Raft
Table of Contents
1. Raft
Raft 是一种分布式共识算法。它可以用来替代 Paxos 算法,而且 Raft 算法比 Paxos 算法更易懂、更容易实现。
参考:
In Search of an Understandable Consensus Algorithm (原始论文)
Visualization of Raft: http://thesecretlivesofdata.com/raft/
1.1. 问题描述
什么是分布式共识呢?假设有一个分布式 key-value 存储系统,它有多台(如 10 台)服务器组成集群共同提供服务,有很多 client 往这个分布式系统中写数据,如何确保这 10 台服务器上的数据是一致的?这就是分布式共识问题。
1.2. 节点状态(Follower/Candidate/Leader)
每个节点可以处于下面三种状态中的一种:
- Follower
- Candidate
- Leader
1.3. 任期(Term)
Raft 算法将时间划分成为不同长度的任期(Term),如图 1 所示。任期用连续的数字进行表示。每一个任期的开始都是一次选举(election),一个或多个 Candidate 会试图成为 Leader。如果一个 Leader 赢得了选举,它就会在该任期的剩余时间担任 Leader。在某些情况下,选票会被瓜分,有可能没有选出 Leader,那么,将会开始另一个任期,并且立刻开始下一次选举。 Raft 算法可保证在给定的一个任期最多只有一个 Leader。Leader 在它宕机之前会一直保持 Leader 的状态。
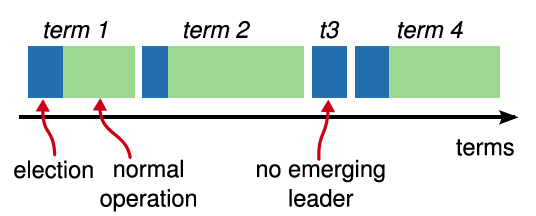
Figure 1: Time is divided into terms, and each term begins with an election.
2. Raft 算法简介
Raft 算法的基本描述为:Client 只能向 Leader 发送更新请求(这和 Paxos 是不同的,在 Paxos 算法中 Client 可向任一节点发送更新请求),Leader 等待大多数其它节点(即 Follower)都完成修改后,再返回给 Client,并提交 Log。然后 Leader 负责把已经提交的 Log 复制到所有其他节点中。
从上面的描述中可知, Raft 有两个基本过程:“Leader Election”(决定哪个节点是 Leader)和“Log Replication”。
2.1. Leader Election
Leader Election 的基本过程为:
1、系统刚开始运行时,大家都是 Follower,没有 Leader,也没有 Candidate;
2、如果 Follower 在一段时间(称为 ElectionTimeout,例如每个结点设置为 150ms 到 300ms 内的一个随机数)内没有收到 Leader 发送的心跳消息,则 Follower 自己变为 Candidate;
3、Candidate 发送 Request Vote 消息给其它节点;
4、其它节点在一个给定任期内有一次投票权,它按照先来先服务(first-come-first-served)的原则把选票投给它收到的第一个 Request Vote 消息所对应的 Candidate;
5、如果 Candidate 收到大多数节点的选票,则 Candidate 就变为了 Leader;
6、如果选举后,没有一个 Candidate 收到大多数节点的选票,则重新进行一次选举。
2.2. Log Replication
所有的写操作必需通过 Leader 进行,接受 Client 端命令的过程:
1、Leader 接受 Client 请求;
2、Leader 把指令追加到日志(日志目前还没有 Commit);
3、Leader 通过 AppendEntries RPC 把未提交的日志发送到 Follower;
4、Leader 收到“大多数”Follower 的确认后,才 Commit 该日志,把日志在状态机中回放,并返回结果给 Client;
提交 Log 到 Follower 过程:
1、在下一个心跳阶段,Leader 再次发送 AppendEntries RPC 给 Follower,告诉它们日志已经 Commited;
2、Follower 收到 Commited 日志后,将日志在状态机中回放,这样 Follower 中数据和 Leader 中一致。
说明:Raft 不是一种强一致性算法,它只需要大多数的 Follower 确认后就可以返回给 Client 端。而微软设计的 PacificA 是一种强一致性算法,它需要所有的“从节点”返回成功后“主节点”才返回给 Client 端。
2.3. Membership Changes
除了前面介绍的“Leader Election”和“Log Replication”过程外,Raft 的完整实现一般还应具备处理集群成员的变更(Membership Changes)的情况。
集群成员的变更和成员的宕机与重启不同,因为前者会修改成员个数进而影响到领导者的选取和决议过程,一旦节点个数发生变化,判断“大多数节点”就不同了。当然,可以简单地让运维人员将系统临时下线,修改配置,重新上线,但这往往不可取,因为它会使系统暂时不可用。这里不介绍Raft是如何处理“Membership Changes”的,请参考原始论文。