Socket, Network programming
Table of Contents
1. Sockets 简介
Berkeley sockets is an application programming interface (API) for Internet sockets and Unix domain sockets, used for inter-process communication (IPC). It is commonly implemented as a library of linkable modules. It originated with the 4.2BSD Unix released in 1983.
参考:
本文很多内容直接摘自《UNIX 网络编程卷 1:套接字联网 API(第 3 版)》
The Linux Programming Interface, by Michael Kerrisk
1.1. 套接字描述符
套接字是通信端点的抽象。和访问文件需要使用文件描述符类似,访问套接字需要使用套接字描述符。在 UNIX 系统中套接字描述符直接用文件描述符实现,处理文件描述符的函数(如 read 和 write)可以直接处理套接字描述符。
1.1.1. 创建套接字(socket 函数)
用函数 socket 可以创建一个套接字描述符(类似于用 open 创建一个文件描述符)。
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
/* Returns: file (socket) descriptor if OK, −1 on error */
函数 socket 的第 1、2 个参数的含义分别如表 1 和表 2 所示。
| Domain | Communication between applications | Address format | Address structure |
|---|---|---|---|
| AF_UNIX | on same host | pathname | sockaddr_un |
| AF_INET | via IPv4 on hosts connected via an IPv4 network | 32-bit IPv4 address + 16-bit port number | sockaddr_in |
| AF_INET6 | via IPv6 on hosts connected via an IPv6 network | 128-bit IPv6 address + 16-bit port number | sockaddr_in6 |
| AF_UNSPEC | unspecified | unspecified | unspecified |
说明:AF 表示 Address Family。
| Type | Description |
|---|---|
| SOCK_DGRAM | fixed-length, connectionless, unreliable messages |
| SOCK_RAW | datagram interface to IP (optional in POSIX.1) |
| SOCK_SEQPACKET | fixed-length, sequenced, reliable, connection-oriented messages |
| SOCK_STREAM | sequenced, reliable, bidirectional, connection-oriented byte streams |
说明:当函数 socket 第 1 个参数为 AF_INET 时,如果第 2 个参数设置为 SOCK_STREAM 则表示是 TCP 协议,如果设置为 SOCK_DGARM 则表示是 UDP 协议。
函数 socket 的第 3 个参数 protocol 通常为是零(表示按给定域和套接字类型选择默认协议)。
1.1.2. 关闭套接字(shutdown 函数)
函数 shutdown 用于关闭套接字,其原型为:
#include <sys/socket.h>
int shutdown(int sockfd, int howto);
/* Returns 0 on success, or –1 on error */
函数 shutdown 的第 2 个参数的含义如表 3 所示。
| howto | discription |
|---|---|
| SHUT_RD | Close the reading half of the connection. Subsequent reads will return EOF. Data can still be written to the socket. |
| SHUT_WR | Close the writing half of the connection. Once the peer application has read all outstanding data, it will see EOF. Subsequent writes to the local socket yield the SIGPIPE signal and an EPIPE error. Data written by the peer can still be read from the socket. |
| SHUT_RDWR | Close both the read and the write halves of the connection. |
1.1.2.1. close 和 shutdown 的区别
处理文件描述符的函数 close 也可以用来关闭套接字。使用 shutdown 有下面两个优势:
(1) close 将描述字的访问计数减 1,仅当此计数为 0 时才真正关闭套接字。而用 shutdown 可以发起 TCP 的正常连接终止序列,而不管它的访问计数为多少。
(2) close 终止数据传送的两个访问:读和写。TCP 连接是全双工的,用 shutdown 可以只关闭“读方向”的连接或者只关闭“写方向”的连接。
2. TCP 套接字编程
图 1 给出了在一对 TCP 客户与服务器进程之间发生的一些典型事件的时间表。服务器首先启动,稍后某个时刻客户启动,它试图连接到服务器。我们假设客户给服务器发送一个请求,服务器处理该请求,并且给客户发回一个响应。这个过程一直持续下去,直到客户关闭连接的客户端,从而给服务器发送一个 EOF(文件结束)通知为止。服务器接着也关闭连接的服务器端,然后结束运行或者等待新的客户连接。
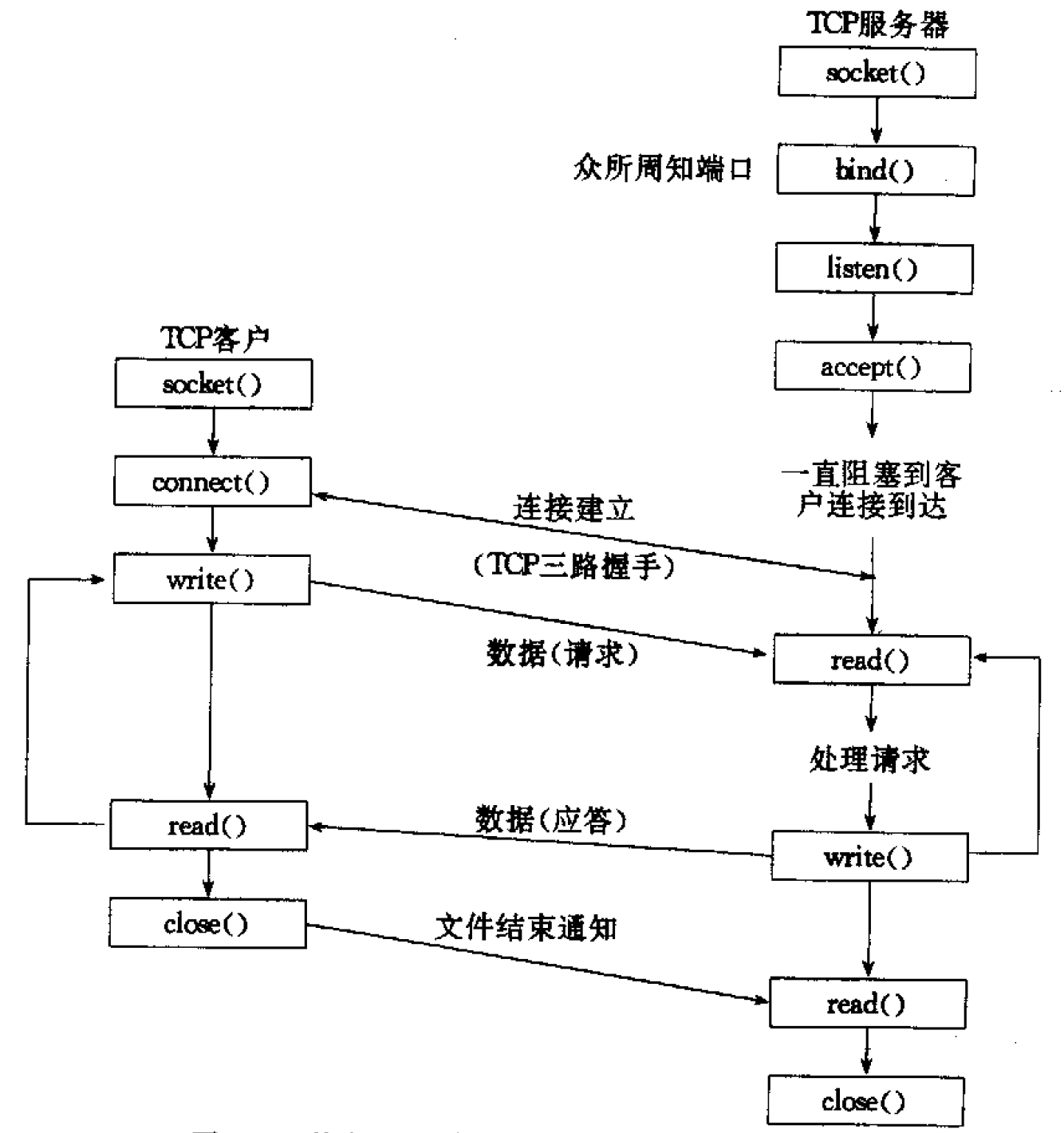
Figure 1: 基本 TCP 客户——服务器程序所用的套接字函数
2.1. listen 函数
函数 listen 原型如下:
#include <sys/socket.h>
int listen(int sockfd, int backlog);
/* Returns 0 on success, or –1 on error */
函数 listen 仅由 TCP 服务器调用,它有两个作用:
- 把主动套接字(active socket)转换为被动套接字(passive socket);用 socket 函数创建一个套接字时,默认为主动套接字(即将调用 connect 发起连接的客户端套接字),函数 listen 可以把未连接的套接字转换为“被动套接字”。在 TCP 状态转换图中, 调用 listen 函数将导致套接字从 CLOSED 状态转移到 LISTEN 状态。
- 指定了内核应该为相应套接字排队的最大连接个数(listen 第二个参数)。
2.1.1. SYN Queue and Accept Queue
为了理解 listen 函数的第二个参数(套接字排队的最大连接个数),我们必须明白,对于给定的监听套接字,内核要维护两个队列(这个描述是原理性地,也可以是一个队列但有两种状态):
- “未完成连接队列”,为每个这样的 SYN 分节开设一个条目:已经由客户发出并到达服务器,服务器正在等待完成相应的 TCP 三次握手过程。这些套接字都处于 SYN_RCVD 状态。这个队列也称为“SYN Queue”。
- “已完成连接队列”,为每个已完成 TCP 三次握手过程的客户开设一个条目。这些套接字都处于 ESTABLISHED 状态。这个队列也称为“Accept Queue”。
TCP 为监听套接字维护两个队列如图 2 所示;如果对应到 TCP 三次握手的细节,则可参考图 3 。
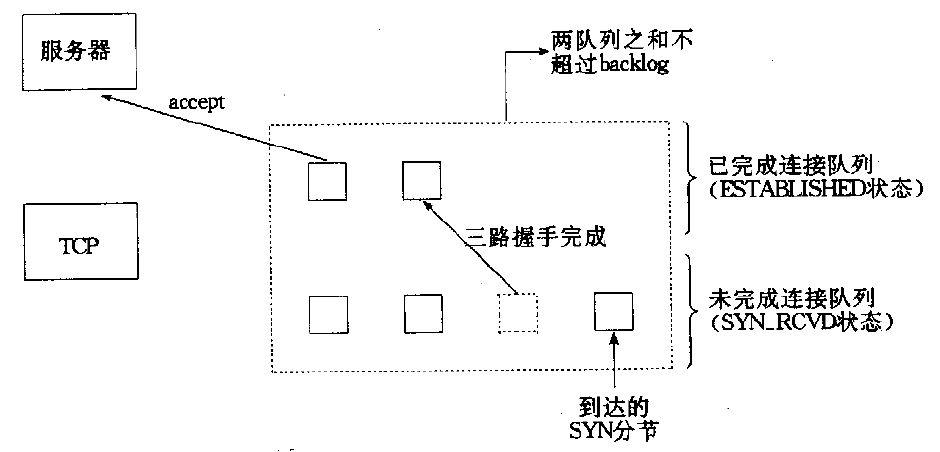
Figure 2: TCP 为监听套接字维护两个队列
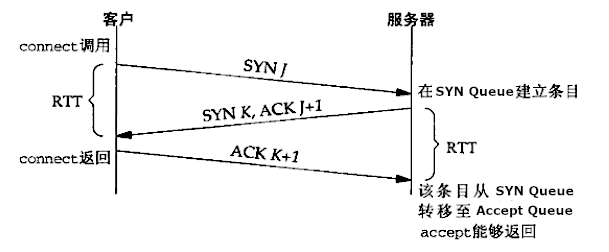
Figure 3: TCP 三次握手和监听套接字的两个队列
listen 函数的第二个参数 backlog 的含义没有统一的定义,在不同系统中很可能不一样(请查阅当前系统的文档):
- 在 BSD 系统中,listen 函数的第二个参数 backlog 用于指定这两个队列中条目之和的最大值,如图 2 所示。
- 在 Linux 2.2 及更新版本中,listen 函数的第二个参数 backlog 仅用于指定 Accept Queue 的大小;而 /proc/sys/net/ipv4/tcp_max_syn_backlog(典型值为 256)则用于指定 SYN Queue 的大小。
说明 1:如果没有特别要求,你可以指定 backlog 为 SOMAXCONN (它的典型值可能为 128);在 Linux 中如果 backlog 所指定的值比 SOMAXCONN 大,那么系统会忽略 backlog,直接使用 /proc/sys/net/core/somaxconn(即 SOMAXCONN)值作为 Accept Queue 的大小。
说明 2:从图 2 中可知 TCP 服务器调用 accept 函数(后文将介绍)时,Accept Queue 中的条目会减少。
