Redis
Table of Contents
1. Redis 简介
REmote DIctionary Server(Redis) 是一个 C 语言实现的开源 key-value 数据库。
1.1. Redis 安装
下载和编译过程:
$ curl -O http://download.redis.io/releases/redis-4.0.0.tar.gz $ tar xzf redis-4.0.0.tar.gz $ cd redis-4.0.10 $ make
上面命令成功完成后,会在 src 目录中生成下面这些可执行程序:
redis-server # Redis服务器 redis-cli # Redis命令行客户端 redis-benchmark # Redis性能测试工具 redis-check-aof # AOF文件检测工具 redis-check-rdb # RDB文件检测工具 redis-sentinel # Sentinel服务器,4.0开始和redis-server是同一文件,使用--sentinel指定为哨兵
1.1.1. 简单测试
启动 Redis Server:
$ ./src/redis-server # 默认监听在本机的6379端口
使用内置的 client,测试如下:
$ ./src/redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> SET foo bar OK 127.0.0.1:6379> GET foo "bar" 127.0.0.1:6379> EXPIRE foo 10 (integer) 1
命令 EXPIRE 用于设置过期时间。
1.2. 查看命令帮助
使用 help COMMAND 可以查看命令的在线帮助文档。如:
127.0.0.1:6379> help del DEL key [key ...] summary: Delete a key since: 1.0.0 group: generic
使用 help @GROUP 可以查看一组命令的相关帮助文档。如:
127.0.0.1:6379> help @hash HDEL key field [field ...] summary: Delete one or more hash fields since: 2.0.0 HEXISTS key field summary: Determine if a hash field exists since: 2.0.0 HGET key field summary: Get the value of a hash field since: 2.0.0 ......
下面一些 GROUP 名称:
generic # 一般命令 string # 字符串类型命令 list # 列表类型命令 set # 集合类型命令 sorted_set # 有序集合命令 hash # hash操作命令 pubsub # 发布命令 transactions # 事务操作命令 connection # 连接相关命令 server # 服务器相关命令 scripting # 脚本相关命令 hyperloglog # hyperloglog类型命令 cluster # 集群相关命令 geo # 经纬度相关命令
1.3. Redis 应用场景
Redis 应用场景很广泛,如缓存、分布式集群中的 session 共享、统计排行榜(使用 Sorted Sets)、网站点击量统计等等。
1.4. Redis VS. Memcached
相比于 Memcached,Redis 主要有下面优点:
- 提供了丰富的数据类型;
- 可以持久化内存数据到磁盘,提供了 AOF 和 RDB 两种持久化机制(Memcached 不支持持久化)。
2. Redis 数据类型
Redis 支持的主要数据类型有 5 种:string、list、hash、set、sorted_set。
使用 type 命令可以查看 key 对应 value 的类型。如:
127.0.0.1:6379> set foo abc OK 127.0.0.1:6379> get foo "abc" 127.0.0.1:6379> type foo string
2.1. String
String 是 Redis 中最基本的类型,且它是二进制安全的(可以保存二进制数据,如图片等)。
2.2. List
Redis List 的常用操作如表 1 所示。
| 命令 | 描述 |
|---|---|
| lpush | 从头往 list 中增加元素 |
| rpush | 从尾往 list 中增加元素 |
| lpop | 弹出第 1 个元素,没有元素时返回 nil |
| rpop | 弹出最后 1 个元素,没有元素时返回 nil |
| lindex | 获取指定下标的元素,如 lindex key1 0 是查看首个元素 |
| lset | 设置指定下标的元素 |
| llen | 查看 list 中元素个数 |
| lrange | 查看 list 中某个区间的元素,如 lrange key1 0 -1 是查看所有元素 |
| ltrim | 删除 list 中元素,只留下指定区间元素 |
| blpop | lpop 命令的 blocking 版本。弹出第 1 个元素,没有元素时将阻塞 |
| brpop | rpop 命令的 blocking 版本。弹出最后 1 个元素,没有元素时将阻塞 |
2.3. Hash
Redis Hash 常用操作如表 2 所示。
| 命令 | 描述 |
|---|---|
| hmset | 创建 hash 表 |
| hset | 修改或创建 hash 表 |
| hget | 获取 hash 表中元素 |
| hmget | 获取 hash 表中指定的多个元素 |
| hgetall | 获取 hash 表中所有元素 |
| hdel | 删除 hash 表中指定元素 |
2.4. Set
Set 是 Strings 的集合(无序的),它的常用操作如表 3 所示。
| 命令 | 描述 |
|---|---|
| sadd | 往 set 中增加元素 |
| smembers | 查看 set 中所有元素(不要依赖返回结果的顺序) |
| sismember | 测试元素是否存在于集合中 |
| scard | 求集合元素个数 |
| srem | 删除集合中元素 |
| sinter/sinterstore | 求交集 |
| sunion/sunionstore | 求并集 |
| sdiff/sdiffstore | 求差集 |
2.5. Sorted Set
Sorted Set 是 Strings 的有序集合,它的常用操作如表 4 所示。
| 命令 | 描述 |
|---|---|
| zadd | 往有序集合中增加元素,增加元素时要同时指定“分数”和“元素名称” |
| zcard | 求有序集合元素个数 |
| zrem | 删除有序集合中元素 |
| zrange | 查看有序集合某个区间的元素,如 zrange zz 0 -1 withscores 可查看有序集合 zz 中所有元素及其分数 |
