Network Memo
Table of Contents
1. Internet
The Internet is a global system of interconnected computer networks that use the Internet protocol suite (TCP/IP) to link several billion devices worldwide.
2. TCP/IP 简介
The Internet protocol suite is the computer networking model and set of communications protocols used on the Internet and similar computer networks. It is commonly known as TCP/IP.
2.1. TCP/IP Four-layer Model
TCP/IP 协议族分为四层:链路层、网络层、运输层和应用层,每一层各有不同的责任。如图 1 所示。

Figure 1: TCP/IP Four-layer Model
RFC 1122 covers the communications protocol layers: link layer, IP layer, and transport layer; its companion RFC 1123 covers the application and support protocols.
参考:https://en.wikipedia.org/wiki/Internet_protocol_suite#Abstraction_layers
2.2. TCP/IP vs OSI Model
TCP/IP 和 OSI Model 的对比如图 2 所示。
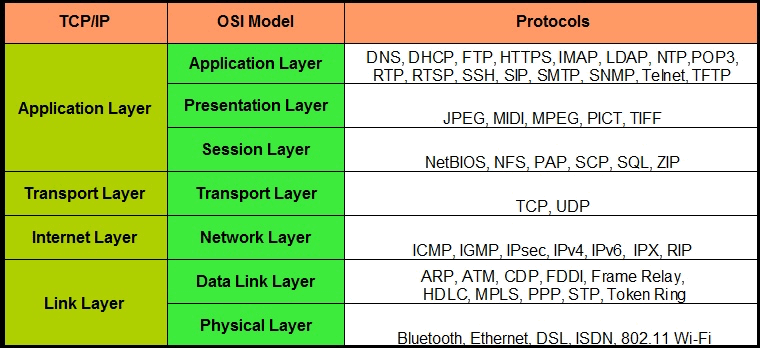
Figure 2: TCP/IP vs OSI Model
参考:https://supportforums.cisco.com/discussion/11795526/osi-and-tcpip-model
3. 链路层
链路层主要有三个目的:(1)为 IP 模块发送和接收 IP 数据报;(2)为 ARP 模块发送 ARP 请求和接收 ARP 应答;(3)为 RARP 发送请求和接收 RARP 应答。
3.1. PPP 协议
Point-to-Point Protocol (PPP) is used over many types of physical networks including serial cable, phone line, trunk line, cellular telephone, specialized radio links, and fiber optic links such as SONET.
PPP is also used over Internet access connections, Internet service providers (ISPs) have used PPP for customer dial-up access to the Internet.
3.2. Ethernet
以太网有两种帧格式:
其中, DIX Ethernet 格式的应用更加广泛(DIX 代表 DEC,Intel 和 Xerox)。 IEEE 802.2/802.3 和 DIX Ethernet 帧格式的区别如图 3 所示。
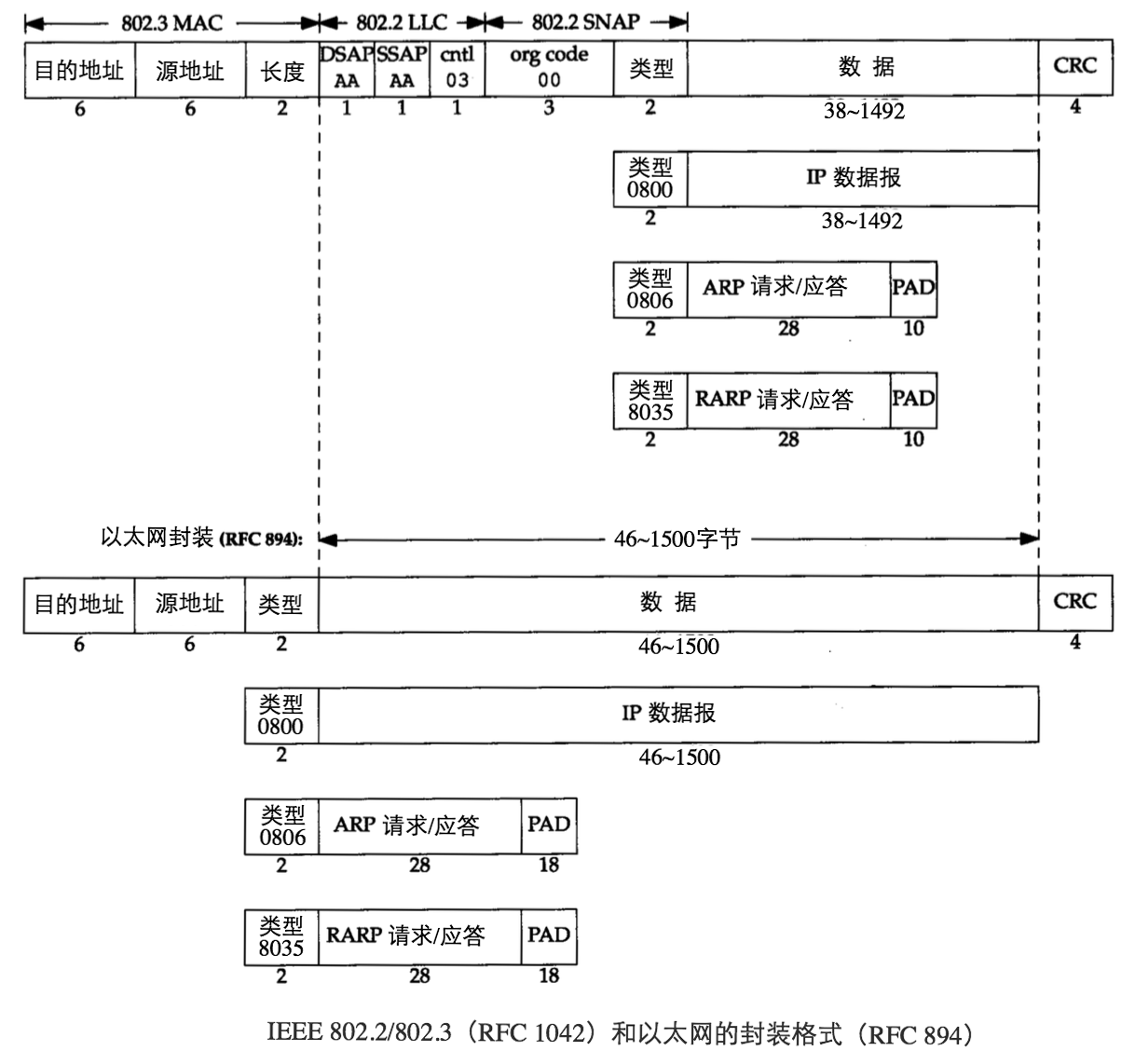
Figure 3: IEEE 802.2/802.3 和 DIX Ethernet 帧(应用更广泛)格式的区别
3.3. 最大传输单元 MTU
DIX Ethernet 和 IEEE 802.3 对数据帧和长度都有一个限制,其最大值分别为 1500 和 1492 字节。 链路层的这个特性称作 Maximum Transmission Unit (MTU)。
如果 IP 层有一个数据报要传,其数据的长度比链路层的 MTU 要大,那么 IP 层就需要进行分片(fragmentation),把数据报分成若干片,这样每一片都小于 MTU。
一些链路的 MTU 值如表 1 所示。
| Network | MTU (bytes) |
|---|---|
| Hyperchannel | 65535 |
| 16 Mbits/sec token ring (IBM) | 17914 |
| 4 Mbits/sec token ring (IEEE 802.5) | 4464 |
| FDDI | 4352 |
| DIX Ethernet | 1500 |
| IEEE 802.3/802.2 | 1492 |
| X.25 | 576 |
| Point-to-Point (low delay) | 296 |
参考:TCP/IP Illustrated Volume 1, 2.8 MTU
3.3.1. 路径 MTU
如果两台主机通信要通过多个网络,那么每个网络可能有不同的 MTU。两台通信主机路径中的最小 MTU,被称为路径 MTU。
两台主机之间的路径 MTU 不一定是个常数。它取决于当时所选择的路由。而选路不一定是对称的(从 A 到 B 的路由可能与从 B 到 A 的路由不同), 因此路径 MTU 在两个方向不一定是一致的。
参考:TCP/IP Illustrated Volume 1, 2.9 Path MTU
4. 网络层
IP 协议是网络层最重要的协议。 IP 协议提供不可靠、无连续的数据报传送服务。
不可靠(unreliable)的意思是它不保证 IP 数据报能成功地到达目的地。如果发生某种错误,如路由器暂时用完了缓冲区,IP 有一个简单的错误处理算法: 丢弃该数据报,然后发送 ICMP 消息报给信源端。
无连接(connectionless)的意思是 IP 并不维护任何关于后续数据报的状态信息,每个数据报的处理是相互独立的。这也说明,IP 数据报可以不按发送顺序接收。
4.1. IP 协议
RFC 791 对 Internet Protocol (IP)协议进行了描述。
普通的 IP 数据头(不包含选项字段)为 20 个字节。IP 数据头的格式如下:
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |Version| IHL |Type of Service| Total Length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Identification |Flags| Fragment Offset | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Time to Live | Protocol | Header Checksum | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Options | Padding | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
4.1.1. Protocol 字段
| Protocol Number | Protocol Name |
|---|---|
| 1 | ICMP (Internet Control Message Protocol) |
| 2 | IGMP (Internet Group Management Protocol) |
| 6 | TCP (Transmission Control Protocol) |
| 17 | UDP (User Datagram Protocol) |
| 41 | ENCAP (IPv6 encapsulation) |
| 89 | OSPF (Open Shortest Path First) |
| 132 | SCTP (Stream Control Transmission Protocol) |
参考:IP 数据报中协议字段值:https://en.wikipedia.org/wiki/List_of_IP_protocol_numbers
4.2. IP 地址
