Apache Lucene
Table of Contents
1. Lucene 简介
Lucene 是一套用于全文检索和搜索的开源库,它提供了简单却强大的应用程序接口。Lucene 不提供爬虫功能,如果需要获取内容需要自己建立爬虫应用。Lucene 只做“创建索引”和“搜索索引”工作。
什么是全文检索呢? 全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。 对于全文检索,它只处理文本、不处理语义;搜索时英文不区分大小写。
1.1. Lucene 架构
Lucene 架构如图 1 所示,对上层应用来说它提供“创建索引”和“搜索索引”的功能。
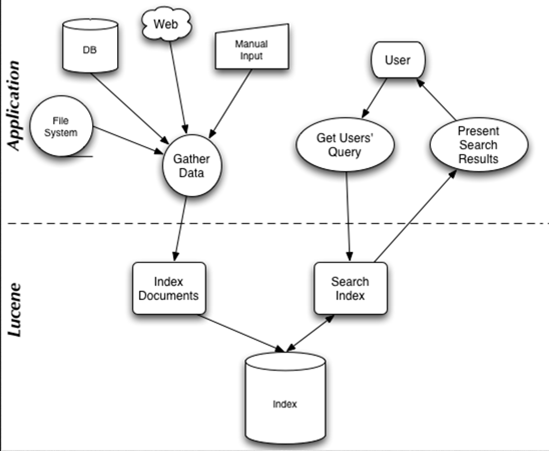
Figure 1: Lucene Real-World Application Typical Data Flow
1.2. Lucene 倒排索引原理
Lucene 采用的是一种称为 Inverted Index(“反向索引”或“倒排索引”)的机制。反向索引就是说我们维护了一个词(或短语)表,对于这个表中的每个词(或短语),都有一个链表描述了有哪些文档包含了这个词(或短语),这样在用户输入查询条件的时候,就能非常快的得到搜索结果(即出现在哪个文档中,在文件的什么位置)。
倒排索引原理如图 2 所示。
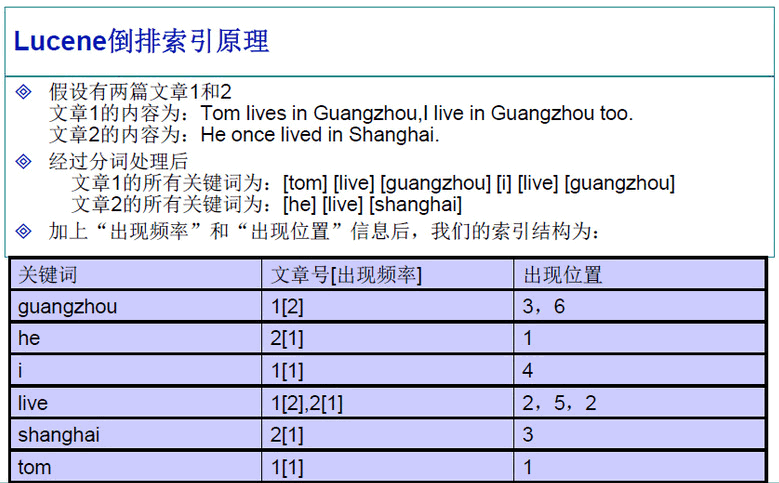
Figure 2: 倒排索引原理
1.2.1. 实例:倒排索引建立过程
下面详细介绍一下图 2 中倒排索引建立的过程。
设有两篇文章 1 和 2,文章 1 的内容为:
Tom lives in Guangzhou, I live in Guangzhou too.
文章 2 的内容为:
He once lived in Shanghai.
