Linux Kernel - Process Management
Table of Contents
1. 进程
进程就是处于执行期的程序(目标码存放在某种存储介质上)。但进程并不仅仅局限于一段可执行程序代码(Unix 称其为代码段,text section)。通常进程还要包含其他资源,像打开的文件,挂起的信号,内核内部数据,处理器状态,一个或多个具有内存映射的内存地址空间及一个或多个执行线程(thread of execution),当然还包括用来存放全局变量的数据段等。
执行线程,简称线程(thread),是在进程中活动的对象。每个线程都拥有一个独立的程序计数器、进程栈和一组进程寄存器。内核调度的对象是线程,而不是进程。在传统的 Unix 系统中,一个进程只包含一个线程,但现在的系统中,包含多个线程的多线程程序司空见惯。
2. 进程描述符
内核把进程的列表存放在叫做任务队列(task list)的双向循环链表中,如图 1 所示。链表中的每一项都是类型为 task_struct、称为进程描述符(process descriptor)的结构,该结构定义在<linux/sched.h>文件中。
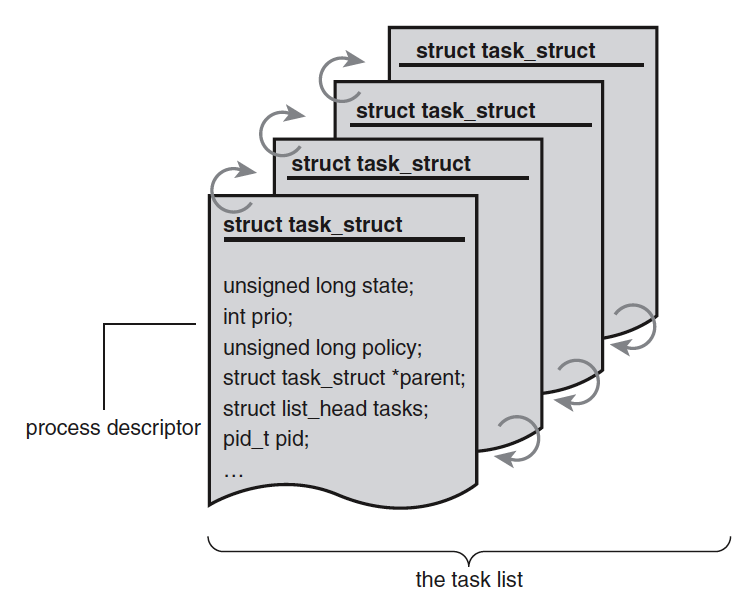
Figure 1: The process descriptor and task list
进程描述符中包含的数据能完整地描述一个正在执行的程序:它打开的文件,进程的地址空间,挂起的信号,进程的状态,还有其他更多信息,下面是一个简化的 task_struct :
struct task_struct {
volatile long state; // 进程状态
struct sched_entity se; // 调度相关信息
struct list_head tasks; // 双向链表,list_head 的字段 prev/next分别表示前面/后面的 task_struct
struct mm_struct *mm; // 进程地址空间(用户空间中进程的内存),即虚拟内存相关信息
pid_t pid; // 进程ID
struct task_struct *real_parent; // 真正父进程
struct task_struct *parent; // SIGCHLD 信号的接收者
struct files_struct *files; // 打开的文件
struct signal_struct *signal; // 所接收的信号
struct sigpending pending; // 挂起的信号
// ......