整个因特网就是一个单一的、抽象的网络。IP 地址就是给因特网上的每一个主机(或路由器)的每一个接口分配的一个在全世界范围唯一的“32 位标识符”。
IP 地址的编址方法共经过了三个历史阶段:
1、分类的 IP 地址。这是最基本的编址方法,在 1981 年就通过了相应的标准协议。
2、子网的划分。这是对最基本的编址方法的改进,其标准 RFC 950 在 1985 年通过。
3、无分类编址 CIDR。1993 年提出后很快就得到推广应用。
4.2.1. 编址方法:分类的 IP 地址
所谓“分类的 IP 地址”就是将 IP 地址划分为若干固定类,每一类地址都由两个固定长度的字段,其中第一个字段是“网络号”,它标志主机(或路由器)所连接到的网络,一个网络号在整个互联网范围内必须是唯一的。第二个字段是“主机号”,它标志该主机(或路由器),一个主机号在它前面的网络号所指明的网络范围内必须是唯一的。由此可见,一个 IP 地址在整个互联网范围内是唯一的。
这种两级的 IP 地址可以记为:
IP 地址 ::= {<网络号>, <主机号>}
图 4 给出了各种 IP 地址的网络号字段和主机号字段,其中 A 类、B类和 C 类地址都是单播地址(一对一通信),是最常用的;D类地址是多播地址;E类地址保留。
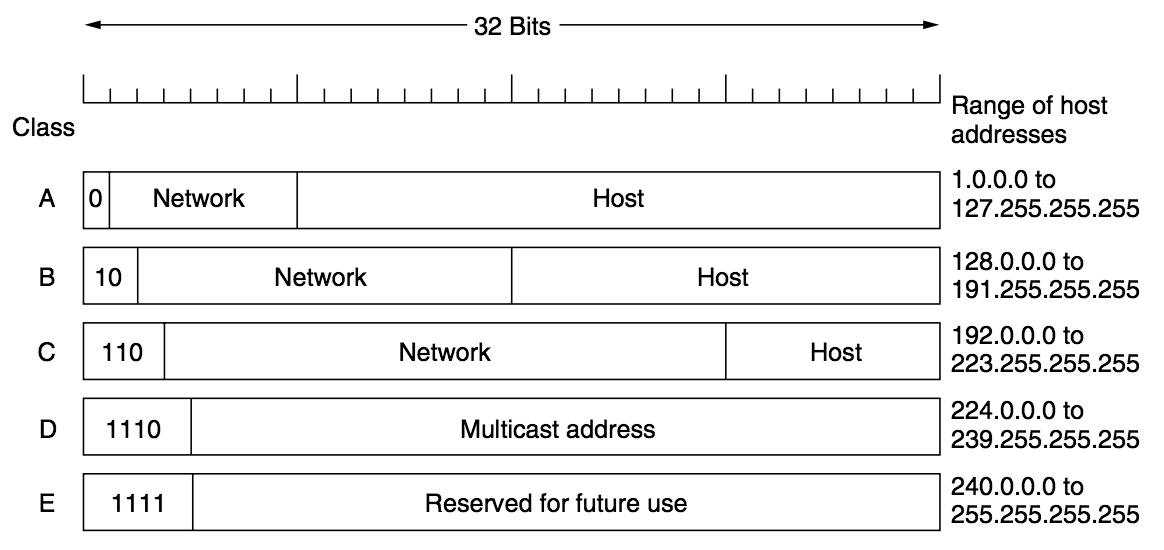
Figure 4: IP 地址中的网络号字段和主机号字段
需要说明的是, 随着无分类编址 CIDR 广泛使用,A类、B类和 C 类地址的区分已成为了历史。
4.2.1.1. 特殊的 IP 地址
表 3 列出了一般不使用的特殊 IP 地址,这些地址只能在特定的情况下使用。
| 网络号 | 主机号 | 源地址使用 | 目的地址使用 | 代表的意思 |
|---|---|---|---|---|
| 0 | 0 | 可以 | 不可以 | 在本网络上的本主机 |
| 0 | host-id | 可以 | 不可以 | 在本网络上的某台主机 host-id |
| 全 1 | 全 1 | 不可以 | 可以 | 只在本网络上进行广播(各路由器均不转发) |
| net-id | 全 1 | 不可以 | 可以 | 对 net-id 上的所有主机进行广播 |
| 127 | 非全 0 或全 1 的任何数 | 可以 | 可以 | 用于本地软件环回测试 |
4.2.2. 编址方法:子网的划分
前面介绍的“分类的 IP 地址”存在下面问题:
1、 IP 地址空间的利用率低。 每一个 A 类地址网络可连接的主机数超过 1000 万,而每一个 B 类地址网络可连接的主机数也超过 6 万。有的单位申请到了一个 B 类地址网络,但所连接的主机数并不多,可是又不愿意申请一个足够使用的 C 类地址,理由是考虑到今后可能的发展。
2、 两级 IP 地址不够灵活。 有时情况紧急,一个单位需要在新的地点马上开通一个新的网络。但是在申请到一个新的 IP 地址之前,新增加的网络是不可能连接到互联网上工作的。我们希望有一种方法,使一个单位能随时灵活地增加本单位的网络,而不必事先互联网管理机构去申请新的网络号。
为了解决上述问题,从 1985 年起在 IP 地址中又增加了一个“子网号字段”,使两级 IP 地址变成为三级 IP 地址,这种做法叫做“划分子网(subnetting)”,或“子网寻址”或“子网路由选择”。
“划分子网”的基本思路:
1、一个拥有物理网络的单位,可将所属的物理网络划分为若干个子网(subnet)。划分子网纯属一个单位内部的事情。本单位以外的网络看不见这个网络是由多少个子网组成,因为这个单位对外仍然表现为一个网络。
2、划分子网的方法是从网络的主机号借用若干位作为子网号(subnet-id),当然主机号也就相应减少了同样的位数。于是两级 IP 地址就变为三级 IP 地址:网络号、子网号和主机号。即可以记为:
IP 地址 ::= {<网络号>, <子网号>, <主机号>}
我们用“子网掩码(subnet mask)”来标记网络号和子网号。
如,在 B 类 IP 地址 145.13.3.10 中,如果从主机号中借用了 8 位作为子网号,则对应的子网掩码为 111111111111111100000000(即 255.255.255.0),如图 5 所示。
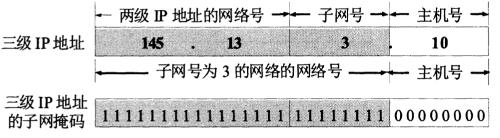
Figure 5: 子网掩码示意图
4.2.3. 编址方法:无分类编址 CIDR
随着 IP 地址分配的增加,互联网主干网上的路由表中的项目数量急剧增长(从几千个增长到了几万个)。这会使查找路由耗费更多的时间,同时路由器之间定期交换的路由信息急剧增加,使路由器和整个互联网的性能下降。
无分类域间路由选择(Classless InterDomain Routing, CIDR)编址方法可以解决上面问题。
CIDR 把 32 位的 IP 地址划分为前后两个部分,前面部分称为“网络前缀(network-prefix)”,用来指明网络,后面部分则用来指明主机。CIDR 消除了传统的 A 类、B类和 C 类地址以及划分子网的概念,使 IP 地址从三级编址又回到了两级编址。
在 CIDR 编址方法中 IP 的记法是:
IP 地址 ::= {<网络前缀>, <主机号>}
CIDR 还使用“斜线记法”(或者称为 CIDR 记法),即在 IP 地址后面加上斜线“/”,然后写上网络前缀所占的位数。比如(下划线表示网络前缀):
128.14.35.7/20 = 1000 0000 0000 1110 0010 0011 0000 0111
尽管 CIDR 中不使用子网了,但仍然可以使用术语“子网掩码”来标记“网络前缀”所占的位数。
CIDR 把网络前缀都相同的连续 IP 地址集合称为一个“CIDR 地址块”。我们只要知道 CIDR 地址块中的任何一个地址,就可以知道这个地址块的最小地址和最大地址。比如 128.14.35.7/20 是某 CIDR 地址块中的一个地址,则这个地址所在的地址块中的最小地址为:
最小地址: 128.14.32.0 = 1000 0000 0000 1110 0010 0000 0000 0000
地址块中的最大地址为:
最大地址: 128.14.47.255 = 1000 0000 0000 1110 0010 1111 1111 1111
4.2.3.1. 路由聚合
采用 CIDR 后,路由表中的一个项目可以表示原来传统分类地址的很多个(例如上千个)路由。这称为 路由聚合(Route Aggregation) 。
图 6 是 CIDR 地址块分配的例子。假定某个 ISP(Internet Service Provider)拥有地址块 206.0.64.0/18(相当于 64 个 C 类网络)。现在某大学需要 800 个 IP 地址。ISP 可以给该大学分配一个地址块 206.0.64.0/22,它包括 1024 个 IP 地址。这个大学然后可自由地对本校的各系分配地址块,而各系还可再划分本系的地址块。CIDR 的地址块分配有时不易看清,这是因为网络前缀和主机号的界限不是恰好出现在整数字节处,只要写出地址的二进制表示,弄清网络前缀的位数,就不会把地址块的范围弄错。
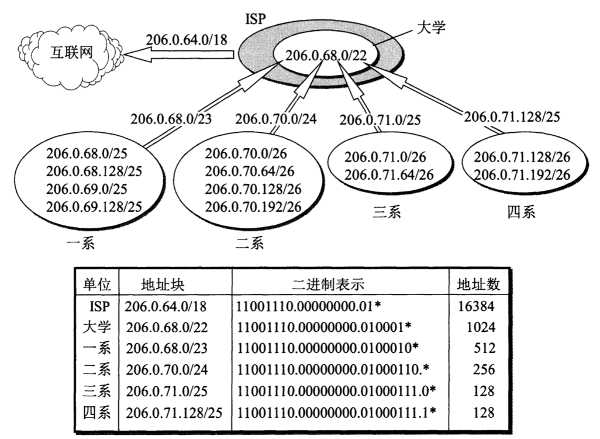
Figure 6: CIDR 地址块划分举例
通过这个例子可以了解路由聚合的概念。 这个 ISP 共拥有 64 个 C 类网络,如果不采用 CIDR 技术,则在与该 ISP 的路由器交换路由信息的每一个路由器的路由表中,就需要有 64 个项目。但采用路由聚合后,就只需要一个项目(即 206.0.64.0/18)就能找到该 ISP。 同理,这个大学共有 4 个系。在 ISP 内的路由器的路由表中,也需要使用 206.0.68.0/22 这个项目。这个项目好比是大学的收发室,凡寄给这个大学任何一个系的邮件,邮递员都不考虑各个系的地坛,而是把些邮件集中投递到大学的收发室,然后由大学的收发室再进行下一步的投递。
4.2.4. 私有 IP 地址
RFC 1918 中规定了一些私有 IP 地址空间(“Private IPv4 address spaces”),如表 4 所示。
| Private Address range | CIDR block |
|---|---|
| 10.0.0.0 – 10.255.255.255 | 10.0.0.0/8 |
| 172.16.0.0 – 172.31.255.255 | 172.16.0.0/12 |
