MySQL
Table of Contents
- 1. MySQL 基本介绍
- 2. 基本使用
- 3. 数据库相关操作
- 4. 存储过程
- 5. The Binary Log
- 6. 复制
- 7. 性能调优
- 8. 全量备份(mysqldump)
- 9. 用户管理
- 10. Tip
1. MySQL 基本介绍
MySQL 是著名的开源关系型数据库。
参考:
MySQL 8.0 Reference Manual
MySQL Reference Manual, SQL Statement Syntax
1.1. MySQL 历史版本
MySQL 部分历史版本如表 1 所示。
| Release | General availability | Latest minor version | Latest release | End of support |
|---|---|---|---|---|
| 5.1 | 2008-11-14 | 5.1.73 | 2013-12-03 | December 2013 |
| 5.5 | 2010-12-03 | 5.5.60 | 2018-04-19 | December 2018 |
| 5.6 | 2013-02-05 | 5.6.40 | 2018-04-19 | February 2021 |
| 5.7 | 2015-10-21 | 5.7.22 | 2018-04-19 | October 2023 |
| 8.0 | 2018-04-19 | 8.0.11 | 2018-04-19 | N/A |
1.2. 安装和启动 MySQL
在 Ubuntu 中,可以用下面命令安装 MySQL:
$ sudo apt-get install mysql-server # 安装 server $ sudo apt-get install mysql-client # 安装 client
在 Ubuntu 中,使用下面命令可以管理 mysql 服务:
$ service mysql start $ service mysql status $ service mysql stop
在 Redhat 中,可以用下面命令安装 MySQL:
$ sudo yum install mariadb-server # 安装 server $ sudo yum install mysql # 安装 client
在 Redhat 中,使用下面命令可以管理 mysql 服务:
$ sudo systemctl start mariadb $ sudo systemctl status mariadb $ sudo systemctl stop mariadb
执行命令 mysql_secure_installation 可以在安装完成后设置 root 密码。
2. 基本使用
2.1. 连接 MySQL 服务器
使用客户端 mysql 可以连接 MySQL 服务器,格式如下:
$ mysql -h host_name -u user_name -ppassword [database_name] $ mysql --protocol=tcp -h host_name --port=3306 -u user_name -ppassword [database_name]
注: -ppassword 中可以省略 password 部分(会交互式地提示你输入密码),如果不省略则 -p 和 password 之间不能有空格。
2.1.1. MySQL 服务器配置文件
MySQL 服务器配置文件一般名为 my.cnf ,它的所在目录可以通过下面命令得到:
$ /usr/sbin/mysqld --help --verbose |more Default options are read from the following files in the given order: /etc/my.cnf /etc/mysql/my.cnf ~/.my.cnf
2.2. 查看在线帮助文档(help)
使用 help 可以查看相关帮助文档。
如,执行 help create table 可以查看语句 create table 的帮助文档:
mysql> help create table
Name: 'CREATE TABLE'
Description:
Syntax:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
[(create_definition,...)]
[table_options]
[partition_options]
[IGNORE | REPLACE]
[AS] query_expression
......
2.3. help 支持通配符( % 和 _ )
使用 help 查找帮助文档时,支持下面通配符:
1、 % 表示任意个(可以是零个)字符;
2、 _ 表示任意单个字符。
例如, help create% 可查找所有以 create 开头的语句:
mysql> help create% Many help items for your request exist. To make a more specific request, please type 'help <item>', where <item> is one of the following topics: CREATE DATABASE CREATE EVENT CREATE FUNCTION CREATE FUNCTION UDF CREATE INDEX CREATE PROCEDURE CREATE RESOURCE GROUP CREATE ROLE CREATE SERVER CREATE SPATIAL REFERENCE SYSTEM CREATE TABLE CREATE TABLESPACE CREATE TRIGGER CREATE USER CREATE VIEW
例如, help create ____ 可查找所有 create 后接任意 4 个字符的语句:
mysql> help create ____ Many help items for your request exist. To make a more specific request, please type 'help <item>', where <item> is one of the following topics: CREATE ROLE CREATE USER CREATE VIEW
2.4. 查看服务器基本信息
登录服务器后,使用 status 可以查看服务器基本信息。如:
mysql> status; -------------- mysql Ver 14.14 Distrib 5.7.23, for Linux (x86_64) using EditLine wrapper Connection id: 3 Current database: Current user: root@localhost SSL: Not in use Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 5.7.23-0ubuntu0.18.04.1 (Ubuntu) Protocol version: 10 Connection: Localhost via UNIX socket Server characterset: latin1 Db characterset: latin1 Client characterset: latin1 Conn. characterset: latin1 UNIX socket: /var/run/mysqld/mysqld.sock Uptime: 3 min 13 sec Threads: 1 Questions: 5 Slow queries: 0 Opens: 105 Flush tables: 1 Open tables: 98 Queries per second avg: 0.025 --------------
2.5. Server System Variables
2.5.1. 查看系统变量
查看系统变量有很多方法。
方法一、通过 show variables; 可以查看服务器所有系统变量。如:
mysql> show variables; +---------------------------------+-----------------------------------+ | Variable_name | Value | +---------------------------------+-----------------------------------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | | automatic_sp_privileges | ON | | back_log | 50 | | basedir | /home/mysql/ | | binlog_cache_size | 32768 | | bulk_insert_buffer_size | 8388608 | | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /home/mysql/share/mysql/charsets/ | | collation_connection | utf8_general_ci | | collation_database | latin1_swedish_ci | | collation_server | latin1_swedish_ci | ... | innodb_additional_mem_pool_size | 1048576 | | innodb_autoextend_increment | 8 | | innodb_buffer_pool_size | 8388608 | | innodb_checksums | ON | | innodb_commit_concurrency | 0 | | innodb_concurrency_tickets | 500 | | innodb_data_file_path | ibdata1:10M:autoextend | | innodb_data_home_dir | | ... | version | 5.5.56-log | | version_comment | Source distribution | | version_compile_machine | i686 | | version_compile_os | suse-linux | | wait_timeout | 28800 | +---------------------------------+-----------------------------------+
方法二、通过 show variables like; 可以配置指定模式的系统变量。如:
mysql> show variables like '%commit%'; -- 包含commit的系统变量 +-----------------------------------------+-------+ | Variable_name | Value | +-----------------------------------------+-------+ | autocommit | ON | | binlog_group_commit_sync_delay | 0 | | binlog_group_commit_sync_no_delay_count | 0 | | binlog_order_commits | ON | | innodb_api_bk_commit_interval | 5 | | innodb_commit_concurrency | 0 | | innodb_flush_log_at_trx_commit | 1 | | slave_preserve_commit_order | OFF | +-----------------------------------------+-------+ 8 rows in set (0.01 sec) mysql> show variables like '%commit'; -- 以commit结尾的系统变量 +--------------------------------+-------+ | Variable_name | Value | +--------------------------------+-------+ | autocommit | ON | | innodb_flush_log_at_trx_commit | 1 | +--------------------------------+-------+ 2 rows in set (0.00 sec)
方法三、通过 select @@varname; 可以查看某个系统变量的当前值。如:
mysql> select @@autocommit; +--------------+ | @@autocommit | +--------------+ | 1 | +--------------+ 1 row in set (0.00 sec) mysql> show variables like 'autocommit'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | autocommit | ON | +---------------+-------+ 1 row in set (0.01 sec)
2.5.2. 修改系统变量(set)
修改“全局系统变量”,有下面两种形式:
SET GLOBAL max_connections = 1000; SET @@GLOBAL.max_connections = 1000; // 同上
修改“session 系统变量”,有下面很多种形式:
SET SESSION sql_mode = 'TRADITIONAL'; SET LOCAL sql_mode = 'TRADITIONAL'; // 同上 SET @@SESSION.sql_mode = 'TRADITIONAL'; // 同上 SET @@LOCAL.sql_mode = 'TRADITIONAL'; // 同上 SET @@sql_mode = 'TRADITIONAL'; // 同上 SET sql_mode = 'TRADITIONAL'; // 同上
2.6. Character Set 和 Collation
Character Set 是字符集,如我们常看到的 UTF-8、GB18030 都是字符集。 而 Collation 用于指定数据集排序规则,以及字符串的比对规则。
可以在不同级别指定字符集和 Collation,如数据库级别、表级别、列级别。
使用 show character set; 可以列出 MySQL 支持的字符集;使用 show collation; 可以列出 MySQL 支持的 Collation。
Collation 名字的规则可分为两类:
<character set>_<language/other>_<ci/cs> <character set>_bin
其中,ci 是 case insensitive 的缩写,cs 是 case sensitive 的缩写。即指定大小写是否敏感。
比如,utf8_danish_ci 相对于 utf8_unicode_ci 增加了对丹麦语的特殊排序支持。
参考:https://dev.mysql.com/doc/refman/8.0/en/charset-mysql.html
3. 数据库相关操作
3.1. 列出已有数据库
执行语句 show databases; 可查看所有数据库。
mysql> show databases; +--------------------+ | Database | +--------------------+ | db1 | | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.01 sec)
3.2. 设置、查询当前数据库
执行语句 use your_db_name; 可设置当前想要使用的数据库,如:
mysql> use mytest; Database changed
执行语句 select database(); 可以查询当前所使用的数据库(如果你还有设置当前数据库,会返回 NULL )。如:
mysql> select database(); +------------+ | database() | +------------+ | mytest | +------------+ 1 row in set (0.00 sec)
3.3. 创建、删除数据库
执行语句 create database db_name; 可以创建数据库,如:
mysql> create database mytest; Query OK, 1 row affected (0.04 sec)
执行语句 drop database db_name; 可以删除数据库,如:
mysql> drop database mytest; Query OK, 0 rows affected (0.10 sec)
3.3.1. 复制整个数据库
下面操作可以把数据库 db1 复制为 db2:
shell> mysqldump db1 > dump.sql shell> mysqladmin create db2 shell> mysql db2 < dump.sql
参考:https://dev.mysql.com/doc/refman/8.0/en/mysqldump-copying-database.html
3.4. 列出当前数据库所有的表
执行语句 show tables; 可列出当前数据库所有的表。如:
mysql> use mysql; -- 设置当前数据库为mysql Database changed mysql> show tables; -- 查看当前数据库中所有的表 +---------------------------+ | Tables_in_mysql | +---------------------------+ | columns_priv | | db | | engine_cost | | event | | func | | general_log | | gtid_executed | | help_category | | help_keyword | | help_relation | | help_topic | | innodb_index_stats | | innodb_table_stats | | ndb_binlog_index | | plugin | | proc | | procs_priv | | proxies_priv | | server_cost | | servers | | slave_master_info | | slave_relay_log_info | | slave_worker_info | | slow_log | | tables_priv | | time_zone | | time_zone_leap_second | | time_zone_name | | time_zone_transition | | time_zone_transition_type | | user | +---------------------------+ 31 rows in set (0.00 sec)
3.5. 查看表的详细定义(show create table)
如果想查看某个表的定义,可以使用 show create table table_name 。如:
mysql> show create table userinfo\G
*************************** 1. row ***************************
Table: userinfo
Create Table: CREATE TABLE `userinfo` (
`name` varchar(12) DEFAULT NULL COMMENT '用户名',
`age` int(11) DEFAULT NULL COMMENT '用户年龄'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
3.6. MySQL 数据类型
MySQL 支持的数据类型可参考:https://dev.mysql.com/doc/refman/8.0/en/data-types.html
3.6.1. 二进制数据
3.6.1.1. 查看更新 BINARY(或 VARBINARY)列
BINARY 和 VARBINARY 都可以用于保存二进制数据,它们的区别在于 BINARY 是定长的,而 VARBINARY 是变长的。
BINARY 是定长的,如果插入数据不够长,会在后面补零,如:
mysql> CREATE TABLE t (c BINARY(3)); Query OK, 0 rows affected (0.08 sec) mysql> INSERT INTO t SET c = 'a'; Query OK, 1 row affected (0.03 sec) mysql> SELECT HEX(c), c = 'a', c = 'a\0\0' from t; +--------+---------+-------------+ | HEX(c) | c = 'a' | c = 'a\0\0' | +--------+---------+-------------+ | 610000 | 0 | 1 | +--------+---------+-------------+ 1 row in set (0.09 sec)
上面例子中 c 例补了两个字节的零。
使用函数 HEX 可以把二进制数据以十六进制形式显示出来。而插入(或更新)时,使用 0x 前缀可以用十六进制形式操作二进制数据。 如:
mysql> INSERT INTO t SET c = 0x62; Query OK, 1 row affected (0.11 sec) mysql> select hex(c) from t; +--------+ | hex(c) | +--------+ | 610000 | | 620000 | +--------+ 2 rows in set (0.00 sec)
3.6.2. DATETIME VS. TIMESTAMP
MySQL 中 DATETIME 和 TIMESTAMP 两者都是时间类型字段。它们的区别如下:
不同点一、TIMESTAMP 会跟随设置的时区变化而变化,而 DATETIME 保存的是什么拿出来就是什么,不受时区影响。
不同点二、DATETIME 类型的存储长度是 8 字节,而 TIMESTAMP 类型的存储长度 4 字节,这导致 TIMESTAMP 支持的范围的比 DATETIME 的要小。The range for DATETIME values is '1000-01-01 00:00:00.000000' to '9999-12-31 23:59:59.999999', and the range for TIMESTAMP values is '1970-01-01 00:00:01.000000' to '2038-01-19 03:14:07.999999'.
注 1、MySQL converts TIMESTAMP values from the current time zone to UTC for storage, and back from UTC to the current time zone for retrieval. (This does not occur for other types such as DATETIME.)
注 2:在 MySQL 5.6.5 版本之前,Automatic Initialization and Updating(更新某行数据时自动更新时间字段)只适用于 TIMESTAMP,而且一张表中,最多允许一个 TIMESTAMP 字段采用该特性。从 MySQL 5.6.5 开始,Automatic Initialization and Updating 同时适用于 TIMESTAMP 和 DATETIME,且不限制数量。
3.6.2.1. 更新数据时自动设置更新时间到某字段
下面例子中,只要表中数据有更新就会把更新时间设置到相应数据的 updated_at 字段中:
-- 字段类型为 TIMESTAMP CREATE TABLE `t1` ( `id` int unsigned AUTO_INCREMENT, `created_at` TIMESTAMP(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6), `updated_at` TIMESTAMP(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6), `deleted_at` TIMESTAMP NULL, PRIMARY KEY (`id`) ) -- 同上。只不过是字段类型为 DATETIME CREATE TABLE `t2` ( `id` int unsigned AUTO_INCREMENT, `created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, `updated_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `deleted_at` DATETIME NULL, PRIMARY KEY (`id`) )
4. 存储过程
定义存储过程可以使用下面语句:
CREATE
[DEFINER = user]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
CREATE
[DEFINER = user]
FUNCTION sp_name ([func_parameter[,...]])
RETURNS type
[characteristic ...] routine_body
参考:https://dev.mysql.com/doc/refman/8.0/en/create-procedure.html
4.1. 存储过程实例
假设订单表为 orders,其中订单号保存在字段 order_id 中,下面语句定义了名为 show_order 的存储过程,实现的功能是显示订单详情,其订单号是以指定数字结尾:
DELIMITER //
CREATE PROCEDURE show_order(order_suffix varchar(30))
BEGIN
select * from orders where order_id like CONCAT('%', order_suffix);
END//
DELIMITER ;
调用该存储过程:
mysql> call show_order("123"); -- 显示以订单号以123结尾的订单
4.2. 查看自定义函数和存储过程
使用下面命令可以查看用户自定义函数和存储过程:
select * from mysql.func; select specific_name, definer from information_schema.routines where definer not like '%mysql%';
5. The Binary Log
The binary log was introduced in MySQL 3.23.14. It contains all statements that update data. The binary log also contains some other metadata, including:
- Information about the state of the server that is needed to reproduce statements correctly
- Error codes
- Metadata needed for the maintenance of the binary llog itself (for example, rotate events)
5.1. Binary Log 的用途
The binary log has two important purposes:
- For replication, the binary log is used on master replication servers as a record of the statements to be sent to slave servers. Many details of binary log format and handling are specific to this purpose. The master server sends the events contained in its binary log to its slaves, which execute those events to make the same data changes that were made on the master. A slave stores events received from the master in its relay log until they can be executed. The relay log has the same format as the binary log.
- Certain data recovery operations require use of the binary log. After a backup file has been restored, the events in the binary log that were recorded after the backup was made are re-executed. These events bring databases up to date from the point of the backup.