| zrangebyscore | 按“分数”对元素进行排序(常用它实现排行榜等功能) |
2.5.1. 设置集合元素的过期时间
目前,redis 中的过期时间只能设置在 key 上,无法直接地为集合元素设置过期时间。
不过,使用 Sorted Set 可以实现元素的过期时间:元素加入 Sorted Set 时指定当前时间为它的 score,获取元素时分数小于“读取时的时间减去过期时间”的那些元素就认为是已经过期了。
2.5.2. 实现延迟队列
使用 redis zset 可以实现延迟队列,思想如下:
1、加入元素时,将其 score 设置为过期的时间点;
2、启动线程不断取出排序后第一个元素,比较其 score 和当前时间点,如果 score 小于或等于当前时间,则说明已经到期了,需要处理;
3、处理完毕在 zset 中移除元素
2.6. Bit Array (Bitmap)
位图(Bitmap)不是一个“新数据类型”,它用 String 实现,用 String 的每一个“比特位”来表示元素的一种状态。Redis 中 String 的最大长度为 512 MB,即有 \(512 \times 1024 \times 1024 \times 8 = 2^32\) 个(这个数大于 42 亿)比特位。
由于以比特为单位来存储数据,所有它非常节省内存。比如, 我们要记录 42 亿用户的在线状态,使用 512 MB 内存就足够了(每个用户占用一个比特位,比特位上用 0 和 1 分别表示“不在线”和“在线”)。
Bitmap 的常用操作如表 5 所示。
| 命令 | 描述 |
|---|---|
| SETBIT | 设置比特位为 0 或者 1 |
| GETBIT | 获取比特位中的值 |
| BITOP | 位图运算,支持 AND, OR, XOR and NOT 操作 |
| BITCOUNT | 返回置为了 1 的比特位个数 |
| BITPOS | 返回字符串里面第一个被设置为 0 或者 1 的比特位 |
2.7. HyperLogLog
HyperLogLog 是一种“Probabilistic Data Structure”,它用于“估计集合中元素的个数”。 集合中元素个数直接使用 Redis 命令 SCARD 不就行了吗?SCARD 不仅时间复杂度为 \(O(1)\) ,而且计算还是精确的。
HyperLogLog 主要用于“大数据”场景。当集合元素非常多时,内存中可能根本放不下这么多的元素,所以无法使用 HashMap 等数据结构,甚至 BitMap 占用的内存也太大而无法使用。这时如果不要求统计绝对精确,则可以使用 HyperLogLog 。
HyperLogLog 有下面特点:
1、极少的内存可以统计极大的数据。在 Redis 的 HyperLogLog 实现中,只需要 12K 内存就能统计出实际应用中任意大集合(其实是不超时 \(2^{64}\) ,基本上不会有集合超过这个限制)中的元素个数。
2、统计不是精确的,误差率整体较低,标准误差为 0.81%。
HyperLogLog 的常用操作如表 6 所示。
| 命令 | 描述 |
|---|---|
| PFADD | 增加计数 |
| PFCOUNT | 获取计数 |
| PFMERGE | 合并多个计数(比如把 30 个日活数据变为一个月活数据) |
注:上面命令都有前缀“PF”,它是 HyperLogLog 算法发明者 Philippe Flajolet 的首字母缩写。
Redis Best Practices 中有一个 HyperLogLog 的应用实例,请参考:https://redislabs.com/redis-best-practices/counting/hyperloglog/
2.7.1. 热点链接的点击量统计
假设有任务:统计网页中一个链接,每天有多少用户点击。同一个用户的反复点击只记为 1 次。
这个任务使用 HyperLogLog 来实现很简单。比如,统计今天(20171101)的用户点击:
> PFADD url1:20171101 ip_of_user1 > PFADD url1:20171101 ip_of_user2 > PFADD url1:20171101 ip_of_user3 > ...... > PFCOUNT url1:20171101 (integer) 13875631
统计日期 20171102 内的用户点击:
> PFADD url1:20171102 ip_of_user1 > PFADD url1:20171102 ip_of_user2 > PFADD url1:20171102 ip_of_user3 > ...... > PFCOUNT url1:20171102 (integer) 12841153
一个月的点击量可以通过 PFMERGE 实现:
> PFMERGE url1:20171101 url1:20171102 url1:20171103 ...... url1:20171130 (integer) 381517621
这个任务使用 Bitmap 是非常消耗内存的。这个例子中,仅仅是统计一个链接,如果要统计 1000 个链接,且都是热点链接呢,这时 Bitmap 的内存消耗是巨大的。而 HyperLogLog 仅需要 1000 乘以 12K 的内存,优势十分明显。
3. Redis 事务
Redis 中的事务(transaction)是一组命令的集合。 Redis 事务的实现需要 MULTI 和 EXEC 两个命令,事务开始的时候先向 Redis 服务器发送 MULTI 命令,然后依次发送需要在本次事务中处理的命令,最后再发送 EXEC 命令表示事务命令结束。
下面是事务的基本使用实例:
127.0.0.1:6379> MULTI OK 127.0.0.1:6379> INCR foo QUEUED 127.0.0.1:6379> INCR bar QUEUED 127.0.0.1:6379> EXEC 1) (integer) 1 2) (integer) 1 127.0.0.1:6379> GET foo "1" 127.0.0.1:6379> GET bar "1"
从上面输出中可以看到,当输入 MULTI 命令后,服务器返回 OK 表示事务开始成功,然后依次输入需要在本次事务中执行的所有命令,每次输入一个命令服务器并不会马上执行,而是返回“QUEUED”,这表示命令已经被服务器接受并且暂时保存起来,最后输入 EXEC 命令后,本次事务中的所有命令才会被依次执行,可以看到最后服务器一次性地返回了 2 行输出,分别对应事务中的两条命令的输出。
3.1. 原子性
Redis 事务具有原子性,一个事务中的命令要么都执行,要么都不执行。
如果一个事务中的某个命令执行出错,Redis 会怎样处理呢?要分情况讨论。
1、 某个命令出错是语法错误,这时所有命令都不执行。 语法错误表示命令不存在或者参数错误,这种情况需要区分 Redis 的版本,Redis 2.6.5 之前的版本会忽略错误的命令,执行其他正确的命令,2.6.5 之后的版本会忽略这个事务中的所有命令,都不执行。