| 192.168.0.0 – 192.168.255.255 | 192.168.0.0/16 |
这些私有地址(也称本地地址)只能用于一个机构的内部通信,而不能用于和互联网上的主机通信。换言之,私有地址只能用做本地地址而不能用作全球地址。在互联网中的所有路由器,对目的地址是私有地址的数据报一律不进行转发。
私有 IP 可以用于 NAT(Network Address Translation)等技术中。
除表 4 所示的私有地址外,169.254.0.0 到 169.254.255.255 也是私有地址,用于 Automatic Private IP Addressing (APIPA)。APIPA 是一个 DHCP 故障转移机制,当 DHCP 服务器出故障时,APIPA 在 169.254.0.1 到 169.254.255.254 的私有空间内分配地址。
4.3. IPv6
IPv6 数据报的首部格式为:
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |Version| Traffic Class | Flow Label | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Payload Length | Next Header | Hop Limit | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | + + | | + Source Address + | | + + | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | + + | | + Destination Address + | | + + | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
4.3.1. IPv6 地址
在 IPv6 中,每个地址占 128 位,在可预见的将来,其地址空间不可能用完。
和 IPv4 采用“点分十进制”记法不同,IPv6 采用“冒号十六进制记法”。如:
68E6:8C64:FFFF:FFFF:0:1180:960A:FFFF
在冒号十六进制记法中,允许把数字前面的 0 省略。上面例子中就把 0000 中的前三个 0 省略了。
冒号十六进制记法可以允许零压缩(zero compression),即一连串连续的零可以为一对冒号所取代(为避免歧义,一个地址中只能使用一次零压缩)。 如:
FF05:0:0:0:0:0:0:B3 0:0:0:0:0:0:0:1 0:0:0:0:0:0:0:0
可分别压缩为:
FF05::B3 ::1 ::
冒号十六进制记法可结合使用点分十进制记法的后缀。 例如,下面的串是一个合法的冒号十六进制记法:
0:0:0:0:0:0:128.10.2.1
再使用零压缩,上面地址也可以写为:
::128.10.2.1
4.4. NAT (Network Address Translation)
在公司内部可以使用 VPN 技术搭建自己的专用网。专用网内部的主机一般使用私有 IP(即本地 IP),当我们想和互联网上的主机通信时,应该采取什么措施呢?一种简单的办法是多申请一些全球 IP 地址分配给内部的主机,不过全球 IPv4 的地址很紧缺。目前使用的最多的方法是采用 NAT (Network Address Translation) 技术。
网络地址转换 NAT (Network Address Translation)方法是在 1994 年提出的。这种方法需要在专用网连接到互联网的路由器上安装 NAT 软件。装有 NAT 软件的路由器叫做 NAT 路由器,它至少有一个有效的外部全球 IP 地址。这样,所有使用本地地址的主机在和外界通信时,都要在 NAT 路由器上将其本地地址转换成全球 IP 地址,才能和互联网连接。
图 7 给出了 NAT 路由器的工作原理。在图中,专用网 192.168.0.0 内所有主机的 IP 地址都是本地 IP 地址 192.168.x.x。NAT 路由器至少要有一个全球 IP 地址,才能和互联网相连。NAT 路由器有一个全球 IP 地址 172.38.1.5(当然,NAT 路由器可以有多个全球 IP 地址)。
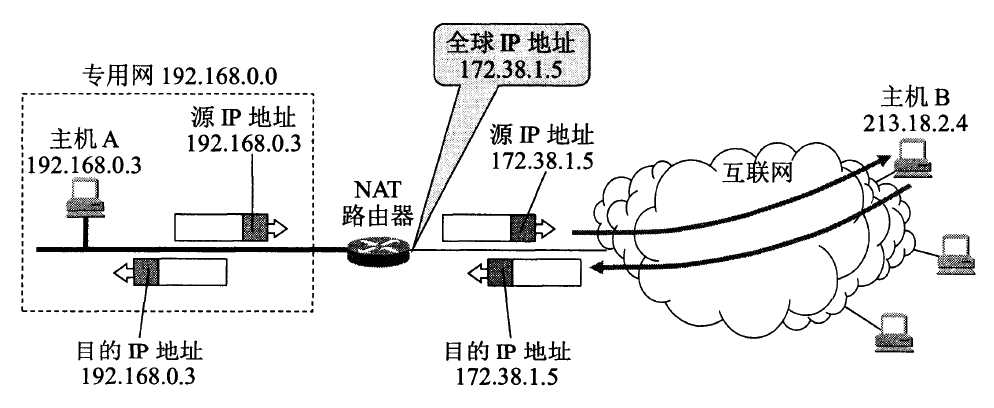
Figure 7: NAT 路由器的工作原理
NAT 路由器收到从专用网内部的主机 A 发往互联网上主机 B 的 IP 数据报:源 IP 地址是 192.168.0.3, 而目的 IP 地址是 213.18.2.4。NAT 路由器把 IP 数据报的源 IP 地址 192.168.0.3, 转换为新的源 IP 地址(即 NAT 路由器的全球 IP 地址)172.38.1.5, 然后转发出去。因此,主机 B 收到这个 IP 数据报时,以为 A 的 IP 地址是 172.38.1.5。当 B 给 A 发送应答时,IP 数据报的目的 IP 地址是 NAT 路由器的 IP 地址 172.38.1.5。B 并不知道 A 的专用地址 192.168.0.3。实际上,即使知道了,也不能使用,因为互联网上的路由器都不转发目的地址是专用网本地 IP 地址的 IP 数据报。当 NAT 路由器收到互联网上的主机 B 发来的 IP 数据报时,还要进行一次 IP 地址的转换。通过 NAT 地址转换表,就可把 IP 数据报上的旧的目的 IP 地址 172.38.1.5, 转换为新的目的 IP 地址 192.168.0.3(主机 A 真正的本地 IP 地址)。表 5 给出了 NAT 地址转换表的举例。表中的前两行数据对应于图 7 中所举的例子。第一列“方向”中的“出”表示离开专用网,而“入”表示进入专用网。表中后两行数据(图 7 中没有画出对应的 IP 数据报)表示专用网内的另一主机 192.168.0.7 向互联网发送了 IP 数据报,而 NAT 路由器还有另外一个全球 IP 地址 172.38.1.6。
| 方向 | 字段 | 旧的 IP 地址 | 新的 IP 地址 |
|---|---|---|---|
| 出 | 源 IP 地址 | 192.168.0.3 | 172.38.1.5 |
| 入 | 目的 IP 地址 | 172.38.1.5 | 192.168.0.3 |
| 出 | 源 IP 地址 | 192.168.0.7 | 172.38.1.16 |
| 入 | 目的 IP 地址 | 172.38.1.6 | 192.168.0.7 |
由此可见,当 NAT 路由器具有 n 个全球 IP 地址时,专用网内最多可以同时有 n 台主机接入到互联网。这样就可以使专用网内较多数量的主机,轮流使用 NAT 路由器有限数量的全球 IP 地址。
显然, 通过 NAT 路由器的通信必须由专用网内的主机发起。 设想互联网上的主机要发起通信,当 IP 数据报到达 NAT 路由器时,NAT 路由器就不知道应当把目的 IP 地址转换成专用网内的哪一个本地 IP 地址。这就表明,这种专用网内部的主机不能充当服务器用,因为互联网上的客户无法请求专用网内的服务器提供服务。
为了更加有效地利用 NAT 路由器上的全球 IP 地址,现在常用的 NAT 转换表把运输层的端口号也利用上。这样,就可以使多个拥有本地地址的主机,共用一个 NAT 路由器上的全球 IP 地址,因而可以同时和互联网上的不同主机进行通信。
使用端口号的 NAT 也叫做网络地址与端口号转换 NAPT (Network Address and Port Translation),而不使用端口号的 NAT 就叫做传统的 NAT (traditional NAT)。但在许多文献中并没有这样区分,而是不加区分地都使用 NAT 这个更加简洁的缩写词。表 6 说明了 NAPT 的地址转换机制。
| 方向 | 字段 | 目的 IP 地址和端口号 | 新的 IP 地址和端口号 |
|---|---|---|---|
| 出 | 源 IP 地址:TCP 源端口 | 192.168.0.3:30000 | 172.38.1.5:40001 |
| 出 | 源 IP 地址:TCP 源端口 | 192.168.0.4:30000 | 172.38.1.5:40002 |
| 入 | 目的 IP 地址:TCP 目的端口 | 172.38.1.5:40001 | 192.168.0.3:30000 |
