Sed
Table of Contents
1. sed 简介
sed (Stream EDitor) is a Unix utility that parses and transforms text, using a simple, compact programming language. sed was developed from 1973 to 1974 by Lee E. McMahon of Bell Labs, and is available today for most operating systems.
参考:
sed Wikipedia: http://en.wikipedia.org/wiki/Sed
GNU sed manual: http://www.gnu.org/software/sed/manual/sed.html
Sed - An Introduction and Tutorial by Bruce Barnett: http://www.grymoire.com/Unix/Sed.html
2. sed 基本格式
sed 基本格式如下:
sed 'script' file sed -e 'script 1' -e 'script 2' file #执行多个sed script,每个script前要用-e选项 sed -f scriptfile file #从scriptfile中读取sed script
若不指定 file,sed 从标准输入中读取待处理的内容,故上面命令中的 file 可以改为<file。
2.1. sed script 格式
sed script 格式为:
[addresses] [!] command [arguments]
说明:[addresses]用来限制 sed command 应用于哪些行,如果省略[addresses]则表示没有限制,即选择所有的行。[addresses]后面的感叹号[!]表示对选定的范围取反。
如果要对[addresses]应用多个命令,除了用多个-e 外(sed -e 'addresses command1' -e 'addresses command2' file),还可用一对大括号把多个命令包围起来(最好把右边的大括号放到单独的一行中,这样兼容性更好)。
[addresses] [!] {
command1 [arguments]
command2 [arguments]
command3 [arguments]
}
对于每个命令还可以单独指定一个[addresses],每个 command 的限定范围同时满足外层的[addresses]和内层[addresses],如下所示:
[addresses] [!] {
[addresses] [!] command1 [arguments]
[addresses] [!] command2 [arguments]
[addresses] [!] command3 [arguments]
}
2.1.1. addresses 形式
| format of address | description | GNU extension |
|---|---|---|
| number | matches only that line in the input. | - |
first~step |
matches every stepth line starting with line first. For example, odd-numbered lines: 1~2. |
Y |
$ |
the last line of the last file of input. | - |
/regexp/ |
any line which matches the regular expression regexp. The empty regular expression // repeats the last regular expression match. \%regexp% is same as /regexp/ (just choose a different delimiter), the % may be replaced by any other single character. |
- |
/regexp/I |
case-insensitive. | Y |
/regexp/M |
causes ^ and $ to match respectively (in addition to the normal behavior) the empty string after a newline, and the empty string before a newline. There are special character sequences (\` and \') which always match the beginning or the end of the buffer. M stands for multi-line. |
Y |
| format of address range | description | GNU extension |
|---|---|---|
| address1, address2 | lines starting from where address1 matches, and continues until address2 matches (inclusively). | - |
| address1, +N | matches address1 and the N lines following address1. | Y |
| address1, ~N | matches address1 and the lines following addr1 until the next line whose input line number is a multiple of N. | Y |
参考:http://www.gnu.org/software/sed/manual/sed.html#Addresses
2.2. sed 工作流程
sed 工作流程如图 1 所示。
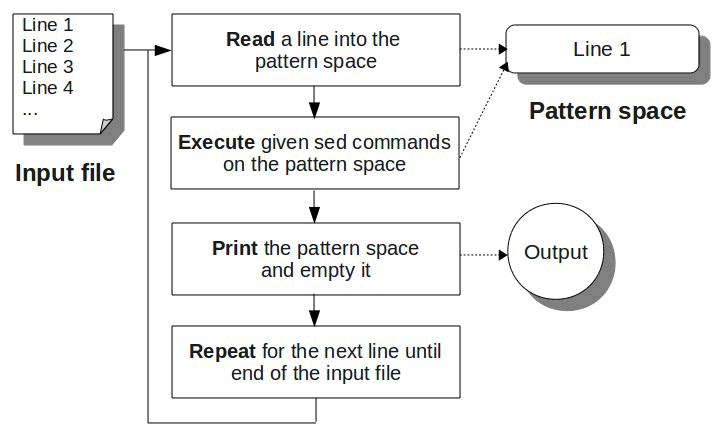
Figure 1: sed 工作流程(摘自:Sed and Awk 101 Hacks)
2.3. option -n: no printing
The "-n" option (-n is same as --quiet or --silent) will not print anything unless an explicit request (command p) to print is found.
