LevelDB
Table of Contents
1. LevelDB 简介
LevelDB 是 Google 开源的 Key-Value Storage Library,之所以称为“Library”,是因为它不提供网络相关的代码(如果你想以 Client-Server 方式来使用,则需要自己去封装,或者使用别人的封装,比如 ssdb),它以库的形式提供功能,支持的基本操作有 Put(key,value), Get(key), Delete(key) 。
LevelDB 存储的数据是按 Key 进行排序的,所以可以快速地查寻某个 Key 范围内的所有的 Value。
LevelDB 采用了 Log Structured Merge(LSM)存储结构,具有很好的“写入(包含顺序写入和随机写入)”性能,也有很好的“顺序读取”性能,但“随机读取”性能一般。 除 LevelDB 外,很多著名数据库也采用了 LSM 存储结构,比如 Bigtable, HBase, SQLite4, Tarantool, WiredTiger, Apache Cassandra, InfluxDB and ScyllaDB。
2. LevelDB 基本思想
我们知道,不管是机械硬盘还是 SSD,其“顺序”写入要比“随机”写入要快很多。对于机械硬盘我们容易理解,随机写入时磁头需要重定位;而对于 SSD 这和它的 Garbage Collection 等机制有关,具体可以参考 https://serverfault.com/questions/843628/why-do-sequential-writes-have-better-performance-than-random-writes-on-ssds
为了防止断电数据丢失,一般都会采用 Write-Ahead Logging(简称 WAL),以顺序写入的方式记录日志。如果数据量不大,则写完 WAL 后,再把数据写入到内存中即可。当数据量大时,内存放不下,肯定需要写入到磁盘中(前面不是写 WAL 时已经落盘了吗?WAL 日志是按照请求的次序顺序写入的,不方便读取这个文件来响应 Get 请求,而且 LevelDB 还支持 Key 的有序操作,使用 WAL 更不可行了)。LevelDB 的核心就是解决内存放不下时,如何较好地组织数据到磁盘中,以方便快速地写入和读取。
LevelDB 架构如图 1 所示。

Figure 1: Leveldb Architecture
在内存中有两个结构:MemTable 和 Immutable MemTable,磁盘中有很多 SSTable(Sorted Strings Table)。 只有 MemTable 可以修改,Immutable MemTable 和 SSTable 都不能修改。
SSTable 是按 Key 排序的文件,如图 2(摘自 https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/ )所示。

Figure 2: Leveldb SSTable
磁盘中的 log 就是 WAL 日志文件; MANIFEST 用于记录 SSTable 的基本信息,比如每个 SSTable 包含了哪一些 Key 范围的数据; CURRENT 文件的内容很简单,整个文件就记录一个 MANIFEST 文件名,表示当前正在使用的 MANIFEST 文件名(可能有多个 MANIFEST,如 MANIFEST-000001、MANIFEST-000002)。
2.1. 写入流程
LevelDB 写入数据的主要步骤:
- 顺序写 WAL 日志文件;
- 写内存的 MemTable。
大部分情况下,写入就完成了(当然,有时可能会触发 Compaction,后面将介绍)。 LevelDB 之所以写入快,就是因为上面这两个操作(即磁盘的顺序写入、内存操作)都是很快的。
一直写内存的 MemTable,当数据量大时肯定会写不下,怎么办呢?LevelDB 的处理机制是: 当 MemTable 插入的数据到达一个界限后,LevelDB 会生成新的 log 文件和新的 MemTable,原先的 MemTable 就成为 Immutable MemTable(它的内容是不可修改的)。 新数据被写入新的 log 文件和新的 MemTable,而 LevelDB 后台调度会将 Immutable MemTable 的数据 Dump 到 Level 0 的一个 SSTable 文件。