}
2.1. 分配进程描述符
我们先介绍一下内核栈。 进程除了用户态的栈外,还有一个“内核栈”,当进程通过系统调用等方式进入内核态时,会使用其内核栈。 “内核栈”位于内核数据段中;而用户态进程所用的栈,在进程线性地址空间中。内核控制路径使用很少的栈空间,所以内核栈几千个字节就够用了(一般为 8KB)。
在 Linux 2.6 以前的内核中,各个进程的 task_struct 存放在它们“内核栈”的尾端。这样做是为了让那些像 x86 那样寄存器较少的硬件体系结构只要通过栈指针就能计算出它的位置,而避免使用额外的寄存器专门记录。而在 Linux 2.6 及以后,使用 slab 分配器动态生成 task_struct ,所以只需在栈的尾部创建一个新的结构 thread_info 。
在 x86 中,结构 thread_info 的定义如下:
struct thread_info {
struct task_struct *task; // “进程描述符”的指针
struct exec_domain *exec_domain; /* execution domain */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
int preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
void *sysenter_return;
int uaccess_err;
};
每个任务的 thread_info 结构在它的内核栈的尾端分配,其结构中 task 域中存放的是指向该任务实际 task_struct 的指针。
内核栈、 thread_info 及 task_struct 的关系如图 2 所示。

Figure 2: 内核栈、thread_info、task_struct 等
2.2. 进程描述符的存放
在内核中,访问任务通常需要获得指向其 task_struct 的指针。实际上,内核中大部分处理进程的代码都是直接通过 task_struct 进行的。因此,通过 current 宏查找到当前正在运行进程的进程描述符的速度就显得尤为重要。硬件体系结构不同,该宏的实现也不同,它必须针对专门的硬件体系结构做处理。有的硬件体系结构可以拿出一个专门寄存器来存放指向当前进程 task_struct 的指针,用于加快访问速度。而有些像 x86 这样的体系结构(其寄存器并不富余),就只能在内核栈的尾端创建 thread_info 结构,通过计算偏移间接地查找 task_struct 结构。
通过 current_thread_info() 可以找到 thread_info 的位置。在 x86 系统上,就是栈指针(保存在 ESP 寄存器中)减去 8KB(内核栈为 8KB),汇编代码如下:
movl $-8192,%eax andl %esp, %eax
通过 current_thread_info() 找到 thread_info 后,再找进程描述符就很简单了,访问其 task 域即可:
current_thread_info()->task;
对比一下这部分在 PowerPC 上的实现(IBM 基于 RISC 的现代微处理器),我们可以发现 PPC 当前的 task_struct 是保存在一个寄存器中的。也就是说,在 PPC 上, current 宏只需把 r2 寄存器中的值返回就行了。与 x86 不一样,PPC 有足够多的寄存器,所以它的实现有这样选择的余地。而访问进程描述符是一个重要的频繁操作,所以 PPC 的内核开发者觉得完全有必要为此使用一个专门的寄存器。
2.3. 进程状态
进程描述符中的 state 域描述了进程的当前状态(如图 3 所示)。系统中的每个进程都必然处于五种进程状态中的一种。该域的值也必为下列五种状态标志之一:
- TASK_RUNNING(运行):进程是可执行的;它或者正在执行,或者在运行队列中等待执行。这是进程在用户空间中执行的唯一可能的状态;这种状态也可以应用到内核空间中正在执行的进程。
- TASK_INTERRUPTIBLE(可中断):进程正在睡眠(也就是说它被阻塞),等待某些条件的达成。一旦这些条件达成,内核就会把进程状态设置为运行。处于此状态的进程也会因为接收到信号而提前被唤醒并随时准备投入运行。
