, width: Int) = {
def processLine(line: String) = { // 局部函数,在另一个函数体内定义
if (line.length > width)
println(filename + ": " + line.trim)
}
val source = Source.fromFile(filename)
for (line <- source.getLines())
processLine(line)
}
}
7.2. 占位符语法
为了让函数字面量更加精简,还可以使用下划线 _ 作为占位符,用来表示一个或多个参数,只要满足每个参数只在函数字面量中出现一次即可。例如, _ > 0 是一个非常短的表示法,表示一个检查某个值是否大于 0 的函数:
val someNumbers = List(-11, -10, -5, 0, 5, 10) someNumbers.filter((x) => x > 0) // 过滤出大于 0 的元素 someNumbers.filter(x => x > 0) // 同上 someNumbers.filter(_ > 0) // 同上。占位符语法,省写了参数
下面再介绍一个占位符语法的例子:
scala> val f = (_: Int) + (_: Int) // 占位符语法,省写了参数 f: (Int, Int) => Int = <function2> scala> f(5, 10) res9: Int = 15
多个下划线意味着多个参数,而不是对单个参数的重复使用。第一个下划线代表第一个参数,第二个下划线代表第二个参数,以此类推。 这意味着,只有当每个参数在函数字面量中出现不多不少正好一次的时候才能使用这样的精简写法。
7.3. 部分应用的函数
我们知道,调用函数时需要指定函数参数。如:
scala> def sum(a: Int, b: Int, c: Int) = a + b + c sum: (a: Int, b: Int, c: Int)Int
scala> sum(1, 2, 3) res10: Int = 6
部分应用的函数是一个表达式,在这个表达式中,并不给出函数需要的所有参数,而是给出部分,或完全不给。举例来说,要基于 sum 创建一个部分应用的函数,可以在“sum”之后放一个下划线 _ 。这将返回一个函数,可以被存放到变量中。参考下面的例子:
scala> val a = sum _ // a 是通过 sum 创建的部分应用函数 a: (Int, Int, Int) => Int = <function3> scala> a(1, 2, 3) // 相当于 a.apply(1, 2, 3),最终调用 sum(1, 2, 3) res11: Int = 6
前面例子中,创建 a 时 sum 的一个参数也没有指定。当然,也可以指定部分的参数。如:
scala> val b = sum(1, _: Int, 3) // 部分应用函数,指定了第 1 个和第 3 个参数 b: Int => Int = <function1> scala> b(2) // 相当于 b.apply(2),最终调用 sum(1, 2, 3) res13: Int = 6
7.4. 特殊的函数调用形式
7.4.1. 重复参数
Scala 允许你标识出函数的最后一个参数可以被重复。这让我们可以对函数传入一个可变长度的参数列表。要表示这样一个重复参数,需要在参数的类型之后加上一个星号 * 。例如:
scala> def echo(args: String*) =
for (arg <- args) println(arg)
echo: (args: String*)Unit
上面函数可以指定任意多个 String 类型参数。如:
scala> echo()
scala> echo("one")
one
scala> echo("hello", "world!")
hello
world!
不过,你不能向 echo 传递 Array[String] 。下面代码会报错:
scala> val arr = Array("What's", "up", "doc?")
arr: Array[String] = Array(What's, up, doc?)
scala> echo(arr)
<console>:10: error: type mismatch;
found : Array[String]
required: String
echo(arr)
^
为了解决上面问题,可以在数组参数后面加上冒号和一个 _* 符号,如:
scala> echo(arr: _*) // arr 是数组,在后面加上 : _* 后就可以传给 echo 了 What's up doc?
这种表示法告诉编译器将 arr 的每个元素作为参数传给 echo ,而不是将所有元素放在一起作为单个实参传入。
7.4.2. 带名字的参数
带名字的参数让你可以用不同的顺序将参数传给函数。其语法是简单地在每个实参前加上参数名和等号。例如:
scala> def speed(distance: Float, time: Float): Float = distance / time speed: (distance: Float, time: Float)Float scala> speed(100, 10) res27: Float = 10.0 scala> speed(distance = 100, time = 10) // 使用带名字的参数 res28: Float = 10.0
使用带名字的参数时,参数顺序就不所谓了。也可以只对部分参数指定名字。如:
scala> speed(time = 10, distance = 100) // 同 speed(distance = 100, time = 10) res29: Float = 10.0 scala> speed(100, time = 10) // 只指定了第 2 个参数的名字 res20: Float = 10.0
8. 控制抽象
8.1. 柯里化
下面是一个普通的函数(实现两个整数相加):
scala> def plainOldSum(x: Int, y: Int) = x + y plainOldSum: (x: Int, y: Int)Int scala> plainOldSum(1, 2) res4: Int = 3
下面是一个相似功能的函数,不过这次是经过“柯里化”的:
scala> def curriedSum(x: Int)(y: Int) = x + y // 定义柯里化函数,参数分别在独立小括号中 curriedSum: (x: Int)(y: Int)Int scala> curriedSum(1)(2) // 调用柯里化函数 res5: Int = 3
柯里化函数可以“部分应用”,即一次不指定全部参数。待定的参数用“占位符”表示,如:
scala> val onePlus = curriedSum(1)_ // “占位符”表示待定的参数 onePlus: Int => Int = <function1> scala> onePlus(2) res7: Int = 3
又如:
scala> val twoPlus = curriedSum(2)_ twoPlus: Int => Int = <function1> scala> twoPlus(2) res8: Int = 4
8.2. 编写新的控制结构
每当你发现某个控制模式在代码中多处出现,就应该考虑将这个模式实现为新的控制结构。
下面看一个常用的编码模式:打开某个资源,对它进行操作,然后关闭这个资源。可以用类似如下的方法,将这个模式捕获成一个控制抽象:
def withPrintWriter(file: File)(op: PrintWriter => Unit) = {
val writer = new PrintWriter(file)
try {
op(writer)
} finally {
writer.close()
}
}
有了这个方法后,你就可以像这样来使用它:
withPrintWriter(
new File("date.txt"),
writer => writer.println(new java.util.Date)
)
使用 withPrintWriter 把资源访问封装起来的好处是,确保文件在最后被关闭的是 withPrintWriter 而不是用户代码。因此 不可能出现使用者忘记关闭文件的情况。
如果用花括号而不是圆括号来表示参数列表,这样调用方的代码看上去更像是在使用内建的控制结构。 在 Scala 中,只要是那种只传入一个参数的方法调用,都可以选择使用花括号(代替圆括号)来将入参包起来:
scala> println("Hello, world!")
Hello, world!
scala> println { "Hello, world!" } // println 参数个数是 1,调用时可以用花括号(代替圆括号)
Hello, world!
对于前面介绍的 withPrintWriter,由于它有两个参数(参数个数不是 1),所以调用时不能用花括号代替圆括号。尽管如此,我们还是有办法让 withPrintWriter 的调用更像是“控制结构”(即使用大括号)。
我们把 withPrintWriter 进行柯里化,即写为下面形式:
def withPrintWriter(file: File)(op: PrintWriter => Unit) = { // 柯里化版本
val writer = new PrintWriter(file)
try {
op(writer)
} finally {
writer.close()
}
}
新版本跟老版本的唯一区别在于新版本是两个各包含一个参数的参数列表,而不是一个包含两个参数的参数列表。这时,我们可以像下面这样调用柯里化后的 withPrintWriter 了:
val file = new File("date.txt")
withPrintWriter(file) { writer => // 第二个参数使用的是大括号
writer.println(new java.util.Date)
}
上面例子中,第一个参数列表,也就是那个包含了一个 File 入参的参数列表,用的是“圆括号”;而第二个参数列表,即包含函数入参的那个,用的是“花括号”。看起来更像是“控制结构”了。
8.3. 传名参数(By-name parameter)
考虑下面函数:
var assertionsEnabled = true def boolAssert(predicate: Boolean) = if (assertionsEnabled && !predicate) throw new AssertionError
上面函数和预期的一样:
scala> boolAssert(5 > 3) // 不会抛出异常 scala> boolAssert(5 == 3) // 抛出异常 java.lang.AssertionError at .boolAssert(<console>:3) ... 28 elided
不过, boolAssert 的实现有一点点瑕疵。 由于 boolAssert 的参数类型为 Boolean,在 boolAssert(5 > 3) 圆括号中的表达式将“先于”对 boolAssert 的调用被求值。 就算断言被禁用(即 assertionsEnabled 为 false ),圆括号中的表达式仍然会被求值,这并不好:
scala> val x = 0 x: Int = 0 scala> var assertionsEnabled = false assertionsEnabled: Boolean = false scala> boolAssert(1 / x > 3) // 抛出了除零异常 java.lang.ArithmeticException: / by zero ... 33 elided
断言都被禁用了,调用它时还抛出了除零异常,有点不友好。下面将解决这个问题。
下面,我们把断言函数改写为:
var assertionsEnabled = true def myAssert(predicate: () => Boolean) = if (assertionsEnabled && !predicate()) throw new AssertionError
主要的区别在于,新的断言函数的参数类型变为了“函数”。
不过,由于它的参数是函数,用起来有点别扭:
scala> myAssert(() => 5 > 3) scala> myAssert(() => 5 == 3) java.lang.AssertionError at .myAssert(<console>:3) ... 28 elided
当我们禁用断言后,这个版本的断言函数不会抛出除零异常了:
scala> assertionsEnabled = false mutated assertionsEnabled scala> myAssert(() => 1 / 0 > 3) // 不会抛出除零异常
下面用传名参数(by-name parameter)来解决“由于参数是函数,导致调用方式很别扭”的问题。
要让参数成为传名参数,需要给参数一个以 => 开头的类型声明,而不是 ()=> 。例如,可以像这样将 myAssert 的 predicate 参数转成传名参数:把类型 ()=> Boolean 改成 = Boolean :
def byNameAssert(predicate: => Boolean) = // 定义 predicate 为传名参数 if (assertionsEnabled && !predicate) // predicate 不是函数,使用时去掉调用括号 throw new AssertionError
参数成为传名参数后,可以像下面这样更舒服的方式调用 byNameAssert 了:
byNameAssert(5 > 3)
By-name parameters are evaluated every time they are used. They won’t be evaluated at all if they are unused.