说明 3:Linux 中,使用命令 ss -lt 查看处于 LISTEN 状态的 TCP 套接字时,其 Recv-Q/Send-Q 列分别表示 Accept Queue 中当前元素个数和 Accept Queue 的大小:
$ ss -lt State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 127.0.0.1:42527 0.0.0.0:* LISTEN 0 10 0.0.0.0:13000 0.0.0.0:* LISTEN 0 128 0.0.0.0:5000 0.0.0.0:* LISTEN 0 128 0.0.0.0:http 0.0.0.0:* LISTEN 0 128 127.0.0.53%lo:domain 0.0.0.0:* LISTEN 0 128 0.0.0.0:ssh 0.0.0.0:* LISTEN 0 128 0.0.0.0:https 0.0.0.0:*
2.1.2. SYN Flood 攻击
在 1996 年间,因特网受到一种称之为 SYN 泛滥(SYN Flood)的攻击。黑客编写了一个以高速率给受害主机发送 SYN 报文的程序,用以装填一个或多个 TCP 端口的未完成连接队列。而且该程序将每个 SYN 的源 IP 地址都置成随机数(称为 IP Spoofing),这样服务器的 SYN-ACK 就发往不知道什么地方了,同时防止受攻击服务器获悉黑容的真实 IP 地址。这样,通过以伪造的 SYN 装填未完成连接队列(即 SYN Queue 满了),使合法的 SYN 排不上队,导致针对合法客户的服务被拒绝(denial of service)。
为了解决 SYN Flood 攻击,RFC 4987 中列举了下面一些措施:
- Filtering
- Increasing backlog
- Reducing SYN-RECEIVED timer
- Recycling the oldest half-open TCP
- SYN cache
- SYN cookies
- Hybrid approaches
- Firewalls and proxies
2.1.2.1. SYN cookies 机制
SYN cookies 是解决 SYN Flood 攻击的一种有效方式。
SYN cookies 的原理: 攻击者对于我们返回的 SYN/ACK 包是不会回复的,而正常用户会回复一个 ACK 包。这样,当 TCP 服务器接收到 SYN 包并返回 SYN/ACK 包时,并不马上分配一个专门的数据区(不保存条目到 SYN Queue 中),而是根据这个 SYN 包计算出一个 cookie 值。这个 cookie 作为将要返回的 SYN/ACK 包的初始序列号。当客户端返回一个 ACK 包时,根据包头信息计算 cookie,与返回的确认序列号(初始序列号 + 1)进行对比,如果相同,则是一个正常连接,这时才分配资源,建立连接。
在 Linux 中,通过 /proc/sys/net/ipv4/tcp_syncookies 可以启用(默认启用)或者停用 SYN cookies。如果 SYN cookies 被启用,则 /proc/sys/net/ipv4/tcp_max_syn_backlog 被忽略(因为启用 SYN cookies 时,不保存条目到 SYN Queue 中,其最大长度的概念也就不存在了)。
2.1.3. 两个队列满了怎么办
当禁用 SYN cookies 时,SYN Queue 满了,服务器直接丢弃客户端的 SYN 报文。当启用 SYN cookies 机制时,服务器收到 SYN 包后不会马上把相关条目保存到 SYN Queue 中,这时,不存在 SYN Queue 会满的情况了。
前面提到过,当服务器调用 accept 后,Accept Queue 中的条目会减少。如果服务器调用 accept 太慢,导致 Accept Queue 满了,那怎么办呢?在 Linux 系统中:
- 当 /proc/sys/net/ipv4/tcp_abort_on_overflow 为 1 时,TCP 协议栈直接回给客户端 RST 报文。
- 当 /proc/sys/net/ipv4/tcp_abort_on_overflow 为 0(这是默认值)时,服务器认为这可能是正常的突发流量导致,不会马上发 RST 报文。而是忽略客户端的当前的 ACK,过一段时间后,服务器再给客户端发 SYN/ACK,客户端又回 ACK,这时服务器 Accept Queue 可以已经有空闲了,正常建立连接。当然,如果服务器 Accept Queue 仍然是满的,那么重试 /proc/sys/net/ipv4/tcp_synack_retries(默认值为 5)次都失败后,TCP 协议栈才会给客户端回 RST 报文。
2.2. accept 函数
函数 accept 原型如下:
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
/* Returns file descriptor on success, or –1 on error */
函数 accept 由 TCP 服务器调用,用于从“已完成连接队列”的队列头返回下一个已完成的连接。如果“已完成连接队列”为空,那么 accept 会阻塞(假定套接字为默认的阻塞方式)直到一个请求到来。
如果 accept 成功,那么它的返回值是“由内核自动生成的一个全新套接字描述符,代表与所返回客户的 TCP 连接”。
2.2.1. “监听套接字”和“已连接套接字”的区别
函数 accept 的第一个参数称为“监听套接字”,而一个成功 accept 调用的返回值称为“已连接套接字”。
两者区别如下:
一个服务器通常仅仅创建一个“监听套接字”,它在该服务器的生命期内一直存在。内核自动为每个服务进程接受的客户连接创建一个“已连接套接字”(也就是说它的 TCP 三次握手过程已经完成),当服务器完成对某个给定客户的服务时,相应的“已连接套接字”就被关闭。
2.2.2. 惊群问题(Thundering Herd)
惊群问题(Thundering herd problem):当某一时刻只有一个连接过来时,N个睡眠进程会被同时叫醒,但只有一个进程可获得连接。如果每次唤醒的进程数目太多,会影响一部分系统性能。
和 accept 函数相关的惊群问题在比较新的系统内核中已经解决。
参考:
UNIX 网络编程第 1 卷:套接口 API 和 XOpen 传输接口 API(第 2 版),27.6 节
http://stackoverflow.com/questions/2213779/does-the-thundering-herd-problem-exist-on-linux-anymore
2.3. 实例:迭代服务器
下面程序基于 TCP 实现一个简单的时间服务器(类似于:https://en.wikipedia.org/wiki/Daytime_Protocol)。
程序摘自:UNIX 网络编程第 1 卷:套接口 API 和 XOpen 传输接口 API(第 2 版),4.6 节
// file mytimesrv.c: A time server
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <time.h>
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t len;
struct sockaddr_in servaddr, cliaddr;
char buff[1024];
time_t ticks;
if ((listenfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror ("socket");
exit (1);
}
memset(&servaddr, 0, sizeof (servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(13000); /* daytime server */
if (bind(listenfd, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0) {
perror("bind");
exit (1);
}
if (listen(listenfd, SOMAXCONN) < 0) {
perror("listen");
exit (1);
}
for ( ; ; ) {
len = sizeof(cliaddr);
if ((connfd = accept(listenfd, (struct sockaddr *) &cliaddr, &len)) < 0) {
perror ("accept");
exit (1);
}
printf("connection from %s, port %d\n",
inet_ntop(AF_INET, &cliaddr.sin_addr, buff, sizeof(buff)),
ntohs(cliaddr.sin_port));
ticks = time(NULL);
snprintf(buff, sizeof(buff), "%.24s\r\n", ctime(&ticks));
write(connfd, buff, strlen(buff));
close(connfd);
}
}
编译完成并启动程序(服务器)后,在另一个终端中用程序(客户端)连接到服务器的 TCP 端口 13000,如:
$ nc localhost 13000 Sat Dec 14 22:55:23 2013
而在服务器的终端中,则会显示类似下面的输出:
$ ./mytimesrv connection from 127.0.0.1, port 51205
说明:这个服务器不是并发的,称为迭代服务器。由于它提供的服务是返回服务器的时间,这个操作在很短的时间内可以完成,函数 accept 很快又会被调用,这样当客户端较多时也能很快地获取下一个客户端的连接,所以采用迭代服务器也是可行的。但如果服务器提供的服务比较耗时,则不宜采用上面的编程方法,因为当客户端比较多时,不能让服务器长时间为某一个客户提供服务。这时,可以为每一个客户端连接 fork 出一个进程进行处理,或者使用 select 和 poll 等 I/O 复用方式或者其它方法。
