Practical Byzantine Fault Tolerance (PBFT)
Table of Contents
1. PBFT 简介
PBFT 是 Miguel Castro 和 Barbara Liskov 于 1999 年在论文 Practical Byzantine Fault Tolerance 提出的 BFT 算法,它的时间复杂度为 \(O(n^2)\) ,这是一个“多项式级”复杂度。注:BFT 问题是 1982 年 Lamport 在论文 The Byzantine Generals Problem 中提出的,原论文中给出的算法是“指数级”复杂度,不具备实用性。
1.1. 问题定义 State Machine Replication(状态机复制)
PBFT 是一种 State Machine Replication 算法。PBFT 可以容忍 Byzantine Failure。如果系统中存在 \(f\) 个有问题节点,则当总节点数大于等于 \(3f+1\) 时系统可正常工作。 \(3f+1\) 是基于消息传递的共识算法的最小节点数。 关于这个结论的证明可以参考 G. Bracha and S. Toueg 于 1985 年发表的论文 Asynchronous Consensus and Broadcast Protocols 。
1.2. 系统的同步模型
在谈论分布式系统中的共识时,我们明确采用了下面哪种同步模型:
- synchrony:节点发出的消息,在一个确定的时间内,肯定会到达目标节点;这是一种理想情况。
- partial synchrony (weak synchrony):节点发出的消息,虽然会有延迟,但是最终会到达目标节点。
- asynchrony:节点发出的消息,可能丢失,不能确定一定会到达目标节点。
PBFT 假设系统是异步的(asynchrony)。
2. PBFT 主要流程
PBFT 的作者 Liskov 同时也是 Viewstamped Replication(VR)协议的作者。VR 协议仅考虑 Crash 错误,更加简单,建议读者 在阅读 PBFT 之前先了解一下 VR 协议。
PBFT 正常情况下的流程如图 1 所示。
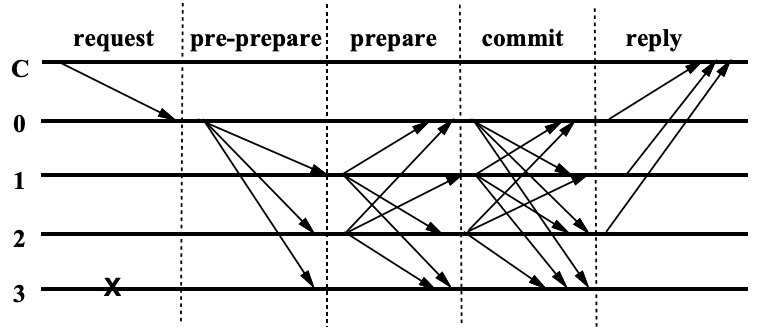
Figure 1: Normal Case Operation,其中 C 表示 client,0 为 primary,3 出了故障
正常情况下的主要流程如下:
- Pre-Prepare:primary 节点把客户端发来的请求进行编号,并把请求广播给其它节点;
- Prepare:每个节点接收到请求后,按编号顺序模拟执行(模拟执行的意思是仅得到结果暂时不提交)这些请求。每个节点向其它节点广播自己的结果;
- Commit: 如果一个节点收到的 \(2f\) 个其它节点发来的结果都和自己执行的结果相等,则向其它节点广播一条 commit 消息;
- Reply: 如果一个节点收到 \(2f+1\) 条 commit 消息(可以包含节点自己的 commit 消息),即可提交到本地的状态数据库,这个请求已经被系统接受。
PBFT 算法的时间复杂度 \(O(n^2)\) ,因为在 Prepare 和 Commit 阶段每个节点会向其它节点广播消息。 PBFT 不适合节点很多的场景,也就是说 scalability 不好,这是 PBFT 的一个缺点。当节点数超过 100 时,由于,Prepare 和 Commit 阶段会广播大量数据,效率会变得很低。
注:为什么在 Prepare 阶段,每个节点要向其它节点广播自己的执行结果?这是因为,我们要考虑 primary 节点可能作恶的情况。比如,primary 在 pre-prepare 阶段向其它节点发送不一致的数据,在 Prepare 阶段,节点广播自己执行结果后,其它节点收到数据一看和自己执行结果不一样,这样就知道系统中可能有恶意节点。至于恶意节点是否能破坏系统,则依赖于总节点数,总节点数大于等于 \(3f+1\) 时,不会破坏一致性,在后续 Commit/Reply 阶段中,“诚实”节点之间还是会达成一致的。注: VR 协议仅考虑 Crash 错误,所以不需要 PBFT 中的每个节点向其它节点广播数据的流程。
这里仅介绍了正常情况下的主要流程,当 primary 不可用时,会出现 “View Changes”,请参阅原始论文。