传名参数未使用时,不会求值。 所以禁用断言后, predicate 不会使用,从而不会求值,下面例子不会抛出除零异常:
assertionsEnabled = false // 禁用断言 byNameAssert(1 / 0 > 3) // 不会抛出除零异常
9. 类继承
9.1. 类继承实例
下面是类继承的例子:
class Point(xc: Int, yc: Int) { // 基类
val x: Int = xc
val y: Int = yc
def show(): Unit = {
println("This is Point, x: " + x + ", y: " + y)
}
}
class ColorPoint(u: Int, v: Int, c: String) extends Point(u, v) { // 子类
val color: String = c
def compareWith(pt: ColorPoint): Boolean =
(pt.x == x) && (pt.y == y) && (pt.color == color)
override def show(): Unit = {
println("This is ColorPoint, x: " + x + ", y: " + y + ", c: " + color)
}
}
object Test {
def printPoint(p: Point) = {
p.show() // 动态绑定
}
def main(args: Array[String]) : Unit = {
printPoint(new Point(10, 20)) // This is Point, x: 10, y: 20
printPoint(new ColorPoint(10, 20, "red")) // This is ColorPoint, x: 10, y: 20, c: red
}
}
有下面几点需要交待一下:
1、和 Java 一样,scala 也使用关键字 extends 表示继承。
2、类名后面小括号中的参数称为“类参数”(如 Point 中的 xc, yc 是类参数),参考节:5.2
3、重写一个非抽象方法必须使用 override 修饰符,如上面例子中 ColorPoint 中使用 override 重写了其基类中的 show() 方法。
4、对变量和表达式的方法调用是动态绑定(dynamic bound)的。意思是说实际被调用的方法实现是在运行时基于对象的类来决定的,而不是变量或表达式的类型决定的。如前面例子中尽管 printPoint 中的参数 p 是 Point 类型,但 printPoint(new ColorPoint(10, 20, "red")) 这一行传进来的是 ColorPoint 类型的对象,所以会调用 ColorPoint 中的 show() 方法。
5、和 Java 一样,用 final 修饰类,表示这个类不能被继承;用 final 修饰方法,表示这个方法不能被重写。这在前面例子中并没有体现,在这里顺便也交待一下。
9.2. 参数化字段(parametric field)
可以把类参数和字段合并在一起,称为参数化字段(parametric field)。 如:
class Point(xc: Int, yc: Int) { // 基类
val x: Int = xc
val y: Int = yc
def show(): Unit = {
println("This is Point, x: " + x + ", y: " + y)
}
}
可以改写为使用参数化字段的形式(在类参数前面用 val 或者 var 声明):
class Point(val x: Int, val y: Int) { // x, y 是“参数化字段”
def show(): Unit = {
println("This is Point, x: " + x + ", y: " + y)
}
}
定义参数化字段时,可以在字段前添加修饰符(如 override,private 等)。如:
class Cat {
val dangerous = false
}
class Tiger(
override val dangerous: Boolean, // dangerous 是参数化字段
private var age: Int // age 也是参数化字段
) extends Cat
上面的 Tiger 定义等同于:
class Tiger(param1: Boolean, param2: Int) extends Cat {
override val dangerous = param1
private var age = param2
}
9.3. 无参方法(parameterless method)
Scala 中,如果一个方法没有参数,则可以直接省略空括号,这称为无参方法(parameterless method)。
如下面的 squareDistance 是一个无参方法(用 def ,所以它不是字段):
class Point(val x: Int, val y: Int) {
def squareDistance: Int = x * x + y * y // squareDistance 用 def 定义,它是方法
}
val p = new Point(10, 20)
print(p.squareDistance) // 调用的是方法,但使用起来像“字段”
这样,使用方代码“不用关心它到底是方法还是字段”。这样的做法是所谓的统一访问原则(uniform access principle):使用方代码不应受到某个属性是用字段还是用方法实现的影响。
从使用方代码来看,“无参方法”和“字段”的唯一的区别是字段访问可能比方法调用略快,因为字段值在类初始化时就被预先计算好,而不是每次方法用时都重新计算。
重写时,我们甚至可以把“无参方法”变为“字段”(也可以把“字段”重写为“无参方法”) ,如:
class ColorPoint(u: Int, v: Int, c: String) extends Point(u, v) {
override val squareDistance: Int = x * x + y * y // squareDistance 用 val 定义(不再是方法)
}
上面例子中, ColorPoint 类的 squareDistance 字段是从其基类 Point 的“无参方法”重写而来。
9.3.1. 方法和字段在同一个命名空间(和 Java 不同)
在 Java 中字段和方法在不同的命名空间。也就是说我们可以定义一个方法和一个字段,它们具体相同的名字:
// This is Java
class CompilesFine {
private int f = 0;
public int f() {
return 1;
}
}
在 Scala 中,字段和方法在同一个命名空间,下面代码不会通过编译:
class WontCompile {
private var f = 0 // Won't compile, because a field
def f = 1 // and method have the same name
}
如果 Scala 中字段和方法不在同一个命名空间,那么前一节所说的“无参方法”重写为“字段”(或者“字段”重写为“无参方法”)就会乱套。
10. Scala 的继承关系
10.1. Scala 的类继承关系
Scala 的类继承关系如图 3 所示。
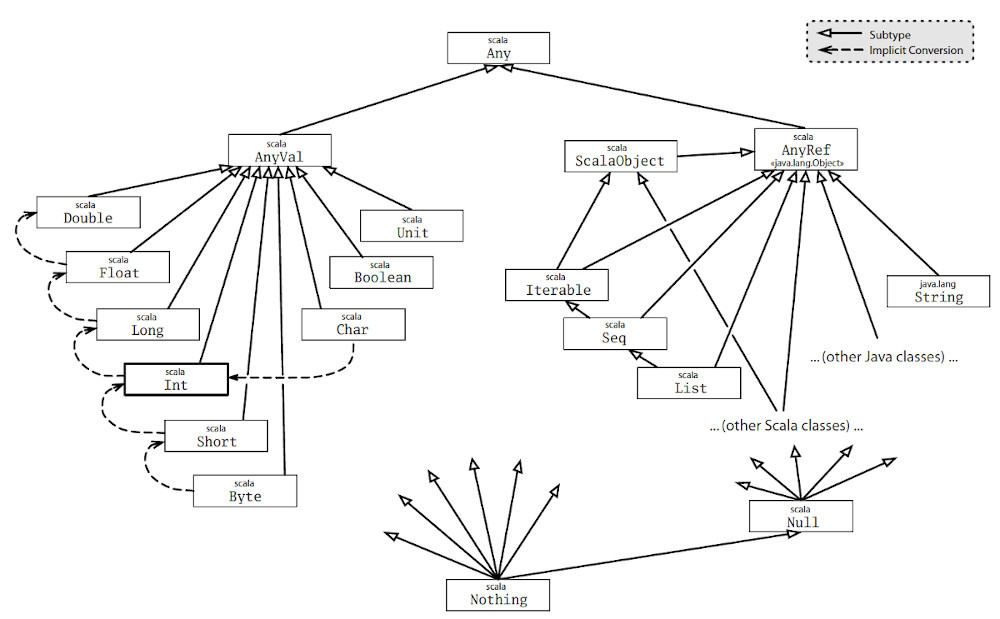
Figure 3: Scala Class Hierarchy
在继承关系的顶部是 Any 类,定义了如下方法:
final def ==(that: Any): Boolean final def !=(that: Any): Boolean def equals(that: Any): Boolean def ##: Int def hashCode: Int def toString: String
根类 Any 有两个子类: AnyVal 和 AnyRef 。 AnyVal 是中所有“值类”(value class)的父类。Scala 提供了九个内建的值类:Byte、Short、Char、Int、Long、Float、Double、Boolean 和 Unit。前八个对应 Java 的基本类型,它们的值在运行时是用 Java 的基本类型的值来表示的。这些类的实例在 Scala 中统统写作“字面量”。例如,42 是 Int 的实例,x 是 Char 的实例,而 false 是 Boolean 的实例。类 Unit 粗略地对应到 Java 的 void 类型;它用来作为那些不返回有意义结果的方法的结果类型。Unit 有且只有一个实例值,写作 () 。
不能用 new 来创建内置“值类”的实例。当然,自定义值类的实例还是用 new 创建,参考节:10.3
10.2. 底类型(bottom types)
在图 3 中的类继承关系的底部,你会看到两个类: scala.Null 和 scala.Nothing ,它们是 Scala 面向对象的类型系统用于统一处理某些“极端情况”(corner case)的特殊类型。
Null 类是 null 引用的类型,它是每个引用类(也就是每个继承自 AnyRef 的类)的子类。 Null 并不兼容于值类型,比如你并不能将 null 赋值给一个整数变量:
scala> val i: Int = null
^
error: an expression of type Null is ineligible for implicit conversion
Nothing 位于 Scala 类继承关系的底部,它是每个其他类型的子类型。不过并不存在这个类型的任何值。为什么需要这样一个没有值的类型呢?我们来看它的一个用处。
Scala 标准类库的 Predef 对象有一个 error 方法,其定义如下:
def error(message: String): Nothing = throw new RuntimeException(message)
error 的返回类型是 Nothing ,这告诉使用者该方法并不会正常返回(它会抛出异常)。由于 Nothing 是每个其他类型的子类型,可以以非常灵活的方式来使用 error 这样的方法。例如:
def divide(x: Int, y: Int): Int =
if (y != 0) x / y
else error("can't divide by zero")
这里 x/y 条件判断的“then”分支的类型为 Int ,而 else 分支(即调用 error 的部分)类型为 Nothing 。由于 Nothing 是 Int 的子类型,整个条件判断表达式的类型就是 Int ,正如方法声明要求的那样。
10.3. 定义自己的值类型
11. 特质(trait)
特质是 Scala 代码复用的基础单元。特质将方法和字段定义封装起来,然后通过将它们混入(mix in)类的方式来实现复用。它不同于类继承,类只能继承自一个超类,而类可以同时混入任意数量的特质。
11.1. 特质如何工作
特质的定义跟类定义很像,除了使用关键字 trait 。如下面是定义特质的例子:
trait Philosophical {
def philosophize() = {
println("I consume memory, therefore I am!")
}
}
该特质名为 Philosophical 。它并没有声明一个超类,因此跟类一样,有一个默认的超类 AnyRef 。它定义了一个名为 philosophize 的方法。一旦特质被定义好,我们就可以用 extends 或 with 关键字将它“混入”到类中。
下面例子展示了一个用 extends 混了 Philosophical 特质的类:
class Frog extends Philosophical {
override def toString = "green"
}
Frog 类混入了特质 Philosophical,从特质继承的方法(如例子中的 philosophize)跟从超类继承的方法用起来一样:
scala> val frog = new Frog frog: Frog = green scala> frog.philosophize() I consume memory, therefore I am!
特质同时也定义了一个类型。 以下是特质 Philosophical 被用作类型的例子:
scala> val phil: Philosophical = frog // phil 的类型是 Philosophical(特质) phil: Philosophical = green scala> phil.philosophize() I consume memory, therefore I am!
如果想要将特质混入一个显式继承自某个超类的类,可以用 extends 来给出这个超类,然后用 with 来混入特质。如:
class Animal // Scala 中可以省略空定义体中的花括号。同 class Animal {}
class Frog extends Animal with Philosophical { // Animal 是类,Philosophical 是特质
override def toString = "green"
}
如果你想混入多个特质,可以用多个 with 子句进行添加。如:
class Animal
trait HasLegs
class Frog extends Animal with Philosophical with HasLegs { // Philosophical, HasLegs 都是特质
override def toString = "green"
}
11.1.1. 重写特质中的方法
特质中的方法可以被重写。
如前面介绍的 Frog 类可以重写从特质 Philosophical 中继承的 philosophize 实现。重写的语法跟重写超类中声明的方法看上去一样,使用 override 关键字。参考下面这个例子:
class Animal
class Frog extends Animal with Philosophical {
override def toString = "green"
override def philosophize() = { // Frog 类中重写了特质 Philosophical 中的方法 philosophize
println("It ain't easy being " + toString + "!")
}
}
由于 Frog 重写了 Philosophical 的 philosophize 实现,当你调用这个方法时,将得到新的行为:
scala> val phrog: Philosophical = new Frog phrog: Philosophical = green scala> phrog.philosophize() It ain't easy being green!
11.1.2. 类和特质的区别
在特质定义中可以做任何在类定义中做的事,语法也完全相同。除了以下两种情况:首先,特质不能有任何“类参数”(即那些传类的主构造方法的参数)。换句话说,虽然可以像这样定义一个类:
class Point(x: Int, y: Int) // x, y 是类参数
而像下面这样定义特质则无法通过编译:
trait NoPoint(x: Int, y: Int) // Does not compile,特质不能有“类参数”
另一个类和特质的区别在于类中的 super 调用是静态绑定的,而在特质中 super 是动态绑定的。如果在类中编写 super.toString 这样的代码,你会确切地知道实际调用的是哪一个实现。在你定义特质的时候并没有被定义具体是哪个实现被调用,在每次该特质被混入到某个具体的类时,都会重新判定。
11.2. Ordered 特质
对象大小比较是一个较普遍的场景。
比如,在 5 中我们介绍了有理数类:Rational,如果我们想让其支持大小比较,可能会添加下面的代码:
class Rational(n: Int, d: Int) {
// ...
def < (that: Rational) = this.numer * that.denom < that.numer * this.denom
def > (that: Rational) = that < this
def <= (that: Rational) = (this < that) || (this == that)
def >= (that: Rational) = (this > that) || (this == that)
}
上面类中定义了四个比较操作符( <, >, <=, >= ),我们注意到其中的三个比较操作符都是基于第一个操作符来定义的。而且这些方法对于任何其他可以被比较的类来说都是一样的。也就是说这个类里的相当多代码都是样板代码,在其他实现了比较操作的类中不会与此有什么不同。
由于这个问题如此普遍,Scala 提供了专门的特质来解决。这个特质叫作 Ordered 。使用的方式是将所有单独的比较方法替换成 compare 方法。 Ordered 特质将为你定义 <, >, <=, >= ,这些方法都是基于你提供的 compare 来实现的。因此, Ordered 特质允许你只实现一个 compare 方法来增强某个类,让它拥有完整的比较操作。
以下是用 Ordered 特质来对 Rational 定义比较操作的代码:
class Rational(n: Int, d: Int) extends Ordered[Rational] {
// ...