2.4. 实例:并发服务器(为客户请求 fork 进程)
下面实例中,为每个客户请求 fork 一个子进程来处理连接,处理完就退出。
/* 只演示了核心代码逻辑。比如没有wait子进程(防止子进程成为zombie process)等代码 */
for (;;) {
cfd = accept(lfd, NULL, NULL); /* Wait for connection */
if (cfd == -1) {
perror("accept");
exit(EXIT_FAILURE);
}
/* Handle each client request in a new child process */
switch (fork()) { /* fork后,“监听套接字”和“已连接套接字”都会共享 */
case -1:
syslog(LOG_ERR, "Can't create child (%s)", strerror(errno));
close(cfd); /* Give up on this client */
break; /* May be temporary; try next client */
case 0: /* Child */
close(lfd); /* “监听套接字”在父进程中处理,子进程中应该close它 */
handleRequest(cfd); /* 实际处理代码在handleRequest函数中 */
exit(EXIT_SUCCESS);
default: /* Parent */
close(cfd); /* “已连接套接字”会在子进程中处理,父进程中应该close它(即引用计数减1) */
break; /* Loop to accept next connection */
}
}
参考:
The Linux Programming Interface, 60.3 A Concurrent TCP echo Server
《UNIX 网络编程卷 1:套接字联网 API(第 3 版)》 4.8 节 并发服务器
3. UDP 套接字编程
图 4 给出了典型的 UDP 客户/服务器程序的函数调用。客户不与服务器建立连接,而是只管使用 sendto 函数给服务器发送数据报,其中必须指定目的地(即服务器)的地址作为参数。类似地,服务器不接受来自客户的连接,而是只管调用 recvfrom 函数,等待来自某个客户的数据到达。recvfrom 将与所接收的数据报一道返回客户的协议地址,因此服务器可以把响应发送给正确的客户。
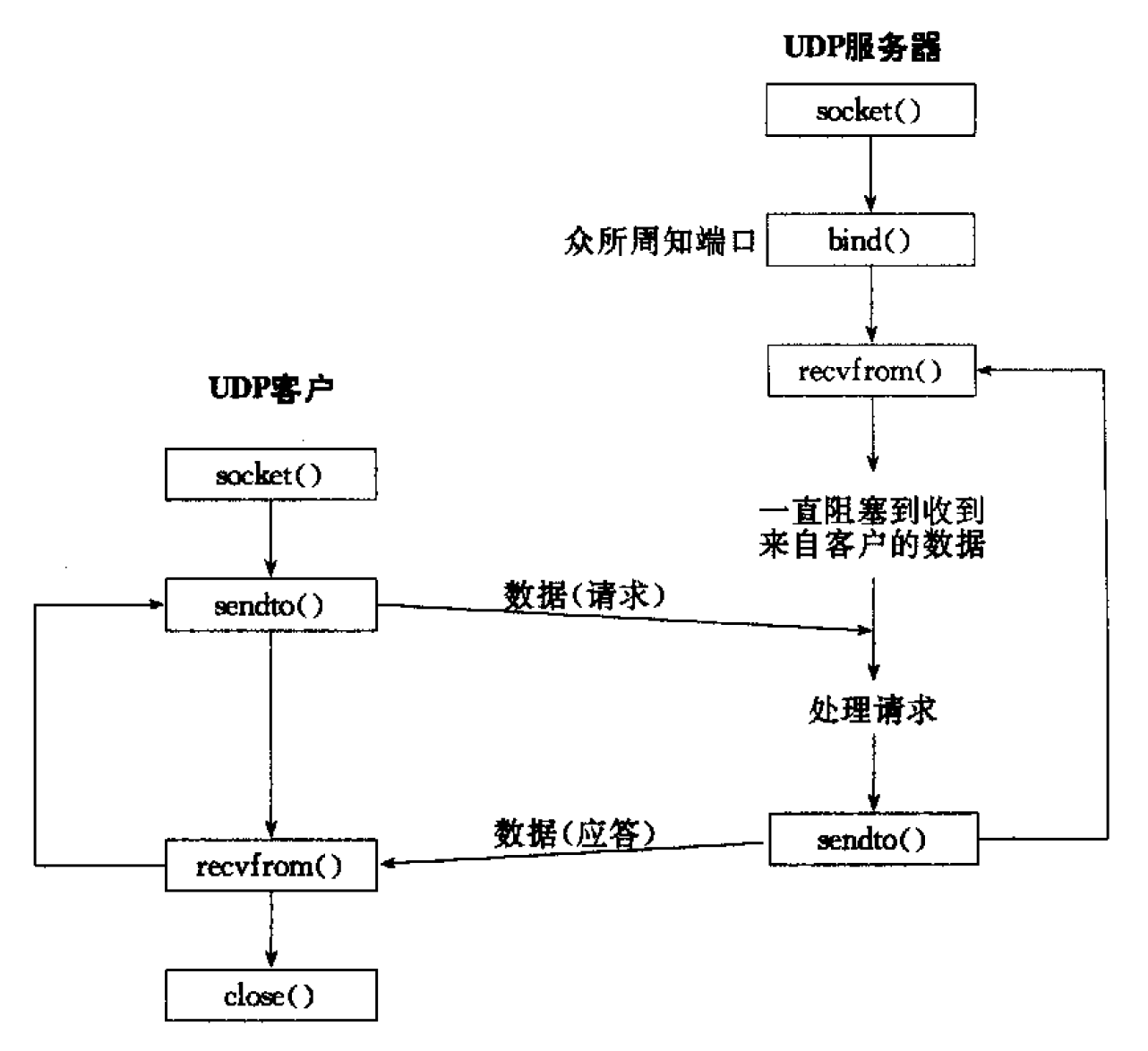
Figure 4: 基本 UDP 客户——服务器程序所用的套接字函数
4. 套接字选项
用 getsockopt 可以获取 socket 的相关选项,用 setsockopt 可以设置 socket 的相关选项。
#include <sys/socket.h>
int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t *optlen);
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
/* Both return 0 on success, or –1 on error */
其中,level 可以是 SOL_SOCKET/IPPROTO_IP/IPPROTO_TCP 等。
参考:《UNIX 网络编程第 1 卷:套接口 API 和 XOpen 传输接口 API(第 2 版)》第 7 章
4.1. SO_REUSEADDR
SO_REUSEADDR 是一个常用的套接字选项,它有下面 4 个作用。
作用一:使服务器可以快速重启。 SO_REUSEADDR 通知内核,如果端口忙,但 TCP 状态位于 TIME_WAIT,可以重用端口。
这个情况可能这样碰到的:
(a) 启动一个监听服务器;
(b) 连接请求到达,派生一个子进程来处理这个客户;
(c) 监听服务器终止,但子进程继续为现有连接上的客户提供服务;
(d) 重启监听服务器。
默认地,监听服务器在步骤(d)时会出现 bind 失败,但如果该服务器在调用 bind 前设置了 SO_REUSEADDR 套接字选项,则 bind 将成功。
作用二:允许在同一个端口启动同一个服务器的多个实例,只要每个实例捆绑一个不同的本地 IP 地址即可。 这对于使用 IP 别名技术托管多个 HTTP 服务器的网点来说是很常见的。假设本地主机的主 IP 为 198.69.10.2,不过它有两个别名:198.69.10.128 和 198.69.10.129。启动三个 HTTP 服务器。第一个绑定到 INADDR_ANY 和端口 80。第二个 HTTP 服务器绑定到 198.69.10.128 和端口 80 会失败,除非调用 bind 前设置了 SO_REUSEADDR 选项。
作用三:允许单个进程捆绑同一端口到多个套接字上,只要每次捆绑指定不同的本地 IP 地址即可。
作用四:允许完全重复的捆绑:当一个 IP 地址和端口已绑定到某个套接字上时,如果传输协议支持,同样的 IP 地址和端口还可以捆绑到另一个套接字上。 一般来说,这个特性仅在支持多播的系统上才有,而且只对 UDP 套接口而言(TCP 不支持多播)。
4.2. SO_KEEPALIVE
用 SOL_SOCKET 级别的 SO_KEEPALIVE 选项可以启动 socket 的 keepalive 特性。如果 2 小时(一般是默认值)内此套接字的任一方向都没有数据交换,TCP 就自动给对方发一个保持存活探测分节(keepalive probe)。
下面是一个设置和检测 keepalive 选项的测试程序:
/* --- begin of keepalive test program --- */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main(void);
int main()
{
int s;
int optval;
socklen_t optlen = sizeof(optval);
/* Create the socket */
if((s = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP)) < 0) {
perror("socket()");
exit(EXIT_FAILURE);
}
/* Check the status for the keepalive option */
if(getsockopt(s, SOL_SOCKET, SO_KEEPALIVE, &optval, &optlen) < 0) {
perror("getsockopt()");
close(s);
exit(EXIT_FAILURE);
}
printf("SO_KEEPALIVE is %s\n", (optval ? "ON" : "OFF"));
/* Set the option active */
optval = 1;
optlen = sizeof(optval);
if(setsockopt(s, SOL_SOCKET, SO_KEEPALIVE, &optval, optlen) < 0) {
perror("setsockopt()");
close(s);
exit(EXIT_FAILURE);
}
printf("SO_KEEPALIVE set on socket\n");
/* Check the status again */
if(getsockopt(s, SOL_SOCKET, SO_KEEPALIVE, &optval, &optlen) < 0) {
perror("getsockopt()");
close(s);
exit(EXIT_FAILURE);
}
printf("SO_KEEPALIVE is %s\n", (optval ? "ON" : "OFF"));
close(s);
exit(EXIT_SUCCESS);
}
/* --- end of keepalive test program --- */
注:上面程序摘自http://www.tldp.org/HOWTO/html_single/TCP-Keepalive-HOWTO/#examples
4.2.1. 定制 keepalive
由于系统的 keepalive 一般会设置为 2 小时,如果这不能满足需求,可以在应用程序中覆盖系统的设置。
IPPROTO_TCP 级别的 TCP_KEEPIDLE/TCP_KEEPINTVL/TCP_KEEPCNT 对 keepalive 做更精细的控制。它们的说明如下:
- tcp_keepalive_time(TCP_KEEPIDLE)
- the interval between the last data packet sent (simple ACKs are not considered data) and the first keepalive probe; after the connection is marked to need keepalive, this counter is not used any further.
- tcp_keepalive_intvl(TCP_KEEPINTVL)
- the interval between subsequential keepalive probes, regardless of what the connection has exchanged in the meantime.
- tcp_keepalive_probes(TCP_KEEPCNT)
- the number of unacknowledged probes to send before considering the connection dead and notifying the application layer.