2、 某个命令出错是运行错误,这时所有命令还是会都执行。 运行错误表示命令在执行过程中出现错误,比如用 GET 命令获取一个 Hash 类型的键值(注:GET 操作 string 类型,Hash 类型应该使用 HGET)。这种错误在命令执行之前 Redis 是无法发现的,所以在事务里这样的命令会被 Redis 接受并执行。如果事务里有一条命令执行错误,其他命令依旧会执行(包括出错之后的命令)。
Redis 中的事务没有回滚(rollback)功能,对于上面的情况 2,使用者必须自己收拾剩下的烂摊子。
3.2. 隔离性
Redis 的事务能保证一个事务中的几个命令会依次执行而不会被其他命令插入。试想一个客户端 A 需要执行几条命令,同时客户端 B 发送了几条命令,如果不使用事务,则客户端 B 的命令有可能会插入到客户端 A 的几条命令中,如果想避免这种情况发生,也可以使用事务。
3.3. WATCH(可实现 CAS 语义,实现“乐观锁”)
WATCH 命令为 Redis 事务提供了 CAS(check-and-set)语义。
假设我们要实现一个 value“原子地增加 1”(假设 Redis 中还没有 INCR 命令),自然地可以想到下面伪代码:
val = GET mykey val = val + 1 SET mykey $val
上面代码,当存在多个 client 同时执行时会出问题。比如 client A 和 client B 都执行上面代码,且两个 client 执行完第一行语句后(读到的 mykey 值相同,假设为 10)才执行第二条语句,则两个 client 结束后 mykey 会为 11,而我们希望的结果却是 12。
有了 WATCH 命令,我们可以安全地完成上面任务了:
WATCH mykey val = GET mykey val = val + 1 MULTI SET mykey $val EXEC
WATCH 可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到 EXEC 命令。注:事务中的命令是在 EXEC 之后才执行的,EXEC 命令执行完之后被监控的键会自动被 UNWATCH。
对于前面说到的两个 client 同时执行的情况,并发时,有一个事务不会执行。
下面是 watch 的演示实例:
127.0.0.1:6379> set key1 100 OK 127.0.0.1:6379> watch key1 OK 127.0.0.1:6379> set key1 200 # 它会导致下面的事务不会执行(这个set命令也可以来自其它client) OK 127.0.0.1:6379> multi OK 127.0.0.1:6379> set key1 300 QUEUED 127.0.0.1:6379> exec # exec返回了nil,说明事务中的命令set key1 300并没有执行 (nil) 127.0.0.1:6379> get key1 "200"
上面的例子中,由于 watch 的键 key1 在事务执行之前被修改了,所以事务中所有命令都不会执行。
3.4. UNWATCH
UNWATCH 命令可以在 WATCH 命令执行之后、MULTI 命令执行之前取消对某个键的监控。如:
127.0.0.1:6379> set key1 100 OK 127.0.0.1:6379> watch key1 OK 127.0.0.1:6379> set key1 200 OK 127.0.0.1:6379> unwatch OK 127.0.0.1:6379> multi OK 127.0.0.1:6379> set key1 300 QUEUED 127.0.0.1:6379> exec 1) OK 127.0.0.1:6379> get key1 "300"
上面的例子中,首先设置 key1 的键值为 100,然后使用 WATCH 命令监控 key1,随后更改 key1 的值为 200,然后取消对 key1 的监控,再进入事务,事务中设置 key1 的值为 300,然后执行 EXEC 运行事务中的命令,最后使用 get 命令查看 key1 的值(是 300),也就是说事务中的命令运行成功。
注:UNWATCH 命令的使用场景比较少,因为 在执行 EXEC 或者 DISCARD 命令后,被监控的键会被自动 UNWATCH。
3.5. DISCARD 命令(从事务状态中退出)
DISCARD 命令可以在 MULTI 命令执行之后,EXEC 命令执行之前取消 WATCH 命令并清空事务队列,然后从事务状态中退出。
执行 DISCARD 前,当前环境要在事务状态中(即之前需要执行过 MULTI);执行完 DISCARD 后,已经了退出了事务状态,不能再执行 EXEC 命令了。
4. Redis DB
默认地,Redis 服务器在启动时,会创建 16 个 DB,编号分别为 0,1,2,...,15,当前 DB 默认是编号为 0 的 DB。如果你想修改 DB 的总数(如修改为 8 个 DB),可以在配置文件 redis.conf 中指定:
# Set the number of databases. databases 8
4.1. DB 相关命令
DB 相关命令如表 7 所示。
| 命令 | 描述 |
|---|---|
| dbsize | 返回当前 DB 中键的个数 |
| select <db-index> | 切换 DB |
| swapdb <db-index1> <db-index2> | 交换两个 DB 的内容 |
| flushdb | 删除当前 DB 的所有内容 |
| flushall | 删除所有 DB 的所有内容 |
4.2. 查看当前 DB 所有的键(KEYS *)
使用 keys pattern 命令可以查看满足 pattern 的所有 key。如 keys * 可以查看当前 DB 的所有 key。
4.2.1. 线上系统谨慎使用 KEYS 命令
如果 Redis 当前 DB 中的 key 非常多, keys 命令会导致 Redis 服务器响应很慢,这会影响到其它业务。所以,线上系统谨慎使用 keys 命令。
4.2.2. 禁止 KEYS 等危险命令(rename-command)
为了避免在线上系统中不小心执行了 keys, flushdb, flushall 等危险命令,可以在 redis.conf 把这些危险命令重命名为空字符串,如:
rename-command KEYS "" rename-command FLUSHDB "" rename-command FLUSHALL "" rename-command CONFIG ""
4.2.3. 使用 SCAN 遍历所有键
既然使用 KEYS 命令查看 Redis 中所有的键是危险的,那怎么才能安全地查看 Redis 中所有的键呢?答案是 SCAN 命令。每次执行 SCAN 都会从数据库里返回一部分键, 用户通过多次执行 SCAN 命令可以达到遍历所有键的目的。