def compare(that: Rational) = (this.numer * that.denom) - (that.numer * this.denom)
}
显然,这段代码比前面的代码都简单很多。
这个版本的 Rational 混入了 Ordered 特质与之前讨论过的其他特质不同:Ordered 要求你在混入时传入一个类型参数(type parameter)。也就是 Ordered[Rational] 中括号中的 Rational。
要小心 Ordered 特质只会为你增加 <, >, <=, >= ,而并不会帮你定义 equals 方法,因为它做不到。这当中的问题在于用 compare 来实现 equals 需要检查传入对象的类型,而由于(Java 的)类型擦除机制,Ordered 特质自己无法完成这个检查。
11.3. 作为可叠加修改的特质
特质让你修改类的方法,而且还允许你将这些修改叠加起来。
考虑这样一个例子,对某个“整数队列”叠加修改。这个队列有两个操作:put,它将整数放入队列;get,它将它们取出来。
给定一个实现了这样一个队列的类,可以定义特质来执行如下这些修改:
- Doubling:将所有放入队列的整数翻倍;
- Incrementing:将所有放入队列的整数加一;
- Filtering:从队列中去除负整数。
这三个特质有修改(modification)操作,因为它们修改底层的队列类,而不是自己定义的队列类。这三个特质也是“可叠加的”(stackable)。比如,可以选择特质 Incrementing 和 Filtering,将它们混入类,得到的新类具有这两个特质的效果。
下面将通过具体代码演示一下特质是“可叠加的”。
下面是一个抽象的 IntQueue 类,它有一个 put 方法将新的整数加入队列,以及一个 get 方法从队列中去除并返回整数:
abstract class IntQueue {
def get(): Int
def put(x: Int)
}
下面给出了使用 ArrayBuffer 的 IntQueue 的基本实现:
import scala.collection.mutable.ArrayBuffer
class BasicIntQueue extends IntQueue {
private val buf = new ArrayBuffer[Int]
def get() = buf.remove(0)
def put(x: Int) = { buf += x }
}
下面对 BasicIntQueue 进行基本测试:
scala> val queue = new BasicIntQueue queue: BasicIntQueue = BasicIntQueue@23164256 scala> queue.put(10) scala> queue.put(20) scala> queue.get() res9: Int = 10 scala> queue.get() res10: Int = 20
现在我们来看看如何用特质修改这个行为。下面给出了在放入队列时对整数翻倍的特质 Doubling 的实现:
trait Doubling extends IntQueue {
abstract override def put(x: Int) = { super.put(2 * x) }
}
Doubling 特质有两个有意思的地方。首先,它声明了一个超类 IntQueue。这个声明意味着这个特质只能被混入同样继承自 IntQueue 的类。因此,可以将 Doubling 混入 BasicIntQueue,但不能将它混入其它类(如 Rational)。
第二个有意思的地方是该特质有在一个声明为抽象的方法里做了一个 super 调用。对于普通的类而言这样的调用是非法的,因为它们在运行时必定会失败。不过对于特质来说,这样的调用实际上可以成功。由于特质中的 super 调用是动态绑定的(在节 11.1.2 中提到过),只要在给出了该方法具体定义的特质或类之后混入,Doubling 特质里的 super 调用就可以正常工作。
对于实现可叠加修改的特质,这样的安排通常是需要的。为了告诉编译器你是特意这样做的,必须将这样的方法标记为 abstract override 这样的修饰符组合只允许用在特质的成员上,不允许用在类的成员上,它的含义是该特质必须混入某个拥有该方法具体定义的类中。
下面是 BasicIntQueue 混入特质 Doubling 的例子:
scala> class MyQueue extends BasicIntQueue with Doubling defined class MyQueue scala> val queue = new MyQueue queue: MyQueue = MyQueue@44bbf788 scala> queue.put(10) scala> queue.get() // 放入队列的是 10,取出来时是 20。特质 Doubling 已经生效 res12: Int = 20
从上面例子中可知,放入队列的是 10,取出来时是 20,所以特质 Doubling 已经生效。
注意到 MyQueue 并没有定义新的代码,它只是简单地给出一个类然后混入一个特质。在这种情况下,可以在用 new 实例化的时候直接给出 BasicIntQueue with Doubling ,而不是定义一个有名字的类。如:
scala> val queue = new BasicIntQueue with Doubling queue: BasicIntQueue with Doubling = $anon$1@141f05bf scala> queue.put(10) scala> queue.get() res14: Int = 20
为了搞清楚如何叠加修改,我们需要定义另外两个修改特质 Incrementing 和 Filtering:
trait Incrementing extends IntQueue {
abstract override def put(x: Int) = { super.put(x + 1) }
}
trait Filtering extends IntQueue {
abstract override def put(x: Int) = {
if (x >= 0) super.put(x)
}
}
下面演示一下同时混入两个特质(Incrementing 和 Filtering)的例子:
scala> val queue = new BasicIntQueue with Incrementing with Filtering queue: BasicIntQueue with Incrementing with Filtering... scala> queue.put(-1); queue.put(0); queue.put(1) scala> queue.get() res16: Int = 1 scala> queue.get() res17: Int = 2
从例子中,可以发现,队列中存入的负数(-1)被丢弃了,其它两个非负数被增加了 1。可见两个特质都生效了。
混入特质的顺序是重要的。确切的规则稍微有些复杂,不过粗略地讲,“越靠右出现的特质越先起作用”。当你调用某个带有混入的类的方法时,最靠右端的特质中的方法最先被调用。 把前面例子中特质 Incrementing 和 Filtering 的混入顺序换一下,即:
scala> val queue = new BasicIntQueue with Filtering with Incrementing queue: BasicIntQueue with Filtering with Incrementing... scala> queue.put(-1); queue.put(0); queue.put(1) scala> queue.get() res19: Int = 0 scala> queue.get() res20: Int = 1 scala> queue.get() res21: Int = 2
可以发现,存入的负数(-1)没有被丢弃了,而是也和其它数一样被加 1 了,可见最右出现的 Incrementing 先起作用。
12. 包和引入
12.1. 将代码放进包里
到目前为止,前面介绍的代码都位于未名(unnamed)包。在 Scala 中,可以通过两种方式将代码放进带名字的包里。第一种方式是在文件顶部放置一个 package 子句,让整个文件的内容放进指定的包,如:
package bobsrockets.navigation // 方式一 class Navigator
另一种将 Scala 代码放进包的方式更像是 C# 的命名空间。可以在 package 子句之后加上一段用花括号包起来的代码块,这个代码块包含了进入该包的定义。这个语法称为“打包”(packaging)。如前面介绍的代码还可以写为:
package bobsrockets.navigation { // 方式二
class Navigator
}
打包还可以嵌套,如:
package bobsrockets {
package navigation {
// In package bobsrockets.navigation
class Navigator
package tests {
// In package bobsrockets.navigation.tests
class NavigatorSuite
}
}
}
特殊的包名 _root_ 表示“最顶层包”。 当不同层级的包名有冲突时,它有用处:
1: // In file launch.scala 2: package launch { // 一处 3: class Booster3 4: } 5: 6: // In file bobsrockets.scala 7: package bobsrockets { 8: 9: package navigation { 10: package launch { // 二处 11: class Booster1 12: } 13: class MissionControl { 14: val booster1 = new launch.Booster1 // 同 new bobsrockets.navigation.launch.Booster1 15: val booster2 = new bobsrockets.launch.Booster2 16: val booster3 = new _root_.launch.Booster3 // 省略 _root_ 会报错 17: } 18: } 19: 20: package launch { // 三处 21: class Booster2 22: } 23: }
上面代码有三处名为 launch 的包(第 2 行,第 10 行,第 20 行)。第 16 行中的 _root_ 不能省略,如果省略,会去第 10 行的 launch 包中去寻找类 Booster3,但找不到,所以报错。
12.2. 引入(import)
在 Scala 中,我们可以用 import 子句引入包和它们的成员。被引入的项目可以用 File 这样的简单名称访问,而不需要限定名称,比如 java.io.File 。
假设有代码:
package bobsdelights
abstract class Fruit(
val name: String,
val color: String
)
object Fruits {
object Apple extends Fruit("apple", "red")
object Orange extends Fruit("orange", "orange")
object Pear extends Fruit("pear", "yellowish")
val menu = List(Apple, Orange, Pear)
}
import 子句使得某个包或对象的成员可以只用它们的名字访问,而不需要在前面加上包名或对象名。下面是一些简单的例子:
// easy access to Fruit import bobsdelights.Fruit // 可以直接使用 Fruit 了 // easy access to all members of bobsdelights import bobsdelights._ // 可以直接使用 Fruit, Fruits 了 // easy access to all members of Fruits import bobsdelights.Fruits._ // 可以直接使用 Apple,Orange,Pear,menu 了
Scala 的引入可以出现在任何地方,不仅仅是在某个编译单元的最开始,而且它们还可以引用任意的值。比如:
def showFruit(fruit: Fruit) = {
import fruit._ // import 的是参数名!
println(name + "s are " + color)
}
showFruit 方法引入了其参数 fruit (类型为 Fruit )的所有成员。这样接下来的 println 语句就可以直接引用 name 和 color 。这两个引用等同于 fruit.name 和 fruit.color 。
12.2.1. 引入选择性子句
Scala 中的引入还可以重命名或隐藏指定的成员。做法是包在花括号内的“引入选择器子句”(import selector clause)中,这个子句跟在那个我们要引入成员的对象后面。以下是一些例子:
import Fruits.{Apple, Orange} // 仅从 Fruits 中引入 Apple, Orange 两个成员
import java.sql.{Date => SDate} // 从 java.sql 中引入 Date,且重命名为 SDate
import Fruits.{Apple => McIntosh, Orange} // 引入 Apple(且重命名为 McIntosh),和 Orange
import Fruits.{_} // 引入 Fruits 中所有成员,同 import Fruits._
import Fruits.{Apple => McIntosh, _} // 引入 Fruits 对象所有成员,且将 Apple 重命名为 MeIntosh
下面再看一些例子:
import Fruits.{Pear => _, _} // 引入 Fruits 对象中除 Pear 外的所有成员
上面代码会引入除 Pear 之外 Fruits 的所有成员。可以认为是把 Pear 重命名为了 _ ,将某个名称重命名为 _ 意味着将它完全隐藏掉。
12.3. 隐式引入
Scala 对每个程序都隐式地添加了下面引入:
import java.lang._ // everything in the java.lang package import scala._ // everything in the scala package import Predef._ // everything in the Predef object
比如,可以直接写 Thread ,而不是全名 java.lang.Thread ;可以直接写 List ,而不是全名 scala.List ;可以直接写 assert ,而不是全名 Predef.assert 。
Scala 对这三个引入子句做了一些特殊处理, 后引入的会遮挡前面。 的举例来说, scala 包和 java.lang 包都定义了 StringBuilder 类。由于 scala 后引入,因此 StringBuilder 这个简单名称会引用到 scala.StringBuilder ,而不是 java.lang.StringBuilder 。
12.4. 指定保护范围的访问修饰符
Scala 中,访问修饰符(private,protected)可以通过使用限定词强调。格式为:
private[X] protected[X]
这里的 X 指代某个所属的包、类或单例对象。如果写成 private[X] ,表示“这个成员除了对 X 中的类或 X 中的包中的类及它们的伴生对像可见外,对其它所有类都是 private”。如:
package society {
package professional {
class Executive {
private[professional] var workDetails = null // 只能被包 professional 内的成员访问
private[society] var friends = null // 只能被包 society 内的任何成员访问
private[this] var secrets = null // 只能通过 this 访问
def help(another : Executive) : Unit = {
println(another.workDetails)
println(another.secrets) // ERROR
println(this.secrets)
}
}
}
}
12.5. 包对象(Package object)
如果你有一些希望在“整个包中都能使用”的辅助方法或者变量,可将它们统一放在包的顶层(也就是它不属于某个类)。具体的做法是把这些辅助方法或者变量的定义放在“包对象”(package object)中。
关键字组合 package object 用于定义“包对象”,如:
// In file bobsdelights/package.scala