| 入 | 目的 IP 地址:TCP 目的端口 | 172.38.1.5:40002 | 192.168.0.4:30000 |
当 NAPT 路由器收到从互联网发来的应答时,就可以从 IP 数据报的数据部分找出运输层的端口号,然后根据不同的目的端口号,从 NAPT 转换表中找到正确的目的主机。
应当指出,从层次的角度看,NAPT 的机制有些特殊。普通路由器在转发 IP 数据报时,对于源 IP 地址或目的 IP 地址都是不改变的。但 NAT 路由器在转发 IP 数据报时,一定要更换其 IP 地址(转换源 IP 地址或目的 IP 地址)。其次,普通路由器在转发分组时,是工作在网络层。但 NAPT 路由器还要査看和转换运输层的端口号,而这本来应当属于运输层的范畴。也正因为这样,NAPT 曾遭受了一些人的批评,认为 NAPT 的操作没有严格按照层次的关系。但不管怎样,NAT(包括 NAPT)已成为互联网的一个重要构件。
4.4.1. NAT 穿透
前面介绍过,专用网内部的主机不能充当服务器(不能接收某客户端的请求),这是因为专用网内部的主机并没有公网 IP 地址,公网 IP 地址仅在 NAT 路由器上才有。
4.4.1.1. STUN
前面介绍过,当专用网内部的主机(如 192.168.0.1)向公网中服务器(如 50.76.44.114)请求数据时,NAT 路由器会根据地址转换表,把数据包的源地址设置为公网的 IP 和端口,如图 8(摘自:https://hpbn.co/building-blocks-of-udp/ )中的 50.76.44.114:31454 就是公网的 IP 和端口。

Figure 8: IP Network Address Translator
在大部分情况下,其它节点发往 50.76.44.114:31454 的数据也会被 NAT 路由器转发到内部主机 192.168.0.1 的端口 1337 上。 不过,内部主机自己并不知道它在 NAT 路由器上的公网地址是多少,即这个例子中的 50.76.44.114:31454。
不过,内部主机连接公网服务器时,公网服务器是知道内部主机在 NAT 路由器上的公网地址的。STUN 内网穿透的基本原理就是在公网上部署一个 STUN 服务器,这样内部主机可以向 STUN 服务器查询自己在 NAT 路由器上的公网地址,如图 9(摘自:https://hpbn.co/building-blocks-of-udp/ )所示。

Figure 9: STUN query for public IP and port
4.4.1.2. TURN
网络环境很复杂,前面介绍的 STUN 方案并不总是可用。比如,网络提供商配置了防火墙禁止 UDP,禁止外部的连接请求,这都会导致 STUN 不可用。
当 STUN 不可用时,可使用 TURN(Traversal Using Relays around NAT, RFC5766)作为最后的备选保障。TURN 采用的是“中继”思路,由另外一个外网的服务器来中转数据。TURN 如图 10(摘自:https://hpbn.co/building-blocks-of-udp/ )所示。

Figure 10: TURN relay server
5. 运输层 UDP 协议
TCP 协议和 UDP 协议是运输层中重要的两个协议。
User Datagram Protocol (UDP) 是一个简单的面向数据报的运输层协议。UDP 不提供可靠性,它把应用程序传给 IP 层的数据发送出去,但是并不保证它们能到达目的地。RFC 768 是 UDP 的正式规范。
5.1. UDP 首部格式
UDP 的首部为固定的 8 字节。
0 7 8 15 16 23 24 31 +--------+--------+--------+--------+ | Source | Destination | | Port | Port | +--------+--------+--------+--------+ | | | | Length | Checksum | +--------+--------+--------+--------+ | | data octets ... +---------------- ...
由于 IP 层已经把 IP 数据报分配给 TCP 或 UDP(根据 IP 首部协议字段值),因此 TCP 端口号由 TCP 来查看,而 UDP 端口号由 UDP 来查看。 TCP 端口号和 UDP 端口号是相互独立的。
6. 运输层 TCP 协议
Transmission Control Protocol (TCP) 是运输层最重要的协议。RFC 793 对 TCP 协议进行了描述。
TCP 提供一种面向连接的、可靠的字节流服务。 :
1、“面向连接”意味着两个使用 TCP 的应用在彼此交换数据之前必须先建立一个 TCP 连接。
2、TCP 有很多手段来提供“可靠性”:如检验和确保数据传输过程中无变化,选择确认机制,超时重传等等。
3、TCP 的“字节流”服务是指:两个应用程序通过 TCP 连接交换 8 bit 字节构成的字节流(而不是比特流)。TCP 不在字节流中插入记录标识符,如果一方的应用程序先传 10 字节,又传 20 字节,再传 50 字节,连接的另一方将无法了解发送方每次发送了多少字节。收方可能每次接收 20 字节,分 4 次接收这 80 个字节。此外,TCP 对字节流的内容不作任何解释,TCP 不知道传送的字节流是 ASCII 字符、EBCDIC 字符还是二进制数据。
6.1. TCP Header Format
TCP 报文头如下所示:
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Port | Destination Port | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Sequence Number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Acknowledgment Number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Data | |U|A|P|R|S|F| | | Offset| Reserved |R|C|S|S|Y|I| Window | | | |G|K|H|T|N|N| | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Checksum | Urgent Pointer | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Options | Padding | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | data | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
TCP 报头中标志位的说明如表 7 所示。
| TCP 头中标志位 | 说明 |
|---|---|
| URG | 紧急指针( urgent pointer)有效。 |
| ACK | 确认序号有效。 |
| PSH | 接收方应该尽快将这个报文段交给应用层。 |
| RST | 重建连接。 |
| SYN | 同步序号用来发起一个连接。 |
| FIN | 发端完成发送任务。 |
6.2. TCP 连接的建立(三次握手)
TCP 用如下方式建立一个连接:
- 请求端(通常称为客户)发送一个 SYN 报文段指明打算连接的服务器的端口,以及初始序号(ISN)。这是报文段 1。
- 服务器发回包含服务器的初始序号的 SYN 报文段(报文段 2)作为应答。同时,将确认序号设置为客户的 ISN 加 1 以对客户的 SYN 报文段进行确认。一个 SYN 将消耗一个序号。
- 客户必然将确认序号设置为服务器的 ISN 加 1 以对服务器的 SYN 报文段进行确认(报文段 3)。
上面过程称为“三次握手”, 如图 11 所示。
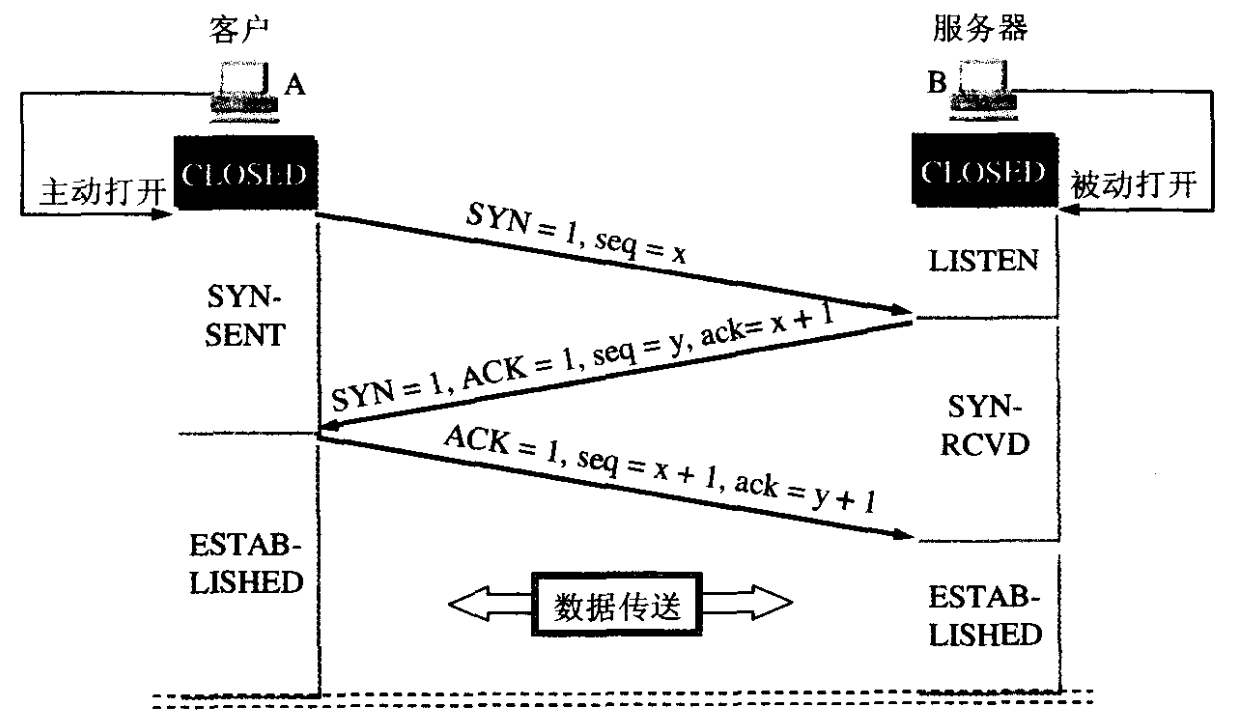
Figure 11: TCP 用三次握手建立连接
6.2.1. 为什么要三次握手(两次握手不行?)