下例中,PATTERN 所在行会被输出两次,其它行输出一次。
sed '/PATTERN/ p' file
下例中,只会输出 PATTERN 所在行(和 grep 类似)。
sed -n '/PATTERN/ p' file
3. sed 中的正则表达式
默认 sed 支持的是基本的正则表达式。
在基本的正则表达式中,{, |, (, )仅是其代表的字面字符,要进行转义(前面加反斜线)才是正则的元字符;在基本的正则表达式中不支持元字符?, +。
下面实例中,用正则找到重复的单词:
$ echo "abc abc" | sed -n '/\([a-z][a-z]*\) \1/p' abc abc
参考
Basic Regular Expressions
Overview of Regular Expression Syntax
3.1. extended regular expressions
在扩展的正则表达式中,?, +, {, |, (, )都是正则元字符,这样写书正则表达式更方便。
GNU sed 中,-r 选项表达使用扩展的正则表达式,在 Mac OS X 或 FreeBSD 中-E 选项表达使用扩展的正则表达式。
用扩展正则表达式(GNU sed)重写前面找重复单词的例子:
$ echo "abc abc" | sed -rn '/([a-z]+) \1/p' abc abc
4. Substitute (s command)
substitute 命令的基本格式为:
sed '[addresses] s/regexp/replacement/flags'
注:其中分隔符‘/’也可以为其它任意的单个字符。
4.1. replacement
| special character | description | GNU extension |
|---|---|---|
\number |
匹配正则表达式中的第 number 组(组是正则表达式中小括号中的内容) | - |
& |
The whole matched portion of the pattern space. 相当于 \0 |
- |
\L |
Turn the replacement to lowercase until a \U or \E is found. |
Y |
\l |
Turn the next character to lowercase. | Y |
\U |
Turn the replacement to uppercase until a \L or \E is found. |
Y |
\u |
Turn the next character to uppercase. | Y |
\E |
Stop case conversion started by \L or \U. |
Y |
4.1.1. \number 实例(group 的使用)
下面实例将删除 abcd123 中的数字:
$ echo abcd123 | sed 's/\([a-z]*\).*/\1/' abcd
4.1.2. \U 实例(转大写)
下面实例将把匹配的内容变为大写:
$ echo abcd123 | sed 's/\([a-z]*\).*/\U\1/' ABCD
4.2. flags
| substitute flags | description | GNU Extension |
|---|---|---|
| g | "global" 替换所有的匹配,而不仅仅是第一个匹配 | - |
| number | 替换指定的第几个匹配,如 echo "abc,abc,abc" | sed 's/abc/ABC/2' => "abc,ABC,abc" | - |
| p | "print" 打印替换后的行,往往和 -n 一起使用(默认 sed 会输出所有的行,除非用 -n 选项禁止输出) |
- |
| w file-name | "write" 把结果输出到文件 file-name 中 | - |
| i 或 I | 大小写不敏感 | Y |
| m 或 M | 多行模式 | Y |
| e | Execute whatever is available in the pattern space as a shell command, and the output will be returned to the pattern space. | Y |
4.2.1. flag e 实例
The sed substitute flag e stands for execute. Using the sed e flag, you can execute whatever is available in the pattern space as a shell command, and the output will be returned to the pattern space. This is available only in the GNU sed.
flag e 实例:
假设有如下文件(files.txt)。
$ cat files.txt /etc/shells /etc/profile
在每行的行首增加 ls -l:
$ sed 's/^/ls -l /' files.txt ls -l /etc/shells ls -l /etc/profile
把 pattern space 按 shell 命令执行:
$ sed 's/^/ls -l /e' files.txt -rw-r--r-- 1 root root 201 Apr 13 20:47 /etc/shells -rw-r--r-- 1 root root 7634 Apr 13 20:47 /etc/profile
pattern space 被 flag e 处理后,会把输出放回到 pattern space 中,可以再次进行处理:
$ sed -e 's/^/ls -l /e' -e 's/root/cig01/g' files.txt -rw-r--r-- 1 cig01 cig01 201 Apr 13 20:47 /etc/shells -rw-r--r-- 1 cig01 cig01 7634 Apr 13 20:47 /etc/profile
5. Hold space
sed 维护着两个 buffer:pattern space 和 hold space,初始时都为空。hold space 常用来作临时备份数据。有 5 个命令可操作 hold space。
| commands on hold space | description |
|---|---|
| g | 复制 hold space 中的内容到 pattern space 中,原来 pattern space 里的内容被清除 |
| G | 追加 hold space 中的内容到 pattern space 中(追加内容前先插入换行符) |
| h | 复制 pattern space 中的内容到 hold space 中,原来 hold space 里的内容被清除 |
| H | 追加 pattern space 中的内容到 hold space 中(追加内容前先插入换行符) |
| x | 交换 pattern space 和 hold space 的内容 |
hold space 的几个实例:http://www.thegeekstuff.com/2009/12/unix-sed-tutorial-7-examples-for-sed-hold-and-pattern-buffer-operations/
5.1. 实例:确保某行前面有特定行
假设有个数据文件,我们希望当某行内容为 KEYWORD 时,在它前一行增加 ABCD(如果前一行是 ABCD 则不做改动)。
这个任务可用下面脚本(1.sh)完成:
#!/usr/bin/env sh
sed '
# 当前行不是KEYWORD时,备份到hold space
/KEYWORD/ !{
h
}
# 当前行是KEYWORD时,检查上一行是否是ABCD,若不是则插入ABCD
/KEYWORD/ {
# 交换pattern space和hold space
# 即把之前备份的上一行放入到pattern space,把当前行备份到hold space
x
# 检查pattern space是不是ABCD,或不是则用i在Output Stream中插入ABCD
/ABCD/ !{
i\
ABCD
}
# 恢复当前行,下行不用x,用g也可以
x
}
'
假设原数据文件为(data),有两个 KEYWORD 行前面没有 ABCD:
XYZ KEYWORD ABCD KEYWORD ABCD KEYWORD KEYWORD
用前面脚本处理这个文件( sh 1.sh <data ),可得到下面结果(每个 KEYWORD 行前都有 ABCD 了):
XYZ ABCD KEYWORD ABCD KEYWORD ABCD KEYWORD ABCD KEYWORD
5.2. 实例:确保每行后有且仅有一个空行
假设有下面数据文件,如何让每行后面都有且仅有一个空行呢?