一、取得关键词。
由于 lucene 是基于关键词索引和查询的,首先我们要取得这两篇文章的关键词,通常我们需要如下处理措施:
a. 我们现在有的是文章内容,即一个字符串,我们先要找出字符串中的所有单词,即分词。英文单词由于用空格分隔,比较好处理。中文单词间是连在一起的需要特殊的分词处理。
b.文章中的“in”, “once” “too”等词没有什么实际意义,中文中的“的”“是”等字通常也无具体含义,这些不代表概念的词可以过滤掉。
c.用户通常希望查“He”时能把含“he”,“HE”的文章也找出来,所以所有单词需要统一大小写。
d.用户通常希望查“live”时能把含“lives”,“lived”的文章也找出来,所以需要把“lives”,“lived”还原成“live”。
e.文章中的标点符号通常不表示某种概念,也可以过滤掉。
在 lucene 中以上措施由 Analyzer 类完成。经过上面处理后,
文章 1 的所有关键词为:
[tom] [live] [guangzhou] [i] [live] [guangzhou]
文章 2 的所有关键词为:
[he] [live] [shanghai]
二、建立倒排索引。
有了关键词后,我们就可以建立倒排索引了。上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有文章号”。
文章 1,2 经过倒排后变成:
关键词 文章号 guangzhou 1 he 2 i 1 live 1,2 shanghai 2 tom 1
通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置,通常有两种位置:
a.字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
b.关键词位置,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene 中记录的就是这种位置。
加上“出现频率”和“出现位置”信息后,我们的索引结构变为:
关键词 文章号[出现频率] 出现位置
guangzhou 1[2] 3,6
he 2[1] 1
i 1[1] 4
live 1[2] 2,5,
2[1] 2
shanghai 2[1] 3
tom 1[1] 1
以 live 这行为例我们说明一下该结构:live 在文章 1 中出现了 2 次,文章 2 中出现了一次,它的出现位置为“2,5,2”这表示什么呢?我们需要结合文章号和出现频率来分析,文章 1 中出现了 2 次,那么“2,5”就表示 live 在文章 1 中出现的两个位置,文章 2 中出现了一次,剩下的“2”就表示 live 是文章 2 中第 2 个关键字。
以上就是 lucene 索引结构中最核心的部分。我们注意到关键字是按字符顺序排列的(lucene 没有使用 B 树结构),因此 lucene 可以用二元搜索算法快速定位关键词。
三、实现。
实现时,lucene 将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
Lucene 中使用了 field 的概念,用于表达信息所在位置(如标题中,文章中,url 中),在建索引中,该 field 信息也记录在词典文件中,每个关键词都有一个 field 信息(因为每个关键字一定属于一个或多个 field)。
四、压缩算法。
为了减小索引文件的大小,Lucene 对索引还使用了压缩技术。
首先,对词典文件中的关键词进行了压缩,关键词压缩为<前缀长度,后缀>,例如:当前词为“阿拉伯语”,上一个词为“阿拉伯”,那么“阿拉伯语”压缩为<3,语>。
其次大量用到的是对数字的压缩,数字只保存与上一个值的差值(这样可以减小数字的长度,进而减少保存该数字需要的字节数)。例如当前文章号是 16389(不压缩要用 3 个字节保存),上一文章号是 16382,压缩后保存 7(只用一个字节)。
摘自:http://www.cnblogs.com/fly1988happy/archive/2012/04/01/2429000.html
2. Lucene 实例
下面通过实例介绍一下 Lucene 的基本使用,请提前下载好 Lucene 软件包,使用 maven 的话加入下面依赖即可:
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>7.0.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queries</artifactId> <version>7.0.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-test-framework</artifactId> <version>7.0.0</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>7.0.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>7.0.0</version> </dependency>
2.1. 完整源码
下面是一个完整的 Lucene 使用实例代码,改编自:http://www.lucenetutorial.com/lucene-in-5-minutes.html
package HelloLucene;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.text.ParseException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.IOUtils;
public class HelloLucene {
public static void main(String[] args)
throws IOException, ParseException, org.apache.lucene.queryparser.classic.ParseException {
// 第一步,为文档建立索引。下面为3个文档建立索引
Analyzer analyzer = new StandardAnalyzer();
Path indexPath = Files.createTempDirectory("tempIndex");
Directory directory = FSDirectory.open(indexPath);
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter iwriter = new IndexWriter(directory, config);
Document doc1 = new Document();
doc1.add(new TextField("title", "Lucene in Action", Field.Store.YES)); // TextField会被tokenized
doc1.add(new StringField("isbn", "193398817", Field.Store.YES)); // StringField不会被tokenized
iwriter.addDocument(doc1);
Document doc2 = new Document();
doc2.add(new TextField("title", "Lucene for Dummies", Field.Store.YES));
doc2.add(new StringField("isbn", "55320055Z", Field.Store.YES));
iwriter.addDocument(doc2);
Document doc3 = new Document();
doc3.add(new TextField("title", "Elasticsearch in Action", Field.Store.YES));
doc3.add(new StringField("isbn", "1617291625", Field.Store.YES));
iwriter.addDocument(doc3);
iwriter.close();
// 第二步,索引关键字。下面从title中查找lucene关键字
DirectoryReader ireader = DirectoryReader.open(directory);
IndexSearcher isearcher = new IndexSearcher(ireader);
QueryParser parser = new QueryParser("title", analyzer);
Query query = parser.parse("lucene");
ScoreDoc[] hits = isearcher.search(query, 10).scoreDocs;
// 第三步,显示搜索的结果。
System.out.println("Found " + hits.length + " hits.");
for (int i = 0; i < hits.length; ++i) {
int docId = hits[i].doc;
Document d = isearcher.doc(docId);
System.out.println((i + 1) + ". " + d.get("title") + "\t" + d.get("isbn"));
}
ireader.close();
directory.close();
IOUtils.rm(indexPath);
}
}
运行上面程序,会输出:
Found 2 hits. 1. Lucene in Action 193398817 2. Lucene for Dummies 55320055Z