为什么要三次握手?两次握手不行?这主要是为了防止“已失效的连接请求报文段”突然又传送到了 B,因而产生错误。
所谓的“已失效的连接请求报文段”是这样产生的。考虑一种正常情况:A 发出连接请求,但因为连接请求报文丢失而未收到确认。于是 A 再重新发送一次连接请求。后来收到了确认,建立了连接。数据传输完毕后,就释放了连接。A 一共发送了两个连接请求报文段,其中第一个丢失,第二个到达了 B。没有“已失效的连接请求报文段”。
现在假定出现一种异常情况,即 A 发出的第一个连接请求报文段并没丢失,而是在某个网络结点长时间滞留了,以致延误到连接释放以后的某个时间才达到 B。本来这是一个早已失效的报文段,但 B 收到此失效报文段后,就误认为 A 又发出一次新的连接请求。于是就向 A 发出确认报文段,同意建立连接。假定不采用三次握手,那么只要 B 发出确认,B 就进入连接建立状态。由于 A 并没有发出连接请求,因此,会忽略 B 的连接确认报文段,也不会向 B 发送数据,但是 B 却一直处于连接建立状态,一直在等待 A 发送数据,这样导致 B 的资源被白白浪费。
采用三次握手可以防止上述现象的发生,例如在上述情况下,由于 A 并没有发出连接请求,因此,并不会发出确认信号,而 B 没有收到确认报文段,也就不会进入连接建立状态,这样就能避免 A 没有进入连接建立状态,而 B 处于连接建立状态的情况。
6.2.2. 同时打开(Simultaneous Open)
TCP 支持同时打开(Simultaneous Open),对于同时打开它仅建立一条连接而不是两条连接。如图 12 所示。
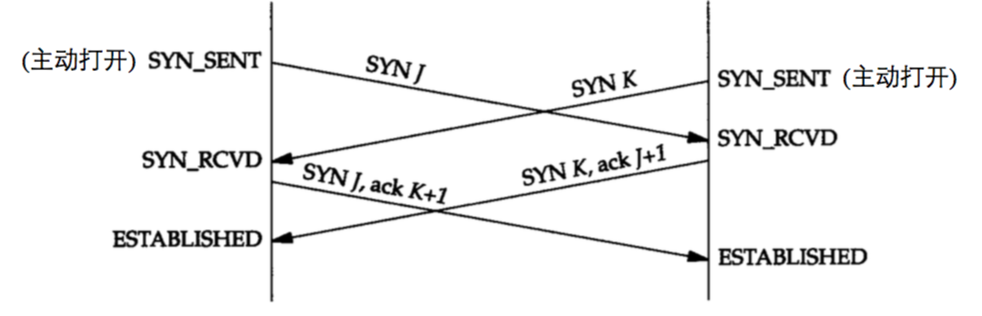
Figure 12: TCP 同时打开建立一条连接
6.2.3. TCP Fast Open
TCP 三次握手对时延有非常大的影响。RFC 7413 中提出了 TCP Fast Open 的概念,客户端第一次连接(这依然是三次握手)时服务器生成一个 Fast Open Cookie,后续再连接时,带上这个 Cookie,服务验证有效后,可以省掉一次握手过程。
TCP 普通的三次握手和 Fast Open 的区别如图 13(摘自:https://www.slideshare.net/ThomasGraf5/devconf-2014-kernel-networking-walkthrough )所示。
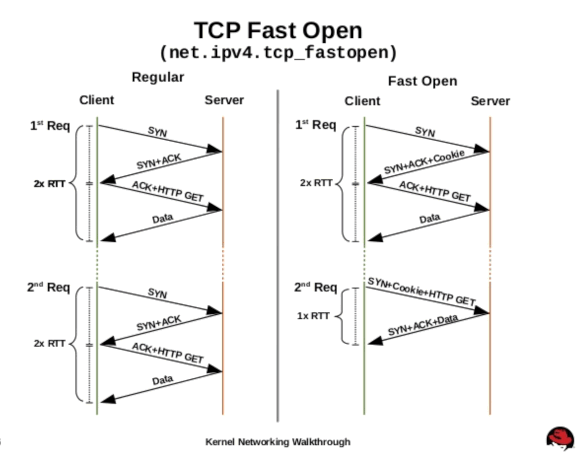
Figure 13: TCP Fast Open
6.3. TCP 连接的释放(两个二次握手,即四次挥手)
TCP 连接的释放过程如图 14 所示。
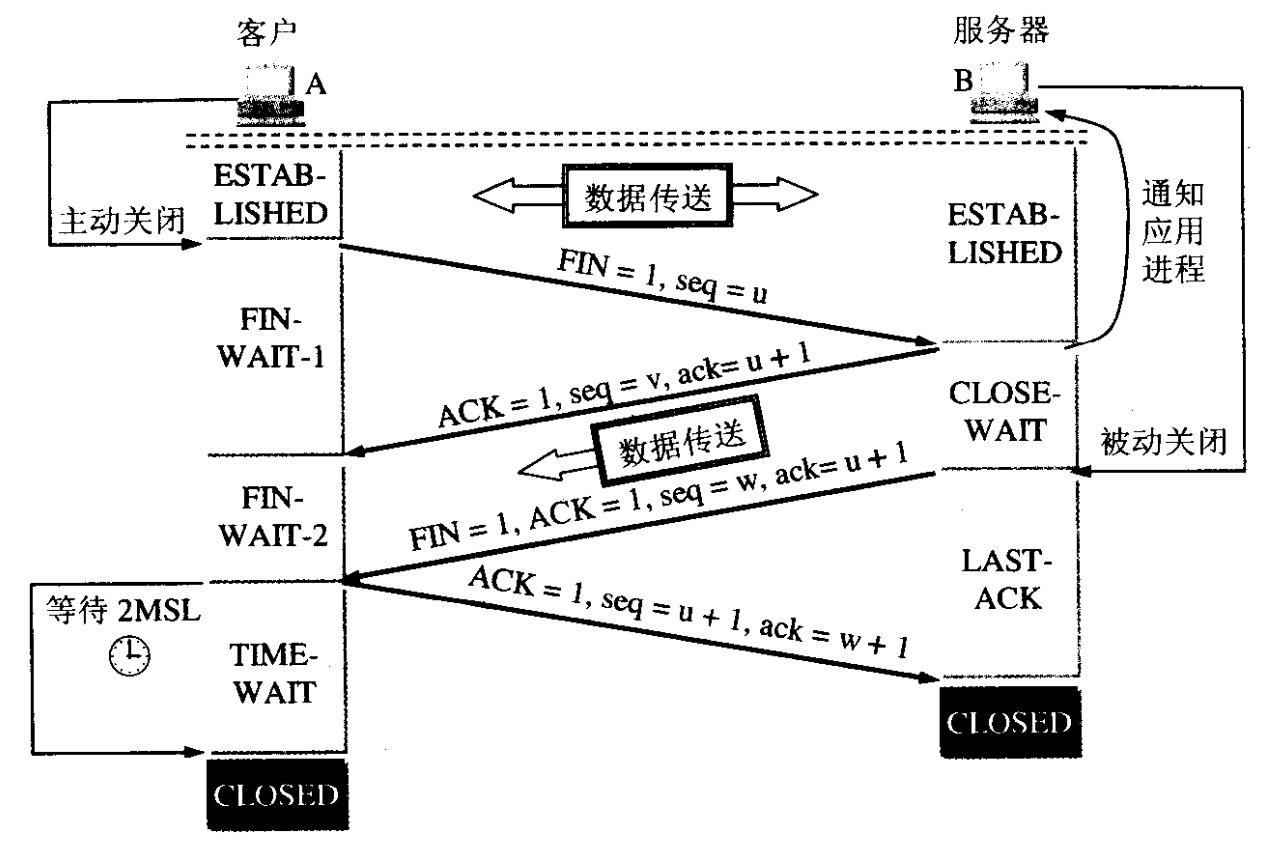
Figure 14: TCP 连接的释放过程
A 把连接释放报文段首部的 FIN 置 1,其序号 seq=u,它等于前面已传送过的数据的最后一个字节的序号加 1。这时 A 进入 FIN-WAIT-1 状态,等待 B 的确认。B收到连接释放报文段后即发出确认,确认号是 ack=u+1,而这个报文段自己的序号为 v,等于 B 前面已传送过的数据的最后一个字节的序号加 1。然后 B 就进入 CLOSE-WAIT 状态。这时从 A 到 B 这个方向的连接就释放了,TCP 连接处于半关闭(half-close)状态。从 B 到 A 这个方向的连接并未关闭,如果 B 还有数据要发送,A仍需要接收。
A 收到来自 B 的确认后,就进入 FIN-WAIT-2 状态,等待 B 发出的连接释放报文段。
如果 B 已经没有要向 A 发送的数据,其应用进程通知 TCP 释放连接。这时 B 发出的连接释放报文段必须使 FIN=1,现假定 B 的序号为 w (在半关闭状态 B 可能又发送了一些数据)。B还必须重复上次已发送过的确认号 ack=u+1,这时 B 就进入 LAST-ACK 状态,等待 A 的确认。
A 在收到 B 的连接释放报文段后,必须对些发出确认。在确认报文段中所 ACK 置 1,确认号 ack=w+1,而自己的序号是 seq=u+1(前面发送过的 FIN 报文段也要消耗一个序号)。然后进行到 TIME-WAIT 状态。A再经过 2MSL (Maximum Segment Lifetime, RFC 793 建议 MSL 设为 2 分钟)后才进入到 CLOSED 状态。
B 只要收到 A 发出的确认,就进入到 CLOSED 状态。
参考:计算机网络(第 5 版),谢希仁著,5.9.2 TCP 的连接释放
6.3.1. 为什么要等待 2MSL(或为什么需要 TIME_WAIT 状态)
为什么 A 在 TIME-WAIT 状态必须等待 2MSL 的时间呢?有两个理由:
- 为了保证 A 发送的最后一个 ACK 报文段能够到达 B。这个 ACK 报文段有可能丢失,因而使处于 LAST-ACK 状态的 B 收不到对已发送的 FIN+ACK 报文段的确认。B 会超时重传这个 FIN+ACK 报文段,而 A 就能在 2MSL 时间内收到这个重传的 FIN+ACK 报文段。
- 为了本连接持续的时间内所产生的所有报文段都从网络中消失,这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。
6.3.2. TIME-WAIT 状态的连接过多导致端口资源耗尽
由前面知识可知, 每一个 TCP 连接关闭后,主动关闭连接的一方都会保留这个连接一段时间(2MSL),这个时间内,这个连接的状态是 TIME-WAIT,端口资源不会被释放。 图 14 显示的是客户端主动关闭连接的情况,也有服务端主动关闭连接的情况。
在并发量较高的系统中,系统中可能会出现大量 TIME-WAIT 状态的连接,严重时会耗尽端口资源,导致新的连接无法建立。
如何解决这个问题呢?下面介绍一些方法。
方法一:修改内核参数 net.ipv4.ip_local_port_range 以增加可用的端口数量。默认可用的端口只有 2 万多个:
$ cat /proc/sys/net/ipv4/ip_local_port_range 32768 60999
方法二:设置内核参数 net.ipv4.tcp_tw_reuse 为 1,开启“重用”机制。
当内核参数 net.ipv4.tcp_tw_reuse 为 1 时,内核可能重用 TIME-WAIT sockets 来创建新连接。
方法三(不推荐):设置内核参数 net.ipv4.tcp_tw_recycle 为 1,开启“回收”机制(谨慎使用,NAT 环境下可能有问题)。
从 Linux 内核 4.12 开始,已经去掉了这个参数,参考:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=4396e46187ca5070219b81773c4e65088dac50cc
方法四(推荐):优化自己的系统,减少短连接次数。
很多时候,系统中存在大量 TIME-WAIT 状态的连接是由于过多的短连接造成的。我们应该找到具体的问题点,从根本上优化系统的设计。
6.3.3. 同时关闭(Simultaneous Close)
TCP 协议允许同时关闭(Simultaneous Close)。如图 15 所示。
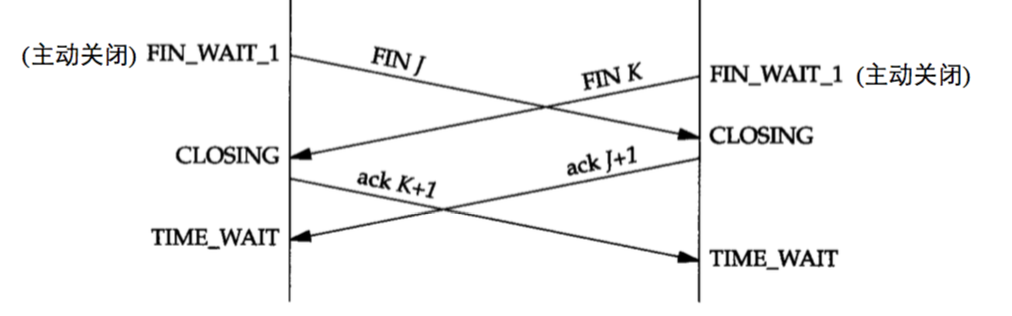
Figure 15: TCP 同时关闭连接
6.4. TCP 的状态变迁图
TCP 的状态变迁如图 16 所示。

Figure 16: TCP state transition diagram
客户端的状态变迁为: CLOSED-->SYN_SENT-->ESTABLISHED-->FIN_WAIT_1-->FIN_WAIT_2-->TIME_WAIT-->CLOSED
服务器的状态变迁为: CLOSED-->LISTEN-->SYN_RCVD-->ESTABLISHED-->CLOSE_WAIT-->LAST_ACK--->CLOSED