package object bobsdelights { // package object 用于定义包对象
def showFruit(fruit: Fruit) = {
import fruit._
println(name + "s are " + color)
}
}
每个包都允许最多有一个包对象,一般其文件名命名为 package.scala。
下面是包对象中 showFruit 成员的使用例子:
import bobsdelights.Fruits
import bobsdelights.showFruit // 引入包对象中的 showFruit 成员
object PrintMenu {
def main(args: Array[String]) = {
for (fruit <- Fruits.menu) {
showFruit(fruit)
}
}
}
13. Case Classes and Pattern Matching
样例类(case class)和模式匹配(pattern matching)这组孪生的语法结构可以使我们更方便地编写规则的、未封装的数据结构。这两个语法结构对于表达树形的递归数据尤其有用。
13.1. 一个简单的例子
下面通过一个简单的例子来介绍一下什么是“样例类”和“模式匹配”。
假定你正在设计的某个领域特性语言(DSL),需要编写一个操作其算术表达式的类库。第一件事,我们需要定义输入数据。我们将注意力集中在由变量、数、以及一元和二元操作符组成的算术表达式上。用 Scala 的类层次结构来表达,如下所示:
abstract class Expr case class Var(name: String) extends Expr case class Number(num: Double) extends Expr case class UnOp(operator: String, arg: Expr) extends Expr case class BinOp(operator: String, left: Expr, right: Expr) extends Expr
这个层次结构包括一个抽象的基类 Expr 和四个子类,每一个都表示我们要考虑的一种表达式。所有五个类的定义体都是空的(Scala 允许我们省去空定义体的花括号,即 class C 和 class C {} 是相同的)。
注意到四个子类的前面都有 case 修饰符,带有这种修饰符的类称为“样例类”。
13.1.1. 样例类
前面说过,带有 case 修饰符的类称作样例类(case class)。对于样例类,Scala 编译器对其添加一些语法上的便利,下面将一一介绍。
首先,它会添加一个跟类同名的工厂方法。这意味着我们可以用 Var("x") 来构造一个 Var 对象,而不用稍长版本的 new Var("x") :
scala> val v = Var("x") // Var 是工厂方法,不用麻烦地写为 val v = new Var("x") 了
v: Var = Var(x)
当你需要嵌套定义时,工厂方法尤为有用。由于代码中不再到处是 new 关键字,可以一眼就看明白表达式的结构:
scala> val op = BinOp("+", Number(1), v) // 如果没有工厂方法,则代码到处是 new 关键字
op: BinOp = BinOp(+, Number(1.0), Var(x))
其次,第二个语法上的便利是参数列表中的参数都隐式地获得了一个 val 前缀(即“类参数化字段”,参考节 9.2)。因此它们会被当作字段处理:
scala> v.name res0: String = x scala> op.left res1: Expr = Number(1.0)
再次,编译器会帮我们以“自然”的方式实现 toString, hashCode 和 equals 方法。这些方法分别会打印、哈希、比较包含类及所有入参的整棵树。由于 Scala 的 == 总是代理给 equals 方法,这意味着以样例类表示的元素总是以结构化的方式做比较:
scala> println(op) // toString 实现得更自然了,不重写 toString 也可得到友好的输出
BinOp(+,Number(1.0),Var(x))
scala> op.right == Var("x") // 以结构化的方式做比较,而不是严格的对象内存地址相同
res3: Boolean = true
最后,编译器还会添加一个 copy 方法用于得到修改过的拷贝。这个方法可以用于得到除了一两个属性不同之外其余完全相同的该类的新实例。这个方法用到了带名字的参数(参考节 7.4.2)和缺省参数(参考节 7.4.3)。我们用带名字的参数给出想要做的修改。对于任何你没有给出的参数,都会用老对象中的原值。例如下面这段制作一个跟 op 一样不过操作符改变了的操作的代码:
scala> op.copy(operator = "-") res4: BinOp = BinOp(-,Number(1.0),Var(x))
所有这些带来的是大量的便利(代价却很小你需要多写一个 case 修饰符,并且你的类和对象会变得大那么一点。之所以更大,是因为生成了额外的方法,并且对于构造方法的每个参数都隐式地添加了字段。不过,样例类最大的好处是它们支持模式匹配。
13.1.2. 模式匹配(match 表达式)
假定我们想简化前面展示的算术表达式。比如使用下面规则来简化算术表达式:
UnOp("-", UnOp("-", e)) => e // Double negation
BinOp("+", e, Number(0)) => e // Adding zero
BinOp("*", e, Number(1)) => e // Multiplying by one
这个任务可以用“模式匹配”来完成:
def simplifyTop(expr: Expr): Expr = expr match {
case UnOp("-", UnOp("-", e)) => e // Double negation
case BinOp("+", e, Number(0)) => e // Adding zero
case BinOp("*", e, Number(1)) => e // Multiplying by one
case _ => expr
}
模式匹配包含一系列以 case 关键字打头的可选分支。每个可选分支都包括一个模式(pattern)以及一个或多个表达式,如果模式匹配(match)了,这些表达式就会被求值。箭头符 => 用于将模式和表达式分开。
一个 match 表达式的求值过程是按照模式给出的顺序逐一尝试的。第一个匹配上的模式被选中,跟在这个模式后面的表达式被执行。
模式有很多种类。像 e 这样的“变量模式”可以匹配任何值。匹配后,在右侧的表达式中,这变量将指向这个匹配的值。“通配模式”,即 _ ,它也匹配任何值,不过它并不会引入一个变量名来指向这个值。
构造方法模式(constructor pattern),看上去就像 UnOp("-", e) 。这个模式匹配所有类型为 UnOp 且首个入参匹配 "-" 而第二个入参匹配 e 的值。注意构造方法的入参本身也可以是模式。这允许我们用精简的表示法来编写有深度的模式。例如:
UnOp("-", UnOp("-", e))
想象一下如果用访问者模式来实现相同的功能要怎么做!再想象一下如果用一长串 if 语句、类型测试和类型转换来实现相同的功能,几乎同样笨拙。
函数 simplifyTop 中模式匹配语句的前三个 case 中既用到了“变量模式”又用到了“构造方法模式”,最后一个 case 使用的是“通配模式”。
模式还有很多其它种类,这里简单地介绍三种(变量模式/构造方法模式/通配模式),后文还将介绍所有模式。
13.2. 模式的种类
前面的例子快速地展示了几种模式,接下来花些时间详细来介绍每一种。
13.2.1. 通配模式
通配模式 _ 会匹配任何对象。前面已经看到过通配模式用于缺省捕所有的可选路径,就像这样:
expr match {
case BinOp(op, left, right) => println(expr + " is a binary operation")
case _ => // 什么都没写,表示 Unit 值,即 ()
}
通配模式还可以用来忽略某个对象中你并不关心的局部。 例如,前面这个例子实际上并不需要关心二元操作的操作元是什么,它只是检查这个表达式是否是二元操作,仅此而已。因此,这段代码也完全可以用通配模式来表示 BinOp 的操作元,如:
expr match {
case BinOp(_, _, _) => println(expr + " is a binary operation")
case _ => println("It's something else")
}
13.2.2. 常量模式
常量模式仅匹配自己。任何字面量都可以作为常量(模式)使用。例如,5、true 和"hello"都是常量模式。同时,任何 val 或单例对象也可以被当作常量(模式)使用。例如,Nil 这个单例对象能且仅能匹配空列表。下面给出了常量模式的例子:
def describe(x: Any) = x match {
case 5 => "five"
case true => "truth"
case "hello" => "hi!"
case Nil => "the empty list"
case _ => "something else"
}
13.2.3. 变量模式
变量模式变量模式匹配任何对象,这一点跟通配模式相同。不过不同于通配模式的是, Scala 将对应的变量绑定成匹配上的对象在绑定之后,你就可以用这个变量来对对象做进一步的处理。
下面例子中第二个 case 是使用的变量模式:
expr match {
case 0 => "zero"
case somethingElse => "not zero: " + somethingElse // somethingElse 是“模式变量”
}
13.2.3.1. 如何区别变量模式还是常量模式
考虑下面例子:
scala> import math.{E, Pi}
import math.{E, Pi}
scala> E match {
case Pi => "Pi = " + Pi // Pi 是常量(因为不是以“小写字母”打头)
case _ => "Not Pi"
}
res0: String = Not Pi
scala> Pi match {
case Pi => "Pi = " + Pi // Pi 是常量(因为不是以“小写字母”打头)
case _ => "Not Pi"
}
res1: String = Pi = 2.718281828459045
上面的输出符合你的预期。 但 Scala 编译器是如何知道 Pi 是从 scala.math 包引入的常量,而不是一个代表选择器值本身的变量呢?
其实,Scala 采用了一个简单的词法规则来区分: 一个以小写字母打头的简单名称会被当作“模式变量”处理;所有其他引用都是常量。
下面例子中,由于 pi 是小写字母打头,所以是“模式变量”:
scala> E match {
case pi => "Pi = " + pi // pi 是“模式变量”,可以匹配任何值!
// case _ => "Not pi" // 上一个 case 可以匹配任何值,这里不能再有通配模式了
}
res2: String = Pi = 2.718281828459045
如果需要,仍然可以用小写的名称来作为模式常量,有两个小技巧。技巧一,如果常量是某个对象的字段,可以在字段名前面加上限定词。例如,虽然 pi 是个变量模式,但 this.pi 或 obj.pi 是常量模式),尽管它们以小写字母打头。技巧二,用反引号将这个名称包起来。例如 `pi` 就能再次被编译器解读为一个常量,而不是变量了:
scala> val pi = math.Pi
pi: Double = 3.141592653589793
scala> E match {
case `pi` => "Pi = " + pi // pi 是常量(如果不用反引号,则它会是“模式变量”)
case _ => "Not pi"
}
res14: String = Not pi
13.2.4. 构造方法模式
构造方法模式是真正体现出模式匹配威力的地方(节 13.1.2 中已经介绍过它)。 一个构造方法模式看上去像这样: Binop("+",e, Number(0)) 。它由一个名称(BinOp)和组圆括号中的模式: e 和 Number(0) 组成。假定这里的名称指定的是一个样例类,这样的一个模式将首先检查被匹配的对象是否是以这个名称命名的样例类的实例,然后再检查这个对象的构造方法参数是否匹配这些额外给出的模式。
这些额外的模式意味着 Scala 的模式支持深度匹配(deep match)这样的模式不仅检查给出的对象的顶层,还会进一步检查对象的内容是否匹配额外的模式要求。由于额外的模式也可能是构造方法模式,用它们来检查对象内部时可以到任意的深度。
13.2.5. 序列模式
就跟与样例类匹配一样,也可以跟序列类型做匹配,比如 List 或 Array 使用的语法是相同的,不过现在可以在模式中给出任意数量的元素。下面显示了一个以 0 开始的三元素列表的模式:
expr match {
case List(0, _, _) => println("found it")
case _ =>
}
如果你想匹配一个序列,但又不想给出多长,你可以用 _* 作为模式的最后一个元素。这个看上去有些奇怪的模式能够匹配序列中任意数量的元素,包括 0 个元素。下面显示了一个能匹配任意长度的以 0 开始的列表:
expr match {
case List(0, _*) => println("found it")
case _ =>
}
13.2.6. 元组模式
我们还可以匹配元组(tuple)。形如 (a, b, c) 这样的模式能匹配任意的元组模式三元组。如:
def tupleDemo(expr: Any) =
expr match {
case (a, b, c) => println("matched " + a + b + c)
case _ =>
}
下面是测试代码:
scala> tupleDemo(("a ", 3, "-tuple"))
matched a 3-tuple
13.2.7. 带类型的模式(替代类型测试和类型转换)
可以用带类型的模式(typed pattern)来替代类型测试和类型转换。如:
def generalSize(x: Any) = x match {
case s: String => s.length
case m: Map[_, _] => m.size
case _ => -1
}
下面是测试代码:
scala> generalSize("abc")
res16: Int = 3
scala> generalSize(Map(1 -> 'a', 2 -> 'b'))
res17: Int = 2
scala> generalSize(math.Pi)
res18: Int = -1
如果我们用“类型测试和类型转换”来实现函数 generalSize ,则是这样的(很啰嗦,不推荐这样写):
if (x.isInstanceOf[String]) { // isInstanceOf 类型测试
val s = x.asInstanceOf[String] // asInstanceOf 类型转换
s.length
} else ...
13.3. 模式守卫(Pattern Guards)
有时候语法级的模式匹配不够精准。举例来说,假定我们要公式化一个简化规则,即用乘以 2 来替换对两个相同操作元的加法。即把 e * 2 替换为 e + e 。你可能会像如下这样来定义这个规则:
scala> def simplifyAdd(e: Expr) = e match {
case BinOp("+", x, x) => BinOp("*", x, Number(2)) // 会报错
case _ => e
}
<console>:14: error: x is already defined as value x
case BinOp("+", x, x) => BinOp("*", x, Number(2))
^
这样做会失败,因为 Scala 要求模式都是线性(linear)的:同一个模式变量在模式中只能出现一次。不过,我们可以用(pattern guard)来重新定义这个匹配逻辑:
scala> def simplifyAdd(e: Expr) = e match {
case BinOp("+", x, y) if x == y => BinOp("*", x, Number(2)) // if 是“模式守卫”
case _ => e
}
simplifyAdd: (e: Expr)Expr
模式守卫出现在模式之后,并以 if 打头。模式守卫可以是任意的布尔表达式,通常会引用到模式中的变量。如果存在模式守卫,这个匹配仅在模式守卫求值得到 true 时才会成功。 因此,上面提到的首个 case 只能匹配那些两个操作元相等的二元操作。
以下是模式守卫的其他示例:
// match only positive integers case n: Int if 0 < n => ... // match only strings starting with the letter `a' case s: String if s(0) == 'a' => ...
