Process
1. 进程简介
程序的执行实例被称为进程(process)。
注:本文很多内容直接摘自:Advanced Programming in the UNIX Environment, Second Edition
1.1. 进程标识符及其用户标识符
用 getpid 可以返回进程的 PID,用 getppid 可以返回父进程的 PID。
#include <unistd.h>
pid_t getpid(void);
/* Returns: process ID of calling process */
pid_t getppid(void);
/* Returns: parent process ID of calling process */
1.1.1. real user 和 effective user 的区别
内核将两个用户标识号(“真正用户”和“有效用户”)与一个进程相关联。它们独立于进程标识号。
- 真正用户(real user)是指“运行进程的用户”。
- 有效用户(effective user)标识号用于给新创建的文件赋所有权、检查文件的存取权限和检查通过系统调用 kill 向进程发送软中断信号的许可权限。
注:一般来说,真正用户和有效用户是同一个用户,但如果一个程序的“setuid 位”被置为 1,则进程的“有效用户”会是这个程序对应可执行文件的 owner。
参考:UNIX 操作系统设计(Maurice J.Bach, 1986), 7.6 节 进程的用户标记号
1.1.2. 获取进程用户标识符
#include <unistd.h>
uid_t getuid(void);
/* Returns: real user ID of calling process */
uid_t geteuid(void);
/* Returns: effective user ID of calling process */
gid_t getgid(void);
/* Returns: real group ID of calling process */
gid_t getegid(void);
/* Returns: effective group ID of calling process */
1.1.3. 修改进程用户标识号
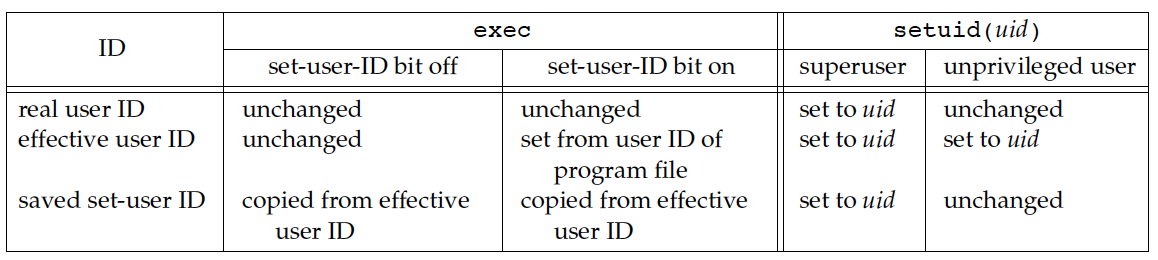
Figure 1: Ways to change the three user IDs
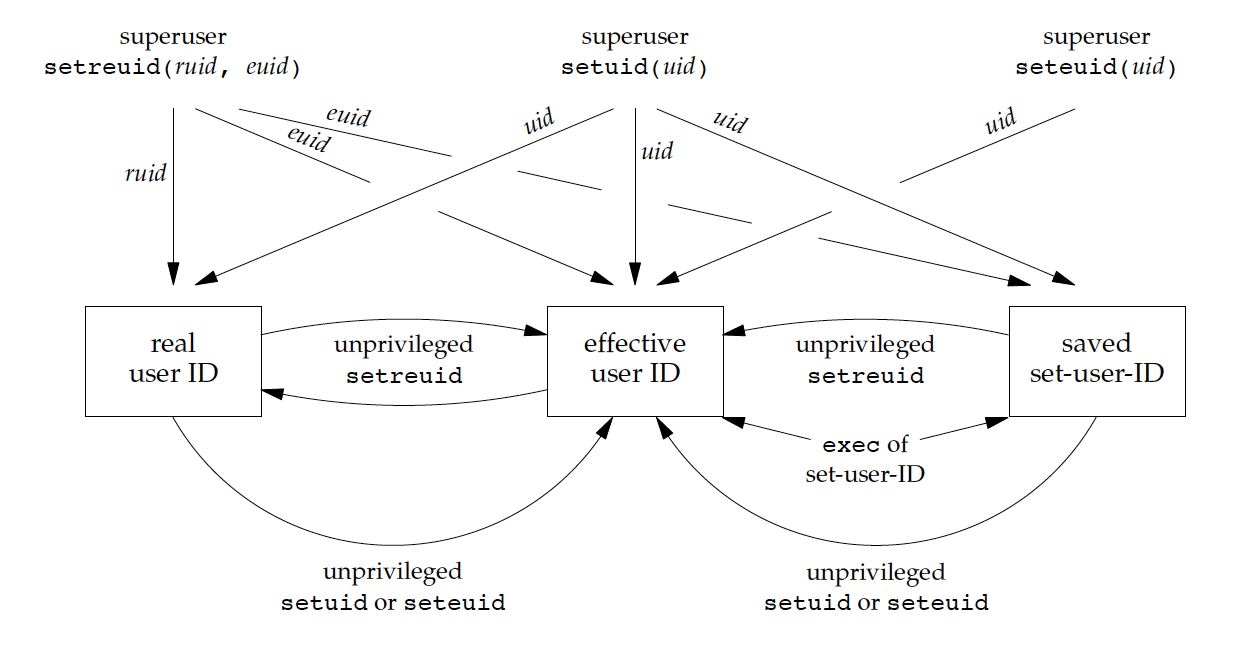
Figure 2: Summary of all the functions that set the various user IDs
通过上面的总结知,下面两种方法均可改变进程的“有效用户标识号”:
- 显示地调用系统调用
