Performance Measures for Machine Learning
Table of Contents
1. 性能度量简介
机器学习得到模型后,如何评价其好坏呢?这就是性能度量(Performance Measures)问题。本文主要介绍分类问题的性能度量,不介绍聚类问题的性能度量。
对于分类模型的性能度量,通常用下面几种方法:
- 错误率/精度(Accuracy)
- 查准率(准确率,Precision)/查全率(召回率,Recall)
- ROC 曲线/AUC
- 代价曲线(Cost curve)
后文将会详细地介绍前面三个概念。
本文主要摘自:《机器学习,周志华,2016》,2.3,性能度量
2. 错误率与精度
错误率与精度是常用的两种性能度量方式。
错误率:分类错误的样本数占样本总数的比例。
精度(Accuracy):分类正确的样本数占样本总数的比例。显然有:“精度 = 1 - 错误率”。
3. 查准率、查全率与 F1
对于二分类问题,可将样例根据其真实类别与分别器预测类别的组合分为下表所示的四种情形:
|
真实情况 |
预测结果 | |
| 正例 | 反例 | |
| 正例 | TP (True Positive) | FN (False Negative) |
| 反例 | FP (False Positive) | TN (True Negative) |
其中,TP、FP、FN、TN 分别表示其对应的样例数,显然有“TP+FP+FN+TN=样例总数”。
“False Positive”是“误报”情况,“False Negative”是“漏报”情况。
查准率(也称“准确率”) \(P\) 与查全率(也称“召回率”) \(R\) 的定义分别为:
\[\begin{aligned} P &= \frac{TP}{TP + FP} \\
R &= \frac{TP}{TP + FN}
\end{aligned}\]
查准率和查全率都高的模型是好模型,但它们往往是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。通常只有在一些简单任务中,才可能使查准率和查全率都很高。
查准率可以认为是“宁缺毋滥”,适合对准确率要求高的应用,例如商品推荐,网页检索等。查全率可以认为是“宁错杀一百,不放过一个”,适合类似于检查走私、逃犯信息等。
“F1 度量(F1 score)”综合地考虑了查准率和查全率,它是基于查准率和查全率的调和平均(harmonic mean)定义的:
\[\frac{1}{F1} = \frac{1}{2} \cdot \left(\frac{1}{P} + \frac{1}{R} \right)\]
由上式,可推出:
\[F1 = \frac{2 \times P \times R}{P + R} = \frac{2 \times TP}{\text{样例总数} + TP - TN}\]
3.1. PR 曲线
