Understanding Query Execution in RDBMS
Table of Contents
1. Query 处理过程简介
Query 的处理过程如图 1(摘自 CMU 15-721, Advanced Database Systems, Query Compilation)所示。
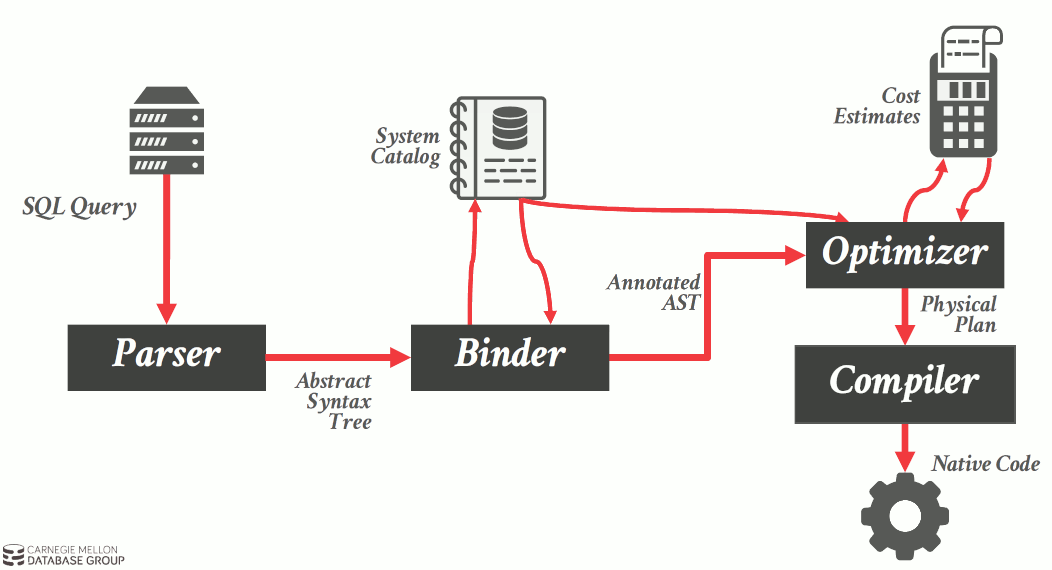
Figure 1: SQL Query 的执行过程
Parser 完成语法分析等任务;Binder 完成参数化查询中参数绑定等任务;Optimizer 用于生成最优的执行计划(Execution Plan)。
不过,经常把 Parser 和 Binder 也归到 Optimizer 中,如图 2(摘自 Query Processing Architecture Guide)所示。
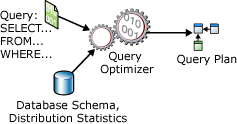
Figure 2: SQL Query 的简化示意图
Optimizer 的输出为“Query Execution Plan”,有时称为“Query Plan”,或者“Execution Plan”等等,它们都是一回事。
1.1. Execution Plan
Execution Plan 由一些 Operator(如 HashJoin、IndexScan、TableScan、Filter、Aggregation 等等)组成。
1.1.1. Google Spanner 的 Execution Plan
图 3 和 4(两图都摘自 Spanner, Query execution plans)是 Google Spanner 的 Execution Plan 例子。图中的“Table Scan”/“Index Scan”/“Filter”/“Local Distributed Union”/“Aggregate”等等都是 Operator。

Figure 3: Spanner's Execution Plan Example 1

Figure 4: Spanner's Execution Plan Example 2
1.1.2. Oracle 的 Execution Plan
Oracle 中使用 EXPLAIN PLAN FOR 语句可查看 SQL 语句的 Execution Plan,如:
EXPLAIN PLAN FOR
SELECT e.last_name, j.job_title, d.department_name
FROM hr.employees e, hr.departments d, hr.jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND e.last_name LIKE 'A%';
Execution Plan
----------------------------------------------------------
Plan hash value: 975837011
