Linux Buddy and Slab Allocator
Table of Contents
1. 基本知识
1.1. 页和页框
页(Page)是一段连续的“虚拟内存”,它是“虚拟内存”的最小管理单元;页框(Page Frame)是一段连续的“物理内存”,它是“物理内存”的最小管理单元。
Page 和 Page Frame 的大小是相同的。一般为 4K,通过执行命令 getconf PAGESIZE 可以得到页的大小。
Page 和 Page Frame 有下面关系:
At any given time, a page may not be backed by a page frame (it could be a zero-fill page which hasn't been accessed, or paged out to secondary memory), and a page frame may back multiple pages (sometimes in different address spaces, e.g. shared memory or memory-mapped files).
1.2. NUMA
SMP(Symmetric Multi-Processor,对称多处理器)结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 属于 Uniform Memory Access (UMA) 结构。
但是随着 CPU 的增加,CPU 共享内存可能会导致内存访问冲突越来越厉害,且如果内存访问达到瓶颈的时候,性能就不能随之增加。非统一内存访问(Non-Uniform Memory Access, NUMA)就是这样的环境下引入的一个模型。
比如一台机器是有 2 个处理器,有 4 个内存块。我们将 1 个处理器和 2 个内存块合起来,称为一个“NUMA node”,这样这个机器就会有两个 NUMA node。在物理分布上,NUMA node 的处理器和内存块的物理距离更小,因此访问也更快。使用 NUMA 的模式如果能尽量保证本 node 内的 CPU 只访问本 node 内的内存块,那这样的效率就比较高。
1.3. 内存区域(Zones)
物理内存一般划分为不同的区(Zones)。
在 32 位系统中,物理内存分为下面三个 Zones:
DMA 0 - 16MB Normal 16MB - 896MB HighMem 896MB - above
在 64 位系统中,物理内存分为下面三个 Zones:
DMA 0 - 16MB DMA32 16MB - 4GB Normal 4GB - above
Linux 中执行命令 cat /proc/zoneinfo 可以查看内存 Zones 的一些基本信息。
2. Buddy 分配器
频繁地请求和释放不同大小的一组连续页框(Page Frame),必然导致在已分配页框的块内分散了许多小块的空闲页框。由此带来的问题是,即使有足够的空闲页框可以满足请求,但要分配一个大块的连续页框就可能无法满足。这是所谓的外部碎片(external fragmentation)。
2.1. Buddy 分配算法
Linux 采用著名的“伙伴系统”(Buddy System)分配算法来减少外部碎片的产生。
把所有的空闲页框分组为 11 个块链表(如图 1 所示,图片摘自书籍 Understanding the Linux Virtual Memory Manager),每个块链表分别包含大小为 1, 2, 4, 8, 16, 32, 64, 128, 256, 512 和 1024 个连续的页框。对 1024 个页框的最大请求对应着 4MB(假设页大小为 4KB)大小的连续内存块(也就是说内核一次最多分配 4MB 的连续物理内存,如果应用程序需要更大连续内存,用页表可以把不连续的物理地址在虚拟地址上连续起来)。每个块的第一个页框的物理地址是该块大小的整数倍。例如,大小为 16 个页框的块,其起始地址是 16 x 4096 (4096 就是页大小 4KB)的倍数。