setuid/seteuid/setreuid。 - 用 exec 执行一个“setuid 位”被置为 1 的可执行程序(使用者在执行该程序时,会使用可执行程序 owner 的权限)。
例如:程序 su 就是一个“setuid 位”被置为 1 的可执行程序(它的 owner 为 root,所以使用者在执行它时将使用 root 权限)。下面'ls -l'的输出“-rwsr-xr-x”中的“s”字符就是“setuid 位”被置为 1 的标记。
$ ls -l /bin/su -rwsr-xr-x 1 root root 36936 2月 17 2014 /bin/su
2. 进程控制
进程控制有 3 个最主要函数:fork,exec 和 waitpid。
2.1. fork 函数
可以用 fork 函数来创建一个新进程(称为子进程)。
#include <unistd.h>
pid_t fork(void);
/* Returns: 0 in child, process ID of child in parent, −1 on error */
fork 函数被调用一次,但返回两次:在子进程中 fork 返回 0,在父进程中 fork 返回子进程的 PID。 子进程和父进程继续执行 fork 调用之后的指令。 子进程获得父进程数据空间、堆和栈的副本。父、子进程共享正文段。
由于 fork 之后经常跟随着 exec,所以现在的很多实现并不执行一个父进程数据段、栈和堆的完全复制。作为替代,使用了写时复制(Copy-On-Write, COW)技术。这些区域由父、子进程共享,而且内核将它们的访问权限改变为只读的。如果父、子进程中的任一个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本,通常是虚拟存储器系统中的“一页”。
fork 测试程序:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int globvar = 6; /* external variable in initialized data */
char buf[] = "a write to stdout\n";
int main(void) {
int var; /* automatic variable on the stack */
pid_t pid;
var = 88;
if (write(STDOUT_FILENO, buf, sizeof(buf)-1) != sizeof(buf)-1) {
perror("write");
}
printf("before fork\n"); /* we don’t flush stdout */
/* fflush(stdout); */
if ((pid = fork()) < 0) {
perror("fork");