$ cat file a b c d e
思路很简单,删除所有空行,再把每行后增加一个空行即可。
$ sed '/^$/d; G' file a b c d e
6. Multiple lines commands
默认 sed 是一行一行处理的,sed 中有三个命令用于多行处理:"N","D","P",其对应的单行处理命令分别为"n","d","p"。
注:当 pattern space 中有多行时,^和$分别匹配的是整个多行的“第一个位置”和“最后一个位置”。
6.1. Append next line to pattern space (N command)
The "n" command will print out the current pattern space (unless the "-n" flag is used), empty the current pattern space, and read in the next line of input. The "N" command does not print out the current pattern space and does not empty the pattern space. It reads in the next line, but appends a new line character along with the input line itself to the pattern space.
6.1.1. 实例:对文件每一行进行编号
假设有下面数据文件,如何对每一行进行编号后再输出呢?
$ cat file a b c
用=命令可以输出行号,但行号在单独的行中:
$ sed = file 1 a 2 b 3 4 c
再用 N 命令读取连续两行,把换行符替换为制表符即可。
$ sed = file | sed 'N; s/\n/\t/' 1 a 2 b 3 4 c
6.2. Delete first line in multiple lines (D command)
The "d" command deletes the current pattern space, reads in the next line, puts the new line into the pattern space, and aborts the current command, and starts execution at the first sed command. This is called starting a new "cycle." The "D" command deletes the first portion of the pattern space, up to the new line character, leaving the rest of the pattern alone.
6.2.1. 实例:删除特定行如果它后面是另一特定行
假设有下面数据文件,我们想删除 KEY1 所在行,当且仅当它的下一行中含有 KEY2 时。
$ cat file KEY1 KEY2 KEY1 OTHER
下面脚本能完成这个任务:
#!/usr/bin/env sh
sed '
/KEY1/ {
# append a line
N
# if KEY2 found, delete the first line
/\n.*KEY2/ D
}
' file
6.3. Print first line in multiple lines (P command)
The "p" command prints the entire pattern space. The "P" command only prints the first part of the pattern space, up to the NEWLINE character. Neither the "p" nor the "P" command changes the patterns space.
7. Flow control (:label, b, t command)
| Flow Control | description |
|---|---|
| :label | Defines the label. |
| b [label] | Jumps to the line marked by the label and continues executing the rest of the commands from there. If label is omitted, jumps to the end of the sed script file. |
| t [lable] | When the previous substitution was successful, sed jumps to the line marked by the label and continues executing the rest of the commands from there, otherwise it continues normal execution flow. If label is omitted, jumps to the end of the sed script file. |
7.1. 实例:删除双引号之间的内容
假设在下面数据文件,如何删除双引号之间(可能跨行)的内容呢?
$ cat file
Productivity
Google Search\
Tips
"Web Based Time Tracking,
Web Based Todo list and
Reduce Key Stores etc"
下面脚本能完成这个任务:
#!/usr/bin/env sh
sed '{
:loop
$ ! {
# If its not the last line of file
# Append the next line with the pattern space delimited by \n.
# Jump to the loop again.
N
b loop
}
# Now all the lines will be available in pattern space delimited by newline.
# Substitute all the occurrence of data between "" with the empty.
s/\"[^\"]*\"//g
}
' file
参考:http://www.thegeekstuff.com/2009/12/unix-sed-tutorial-6-examples-for-sed-branching-operation/
7.2. 实例:删除续行符\后合并下行到当前行
假设在下面数据文件,如何删除续行符\后合并下行到当前行?