说明:并不是所有系统都支持上面的设置,如 Solaris 中就不支持在应用级别定制 keepalive。
5. I/O 复用
5.1. 五种 I/O 模型概述
UNIX 中有五种可用的 I/O 模型:
- 阻塞 I/O
- 非阻塞 I/O
- I/O 复用 (select 和 poll)
- 信号驱动 I/O (SIGIO)
- 异步 I/O (aio_系列函数)
5.1.1. 阻塞 I/O
阻塞 I/O 是最简单的模型,默认情况下,I/O 系统调用都是阻塞的。这种方式的编程比较简单。
5.1.2. 非阻塞 I/O
阻塞 I/O 很可能由于数据没有准备好,而使进程长时间等待在 read 或 write 上。
非阻塞 I/O 使 open/read/write 等 I/O 操作函数不会阻塞,如果操作无法完成,就立即返回出错(设置 errno 为 EAGIN 或 EWOULDBLOCK,在大多数现代系统中 EAGIN 和 EWOULDBLOCK 是相同的值)。
5.1.2.1. 设置为非阻塞 I/O
两种方法可以设置描述符为非阻塞 I/O 的方式:
方法一:如果调用 open 获得描述符,则可指定 O_NONBLOCK 标志;
方法二:对于已经打开的一个描述符,则可以调用 fcntl,则该函数打开 O_NONBLOCK 文件状态标志。
5.1.2.2. 轮询(浪费 CPU 资源)
在非阻塞 I/O 中,如果发现返回 EAGIN 或 EWOULDBLOCK 错误,可以隔一段时间再进行尝试。这种形式的循环称为 轮询(polling) 。但轮询中,我们很难知道需要等待多久再进行尝试,这可能 严重浪费 CPU 资源 。
5.1.3. 信号驱动 I/O(对于 TCP 套接字近乎无用)
信号驱动式 I/O 是指进程预先告知内核,使得当某个描述符上发生某事时,内核使用信号通知相关进程。它在历史上也曾被称为异步 I/O。
针对一个套接使用信号驱动 I/O 要求进程执行以下 3 个步骤:
(1) 建立 SIGIO 信号的信号处理函数;
(2) 设置该套接字的属主,通常使用 fcntl 的 F_SETOWN 命令设置;
(3) 开启该套接字的信号驱动式 I/O,通常通过使用 fcntl 的 F_SETFL 命令打开 O_ASYNC 标志完成。
在 UDP 上使用信号驱动式 I/O 是简单的。SIGIO 信号在发生以下事件时产生:
- 数据报到达套接字;
- 套接字上发生异步错误。
不幸的是,信号驱动式 I/O 到于 TCP 套接字近乎无用。因为信号 SIGIO 产生得过于频繁,且它的出现并没有告诉我们发生了什么事件。 下面条件均会导致对于一个 TCP 套接字产生 SIGIO 信号(假设该套接字的信号驱动式 I/O 已经开启):
- A connection request has completed on a listening socket
- A disconnect request has been initiated
- A disconnect request has completed
- Half of a connection has been shut down
- Data has arrived on a socket
- Data has been sent from a socket (i.e., the output buffer has free space)
- An asynchronous error occurred
参考:《UNIX 网络编程卷 1:套接字联网 API(第 3 版)》第 25 章 信号驱动式 I/O
5.1.4. 异步 I/O(应用程序设计比较复杂)
System V 系统和 BSD 系统中对异步 I/O 有自己的实现,它们都有各自的局限,这里讨论的是 POSIX 异步 I/O。
使用 POSIX 异步 I/O 接口,多少有些复杂:
- 每个异步操作有 3 处可能产生错误的地方:一处是操作提交的部分,一处是操作本身的结果,还有一处是用于决定异步操作状态的函数中。
- 与传统方法相比,它涉及大量的额外设置和处理规则。
- 从错误中恢复可能会比较困难。举例来说,如果提交了多个异步写操作,其中一个失败了,下一步我们应该怎么做?如果这些写操作是相关的,那么可能还需要撤销所有成功的写操作。
参考:《UNIX 环境高级编程(第 3 版)》14.5 异步 I/O