当使用 MySQL 的主从模式时,必须开启 Binary Log。
5.2. Binary Log 基本操作
5.2.1. 查看 Binary Log 相关配置
使用 show variables like '%log_bin%'; 可以查看 Binary Log 是否开启:
MySQL [(none)]> show variables like '%log_bin%'; +---------------------------------+----------------------------+ | Variable_name | Value | +---------------------------------+----------------------------+ | log_bin | ON | | log_bin_basename | /rdsdbdata/db/binlog | | log_bin_index | /rdsdbdata/db/binlog.index | | log_bin_trust_function_creators | OFF | | log_bin_use_v1_row_events | OFF | | sql_log_bin | ON | +---------------------------------+----------------------------+ 6 rows in set (0.01 sec)
上面输出中,log_bin 变量对应的 Value 那列显示“ON/OFF”分别表示“开启/关闭”了 Binary Log。
5.2.2. 查看 Binary Log 文件列表
使用 show binary logs; (或者 show master logs; )可以查看系统中的 Binary Log 文件列表:
MySQL [(none)]> SHOW BINARY LOGS; +---------------+-----------+ | Log_name | File_size | +---------------+-----------+ ....... | binlog.019884 | 20315325 | | binlog.019885 | 20337827 | | binlog.019886 | 83627 | | binlog.019887 | 63267 | | binlog.019888 | 20376091 | | binlog.019889 | 20334810 | | binlog.019890 | 20381044 | | binlog.019891 | 20348220 | | binlog.019892 | 52217 | | binlog.019893 | 22295 | | binlog.019894 | 40643843 | | binlog.019895 | 142201414 | | binlog.019896 | 20324146 | | binlog.019897 | 40644610 | +---------------+-----------+ 8645 rows in set (0.02 sec)
5.2.3. 查看 Binary Log 中的内容
通过 SHOW BINLOG EVENTS 可以查看 Binary Log 中的内容,如:
mysql> SHOW BINLOG EVENTS in 'TP-bin.000105'\G;
*************************** 1. row ***************************
Log_name: TP-bin.000105
Pos: 4
Event_type: Format_desc
Server_id: 1
End_log_pos: 125
Info: Server ver: 8.0.22, Binlog ver: 4
*************************** 2. row ***************************
Log_name: TP-bin.000105
Pos: 125
Event_type: Previous_gtids
Server_id: 1
End_log_pos: 156
Info:
*************************** 3. row ***************************
Log_name: TP-bin.000105
Pos: 156
Event_type: Anonymous_Gtid
Server_id: 1
End_log_pos: 233
Info: SET @@SESSION.GTID_NEXT= 'ANONYMOUS'
*************************** 4. row ***************************
Log_name: TP-bin.000105
Pos: 233
Event_type: Query
Server_id: 1
End_log_pos: 366
Info: use `test`; DROP TABLE `employee` /* generated by server */ /* xid=8 */
*************************** 5. row ***************************
Log_name: TP-bin.000105
Pos: 366
Event_type: Anonymous_Gtid
Server_id: 1
End_log_pos: 445
Info: SET @@SESSION.GTID_NEXT= 'ANONYMOUS'
*************************** 6. row ***************************
Log_name: TP-bin.000105
Pos: 445
Event_type: Query
Server_id: 1
End_log_pos: 730
Info: use `test`; CREATE TABLE EMPLOYEE(
ID INT NOT NULL,
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT,
CONTACT INT
) /* xid=9 */
*************************** 7. row ***************************
Log_name: TP-bin.000105
Pos: 730
Event_type: Anonymous_Gtid
Server_id: 1
End_log_pos: 809
Info: SET @@SESSION.GTID_NEXT= 'ANONYMOUS'
5.2.4. 下载 Binary Log(mysqlbinlog)
使用 mysqlbinlog 可以下载 Binary Log,如:
$ mysqlbinlog \
--read-from-remote-server \
--host=primarydb.xxx.com \
--port=3306 \
--user repl \
--password \
--raw \
--verbose \
--result-file=/tmp/ \
mysql-bin-changelog.418987
上面命令是从 primarydb.xxx.com 下载 Binary Log mysql-bin-changelog.418987,保存到本地目录 /tmp 中。
使用 mysqlbinlog 可以查看 Binary Log 文件中的内容:
$ mysqlbinlog /tmp/mysql-bin-changelog.418987
5.2.5. 删除 Binary Log
在 MySQL 的主从模式中,Binary Log 会发送给“从库”来实现同步。如果不定期清理 Binary Log,会占用过多的磁盘空间。
我们可以设置日志保留天数(即变量 expire_logs_days )来达到自动删除 Binary Log 的效果。
查看当前的日志保存天数:
MySQL [(none)]> show variables like '%expire_logs_days%'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | expire_logs_days | 0 | +------------------+-------+ 1 row in set (0.01 sec)
expire_logs_days 的默认值是 0,也就是日志不过期,可通过设置全局的参数,使它临时生效:
MySQL [(none)]> set global expire_logs_days=7;
设置了只保留 7 天 BINLOG, 下次重启 mysql 这个参数默认会失败。要永远有效,需要在 my.cnf 中设置:
expire_logs_days = 7
我们也使用下面命令手动删除 Binary Log:
PURGE {MASTER | BINARY} LOGS TO 'log_name'
PURGE {MASTER | BINARY} LOGS BEFORE 'date'
比如:
PURGE BINARY LOGS TO 'mysql-bin.010'; -- 删除指定log之前的Binary Log PURGE BINARY LOGS BEFORE '2008-04-02 22:46:26'; -- 删除指定日期之前的Binary Log PURGE BINARY LOGS BEFORE DATE_SUB( NOW( ), INTERVAL 7 DAY); -- 删除7天前的Binary Log
5.3. mysqlbinlog(可用来进行增量备份)
mysqlbinlog 是 Binary Log 的分析工具,可以用来对数据库进行增量备份。
6. 复制
6.1. 主从复制
为了实现高可用,常常将 MySQL 运行在“主从复制”模式下:一个主节点,一个或者多个从节点。所有写操作只能在主节点上,而读操作则在从节点上(当然也可以从主节点读取,为分担主节点压力,往往把读操作放在从节点上,这就是所谓的“读写分离”)。
主从复制的原理是:将主节点的 binlog 日志复制到从节点上执行一遍,从而实现主从数据的一致。
主从复制的具体细节是:“从节点”开启一个 I/O 线程,向“主节点”请求 binlog 日志。“主节点”开启一个 binlog dump 线程,检查自己的 binlog 日志,并发送给“从节点”;“从节点”将接收到的数据保存到中继日志(relay log)中,另外开启一个 SQL 线程,把 relay log 中的操作在其数据库中执行一遍,从而达到主从数据库的最终一致。
主从复制的复制方式主要有:“异步复制”和“半同步复制”等等。默认采用的是“异步复制”方式,后面将介绍这些方式。
在主节点上查看从节点的列表:
MySQL [(none)]> show replicas; # 低版本 mysql 对应的命令是 show slave hosts; +------------+------+------+-----------+--------------------------------------+ | Server_Id | Host | Port | Source_Id | Replica_UUID | +------------+------+------+-----------+--------------------------------------+ | 1314176434 | | 3306 | 490423729 | 321c2923-565d-11ec-929f-069f38603aec | | 333191776 | | 3306 | 490423729 | ef75c41e-0c50-11ea-aad9-0ab1293beb5c | +------------+------+------+-----------+--------------------------------------+ 2 rows in set (0.00 sec)
在主节点上查看状态:
MySQL [(none)]> show master status; +----------------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +----------------------------+----------+--------------+------------------+-------------------+ | mysql-bin-changelog.205580 | 156 | | | | +----------------------------+----------+--------------+------------------+-------------------+
在从节点上查看状态:
MySQL [(none)]> show replica status\G # 低版本 mysql 对应的命令是show slave status\G
Replica_IO_State: Waiting for master to send event
Source_Host: 10.5.1.131
Source_User: rdsrepladmin
Source_Port: 3306
......
Seconds_Behind_Source: 0 # 从节点落后多少秒
......