由于 Level 0 仅仅是 Immutable MemTable 的一个“原样”导出,所以 Level 0 可能出现 Overlapping。 比如,刚刚导出了 Immutable MemTable 为 Level 0 的一个 SSTable,它包含了 Key 是 3,4,60;现在又导出了另一个 Immutable MemTable 为 Level 0 的一个 SSTable,它包含了 Key 是 7,9,80;这两个 SSTable 就出现了 Overlapping。
Level 0 中的 SSTable 达到一定数量(默认为 4 个)后会 Merge 为 Level 1 中的 SSTable,而 Level 1 会进一步 Merge 为 Level 2 中的 SSTable,依此类推,层层 Merge(默认最多 7 个 Level),这个过程称为 Compaction,细节可参考节 3 。
2.2. 读取流程
LevelDB 读取数据的步骤:
- 从 MemTable 中找,找到就直接返回;
- 再从 Immutable MemTable 中找,找到就直接返回;
- 再从 Level 0 中找,找到就直接返回;
- 再从 Level 1 中找,找到就直接返回;
- 依次类推,如果在最大 Level 中也找不到,则说明 Key 不存在。
如果运气好,读取的数据在 MemTable 或者 Immutable MemTable 中,那么查找也是很快的;运行不好,则可能要找很多层才能找到,或者找了很多层后最后也还是没有找到(使用 Bloom Filter 可以避免查找很多次最后没找到的情况,因为 Bloom Filter 有个特性“如果找不到则一定不存在”)。
3. Compaction
LevelDB 使用后台线程执行 Compaction,当“某个 Level 的 SSTable 太多”或者“某个 SSTable 被无效查询的次数过多(在文件中查询 Key,但却找不到时,这次查询就是这个文件的一次无效查询)”等情况时,会触发 Compaction。
将 Level L 层中一个 SSTable 进行 Compaction 时,需要找到 Level L+1 层那些和 Level L 层这个 SSTable 有 Overlapping 的所有 SSTable(可能有多个),然后进行 Merge,生成 Level L+1 层一个新的 SSTable, 图 3(原图来源于 https://draveness.me/bigtable-leveldb/ ,但有改编)演示了 Compaction 的过程。
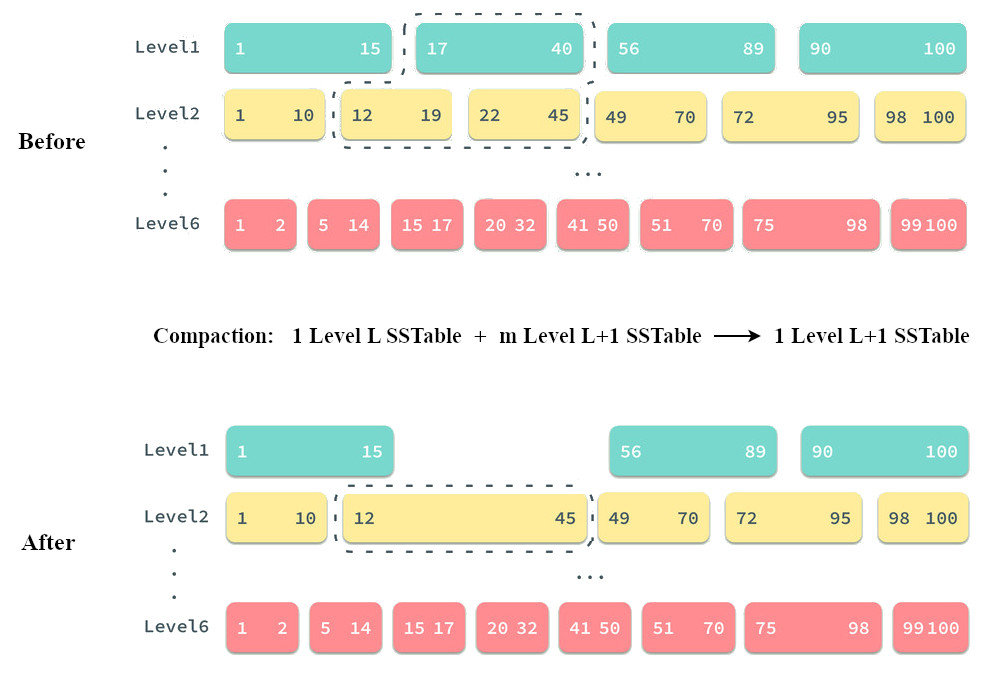
Figure 3: Leveldb Compaction
由于写入数据时,总是先放到 Level 小的层,所以 Level 越小,它的数据就越新。假设在图 3 的 Compaction 过程时,Level 1 中有个 Key(18) = Value1,而 Level 2 中有个 Key(18) = Value2,则 Compaction 后,会留下 Key(18) = Value1 放到 Level 2 的 SSTable 中。
参考:https://github.com/google/leveldb/blob/master/doc/impl.md#compactions
3.1. MVCC (Version/VersionEdit/VersionSet)
图 3 所示的例子中,Compaction 完成后,可以马上删除 3 个旧的 SSTable 吗?由于它们可能正在被其它线程读取,所以不能删除。LevelDB 采用了 MVCC 的方式的处理这个问题: 示例中 3 个旧的 SSTable 组成“旧的 Version”,继续提供读服务,当确定没有线程读取后才可以安全地删除。
LevelDB 中还有 VersionEdit/VersionSet 的概念:
VersionSet is a helper class that manages all of the live Version objects.