13.4. 密封类(Sealed Classes)
每当我们编写一个模式匹配时,都需要确保完整地覆盖了所有可能的 case。有时候可以通过在末尾添加一个缺省 case 来做到,不过这仅限于有合理兜底的场合。如果没有这样的缺省行为,我们如何确信自己覆盖了所有的场景呢?我们可以寻求 Scala 编译器的帮助,帮我们检测出表达式中缺失的模式组合。为了做到这一点,编译器需要分辨出可能的 case 有哪些。一般来说在 Scala 中这是不可能的,因为新的样例类随时随地都能被定义出来。例如没有人会阻止你在现在的四个样例类所在的编译单元之外的另一个编译单元中给 Expr 的类继承关系添加第五个样例类。
解决这个问题的手段是将这些样例类的超类标记为密封(sealed)的。密封类除了在同一个文件中定义的子类之外,不能添加新的子类。这一点对于模式匹配而言十分有用,因为这样一来我们就只需要关心那些已知的样例类。不仅如此,我们还因此获得了更好的编译器支持。如果我们对继承自密封类的样例类做匹配,编译器会用警告消息标示出缺失的模式组合。
如果你的类打算被用于模式匹配,那么你应该考虑将它们做成密封类。只需要在类继承关系的顶部那个类的类名前面加上 sealed 关键字。这样,使用你的这组类的程序员在模式匹配你的这些类时,就会信心十足。下面给出了 Expr 被转成密封类的例子:
sealed abstract class Expr case class Var(name: String) extends Expr case class Number(num: Double) extends Expr case class UnOp(operator: String, arg: Expr) extends Expr case class BinOp(operator: String, left: Expr, right: Expr) extends Expr
现在我们可以试着定义一个漏掉了某些可能 casc 的模式匹配:
def describe(e: Expr): String = e match {
case Number(_) => "a number"
case Var(_) => "a variable"
}
我们将得到类似下面这样的编译器警告:
warning: match is not exhaustive! missing combination UnOp missing combination BinOp
不过,有时候你也会遇到编译器过于挑的情况。举例来说,你可能从上下文知道你永远只会将 describe 应用到 Number 或 Var ,因此你很清楚不会有 MatchError 发生。这时你可以对 describe 添加一个捕获所有的 case,这样就不会有编译器告警了:
def describe(e: Expr): String = e match {
case Number(_) => "a number"
case Var(_) => "a variable"
case _ => throw new RuntimeException // Should not happen
}
还有一种做法:在 match 表达式的选择器部分添加一个 unchecked 注解,就像这样:
def describe(e: Expr): String = (e: @unchecked) match {
case Number(_) => "a number"
case Var(_) => "a variable"
}
如果 match 表达式的选择器带上了 unchecked 注解,那么编译器就不会对后续模式分支进行覆盖完整性检查。
13.5. Option 类型
Scala 由一个名为 Option 的标准类型来表示“可选值”。这样的值可以有两种形式: Some(x) ,其中 x 是那个实际的值;或者 None 对象,代表没有值。
Scala 集合类的某些标准操作会返回可选值。比如, Scala 的 Map 有一个 get 方法,当传的键有对应的值时,返回 Some(value) ;而当传的键在 Map 中没有定义时,返回 None ,我们来看下面这个例子:
scala> val capitals = Map("France" -> "Paris", "Japan" -> "Tokyo")
capitals: scala.collection.immutable.Map[String,String] = Map(France -> Paris, Japan -> Tokyo)
scala> capitals.get("France")
res0: Option[String] = Some(Paris)
scala>
scala> capitals.get("North Pole")
res1: Option[String] = None
将可选值“解开”的最常见方式是通过模式匹配。例如:
scala> def show(x: Option[String]) = x match {
case Some(s) => s
case None => "?"
}
show: (x: Option[String]) String
scala> show(capitals.get("Japan"))
res25: String = Tokyo
scala> show(capitals.get("France"))
res26: String = Paris
scala> show(capitals.get("North Pole"))
res27: String = ?
Scala 程序经常用到 Option 类型。它类似于 Java 中用 null 来表示无值。Java 中的 null 在下面缺点:如果某个变量允许为 null,那么必须记住在每次用到它的时候都要判空(null)。如果忘记了,那么运行时就有可能出现 NullPointerException 。由于这样的类异常可能并不经常发生,在测试过程中也就很难发现。
Scala 鼓励我们使用 Option 来表示可选值。这种处理可选值的方式跟 Java 的 null 相比有很大优势。对于代码的读者而言,某个类型为 Option[String] 的变量对应一个可选的 String ,跟某个类型为 String 的变量可能是 String 或者 null 相比,要直观得多。
13.6. 到处都是模式
Scala 中很多地方都允许使用模式,并不仅仅是 match 表达式。我们来看看其他能用模式的地方。
13.6.1. 变量定义中的模式
每当我们定义一个 val(或 var),都可以用模式而不是简单的标识符。例如,可以将一个元组解开并将其中的每个元素分别赋值给不同的变量,如:
scala> val myTuple = (123, "abc") myTuple: (Int, String) = (123,abc) scala> val (num1, str1) = myTuple // 等号左边是模式 num1: Int = 123 str1: String = abc
这个语法结构在处理样例类时非常有用。如果你知道要处理的样例类是什么,就可以用一个模式来析构它。如:
scala> val exp = new BinOp("*", Number(5), Number(1))
exp: BinOp = BinOp(*,Number(5.0),Number(1.0))
scala> val BinOp(op, left, right) = exp
op: String = *
left: Expr = Number(5.0)
right: Expr = Number(1.0)
13.6.2. case 序列(相当于函数字面量)
用花括号包起来的一系列 case(即可选分支)可以用在任何允许出现“函数字面量”的地方。 本质上讲,case 序列就是一个函数字面量,只是更加通用。 不像普通函数那样只有一个口和参数列表,case 序列可以有多个入口,每个入口都有自己的参数列表。每个 case 对应该函数的一个入口,而该入口的参数列表用模式来指定。每个入口的逻辑主体是 case 右边的部分。
下面是“case”序列的例子:
val withDefault: Option[Int] => Int = {
case Some(x) => x
case None => 0
}
下面是一些测试代码:
scala> withDefault(Some(10)) res28: Int = 10 scala> withDefault(None) res29: Int = 0
13.6.2.1. 偏函数
通过 case 序列得到的是一个偏函数(partial function)。如果我们将偏函数应用到它不支持的值上,它会产生一个运行时异常,如:
scala> val second: List[Int] => Int = { // second 是偏函数,返回 List[Int] 中第二个元素
case x :: y :: _ => y
}
warning: match may not be exhaustive.
It would fail on the following inputs: List(_), Nil
second: List[Int] => Int = $$Lambda$921/733693146@2f80cb79
scala> second(List(5, 6, 7)) // 返回第二个元素
res24: Int = 6
scala> second(List(1)) // second 对 List(1) 没有定义,报运行时异常
scala.MatchError: List(1) (of class scala.collection.immutable.$colon$colon)
at .$anonfun$second$1(<console>:1)
at .$anonfun$second$1$adapted(<console>:1)
... 28 elided
如果你想检查某个偏函数是否对某个入参有定义,可以使用特质 PartialFunction 中的 isDefinedAt 方法。
用偏函数的类型声明,前面的函数 second 可以重新定义为:
val second: PartialFunction[List[Int], Int] = {
case x :: y :: _ => y
}
下面使用 isDefinedAt 测试 second 偏函数是否对某些入参有定义:
scala> second.isDefinedAt(List(5,6,7)) res30: Boolean = true scala> second.isDefinedAt(List()) res31: Boolean = false
13.6.3. for 表达式中的模式
我们还可以在 for 表达式中使用模式。如下面模式中定义了两个变量,country 和 city:
scala> val capitals = Map("France" -> "Paris", "Japan" -> "Tokyo")
scala> for ((country, city) <- capitals) // for 表达式中的模式定义了变量 country 和 city
println("The capital of " + country + " is " + city)
The capital of France is Paris
The capital of Japan is Tokyo
下面再看一个 for 表达式中使用模式的例子:
scala> val results = List(Some("apple"), None, Some("orange"))
results: List[Option[String]] = List(Some(apple), None, Some(orange))
scala> for (Some(fruit) <- results) println(fruit) // for 表达式中的模式定义了变量 fruit
apple
orange
我们从这个例子当中可以看到,那些不能匹配给定模式的值会被直接丢弃。例如,results 列表中的第二个元素 None 就不能匹配上模式 Some(fruit) ,因此它也就不会出现在输出当中了。
14. 类型参数化(Type Parameterization)
类型参数化让我们能够编写泛型的类和特质。例如,集(set)是泛型的,接收一个类型参数:定义为 Set[T] 。这样,具体的集的实例可以是 Set[String] , Set[Int] 等,不过必须是某种类型的集(也就是说不能省略类型直接写为 Set )。“型变注解”定义了参数化类型的继承关系,以 Set[String] 为例,“型变注解”决定了它是不是 Set[AnyRef] 的子类型。
下面先通过一个具体的例子(实现一个函数式队列)来介绍信息隐藏的技巧,然后引入“型变注解”等概念。
14.1. 实现一个函数式队列
函数式队列是一个数据结构,它支持三种操作:
1、head 返回队列的第一个元素
2、tail 返回除第一个元素外的队列
3、enqueue 返回一个将给定元素追加到队尾的新队列
跟可变队列不同,“函数式队列”在新元素被追加时,其内容并不改变,而是会返回一个新的包含该元素的队列。这一点和“列表”有些相似,经过扩展或修改之后,老版本将继续保持可用。
下面是用列表(List)作底层存储来实现的“函数队列”的例子:
class SlowAppendQueue[T](elems: List[T]) { // Not efficient
def head = elems.head // 返回队列的第一个元素
def tail = new SlowAppendQueue(elems.tail) // 返回除第一个元素外的队列
def enqueue(x: T) = new SlowAppendQueue(elems ::: List(x)) // 返回把 x 加到队尾的新队列,操作 ::: 是低效的
}
上面对 enqueue 的实现是低效的,它的时间开销跟队列中存放的元素数量成正比。如果想要常量时间的 enqueue 操作,可以尝试存储时将底层列表中的元素顺序反转过来,得到下面实现:
class SlowHeadQueue[T](smele: List[T]) { // Not efficient
// smele is elems reversed
def head = smele.last // List 上的 last 是低效的
def tail = new SlowHeadQueue(smele.init) // List 上的 init 也是低效的
def enqueue(x: T) = new SlowHeadQueue(x :: smele)
}
在这个新实现中, enqueue 变得高效了,但 head 和 tail 的时间开销却跟队列中元素数量成正比了。
14.1.1. “函数队列”的优化实现
从这两个实现来看,似乎并没有一个实现可以对所有三种操作都做到常量时间。事实上,这看上去几乎是不可能做到的。不过,将两种操作结合到一起,可以非常接近这个目标。背后的理念是用两个列表(如 leading 和 trailing)来表示队列。其中 leading 列表保存队列中“靠前的元素”,而 trailing 列表保存队列中“靠后的元素”,并按倒序排列。整个队列在任何时刻的内容都等于 leading ::: trailing.reverse 。
现在,要追加一个元素,只需要用 :: 操作符将它追加到 trailing 列表中,这样一来 enqueue 操作就是常量时间。这意味着,如果一个队列初始为空,现在想通过连续的多个 enqueue 操作来初始化为个队列,这时 trailing 列表会一直增长,而 heading 列表会一直为空。接下来,在执行 head 或 tail 时,如果发现 leading 为空,则把整个 trailing 列表反转后复制到 leading 列表中,把这个步骤封装到名为 mirror 的方法中。我们得到了下面更高效的“函数队列”实现方式:
class Queue[T](
private val leading: List[T],
private val trailing: List[T]
) {
private def mirror =
if (leading.isEmpty)
new Queue(trailing.reverse, Nil) // reverse 是低效的。但仅 leading 为空时才会触发
else
this
def head = mirror.leading.head
def tail = {
val q = mirror
new Queue(q.leading.tail, q.trailing)
}
def enqueue(x: T) =
