Probabilistic Data Structures
Table of Contents
1. 概率数据结构简介
在“大数据”场景下,一些传统的数据结构很可能由于占用内存太多而不再适用。概率数据结构适应于大数据和流式应用,它们使用的内存很少,不过存在一定的错误率。
在书籍 Probabilistic Data Structures and Algorithms for Big Data Applications 中,总结了一些“概率数据结构”,如下:
- Membership (Bloom filter, Counting Bloom filter, Quotient filter, Cuckoo filter).
- Cardinality (Linear counting, probabilistic counting, LogLog, HyperLogLog, HyperLogLog++).
- Frequency (Majority algorithm, Frequent, Count Sketch, Count-Min Sketch).
- Rank (Random sampling, q-digest, t-digest).
- Similarity (Locality-Sensitive Hashing, MinHash, SimHash).
本文将选取几种典型的数据结构进行描述。
2. Membership
Membership 是指“查询集合中是否存在指定的元素”。
2.1. Bloom Filter
Bloom Filter 是 1970 年由 Burton Howard Bloom 提出来的。它是一种空间效率很高的数据结构,用于检测一个元素是否存在于集合中。
Bloom Filter 的原理为:设计一个长度为 \(m\) 的位数组(初始时每一位都置 0),用 \(k\) 个相互独立的哈希函数,每个哈希函数都能将元素映射到位数组中的某位上, 对每一个想加入集合中的元素使用 \(k\) 个哈希函数进行计算,得到位置 \(h_1, h_2, \cdots, h_k\) ,并把数组中相应位置设为 1;要测试某元素 \(w\) 是否为集合中的元素时,对该元素进行相同的 \(k\) 个哈希运算,得到了 \(k\) 个位置,如果位数组里这 \(k\) 个位置全为 1,则认为元素 \(w\) 存在于集合中。
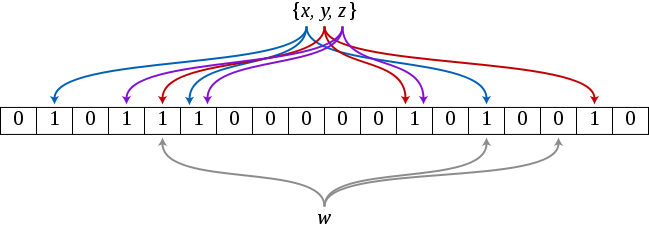
Figure 1: Bloom Filter 原理
图 1 的例子中,我们将元素 \(x, y, z\) 添加到 Bloom Filter 中(位数组长度 \(m=18\) ),并使用 3 个哈希函数(即 \(k = 3\) )设置比特位。例如,加入元素 \(x\) 时,有 \(h_1(x) = 1, h_2(x)=5, h_3(x)=13\) ,所以我们把位数组中的第 \(1, 5, 13\) 位置设置为 1。当我们在集合中查找 \(w\) 时,检查 \(h_1(w), h_2(w), h_3(w)\) 发现其中一个对应位置的比特位没有被设置为 1,所以认为 \(w\) 不在集合中。
当 Bloom Filter 认为一个元素存在于集合中时,这个元素可能并不在集合中。而当 Bloom Filter 认为一个元素不在集合中时,那么这个元素一定不在集合中。
2.1.1. Hash 算法
Bloom Filter 算法经常使用 MurmurHash 和 FNV 作为其 Hash 算法,这类算法追求“运算速度”和“哈希的随机性”,而不在意安全性。
2.1.2. 优缺点
Bloom Filter 优点:
1、空间效率高,所占内存小。
2、查询时间短。
Bloom Filter 缺点:
1、元素添加到集合中后,不能被删除。
2、存在误判。
2.2. Counting Bloom Filter
Bloom Filter 有个缺点:元素添加到集合中后,不能被删除。