- TASK_UNINTERRUPTIBLE(不可中断):除了就算是接收到信号也不会被唤醒或准备投入运行外,这个状态与可打断状态相同。这个状态通常在进程必须在等待时不受干扰或等待事件很快就会发生时出现。由于处于此状态的任务对信号不做响应,所以较之可中断状态,使用得较少。
- __TASK_TRACED:被其他进程跟踪的进程,例如通过
ptrace对程序进行跟踪。 - __TASK_STOPPED(停止):进程停止执行;进程没有投入运行也不能投入运行。通常这种状态发生在接收到 SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU 等信号的时候。此外,在调试期间接收到任何信号,都会使进程进入这种状态。
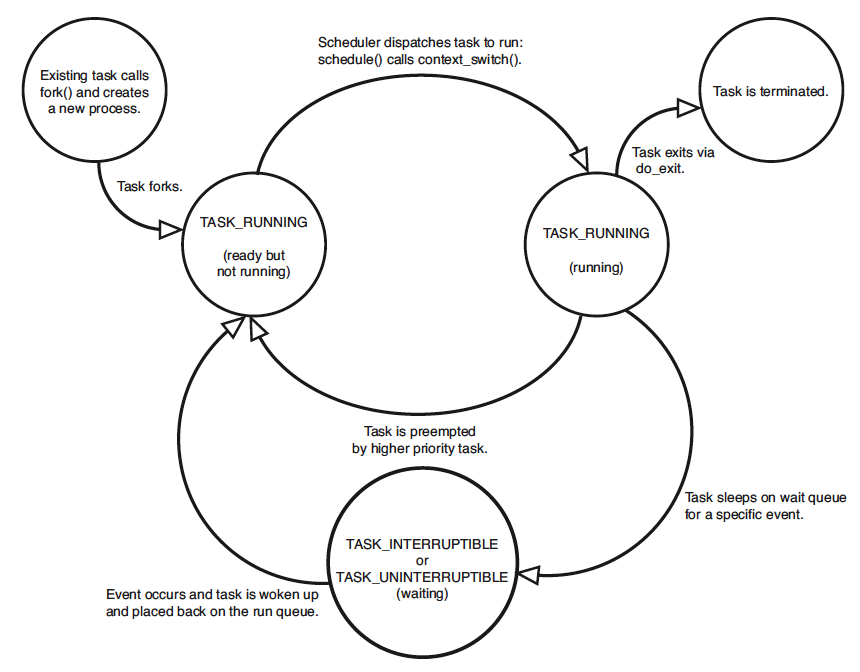
Figure 3: 进程状态转化
2.4. 设置当前进程状态
内核经常需要调整某个进程的状态。这时最好使用 set_task_state(task, state) 函数:
set_task_state(task, state); /* 将 task 的状态设置为 state */
该函数将指定的进程设置为指定的状态。必要的时候,它会设置内存屏障来强制其他处理器作重新排序(一般只有在 SMP 系统中有此必要)。否则,它等价于:
task->state = state;
set_current_state(state) 和 set_task_state(current, state) 含义是等同的。参看<linux/sched.h>中对这些相关函数实现的说明。
2.5. 进程上下文
可执行程序代码是进程的重要组成部分。这些代码从一个可执行文件载入到进程的地址空间执行。 一般程序在用户空间执行。当一个程序调执行了系统调用或者触发了某个异常,它就陷入了内核空间。此时,我们称内核“代表进程执行”并处于进程上下文中。 在此上下文中 current 宏是有效的。除非在此间隙有更高优先级的进程需要执行并由调度器做出了相应调整,否则在内核退出的时候,程序恢复在用户空间会继续执行。
系统调用和异常处理程序是对内核明确定义的接口。进程只有通过这些接口才能陷入内核执行——对内核的所有访问都必须通过这些接口。
注:除“进程上下文”(内核代表进程运行于内核空间)外,内核中还有“中断上下文”(内核代表硬件运行于内核空间)。
2.6. 进程家族树
Unix 系统的进程之间存在一个明显的继承关系,在 Linux 系统中也是如此。所有的进程都是 PID 为 1 的进程的 init 进程的后代。内核在系统启动的最后阶段启动 init 进程。该进程读取系统的初始化脚本并执行其他的相关程序,最终完成系统启动的整个过程。
系统中的每个进程必有一个父进程,相应的,每个进程也可以拥有零个或多个子进程。拥有同一个父进程的所有进程被称为兄弟。进程间的关系存放在进程描述符中。每个 task_struct 都包含一个指向其父进程 tast_struct 、叫做 parent 的指针,还包含一个称为 children 的子进程链表。
3. 进程创建
Unix 的进程创建很特别。许多其他的操作系统都提供了产生(spawn)进程的机制,首先在新的地址空间里创建进程,读入可执行文件,最后开始执行。Unix 采用了与众不同的实现方式,它把上述步骤分解到两个单独的函数中去执行: fork() 和 exec() 。首先, fork() 通过拷贝当前进程创建一个子进程。子进程与父进程的区别仅仅在于 PID(每个进程唯一)、PPID(父进程的进程号,子进程将其设置为被拷贝进程的 PID)和某些资源和统计量(例如,挂起的信号,它没有必要被继承)。 exec() 函数负责读取可执行文件并将其载入地址空间开始运行。把这两个函数组合起来使用的效果跟其他系统使用的单一函数的效果相似。
3.1. 写时拷贝
传统的 fork() 系统调用直接把所有的资源复制给新创建的进程。这种实现过于简单并且效率低下,因为它拷贝的数据也许并不共享更糟的情况是,如果新进程打算立即执行一个新的映像,那么所有的拷贝都将前功尽弃。 Linux 的 fork() 使用写时拷贝(copy-on-write)页实现。写时拷贝是一种可以推迟甚至免除拷贝数据的技术。内核此时并不复制整个进程地址空间,而是让父进程和子进程共享同一个拷贝。