new Queue(leading, x :: trailing)
}
这个队列实现的复杂度如何呢? mirror 操作的耗时跟队列元素的数量成正比,但仅当 leading 为空时才发生。如果 leading 为非空,那么它就直接返回了。由于 head 和 tail 调用了 mirror,它们的复杂度与队列长度也成线性关系。不过,随着队列变长, mirror 被调用的频率也会变低。
的确,假定我们有一个长度为 n 的队列,其 leading 列表为空,那么 mirror 操作必须将一个长度为 n 的列表做一次反向拷贝。不过下一次 mirror 要做任何工作都要等到 leading 列表再次变空时,这将发生在 n 次 tail 操作过后。这意味着可以让这 n 次 tail 操作“分担”1/n 的 mirror 复杂度,也就是常量时间的工作。假定 head、tail 和 enqueue 操作差不多以相同频次出现,那么均摊(amortized)时间复杂度对于每个操作而言就是常量的了。因此从渐进的视角看,函数式队列跟可变队列同样高效。
不过,对于这个论点,我们要附加两点说明。首先,这里探讨的只是渐进行为,常量因子可能会不一样。其次,这个论点基于 head、tail 和 enqueue 的两用频次差不多相同。如果 head 的调用比其他两个操作要频繁得多,那么这个论点就不成立,因为每次对 head 的调用都可能牵涉用 mirror 重新组织列表这个昂贵的操作。比如,队列 Q 的 leading 列表为空时,如果连续在 Q 上调用多次 head,那么每次 head 操作都会执行 mirror 中最耗时的 reverse 操作。不过,这一点可以被避免,可以设计出这样一个函数式队列,在连续的 head 操作中,只有第一次需要重组,详情可参考《Scala 编程(第三版)》示例 19.10。
14.2. 信息隐藏
前一节给出的 Queue 优化实现在效率上来说已经非常棒了。不过,我们暴露了不必要的实现细节,如全局可访问的 Queue 构造方法接收两个列表作为参数,其中第二个顺序还是反的,比如下面创建的队列中元素顺序为 1,2,4,3(而不是更直观的 1,2,3,4):
val q = new Queue(List(1, 2), List(3, 4)) // trailing 列表是反的
我们需要把这样的细节隐藏起来,比如直接把构造方法私有化。
14.2.1. 方式一:私有构造方法和工厂方法
在 Scala 中主构造方法并没有显式的定义,它是通过类参数和类定义体隐式地定义的。尽管如此,还是可以通过在参数列表前加上 private 修饰符来隐藏主构造方法。如下所示:
class Queue[T] private ( // 这一行的 private 关键字表示隐藏主构造方法 private val leading: List[T], private val trailing: List[T] )
类名和参数之间的 private 修饰符表示 Queue 的构造方法是私有的:它只能从类本身及其伴生对象访问。类名 Queue 依然是公有的,因此可以把它当作类型来使用,但不能调用其构造方法了。
既然 Queue 类的主构造方法不能从使用方代码调用,我们需要别的方式来创建新的队列。一种可能的方式是添加一个辅助构造方法,就像这样:
def this() = this(Nil, Nil) // 这是辅助构造方法 def this(elems: T*) = this(elems.toList, Nil) // 这也是辅助构造方法, T* 表示重复函数
另外一种创建新队列的方式是添加一个工厂方法。一种不错的实现方式是定义一个跟 Queue 类同名的对象(伴生对象),并提供一个 apply 方法。如:
object Queue {
// constructs a queue with initial elements `xs'
def apply[T](xs: T*) = new Queue[T](xs.toList, Nil) // 伴生对象中的 apply 工厂方法
}
由于这个工厂方法的名称是 apply ,使用方代码可以用诸如 Queue(1, 2, 3) 这样的表达式来创建队列。这个表达式会展开成 Queue.apply(1, 2, 3) ,因为 Queue 是对象而不是函数。这样一来,Queue 在使用方看来,就像是全局定义的工厂方法一样。实际上, Scala 并没有全局可见的方法,每个方法都必须被包含在某个对象或某个类当中。不过,通过在全局对象中使用名为 apply 的方法,可以支持看上去像是全局方法的使用模式。
14.2.2. 方式二:私有类
私有构造方法和私有成员只是隐藏类的初始化和内部表现形式的一种方式,另一种更激进的方式是隐藏整个类本身,并且只暴露一个反映类的公有接口的特质。下面的代码实现了这种更激进的设计:
trait Queue[T] {
def head: T
def tail: Queue[T]
def enqueue(x: T): Queue[T]
}
object Queue {
def apply[T](xs: T*): Queue[T] =
new QueueImpl[T](xs.toList, Nil)
private class QueueImpl[T]( // 特质 Queue 的子类 QueueImpl,它是一个私有内部类
private val leading: List[T],
private val trailing: List[T]
) extends Queue[T] {
def mirror =
if (leading.isEmpty)
new QueueImpl(trailing.reverse, Nil)
else
this
def head: T = mirror.leading.head
def tail: QueueImpl[T] = {
val q = mirror
new QueueImpl(q.leading.tail, q.trailing)
}
def enqueue(x: T) =
new QueueImpl(leading, x :: trailing)
}
}
其中定义了一个 Queue 特质,声明了方法 head、tail 和 enqueue。所有这三个方法都实现在子类 QueueImpl 中,这个子类本身是对象 Queue 的一个私有内部类。
14.3. 型变注解(+T, -T)
节 14.2.2 定义的 Queue 是一个特质,而不是一个类型。Queue 不是类型,因为它接收一个类型参数 T 。
由于 Queue 不是类型,所以不能创建类型为 Queue 的变量,如下面代码会报错:
scala> def doesNotCompile(q: Queue) = {} // Queue 不是类型
<console>:8: error: class Queue takes type parameters
def doesNotCompile(q: Queue) = {}
^
Queue 特质让我们可以指定参数化(parameterized)的类型,比如 Queue[String], Queue[Int], Queue[AnyRef] 等:
scala> def doesCompile(q: Queue[AnyRef]) = {} // Queue[AnyRef] 是类型
doesCompile: (q: Queue[AnyRef])Unit
Queue 也被称作“类型构造方法”(type constructor) ,因为我们可以通过指定类型参数来构造一个类型(这跟通过指定值参数来构造对象实例的普通构造方法的道理是一样的)。类型构造方法 Queue 能够“生成”成组的类型,包括 Queue[String], Queue[Int], Queue[AnyRef] 等。
类型参数和子类型这两个概念放在一起,会产生一些有趣的问题。例如,通过 Queue[T] 生成的类型之间,有没有特殊的子类型关系?更确切地说, Queue[String] 应不应该被当作 Queue[AnyRef] 的子类型?这个问题可以概括为: 如果 S 是类型 T 的子类型,那么 Queue[S] 应不应该被当作 Queue[T] 的子类型?答案是取决于“型变”(variance):
trait Queue[T] { ... } // 表示“不变”(nonvariant)。S 是 T 的子类型,则 Queue[S] 不是 Queue[T] 的子类型
trait Queue[+T] { ... } // + 表示“协变”(convariant)。S 是 T 的子类型,则 Queue[S] 是 Queue[T] 的子类型
trait Queue[-T] { ... } // - 表示“逆变”(contravariant)。S 是 T 的子类型,则 Queue[T] 是 Queue[S] 的子类型
如果类型形参前面没有标记,表示子类型关系在这个参数上是“不变”的。比如, String 是 AnyRef 的子类型,但 Queue[String] 不是 Qucue[AnyRef] 的子类型。
在类型形参前面加上 + 表示子类型关系在这个参数上是“协变”的。比如, String 是 AnyRef 的子类型,从而 Queue[String] 是 Qucue[AnyRef] 的子类型。
在类型形参前面加上 - 表示子类型关系在这个参数上是“逆变”的。比如, String 是 AnyRef 的子类型,从而 Queue[AnyRef] 是 Qucue[String] 的子类型(队列这个场景中这是不可思议的)。
放在类型参数旁边的 +, - 符号被称为“型变注解”(variance annotation)。对 Queue 进行信息隐藏前的那个版本也是可以使用“型变注解”的,如:
class Queue[T](private val leading: List[T], private val trailing: List[T]) { ... }
class Queue[+T](private val leading: List[T], private val trailing: List[T]) { ... }
class Queue[-T](private val leading: List[T], private val trailing: List[T]) { ... }
14.4. 检查“型变注解”
下面我们先看几个“型变”会导致“危险状况”的例子。然后通过这些例子引入“不变点”,“协变点”,“逆变点”的概念。
14.4.1. Cell 类
考虑这样一个简单的可被读写的单元格:
class Cell[T](init: T) { // 型变注解是“不变的”
private[this] var current = init
def get = current
def set(x: T) = { current = x }
}
如果我们把 Cell 的型变注解改为“协变的”,即 class Cell[T](init: T) ,我们考虑一下下面四行代码:
val c1 = new Cell[String]("abc")
val c2: Cell[Any] = c1
c2.set(1)
val s: String = c1.get
单独看每一句,这四行代码都是 OK 的。第一行创建了一个字符串的单元格,并将它保存在名为 c1 的 val 中。第二行定义了一个新的 val(即 c2),类型为 Cell[Any] ,并用 c1 初始化,这是 OK 的,因为 Cell 被认为是协变的。第三行将 c2 这个单元格的值设为 1,这也是 OK 的,因为被赋的值 1 是 c2 的元素类型 Any 的实例。最后一行将 c1 的元素值赋值给一个字符串。不过放在一起,这四行代码产生的效果是将整数 1 赋值给了字符串 s。这显然有悖于类型约束。
我们应该将运行时的错误归咎于哪一步操作呢?一定是第二行,因为在这一行我们用到了协变的子类型关系。其他的语句都太简单和基础了。因此 String 的 Cell 并不同时是 Any 的 Cell,因为有些我们能对 Any 的 Cell 做的事并不能对 String 的 Cell 做。举例来说,我们并不能对 String 的 Cell 使用参数为 Int 的 set。
从上面的分析可以知道:把 Cell 改为“协变的”后,会导致“危险状况”出现。Scala 编译器能够发现这种情况,它的解决方案是:编译时拒绝会导致“危险状况”的代码:
class Cell[+T](init: T) { // 类型参数 T 的型变注解是“协变的”
private[this] var current = init
def get = current
def set(x: T) = { current = x } // 编译时,会在这一行报错。从而阻止了的“危险状况”
}
编译上面代码会得到下面错误:
Cell.scala:7: error: covariant type T occurs in contravariant position in type T of value x
def set(x: T) = current = x
^
从错误消息中,可以看到有个“contravariant position”的概念,后面会介绍它。
14.4.1.1. 型变和数组(Java 数组是协变的)
前面介绍的 Cell 的行为跟 Java 的数组相比较会很有趣。从原理上讲,数组跟单元格很像,只不过数组可以有多于一个元素。尽管如此, 数组在 Java 中是被当作协变的来处理的。 我们可以仿照前面的单元格交互来尝试 Java 数组的例子:
// this is Java
String[] a1 = { "abc" };
Object[] a2 = a1;
a2[0] = new Integer(17);
String s = a1[0];
如果执行这段代码,你会发现它能够编译成功,不过在运行时,当 a2[0] 被赋值成个 Integer,程序会抛出 ArrayStoreException :
Exception in thread "main" java.lang.ArrayStoreException:
java.lang.Integer
at JavaArrays.main(JavaArrays.java:8)
发生了什么?Java 在运行时会保存数组的元素类型。每当数组元素被更新,都会检查新元素值是否满足保存下来的类型要求。如果新元素值不是这个类型的实例,就会抛出 ArrayStoreException 。
你可能会问 Java 为什么会采纳这样的设计,看上去既不安全,运行开销也不低。当被问及这个问题时,Java 语言的主要发明人 James Gosling 是这样回答的:他们想要一种简单的手段来泛化地处理数组。举例来说,它们想要用下面这样的接收一个 Object 数组的方法来对数组的所有元素排序:
void sort(Object[] a, Comparator cmp) { ... }
需要协变的数组,才能让任意引用类型的数组得以传这个方法。当然了,随着 Java 泛型的引入,这样的 sort 方法可以用类型参数来编写,这样一来就不再需要协变的数组了。不过由于兼容性的原因,直到今天 Java 还保留了这样的做法。
Scala 在这一点上比 Java 做得更纯粹,它并不把数组当作是协变的(Scala 中数组默认是“不变的”)。如果我们尝试将数组的例子的前两行翻译成 Scala,就像这样:
scala> val a1 = Array("abc")
a1: Array[String] = Array(abc)
scala> val a2: Array[Any] = a1
<console>:8: error: type mismatch;
found : Array[String]
required: Array[Any]
val a2: Array[Any] = a1
^
之所以报错,是由于 Scala 将数组处理成“不变的”。因此 Array[String] 并不认为是 Array[Any] 的子类型。不过的,有时候我们需要跟 Java 的历史方法交互,这些方法用 Object 数组来仿真泛型数组。举例来说,你可能会想以一个 String 数组为入参调用前面描述的那样一个 sort 方法。Scala 允许我们将元类型为 T 的数组类型转换成 T 的任意超类型的数组(使用 asInstanceOf ):
scala> val a2: Array[Object] = a1.asInstanceOf[Array[Object]] a2: Array[Object] = Array(abc)
这个类型转换在编译时永远合法,且在运行时也水远会成功,因为 JVM 的底层运行时模型对数组的处理都是协变的,就跟 Java 语言一样。不过你可能在这之后得到 ArrayStoreException ,这也是跟 Java 一样的。
14.4.2. 不变点,协变点,逆变点