参考:https://dev.mysql.com/doc/refman/8.0/en/replication-administration-status.html
6.1.1. 异步复制(Asynchronous Replication)
异步复制是 MySQL 主从复制模型下的默认工作方式。
异步复制的机制如下:主库执行完写操作后,且写入 binlog 日志后,就返回客户端。这个过程中,并不会验证从库有没有收到,所以这样可能会造成数据的不一致。换句话说,复制过程中数据是否一致,主要取决于 binlog 日志的安全性与完整性。
如果主库突然宕机,那么 binlog 可能还没有安全地传输给任何一个从库。这时,进行故障恢复(把从库升级为主库,以提供服务)后,可能会丢失之前交易对数据的改动。
6.1.2. 半同步复制(Semi-Synchronous Replication)
前面说过,采用异步复制时,主库不会去验证 binlog 有没有成功复制到从库,这有潜在的数据丢失风险。
半同步复制:一主多从模式下,有一个从库返回成功,即成功,不必等待多个从库全部返回。
MySQL5.5 中增加了半同步复制(Semi-Synchronous Replication),它是由 Google 贡献的补丁。 半同步复制的机制如下:主库在应答客户端提交的事务前需要保证“至少一个从库”接收并写到 relay log 中。 从而,能更好地保证数据的安全性和一致性。
而半同步复制,当主库每提交一个事务后,不会立即返回,而是等待其中一个从库接收到 Binlog 并成功写入 Relay-log 中才返回客户端,所以这样就保证了一个事务至少有两份日志,一份保存在主库的 Binlog,另一份保存在其中一个从库的 Relay-log 中,从而保证了数据的安全性和一致性。
需要说明的是: 在半同步复制中,如果主库的一个事务提交成功了,但在推送到从库的过程当中,从库宕机了或网络故障,导致从库并没有接收到这个事务的 binlog,此时主库会等待一段时间(这个时间由 rpl_semi_sync_master_timeout 的毫秒数决定,默认为 10000,即 10s ),如果这个时间过后还无法推送到从库,那 MySQL 会自动从半同步复制切换为异步复制,当从库恢复正常连接到主库后,主库又会自动切换回半同步复制。
要启用半同步复制,需要主库从库都安装对应插件:
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so'; mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so'; mysql> SELECT * FROM mysql.plugin; +----------------------+--------------------+ | name | dl | +----------------------+--------------------+ | rpl_semi_sync_master | semisync_master.so | | rpl_semi_sync_slave | semisync_slave.so | +----------------------+--------------------+ 2 rows in set (0.00 sec)
参考:https://dev.mysql.com/doc/refman/8.0/en/replication-semisync.html
6.1.3. 基于 GTID 的复制
MySQL 5.6.5 开始新增了一种基于 GTID (Global Transaction Identifieds) 的复制方式。GTID 可以保证每个在主库上提交的事务在集群中有一个唯一的 ID。
基于 GTID 的复制不像传统的复制方式(异步复制、半同步复制)那样复制时需要找到 binlog(MASTER_LOG_FILE)及 POS 点(MASTER_LOG_POS),GTID 复制只需要知道主库的 IP、端口、账号、密码即可。启用 GTID 复制后,MySQL 会通过内部机制自动找点同步。
下面是 GTID 的两个关键配置:
gtid_mode=ON enforce-gtid-consistency=true
启用 GTID 复制后,有些 SQL 语句是禁用的,如 CREATE TABLE xxx AS SELECT 语句(其实会被拆分为两部分,CREATE 语句和 INSERT 语句):
mysql> CREATE TABLE test2 AS SELECT * FROM test1; ERROR 1786 (HY000): Statement violates GTID consistency: CREATE TABLE ... SELECT.
参考:
https://dev.mysql.com/doc/refman/8.0/en/replication-gtids.html
https://severalnines.com/resources/tutorials/mysql-replication-high-availability-tutorial
6.1.4. 主从复制集群的部署
下面介绍一下主从复制 MySQL 集群的部署。
在开始之前,请做好下面 3 个准备工作:
准备 1、开启 Binary Log 功能。从 MySQL 8.0 开始,Binary Log 功能默认是开启的,不用额外操作。通过 SHOW VARIABLES LIKE '%log_bin%;' 可以检查目前 Binary Log 功能是否开启:
mysql> SHOW VARIABLES LIKE '%log_bin%'; +---------------------------------+----------------------------+ | Variable_name | Value | +---------------------------------+----------------------------+ | log_bin | ON | | log_bin_basename | /rdsdbdata/db/binlog | | log_bin_index | /rdsdbdata/db/binlog.index | | log_bin_trust_function_creators | OFF | | log_bin_use_v1_row_events | OFF | | sql_log_bin | ON | +---------------------------------+----------------------------+ 6 rows in set (0.01 sec)
如果 Binary Log 功能没有开启,则通过指定 --log-bin 选项启动 mysqld 可以开启 Binary Log 功能。
准备 2、确保主库和从库的 server-id 是不相同的。通过 SHOW VARIABLES LIKE 'server_id'; 可以查看当前的 server_id:
mysql> SHOW VARIABLES LIKE 'server_id'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | server_id | 1 | +---------------+-------+ 1 row in set (0.02 sec)
尽管通过 SET GLOBAL server_id = 123; 可以修改 server_id,但当 MySQL 重启后,这个修改就失效了。建议在配置文件 my.conf 中修改 server_id:
[mysqld] server-id=123
准备 3、主库上创建用于同步的用户(假设用户名为 repl),并为这个新用户进行授权:
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY 'mypassword'; mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
这个用户后面会用到。
在做完上面 3 个准备工作后。主库要进行下面操作:
mysql> FLUSH TABLES WITH READ LOCK; -- 第一步,为了数据一致,先把主库加锁,让主库处于只读状态
mysql> SHOW MASTER STATUS\G -- 第二步,查看目前 binlog 的状态
*************************** 1. row ***************************
File: binlog.000003
Position: 73
Binlog_Do_DB: test
Binlog_Ignore_DB: manual, mysql
Executed_Gtid_Set: 3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
1 row in set (0.00 sec)
$ mysqldump -u root -p --all-databases --source-data > dbdump.sql # 第三步,导出主库所有数据到 dbdump.sql 中,后面从库会从这个文件加载数据
把主库中导出的文件 dbdump.sql 复制到从库所在机器,在从库中执行 mysql -u root -p < dbdump.sql 加载 dbdump.sql 中的内容,这样从库的内容就行主库一样了。
在从库中执行 CHANGE REPLICATION SOURCE TO 让从库与主库建立连接,同时配置从哪个 binlog 的哪个位置开始复制:
mysql> CHANGE REPLICATION SOURCE TO SOURCE_HOST='primarydb.xxx.com', SOURCE_PORT=3306, SOURCE_USER='repl', SOURCE_PASSWORD='mypassword', SOURCE_LOG_FILE='binlog.000003', SOURCE_LOG_POS=73; -- 在从库中配置主库的地址,配置从哪个 binlog 的哪个位置开始复制 mysql> START REPLICA; -- 开始主从同步
上面 SOURCE_USER/SOURCE_PASSWORD 就是前面在主库中创建的用于同步的用户名和密码;SOURCE_LOG_FILE/SOURCE_LOG_POS 可以从主库中执行 SHOW MASTER STATUS\G 时的输出中找到。
在从库中执行 SHOW REPLICA STATUS\G 可以查看目前的同步状态:
mysql> SHOW REPLICA STATUS\G
*************************** 1. row ***************************
Replica_IO_State: Waiting for source to send event
Source_Host: 127.0.0.1
Source_User: repl
Source_Port: 3307
Connect_Retry: 60
Source_Log_File: binlog.000002
......
Replica_IO_Running: Yes
Replica_SQL_Running: Yes
......
如果 Slave_IO_Running 与 Slave_SQL_Running 都为 Yes,说明配置成功。
参考:https://dev.mysql.com/doc/refman/8.0/en/replication-howto.html
6.2. 多主集群(Group Replication, Galera Cluster)
MySQL Group Replication (MGR) 是 MySQL 5.7.17 中新增加的特性,可以实现任何节点都可以写入,实现了真正意义上的“多主”。
Galera Cluster 是由 Codership 开发的“多主集群”,包含在 MariaDB 中。
Galera Cluster 和 MySQL Group Replication 的对比如表 2 所示。
| 对比项 | Galera Cluster | MySQL Group Replication |
|---|---|---|
| 组通信系统(Group Communication System) | 专有组通信系统 GComm,所有节点都必须有 ACK 消息 | 基于 Paxos,只要求大多数节点有 ACK 消息 |
| 二进制日志(Binlog) | 不需要二进制日志,将二进制行事件写入 Gcache | 需要二进制日志 |
| 节点配置(Node Provisioning) | 自动全量同步(State Snapshot Transfer,SST)与增量同步(Incremental State Transfer,IST) | 没有自动全量同步,使用异步复制通道 |
| 全局事务 ID(GTID) | 使用状态 UUID 和递增序列号 | 依赖 GTID,集群上的写操作产生 GTID 事件 |
| 分区控制(Partition Handling) | 分区节点拒绝读写,自动恢复并重新加入集群 | 分区节点可读,接受写请求但将永久挂起,需要手工重新加入集群 |
| 流控(Flow Control) | 当一个节点慢到一个限制值,阻止所有节点写 | 每个节点都有所有成员的统计信息,独立决定该节点写的阈值。如果有节点慢到阈值,其它节点放慢写速度。 |
| DDL 支持 | 总序隔离(Total Order Isolation,TOI),DDL 执行期间,所有写入都将被阻止 | DDL 并不会阻塞写,仅建议在单主模式下使用(因为 DDL 并没有冲突检测) |
7. 性能调优
7.1. Explain 语句
在 select 等语句前增加 explain ,可以查看该语句是如何执行的。
假设测试数据表为:
mysql> CREATE TABLE `posts` (
-> `Id` int(11) NOT NULL AUTO_INCREMENT,
-> `AcceptedAnswerId` int(11) DEFAULT NULL,
-> `AnswerCount` int(11) DEFAULT NULL,