VersionEdit is a delta that describes what files have been added and removed between two adjacent Versions. This delta is logged to a MANIFEST file. The MANIFEST file is read during recovery and is used to reconstruct the current Version. VersionEdit objects are just short-lived objects that are created during recovery and in the process of installing a new version.
3.2. Size-Tiered Compaction
节 3 介绍的 Compaction 策略被称为“Leveled Compaction”,它的特征是:“每个 Level(注:Level 0 除外)的 SSTable 没有 overlapping”,这样有个好处:在同一层查找 Key 时只用找一个 SSTable 文件。
除 Leveled Compaction 外,还有一个称为“Size-Tiered Compaction”的策略,它是思想是:根据每层 SSTable 文件的数量进行 Compaction,比如每一层 SSTable 超过某个阈值(如 4 个)就 Compaction,也就是限制每层最多只能有 4 个 SSTable(对于同层 SSTable 文件是否 overlapping 不做要求),如图 4(摘自 https://www.scylladb.com/2018/01/17/compaction-series-space-amplification/ )所示。Cassandra 默认采用“Size-Tiered Compaction”策略。
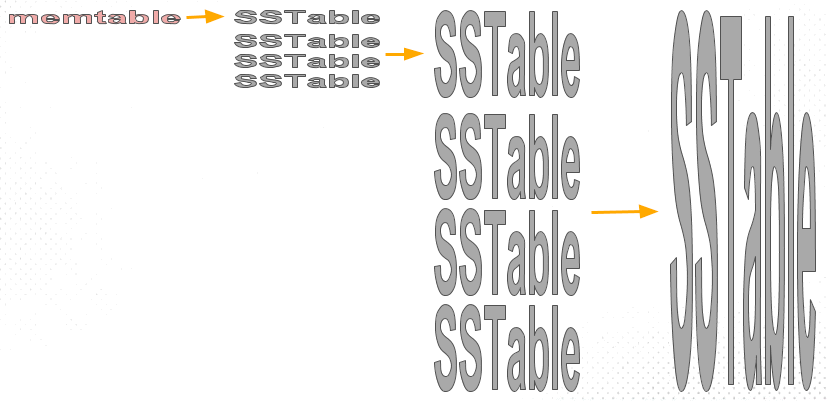
Figure 4: Size-Tiered Compaction
3.3. Compaction 策略及其取舍
没有完美的 Compaction 策略,不同的策略之间对应不同的取舍。图 5(摘自 https://stratos.seas.harvard.edu/files/stratos/files/dostoevskykv.pdf )展示了这种取余关系。
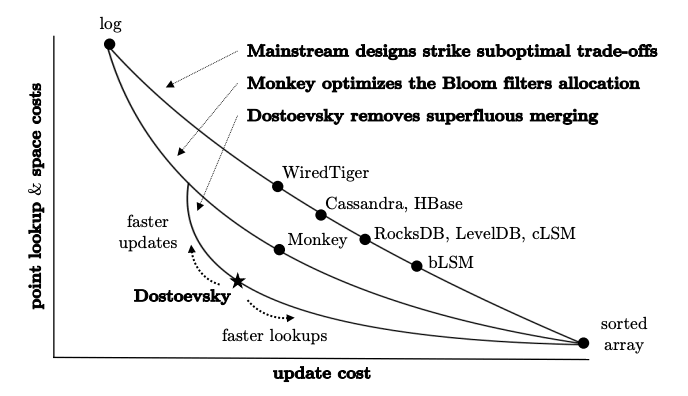
Figure 5: Compaction 策略及其取舍
在图 5 左上角 log,表示不做 Compaction,这样写入很快,但查询会很慢,而且由于不删除过时的旧值,硬盘占用随着不停写入(更新)会一直增加。而右下角 sorted array,表示每次都立即去 Compaction,所有数据都只留下最新值,而且是排序状态,这样查询效率最高,但写入性能不好。
3.3.1. Read, Write & Space Amplification
有 3 个指标来衡量 Key-Value 数据库性能:
- Write Amplification,衡量一个写操作需要付出多少工作。
- Read Amplification,衡量一个读操作需要付出多少工作。
- Space Amplification,假设数据的真正大小是 100MB,但实际存储时耗掉了 300MB,说明 Space 被放大了 3 倍。
表 1 对比了 Leveled Compaction 和 Size-Tiered Compaction 的 3 个指标:
- 由于 Leveled Compaction 会维持每一层(Level 0 排外)SSTable 没有 overlapping(方便同层中更快查找),这相对 Size-Tiered Compaction 来说需要额外的工作,所以 Leveled Compaction 的 Write Amplification 相当会更大。