$ cat file
Productivity
Google Search\
Tips
"Web Based Time Tracking,
Web Based Todo list and
Reduce Key Stores etc"
下面脚本能完成这个任务:
#!/usr/bin/env sh
sed '{
:loop
# Check if the line ends with the backslash (/\\$/),
# if yes, read and append the next line to pattern space.
/\\$/ N
# Substitute the \ at the end of the line and number of spaces
# followed by that, with the single space.
s/\\\n */ /
# The branch will be executed only if substitution is success.
t loop
}
' file
运行上面脚本后,可得到下面输出(Search Tips 已经在同一行了):
Productivity
Google Search Tips
"Web Based Time Tracking,
Web Based Todo list and
Reduce Key Stores etc"
8. sed command summary
表 7 总结了 sed 所支持的命令。
| Command | Description | Address or Range | Modification to Input Stream | Modification to Output Stream | Modification to Pattern Space | Modification to Hold Sapce |
|---|---|---|---|---|---|---|
| = | Print line number | - | - | Y | - | - |
| a | Append a line after | Address | - | Y | - | - |
| b | Branch to a label | Range | - | - | - | - |
| c | Change a line | Range | - | Y | - | - |
| d | Delete current pattern space, and loads new line | Range | Y | - | Y | - |
| D | Deletes first line of pattern space, loads new line | Range | Y | - | Y | - |
| g | Copy hold space into pattern buffer | Range | - | - | Y | - |
| G | Append hold space into pattern buffer | Range | - | - | Y | - |
| h | Copies pattern space into hold buffer | Range | - | - | - | Y |
| H | Appends pattern space into hold buffer | Range | - | - | - | Y |
| i | Insert a line before | Address | - | Y | - | - |
| l | Display pattern space (useful when debugging) | Address | - | Y | - | - |
| n | Print current pattern space, loads new line | Range | Y | * | - | - |
| N | Appends new line into pattern space | Range | Y | - | Y | - |
| p | Prints current pattern space | Range | - | Y | - | - |
| P | Prints first line of current pattern space | Range | - | Y | - | - |
| q | Quit | Address | - | - | - | - |
| r | Read file | Address | - | Y | - | - |
| s | Substitute | Range | - | - | Y | - |
| t | Brach after testing last substitution | Range | - | - | - | - |
| w | Write file | Range | - | Y | - | - |
| x | Exchanges pattern space and hold buffer | Range | - | - | Y | Y |
| y | Translate (tr) | Range | - | - | Y | - |
参考:http://www.grymoire.com/Unix/SedChart.pdf
说明:关于上表中命令可接受 Address 还是 Range 不一定对所有实现都准确。如在 GNU sed( 测试版本为 4.2.2)中命令 a 也能接受 Range。
$ echo -e "a\nb" |sed '1,2 a\new' a new b new
9. sed 实例
9.1. 实例:在某行之后增加一行
使用命令 a ,可以在某行之后增加一行。下面命令将在“ABCD”这行之后增加一行“NEW LINE”。
$ sed -i.bak "/ABCD/a NEW LINE" file.txt
如果我们想增加的行行首有空格,则需要在第一个空格前面使用反斜线“\”。如:
$ sed -i.bak "/ABCD/a NEW LINE" file.txt # 会增加一行,内容为"NEW LINE"(空格被忽略了) $ sed -i.bak "/ABCD/a \ NEW LINE" file.txt # 会增加一行,内容为" NEW LINE"(空格被保留)
说明:在 posix 兼容的 sed(如 Mac 中默认的 sed)中, a 命令后面必需要有反斜线,而且反斜线后面必需是换行。即上面命令应该写为:
$ sed "/ABCD/a \ > NEW LINE > " file.txt
9.2. 实例:注释某行或对某行取消注释
下面例子演示了如何使用 sed 注释某行或对某行取消注释(假定注释符号为#):
$ sed -i '100,102 s/^/#/g' file # 注释file的第100~102行 $ sed -i '100,102 s/^#//g' file # 对file的第100~102行取消注释
10. sed tips
10.1. Mac sed 中 \t 不是 tab
Mac sed 中 \t 不是 tab,直接看下面例子。
Mac 中测试:
$ echo -e "a\tb" | sed 's/\t//' # Mac中并不会删除a和b之间的tab,Mac中sed不支持\t a b
Linux 中测试:
$ echo -e "a\tb" | sed 's/\t//' # Linux中会删除a和b之间的tab ab
使用 bash 的 ANSI-C style quoting,可以使 \t 在 Mac sed 中有效。Mac/Linux 中测试:
$ echo -e "a\tb" | sed $'s/\t//' # 使用ANSI-C style quoting,Mac/Linux都会删除a和b之间的tab ab
参考:https://stackoverflow.com/questions/5398395/how-can-i-insert-a-tab-character-with-sed-on-os-x