-> `Body` longtext NOT NULL,
-> `OwnerUserId` int(11) DEFAULT NULL,
-> `Title` varchar(250) DEFAULT NULL,
-> `ViewCount` int(11) NOT NULL,
-> PRIMARY KEY (`Id`)
-> ) ENGINE=InnoDB;
mysql> CREATE TABLE `votes` (
-> `Id` int(11) NOT NULL AUTO_INCREMENT,
-> `PostId` int(11) NOT NULL,
-> `UserId` int(11) DEFAULT NULL,
-> `BountyAmount` int(11) DEFAULT NULL,
-> `VoteTypeId` int(11) NOT NULL,
-> PRIMARY KEY (`Id`)
-> ) ENGINE=InnoDB;
下面是 EXPLAIN 某个 select 语句的例子:
mysql> EXPLAIN SELECT
-> v.UserId,
-> COUNT(*) AS FavoriteCount
-> FROM
-> votes v
-> JOIN posts p ON p.id = v.PostId
-> WHERE
-> p.OwnerUserId = 12345678
-> AND v.VoteTypeId = 5 -- (Favorites vote)
-> GROUP BY
-> v.UserId
-> ORDER BY
-> FavoriteCount DESC
-> LIMIT
-> 10;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | p | NULL | ALL | PRIMARY | NULL | NULL | NULL | 1 | 100.00 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | v | NULL | ALL | NULL | NULL | NULL | NULL | 40 | 2.50 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
如果输出的 type 列显示 ALL,则意味着这是一个“全表扫描”,当表中记录很多时,它往往是性能瓶颈。 这时,我们需要通过增加索引等方式来避免“全表扫描”。
7.1.1. EXPLAIN 输出中 type 列的说明
前面介绍了 EXPLAIN 输出中 type 列如果为 ALL 表示“全表扫描”,这列还有其他一些常见可能值,它们的含义如下:
- system :查询 MySQL 系统表,数据很少,往往不需要进行磁盘 I/O;
- const :常量连接,主键;
- eq_ref :主键索引 (primary key) 或者非空唯一索引 (unique not null) 等值扫描;
- ref :非主键非唯一索引等值扫描;
- range :范围扫描;
- index :会扫描索引上的全部数据;
- ALL :全表扫描 (full table scan)。
上面各类扫描方式,由快到慢分别为:
system > const > eq_ref > ref > range > index > ALL
参考:
https://www.tuicool.com/articles/jyMviu3
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
https://severalnines.com/blog/become-mysql-dba-blog-series-using-explain-improve-sql-queries
7.1.1.1. const, range
准备下面数据:
create table user (
id int primary key ,
name varchar(50),
index(name)
) engine=innodb;
insert into user values(1, 'john');
insert into user values(2, 'jack');
insert into user values(3, 'alice');
insert into user values(4, 'bob');
const 扫描的条件为:
1、命中主键 (primary key) 或者唯一 (unique) 索引;
2、被连接的部分是一个常量 (const) 值。
例如 select * from user where id = 1; 会是 const 扫描:
mysql> explain select * from user where id = 1; +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | user | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
在索引(可以是唯一索引,也可以是普通索引)上使用 <, >, BETWEEN, IN(), LIKE 等条件进行查询时,会是 range 扫描:
mysql> explain select * from user where id < 3; +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ | 1 | SIMPLE | user | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 2 | 100.00 | Using where | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
又如,索引上的 LIKE 是 range 扫描:
mysql> explain select * from user where name like 'j%'; +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+ | 1 | SIMPLE | user | NULL | range | name | name | 203 | NULL | 2 | 100.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+ 1 row in set, 1 warning (0.00 sec)
7.1.1.2. eq_ref(前表的每一行记录,后表只有一行记录被扫描)
准备下面数据:
create table user (
id int primary key ,
name varchar(50),
index(name)
) engine=innodb;
insert into user values(1, 'john');
insert into user values(2, 'jack');
insert into user values(3, 'alice');
insert into user values(4, 'bob');
create table user_ex (
id int primary key ,
age int
) engine=innodb;
insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
eq_ref 扫描的条件为:对于前表的每一行记录,后表只有一行记录被扫描。
再细化一点:
1、join 查询;
2、命中主键 (primary key) 或者非空唯一 (unique not null) 索引;
3、等值连接。
如 select * from user, user_ex where user.id=user_ex.id; 是 eq_ref 扫描:
mysql> explain select * from user, user_ex where user.id=user_ex.id; +----+-------------+---------+------------+--------+---------------+---------+---------+--------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+--------+---------------+---------+---------+--------------+------+----------+-------------+ | 1 | SIMPLE | user | NULL | index | PRIMARY | name | 203 | NULL | 4 | 100.00 | Using index | | 1 | SIMPLE | user_ex | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test.user.id | 1 | 100.00 | NULL | +----+-------------+---------+------------+--------+---------------+---------+---------+--------------+------+----------+-------------+ 2 rows in set, 1 warning (0.00 sec)
7.1.1.3. ref(前表的每一行记录,后表可能有多于一行记录被扫描)
准备下面数据:
create table user (
id int,
name varchar(50),
index(name, id)
) engine=innodb;
insert into user values(1, 'john');
insert into user values(2, 'jack');
insert into user values(3, 'alice');
insert into user values(4, 'bob');
create table user_ex (
id int,
age int,
index(id)
) engine=innodb;
insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
这里的数据和前一节介绍 eq_ref 时的数据只有一个不同:id 从唯一索引变为了普通索引。 这时 select * from user,user_ex where user.id=user_ex.id; 会从 eq_ref 降级为 ref 。此时对于前表的每一行记录,后表可能有多于一行记录被扫描。
ref 不一定是两个表,单表上也可能出现。
前面介绍过主键/唯一索引上的等值查询(where x=y)是 const 扫描。 普通非唯一索引上的等值查询,会由 const 降级为了 ref ,因为也可能有多于一行的数据被扫描。 如:
mysql> explain select * from user where name='alice'; +----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+ | 1 | SIMPLE | user | NULL | ref | name | name | 203 | const | 2 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
ref 扫描虽然它比 eq_ref 要慢,但它仍然是一种很快的 join 类型。
7.1.1.4. index(扫描索引上的“全部数据”)
准备下面数据:
create table user (
id int primary key ,
name varchar(50),
index(name)
) engine=innodb;
insert into user values(1, 'john');
insert into user values(2, 'jack');
insert into user values(3, 'alice');
insert into user values(4, 'bob');
index 扫描,需要扫描索引上的“全部数据”。
如 select count(*) from user; 会是 index 扫描。id 是主键, count(*) 需要通过扫描索引上的全部数据来计数。
mysql> explain select count(*) from user; +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | user | NULL | index | NULL | name | 208 | NULL | 4 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
它仅比全表扫描 ALL 快一点。
7.2. 慢查询
MySQL 可以记录下执行时间较长的查询语句,不过默认没有开启。
和慢查询相关的系统变量如表 3 所示。
| 系统变量 | 说明 |
|---|---|
| slow_query_log=0/1 | 是否开启慢查询日志 |
| slow_query_log_file=filename | 慢查询日志文件名,默认为数据文件目录(/var/lib/mysql)中的 hostname-slow.log |
| long_query_time=10 | 指定多少秒返回查询的结果为慢查询 |
| log_queries_not_using_indexes | (非常有用)记录所有没有使用到索引的查询语句,方便排查问题 |
| min_examined_row_limit | Queries that examine fewer than this number of rows are not logged to the slow query log. |
| log_slow_admin_statements | ALTER TABLE, ANALYZE TABLE, CHECK TABLE, CREATE INDEX, DROP INDEX, OPTIMIZE TABLE, and REPAIR TABLE 执行慢时也记录 |