} else if (pid == 0) { /* child */
globvar++; /* modify variables */
var++;
} else {
sleep(2); /* parent */
}
printf("pid = %ld, globvar = %d, var = %d\n", (long)getpid(), globvar, var);
exit(0);
}
运行上面程序,可得类似下面的输出,
$ ./a.out a write to stdout before fork pid = 1434, globvar = 7, var = 89 pid = 1433, globvar = 6, var = 88
从上面例子可以看到,子进程对变量所做的改变并不影响父进程中该变量的值(子进程获得父进程数据空间、堆和栈的副本)。
2.1.1. fork 后的文件共享
fork 的一个重要特性是父进程的所有打开文件描述符都被复制到子进程中,且共享同一个文件偏移量(就好像执行了 dup 函数)。
我们知道,两个独立进程(不是父子关系)打开同一个文件,有图 3 所示的关系。
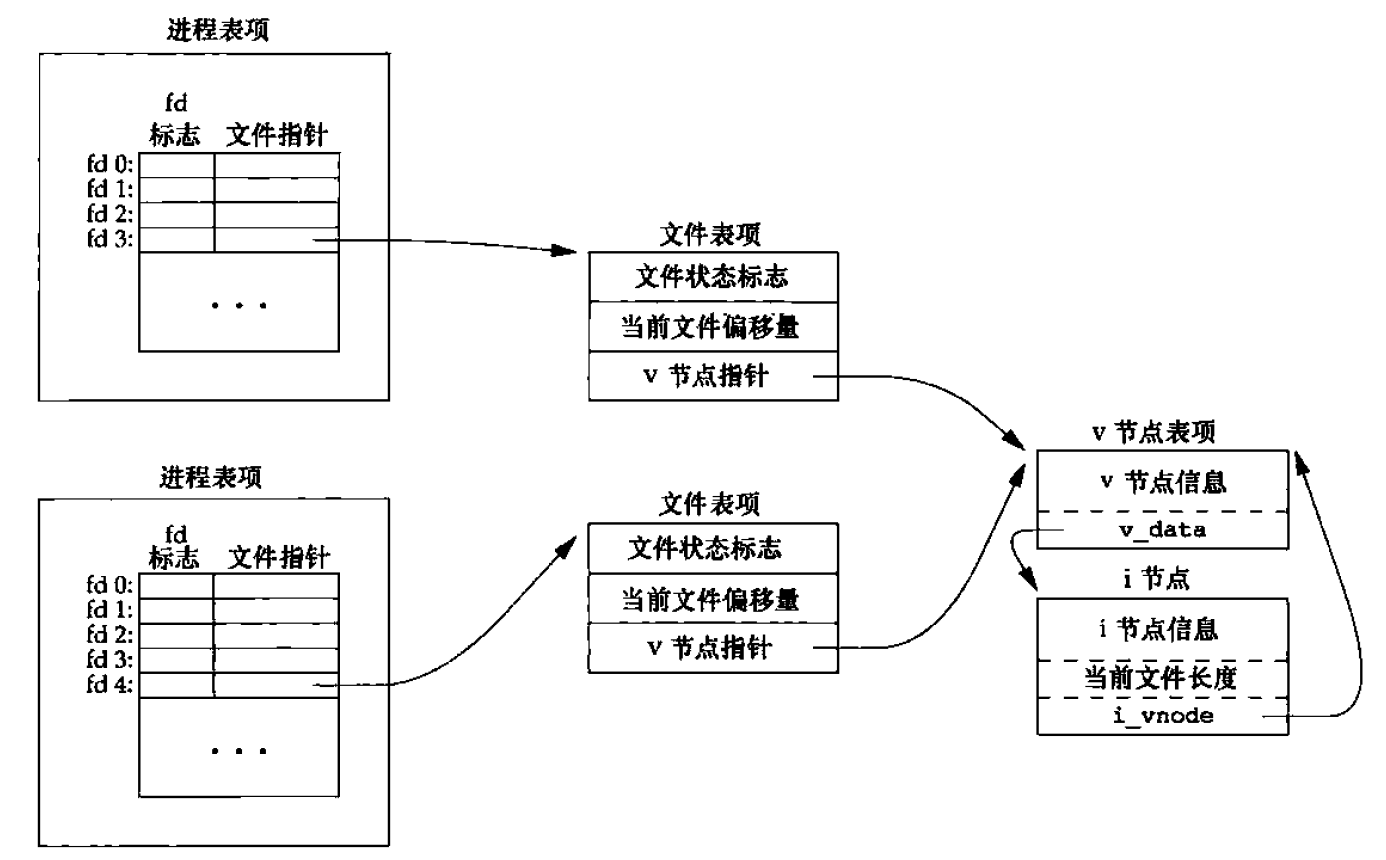
Figure 3: 两个独立进程各自打开同一个文件
假设一个进程具有 3 个不同的打开文件,它们是标准输入、标准输出和标准错误。这时调用了 fork,从 fork 返回时,有图 4 所示的关系。
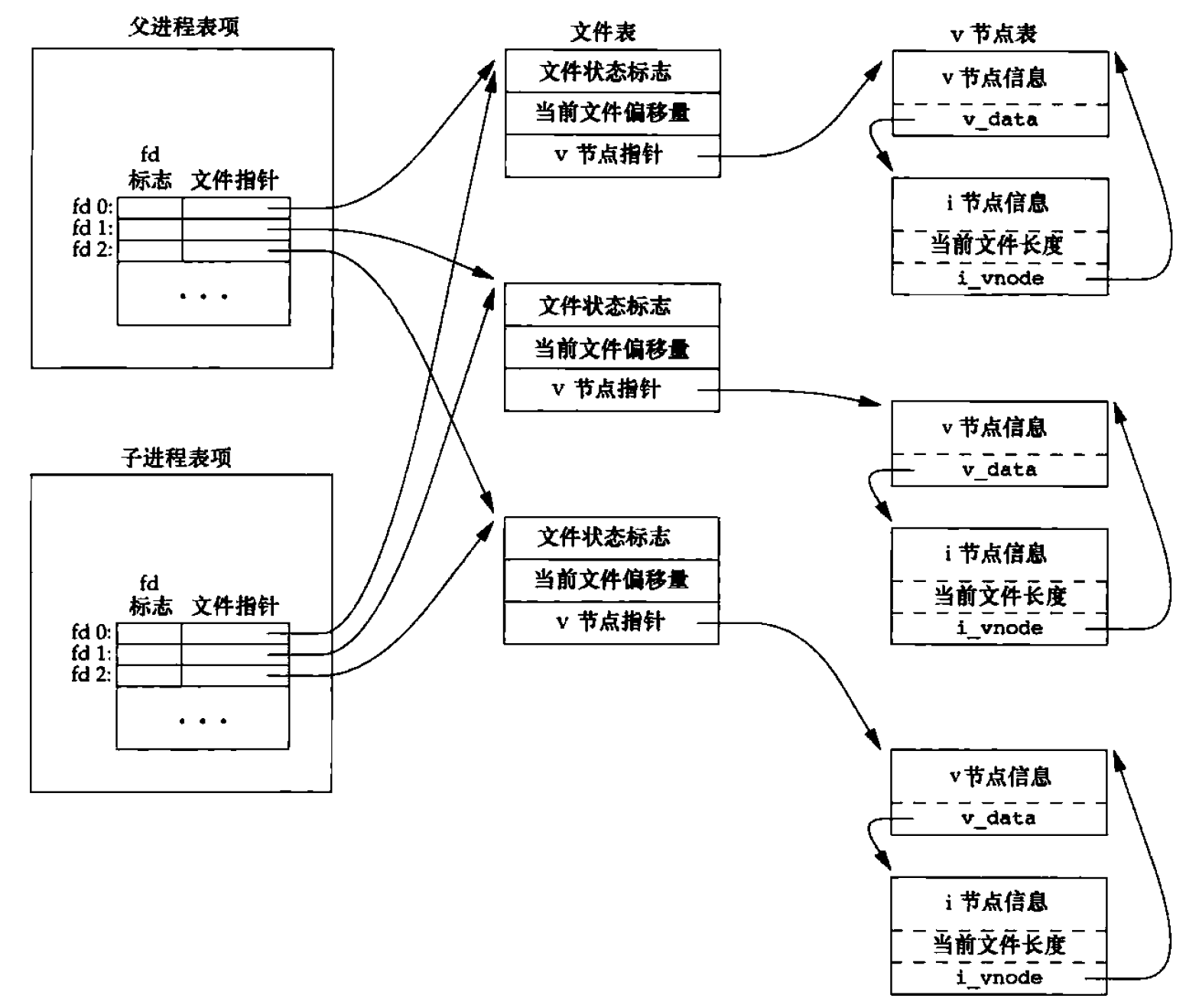
Figure 4: fork 之后父进程和子进程之间对打开文件的共享
继续测试前面的程序,把程序标准输出重定向到文件 temp.out,测试如下:
$ ./a.out > temp.out $ cat temp.out a write to stdout before fork pid = 1437, globvar = 7, var = 89 before fork pid = 1436, globvar = 6, var = 88
在这个例子中,当父进程等待子进程时,子进程写到标准输出;而在子进程终止后,父进程也写到标准输出上,并且知道其输出会追回在子进程所写数据之后。如果父进程和子进程不共享同一文件偏移量,要实现这种形式的交互就要麻烦得多。此外,我们发现当重定向标准输出到文件时“before fork”会被输出了两次(而如果直接输出到终端则只会输出一次),这是为什么呢?解释如下:标准 I/O 库是带缓冲的,如果标准输出连接到终端设备,则它是 行缓冲 的;否则它是 全缓冲 的。前面例子中当标准输出重定向到文件时,在 fork 之前调用了 printf,但当调用 fork 时,该行数据仍在缓冲区中, 在将父进程数据空间复制到子进程中时,该缓冲区数据也被复制到子进程中, 此时父进程和子进程各自有了带该行内容的缓冲区。在 exit 之前的第二个 printf 将其数据追加到已有的缓冲区中,当每个进程终止时,其缓冲区中的内容都被写到相应的文件中。
