RNN, LSTM
Table of Contents
1. RNN 简介
循环神经网络(Recurrent Neural Network, RNN)主要用于对“序列数据”进行建模,在自然语言处理等领域应用广泛。
1.1. RNN 发展历史
Salehinejad 等人在综述文章 Recent Advances in Recurrent Neural Network 中列举了 RNN 发展历史,如表 1 所示。
| Year | First Author | Contribution |
|---|---|---|
| 1990 | Elman | Popularized simple RNNs (Elman network) |
| 1993 | Doya | Teacher forcing for gradient descent (GD) |
| 1994 | Bengio | Difficulty in learning long term dependencies with gradient descend |
| 1997 | Hochreiter | LSTM: long-short term memory for vanishing gradients problem |
| 1997 | Schuster | BRNN: Bidirectional recurrent neural networks |
| 1998 | LeCun | Hessian matrix approach for vanishing gradients problem |
| 2000 | Gers | Extended LSTM with forget gates |
| 2001 | Goodman | Classes for fast Maximum entropy training |
| 2005 | Morin | A hierarchical softmax function for language modeling using RNNs |
| 2005 | Graves | BLSTM: Bidirectional LSTM |
| 2007 | Jaeger | Leaky integration neurons |
| 2007 | Graves | MDRNN: Multi-dimensional RNNs |
| 2009 | Graves | LSTM for hand-writing recognition |
| 2010 | Mikolov | RNN based language model |
| 2010 | Neir | Rectified linear unit (ReLU) for vanishing gradient problem |
| 2011 | Martens | Learning RNN with Hessian-free optimization |
| 2011 | Mikolov | RNN by back-propagation through time (BPTT) for statistical language modeling |
| 2011 | Sutskever | Hessian-free optimization with structural damping |
| 2011 | Duchi | Adaptive learning rates for each weight |
| 2012 | Gutmann | Noise-contrastive estimation (NCE) |
| 2012 | Mnih | NCE for training neural probabilistic language models (NPLMs) |
| 2012 | Pascanu | Avoiding exploding gradient problem by gradient clipping |
| 2013 | Mikolov | Negative sampling instead of hierarchical softmax |
| 2013 | Sutskever | Stochastic gradient descent (SGD) with momentum |
| 2013 | Graves | Deep LSTM RNNs (Stacked LSTM) |
| 2014 | Cho | Gated recurrent units |
| 2015 | Zaremba | Dropout for reducing Overfitting |
| 2015 | Mikolov | Structurally constrained recurrent network (SCRN) to enhance learning longer memory for vanishing gradient problem |
| 2015 | Visin | ReNet: A RNN-based alternative to convolutional neural networks |
| 2015 | Gregor | DRAW: Deep recurrent attentive writer |
| 2015 | Kalchbrenner | Grid long-short term memory |
| 2015 | Srivastava | Highway network |
| 2017 | Jing | Gated orthogonal recurrent units |
1.2. RNN 模型结构
原始的 RNN 有三层:输入层、循环隐藏层、输出层。如图 1 所示, \(\boldsymbol{x}_t\) 为输入层, \(\boldsymbol{h}_t\) 为循环隐藏层, \(\boldsymbol{y}_t\) 输出层。
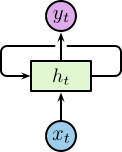
Figure 1: RNN
为了更好地理解,我们可以把“循环隐藏层”进行展开,展开后的模型结构如图 2 所示。
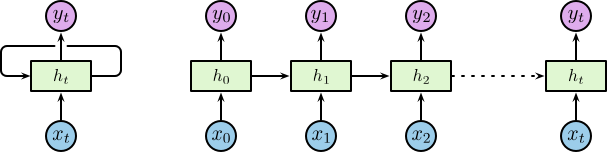
Figure 2: 展开后的 RNN
1.2.1. RNN 缺点:长期依赖问题
考虑一个用于利用之前的文字预测后续文字的语言模型。如果我们想预测 “the clouds are in the *sky*” 中的最后一个词,我们不需要太远的上下文信息,很显然这个词就应该是 sky。
如果我们需要预测 “I grew up in France ... I speak fluent *French*” 中的最后一个词。较近的信息表明待预测的位置应该是一种语言,但想确定具体是哪种语言需要更远位置的“I grew up in France”的背景信息。理论上 RNN 有能力处理这种长期依赖,但在实践中 RNN 却很难解决这个问题。
注:除了“长期依赖难以记住”这个缺点外;RNN 还有“梯度消失”的缺点,这里不介绍。
2. LSTM (Long Short-Term Memory)
长短时记忆网络 (Long Short-Term Memroy, LSTM) 是由 Hochreiter 于 1997 年提出一种特殊 RNN。LSTM 解决了传统 RNN 的缺点:“梯度消失”和“长期依赖难以记住”。
原始的 RNN 如图 3 所示;而 LSTM 如图 4 所示。
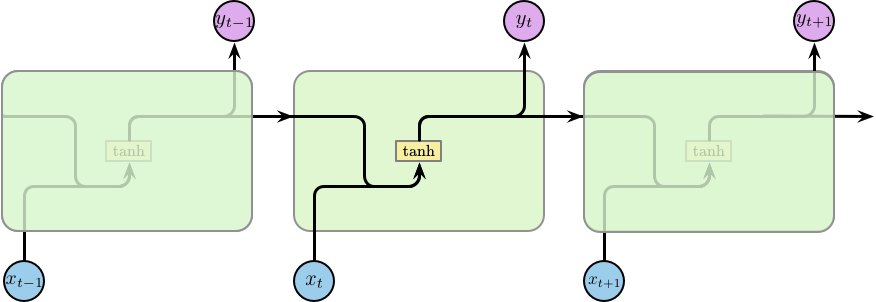
Figure 3: RNN
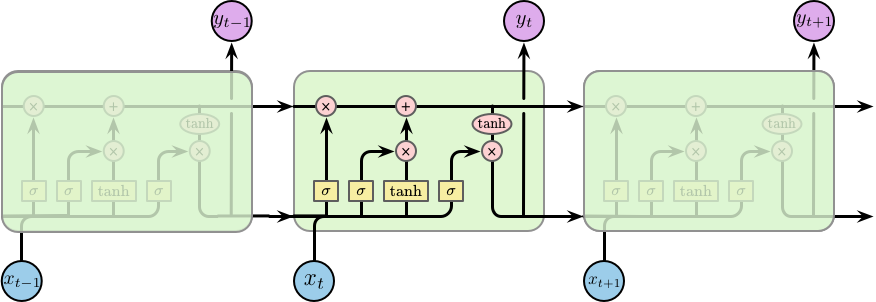
Figure 4: LSTM
2.1. LSTM 记住长期依赖
为什么 LSTM 容易记住长期的依赖呢?主要原因是图 5 所示的顶部水平穿过单元的直线,它贯穿在整个链条上,仅包含少量的线性操作。这样,较远的信息容易传递下去并保持住。
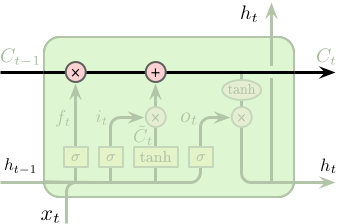
Figure 5: LSTM Cell State
3. 参考
Understanding LSTM Networks: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
本文图片来自:https://leovan.me/cn/2018/09/rnn