执行 SCAN 时需要指定“游标”作为参数(首次执行,请指定 0), SCAN 的结果中除了包含一些键外,还会包含下次遍历所需要的“新游标”的值,如果返回的“新游标”的值是 0 ,则表示遍历已经结束了。
下面是 SCAN 的使用实例:
redis 127.0.0.1:6379> scan 0
1) "17" # 下次遍历需要指定游标为 17
2) 1) "key:12"
2) "key:8"
3) "key:4"
4) "key:14"
5) "key:16"
6) "key:17"
7) "key:15"
8) "key:10"
9) "key:3"
10) "key:7"
11) "key:1"
redis 127.0.0.1:6379> scan 17
1) "0" # 返回的游标为 0 表示遍历已经结束
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"
6) "key:13"
7) "key:6"
8) "key:9"
9) "key:11"
注:
1、 SCAN 命令不保证返回键的唯一性,可能会返回重复的键(之前返回过的键);
2、 SCAN 命令返回的键的数量是不确定的,有时候还可能不返回任何键,只要返回的游标不为 0,就表示迭代没有结束。
5. Redis 其它命令
5.1. 显示所有连接的客户端(client list)
使用 client list 命令可以显示所有连接的客户端,如:
127.0.0.1:6379> client list id=635 addr=127.0.0.1:63611 fd=8 name= age=1068 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client id=669 addr=127.0.0.1:63920 fd=9 name= age=3 idle=3 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=NULL id=670 addr=127.0.0.1:63921 fd=10 name= age=3 idle=3 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=psetex id=671 addr=127.0.0.1:63922 fd=11 name= age=3 idle=3 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=NULL
5.2. 查看内存使用情况(info memory)
使用 info memory 命令可以显示内存使用情况,如:
127.0.0.1:6379> info memory # Memory used_memory:1003696 used_memory_human:980.17K used_memory_rss:7766016 used_memory_rss_human:7.41M used_memory_peak:6791984 used_memory_peak_human:6.48M used_memory_peak_perc:14.78% used_memory_overhead:885286 used_memory_startup:513536 used_memory_dataset:118410 used_memory_dataset_perc:24.16% allocator_allocated:1188072 allocator_active:1552384 allocator_resident:8290304 total_system_memory:8200540160 total_system_memory_human:7.64G used_memory_lua:37888 used_memory_lua_human:37.00K used_memory_scripts:0 used_memory_scripts_human:0B number_of_cached_scripts:0 maxmemory:0 maxmemory_human:0B maxmemory_policy:noeviction allocator_frag_ratio:1.31 allocator_frag_bytes:364312 allocator_rss_ratio:5.34 allocator_rss_bytes:6737920 rss_overhead_ratio:0.94 rss_overhead_bytes:18446744073709027328 mem_fragmentation_ratio:8.43 mem_fragmentation_bytes:6844288 mem_not_counted_for_evict:0 mem_replication_backlog:0 mem_clients_slaves:0 mem_clients_normal:369998 mem_aof_buffer:0 mem_allocator:jemalloc-5.1.0 active_defrag_running:0 lazyfree_pending_objects:0
5.3. 输出服务器收到的命令(monitor)
MONITOR 命令可以输出 redis 服务器收到的命令,这在调试时很方便。如:
$ redis-cli monitor 1339518083.107412 [0 127.0.0.1:60866] "keys" "*" 1339518087.877697 [0 127.0.0.1:60866] "dbsize" 1339518090.420270 [0 127.0.0.1:60866] "set" "x" "6" 1339518096.506257 [0 127.0.0.1:60866] "get" "x" 1339518099.363765 [0 127.0.0.1:60866] "del" "x" 1339518100.544926 [0 127.0.0.1:60866] "get" "x"
这个命令也可以在 telnet 中使用(这在手头没有安装 redis 客户端时会很方便),如:
$ telnet localhost 6379 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. MONITOR +OK +1339518083.107412 [0 127.0.0.1:60866] "keys" "*" +1339518087.877697 [0 127.0.0.1:60866] "dbsize" +1339518090.420270 [0 127.0.0.1:60866] "set" "x" "6" +1339518096.506257 [0 127.0.0.1:60866] "get" "x" +1339518099.363765 [0 127.0.0.1:60866] "del" "x" +1339518100.544926 [0 127.0.0.1:60866] "get" "x" QUIT +OK Connection closed by foreign host.