7.2.1. “大 Offset 值”会导致查询慢
对数据进行分布查询时,我们往往会用到类似于 select * from table where c1 = xx limit 10 offset 10000 这样的语句。
一个非常常见又令人头疼的问题就是,在 offset 非常大的时候,例如 limit 20 offset 10000 这样的査询,MySQL 需要査询 10020 条记录然后只返回最后 20 条,前面 10000 条记录都将被抛弈,这样的代价非常高。 如果所有的页面被访问的频率都相同,那么这样的査询平均需要访问半个表的数据。
下面是同一个查询使用不同的 offset 所消耗的时间:
------ 可得出结论:offset 越大,执行的时间越长 select * from tb1 where score = 2 order by id limit 10 offset 10000; -- 0.02 sec select * from tb1 where score = 2 order by id limit 10 offset 100000; -- 0.23 sec select * from tb1 where score = 2 order by id limit 10 offset 200000; -- 0.71 sec select * from tb1 where score = 2 order by id limit 10 offset 300000; -- 1.29 sec select * from tb1 where score = 2 order by id limit 10 offset 400000; -- 4.66 sec select * from tb1 where score = 2 order by id limit 10 offset 500000; -- 7.47 sec select * from tb1 where score = 2 order by id limit 10 offset 600000; -- 10.02 sec
这个例子中,表 tb1 的定义如下:
CREATE TABLE tb1 ( id int NOT NULL PRIMARY KEY AUTO_INCREMENT, score int, name varchar(20), email varchar(40), hash char(32), key(score) );
从前面测试中可以发现, offset 值越大,执行的时间越长。 这个例子中,表的列比较少,如果表的列比较多(比如有几十个列),则会执行更长的时间。
为什么 offset 值越大,执行的时间越长呢?前面提到过,limit 20 offset 10000 这样的査询,MySQL 需要査询 10020 条记录然后只返回最后 20 条,前面 10000 条记录都将被抛弈,这样的代价非常高。
为什么会这样呢?这是和 MySQL 的分层结构有关系。 MySQL 存储引擎层的 Api 比较简单,只是简单地响应高层的请求,比如我们想得到某个索引下的下一条记录,调用 Api index_init 即可。但是像 limit offset 这样的“高级”功能,存储引擎层没有提供直接的支持,不是在存储引擎层实现的,而是通过对存储引擎层返回的结果进行加工来实现的(如向存储引擎层要 10020 条记录,最后丢掉前面的 10000 条记录)。
7.2.1.1. 解决办法一(想办法把 offset 变小)
从业务上,只支持“下一页”查询,这样,假设当前的查询为:
select * from tb1 where score = 2 order by id limit 10 offset 100000;
假设它返回的 id 字段的范围为 234000 到 234120。我们记下当前页查询结果中 id 的最大值 234120 ,可以把“下一页”查询,即:
select * from tb1 where score = 2 order by id limit 10 offset 100010;
改写为:
select * from tb1 where score = 2 and where id > 234120 order by id limit 10;
上面例子中增加了条件 where id > 234120 ,这样 offset 100010 就可以直接去掉了。这样,无论翻页到多么页面,其性能都会很好。
7.2.1.2. 解决办法二(先使用“索引覆盖扫描”、再“延迟关联”)
另一个优化思路是:尽可能地使用“索引覆盖扫描”,而不是査询所有的列。然后根据需要一次关联操作再返回所需的列。对于偏移量很大的时候,这样做的效率会提升非常大。
如果一个索引包含(或者说“覆盖”)所有需要查询的字段的值,我们就称之为“覆盖索引”。这种扫描称为“索引覆盖扫描”。这种情况下,由于找到了索引就直接找到了所查询字段,所以这是很快的。 比如:
select id from tb1 where score = 2 order by id limit 10 offset 10000; -- 只查询 id 列(它是主键),这是“索引覆盖扫描” select * from tb1 where score = 2 order by id limit 10 offset 10000; -- 查询所有列,这不是“索引覆盖扫描”。
如何判断查询是“索引覆盖扫描”呢? 如果 explain 输出中 Extra 列中包含“Using index”则说明这个查询属于“索引覆盖扫描”。 如:
mysql> explain select id from tb1 where score = 2 order by id limit 10 offset 600000; +----+-------------+-------+------------+------+---------------+-------+---------+-------+--------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------+---------+-------+--------+----------+--------------------------+ | 1 | SIMPLE | tb1 | NULL | ref | score | score | 5 | const | 923670 | 100.00 | Using where; Using index | +----+-------------+-------+------------+------+---------------+-------+---------+-------+--------+----------+--------------------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from tb1 where score = 2 order by id limit 10 offset 600000; +----+-------------+-------+------------+------+---------------+-------+---------+-------+--------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------+---------+-------+--------+----------+-----------------------+ | 1 | SIMPLE | tb1 | NULL | ref | score | score | 5 | const | 923670 | 100.00 | Using index condition | +----+-------------+-------+------------+------+---------------+-------+---------+-------+--------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec)
找到了满足条件的 id 后,再通过一个 inner join 即可找到所有的列。即
select * from tb1 where score = 2 order by id limit 10 offset 10000;
可以改写为:
select * from tb1 inner join (select id from tb1 where score = 2 order by id limit 10 offset 10000) as xx on xx.id = tb1.id; -- 注 on xx.id = tb1.id; 也可以用语法 using(id); 表示
前面例子,采用这种方式优化后的测试如下:
select * from tb1 inner join (select id from tb1 where score = 2 order by id limit 10 offset 10000) as xx on xx.id = tb1.id; -- 0.01 sec select * from tb1 inner join (select id from tb1 where score = 2 order by id limit 10 offset 100000) as xx on xx.id = tb1.id; -- 0.02 sec select * from tb1 inner join (select id from tb1 where score = 2 order by id limit 10 offset 200000) as xx on xx.id = tb1.id; -- 0.04 sec select * from tb1 inner join (select id from tb1 where score = 2 order by id limit 10 offset 300000) as xx on xx.id = tb1.id; -- 0.07 sec select * from tb1 inner join (select id from tb1 where score = 2 order by id limit 10 offset 400000) as xx on xx.id = tb1.id; -- 0.10 sec select * from tb1 inner join (select id from tb1 where score = 2 order by id limit 10 offset 500000) as xx on xx.id = tb1.id; -- 0.11 sec select * from tb1 inner join (select id from tb1 where score = 2 order by id limit 10 offset 600000) as xx on xx.id = tb1.id; -- 0.14 sec
可见,优化效果很明显,当 offset 为 600000 时,查询时间从优化前的 10.02 秒降低到了 0.14 秒。
先使用“索引覆盖扫描”、再“延迟关联”是一种通用的优化技巧,还可以用于其它场景。
参考:高性能 MySQL,6.7.5 节,优化 LIMIT 分页
7.3. Tips
7.3.1. where 中指定类型不一致可能导致全表扫描
假设有下面语句:
SELECT * FROM tbl_name WHERE str_col=1;
其中 str_col 是字符串类型,上面有索引。但上面查询语句拿数字和字符串比较,并不会使用索引(会全表扫描),这是因为不同的字符串,如 '1', ' 1', '1a' 等都可以转换为“数字 1”。
假设有下面测试表,表中有 5 条数据:
create table t1 (
`id` int unsigned not null auto_increment,
`c1` varchar(64) default null,
PRIMARY KEY (`id`),
KEY `idx_c1` (`c1`)
) engine=innodb default charset=utf8mb4;
insert into t1(c1) values ('1'),(' 1'),('1a'),('2'),('3');
下面测试一下 SELECT * FROM t1 WHERE c1 = 1; 和 SELECT * FROM t1 WHERE c1 = '1'; 的区别:
mysql> SELECT * FROM t1 WHERE c1 = 1; -- 全表扫描,当数据多时严重影响性能 +----+------+ | id | c1 | +----+------+ | 2 | 1 | | 1 | 1 | | 3 | 1a | +----+------+ 3 rows in set, 1 warning (0.00 sec) mysql> SELECT * FROM t1 WHERE c1 = '1'; -- 会利用索引 idx_c1 +----+------+ | id | c1 | +----+------+ | 1 | 1 | +----+------+ 1 row in set (0.00 sec)
使用 explain 可以看一下这两个语句执行时的不同,如图 1 所示。
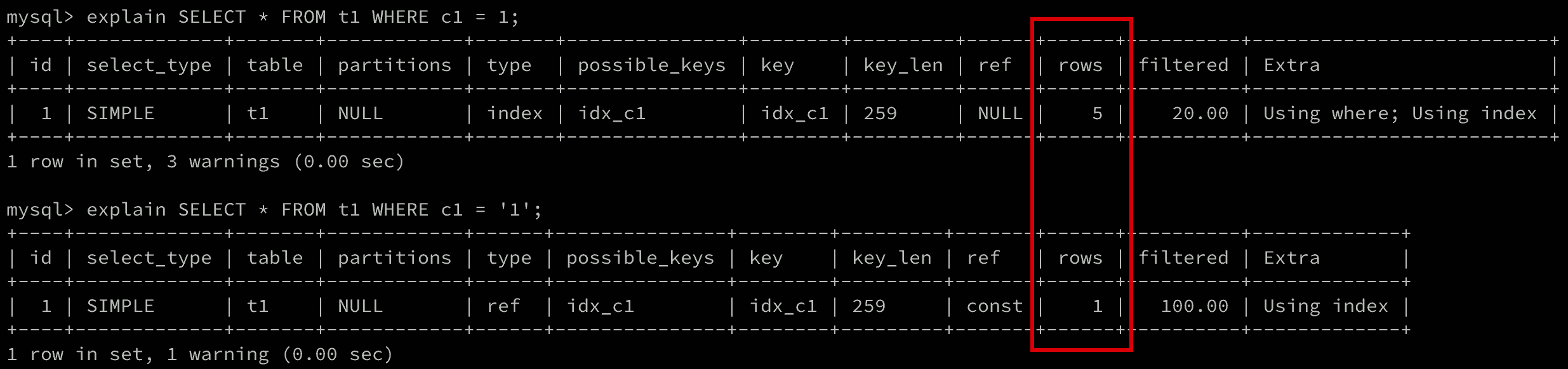
Figure 1: WHERE c1 = 1 进行全表扫描,扫描了全部 5 条记录;WHERE c1 = '1' 仅查询一条记录
参考:https://dev.mysql.com/doc/refman/8.0/en/type-conversion.html
8. 全量备份(mysqldump)
使用 mysqlbinlog 可以对数据库进行增量备份,使用 mysqldump 可以对数据库进行全量备份。mysqldump 生成是可执行的一些 sql 语句。
8.1. 备份过程
备份某个数据库:
$ mysqldump -uroot -p12345 db1 > db1.sql
备份某个数据库中的某个表:
$ mysqldump -uroot -p12345 db1 table1 > table1.sql
备份某个数据库时,排除某个表或多个表:
$ mysqldump -uroot -p12345 --ignore-table=db1.table1 --ignore-table=db1.table2 db1> db1.sql
备份所有数据库:
$ mysqldump -uroot -p12345 --all-databases > alldump.sql
备份指定的几个数据库:
$ mysqldump -uroot -p12345 --databases db1 db2 db3 > db123.sql
8.1.1. 备份脚本实例
下面是使用 mysqldump 备份 mysql 的脚本实例:
#!/bin/bash
# mysql backup script
user=your_db_username
password=your_db_password
host=your_db_host
dbname=your_dbname
bakDir=/opt/backup/mysqlbak
logFile=/opt/backup/mysqlbak.log
datetime=`date +%Y%m%d%H%M%S`
keepDay=21
echo "begin backup $datetime" >> $logFile
cd $bakDir
bakFile=$dbname.$datetime.sql.gz
# 下面是备份数据库的关键语句,备份时使用gzip压缩了sql文件,使用gunzip可以解压
mysqldump -h $host -u$user -p$password $dbname | gzip > $bakFile
echo "database [$dbname] backup finished" >> $logFile
echo "$bakDir/$bakFile" >> $logFile
echo "remove backup files before ${keepDay} days:" >> $logFile
find $bakDir -ctime +$keepDay >> $logFile
find $bakDir -ctime +$keepDay -exec rm -rf {} \;
把上面脚本配置到文件“/etc/crontab”中可实现定时备份,比如每天凌晨 4 点执行上面脚本:
0 4 * * * /opt/backup/mysqlbak.sh # 不同系统配置/etc/crontab可能不一样,有的需要在执行命令前加上用户名,如: # 0 4 * * * root /opt/backup/mysqlbak.sh
重启 crond 使配置生效:
$ sudo systemctl restart crond.service
8.2. 恢复数据库
假设通过 mysqldump 得到了 db1.sql,通过下面命令可以把它恢复到另外一个数据库(名为 db1bak,请提前创建这个数据库)中:
$ mysql -uroot -p12345 db1bak <db1.sql
或者:
mysql> use db1bak -- 切换到需要导入的库中 mysql> source /data/backup/db1.sql
9. 用户管理
9.1. 创建、授权、删除用户
使用语句 CREATE USER 可以创建新用户。
使用语句 GRANT 可以对用户进行授权。
使用语句 DROP USER 可以删除用户。
下面例子创建是用户 youruser,且可以从任何主机登录:
mysql> CREATE USER 'youruser'@'%' IDENTIFIED BY 'yourpw'; Query OK, 0 rows affected (0.00 sec) mysql> GRANT ALL ON *.* TO 'youruser'@'%'; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
9.1.1. 授权用户操作数据库
下面命令将授权用户 user1 对数据库 db1 进行任何操作:
mysql> GRANT ALL PRIVILEGES ON db1.* TO 'user1'@'%';
9.2. 查看用户的授权情况
使用命令 SHOW GRANTS [FOR user]; 可以查看用户的授权情况,如:
MariaDB [(none)]> SHOW GRANTS; +--------------------------------------------------------------------------------------------------------------------------------+ | Grants for root@% | +--------------------------------------------------------------------------------------------------------------------------------+ | GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY PASSWORD '*2470C0C06DEE42FD1618BB99005ADCA2EC9D1E19' WITH GRANT OPTION | | GRANT ALL PRIVILEGES ON `mysql`.* TO 'root'@'%' WITH GRANT OPTION | +--------------------------------------------------------------------------------------------------------------------------------+ 2 rows in set (0.00 sec)
9.3. 修改用户密码
使用 mysqladmin 可修改用户密码。如修改 root 密码:
$ mysqladmin -u root password '新密码' -p'旧密码' # 修改root用户密码,-p后面不要有空格
9.4. 列出所有用户
执行语句 select user, host from mysql.user; 可以列出所有用户。如:
mysql> select user, host from mysql.user; +------------------+-----------+ | user | host | +------------------+-----------+ | debian-sys-maint | localhost | | mysql.session | localhost | | mysql.sys | localhost | | root | localhost | +------------------+-----------+ 4 rows in set (0.00 sec)
上面的 host 列表示用户可以从哪些主机登录 MySQL 服务器。
9.5. 显示当前登录用户
执行语句 select user(); 或者 select current_user(); 可显示当前登录用户。如:
mysql> select user(); +----------------+ | user() | +----------------+ | root@localhost | +----------------+ 1 row in set (0.00 sec) mysql> select current_user(); +----------------+ | current_user() | +----------------+ | root@localhost | +----------------+ 1 row in set (0.00 sec)
9.6. 重置 root 密码
如果你忘记了 root 的密码,可以使用下面步骤重置 root 密码:
第一步,停止 mysql 服务器:
$ service mysql stop
第二步,在 MySQL 服务器配置文件中添加 skip-grant-tables 参数。此参数的作用是登录 MySQL 数据库不进行用户密码验证。
[mysqld] skip-grant-tables
注:mysql 服务器配置文件的位置因系统不同而不同,可能为“/etc/mysql/mysql.conf.d/mysqld.cnf”。
第三步,再启动 mysql 服务器:
$ service mysql start
第四步,连接 MySQL 服务器,设置 root 的新密码:
$ mysql mysql> flush privileges; -- reload the grant tables so that account-management statements work mysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'your_new_pw';
第五步,去掉 MySQL 服务器配置文件中的 skip-grant-tables 参数,再重启服务器。
注:上面方法适用于 MySQL,如果想重置 MariaDB 的 root 密码可参考:How To Reset Your MySQL or MariaDB Root Password
10. Tip
10.1. 不输出表头及表格边框(-sN)
使用 --skip-column-names, -N 可以不输出表头,使用 --silent, -s 可以不输出表格边框。
下面是指定 -sN 选项后的输出实例:
$ mysql -uroot -p1234 -sN -e 'select user, host from mysql.user;' mysql.infoschema localhost mysql.session localhost mysql.sys localhost root localhost
如果不指定 -sN ,则上面的输出为:
$ mysql -uroot -p1234 -e 'select user, host from mysql.user;' +------------------+-----------+ | user | host | +------------------+-----------+ | mysql.infoschema | localhost | | mysql.session | localhost | | mysql.sys | localhost | | root | localhost | +------------------+-----------+
10.2. 结尾指定 \G 让输出按列显式
一般地,我们使用 ; 指定语句结尾符,如:
mysql> select * from userinfo; +-------+------+ | name | age | +-------+------+ | John | 25 | | Herry | 30 | +-------+------+ 2 rows in set (0.00 sec)
如果把 ; 换为 \G ,则可以让输出按列显示,如:
mysql> select * from userinfo\G *************************** 1. row *************************** name: John age: 25 *************************** 2. row *************************** name: Herry age: 30 2 rows in set (0.00 sec)
注:当行比较少,而列很多时,使用 \G 作为结尾符会使结果的查看更方便。
10.3. 导出查询到文件
如果导出输出到文件?
方法 1:使用 mysql 的 -e 执行语句后,重定向到文件即可:
$ mysql -uuser -ppass -e "SELECT id, name FROM person WHERE name like '%smith%'" database > smiths.txt
方法 2:使用 select 语句的 INTO OUTFILE 'filename' :
$ mysql -uuser -ppass database mysql> SELECT id, name INTO OUTFILE '/tmp/smiths.txt' FROM person WHERE name like '%smith%'; Query OK, 10 rows affected (0.01 sec)
10.4. 导出 DDL 语句(mysqldump)
使用工具 mysqldump 可以导出表定义等 DDL 语句。如:
$ mysqldump -d -u <username> -p <password> -h <hostname> <dbname>
其中,参数 -d (--no-data) 表示不要 dump 表中数据。
10.5. 设置和查询事务隔离级别
下面语句可查询 MySQL 中当前的事务隔离级别:
mysql> select @@tx_isolation; -- Mysql8 has renamed tx_isolation to transaction_isolation ERROR 1193 (HY000): Unknown system variable 'tx_isolation' mysql> select @@transaction_isolation; +-------------------------+ | @@transaction_isolation | +-------------------------+ | REPEATABLE-READ | +-------------------------+ 1 row in set (0.00 sec)
使用语句 SET TRANSACTION 可修改事务隔离级别。
SET [GLOBAL | SESSION] TRANSACTION
transaction_characteristic [, transaction_characteristic] ...