--------------------------------------------------------------------------------
| Id| Operation | Name |Rows|Bytes|Cost(%CPU)|Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 189 | 7(15)| 00:00:01 |
|*1 | HASH JOIN | | 3 | 189 | 7(15)| 00:00:01 |
|*2 | HASH JOIN | | 3 | 141 | 5(20)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 3 | 60 | 2 (0)| 00:00:01 |
|*4 | INDEX RANGE SCAN | EMP_NAME_IX | 3 | | 1 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | JOBS | 19 | 513 | 2 (0)| 00:00:01 |
| 6 | TABLE ACCESS FULL | DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
2 - access("E"."JOB_ID"="J"."JOB_ID")
4 - access("E"."LAST_NAME" LIKE 'A%')
filter("E"."LAST_NAME" LIKE 'A%')
输出表格中的第二列就是 Operator 名称(如 HASH JOIN 等等)。
2. Execution Engine
Execution Engine 在 SQL 处理中的层次如图 5(摘自 CMU 15-721, Advanced Database Systems, Query Execution & Processing)所示。
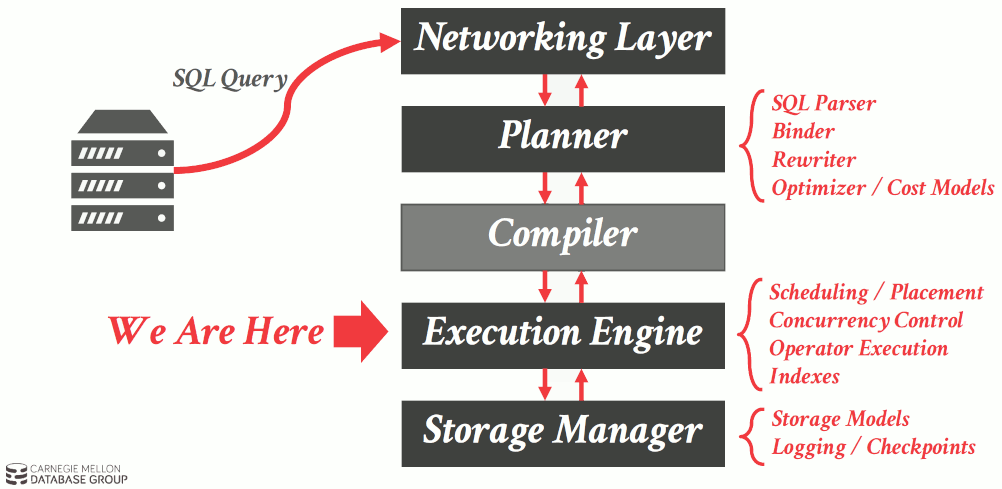
Figure 5: Execution Engine
前面介绍过,Query Plan 由一些算子(Operator)组成:
A query plan is comprised of operators
An operator instance is an invocation of an operator on some segment of data.
A task is the execution of a sequence of one or more operator instances.
更快地执行 Query Plan (Execution Plan) 是 Execution Engine 的目标。
2.1. 处理模型(Processing Model)
A DBMS's processing model defines how the system executes a query plan.