总结: 当 fork 之后,父进程和子进程应该各自关闭它们不需要使用的文件描述符,这样不会干扰对方使用的文件描述符。
2.1.2. 子进程从父进程继承和不继承哪些属性
Properties of the parent are inherited by the child:
- Open files
- Real user ID, real group ID, effective user ID, and effective group ID
- Supplementary group IDs
- Process group ID
- Session ID
- Controlling terminal
- The set-user-ID and set-group-ID flags
- Current working directory
- Root directory
- File mode creation mask
- Signal mask and dispositions
- The close-on-exec flag for any open file descriptors
- Environment
- Attached shared memory segments
- Memory mappings
- Resource limits
The differences between the parent and child are:
- The return values from fork are different.
- The process IDs are different.
- The two processes have different parent process IDs: the parent process ID of the child is the parent; the parent process ID of the parent doesn’t change.
- The child’s tms_utime, tms_stime, tms_cutime, and tms_cstime values are set to 0.
- File locks set by the parent are not inherited by the child.
- Pending alarms are cleared for the child.
- The set of pending signals for the child is set to the empty set.
参考:
Advanced Programming in the UNIX Environment, 3rd Edition, 8.3 fork Function
man fork
2.1.3. fork 多线程程序(仅调用 fork 的线程会被复制)
一个多线程程序调用 fork 时,仅调用 fork 的那个线程会被复制到子进程中。 这可能造成问题,如果其他线程(没有调用 fork 的线程)正在使用被互斥量保护的资源,而 fork 后这个线程会直接消失,造成了这个互斥量在子进程中一直不会解锁,如果再对同一个互斥量加锁的话就会死锁。
那我们把 fork 实现改为复制父进程中的所有线程到子进程中呢?问题会更多,比如某个线程正阻塞在某个系统调用上,那么得想办法让这个系统调用不在子进程中执行。
The general problem with making fork() work in a multi-threaded world is what to do with all of the threads. There are two alternatives. One is to copy all of the threads into the new process. This causes the programmer or implementation to deal with threads that are suspended on system calls or that might be about to execute system calls that should not be executed in the new process. The other alternative is to copy only the thread that calls fork(). This creates the difficulty that the state of process-local resources is usually held in process memory. If a thread that is not calling fork() holds a resource, that resource is never released in the child process because the thread whose job it is to release the resource does not exist in the child process.
摘自:http://pubs.opengroup.org/onlinepubs/9699919799/functions/fork.html
注 1:在多线程程序中使用 fork,有一些需要注意的情况,可参考: Threads and fork(): think twice before mixing them.