参考:
UNIX 网络编程第 1 卷:套接口 API 和 XOpen 传输接口 API(第 2 版),第 2 章
http://www.tti.unipa.it/~gneglia/ip_networks06/slides/TCPIP_State_Transition_Diagram.pdf
6.5. 提供可靠性:“滑动窗口”、“确认机制”、“重传机制”
当底层通信系统仅仅提供不可靠的分组交付功能时,协议软件如何提供可靠的传输呢?答案十分复杂,但是大部分可靠协议使用一个名为“带重传的肯定确认”(positive acknowledgement with retransmission)的技术作为提供可靠性的基础。这种技术要求接收方收到数据之后向发送方回送确认(ACK)报文。发送方对发出的每个分组都保存一份记录,在发送下一个分组之前等待确认信息。发送方还在送出分组时启动一个定时器,并在定时器超时而确认信息还没有到的情况下重发刚才的分组。如图 17 所示。
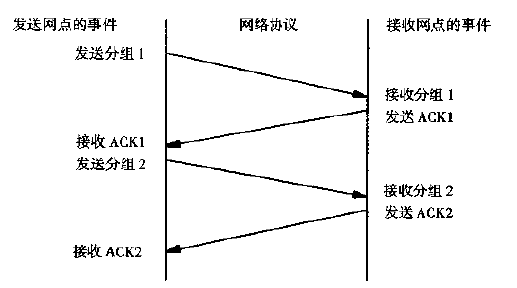
Figure 17: 简单“带重传的肯定确认”协议,发送方等待每个分组的确认信息。向下垂直方向表示时间增长
如果出现分组丢失时(超时还未收到确认),发送方会重新发送分组。如图 18 所示。
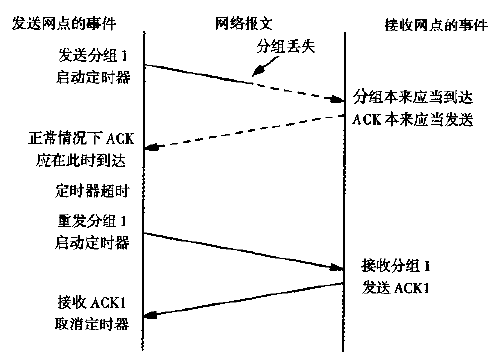
Figure 18: 分组丢失引起了超时和重传
参考:《用 TCP/IP 进行网际互连(第一卷)——原理、协议与结构(第四版)》13.4 提供可靠性
6.5.1. 滑动窗口
为实现可靠性,前面介绍了简单的“带重传的肯定确认”机制,在发送方送出一个分组后,等待相应的确认信息而不发送下一个分组。这样可行,但却没有充分利用网络带宽,在时延大的网络上,浪费带宽的问题更加突出。
TCP 使用滑动窗口协议来更好地利用网络带宽,因为它允许发送方在等待确认之前可以发送多个分组。
图 19 是一个简单的滑动窗口协议示意图,假设窗口的大小为 8 个分组(TCP 滑动窗口的窗口大小是可变的):
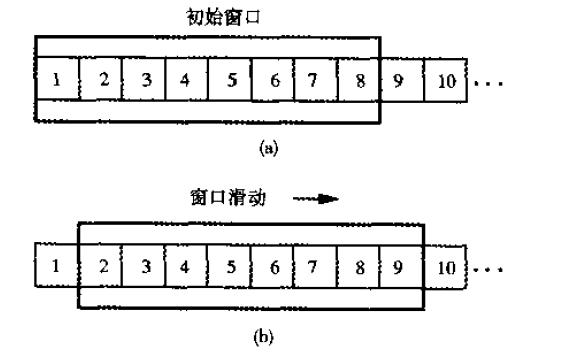
Figure 19: (a) 窗口大小为 8 个分组的滑动窗口;(b) 收到对 1 号分组的确认后,窗口滑动,使得 9 号分组也能被发送。
TCP 滑动窗口的窗口大小可以随时改变,这不仅提供可靠传输,而且还提供了流量控制。 如果接收方的缓冲区快要满了,不能接收更多的分组,这时它就发出小的窗口通告值。在极端情况下,接收方使用 0 通告值来停止一般分组的传输。而在缓冲区空间又可用后,接收方通知一个非 0 的窗口值来再次触发数据流。
6.5.2. 累积式确认(Cummulative Acknowledgement)
TCP 的确认方法称为“累积式确认”。接收端给发送端的确认信息只会确认最后一个连续的包,而不能跳着确认。 比如,发送端发了 11,12,12,14,15 共五个数据包,接收端收到了 11,12,于是回 ACK 13(表示序号 13 之前的所有数据都已经收到,期待收到序号为 13 的数据包),然后收到了 14,15(此时数据包 13 没收到),这时 ACK 仍然为 13。这就是累积式确认(cummulative acknowledgement)。
6.5.3. 选择性确认(Selective Acknowledgment)
“累积式确认”有一个问题:假设发送方发送了 100 个包,而接收方仅第 11 个包这一个包没有收到,那么接收方也只能对前面 10 个包进行确认,这样发送方不知道后面的数据是否已经收到,如果要重传,就不知道重传哪些数据包才合适。
为了克服这个不足,TCP 还有另外一种确认方式叫:选择性确认(Selective Acknowledgment, SACK)。 SACK 的基本思想是接收方汇报收到的所有“数据区间”(很可能不连续),这样发送方就知道哪些数据未收到,哪些已经收到,从而可以优化重传机制。
SACK 需要两端的协议都支持,在 Linux 系统下,通过 tcp_sack 参数可以打开“选择性确认”功能(Linux 2.2 后默认打开)。
6.5.4. 超时重传
为了保证 TCP 的可靠性,必须有重传机制。从概念上讲,重传很简单,在规定时间内没有收到数据包的确认信息就重传数据包即可。但重传时间的选择却是 TCP 最复杂的问题之一。重传时间设置得过短,则可能使没有丢的数据包进行了不必要的重传,使网络负载不必要增大;重传时间设置得过长,则传输效率变低。
TCP 采用了自适应的算法来确认重传时间(Retransmission TimeOut, RTO)。由于路由器和网络流量均会变化,因此我们认为合适的 RTO 可能经常会发生变化,TCP 应该跟踪这些变化并相应地改变其 RTO。
为了计算 RTO,往往需要估计数据包往返时间(Round Trip Time, RTT),也就是一个数据包从发出去到收到该数据包确认所经过的时间。
RFC 793 中有一个利用 RTT 来计算 RTO 的例子:
An Example Retransmission Timeout Procedure
Measure the elapsed time between sending a data octet with a
particular sequence number and receiving an acknowledgment that
covers that sequence number (segments sent do not have to match
segments received). This measured elapsed time is the Round Trip
Time (RTT). Next compute a Smoothed Round Trip Time (SRTT) as:
SRTT = ( ALPHA * SRTT ) + ((1-ALPHA) * RTT)
and based on this, compute the retransmission timeout (RTO) as:
RTO = min[UBOUND,max[LBOUND,(BETA*SRTT)]]
where UBOUND is an upper bound on the timeout (e.g., 1 minute),
LBOUND is a lower bound on the timeout (e.g., 1 second), ALPHA is
a smoothing factor (e.g., .8 to .9), and BETA is a delay variance
factor (e.g., 1.3 to 2.0).
6.5.5. 快速重传
如果一连串收到 3 个或 3 个以上相同的 ACK 值,就非常可能是一个报文段丢失了。于是我们就重传丢失的数据报文段,而无需等待超时定时器溢出。这就是快速重传算法。
6.6. 糊涂窗口综合症(Silly Windows Syndrome)
当发送端应用进程产生数据很慢、或接收端应用进程处理接收缓冲区数据很慢,或二者兼而有之;就会使应用进程间传送的报文段很小,特别是有效载荷很小。 极端情况下,有效载荷可能只有 1 个字节,而传输开销有 40 字节(20 字节的 IP 头+20 字节的 TCP 头),类似这种现象就叫糊涂窗口综合症(Silly Windows Syndrome)。
收发双方都有避免糊涂窗口综合症的责任。
参考:《用 TCP/IP 进行网际互连(第一卷)——原理、协议与结构(第四版)》13.32 避免糊涂窗口综合症
6.6.1. 发送方避免糊涂窗口综合症——Nagle 算法