只有在需要写入的时候,数据才会被复制,从而使各个进程拥有各自的拷贝。也就是说,资源的复制只有在需要写入的时候才进行在此之前,只是以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候才进行。在页根本不会被写入的情况下(举例来说, fork() 后立即调用 exec() 它们就无须复制了。
fork() 的实际开销就是复制父进程的页表以及给子进程创建唯一的进程描述符。在一般情况下,进程创建后都会马上运行一个可执行的文件,这种优化可以避免拷贝大量根本就不会被使用的数据(地址空间里常常包含数十兆的数据)。由于 Unix 强调进程快速执行的能力,所以这个优化是很重要的。
3.2. fork
Linux 通过 clone() 系统调用实现 fork() 。这个调用通过一系列的参数标志来指明父、子进程需要共享的资源。库函数 fork() 、 vfork() 和 __clone() 都根据各自需要的参数标志去调用 clone() ,然后由 clone() 去调用 do_fork() 。
dofork() 完成了创建中的大部分工作,它的定义在 kernel/fork.c 文件中。该函数调用 copy_process() 函数,然后让进程开始运行。 copy_process() 函数完成的工作很有意思:
- 调用
dup_task_struct为新进程创建一个内核栈、thread_info结构和task_struct,这些值与当前进程的值相同。此时,子进程和父进程的描述符是完全相同的。 - 检查并确保新创建这个子进程后,当前用户所拥有的进程数目没有超出给它分配的资源的限制。
- 子进程着手使自己与父进程区别开来。进程描述符内的许多成员都要被清 0 或设为初始值。那些不是继承而来的进程描述符成员主要是统计信息。
task_struct中的大多数数据都依然未被修改。 - 子进程的状态被设置为 TASK_UNINTERRUPTI,以保证它不会投入运行。
copy_process()调用copy_flags()以更新task_struct的 flags 成员。表明进程是否拥有超级用户权限的 PF_SUPERPRIV 标志被清 0。表明进程还没有调用exec()函数的 PF_FORKNOEXEC 标志被设置。- 调用
alloc_pid()为新进程分配一个有效的 PID。 - 根据传递给
clone()的参数标志,copy_process()拷贝共享打开的文件、文件系统信息信号处理函数、进程地址空间和命名空间等。在一般情况下,这些资源会被给定进程的所有线程共享;否则,这些资源对每个进程是不同的,因此被拷贝到这里。 - 最后,
copy_process()做扫尾工作并返回一个指向子进程的指针。
再回到 do_fork() 函数,如果 copy_process() 函数成功返回,新创建的子进程被唤醒并让其投入运行。内核有意选择子进程首先执行(虽然想让子进程先运行,但是并非总能如此)。因为一般子进程都会马上调用 exec 函数,这样可以避免写时拷贝的额外开销,如果父进程首先执行的话,有可能会开始向地址空间写入。
4. 线程在 Linux 中的实现
线程机制是现代编程技术中常用的一种抽象概念。该机制提供了在同一程序内共享内存地址空间运行的一组线程。这些线程还可以共享打开的文件和其他资源。线程机制支持并发程序设计技术(concurrent programming),在多处理器系统上,它也能保证真正的并行处理(parallelism)。
Linux 实现线程的机制非常独特。从内核的角度来说,它并没有线程这个概念。Linux 把所有的线程都当做进程来实现。内核并没有准备特别的调度算法或是定义特别的数据结构来表征线程。相反,线程仅仅被视为一个与其他进程共享某些资源的进程。每个线程都拥有唯一隶属于自己的 task_struct ,所以在内核中,它看起来就像是一个普通的进程(只是线程和其他一些进程共享某些资源,如地址空间)。
4.1. 创建线程