5.1.5. I/O 复用(单进程设计中应用最广)
对于单进程设计,要提供较好的并发度,I/O 复用是较好的选择。后文将介绍它。
5.1.6. 五种 I/O 模型比较
如后面给出的例子所述, 一个输入操作一般可以分为两个不同的阶段:(1) 等待数据准备好;(2) 将数据从内核缓冲区拷贝到应用程序的缓冲区。
下面将以 UDP 而不是 TCP 为例来介绍各个 I/O 模型的特点。采用 UDP 作为例子的原因是在 UDP 中“数据准备好”的概念比较简单:整个数据报是否已经接收。这些都是通用的 I/O 模型,不一定要用于 socket。
阻塞 I/O 模型如图 5 所示。
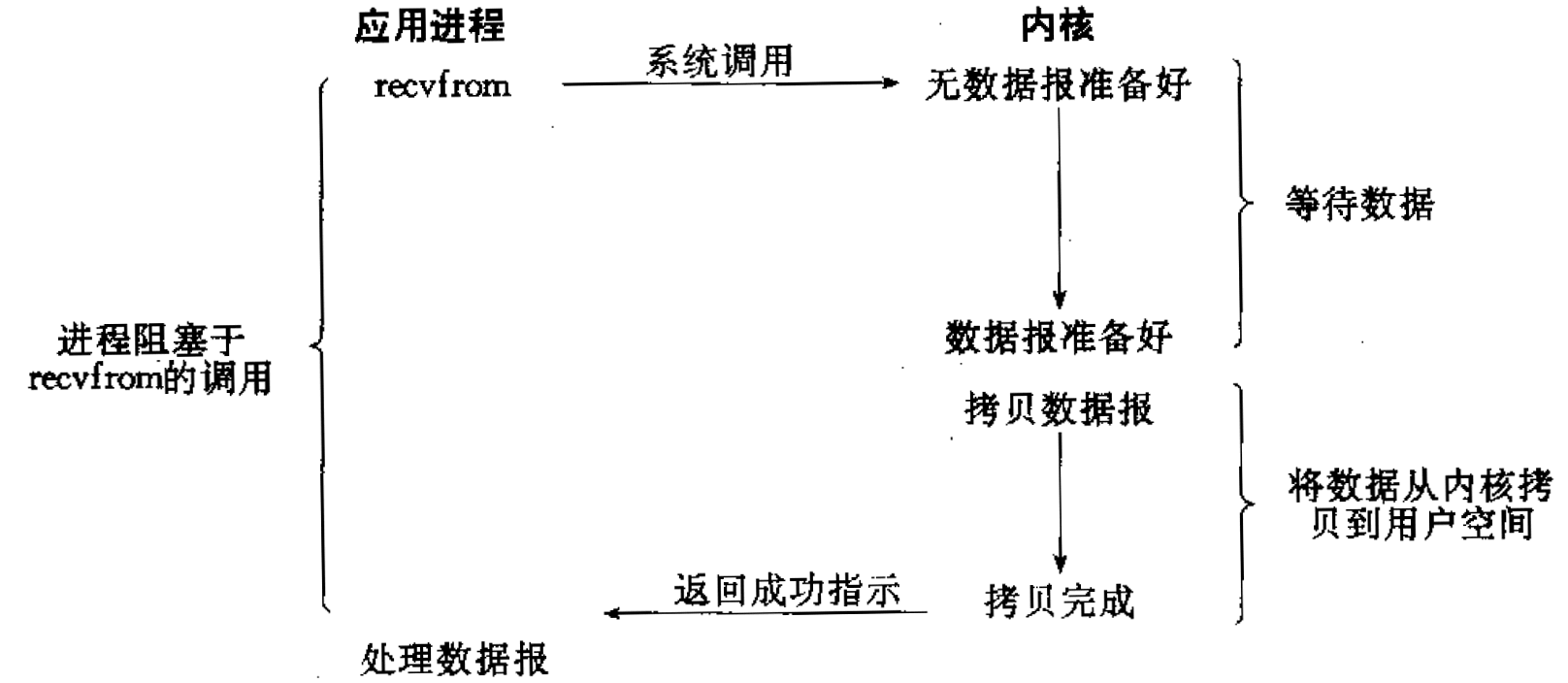
Figure 5: Blocking I/O model
非阻塞 I/O 模型如图 6 所示。
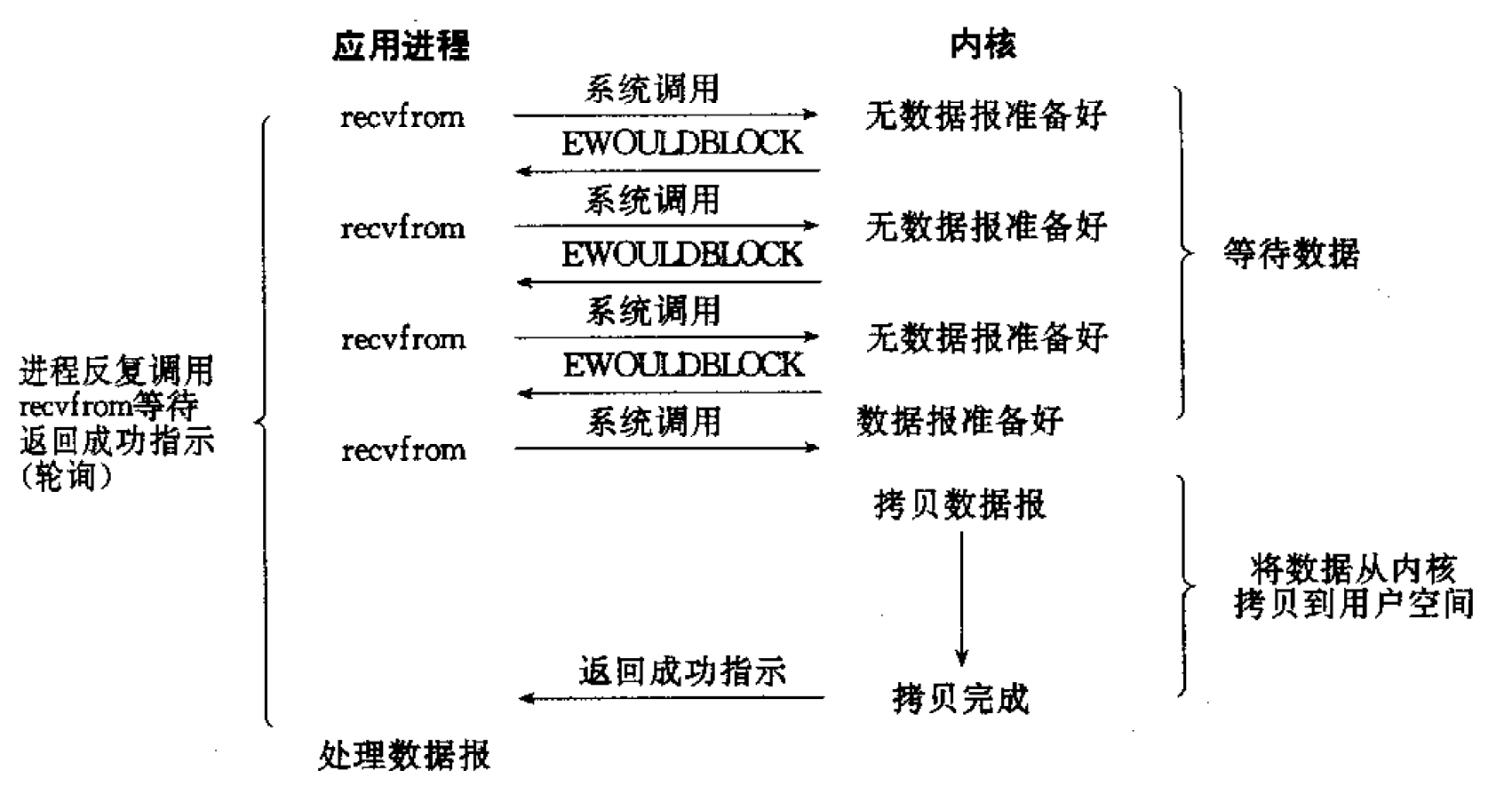
Figure 6: Nonblocking I/O model
I/O 复用模型如图 7 所示。
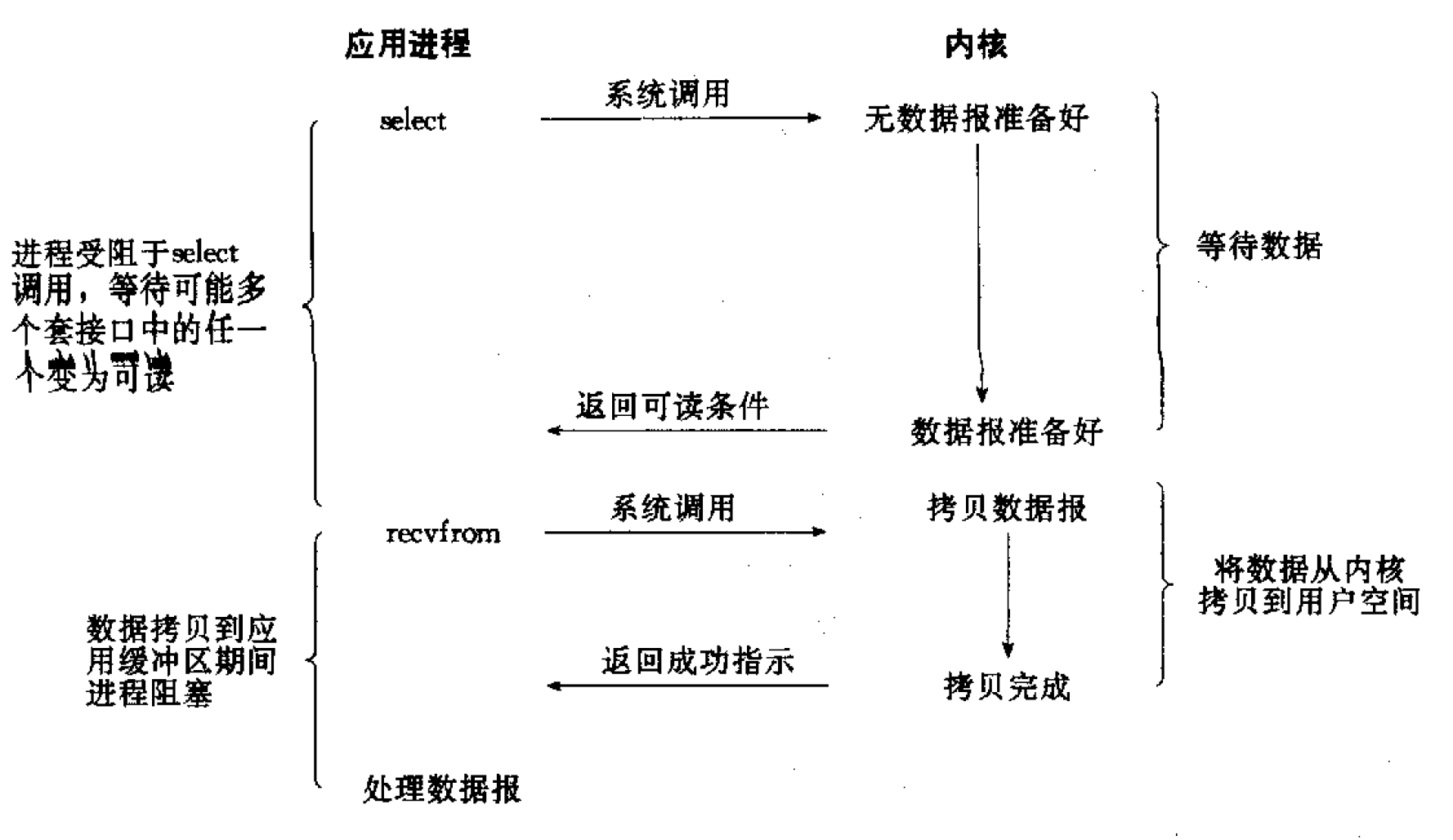
Figure 7: I/O multiplexing model
信号驱动 I/O 模型如图 8 所示。
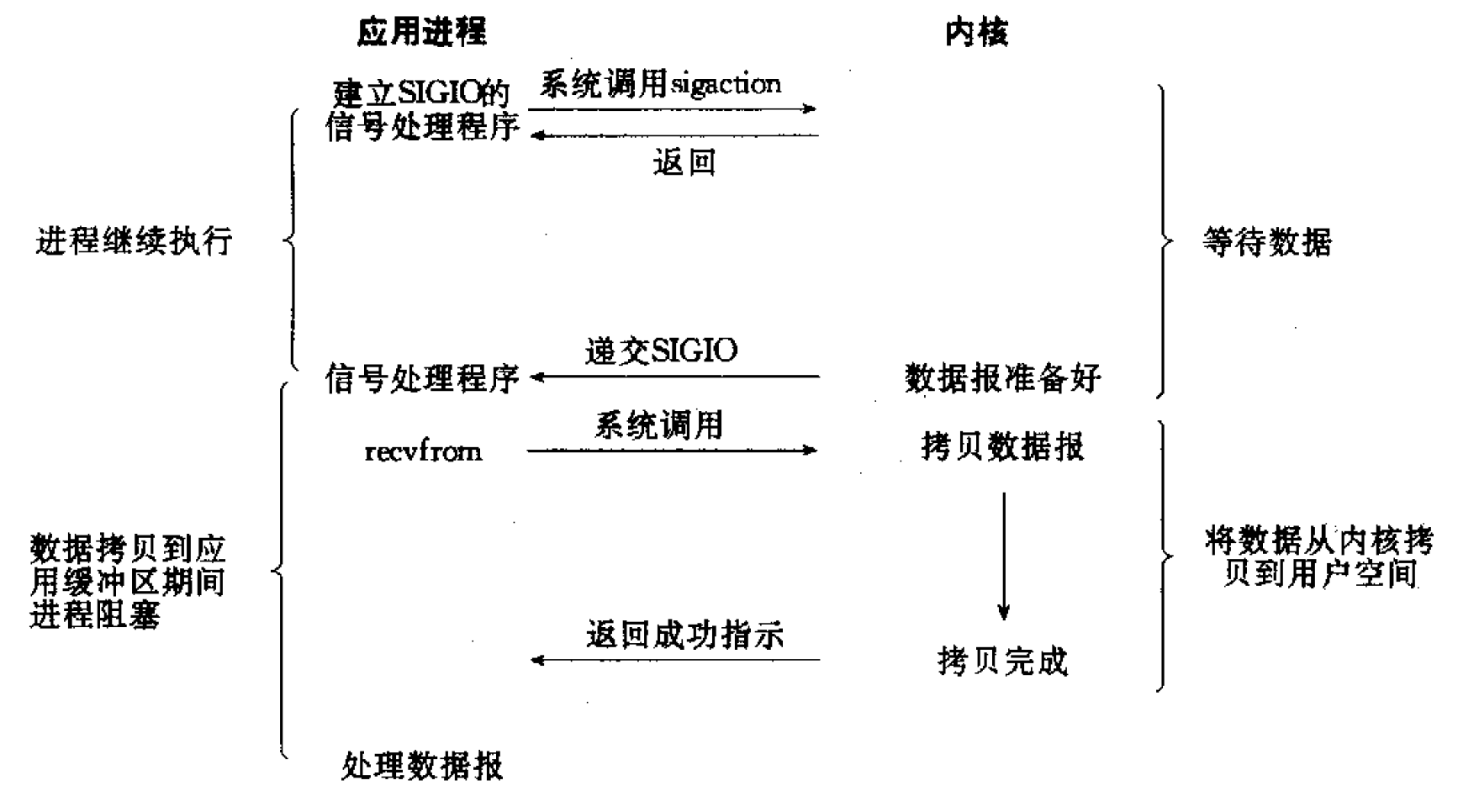
Figure 8: Signal-Driven I/O model
异步 I/O 模型如图 9 所示。
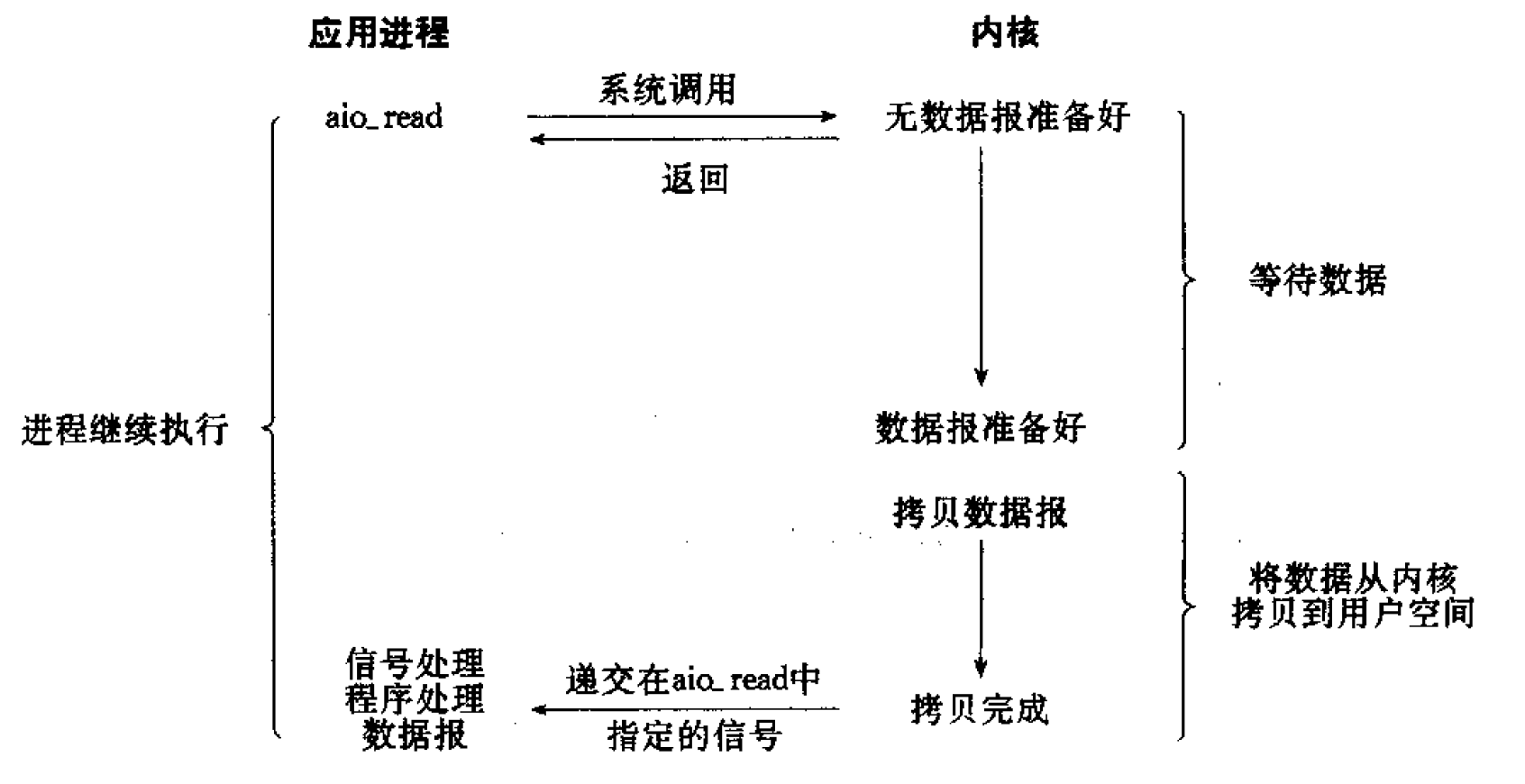
Figure 9: Asynchronous I/O model
在前面介绍的五种 I/O 模型中,前四种模型的主要区别都在第一阶段(等待数据),第二阶段(将数据从内核拷贝到用户空间)基本相同。而异步 I/O 模型处理的两个阶段都不同于前四个模型。五种 I/O 模型的比较如图 10 所示。
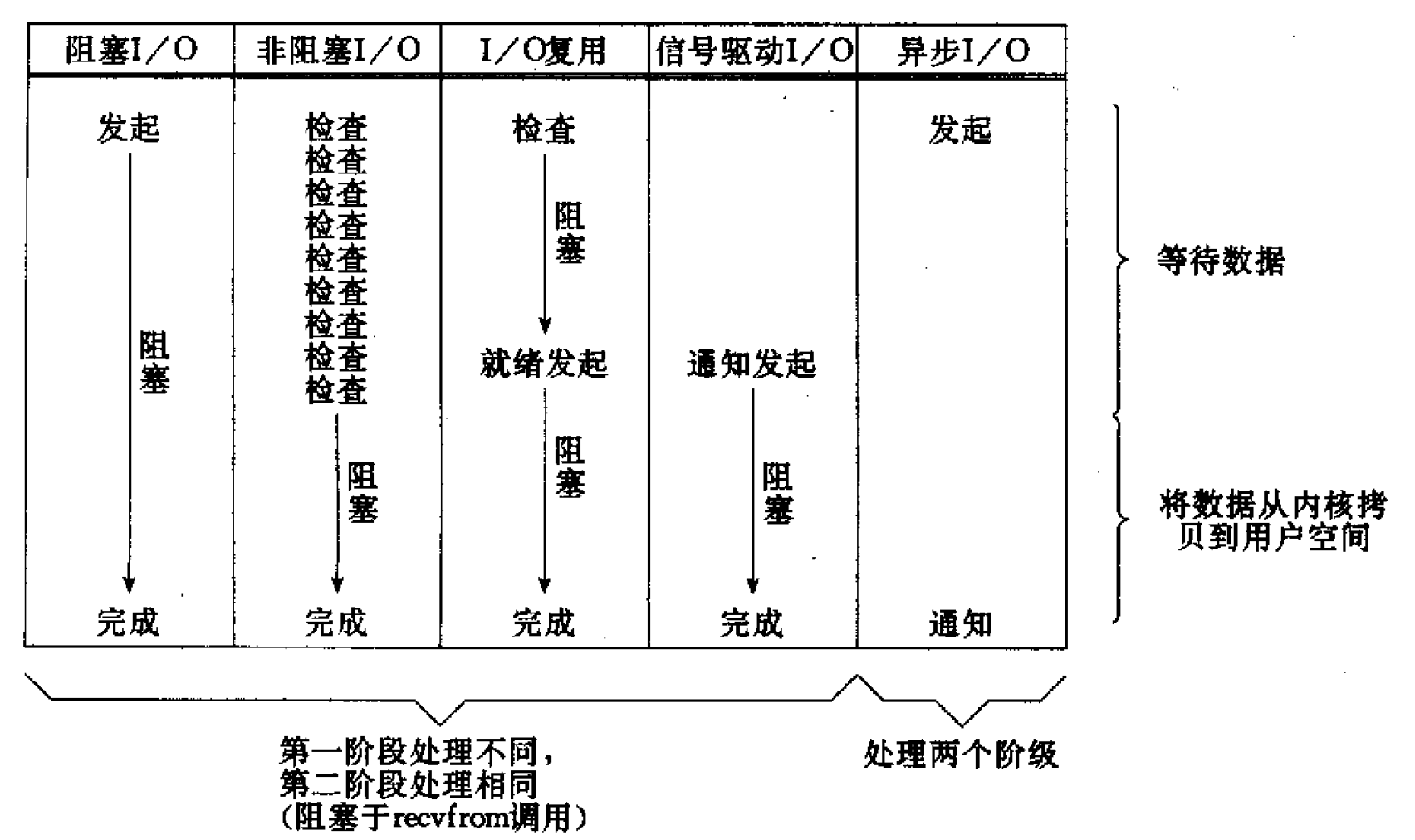
Figure 10: Comparison of the five I/O models
5.2. I/O 复用——select 函数
不用多进程(或多线程)时,阻塞 I/O 无法同时处理多个请求,而对于非阻塞 I/O,其轮询操作会浪费 CPU 资源。
select 函数可以允许应用程序同时在多个文件描述符上等待输入的到达(或者等待输出的结束)。
基本用法是: 先构造一个我们感兴趣的描述符的列表,然后调用函数 select,直到这些描述符中的一个已经准备好进行 I/O 时,select 才返回,返回时内核告诉我们已准备好的描述符总数量以及哪些描述符已准备好。
select 函数的原型为:
#include <sys/select.h>
int select(int maxfdp1, /* 最大文件描述符编号值加1 */
fd_set *restrict readfds, /* 既是输入参数,又是输出参数 */
fd_set *restrict writefds, /* 既是输入参数,又是输出参数 */
fd_set *restrict exceptfds, /* 既是输入参数,又是输出参数 */
struct timeval *restrict tvptr); /* 愿意等待的时间(也可能是输出参数) */
/* Returns: count of ready descriptors, 0 on timeout, −1 on error */
5.2.1. select 的参数说明
下面将从后往前介绍 select 每个参数的含义。
select 的最后一个参数 tvptr 用来指定愿意等待的时间,timeval 结构的精度可控制为“秒数”和“微秒数”。
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
}
| tvptr | 描述 |
|---|---|
| tvptr == NULL | 永远等待。如果捕捉到一个信号则中断此无限期等待。 |
tvptr->tv_sec == 0 && tvptr->tv_usec == 0 |
根本不等待。检查描述符后立即返回,这称为轮询。 |
| tvptr->tv_sec != 0 || tvptr->tv_usec != 0 | 等待指定的秒数和微秒数。时间未到时,也可被信号中断。 |