有些应用产生的有效载荷可能很小,比如交互式程序 Telnet 和 Rlogin 等。在一个 Rlogin 连接上客户一般每次发送一个字节到服务器,这就产生了一些 41 字节长的分组(20 字节 IP 首部、20 字节 TCP 首部、1字节数据),这就是糊涂窗口综合症。在局域网上,这些小分组通常不会引起麻烦;但广域网上,这些小分组则会增加拥塞出现的可能。
避免 TCP 连接上出现很多小分组的一种解决办法是采用 Nagle算法 。Nagle 算法的伪代码如下:
if there is new data to send
if the window size >= MSS(maximum segment size) and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data still in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if
Nagle 算法要求一个 TCP 连接上最多只能有一个未被确认的未完成小分组,在该分组的确认到达之前不能发送其他的小分组。TCP 收集这些少量的分组,并在 ACK 到来时以一个分组的方式发出去。
6.6.1.1. 禁止 Nagle 算法(TCP_NODELAY)
有时我们需要关闭 Nagle 算法,一个典型的例子是 X 窗口系统服务器:小消息(鼠标移动)必做无时延地发送,以便为进行某种操作的交互用户提供实时的反馈。
RFC 1122 Requirements for Internet Hosts 明确指出 TCP 必须实现 Nagle 算法,且还应提供一种方法来关闭这个算法在某个连接上执行。
sock 编程时,可以使用选项 TCP_NODELAY 来关闭 Nagle 算法:
int one = 1; setsockopt(descriptor, SOL_TCP, TCP_NODELAY, &one, sizeof(one));
6.6.2. 接收方避免糊涂窗口综合症
接收端的 TCP 可能产生糊涂窗口综合症,如果它为消耗数据很慢的应用程序服务,例如,一次消耗一个字节。假定发送应用程序产生了 1000 字节的数据块,但接收应用程序每次只吸收 1 字节的数据。再假定接收端的 TCP 的输入缓存为 4000 字节。发送端先发送第一个 4000 字节的数据。接收端将它存储在其缓存中。现在缓存满了。它通知窗口大小为零,这表示发送端必须停止发送数据。接收应用程序从接收端的 TCP 的输入缓存中读取第一个字节的数据。在入缓存中现在有了 1 字节的空间。接收端的 TCP 宣布其窗口大小为 1 字节,这表示正渴望等待发送数据的发送端的 TCP 会把这个宣布当作一个好消息,并发送只包括一个字节数据的报文段。这样的过程一直继续下去。一个字节的数据被消耗掉,然后发送只包含一个字节数据的报文段。
对于这种糊涂窗口综合症,即应用程序消耗数据比到达的慢,有两种建议的解决方法。
(1) Clark 解决方法 :Clark 解决方法是只要有数据到达就发送确认,但宣布的窗口大小为零,直到或者缓存空间已能放入具有最大长度的报文段,或者缓存空间的一半已经空了。
(2) 延迟确认 :即延迟一段时间后再发送确认,当一个报文段到达时并不立即发送确认。
参考:
http://www.cnblogs.com/ggjucheng/archive/2012/02/03/2337046.html
6.7. 拥塞控制(Congestion control)
TCP 的滑动窗口模型使用大小可变的窗口,这能实现“端到端的流量控制”问题。实际上,存在两个独立的流量问题。第一,互联网协议需要源主机和最终目的主机之间“端到端的流量控制”。例如,当一台微机与一台大型机通信时,微机需要调用数据的流入速率,否则协议软件很快就超载了。第二,互联网协议需要一个流量控制机制使得中间系统(如路由器)能够控制一个源主机,以免它发送的通信量超过中间机器(如路由器)的承受能力。
当中间机器(如路由器)超载时,这种状况称为拥塞(congestion),解决这个问题的机制称为拥塞控制机制(TCP Congestion Control)。
有很多拥塞控制思想,如慢启动、拥塞避免、拥塞发生时的快速重传等等。常见的拥塞控制机制如表 8 所示。
| Variant | Feedback | Required changes | Benefits | Fairness |
|---|---|---|---|---|
| (New) Reno | Loss | — | — | Delay |
| Vegas | Delay | Sender | Less loss | Proportional |
| High Speed | Loss | Sender | High bandwidth | |
| BIC | Loss | Sender | High bandwidth | |
| CUBIC | Loss | Sender | High bandwidth | |
| C2TCP | Loss/Delay | Sender | Ultra-low latency and high bandwidth | |
| NATCP | Multi-bit signal | Sender | Near Optimal Performance | |
| Elastic-TCP | Loss and Delay | Sender | High bandwidth/short & long-distance | |
| Agile-TCP | Loss | Sender | High bandwidth/short-distance | |
| H-TCP | Loss | Sender | High bandwidth | |
| FAST | Delay | Sender | High bandwidth | Proportional |
| Compound TCP | Loss/Delay | Sender | High bandwidth | Proportional |
| Westwood | Loss/Delay | Sender | L | |
| Jersey | Loss/Delay | Sender | L | |
| BBR | Delay | Sender | BLVC, Bufferbloat | |
| CLAMP | Multi-bit signal | Receiver, Router | V | Max-min |
| TFRC | Loss | Sender, Receiver | No Retransmission | Minimum delay |
| XCP | Multi-bit signal | Sender, Receiver, Router | BLFC | Max-min |
| VCP | 2-bit signal | Sender, Receiver, Router | BLF | Proportional |
| MaxNet | Multi-bit signal | Sender, Receiver, Router | BLFSC | Max-min |
| JetMax | Multi-bit signal | Sender, Receiver, Router | High bandwidth | Max-min |
| RED | Loss | Router | Reduced delay | |
| ECN | Single-bit signal | Sender, Receiver, Router | Reduced loss |
“Benefits”一列中,单字母缩写的含义分别为:high bandwidth-delay product networks (B); lossy links (L); fairness (F); advantage to short flows (S); variable-rate links (V); speed of convergence (C).