线程的创建和普通进程的创建类似,只不过在调用 clone() 的时候需要传递一些参数标志来指明需要共享的资源:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0); // 创建线程
上面的代码产生的结果和调用 fork() 差不多,只是父子俩共享地址空间、文件系统资源、文件描述符和信号处理程序。换个说法就是,新建的进程和它的父进程就是流行的所谓线程。
对比一下,一个普通的 fork() 的实现是:
clone(SIGCHLD, 0); // 创建进程
传递给 clone() 的参数标志决定了新创建进程的行为方式和父子进程之间共享的资源种类。表 1 列举了这些 clone() 用到的参数标志以及它们的作用,这些是在<linux/sched.h>中定义的。
| 参数标志 | 含义 |
|---|---|
| CLONE_FILES | 父子进程共享打开的文件 |
| CLONE_FS | 父子进程共享文件系统信息 |
| CLONE_IDLETASK | 将 PID 设置为 0(只供 idle 进程使用) |
| CLONE_NEWNS | 为子进程创建新的命名空间 |
| CLONE_PARENT | 指定子进程与父进程拥有同一个父进程 |
| CLONE_PTRACE | 继续调试子进程 |
| CLONE_SETTID | 将 TID 回写至用户空间 |
| CLONE_SETTLS | 为子进程创建新的 TLS(thread-local storage) |
| CLONE_SIGHAND | 父子进程共享信号处理函数及被阻断的信号 |
| CLONE_SYSVSEM | 父子进程共享 System V SEM_UNDO 语义 |
| CLONE_THREAD | 父子进程放入相同的线程组 |
| CLONE_VFORK | 调用 vfork(),所以父进程准备睡眠等待子进程将其唤醒 |
| CLONE_UNTRACED | 防止跟踪进程在子进程上强制执行 CLONE_PTRACE |
| CLONE_STOP | 以 TASK_STOPPED 状态开始进程 |
| CLONE_SETTLS | 为子进程创建新的 TLS |
| CLONE_CHILD_CLEARTID | 清除子进程的 TID |
| CLONE_CHILD_SETTID | 设置子进程的 TID |
| CLONE_PARENT_SETTID | 设置父进程的 TID |
| CLONE_VM | 父子进程共享地址空间 |
4.2. 内核线程
内核经常需要在后台执行一些操作。这种任务可以通过内核线程(kernel thread)完成——独立运行在内核空间的标准进程。 内核线程和普通的进程间的区别在于内核线程没有独立的地址空间(实际上指向地址空间的 mm 指针被设置为 NULL)。 它们只在内核空间运行,从来不切换到用户空间去。内核进程和普通进程一样,可以被调度,也可以被抢占。
Linux 确实会把一些任务交给内核线程去做,像 flush 和 ksoftirqd 这些任务就是明显的例子。在 Linux 系统中运行 ps -ef 命令,你可以看到内核线程,有很多!这些线程在系统启动时由另外一些内核线程创建。实际上内核线程也只能由其他内核线程创建。从现有内核线程中创建一个新的内核线程的方法如下:
struct task_struct *kthread_create(int (*threadfn)(void *data),
void *data,
const char namefmt[],
...)
新的进程将运行 threadfn 函数,给其传递的参数为 data。进程会被命名为 namefmt,namefmt 接受可变参数列表类似于 printf() 的格式化参数。新创建的进程处于不可运行状态,如果不通过调用 wake_up_process() 明确地唤醒它,它不会主动运行。创建一个进程并让它运行起来,可以通过调用 kthread_run 来达到:
struct task_struct *kthread_run(int (*threadfn)(void *data),
void *data,
const char namefmt[],
...)