说明 1: 一个描述符阻塞与否并不影响 select 是否阻塞。
说明 2:POSIX.1 允许在 select 实现中修改 tvptr 结构中的值,所以在 select 返回后,不要指望该结构仍旧保持调用 select 之前它所包含的值。FreeBSD 5.2.1、Mac OS X 10.3 和 Solaris 9 都保持该结构中的值不变。但是 Linux 2.4.22 中,若在该时间值尚未超过时 select 就返回,那么将用“余留时间值”更新该结构。
select 的中间 3 个参数 readfds/writefds/exceptfds 是指向描述符集的指针。这 3 个描述符说明了我们关心的可读、可写或处于异常条件的描述符集合。select 会修改由指针 readfds/writefds/exceptfds 所指向的描述符集。所以, readfds/writefds/exceptfds 既是输入参数又是输出参数(或称“值—结果”参数),调用 select 时,我们指定它为所关心的描述符,当 select 返回时,它将指示哪些描述符已就绪。
fd_set 类型可以由具体的实现来决定,可以认为 fd_set 变量是一个很大的字节数组 ,你可以使用下面函数(或宏)来设置或测试它。
| fd_set 操作函数 | 描述 |
|---|---|
| FD_ZERO | 将 fd_set 变量的所有位设置为 0 |
| FD_SET | 开启 fd_set 变量中的一位 |
| FD_CLR | 消除 fd_set 变量中的一位 |
| FD_ISSET | 测试 fd_set 变量中的指定位是否打开 |
如果 readfds/writefds/exceptfds 指定为空指针表示对相应的条件并不关心。如果 3 个指针都是 NULL,则 select 提供了比 sleep(仅整数秒)更精确的定时器。
select 的第一个参数 maxfdp1 的意思是“最大文件描述符编号值加 1”。它有两种常见的设置:
- 在 3 个描述符集中找出最大的描述符编号值,然后加 1(因为描述符从 0 开始)。
- 设置为 FD_SETSIZE,一般地,它的典型值为 1024。
说明: 通过指定所关注的最大描述符的个数,内核就只需要在些范围内寻找打开的位。 显然,如果我们关心的描述符很少,maxfdp1 设置为 FD_SETSIZE 时可能会影响效率。
参考:
《UNIX 环境高级编程(第 3 版)》14.4 节
《UNIX 网络编程卷 1:套接字联网 API(第 3 版)》6.3 节
5.2.2. select 简单实例
下面是 select 的实例。为简单起见,例子中仅设置对一个描述符(标准输入)感兴趣。
#include <stdio.h>
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int main(void) {
fd_set readfds;
struct timeval tv;
int retval;
FD_ZERO(&readfds);
FD_SET(0, &readfds); /* 把“标准输入”放入“对可读状态感兴趣的描述符集”中 */
/* 如果还对其它描述符的可读状态感兴趣,可以把它加入到readfds中:FD_SET(xx, &readfds); */
tv.tv_sec = 3; /* select最多等待3秒 */
tv.tv_usec = 0;
retval = select(1, &readfds, NULL, NULL, &tv);
switch (retval) {
case -1:
perror("select()");
case 0:
printf("Timeout, no data within 3 seconds.\n");
break;
default:
printf("Data is available now.\n");
/* FD_ISSET(0, &readfds) will be true. */
}
return 0;
}
上面程序测试如下:
$ echo abc | ./a.out Data is available now. $ ./a.out # 3秒内不进行任何操作 Timeout, no data within 3 seconds.