注:为了安全考虑,像 CONFIG 这样的命令并不会出现在 MONITOR 的输出中。
5.4. 把输出导出到文件
下面以命令 keys * 为例,介绍如何把输出导出到文件中:
$ redis-cli keys '*' # 显示所有keys $ redis-cli keys '*' > 1.log # 把命令(keys *)的输出导出到文件1.log
6. Redis 实现发布订阅
Redis 支持 Publish/Subscribe 消息的工作模式,参见:https://redis.io/topics/pubsub
不过,在消息非常重要,不允许丢失的场景中,我们不能使用 Redis 的 Publish/Subscribe 机制,因为它没有传统消息队列的 Confirm 机制(broker 确认已经收到了 Publisher 发出的消息)和 ACK 机制(Subscriber 告诉 broker 已经处理完了消息)。
Redis 官网对 Pub/Sub 的不可靠性有下面说明:
Because Redis Pub/Sub is fire and forget currently there is no way to use this feature if your application demands reliable notification of events, that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost.
7. Redis 实现分布式锁
Redis 可以用来实现分布式锁。
7.1. 单机 Redis 实现分布式锁
7.1.1. 获取锁
获取锁的代码如下:
SET resource_name my_random_value NX EX 20
其中,my_random_value 是想获取锁的客户端生成的一个随机数;“NX”选项表示当“resource_name”对应的 key 值不存在时 SET 才会成功,这是保证存在竞争时只有一个客户端可以拿到锁的关键;“EX 20”表示 20 秒过期,过期后会自动删除这个 key。我们通过检测 SET 的返回值来判断是否加锁成功。
注 1:加锁时设置过期时间的目的是防止某客户端拿到锁后,突然 crash,导致锁一直不释放。注意, SETNX 命令不支持设置过期时间,不要先使用 SETNX 设置 key 为随机数,然后再使用 EXPIRE 设置 key 的过期时间,这是因为如果 SETNX 执行成功后,突然 crash,则也会出现锁一直不释放的问题。
注 2:也有锁的实现不利用 redis 过期时间,而是直接把过期时间保存在对应的 key 中,客户端自己来检测 key 有没有过期,这样也可以,只是客户端代码稍微复杂一些,可参考:https://redis.io/commands/setnx
注 3:为什么要把 key 设置为随机数呢?是为了保证某个客户端获得了锁后,只会被当前客户端自己释放。考虑下面场景:
客户端c1获得了锁。 客户端c1在某个操作上阻塞了很长的时间。 过期时间到了,锁被自动释放。 客户端c2获得了同一个资源的锁。 客户端c1从阻塞中恢复过来,释放了客户端c2持有的锁。
7.1.2. 释放锁
释放锁的逻辑是删除 key: resource_name。前面说过,这安全起见,客户端只能释放自己加的锁。这里我们先要读取 key 的内容,和 my_random_value 做比较,如果相同(说明是自己加的锁)就删除。需要说明的是读取 key 和删除 key 这两个操作在一起要构成原子操作。由于 Lua 脚本可以保证原子性, 我们使用 Lua 脚本使这两个操作构成原子操作:
if redis.call("get",KEYS[1]) == ARGV[1]
then
return redis.call("del",KEYS[1])
else
return 0
end
采用 EVAL 来调用 Lua 脚本,参数如下:
EVAL "content of the lua script" 1 resource-name my_random_value
这时,Lua 脚本中 KEYS[1] 就是 resource-name,而 ARGV[1] 就是 my_random_value。
7.2. 集群 Redis 实现分布式锁(Redlock)
上一节讨论的 Redis 锁基于前提:Redis 工作于单机模式。这已经满足了大部分场景的需求,如果 Redis 是集群模式,有多个 Master 节点,则推荐使用 Redis 作者 Antirez 写的 Redlock。这里不详细介绍,请参考:https://redis.io/topics/distlock
7.3. Redis 分布式锁的安全问题
Martin 在文章 How to do distributed locking 指出 Redis 实现分布式锁存在很多安全问题。如图 1 所示,由 GC 的 STW 可能导致的锁失效。
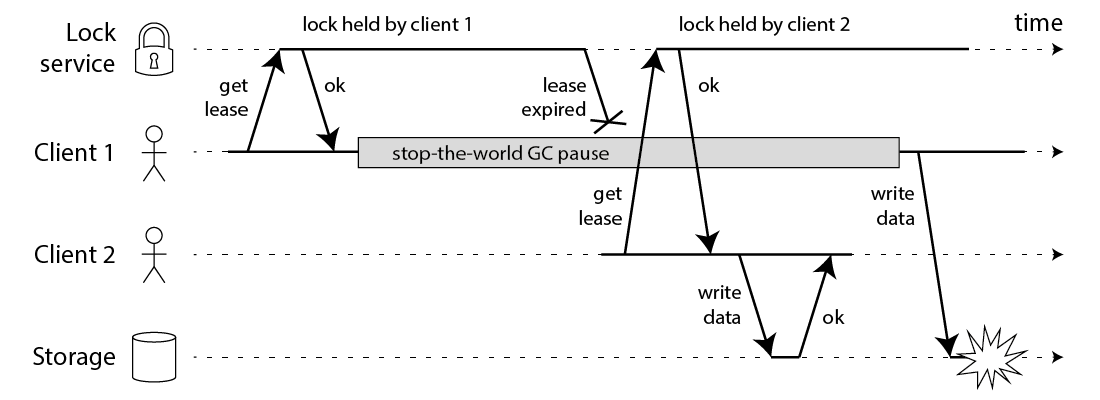
Figure 1: Unsafe lock
初看上去,有人可能会说,既然客户端 1 从 GC pause 中恢复过来以后不知道自己持有的锁已经过期了,那么它可以在访问共享资源之前先判断一下锁是否过期。但仔细想想,这丝毫也没有帮助。因为 GC pause 可能发生在任意时刻,也许恰好在判断完之后。也有人会说,如果客户端使用没有 GC 的语言来实现,是不是就没有这个问题呢?Martin 指出,系统环境太复杂,仍然有很多原因导致进程的 pause,比如虚存造成的缺页故障(page fault),再比如 CPU 资源的竞争。即使不考虑进程 pause 的情况,网络延迟也仍然会造成类似的结果。
在 Martin 的这篇文章中,还有一个很有见地的观点,就是对锁的用途的区分。他把锁的用途分为两种:
1、为了效率(efficiency),协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其它的不良后果。比如重复发送了一封同样的 email。
2、为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,或者其它严重的问题。
最后,Martin 得出了如下的结论:
1、 如果是为了效率(efficiency)而使用分布式锁,允许锁的偶尔失效,那么使用单 Redis 节点的锁方案就足够了,简单而且效率高。Redlock 则是个过重的实现(heavyweight)。
2、 如果是为了正确性(correctness)在很严肃的场合使用分布式锁,那么不要使用 Redlock。它不是建立在异步模型上的一个足够强的算法,它对于系统模型的假设中包含很多危险的成分。那应该使用什么技术呢?Martin 认为,应该考虑类似 Zookeeper 的方案,或者支持事务的数据库。
参考:
http://zhangtielei.com/posts/blog-redlock-reasoning.html
http://zhangtielei.com/posts/blog-redlock-reasoning-part2.html
8. Redis 持久化原理
Redis 提供了两种持久化的方式:RDB(Redis DataBase)和 AOF(Append Only File)。注:RDB 和 AOF 两种方式可以同时使用,也可以全部关闭。
8.1. RDB 原理(快照)
RDB(Redis DataBase)基本原理是在不同的时间点,将 Redis 存储的数据生成快照并存储到磁盘等介质上。
使用命令 save (不带参数时可以直接生成快照,生成快照时不会响应客户端请求,带参数时可以配置生成快照的策略)和 bgsave (创建子进程生成快照,可以响应客户端请求)可以创建快照。
使用 bgsave 命令创建快照的原理(利用了 fork 的 copy-on-write 特性):
1、Redis 调用 fork 创建子进程。
2、父进程继续处理 client 的请求,子进程负责将内存内容写入到临时文件。由于 fork 的写时复制机制(copy-onwrite)父子进程会共享相同的物理页面,当父进程处理写请求时操作系统会为父进程要修改的页面创建副本,而不是写共享的页面。所以 子进程的地址空间内的数据是 fork 时刻整个数据库的一个快照。
3、当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出。
8.2. AOF 原理(日志)
AOF(Append Only File)原理:把执行过的写指令记录到文件(appendonly.aof)中,在数据恢复时按照从前到后的顺序再将指令都执行一遍。
下面是查看和打开 AOF 的方法(修改配置时最好保存到 redis.conf 文件中,否则重启 Redis 时会丢失配置):
127.0.0.1:6379> config get appendonly 1) "appendonly" 2) "no" 127.0.0.1:6379> config set appendonly yes OK 127.0.0.1:6379> config get appendonly 1) "appendonly" 2) "yes"
把写指令同步到 appendonly.aof 文件中,有 3 种策略(默认为第 2 种策略,即每秒钟同步一次):
appendfsync always: fsync every time a new command is appended to the AOF. Very very slow, very safe.appendfsync everysec: fsync every second. Fast enough (in 2.4 likely to be as fast as snapshotting), and you can lose 1 second of data if there is a disaster.appendfsync no: Never fsync, just put your data in the hands of the Operating System. The faster and less safe method. Normally Linux will flush data every 30 seconds with this configuration, but it's up to the kernel exact tuning.
8.2.1. Log rewriting 及其原理
如果每一条写命令都生成一条日志,那么 AOF 文件会越来越大,所以 Redis 又提供了一个功能,叫做 AOF rewrite。其功能就是重新生成一份 AOF 文件,新的 AOF 文件中一条记录的操作只会有一次,而不像一份老文件那样,可能记录了对同一个值的多次操作过程。
使用 bgrewriteaof 可以手动触发 AOF 的重写功能。
bgrewriteaof 命令的实现细节如下(也利用了 fork 的 copy-on-write 特性):
Log rewriting uses the same copy-on-write trick already in use for snapshotting. This is how it works:
- Redis forks, so now we have a child and a parent process.
- The child starts writing the new AOF in a temporary file.
- The parent accumulates all the new changes in an in-memory buffer (but at the same time it writes the new changes in the old append-only file, so if the rewriting fails, we are safe).
- When the child is done rewriting the file, the parent gets a signal, and appends the in-memory buffer at the end of the file generated by the child.
- Profit! Now Redis atomically renames the old file into the new one, and starts appending new data into the new file.