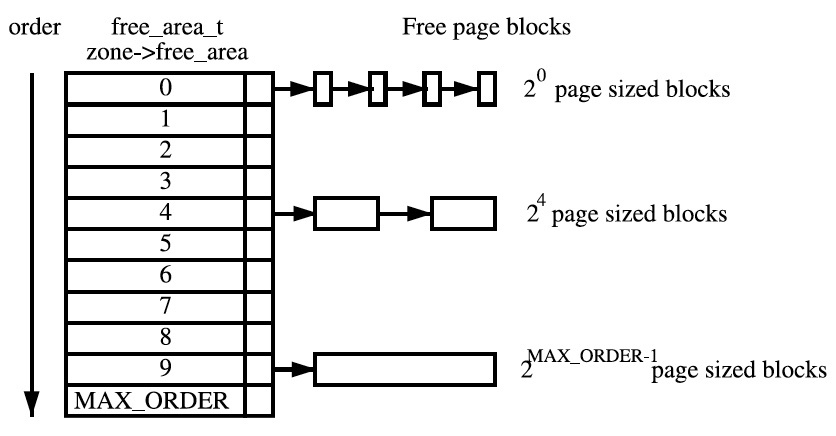
Figure 1: Free Page Block
我们通过一个简单的例子来说明 Buddy 算法的工作原理。
假设要请求一个 256 个页框的块(即 256 x 4KB = 1MB)。算法先在 256 个页框的链表中检查是否有一个空闲块。如果没有这样的块,算法会查找下一个更大的页块,也就是,在 512 个页框的链表中找一个空闲块。如果存在这样的块,内核就把 256 的页框分成两等份,一半用作满足请求,另一半插入到 256 个页框的链表中。如果在 512 个页框的块链表中也没找到空闲块,就继续找更大的块:1024 个页框的块。如果这样的块存在,内核把 1024 个页框块的 256 个页框用作请求,然后从剩余的 768 个页框中拿 512 个插人到 512 个页框的链表中,再把最后的 256 个插人到 256 个页框的链表中。如果 1024 个页框的链表还是空的,算法就放弃并发出错信号。
以上过程的逆过程就是页框块的释放过程,也是该算法名字的由来。内核试图把大小为 \(b\) 的一对空闲伙伴块合并为一个大小为 \(2b\) 的单独块。满足以下条件的两个块称为“伙伴”:
1、两个块具有相同的大小,记作 \(b\) 。
2、它们的物理地址是连续的。
3、第一块的第一个页框的物理地址是 \(2 \times b \times 4096\) (其中 4096 是页的大小)的倍数。
该算法是迭代的,如果它成功合并所释放的块,它会试图合并 \(2b\) 的块,以再次试图形成更大的块。
执行命令 cat /proc/buddyinfo 可以查看空闲的内存信息:
$ cat /proc/buddyinfo Node 0, zone DMA 1 1 1 0 2 1 1 0 1 1 3 Node 0, zone DMA32 3005 14516 20508 6527 1254 386 75 52 20 4 1 Node 0, zone Normal 1291 665 362 125 55 24 2 2 10 5 1
上面输出中,每一行对应每个 Zone,而 11 列数字对应 11 个块链表,数字的具体含义就是对应块链表中空闲块的个数。
3. Slab 分配器
Slab 分器器工作于 Buddy 分配器之上,对内核对象进行缓存,为内核提供更高效的内存分配。内核内存分配 kmalloc 底层就是使用 Slab 分配器。
Slab 的内存来自 Buddy 分配器。Buddy 分配器把内存条当作一个池子来管理,Slab 分配器把从 Buddy 分配器拿到的内存当作一个池子来管理的。
Buddy 分配器和 Slab 分配器如图 2 所示(图片改编自 Shinpei Kato, Advanced Operating Systems)。
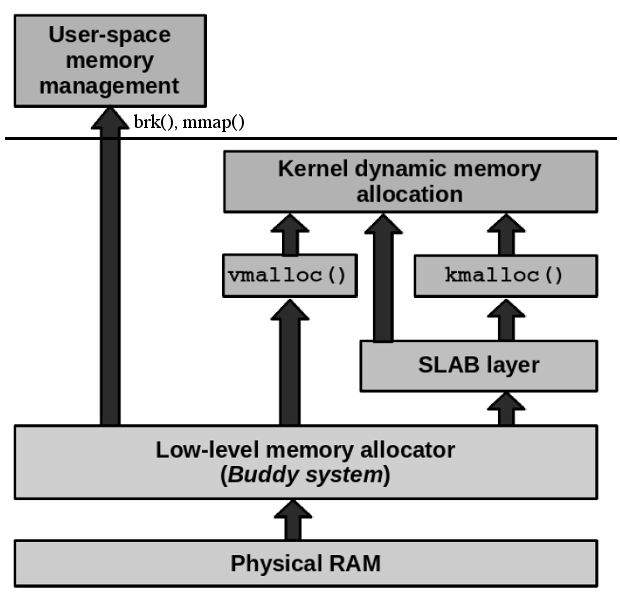
Figure 2: Buddy Slab 的工作层次
从内核 2.6.23 起,Linux 使用的是 Slub 分配器,它是 Slab 的一种改进分配算法。
执行命令 cat /proc/slabinfo 可以查看 Slab/Slub 分配器的相关信息。
4. 参考
Understanding the Linux Virtual Memory Manager
深入理解linux内核(第三版),第八章