select 的其它例子(更接近于实际应用):http://www.lowtek.com/sockets/select.html
5.2.3. select 版 echo 服务器
下面是 select 版本的 echo 服务器。主要代码参考:http://www.gnu.org/software/libc/manual/html_node/Server-Example.html
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <string.h>
#define PORT 5555
#define MAXMSG 512
int make_socket (uint16_t port) {
int sock;
struct sockaddr_in name;
sock = socket (PF_INET, SOCK_STREAM, 0);
if (sock < 0) {
perror ("socket");
exit (EXIT_FAILURE);
}
name.sin_family = AF_INET;
name.sin_port = htons (port);
name.sin_addr.s_addr = htonl (INADDR_ANY);
if (bind (sock, (struct sockaddr *) &name, sizeof (name)) < 0) {
perror ("bind");
exit (EXIT_FAILURE);
}
return sock;
}
int do_it (int filedes) {
char buffer[MAXMSG] = { 0 };
int nbytes;
nbytes = read (filedes, buffer, MAXMSG);
if (nbytes < 0) {
/* Read error. */
perror ("read");
exit (EXIT_FAILURE);
}
else if (nbytes == 0)
/* End-of-file. */
return -1;
else {
/* Data read. */
fprintf (stderr, "Server: got message: `%s'\n", buffer);
/* Just echo the input string back to the client */
write(filedes, buffer, strlen(buffer));
return 0;
}
}
int main (void) {
int sock;
fd_set active_fd_set, read_fd_set;
int fd;
struct sockaddr_in clientname;
socklen_t size;
/* Create the socket and set it up to accept connections. */
sock = make_socket (PORT);
if (listen (sock, 1) < 0) {
perror ("listen");
exit (EXIT_FAILURE);
}
/* Initialize the set of active sockets. */
FD_ZERO (&active_fd_set);
FD_SET (sock, &active_fd_set);
/* 把sock加入到select监视的可读描述符中,
当sock可读时(有新客户连接)select会返回,这时可以用accept获取它 */
while (1) {
/* select 的第2,3,4,5个参数都是“输入-输出”参数,可能被select修改,
即使监视的描述符不变(这里监视的描述符是变化的),也要在每次调用
select前要重新设置它们。
*/
read_fd_set = active_fd_set;
/* Block until input arrives on one or more active sockets. */
if (select (FD_SETSIZE, &read_fd_set, NULL, NULL, NULL) < 0) {
perror ("select");
exit (EXIT_FAILURE);
}
/* Service all the sockets with input pending. */
for (fd = 0; fd < FD_SETSIZE; ++fd) {
if (FD_ISSET (fd, &read_fd_set)) {
if (fd == sock) {
/* Connection request on original socket. */
int new;
size = sizeof (clientname);
new = accept (sock, (struct sockaddr *) &clientname, &size);
if (new < 0) {
perror ("accept");
exit (EXIT_FAILURE);
}
fprintf (stdout,
"Server: connect from host %s, port %hu.\n",
inet_ntoa(clientname.sin_addr),
ntohs(clientname.sin_port));
/* 把“新的客户连接加入到select监视的可读描述符中 */
FD_SET (new, &active_fd_set);
} else {
/* Data arriving on an already-connected socket. */
if (do_it (fd) < 0) {
close (fd);
FD_CLR (fd, &active_fd_set);
}
}
}
}
}
}
5.2.4. select 的缺点
select 存在下面的缺点:
- 最大的并发数限制。进程打开的文件描述符是有限制的(为 FD_SETSIZE,一般为 1024)。
- select 返回后,应用程序仅仅知道有几个描述符已经准备好(有数据),而不知道具体是哪些描述符准备好了,应用程序要 遍历描述符集合才能知道具体哪个描述符已经准备好了 ,当监视的描述符多时,会影响效率。即 I/O 效率随着监视描述符的数目增加而线性下降。
- select 会修改它的参数 readfds/writefds/exceptfds,在后续调用 select 时,要监控同样的描述符,不得不重新初始化参数(可先备份,在再次调用 select 前用 memcpy 恢复这些参数),这会影响效率。
参考:http://stackoverflow.com/questions/970979/what-are-the-differences-between-poll-and-select
5.3. I/O 复用——poll 函数
poll 函数和 select 类似,也能实现 I/O 复用。poll 函数的原型如下:
#include <poll.h>
int poll(struct pollfd fdarray[], nfds_t nfds, int timeout);
/* Returns: count of ready descriptors, 0 on timeout, −1 on error */
和 select 不同之处在于,表达描述符集合的方式不同,poll 使用 pollfd 结构,而不是 select 的 fd_set 结构。
struct pollfd {
int fd; /* file descriptor to check, or < 0 to ignore */
short events; /* (输入参数) events of interest on fd */
short revents; /* (输出参数) events that occurred on fd */
};
5.3.1. select 和 poll 的比较
poll 没有并发数的限制。 因为数组 fdarray 的大小由参数 nfds 指定,它由应用程序指定,可以是非常大。
poll 的参数设计比 select 更合理,它把“输入参数”和“输出参数”分开了(在 pollfd 中分别属于不同的成员),这样不用像 select 那样在后续的调用前需要初始化它的参数 readfds/writefds/exceptfds。
不过,select 中需要轮询才能获取就绪的描述符的缺点,在 poll 中仍然没有解决: poll 函数返回后,也需要轮询 pollfd 数组才能获取就绪的描述符。 一般地,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,poll 的效率也会线性下降。*
5.4. I/O 复用——epoll 函数(Linux 中)
当所监听的文件描述符很多时,select/poll 有下面两个缺点会影响性能:
1、每次调用 select/poll,都需要把文件描述符集合从用户态拷贝到内核态,这个开销在文件描述符很多时会很大。
2、select/poll 返回后需要遍历整个描述符集合才能知道哪些描述符就绪了;
epoll 解决了上面的问题。和 select/poll 仅提供一个函数不一样, epoll 提供了三个函数, epoll_create/epoll_create1, epoll_ctl 和 epoll_wait 。其中, epoll_create/epoll_create1 是创建一个 epoll 句柄(文件描述符,后面两个函数的第一参数就是这个 epoll 句柄); epoll_ctl 是注册/移除想监听的文件描述符和事件类型等等; epoll_wait (只有它需要在循环中调用)则是等待事件的产生。
对于前面提到的第 1 个缺点,epoll 的解决方案在 epoll_ctl 函数中。通过 epoll_ctl 注册新的事件到 epoll 句柄中时(在 epoll_ctl 中指定 EPOLL_CTL_ADD),会把相应的文件描述符拷贝进内核,而不是在 epoll_wait 的时候重复拷贝,epoll 保证了每个文件描述符在整个过程中只会拷贝一次。
对于前面提到的第 2 个缺点,epoll 的解决方案在 epoll_wait 函数中,它的原型如下:
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll_wait 的第 2 个参数 events 是用户自己开辟的一块事件数组,用于存储就绪的事件集合,第 3 个参数 maxevents 是前面事件数组的大小。返回值大于 1 时表示准备好的描述符个数(它不会超过 maxevents)。这样,采用下面方式遍历 events 数组得到的都是已经就绪的描述符(不像 select/poll 那样需要从描述符集合中遍历寻找已经就绪的描述符):
nfds = epoll_wait(epfd, events, 20, 500);
for(i=0; i<nfds; ++i) {
// process events[i]
}
注: epoll_create 和 epoll_create1 有什么不一样呢?它们的原型如下:
int epoll_create(int size); int epoll_create1(int flags);
epoll_create 的参数 size 仅是一个 hit ,用于告诉内核你“大概”需要多少个文件描述符,该参数从 Linux 2.6.8 起已经废弃,大于 0 的数效果都一样。
epoll_create1 的参数 flags 目前支持 EPOLL_CLOEXEC (这个 flag 类似于 open 的 flag O_CLOEXEC)。
epoll_create/epoll_create1 用于生成一个 epoll 专用的文件描述符。它返回的是一个文件描述符,后面使用 epoll_ctl/epoll_wait 时需要用到它(第一个参数 epfd 就是 epoll_create/epoll_create1 的返回值)。
5.4.1. 水平触发和边缘触发
epoll 有两种模式:LT(Level Triggered,水平触发)和 ET(Edge Triggered,边缘触发)。
LT 模式下,缓冲区数据一次没有处理完,那么下次 epoll_wait 返回时,还会返回这个句柄;而 ET 模式下,缓冲区数据一次没处理结束,那么下次是不会再通知了,只在第一次返回。
默认情况下,epoll 采用“Level Triggered”,在函数 epoll_ctl 中通过设置 EPOLLET 可以修改为“Edge Triggered”。
5.5. I/O 复用——kqueue 函数(FreeBSD 类系统中)
Kqueue is a scalable event notification interface introduced in FreeBSD 4.1, also supported in NetBSD, OpenBSD, DragonflyBSD, and OS X. Kqueue was originally authored in 2000 by Jonathan Lemon, then involved with the FreeBSD Core Team.