8.3. RDB 和 AOF 优缺点
RDB 的缺点:对数据的完整性非常敏感时,RDB 方式不太适合你,因为即使你每 5 分钟都持久化一次,当 Redis 故障时,仍然会有近 5 分钟的数据丢失。这种情况下,AOF 更适合你。
AOF 也有缺点:(1)在同样数据规模的情况下,AOF 文件要比 RDB 文件的体积大;(2)AOF 方式的恢复速度也要慢于 RDB 方式。
9. Redis 高可用方案
9.1. 主从模式
Redis 可以配置为主从模式:即一个主库,一个或多个从库。主库支持“读写”,默认从库只支持“读”(可以把 replica-read-only 设置为 no 从而让从库也支持写,但不推荐这样做,它可能造成主从不一致的情况)。
主从配置很简单。把想设置为从库的 Redis 服务器配置文件 redis.conf 中增加下面配置即可:
# replicaof <masterip> <masterport> replicaof 192.168.1.1 6379
9.1.1. 复制原理
从节点复制主节点数据是由下面三个机制的实现的:
1、当网络很好时,主节点把它所执行的“命令”依次发送给从节点,从节点再去执行收到的“命令”。
2、网络不好时,从节点和主节点可能断开连接,再重新连接上后,从节点会向主节点请求网络断开时间段内的那些命令,这称为“Partial Resynchronization”。
3、如果“Partial Resynchronization”也无法成功,则从节点会向主节点请求一次“Full Resynchronization”,这时主节点会把自己的数据生成一个快照,发送给从节点,然后再接着发送主节点上执行的“命令”。
9.1.2. 故障恢复
主从模式下,故障恢复比较繁琐。当主节点出现故障时,需要手动将一个从节点晋升为主节点(在从节点上执行命令 REPLICAOF NO ONE 即可),还需要通知业务方变更配置,并且需要让其它从节点去复制新主节点。
9.1.3. 查看当前节点的主从信息
使用 info replication 可以查看当前节点的主从信息,如:
127.0.0.1:6379> info replication # Replication role:master connected_slaves:0 master_replid:73d89362725d9517726a0fd7ad272f4d66824466 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
9.2. 哨兵模式
Sentinel(哨兵):由多个 Sentinel 节点(要实现高可用,Sentinel 节点的个数应该为奇数,至少三个)组成的 Sentinel 系统可以监视任意多个主节点,以及这些主节点属下的所有从节点,并当被监视的主节点进入下线状态时,自动下线主节点,并将主节点下的某个从节点升级为的主节点,然后由的主节点代替已下线的主节点处理命令请求。
哨兵模式克服了主从模式中遇到故障需要人为干预的缺点。
要启动哨兵节点,有两种方式,一是启动 redis-sentinel ,二是 redis-server 启动时增加参数 --sentinel 。
9.2.1. Leader Sentinel
当一个主节点出现故障,需要被下线时,各个 Sentinel 节点需要协商,选举出一个 Leader Sentinel,由 Leader Sentinel 来执行具体的故障转移操作。
选举 Leader Sentinel 的算法采用的是 Raft 协议中的选举算法。
9.2.2. 客户端支持
在哨兵模式下,需要客户端额外的支持。客户端不能再直接连接某个固定的“主节点”地址了,因为“主节点”地址可能会变。
客户端需要连接哨兵节点,并通过哨兵节点的 sentinel get-master-addr-by-name master-name 这个 API 来获取主节点的相关信息。此外还需要订阅哨兵节点的相关频道,主要是接收“switch-master”消息,这个消息表示主节点发生了切换,客户端需要连接新的主节点了。
9.3. 集群模式
Redis 集群是 Redis 提供的分布式解决方案,集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能。
9.3.1. 数据分片的方式
Redis 集群并没有采用一致性哈希的方式,而是采用下面的方式: 集群的整个数据库被分为 16384 个槽(槽的编号为 0 到 16383),数据库中的每个键都属于这 16384 个槽的其中一个,集群中的每个节点可以处理 0 个或最多 16384 个槽。
把键名 key 进行 CRC16 计算后,再对 16384 取模,得到的数字就是这个键所在的槽的编号(Hash Tag 是个例外,后面将介绍),即:
HASH_SLOT = CRC16(key) mod 16384
Redis 集群中的每个节点都包含一部分的槽,比如集群中有三个节点分别处理不同的槽:
Node A contains hash slots from 0 to 5500. Node B contains hash slots from 5501 to 11000. Node C contains hash slots from 11001 to 16383.
当数据库中的 16384 个槽都有节点在处理时,集群处于上线状态;相反地,如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态。
9.3.1.1. 为什么采用 16384 个槽
CRC16 算法产生的哈值有 16 位,该算法可以产生 \(2^{16}=65536\) 个值。为什么不直接使用 \(\mod 65536\) 计算槽编号,而选择 \(\mod 16384\) 呢?