Counting Bloom Filter 克服了上述问题,它将标准 Bloom Filter 位数组的每一比特位扩展为一个小的计数器(Counter),在插入元素时给对应的 \(k\) ( \(k\) 为哈希函数个数)个 Counter 的值分别加 1,删除元素时把对应的 \(k\) 个 Counter 的值分别减 1。Counting Bloom Filter 通过多占用几倍的存储空间的代价,给 Bloom Filter 增加了删除操作。
Counting Bloom Filter 原理如图 2 所示(上一排是 Bloom Filter,下一排是 Counting Bloom Filter)。
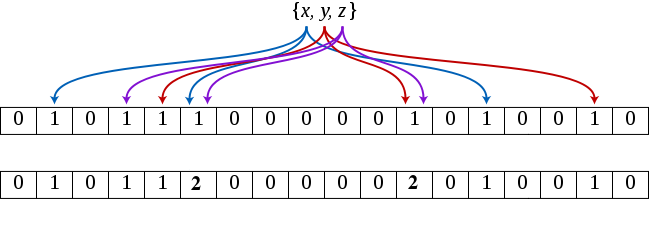
Figure 2: Counting Bloom Filter(用 Counter 代替“0/1 比特位”)
2.3. Cuckoo Filter
Cuckoo Filter 于 2014 年提出,它相对于 Bloom Filter 的最大优点是: Cuckoo Filter 支持元素的删除操作。 当然,Cuckoo Filter 还宣称比 Bloom Filter 的错误率更低,内存占用更少。这里不详细介绍它。
3. Cardinality
Cardinality 是指“集合中的不同元素的个数”。
3.1. HyperLogLog
问题:统计网页中的一个链接,每天有多少用户点击(同一个用户的反复点击仅记为 1 次)。
这个问题可以抽象为:如何统计集合中不同元素的个数。当数据量不大时,用 HashMap,Set 等数据结构就能解决;当数据量很大时,内存不足以保证所有元素,这时问题变得麻烦了。如果不要求精确统计,则可以使用下面介绍的 HyperLogLog 算法。
HyperLogLog 原始论文:HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm
3.1.1. 基本思想
考虑下面“抛硬币”实验。硬币有“正反”(后面用 0/1 分别表示正/反面)两面,抛向地面,正反两面出现的概率都是 50%。
只要出现了正面,就记为一次实验。 \(n\) 次实验中,把扔出连续的反面的最大值记为 \(k_{max}\) 。
下面是 \(n=2\) 次实验的可能结果:
1 0 1
连续反面最多出现 1 次,即 \(k_{max}=1\) 。
下面是 \(n=5\) 次实验的可能结果:
0 1 0 1 1 0 0 1 1
连续反面最多出现 2 次,即 \(k_{max}=2\) 。
显然, \(n\) 越大时时, \(k_{max}\) 往往也越大。如果已知 \(k_{max}\) ,我们可以大概估计出 \(n\) 。比如,如果你最多只有 2 次扔出连续的反面,那我猜你进行“抛硬币”实验的次数不多;但如果你最多有 10 次扔出连续的反面,那我猜你进行“抛硬币”实验的次数比较多。 它们之间大致有下面关系:
\[n = 2^{k_{max}+1}\]
按照这个公式,当最多有 2 次扔出连续的反面时(即出现一次序列 001 时),我们估计你可能进行了 8 次实验;当最多有 10 次扔出连续的反面时,我们估计你可能进行了 2048 次实验。
求集合不同元素个数和上面实验有什么关系呢? 每个元素 \(x\) ,使用哈希函数 \(hash(x)\) 将 \(x\) 转换为“随机比特串”。 假设集合中加入了下面比特串:
01xxxxxx 01xxxxxx 1xxxxxxx 001xxxxx 01xxxxxx
统计得到,前缀中连续 0 最多出现 2 个,那么我可估计集合中元素个数不会太多。
3.1.2. 减少误差:分桶
前面介绍的做法,其误差比较大,容易受到突发事件(比如突然连续抛出好多 0)的影响,HyperLogLog 算法的重点在于研究如何减小这个误差。
最简单的一种优化方法显然就是把数据分成 \(m\) 个均等的部分,分别估计其总数求平均后再乘以 \(m\) ,称之为“分桶”。对应到前面抛硬币的例子,其实就是把硬币序列分成 \(m\) 个均等的部分,分别用之前提到的方法估计实验次数,得到 \(m\) 个估计值,对其求平均后再乘以 \(m\) ,这样就能一定程度上避免单一突发事件造成的误差。