6. 经典服务器设计范式
前面介绍的迭代服务器和并发服务器(为客户请求 fork 进程)的实际可应用范围很少。
为了提供比较好的并发性,有两种常见服务器设计:一是单进程中使用 I/O 复用或信号驱动 I/O 等模型;二是预先创建“进程池”或“线程池”。这里将重点介绍预先创建“进程池”或“线程池”的方法。图 11 列出了一些经典服务器设计范式的测试比较。
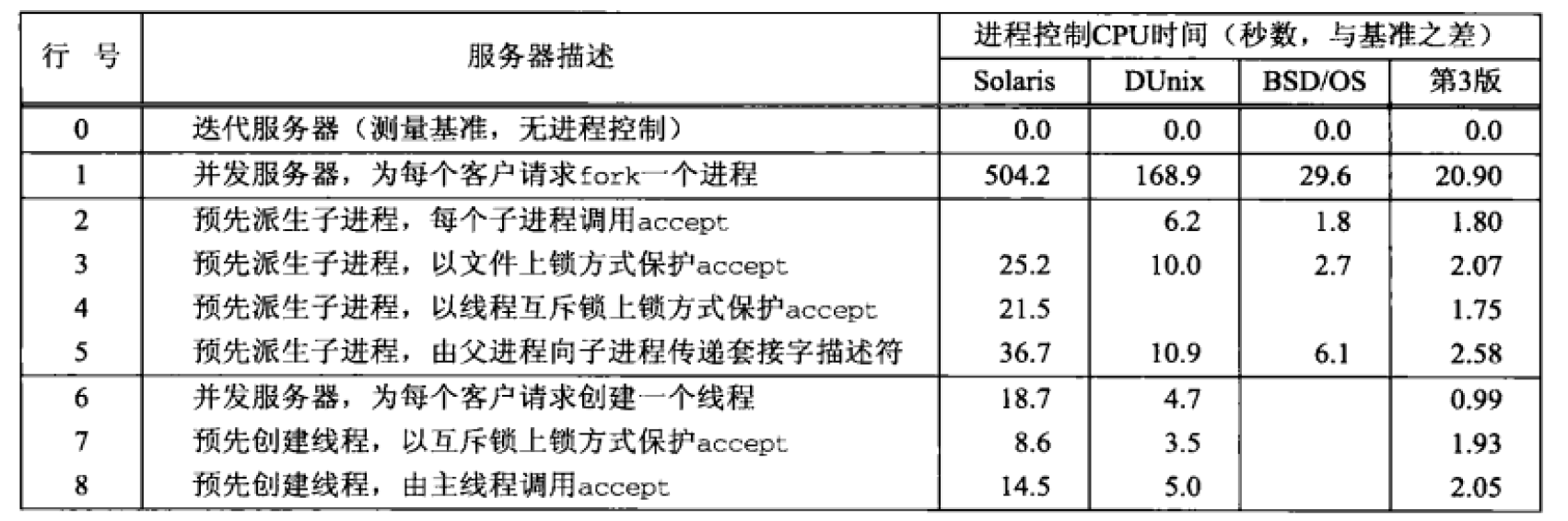
Figure 11: 一些经典服务器设计范式的测试比较(摘自:《UNIX 网络编程,卷 1:套接字联网 API(第 3 版)》,第 30 章)
说明: “进程池”或“线程池”的方法都是比较“经典”的并发服务器设计范式,如果对服务器的并发性要求非常高,则它们都无法胜任。这时,我们可以采用 Reactor 模式(底层使用的是 I/O 复用,如 select/poll 等)或 Proactor 模式(底层使用的是异步 I/O,如 Windows 中的完成端口或 UNIX 中 aio_*()系列函数)来设计服务器。
参考:
《UNIX 网络编程,卷 1:套接字联网 API(第 3 版)》,第 30 章
The Linux Programming Interface, 60.4 Other Concurrent Server Designs
6.1. 实例:并发服务器(预先创建线程池)
下面是一个并发服务器(其功能是返回服务器的当前时间)实例,可以通过命令行参数指定预先启动的线程数。
// file myserv.c: A time server
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <pthread.h>
#include <semaphore.h>
typedef struct _worker_info { /* 每个线程都关联这样一个结构 */
int connfd; /* 保存“已连接套接字”(由accept返回)
初始值为-1,当工作线程在该套接字上的工作完成后也设为-1
它的可能值为-1(当前线程闲),或大于0的值(当前线程忙)
对它的访问要加锁 */
pthread_mutex_t lock; /* 互斥量,用于对connfd的访问加锁 */
pthread_cond_t cond; /* 条件变量,用于管理空闲的线程(让它阻塞,或者唤醒它) */
/* other information */
pthread_t tid;
} worker_info;
worker_info workers[128]; /* 假设线程数不会大于128 */
int threads_num = 3; /* 默认的线程数量 */
sem_t sem; /* 这个信号量管理可用的线程数 */
void * thread_fn(void *arg);
int request_worker();
int main(int argc, char **argv) {
short int port;
if (argc == 2) {
port = atoi(argv[1]);
} else if (argc == 3) {
port = atoi(argv[1]);
threads_num = atoi(argv[2]);
} else {
fprintf(stderr, "%s", "Usage: myserv port [thread_num]\n"); exit(1);
}
/* 第1步:创建socket,绑定、监听到指定端口 */
int listenfd, connfd;
struct sockaddr_in servaddr;
if ((listenfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror("socket"); exit(1);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(port);
if (bind(listenfd, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0) {
perror("bind"); exit (1);
}
if (listen(listenfd, SOMAXCONN) < 0) {
perror("listen"); exit (1);
}
/* 第2步:创建线程池 */
int i;
for (i=0; i < threads_num; i++) {
/* 准备好传递给线程的参数 */
workers[i].connfd = -1;
pthread_mutex_init(&workers[i].lock, NULL);
pthread_cond_init(&workers[i].cond, NULL);
/* 创建线程 */
if (pthread_create(&workers[i].tid, NULL, thread_fn, (void *)(workers + i)) != 0) {
perror("pthread_create"); exit(1);
}
}
sem_init(&sem, 0, threads_num); /* 初始信号量为所创建的线程数 */
/* 第3步:为每个“客户连接”分配一个空闲线程进行处理 */
int slot;
int clientfd;
for( ; ; ) {
slot = request_worker(); /* 寻找空闲的线程,找不到会阻塞 */
if ((clientfd = accept(listenfd, NULL, NULL)) < 0) {
perror("accept"); exit(1);
}
pthread_mutex_lock(&workers[slot].lock);
workers[slot].connfd = clientfd;
pthread_mutex_unlock(&workers[slot].lock);
/* 唤醒这个空闲的线程 */
pthread_cond_signal(&workers[slot].cond);
}
return 0;
}
/* 在线程池中寻找一个空闲线程,当没有空闲线程时会阻塞 */
int request_worker() {
sem_wait(&sem); /* 仅当有空闲线程时,才会返回 */
int i;
int found = 0;
for (i=0; i < threads_num; i++) {
if (workers[i].connfd == -1) {
found = 1;
break;
}
}
assert(found == 1);
return i;
}
/* 业务逻辑(对socket的读写操作)都在这里 */
void doit(int sockfd) {
char buff[1024];
time_t ticks;
ticks = time(NULL);
snprintf(buff, sizeof(buff), "%.24s\r\n", ctime(&ticks));
write(sockfd, buff, strlen(buff));
close(sockfd);
/* sleep(1); */
fprintf(stdout, "server log: do work.\n");
}
/* 线程启动函数 */
void * thread_fn(void *arg) {
worker_info *info = (worker_info *)arg;
for( ; ; ) {
pthread_mutex_lock(&info->lock);
while(info->connfd == -1) {
pthread_cond_wait(&info->cond, &info->lock);
/* pthread_cond_wait有3个作用:
(1) 解锁互斥量info->lock
(2) 阻塞线程直到另外的线程通过条件变量info->cond唤醒它
(3) 再次对互斥量info->lock加锁 */
}
doit(info->connfd); /* Do some work with this connection */
info->connfd = -1;
pthread_mutex_unlock(&info->lock);
sem_post(&sem); /* 信号量加1(空闲线程多了1个) */
}
}
上面的实现中,当工作线程没事可做时,会阻塞在函数 pthread_cond_wait 上;当主线程给它分配了工作(把 connfd 从-1 修改为“已连接套接字”)后,就会唤醒它。
注:对于上面的服务器,如果同时连接的客户端非常多,导致没有空闲的线程时(由于时间服务器的处理非常快,为模拟这种场景我们可以在函数 doit 中调用 sleep),会出现什么情况呢?主线程会阻塞在函数 request_worker 中的 sem_wait 上,这会导致 accept 迟迟得不到调用,客户端可能超时。
7. Unix 域协议
Unix 域协议并不是一个实际的协议族,而是在单个主机上执行客户/服务器通信的一种方法,所用 API 与在不同主机上执行客户/服务器通信所用的 API(套接字 API)相同。Unix 域协议可视为进程间通信(IPC)方法之一。
Unix 域提供两类套接字:字节流套接字(类似 TCP)和数据报套接字(类似 UDP)。
使用 Unix 域套接字的理由有 3 个:
(1) 在源自 Berkeley 的实现中,Unix 域套接字往往比通信两端位于同一主机的 TCP 套接字快出一倍。X Window System 使用了 Unix 域套接字的这个优势,如果发现客户和服务器在一个主机上,则会使用 Unix 域字节流连接,否则使用 TCP 连接。
(2) Unix 域套接字可用于在同一个主机上的不同进程间传递描述字。
(3) Unix 域套接字较新的实现把客户的凭证(用户 ID 和组 ID)提供给服务器,从而能够提供额外的安全检查措施。
注:POSIX 把 Unix 域协议重新命名为“本地 IPC”,以消除它对于 Unix 操作系统的依赖。常值 AF_UNIX 变为 AF_LOCAL。尽管如此,我们依然使用“Unix 域”这个称谓,因为这已成为它约定俗成的名字,与支撑它的操作系统无关。