Redis 作者 antirez 给出了两个原因:
1、如果采用 65536 个槽,会导致集群中的心跳包过于庞大;
2、集群一般不会超过 1000 个,16384 个槽已经够用了。
注:数字 \(16384=2^{14}\) 在 HyperLogLog 中也用到了(表示桶的个数)。
9.3.2. 集群中的主从
我们可以为集群中的每个(主)节点配置“从节点”。比如前面例子中节点 A 处理 0 到 5500 的槽;节点 B 处理 5501 到 11000 的槽;节点 C 处理 11001 到 16383 的槽。我们可以分别为节点 A/B/C 配置三个从节点 A1/B1/C1,如果节点 B 出问题了,集群会让 B1 成为主节点,继续提供服务;不过如果 B 和 B1 同时出问题了,则集群就出故障了,不能提供服务。
9.3.3. Hash Tag
我们知道 MSET 命令可以同时设置几个键值,且操作是原子地。单机配置中,这很容易实现。
而集群上虽然也支持同时设置多个 key,但不再是原子性操作。会存在某些给定 key 被更新而另外一些给定 key 没有改变的情况。其原因是需要设置的多个 key 可能分配到不同的机器上。
为了解决这个问题,Redis 引入了“Hash Tag”的概念。key 中如果包含 {xxx} ,则称为 Hash Tag,在计算这样的 key 所在的槽编号时,只有 {} 内的部分内容才参与计算(不再是整个 key 名参与计算),比如:
{user1000}.following # CRC16("user1000") mod 16384
{user1000}.followers # CRC16("user1000") mod 16384
这样,key 名为 {user1000}.following 和 {user1000}.followers 的数据一定会分配到同一个槽中(因为它们键名中 {} 包含的部分是相同的),从而一定在同一个节点中被处理。
这样,只要取合适的 key 名,我们可以保证 MSET 在集群中也具有原子性了。
9.3.4. 客户端支持
9.3.4.1. MOVED 错误
集群准备好以后,当客户端向某节点发送命令时,接收命令的节点会计算出命令要处理的键属于哪个槽,并检查这个槽是否指派给了自己:
1、如果键所在的槽正好就指派给了当前节点,那么节点直接执行这个命令。
2、如果键所在的槽并没有指派给当前节点,那么节点会向客户端返回一个 MOVED 错误,指引客户端转向(redirect)至正确的节点,再次发送之前想要执行的命令。
当然,客户端实现时可以把“槽分配给了哪个节点处理”的信息缓存起来,下次直接往指定节点发送命令即可。
自带的命令行 redis-cli 有个参数 -c 可以在遇到 MOVED 错误时,自动重新发送命令给 MOVED 错误指示的节点地址。
9.3.4.2. ASK 错误
在进行重新分片期间,源节点向目标节点迁移一个槽的过程中,可能会出现这样一种情况:属于被迁移槽的一部分“键值对”保存在源节点里面,而另一部分“键值对”保存在目标节点里面。
当客户端向源节点发送一个与数据库键有关的命令,并且命令要处理的数据库键恰好就属于正在被迁移的槽时:
1、源节点会先在自己的数据库里面查找指定的键,如果找到的话,就直接执行客户端发送的命令。
2、相反地,如果源节点没能在自己的数据库里面找到指定的键,那么这个键有可能已经被迁移到了目标节点,源节点将向客户端返回一个 ASK 错误,指引客户端转向正在导入槽的目标节点,并再次发送之前想要执行的命令。
自带的命令行 redis-cli 有个参数 -c 可以在遇到 ASK 错误时,自动重新发送命令给 ASK 错误指示的节点地址。
9.3.5. 信息交换(Gossip)
Redis 集群是一个无中心节点的架构,依靠 Gossip 协议传播集群的配置和状态信息。
10. Redis 配置
启动 Redis Server 时,可直接指定配置文件(一般名为 redis.conf)。如:
$ redis-server redis.conf
通过 config get * 可以查看所有配置,也可以指定某一个配置进行查询。如:
$ redis-cli 127.0.0.1:6379> config get * 1) "dbfilename" 2) "dump.rdb" 3) "requirepass" 4) "" 5) "masterauth" 6) "" ...... 165) "notify-keyspace-events" 166) "" 167) "bind" 168) "" 127.0.0.1:6379> config get dbfilename 1) "dbfilename" 2) "dump.rdb"
输出中,前一行配置名称,后面的紧接一行是配置的当前值。
通过 CONFIG SET parameter value 可以修改某个配置。如:
127.0.0.1:6379> config set dbfilename db.rdb OK
10.1. 配置最大内存及内存淘汰策略
默认,在 64 位系统下,Redis 不会限制内存使用。通过配置 maxmemory 可以限制最大的使用内存。当内存到达限制时,默认策略是报错,通过配置 maxmemory-policy 可以设置内存到达限制后的策略,支持表 8 所示的策略。
| maxmemory-policy | Description |
|---|---|
| volatile-lru | Evict using approximated LRU among the keys with an expire set. |
| allkeys-lru | Evict any key using approximated LRU. |
| volatile-lfu | Evict using approximated LFU among the keys with an expire set. |
| allkeys-lfu | Evict any key using approximated LFU. |
| volatile-random | Remove a random key among the ones with an expire set. |
| allkeys-random | Remove a random key, any key. |
| volatile-ttl | Remove the key with the nearest expire time (minor TTL) |
| noeviction | Don't evict anything, just return an error on write operations. (Default) |
10.1.1. LRU Cache
下面配置可以把 Redis 设置为像 memcached 一样工作:
maxmemory 20mb maxmemory-policy allkeys-lru
在这个配置下,上层的应用代码就不用明确设置过期时间了,内存使用超过 20mb,会采用 LRU (Least Recently Used) 策略自动回收内存。
10.2. 查看执行时间长的命令(slowlog get)
Redis 服务器提供了两个配置用于记录执行时间过长的命令:
1、 slowlog-log-slower-than 这是阈值,单位为微秒,执行时间长于这个值的命令将被记录下来;
2、 slowlog-max-len 最大记录多少条慢日志。
通过命令 slowlog get 可以查看当前的慢日志,如:
127.0.0.1:6379> slowlog get
1) 1) (integer) 6
2) (integer) 1558142539 # 命令执行时的 UNIX 时间戳
3) (integer) 44816 # 命令执行的时长(单位为微秒)
4) 1) "info"
5) "127.0.0.1:62511"
6) ""
2) 1) (integer) 5
2) (integer) 1558642246
3) (integer) 122096
4) 1) "CONFIG"
2) "GET"
3) "slowlog-log-slower-than"
5) "127.0.0.1:62265"
6) ""