Operator-precedence Parser, Pratt Parser
Table of Contents
1. 算符优先分析法(自底向上)
算符优先分析法(Operator-precedence parser)是一种简单直观的自底向上的分析法。算符优先分析法的思路是定义算符之间(确切地说是终结符之间)的某种优先关系,利用这种优先关系寻找“可归约串”进行归约。相对 LR 分析方法,算符优先分析法更易于手工构造移动归约分析器。
由于算符优先分析技术比较简单,很多编译器的语法分析器 经常采用算符优先分析技术对表达式进行分析 ,对于语句和高级结构的分析则采用递归下降分析法。也有编译的语法分析器甚至对整个语言都采用算符优先技术进行语法分析。
参考:《编程原理(第 1 版)》4.6 节 算符优先分析法
1.1. 算符文法
算符优先分析法仅能处理 “没有相邻的非终结符出现在产生式的右部”的文法(称为算符文法)。
下面的表达式文法(注:这个文法本身没有体现加减乘除运算的优先级和结合性,它是一个二义性文法) :
E -> EAE | (E) | i A -> + | - | * | /
它不是算符文法。因为第一个产生式中右部 EAE 有 2 个(实际上是 3 个)连续的非终结符。不过,我们可以用 A 的每个候选式替换第一个产生式中的 A,从而得到下面的算符文法(产生式右边不再有相邻的非终结符了):
E -> E + E | E - E | E * E | E / E | (E) | i
参考:https://en.wikipedia.org/wiki/Operator-precedence_grammar
1.2. 算符优先法简介
在算符优先分析中,我们在终结符之间定义如下三种优先关系:
| 关系 | 含义 |
|---|---|
| a <· b | a 的优先级低于 b |
| a =· b | a 的优先级等于 b |
| a ·> b | a 的优先级高于 b |
我们使用这些优先级关系来指导句柄的选取。
下面介绍算符优先法的应用实例(这个例子摘自《编程原理(第 1 版)》4.6.1 使用算符优先关系)。
设算符文法为:
E -> E + T | T T -> T * F | F F -> id
下面是对“id+id*id”的语法分析过程。
用 “$” 表示输入字符串的两端(开始和结尾)。这个文法的算符优先关系为:
| id | + | * | $ | |
|---|---|---|---|---|
| id | ·> | ·> | ·> | |
| + | <· | ·> | <· | ·> |
| * | <· | ·> | ·> | ·> |
| $ | <· | <· | <· | Accept |
把输入字符串“id+id*id”插入优先关系后,可得到符号串:
$ <· id ·> + <· id ·> * <· id ·> $
应用下面的过程可以发现句柄:
(1) 从左端开始扫描串,直到遇到第一个“·>”为止。在上面例子中,第一个“·>”出现在第一个 id 和+之间。
(2) 找到“·>”后,向左扫描,跳过所有的“=·”,直到遇到一个“<·”为止。
(3) 句柄包括从第(2)步遇到的“<·”的右部到第一个“·>”的左部之间的所有符号(还要包括介于其间或者两边的非终结符)。
利用上面过程得到的第一个句柄是“id+id*id”中的第一个 id,由于 id 可以归约为 E,从而,我们得到右句型“E + id * id”。按照同样的步骤将剩余的两个 id 归约为 E 之后,可以得到右句型“E + E * E”。现在考虑忽略非终结符后的符号串“$ + * $”。插入优先关系后,可得到:
$ <· + <· * ·> $
继续按照前面介绍的过程分析,可得,句柄左端位于+和*之间,右端位于*和$之间。即右句型“E + E * E”中,句柄是“E*E”(注意*两边的非终结符 E 也在句柄中)。
如果用栈实现,上面对应的“移进——归约”过程如下:
Handle Stack Input String Reason
(top to the right)
$ id+id*id$ Initialized
$id +id*id$ $ <· id
id $E +id*id$ id >· +
$E+ id*id$ $ <· +
$E+id *id$ + <· id
id $E+E *id$ id >· *
$E+E* id$ + <· id
$E+E*id $ * <· id
id $E+E*E $ id >· $
E * E $E+E $ * >· $
E + E $E $ + >· $
RETURN $ =· $
算符优先分析算法总结如下(w表示输入字符串):
Initialize: Set ip to point to the first symbol of w$