对于计算数据流中不同元素个数问题。我们对元素哈希后得到的“随机比特串”,再按下面办法把它拆分为 \(m\) 个子流(假设 \(m=4\) )。根据前 2 个比特位对比特串进行分流:
前两个比特位如果为 00,则对应比特串放入桶 1 中(放入桶前要先去掉前两个比特位 00 );
前两个比特位如果为 01,则对应比特串放入桶 2 中(放入桶前要先去掉前两个比特位 01 );
前两个比特位如果为 10,则对应比特串放入桶 3 中(放入桶前要先去掉前两个比特位 10 );
前两个比特位如果为 11,则对应比特串放入桶 4 中(放入桶前要先去掉前两个比特位 11 )。
显然,不同的元素会位于不同的桶中,每个桶的元素个数大致相等。这 4 个估计值求平均值后,再乘以 4 可以得到一个误差更小的估计值。即集合中不同元素个数为(记为 Distinct Value, DV):
\[DV_{LL} = constant \times m \times 2^{\bar{R}}\]
这是 LogLog 算法的计算公式,constant 是修正因子,它的具体值是不定的; \(\bar{R}\) 是平均值,即 \(\bar{R} = \frac{(k_{max_1}+1) + (k_{max_2}+1) + \cdots + (k_{max_m}+1)}{m}\)
平均数容易受到大的数值的影响, HyperLogLog 采用调和平均数(Harmonic Mean)来替换上面的平均数,得到公式:
\[DV_{HLL} = constant \times m \times \frac{m}{\sum_{j=1}^{m}\frac{1}{2^{R_j}}}\]
上式中, \(R_j=k_{max_j} + 1\) 也就是随机比特串开始位置连续的 0 比特位的最多数量再加上 1 。
4. Frequency
Frequency 是指“统计实时的数据流中元素出现的频率(次数)”。
4.1. Count-Min Sketch
如何计算实时的数据流中某元素出现的次数(不要求精确)呢?如果数据流中的元素种类不是很多,则我们可以直接使用 HashMap 来统计,每出现一次元素,把其相应计算增加一即可。不过,如果数据流中的元素种类非常地多,则由于会占用内存太多,我们无法使用 HashMap 了。
如果不需要精确的计算,Count-Min Sketch 可以解决这类问题。
Count-Min Sketch 不存储所有元素的计数,仅存在元素 Hash 值的计数。其思路如下: 创建一个长度为 \(w\) 的数组 \(a\) (普通数组,不是位数组),其元素用于计数,初始值设置为 0。每遇到一个元素 \(x\) 时,计算这个元素的哈希(哈希结果是 0 到 \(w\) 之间的数字),比如哈希结果为 \(hash(x)=i\) ,则对数组索引(下标)位置为 \(i\) 的计数值增加 1 (即 \(a[hash(x)] = a[hash(x)] + 1\) )。如果要查询某元素 \(y\) 出现的次数,而直接返回 \(a[hash(y)]\) 。
显然,由于有哈希冲突(不同元素有相同哈希值),所以这种方法得到的元素出现次数会偏大。
为了降低计数误差,我们可以使用多个(如 \(d\) 个)数组,每个数组对应一个哈希函数。这样一个元素有 \(d\) 个哈希值, \(d\) 个“计数值”。如果要查询某个元素的次数时, 返回这个元素在不同数组中的“计数值中的最小值”。 如图 3(摘自:https://www.waitingforcode.com/big-data-algorithms/frequency-estimation--count-min-sketch/read) 所示,元素在 4 个数组中的计数值分别为 5,6,1,4,取最小值(即 1)作为元素出现次数的估计。
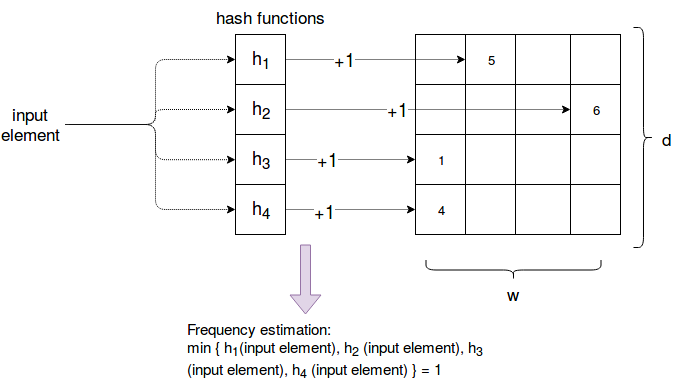
Figure 3: Count-Min Sketch 演示
注1:Count-Min Sketch 算法只会估算偏大,不会偏小。
注2:Count-Min Sketch 可以认为是 Bloom Filter 用于统计领域的变型。