这个例程是以宏实现的,只是简单地调用了 kthread_create() 和 wake_up_process() :
#define kthread_run(threadfn, data, namefmt, ...) \
({ \
struct task_struct *k; \
\
k = kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); \
if (!IS_ERR(k)) \
wake_up_process(k); \
k; \
})
内核线程启动后就一直运行直到调用 do_exit() 退出,或者内核的其他部分调用 kthread_stop() 退出,传递给 kthread_stop() 的参数为 kthread_create() 函数返回的 task_struct 结构的地址:
int kthread_stop(struct task struct *k)
5. 进程终结
虽然让人伤感,但进程终归是要终结的。当一个进程终结时,内核必须释放它所占有的资源并把这一不幸告知其父进程。
一般来说,进程的终结是自身引起的。它发生在进程调用 exit() 系统调用时,既可能显式地调用这个系统调用,也可能隐式地从某个程序的主函数返回(其实 C 语言编译器会在 main() 函数的返回点后面放置调用 exit() 的代码)。当进程接受到它既不能处理也不能忽略的信号或异常时,它还可能被动地终结。不管进程是怎么终结的,该任务大部分都要靠 do_exit() (定义于 kernel/exit.c)来完成,它要做下面这些烦琐的工作:
- 将
task_struct中的标志成员设置为 PF_EXITING。 - 调用
del_timer_sync()删除任一内核定时器。根据返回的结果,它确保没有定时器在排队,也没有定时器处理程序在运行。 - 如果 BSD 的进程记账功能是开启的,
do_exit()调用acct_update_integrals()来输出记账信息。 - 然后调用
exit_mm()函数释放进程占用的mm_struct,如果没有别的进程使用它们(也就是说,这个地址空间没有被共享),就彻底释放它们。 - 接下来调用
sem_exit()函数。如果进程排队等候 IPC 信号,它则离开队列。 - 调用
exit_files() ~和 ~exit_fs(),以分别递减文件描述符、文件系统数据的引用计数。如果其中某个引用计数的数值降为零,那么就代表没有进程在使用相应的资源,此时可以释放。 - 接着把存放在
task_struct的exit_code成员中的任务退出代码置为由exit()提供的退出代码,或者去完成任何其他由内核机制规定的退出动作。退出代码存放在这里供父进程随时检索。 - 调用
exit_notify()向父进程发送信号,给子进程重新找养父,养父为线程组中的其他线程或者为 init 进程,并把进程状态(存放在task_struct结构的exit_state中)设成 EXIT_ZOMBIE。 do_exit()调用schedule()切换到新的进程。因为处于 EXIT_ZOMBIE 状态的进程不会再被调度,所以这是进程所执行的最后一段代码。do_exit()永不返回。
至此,与进程相关联的所有资源都被释放掉了(假设该进程是这些资源的唯一使用者)。进程不可运行(实际上也没有地址空间让它运行)并处于 EXIT_ZOMBIE 退出状态。它占用的所有内存就是内核栈、 thread_info 结构和 task_struct 结构。此时进程存在的唯一目的就是向它的父进程提供信息父进程检索到信息后,或者通知内核那是无关的信息后,由进程所持有的剩余内存被释放,归还给系统使用。
5.1. 删除进程描述符
在调用了 do_exit() 之后,尽管线程已经僵死不能再运行了,但是系统还保留了它的进程描述符。前面说过,这样做可以让系统有办法在子进程终结后仍能获得它的信息。因此, 进程终结时所需的清理工作和进程描述符的删除被分开执行。 在父进程获得已终结的子进程的信息后,或者通知内核它并不关注那些信息后,子进程的 task_struct 结构才被释放。
wait() 这一族函数都是通过唯一(但是很复杂)的一个系统调用 wait4() 来实现的。它的标准动作是挂起调用它的进程,直到其中的一个子进程退出,此时函数会返回该子进程的 PID。此外,调用该函数时提供的指针会包含子函数退出时的退出代码。
当最终需要释放进程描述符时, release_task() 会被调用,用以完成以下工作:
- 它调用
__exit_signal(),该函数调用__unhash_process(),后者又调用detach_pid()从 pidhash 上删除该进程,同时也要从任务列表中删除该进程。 __exit_signal()释放目前僵死进程所使用的所有剩余资源,并进行最终统计和记录。- 如果这个进程是线程组最后一个进程,并且领头进程已经死掉,那么
release_task就要通知僵死的领头进程的父进程。 release_task()调用put_task_struct()释放进程内核栈和thread_info结构所占的页,并释放task_struct所占的 slab 高速缓存。
至此,进程描述符和所有进程独享的资源就全部释放掉了。
5.2. 孤儿进程造成的进退维谷
如果父进程在子进程之前退出,必须有机制来保证子进程能找到一个新的父亲,否则这些成为孤儿的进程就会在退出时永远处于僵死状态,白白地耗费内存。前面的部分已经有所暗示,对于这个问题,解决方法是 给子进程在当前线程组内找一个线程作为父亲,如果不行,就让 init 做它们的父进程。
一旦系统为进程成功地找到和设置了新的父进程,就不会出现驻留僵死进程的危险了。init 进程会例行调用 wait() 来检查其子进程,清除所有与其相关的僵死进程。
6. 参考
本文摘自《Linux 内核设计与实现,第 3 版》