对于模型结果是一个连续值时,类与类的边界必须用一个阈值(Threshold)来界定。举例来说,用血压值来检测一个人是否有高血压,测出的血压值是连续的实数(从 0~200 都有可能),以收缩压 140/舒张压 90 为“阈值”,阈值以上便诊断为有高血压,阈值未满者诊断为无高血压。
把“阈值”看作变量,由于每个阈值都可以求出模型的一个“查全率”和“查准率”,这样会得到很多“查全率”和“查准率”的关系数据。把它们画到一个图中,以查准率为纵轴、查全率为横轴,则称为“PR 图”。如图 1 包含了 3 个模型的 PR 图。
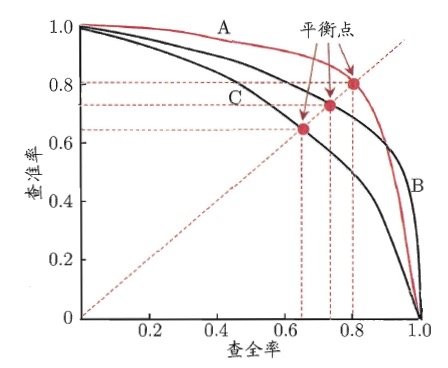
Figure 1: PR 图
如果一个模型的 PR 曲线被另一个模型的 PR 曲线完全“包住”,则可断言后者的性能优于前者,例如图 1 中的模型 A 的性能优于模型 C。
4. ROC 曲线和 AUC
ROC 是“受试者工作特征(Receiver Operating Characteristic)”的缩写。ROC 曲线首先是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军载具(飞机、船舰),也就是信号检测理论。
和 PR 使用“查准率为纵轴、查全率为横轴”不同,ROC 使用“TPR 为纵轴、FPR 为横轴”。 TPR 表示在所有实际为正例的样本中,被正确地判断为正例的比率,而 FRP 表示在所有实际为反例的样本中,被错误地判断为正例的比率。 即 TPR 和 FPR 的定义分别为:
\[\begin{aligned} TPR &= \frac{TP}{TP + FN} \\
FPR &= \frac{FP}{TN + FP}
\end{aligned}\]
假设数据集中有 100 个正例和 100 个反例,四种预测方法(可能是四种模型,或是同一模型的四种阈值设定)的结果如图 2 所示。
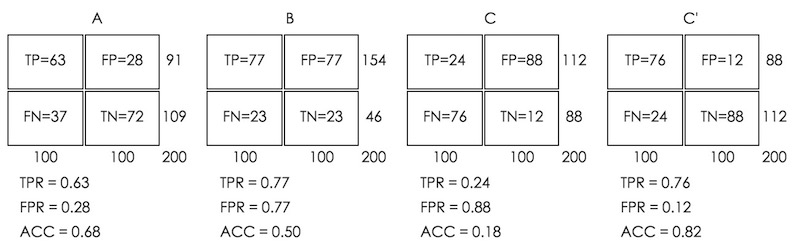
Figure 2: 四种预测方法的结果
把这四种结果画在 ROC 空间里,如图 3 所示。
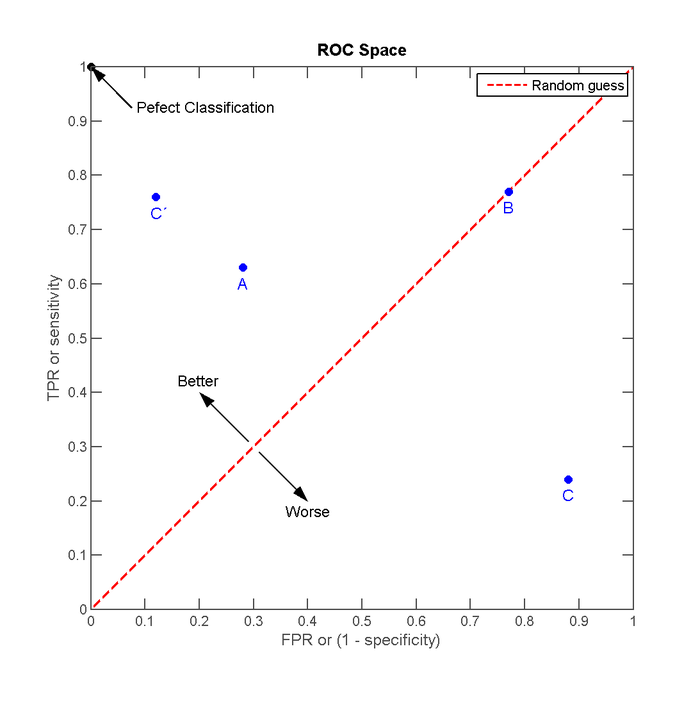
Figure 3: ROC 空间的 4 个例子
在 A、B、C 这三个方法当中,最好的结果是 A 方法,最差的是 C 方法。不过,将 C 以 \((0.5, 0.5)\) 为中点作一个镜像后即(C'方法)的结果甚至要比 A 还要好。作镜像的方法,具体来说就是:不管 C 预测了什么,就做相反的结论。
例子摘自:维基百科,ROC曲线
4.1. ROC 曲线下面积(AUC)
将同一模型每个阈值对应的 \((FPR, TPR)\) 坐标都画在 ROC 空间里,就成为特定模型的 ROC 曲线。
在比较不同的分类模型时,可以将每个模型的 ROC 曲线都画出来,比较曲线下面积(称为 AUC,Area Under ROC Curve)作为模型优劣的指标。如图 4 (摘自维基百科,ROC曲线)所示。
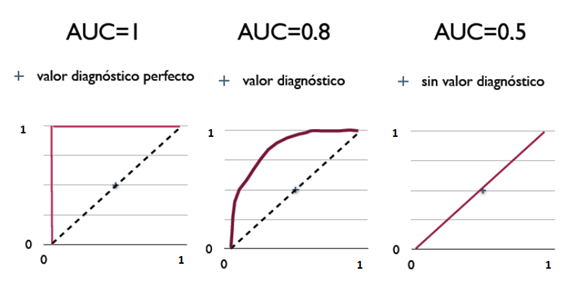
Figure 4: ROC 曲线及 AUC 值(左边模型最好,中间次之,右边最差)