前面介绍的例子提到了,Cell 的类型参数改为“协变的”后,其 set(x: T) 可能导致“危险状况”,编译器会直接拒绝编译:
class Cell[+T](init: T) { // 类型参数 T 的型变注解是“协变的”
private[this] var current = init
def get = current
def set(x: T) = { current = x } // 编译时,会在这一行报错。从而阻止了的“危险状况”
}
我们能够总结为:之所以会出现“危险状况”,是由于 set 方法会“修改”Cell 的字段才导致的吗?其实不是这样的!就算不涉及到“修改”动作,也可能导致“危险状况”出现。下面介绍这样的例子。
假设前面的函数式队列是“协变的”,即 Queue[+T] 。我们创建一个针对元素类型 Int 的队列( Queue[Int] ),重写它的 enqueue 方法:
class StrangeIntQueue extends Queue[Int] {
override def enqueue(x: Int) = {
println(math.sqrt(x)) // 这一行代码,并不会涉及到“修改”
super.enqueue(x)
}
}
现在,我们考虑下面两行代码:
val x: Queue[Any] = new StrangeIntQueue
x.enqueue("abc")
两行代码中的第一行是合法的,因为 StringIntQueue 是 Queue[Int] 的子类。并且(假定队列是协变的) Queue[Int] 是 Queue[Any] 的子类型。第二行也是合法的,因为我们可以追加一个 String 到 Queue[Any] 中,不过两行代码结合在一起,最终的效果是“对一个字符串执行了平方根的方法”,这完全讲不通。
所以,通过上面的例子我们知道:如果类型参数是“协变的”,就算不涉及“字段的修改”,也可能导致“危险状况”出现。
我们可以总结出一个简单的规则:用 + 注解的类型参数(“协变的”)不允许用于方法参数的类型。但这只是一条规则,而为了验证型变注解的正确性(往往安全性,即完全避免“危险状况”),Scala 编译器需要增加很多的规则。
Scala 编译器对类型参数的出现位置归类为“协变点”、“逆变点”、和“不变点”。 Scala 编译器会检查类型参数的每一次使用。用 + 注解的类型参数只能用在“协变点”;而用 - 注解的类型参数只能用在“逆变点”。而没有型变注解的类型参数可以用在任何能出现类型参数的点(“协变点”/“逆变点”/“不变点”都行)。
至于具体哪些位置是“协变点”、“逆变点”、和“不变点”?这个比较复杂,我们暂时不去关心,留给编译器即可。如果类型参数出现在不符合要求的点,编译器就会报错。
比如,函数参数位置是“逆变点”,那么如果类型参数 T 的型变注解是“协变的”,那么函数参数就不能是类型 T 了。这里再重复一下前面说过的例子:
class Cell[+T](init: T) { // 类型参数 T 的型变注解是“协变的”
private[this] var current = init
def get = current
def set(x: T) = { current = x } // 函数参数 x 是“逆变点”(contravariant position)
}
Scala 编译上面代码会得到下面错误:
Cell.scala:7: error: covariant type T occurs in contravariant position in type T of value x
def set(x: T) = current = x
^
14.5. 下界(U >: T)
我们回到 Queue 类,如何既让类型参数 T 为“协变的”,又让 enqueue 能正常通过编译呢?
解决办法:通过多态让 enqueue 泛化(即给 enqueue 方法本身一个类型参数)并对其类型参数使用下界(lower bound)。如下面表格右边的定义:
| 普通版本 | 更好的版本,类型参数 T 型变注解是协变的 |
|
class Queue[T]( private val leading: List[T], private val trailing: List[T] ) { // ...... def enqueue(x: T) = new Queue(leading, x :: trailing) } |
class Queue[+T]( private val leading: List[T], private val trailing: List[T] ) { // ...... def enqueue[U >: T](x: U) = new Queue[U](leading, x :: trailing) } |
仔细观察上面右边的定义, 它给方法 enqueue 添加了一个类型参数 U ,并用 U >: T 这样的语法定义了 U 的下界为 T 。这样一来, U 必须是 T 的超类型。现在 enqueue 的参数类型为 U 而不是 T ,方法的返回值是 Queue[U] 而不是 Queue[T] 。
举例来说,假定有一个 Fruit 类和两个子类 Apple 和 Orange 按照 Queue 类的新定义,可以对 Queue[Apple] 追加一个 Orange ,其结果是一个 Queue[Fruit] 。
修改过后的 enqueue 定义是类型正确的。直观地讲,如果 T 是一个比预期更具体的类型(例如相对 Fruit 而言的 Apple),那么对 enqueue 的调用依然可行,因为 U(Fruit)仍然是 T(Apple)的超类型。
enqueue 的新定义(表格右边版本)显然比原先的定义(表格左边版本)更好,因为它更通用。不同于原先的版本,新的定义允许我们追加任意队列类型 T 的超类型 U 的元素,并得到 Queue[U] 。通过这一点加上队列的协变,获得了一种很自然的方式对不同的元素类型的队列灵活地建模。
这显示出型变注解和下标配合得很好。它们是类型驱动设计(type-driven design)的绝佳例子,在类型驱动设计中,接口的类型引导我们做出细节的设计和实现。在队列这个例子中,很可能一开始并不会想到用下界来优化 enqueue 的实现。不过你可能已经决定让队列支持协变,这种情况下编译器会指出 enqueue 的型变错误。通过添加下界来修复这个型变错误让 enqueue 加通用,也让整个队列变得更加好用。
这也是 Scala 倾向于声明点(declaration-site)型变而不是使用点(use-site) 型变的主要原因。Java 的通配处理采用的是后者(使用点型变)。如果采用使用点型变,我们在设计类的时候只能靠自己。最终是类的使用方来通配,而如果他们搞错了一些重要的实例方法就不再可用了。型变是个很难办的东西,用户经常会搞错,然后得出通配和泛型过于复杂的结论。而如果采用定义点(definition-site)型变(其实跟声明点型变是一回事),可以向编译器表达我们的意图,然后编译器会帮助我们复核那些我们想要使用的方法是真的可用。
15. 隐式转换和隐式参数
在自己的代码和别人的类库之间存在一个根本的差异:可以按照自己的意愿修改或扩展自己的代码,而如果想用别人的类库,则通常只能照单全收。编程语言中涌现出一些语法结构来缓解这个问题。Ruby 有模块,而 Smalltalk 允许包添加来自其他包的类。这些特性功能强大但同时也很危险你可以对整个应用程序修改某个类的行为,而你可能对于这个应用程序的某些部分并不了解。C#3.0 提供了静态扩展方法,这些方法更局部但同时限制也更多,只能对类添加方法而不是字段,并且并不能让某个类实现新的接口。
Scala 对这个问题的答案是“隐式转换和隐式参数”。“隐式转换和隐式参数”可以让已有的类库用起来更舒心,允许省掉那些冗余而明显的细节,因为这些细节往往让代码中真正有意义的部分变得模糊和难以理解。
15.1. 隐式转换
在介绍隐式转换的细节之前,我们先来看一个典型的使用示例。隐式转换通常在处理“两个在开发时完全不知道对方存在的软件或类库”时非常有用。它们各自都有自己的方式来描述某个概念,而这个概念本质上是同一件事。 隐式转换可以减少从一个类型显式转换成另一个类型的需要。
下面我们通过一个例子介绍“隐式转换”。
如果没有隐式转换,使用到 Swing 的 Scala 程序就必须像 Java 那样使用内部类。这里有一个创建按钮并挂上一个动作监听器的例子。每当按钮被按下,这个动作监听器就会被调用,打印出字符串“pressed!”:
val button = new JButton
button.addActionListener( // 版本一:内部类,很多样板代码
new ActionListener {
def actionPerformed(event: ActionEvent) = {
println("pressed!")
}
}
)
这段代码真正有意义的就是对 println 的调用,其它代码都可以认为是样板代码。假设有 10 个按钮,那么这样的相同的样板代码就很多了。
使用 scala 的隐式转换,可以大大减少样板代码。如下面是一个从“函数”到“ActionListener”的隐式转换:
implicit def function2ActionListener(f: ActionEvent => Unit) = // 这是隐式定义
new ActionListener {
def actionPerformed(event: ActionEvent) = f(event)
}
这样,在按钮并挂上一个动作监听器的代码可以写为:
button.addActionListener( // 版本二,显式调用隐式转换
function2ActionListener(
(_: ActionEvent) => println("pressed!")
)
)
其实,隐式转换还能做得更好。由于 function2ActionListener 被标记为隐式的,可以不用写出这个调用,编译器会自动插入。也就是上面代码进一步简写为:
button.addActionListener( // 版本三,省写对隐式转换的调用,这个版本几乎没有“样板代码”了
(_: ActionEvent) => println("pressed!")
)
对于上面代码,编译器首先会照原样编译,不过会遇到一个类型错误:addActionListener 的参数期望是 ActionListener,但实际上是一个函数。在放弃之前,它会查找一个能修复该问题的隐式转换。在本例中,编译器找到了 function2ActionListener 。它会尝试这个隐式转换,发现可行,就继续下去。
15.1.1. 尝试隐式转换的地方
在哪些地方会尝试隐式转换呢? Scala 总共有三个地方会使用隐式定义:1、转换到一个预期的类型;2、转换“接收端”(方法被调用的那个对象);3、隐式参数。后面将一一介绍它们。
15.2. 隐式转换到一个预期的类型
隐式转换到一个预期的类型是编译器第一个使用隐式定义的地方。规则很简单,每当编译器看见一个 X 而它需要一个 Y 的时候,它就会查找一个能将 X 转换成 Y 的隐式转换。例如,通常一个双精度浮点数不能被用作整数,因为这样会丢失精度:
scala> val i: Int = 3.5
<console>:7: error: type mismatch;
found : Double(3.5)
required: Int
val i: Int = 3.5
^
不过,可以定义一个隐式转换来让它走下去:
scala> implicit def doubleToInt(x: Double) = x.toInt doubleToInt: (x: Double)Int scala> val i: Int = 3.5 i: Int = 3
将 Double 转换成 Int 可能会引起一些人的反对,因为让精度丢失悄悄地发生这件事并不是什么好主意,因此这并不是我们推荐采用的转换。不过将从 Int 到 Double 的隐式转换是安全的。事实上,Scala 确实也是这么做的 scala.Predef 这个每个 Scala 程序都隐式引入的对象中可以找到如下转换:
implicit def int2double(x: Int): Double = x.toDouble // scala.Predef 中定义
这就是为什么 Scala 的 Int 值可以被保存到类型为 Double 的变量中。类型系统当中并没有特殊的规则,这只不过是一个被(编译器)应用的隐式转换而已。
15.3. 转换“接收端”(方法被调用的那个对象)
假定你写下了 obj.doIt 。而 obj 并没有一个名为 doIt 的成员。编译器会在放弃之前尝试进行隐式转换。在本例中,这个转换需要应用于接收端(即方法被调用的那个对象),也就是 obj 。 编译器会尝试把 obj 转换为存在 doIt 成员的某个类型。
15.3.1. 与新类型互操作
接收端转换的一个主要用途是让新类型和已有类型的集成更顺滑。尤其是这些转换使得我们可以让使用方程序员想使用新类型那样使用已有类型的实例。考虑下面代码:
class Rational(n: Int, d: Int) {
require(d != 0)
val numer: Int = n
val denom: Int = d
override def toString = numer.toString + "/" + denom.toString
def +(that: Rational): Rational =
new Rational(
numer * that.denom + that.numer * denom,
denom * that.denom
)
def +(i: Int): Rational =
new Rational(numer + i * denom, denom)
}
Rational 类有两个重载的 + 方法变种,分别接收 Rational 和 Int 作为参数。因此可以对两个有理数做加法,或者对一个有理数和一个整数相加:
scala> val oneHalf = new Rational(1, 2) oneHalf: Rational = 1/2 scala> oneHalf + oneHalf res0: Rational = 4/4 scala> oneHalf + 1 res1: Rational = 3/2
那像 1 + oneHalf 这样的表达式呢?这个表达式比较难办,因为作为接收端的 1 并没有一个合适的 + 方法。因此如下代码将会报错:
scala> 1 + oneHalf
<console>:6: error: overloaded method value + with
alternatives (Double)Double <and> ... cannot be applied
to (Rational)
1 + oneHalf
^
为了使上面的表达式能正常工作,我们可以定义从 Int 到 Rational 的隐式转换:
scala> implicit def intToRational(x: Int) = new Rational(x, 1) // Int 到 Rational 的隐式转换 intToRational: (x: Int)Rational
Scala 编译器首先尝试对表达式 1 + oneHalf 做类型检查。Int 虽然有多个 + 方法,但没有一个是接收 Rational 参数的,因此类型检查会失败。接下来,编译器不会马上放弃,而是会查找一个从 Int 到另一个拥有可以应用 Rational 参数的 + 方法的类型的隐式转换(它将找到 intToRational )。这样, 1 + oneHalf 会转换为下面代码:
intToRational(1) + oneHalf // 1 + oneHalf 不再报错了
15.3.2. 模拟新的语法
隐式转换的另一个主要用途是模拟添加新的语法。回想一下我们曾经提到过的,可以用如下的语法来制作一个 Map:
Map(1 -> "one", 2 -> "two", 3 -> "three")
你有没有想过 Scala 是如何支持 -> 这个写法的?它其实并不是语法特性。是 ArrowAssoc 类的方法,ArrowAssoc 是一个定义在 scala.Predef 中的对象。当你写下 1 -> one 时,编译器会插入一个从 1 到 ArrowAssoc 的转换,以便 -> 方法能被找到。以下是相关定义:
package scala
object Predef {
class ArrowAssoc[A](x: A) {
def -> [B](y: B): Tuple2[A, B] = Tuple2(x, y)
}
implicit def any2ArrowAssoc[A](x: A): ArrowAssoc[A] = new ArrowAssoc(x)
...