- 由于 Leveled Compaction 能保证同层 SSTable 之间没有 overlapping,这个性质可以帮助更快查找,所以相对 Size-Tiered Compaction 来说 Read Amplification 会更小。
- Leveled Compaction 冗余数据相当比较少(如同层中没有 overlapping,意味着同层没冗余),所以相对 Size-Tiered Compaction 来说 Space Amplification 会更小。
可见“Leveled Compaction”策略在这 3 指标中有 2 项占据优势。
| Leveled Compaction | Size-Tiered Compaction | |
|---|---|---|
| Write Amplification | 大 | 小 |
| Read Amplification | 小 | 大 |
| Space Amplification | 小 | 大 |
参考:
http://smalldatum.blogspot.com/2015/11/read-write-space-amplification-b-tree.html
http://smalldatum.blogspot.com/2015/11/read-write-space-amplification-pick-2_23.html
4. Snapshot
LevelDB 具有 Snapshot 功能,提供了提取历史数据的能力。
Snapshot 是利用 Sequence Number 来实现的,什么是 Sequence Number 呢?
Sequence number is a monotonically increasing 56 bits integer value. Every time a key is written to LevelDB, it is tagged with a sequence number one larger than sequence number tagged with previous key written to LevelDB. If two entries in LevelDB have same user level keys, the one with larger sequence must shadow the other.
Snapshot in LevelDB is represented by a sequence number. When retrieving entries from a snapshot, entries whose sequence number are larger than the snapshot’s are ignored. In compaction, we record the smallest sequence number among alive snapshots, and we never delete keys shadowed only by entry with sequence number larger that this smallest sequence number. After enforcing these restrictions on retrieve and compaction, we guarantee that: The state a snapshot captured is frozen in its creation time.
摘自:https://blog.kezhuw.name/2016/06/14/invariants-in-leveldb-algorithm/
注:Snapshot 是“只读”的,没有提供把当前 DB 恢复到“创建快照时的版本”的功能,尽管如此,通过一些额外的工作(比如记录修改日志)我们可以把 DB 恢复到“创建快照时的版本”,参见:https://stackoverflow.com/questions/23047796/how-to-rollback-leveldb-to-a-previous-state