Repeat: Let X be the top stack symbol, and a the symbol pointed to by ip
if $ is on the top of the stack and ip points to $ then return
else
Let a be the top terminal on the stack, and b the symbol pointed to by ip
if a <· b or a =· b then
push b onto the stack
advance ip to the next input symbol
else if a ·> b then
repeat
pop the stack
until the top stack terminal is related by <·
to the terminal most recently popped
else error()
end
算法的主要思想: 比较“栈顶的终结符”(对应上面描述中的 a)和“输入字符串的下一个符号”(对应上面描述中的 b)的优先级,如果“栈顶的终结符”的优先级低,则“移进”输入字符串的下一个符号;如果“栈顶的终结符”的优先级高,则去栈中寻找句柄进行归约。
参考:
http://zeus.cs.pacificu.edu/ryand/cs480/2007/ch4f.html
http://tec.5lulu.com/computer/detail/35nn8hy48y8m4a.html
《编程原理(第 1 版)》4.6.1 使用算符优先关系
2. 算符优先分析法(自顶向下):Pratt Parser/Precedence Climbing
1973 年 Pratt 提出了“自顶向下”的算符优先分析法。
2.1. Pratt Parser 简介
在 Pratt Parser 中,每个词法 Token 关联两个函数(记为函数 nud 和函数 led)和一个整数(记为 binding power, bp),利用整数 bp 值来决定算符的优先级。
如何利用 binding power 值来决定优先级的?请看下面例子,假如有表达式:
1 + 2 * 4 ^ ^ ^
为了使数字 2 关联到操作符“*”上,我们设置操作符“*”的 binding power 值(如 20)比操作符“+”的 binding power 值(如 10)小。算法中,把数字 2 关联到 binding power 值更大的操作符(在这里是操作符“*”)上。
下面是 Pratt Parser 的简单实现(省略了词法分析器,后文有介绍),它支持求解加号和乘法运算的表达式:
def expression(rbp=0): # 函数expression是递归的,因为其中的nud和led函数都可能再次调用函数expression
global token
t = token
token = next()
left = t.nud()
while rbp < token.lbp:
t = token
token = next()
left = t.led(left)
return left
class literal_token(object):
def __init__(self, value):
self.value = int(value)
def nud(self):
return self.value
class operator_add_token(object):
lbp = 10
def led(self, left):
right = expression(10)
return left + right
class operator_mul_token(object):
lbp = 20
def led(self, left):
return left * expression(20)
class end_token(object):
lbp = 0
其中,lbp, nud, led 的含义分别如下:
lbp : the left binding power of the operator. For an infix operator, it tells us how strongly the operator binds to the argument at its left.
nud (null denotation) : this is the prefix handler we talked about. In this simple parser it exists only for the literals (the numbers)
led (left denotation) : the infix handler.