}
15.3.3. 隐式类
Scala 2.10 引入了隐式类来简化富包装类的编写。隐式类是一个以 implicit 关键字打头的类。对于隐式类,编译器会生成一个从类的构造方法参数到类本身的隐式转换。
举例来说,假定你有一个名为 Rectangle 的类用来表示屏幕上一个长方形的宽和高:
case class Rectangle(width: Int, height: Int)
如果你经常使用这个类,可能会想用富包装类模式来“简化构造工作”,以下是一种可行的做法:
implicit class RectangleMaker(width: Int) { // 这是隐式类
def x(height: Int) = Rectangle(width, height)
}
上述代码以通常的方式定义了一个 RectangleMaker 类不仅如此,它还自动生成了如下转换:
// Automatically generated implicit def RectangleMaker(width: Int) = new RectangleMaker(width)
这样一来,你就可以通过在两个整数之间放一个 x 来创建点:
scala> val myRectangle = 3 x 4 myRectangle: Rectangle = Rectangle(3,4)
工作原理如下:由于 Int 类型并没有名为 x 的方法,编译器会查找一个从 Int 到某个有这个方法的类型的隐式转换。它将找到自动生成的这个 RectangleMaker 的转换,而 RectangleMaker 的确有一个名为 x 的方法。编译器会插入对这个转换的调用,这样对 x 的调用就能通过类型检查并完成它该做的事。
15.4. 隐式参数
考虑下面代码:
// 版本一:两个参数都需要显式指定
def maxListOrdering[T](elements: List[T])(ordering: Ordering[T]): T =
elements match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x :: rest =>
val maxRest = maxListOrdering(rest)(ordering)
if (ordering.gt(x, maxRest)) x
else maxRest
}
maxListOrdering 会返回传入参数的最大元素。它经过“柯里化”的,接收一个 List[T] 作为入参,还接收一个额外的类型为 Ordering[T] 的入参。这个额外的入参给出在比较类型 T 的元素时应该使用的顺序。这样,这个版本的函数就可以用于那些没有内建顺序的类型。不仅如此,这个版本的函数也可以用于那些有内建顺序不过偶尔你也想用不同排序的类型。
maxListOrdering 的调用者必须给出一个显式的排序(即第二个参数),哪怕当 T 是类似 String 或 Int 这样有明确的默认排序的时候。为了让新的方法更方便使用,可以将第二个参数标记为隐式的:
// 版本二:第二个参数是隐式的,调用时可以省略第二个参数
def maxListImpParm[T](elements: List[T])(implicit ordering: Ordering[T]): T = // 将第二个入参是 implicit
elements match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x :: rest =>
val maxRest = maxListImpParm(rest)(ordering) // 使用 ordering 的第一处
if (ordering.gt(x, maxRest)) x // 使用 ordering 的第二处
else maxRest
}
由于第二个参数是 implicit 的,所以我们调用 maxListOrdering 时,就可以省略第二个参数了:
scala> maxListImpParm(List(1,5,10,3))
res9: Int = 10
scala> maxListImpParm(List(1.5, 5.2, 10.7, 3.14159))
res10: Double = 10.7
scala> maxListImpParm(List("one", "two", "three"))
res11: String = two
15.4.1. 上下文界定(T: Ordering)
maxListImpParm 的“版本二”的函数体内,有“两处”使用了隐式参数 ordering 。其第一处,可以直接省略,即:
// 版本三:省略了定义体内对参数 ordering 的第一处调用
def maxListImpParm[T](elements: List[T])(implicit ordering: Ordering[T]): T =
elements match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x :: rest =>
val maxRest = maxList(rest) // 省略 ordering,相当于 maxList(rest)(ordering)
if (ordering.gt(x, maxRest)) x // 这一处的 ordering 还是显式调用的
else maxRest
}
下面介绍一种方法可以去掉对 ordering 的第二处使用。这涉及标准类库中定义的如下方法:
def implicitly[T](implicit t: T) = t // 标准类库中定义的方法
调用 implicitly[Foo] 的作用是编译器会查找一个类型为 Foo 的隐式定义。然后它会用这个对象来调用 implicitly 方法,这个方法再将这个对象返回。这样就可以在想要当前作用域找到类型为 Foo 的隐式对象时直接写 implicitly[Foo] 。下面展示了用 implicitly[Ordering[T]] 来通过其类型获取 ordering 参数的用法:
// 版本四:省略了定义体内对参数 ordering 的所有调用
def maxListImpParm[T](elements: List[T])(implicit ordering: Ordering[T]): T =
elements match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x :: rest =>
val maxRest = maxList(rest)
if (implicitly[Ordering[T]].gt(x, maxRest)) x
else maxRest
}
在上面例子中,我们发现函数的第二个参数“ordering”在函数体内没有使用了。显然这个参数改为其他名字(如“comparator”也无所谓)。
由于这个模式很常用,Scala 允许我们省掉这个参数的名称并使用上下界定(context bound)来缩短方法签名。如:
// 版本五:使用“上下文界定”来缩短方法签名
def maxListImpParm[T: Ordering](elements: List[T]): T =
elements match {
case List() =>
throw new IllegalArgumentException("empty list!")
case List(x) => x
case x :: rest =>
val maxRest = maxList(rest)
if (implicitly[Ordering[T]].gt(x, maxRest)) x
else maxRest
}
在上面例子中, [T: Ordering] 这样的语法是一个上下文界定(context bound),它做了两件事:首先,它像平常那样引入了一个类型参数 T ;其次,它添加了个类型为 Ordering[T] 的隐式参数。 不过你并不知道这个隐式参数的名字,可以通过 implicitly[Ordering[T]] 来获得这个参数。
15.5. 结语
隐式定义是 Scala 的一项强大的、可以浓缩代码的功能。
作为警告,我们必须提醒你,隐式定义如果使用得过于频繁,会让代码变得令人困惑。因此,在添加一个新的隐式转换之前,首先问自己能否通过其他手段达到相似的效果,比如继承、混入组合或方法重载。不过,如果所有这些都失败了,而你感觉大量代码仍然是繁复冗长的,那么隐式定义可能恰好能帮到你。
16. 提取器(Extractor)
提取器(Extractor)可以用来泛化模式匹配。
16.1. 示例:提取电子邮箱地址
为了说明“提取器”解决的问题,想象一下你需要分析那些表示电子邮箱地址的字符串的场景。给定一个字符串,你要判断它是不是电子邮箱地址,如果是,你还想进一步访问该地址的用户部分和域名部分。传统的方式是用三个助手函数:
def isEMail(s: String): Boolean def domain(s: String): String def user(s: String): String
有了这些函数,就可以像下面这样解析某个给定的字符串 s :
if (isEMail(s)) println(user(s) + " AT " + domain(s))
else println("not an email address")
模式匹配也适合于上面任务,看起来像下面这样:
s match {
case EMail(user, domain) => println(user + " AT " + domain) // 有问题,因为字符串 s 不是样例类
case _ => println("not an email address")
}
这样的代码都更加易读。不过,这里的问题在于字符串 s 并不是样例类,它们并没有符合 EMail(user, domain) 的表现形式。这就是 Scala 提取器出场的时候了,有了提取器,模式并不需要遵从类型的内部表现形式。
16.2. 提取器
在 Scala 中,提取器是拥有名为 unapply 的成员方法的对象。 这个 unapply 方法的目的是跟某个值做匹配并将它拆解开。通常,提取器对象还会定义一个跟 unapply 相对应的 apply 方法用于构建值,不过这并不是必需的。下面是用于处理电子邮件地址的提取器对象:
object EMail {
// The injection method (optional)
def apply(user: String, domain: String) = user + "@" + domain
// The extraction method (mandatory)
def unapply(str: String): Option[(String, String)] = {
val parts = str split "@"
if (parts.length == 2) Some(parts(0), parts(1)) else None
}
}
unapply 方法是将 EMail 变成提取器的核心方法。从某种意义上讲,它是 apply 这个构造过程的反转。这里的 apply 接收两个字符串并它们组成一个电子邮件地址,而 unapply 接收一个电子邮件地址并(可能)返回两个字符串:地址中的用户和域名。不过 unapply 还必须处理字符串不是子邮件地址的情况。这就是为什么 unapply 返回的是一个包含一对字符的 Option 类型。它的结果要么是 Some(user, domain) (即 Some((user, domain)) 的简写,因为将元组传给接收单个入参的函数时可以省去一组圆括号),要么是 None 。
每当模式匹配遇到引用提取器对象的模式时,它都会用选择器表达式来调用提取器的 unapply 方法。例如,执行下面这段代码:
selectorString match { case EMail(user, domain) => ... }
将会引发如下调用:
EMail.unapply(selectorString)
正如你前面看到的,对 EMail.unapply 的调用要么返回 None ,要么返回 Some(u, d) 。如果返回是 None ,那么模式并未匹配上,系统继续尝试另一个模式,或者以 MatchError 异常终止。如果是 Some(u, d) ,那么模式就匹配上了,其变量会被绑上返回值的元素。在前一例中, user 会被绑上 u ,而 domain 会被绑上 d 。
16.3. 同时使用多个提取器
下面看一个同时使用多个提取器的例子:
object EMail {
// The injection method (optional)
def apply(user: String, domain: String) = user + "@" + domain
// The extraction method (mandatory)
def unapply(str: String): Option[(String, String)] = {
val parts = str split "@"
if (parts.length == 2) Some(parts(0), parts(1)) else None
}
}
object Twice {
def apply(s: String): String = s + s
def unapply(s: String): Option[String] = {
val length = s.length / 2
val half = s.substring(0, length)
if (half == s.substring(length)) Some(half) else None
}
}
object UpperCase {
def unapply(s: String): Boolean = s.toUpperCase == s
}
def userTwiceUpper(s: String) = s match {
case EMail(Twice(x @ UpperCase()), domain) => // 使用了三个提取器 EMail/Twice/UpperCase
"match: " + x + " in domain " + domain
case _ =>
"no match"
}
方法 userTwiceUpper 中使用了三个提取器,下面是对它的一些测试:
scala> userTwiceUpper("DIDI@hotmail.com")
res0: String = match: DI in domain hotmail.com
scala> userTwiceUpper("DIDO@hotmail.com")
res1: String = no match
scala> userTwiceUpper("didi@hotmail.com")
res2: String = no match
方法 userTwiceUpper 中提取器部分 x @ UpperCase() 的含义是把 UpperCase() 能匹配上的模式保存到变量 x 中( @ 符号是变量绑定的语法,可以参考节 13.2.8)。比如,第一个测试例子中,字符串 DI 会保存到变量 x 中。
17. 参考
本文主要摘自:《Scala 编程(第三版)》