注 2: 在多线程程序中调用 fork 后,在执行 exec 前不要调用异步信号不安全的函数(比如 printf 等),最安全的办法是立即执行 exec。
2.2. exec 函数
用 fork 函数创建新的子进程后,子进程往往要调用一种 exec 函数来执行另一个程序。当进程调用一种 exec 函数时,该进程执行的程序完全替换为新程序,而新程序则从其 main 函数开始执行。因为调用 exec 并不创建新进程,所以进程的 PID 并不会改变。 exec 只是用磁盘上的一个新程序替换了当前进程的正文段、数据段、堆段和栈段。
有 6 种不同的 exec 函数可供使用,它们常常被统称为 exec 函数。
#include <unistd.h>
int execl(const char *pathname, const char *arg0, ... /* (char *)0 */ );
int execv(const char *pathname, char *const argv[]);
int execle(const char *pathname, const char *arg0, ... /* (char *)0, char *const envp[] */ );
int execve(const char *pathname, char *const argv[], char *const envp[]);
int execlp(const char *filename, const char *arg0, ... /* (char *)0 */ );
int execvp(const char *filename, char *const argv[]);
/* All seven return: −1 on error, no return on success */
这些函数的区别在于其参数形式不同。如前面 4 个函数取路径名作为参数,而后面 2 个函数取文件名作为参数。记住这些 exec 函数比较困难,函数名中的字符可以给我们一些帮助:
- 字母 p 表示该函数取 filename 作为参数,并且用 PATH 环境变量寻找可执行文件;
- 字母 l 表示该函数取一个参数表,它与字母 v 互斥;
- 字母 v 表示该函数取一个 argv[] 矢量,它与字母 l 互斥;
- 字母 e 表示该函数取 envp[] 数组,而不使用当前环境。
一般来说,只有 execve 是内核中的系统调用,其他 5 个都是调用 execve 实现的库函数。
2.2.1. FD_CLOEXEC 描述符标志
进程在调用 exec 后,之前打开着的描述符通常跨 exec 继续保持打开。但如果描述符设置了 FD_CLOEXEC 标志(可以在 open 时指定,或者通过 fcntl 设置),则在执行 exec 时对应的描述符会被关闭。
2.3. waitpid 函数
当一个进程正常或异常终止时,内核会向其父进程发送 SIGCHLD 信号。 因为子进程终止是异步事件(这可以在父进程运行的任何时候发生),所以这种信号也是内核向父进程发的异步通知。父进程可以选择忽略该信号(这个信号的默认动作就是忽略它),或者提供一个该信号发生时被调用的函数(即信号处理函数)。
内核为每个“终止的子进程”保存了一些信息(如它的终止状态),当父进程调用 wait 或 waitpid 时,可以得到这些信息。 如果子进程终止了,但父进程没有调用 wait 或 waitpid,则子进程就变成了所谓的 zombie process。
#include <sys/wait.h>
pid_t wait(int *statloc);
pid_t waitpid(pid_t pid, int *statloc, int options);
/* Both return: process ID if OK, 0 (see later), or −1 on error */
调用 wait 或 waitpid 的进程可能发生的行为如下:
(1) 如果它的所有子进程都还在运行,则阻塞(waitpid 有一个选项,可以使调用者不阻塞);
(2) 如果一个子进程已终止,正等待父进程获取其终止状态,则取得子进程的终止状态立即返回;
(3) 如果它没有任何子进程,则立即出错返回。
waitpid 的提供的功能比 wait 多,这两个函数的主要区别如下:
- 在一个子进程终止前,wait 使其调用者阻塞,而 waitpid 有一选项,可使调用者不阻塞。
- waitpid 有选项设置,可以控制它所等待的进程。
| 参数 pid 的值 | 说明 |
|---|---|
| pid == -1 | 等待任一子进程。这个情况下,waitpid 和 wait 等效。 |
| pid > 0 | 等待进程 ID 与 pid 相等的子进程。 |
| pid == 0 | 等待组 ID 等于调用进程组 ID 的任一子进程(进程组的概念后文将说明)。 |
| pid < -1 | 等待组 ID 等于 pid 绝对值的任一子进程。 |
2.3.1. 明确忽略 SIGCHLD 信号可阻止子进程变为 zombie
Explicitly setting the disposition of SIGCHLD to SIG_IGN causes any child process that subsequently terminates to be immediately removed from the system instead of being converted into a zombie.