算法的核心思想包含在函数 expression 里。函数 expression 是递归的,因为其中的 nud 和 led 函数都可能再次调用函数 expression。下面以“3 + 1 * 2 * 4 + 5”为例说明函数 expression 的工作原理。
函数 expression 接受参数 rlp (right binding power), 当 expression 被调用时,会消耗 binding power 值比 rlp 大的词法 Token”。
分析“3 + 1 * 2 * 4 + 5”时,expression 的递归调用层次为:
<<expression with rbp 0>> # 消耗“binding power”值比0大的词法Token”,这里所有Token都会被消耗
<<literal nud = 3>>
<<led of "+">>
<<expression with rbp 10>> # 消耗“binding power”值比10大的词法Token”
<<literal nud = 1>>
<<led of "*">>
<<expression with rbp 20>> # 消耗“binding power”值比20大的词法Token”
<<literal nud = 2>>
<<led of "*">>
<<expression with rbp 20>> # 消耗“binding power”值比20大的词法Token”
<<literal nud = 4>>
<<led of "+">>
<<expression with rbp 10>> # 消耗“binding power”值比10大的词法Token”
<<literal nud = 5>>
图 1 演示了 expression 调用时在不同的递归层次所消耗词法 Token 的情况。
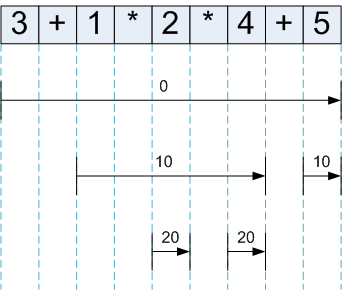
Figure 1: 函数 expression()在不同的递归层次所消耗词法 Token 的情况
参考:
Vaughn R. Pratt, "Top down operator precedence", 1973: https://tdop.github.io/
Simple Top-Down Parsing in Python, by Fredrik Lundh: http://effbot.org/zone/simple-top-down-parsing.htm
Top-Down operator precedence parsing: http://eli.thegreenplace.net/2010/01/02/top-down-operator-precedence-parsing
Pratt Parsing Index and Updates: http://www.oilshell.org/blog/2017/03/31.html
2.2. Pratt Parser 求解加减乘除表达式
下面是 Pratt Parser 的简单实例(求解加减乘除表达式,用 Python 实现,代码摘自Simple Top-Down Parsing in Python, by Fredrik Lundh):
class literal_token:
def __init__(self, value):
self.value = int(value)
def nud(self):
return self.value
class operator_add_token:
lbp = 10
def led(self, left):
right = expression(10)
return left + right
class operator_sub_token:
lbp = 10
def led(self, left):
return left - expression(10)
class operator_mul_token:
lbp = 20
def led(self, left):
return left * expression(20)
class operator_div_token:
lbp = 20
def led(self, left):
return left / expression(20)
class end_token:
lbp = 0
import re
token_pat = re.compile("\s*(?:(\d+)|(.))")
def tokenize(program):
for number, operator in token_pat.findall(program):
if number:
yield literal_token(number)
elif operator == "+":
yield operator_add_token()
elif operator == "-":
yield operator_sub_token()
elif operator == "*":
yield operator_mul_token()
elif operator == "/":
yield operator_div_token()
else:
raise SyntaxError("unknown operator")
yield end_token()
def expression(rbp=0):
global token
t = token
token = next()
left = t.nud()
while rbp < token.lbp:
t = token
token = next()
left = t.led(left)
return left
def parse(program):
global token, next
next = tokenize(program).next
token = next()
return expression()
测试如下:
>>> parse("1+2")
3
>>> parse("1+2*3")
7
>>> parse("1+2-3*4/5")
1
2.3. Precedence Climbing
Precedence Climbing 算法和 Pratt Parser 基本相同。
下面是“Precedence Climbing”和“Pratt Parser”的一些形式上的差异:
| Precedence Climbing | Pratt Parsing | |
|---|---|---|
| Data Structure | A table of token ID to integer precedence | Two tables of precedence, or two dynamically dispatched methods on token objects |
| Code Structure | Single Recursive Function | Mutually recursive functions, all of which mutate the current token. Just like a recursive descent parser. |
| Handling Parentheses | Inline special case | ( is a prefix operator with low left binding power |
| Handling unary/ternary/non-binary operators | Inline special case | User-defined function, i.e. mutually recursive "plugins" |
参考:
Precedence Climbing is Widely Used: http://www.oilshell.org/blog/2017/03/30.html
Pratt Parsing and Precedence Climbing Are the Same Algorithm: http://www.oilshell.org/blog/2016/11/01.html
2.4. Pratt Parser 应用
在 LLVM Tutorial 中使用 Operator-Precedence Parsing 来分析“表达式”,参考:Kaleidoscope: Implementing a Parser and AST
jmespath 的 Python 实现中使用了 Pratt Parser 分析 JSON 语法,参考:https://github.com/jmespath/jmespath.py/blob/develop/jmespath/parser.py
Precedence Climbing 算法(和 Pratt Parser 算法基本相同)的应用很广泛,参考: http://www.oilshell.org/blog/2017/03/30.html