transaction_characteristic: {
ISOLATION LEVEL level
| READ WRITE
| READ ONLY
}
level: {
REPEATABLE READ
| READ COMMITTED
| READ UNCOMMITTED
| SERIALIZABLE
}
在上面语句中,选择 GLOBAL,意思是此语句将应用于之后的所有 session,而当前已经存在的 session 不受影响;选择 SESSION,意思是此语句将应用于当前 session 内之后的所有事务;如果省略 GLOBAL 和 SESSION,意思是此语句将应用于当前 session 内的下一个还未开始的事务。
10.6. 查看连接情况
使用下面语句可以查看 MySQL 的连接情况:
mysql> show status where `variable_name` like 'Threads%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_cached | 10 | | Threads_connected | 3 | | Threads_created | 93058 | # 这是一共创建过多少次连接(包含历史) | Threads_running | 3 | +-------------------+-------+ 4 rows in set (0.00 sec)
10.7. 查看当前有哪些连接
使用 show processlist; 或者 show full processlist; 可以查看当前有哪些线程,如:
mysql> show processlist; +-----+------+-----------------+---------+---------+------+-------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +-----+------+-----------------+---------+---------+------+-------+------------------+ | 118 | root | localhost:52090 | db3 | Sleep | 9221 | | NULL | | 121 | root | localhost | db3 | Sleep | 2826 | | NULL | | 123 | root | localhost | db4test | Sleep | 1984 | | NULL | | 124 | root | localhost:52346 | db4test | Sleep | 54 | | NULL | | 125 | root | localhost | db4test | Sleep | 1189 | | NULL | | 127 | root | localhost:52488 | db4test | Sleep | 54 | | NULL | | 133 | root | localhost | NULL | Query | 0 | NULL | show processlist | +-----+------+-----------------+---------+---------+------+-------+------------------+ 7 rows in set (0.00 sec)
使用 kill processlist_id; 可以结束指定线程。
参考:
https://dev.mysql.com/doc/refman/8.0/en/show-processlist.html
https://dev.mysql.com/doc/refman/8.0/en/kill.html
10.8. 查看数据库占用的大小
使用下面命令可以查看 MySQL 中数据库占用的大小:
SELECT table_schema "DB Name",
ROUND(SUM(data_length + index_length) / 1024 / 1024, 1) "DB Size in MB"
FROM information_schema.tables
GROUP BY table_schema;
下面是一个例子:
mysql> SELECT table_schema "DB Name",
-> ROUND(SUM(data_length + index_length) / 1024 / 1024, 1) "DB Size in MB"
-> FROM information_schema.tables
-> GROUP BY table_schema;
+--------------------+---------------+
| DB Name | DB Size in MB |
+--------------------+---------------+
| test1 | 611.5 |
| information_schema | 0.2 |
| mysql | 2.4 |
| performance_schema | 0.0 |
| sys | 0.0 |
+--------------------+---------------+
5 rows in set (0.02 sec)
10.8.1. 查看表占用的大小
查看数据库(假设名为 db1)中每个表所占用的大小:
mysql> SELECT
table_name AS `Table`,
round(((data_length + index_length) / 1024 / 1024), 2) `Size in MB`
FROM information_schema.tables
WHERE table_schema = 'db1';
+--------+------------+
| Table | Size in MB |
+--------+------------+
| order | 32.11 |
| user | 0.06 |
+--------+------------+
2 rows in set (0.00 sec)
查看数据库(假设名为 db1)中某个表(假设名为 user)所占用的大小:
mysql> SELECT
table_name AS `Table`,
round(((data_length + index_length) / 1024 / 1024), 2) `Size in MB`
FROM information_schema.tables
WHERE table_schema = 'db1' AND table_name = "user";
+-------+------------+
| Table | Size in MB |
+-------+------------+
| user | 0.06 |
+-------+------------+
1 row in set (0.01 sec)
10.9. 使用字符集 utf8mb4(不要使用 utf8)
MySQL 在 5.5.3 之后增加了这个 utf8mb4 的编码,mb4 就是 most bytes 4 的意思,用来兼容四字节的 unicode。 MySQL 中的 utf8 编码最大字符长度为 3 字节(它不是真正的 utf8 编码),如果遇到 4 字节的宽字符就会插入异常了。当我们需要在表中插入 4 字节宽字符(比如 Emoji)时,需要使用 utf8mb4 编译,否则读出来的数据会显示不正常。
创建数据库时,可以指定字符集编码,这样在数据库中创建表时会自动使用当前数据库的字符集。如:
mysql> CREATE DATABASE your_db_name CHARACTER SET = utf8mb4; -- 指定数据库your_db_name的字符集为utf8mb4 Query OK, 1 row affected (0.07 sec)
10.9.1. 查看 MySQL 支持的字符集
执行 SHOW CHARACTER SET; 可以查看 MySQL 支持的字符集,如:
mysql> SHOW CHARACTER SET; +----------+---------------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+---------------------------------+---------------------+--------+ | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 | | binary | Binary pseudo charset | binary | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | cp866 | DOS Russian | cp866_general_ci | 1 | | cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 | | dec8 | DEC West European | dec8_swedish_ci | 1 | | eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 | | euckr | EUC-KR Korean | euckr_korean_ci | 2 | | gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 | | gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 | | gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | tis620 | TIS620 Thai | tis620_thai_ci | 1 | | ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 | | ujis | EUC-JP Japanese | ujis_japanese_ci | 3 | | utf16 | UTF-16 Unicode | utf16_general_ci | 4 | | utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 | | utf32 | UTF-32 Unicode | utf32_general_ci | 4 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 | +----------+---------------------------------+---------------------+--------+ 41 rows in set (0.01 sec)
10.10. varchar 索引列最好不要超过 191 字符
如果要在 column1 上建立索引,最好限制其长度不超过 191 字符。
create table t1 ( column1 varchar(191), ... )
MySQL 5.6(及以前版本)限制了 InnoDB 表的索引列不能超过 767 字节。当使用 utf8mb4 字符集时,对应最大的字符数就是 767/4=191;当使用 utf8 字符集时,对应最大的字符数就是 767/3=255。
10.11. decimal 字面量不要用引号
decimal 字面量不要用引号。看下面例子:
mysql> Create table t1(id int auto_increment, d decimal(40,18), PRIMARY KEY(id)); -- 创建测试用 table Query OK, 0 rows affected (0.02 sec) mysql> Insert t1 (id, d) value (1, '0.123456789012345678'); -- decimal 字面量用了单引号,直接插入时没有问题 Query OK, 1 row affected (0.01 sec) mysql> Select * from t1 where id = 1; +----+----------------------+ | id | d | +----+----------------------+ | 1 | 0.123456789012345678 | +----+----------------------+ 1 row in set (0.00 sec) mysql> Update t1 set `d`=`d` + '0.123456789012345678' where id = 1; -- decimal 字面量 0.123456789012345678 用了单引号,参与了算术(加法)运算,这会导致结果不对 Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> Select * from t1 where id = 1; +----+----------------------+ | id | d | +----+----------------------+ | 1 | 0.246913578024691350 | +----+----------------------+ 1 row in set (0.00 sec)
上面的结果的最后一位是错误的(最后一位期望是 6 但结果却是 0),正确的结果是 0.246913578024691356。
正确的做法是 decimal 字面量不用单引号,上面例子中可以使用 Update t1 set `d`=`d` + 0.123456789012345678 where id = 1; 来更新数据,这会得到正确的结果。
10.12. 查看和设置 MySQL 客户端的时区
下面语句可显示服务端/当前 session 的时区、以及查看当前时间:
MySQL [db1]> SELECT @@global.time_zone, @@session.time_zone; -- 服务端及当前 session 的时区 +--------------------+---------------------+ | @@global.time_zone | @@session.time_zone | +--------------------+---------------------+ | UTC | UTC | +--------------------+---------------------+ 1 row in set (0.00 sec) MySQL [db1]> select now(); +---------------------+ | now() | +---------------------+ | 2019-01-03 10:37:42 | +---------------------+ 1 row in set (0.00 sec)
上面输出中显示的时区为 UTC,通过指令 SET time_zone = "+08:00" 可以设置东八区时间:
MySQL [db1]> SET time_zone = "+08:00"; Query OK, 0 rows affected (0.00 sec) MySQL [db1]> SELECT @@session.time_zone; +-------------+ | @@time_zone | +-------------+ | +08:00 | +-------------+ MySQL [db1]> select now(); +---------------------+ | now() | +---------------------+ | 2019-01-03 18:37:53 | +---------------------+ 1 row in set (0.00 sec)
10.13. 查看服务器版本
使用 select version(); 可以查看 MySQL 服务器版本信息,如:
mysql> select version(); +-------------------------+ | version() | +-------------------------+ | 5.7.27-0ubuntu0.18.04.1 | +-------------------------+ 1 row in set (0.18 sec)