从 Linux 2.6.19 起,默认使用 CUBIC 拥塞控制机制:
$ cat /proc/sys/net/ipv4/tcp_available_congestion_control # 列出系统支持的拥塞控制机制 reno cubic $ cat /proc/sys/net/ipv4/tcp_congestion_control # 显示当前使用的拥塞控制机制 cubic
6.8. TCP 的 4 个定时器
TCP maintains 4 timers for each connection:
- Retransmission Timer(超时重传定时器)
- The timer is started during a transmission. A timeout causes a retransmission.
- Persist Timer(坚持定时器)
- Ensures that window size information is transmitted even if no data is transmitted.
- Keepalive Timer(保活定时器)
- Detects crashes on the other end of the connection.
- 2MSL Timer
- Measures the time that a connection has been in the TIME_WAIT state.
6.8.1. Persist Timer
ACK 的传输并不可靠,也就是说,TCP 不对 ACK 报文段进行确认,TCP 只确认那些包含有数据的 ACK 报文段。
如果一个确认丢失了,则双方就有可能因为等待对方而使连接终止:接收方等待接收数据(因为它已经向发送方通告了一个非 0 的窗口),而发送方在等待允许它继续发送数据的窗口更新。为防止这种死锁情况的发生,发送方使用一个坚持定时器 (persist timer)来周期性地向接收方查询,以便发现窗口是否已增大。
参考:TCP/IP Illustrated, Volume 1 The Protocols, Chapter 22 TCP Persist Timer
6.8.2. Keepalive Timer
保活定时器并不是 TCP 规范中的一部分,RFC 1122 中提供了 3 个不使用保活定时器的理由:(1)在出现短暂有差错的情况下,这可能会使一个非常好的连接释放掉;(2)它们耗费不必要的带宽;(3)在按分组计费的情况下会在互联网上花掉更多的钱。
然而,很多 TCP 实现都提供了保活定时器。保活定时器是一个有争论的功能。 许多人认为如果需要,这个功能不应该在 TCP 中提供,而应该由应用程序来完成。
TCP 关闭 Keepalive 功能时,如果没有应用级的定时器检测非活动状态,我们可以启动一个客户与服务器建立一个连接,双方不发送任何数据,然后离去数天或数月,这个连接依然保持着。 中间路由器可以崩溃或重启,只要两端的主机没有被重启,连接依然保持建立。
问题:当连接成功建立后,客户端拔去网线,客户端电脑重启后插入网线,启动客户端进程,会出现什么情况?
分析:首先如果 TCP 打开了 keeplive 选项,那么客户端关机时间久了以后,服务器就能感知到,如果 keeplive 关闭,或者客户端快速重启,那么这个时候,服务器没有发现异常。客户端重启过后是一个全新状态,由 TCP 状态转换图可知,客户端会发起 SYN,而服务器收到客户端发来的 SYN 的话,发现在 ESTABLISHED 状态收到 SYN 是异常的,于是,返回 RST,自己也复位改连接。客户端收到 RST 后,复位,重新连接。
在 C 程序中,可以使用函数 setsockopt 来使用 keepalive 定时器,完整的测试实例可参考:http://www.tldp.org/HOWTO/html_single/TCP-Keepalive-HOWTO/#examples
参考:
TCP/IP Illustrated, Volume 1 The Protocols, Chapter 23 TCP Keepalive Timer
TCP Keepalive HOWTO: http://www.tldp.org/HOWTO/html_single/TCP-Keepalive-HOWTO/
7. 无线网络
7.1. 无线局域网 WLAN (Wireless Local Area Network, 802.11, Wi-Fi)
1997 年,IEEE 802.11 制定了无线局域网的标准。802.11 是个相当复杂的标准。但简单地说,802.11 就是无线以太网的标准,它使用星形拓扑,其中心叫做接入点 AP(Access Point),在 MAC 层使用 CSMA/CA 协议。凡使用 802.11 系列协议的局域网又称为 Wi-Fi(Wireless-Fidelity)。现在 Wi-Fi 实际上已经成为了无线局域网 WLAN 的代名词。
表 9 是一些主要的无线局域网标准。
| Generation/IEEE Standard | Maximum Linkrate | Adopted | Frequency |
|---|---|---|---|
| Wi-Fi 6E (802.11ax) | 600 to 9608 Mbit/s | 2019 | 6 GHz |
| Wi-Fi 6 (802.11ax) | 600 to 9608 Mbit/s | 2019 | 2.4 or 5 GHz |
| Wi-Fi 5 (802.11ac) | 433 to 6933 Mbit/s | 2014 | 5 GHz |
| Wi-Fi 4 (802.11n) | 72 to 600 Mbit/s | 2008 | 2.4 or 5 GHz |
| 802.11g | 6 to 54 Mbit/s | 2003 | 2.4 GHz |
| 802.11a | 6 to 54 Mbit/s | 1999 | 5 GHz |
| 802.11b | 1 to 11 Mbit/s | 1999 | 2.4 GHz |
| 802.11 | 1 to 2 Mbit/s | 1997 | 2.4 GHz |
7.2. 无线个人区域网 WPAN (Wireless Personal Area Network, 802.15)
IEEE 802.15 工作组专门从事 WPAN 标准化工作。它的任务是开发一套适用于短程无线通信的标准,通常我们称之为无线个人区域网(WPAN)。
WPAN 有下面这些子标准:
- Bluetooth (802.15.1)。Bluetooth 是最早使用的 WPAN,于 1994 年爱立信公司推出。
- High Rate WPAN (802.15.3, UWB)。高速 WPAN 是专为在便携式多媒体装置之间传送数据而制定的。这个标准支持 11~55 Mbit/s 的数据率。使用高速 WPAN 可以不用连接线就能把计算机和在同一间屋子里的打印机、扫描仪、外接硬盘,以及各种消费电子设备连接起来。如别人使用数码摄像机拍摄的视频节目,可以不用连接线就能复制到你的数码摄像机的存储卡上。
- Low Rate WPAN (802.15.4, ZigBee)。低速 WPAN 主要用于工业监控组网、办公自动化与控制等领域,其速率是 2~250 kbit/s。在低速 WPAN 中最重要的就是 ZigBee。ZigBee 的另一个特点是功耗非常低。在工作时,信号的收发时间很短;而在非工作时,ZigBee 结点处于休眠状态。这就使得 ZigBee 节点非常省电,其节点的电池工作时间可以长达 6 个月到 2 年左右。对于某些工作时间和总时间(工作时间+休眠时间)之比小于 1% 的情况,电池的寿命甚至可以超过 10 年。
8. 参考
TCP/IP Illustrated, Volume 1 The Protocols: http://www.cs.newpaltz.edu/~pletcha/NET_PY/the-protocols-tcp-ip-illustrated-volume-1.9780201633467.24290.pdf
TCP/IP Illustrated, Volume 1 The Protocols, 2nd Edition: http://www.jtbookyard.com/uploads/6/2/9/3/6293106/tcp_ip_illustrated_volume_1_the_protocols_2nd_edit.pdf
计算机网络(第 5 版),谢希仁著