注 1:SIGCHLD 的默认动作就是忽略,但仅当显式忽略它时才会使子进程终止时彻底消失,而不会成为 zombie(这样无需调用 wait 或 waitpid 了)。
注 2:这个行为在比较老的 UNIX 实现中可能无效。
参考:The Linux Programming Interface, 26.3.3 Ignoring Dead Child Processes
3. 进程关系
3.1. 进程组
每个进程除了有一进程 ID 之外,还属于一个进程组,每个进程组有一个唯一的进程组 ID。 进程组是一个或多个进程的集合。通常,它们是在同一作业中结合起来的,同一进程组中的各进程接收来自同一终端的各种信号。
用 getpgrp() 或者 getpgid(0) 可以得到自己的进程组 ID。
#include <unistd.h>
pid_t getpgrp(void);
/* Returns: process group ID of calling process */
pid_t getpgid(pid_t pid);
/* Returns: process group ID if OK, −1 on error */
进程调用 setpgid 可以加入一个现有的进程组或者创建一个新进程组。一个进程只能为它自己或它的子进程设置进程组 ID。
#include <unistd.h>
int setpgid(pid_t pid, pid_t pgid);
/* Returns: 0 if OK, −1 on error */
每个进程组有一个“组长进程”。 组长进程的“进程组 ID”等于其“进程 ID”。
3.1.1. 进程组实例
通常,shell 的管道会将几个进程编成一组。
进程组测试实例:
$ sleep 3 | sleep 3 & [1] 1888 $ ps -o pid,pgid,sid,cmd PID PGID SID CMD 1339 1339 1339 -bash 1887 1887 1339 sleep 3 1888 1887 1339 sleep 3 1889 1889 1339 ps -o pid,pgid,sid,cmd
在上面例子中,可以看到两个 sleep 属于同一个进程组(进程组 ID 为 1887)。
3.2. 会话(session)
会话(session)是一个或多个进程组的集合。
下面是一个会话中的进程安排的实例。
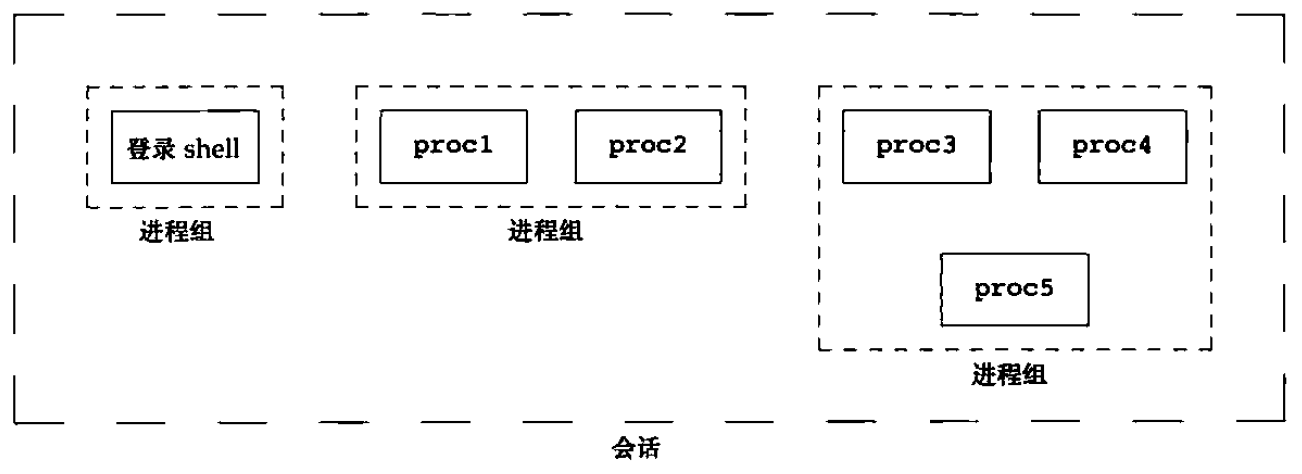
Figure 5: 实例:进程组和会话中的进程安排
shell 的管道会将几个进程编成一组,上面实例可能是由下列形式的 shell 命令形成的:
$ proc1 | proc2 & $ proc3 | proc4 | proc5 &