2.1.1. Iterator Model (Volcano or Pipeline Model)
在 Iterator Model 中,每个算子都实现迭代器模式,即实现接口:open/next/close。每个算子从其子节点的 next 接口获得“一条数据”,施加算子自己的计算逻辑,再返回给父节点。
Iterator Model 的处理过程如图 6 所示。
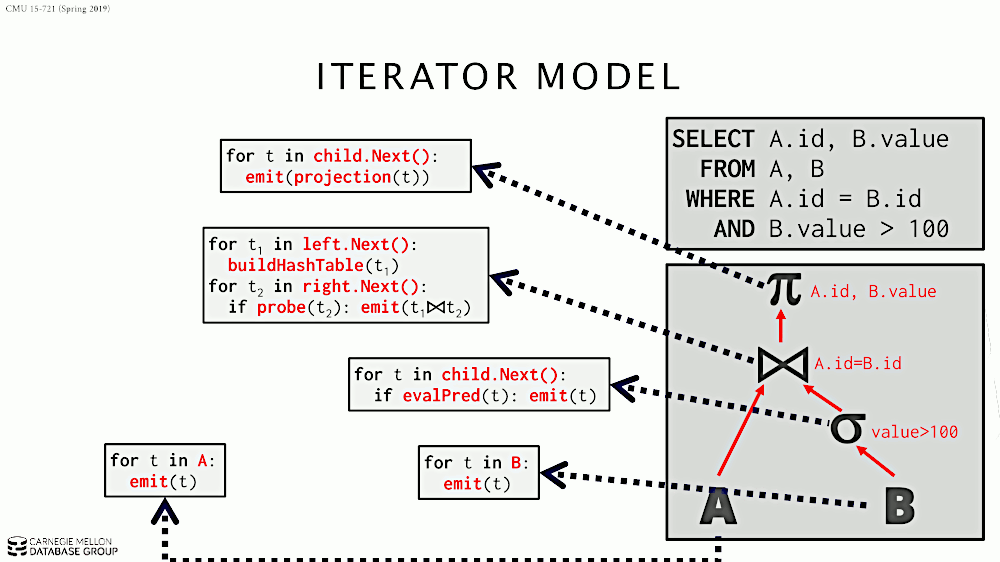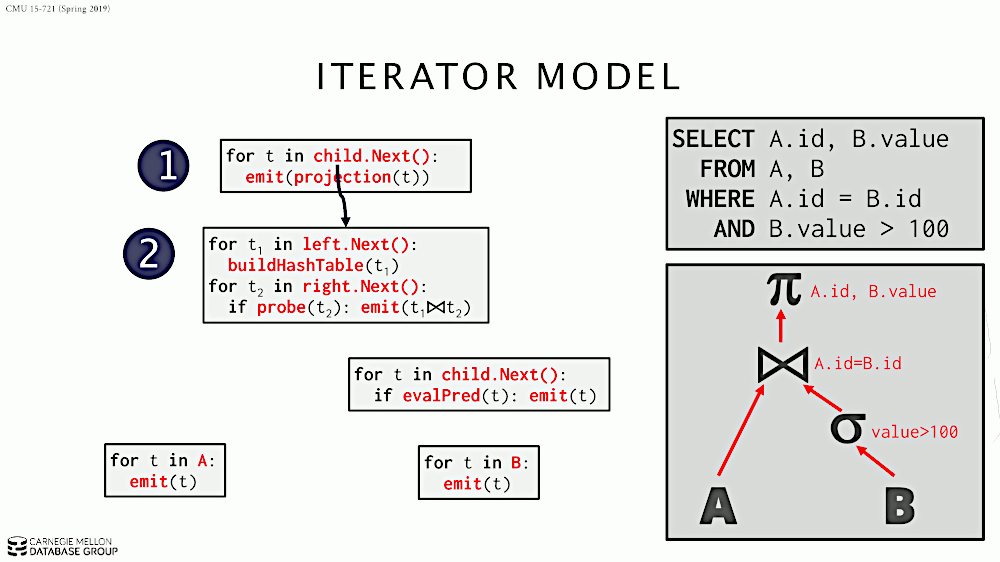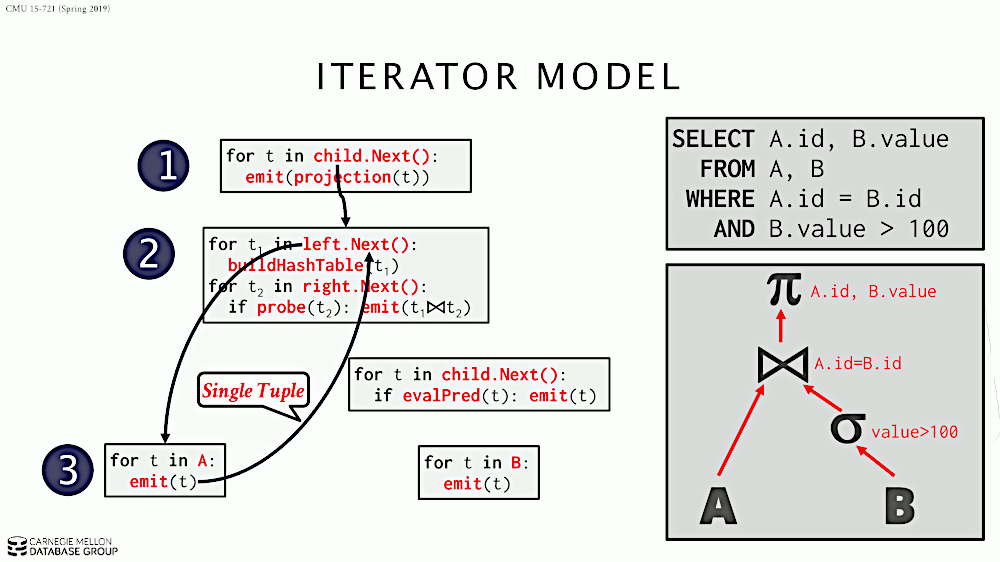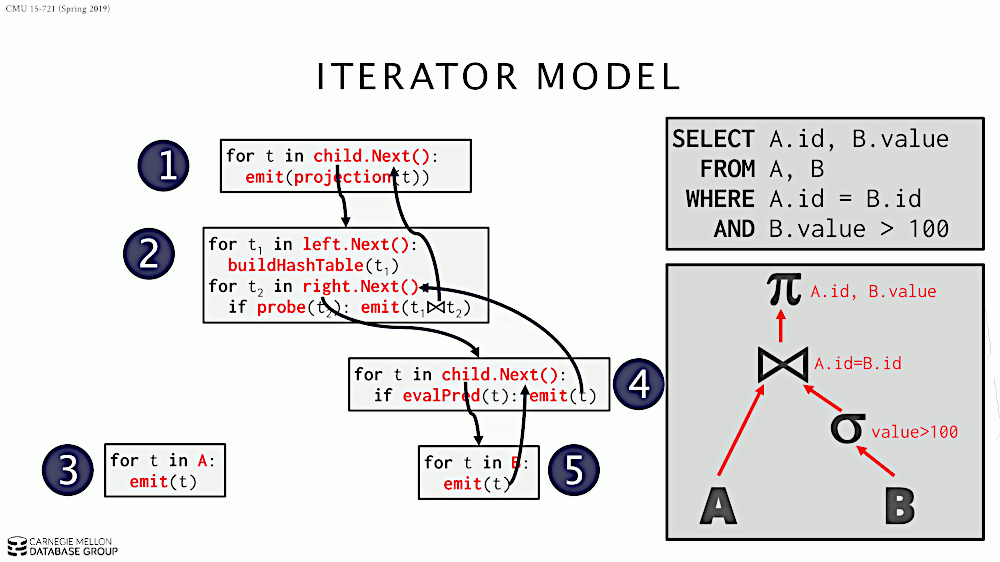
Figure 6: Iterator Model (Volcano or Pipeline Model)
迭代模型(Iterator Model)又称为火山模型(Volcano Model)或者 Pipeline Model。几乎所有主流的 RDBMS 都使用了这个模型。
2.1.2. Materialization Model
在 Materialization Model 中,每个算子一次返回所有的结果。
这种模型仅适应于 OLTP 场景,因为数据量一般不会太大;不太适应于 OLAP 场景,因为 OLAP 的中间结果的数据量可能很大。
数据库 Teradata、VoltDB、MonetDB 等采用了这种模型。
2.1.3. Vectorization Model (Batch Model)
Vectorization Model 和 Iterator Model 类似,每个算子都实现迭代器模式,不过算子的 next 函数每次将返回“批量数据”,如图 7 所示。Vectorization Model 也称为 Batch Model。
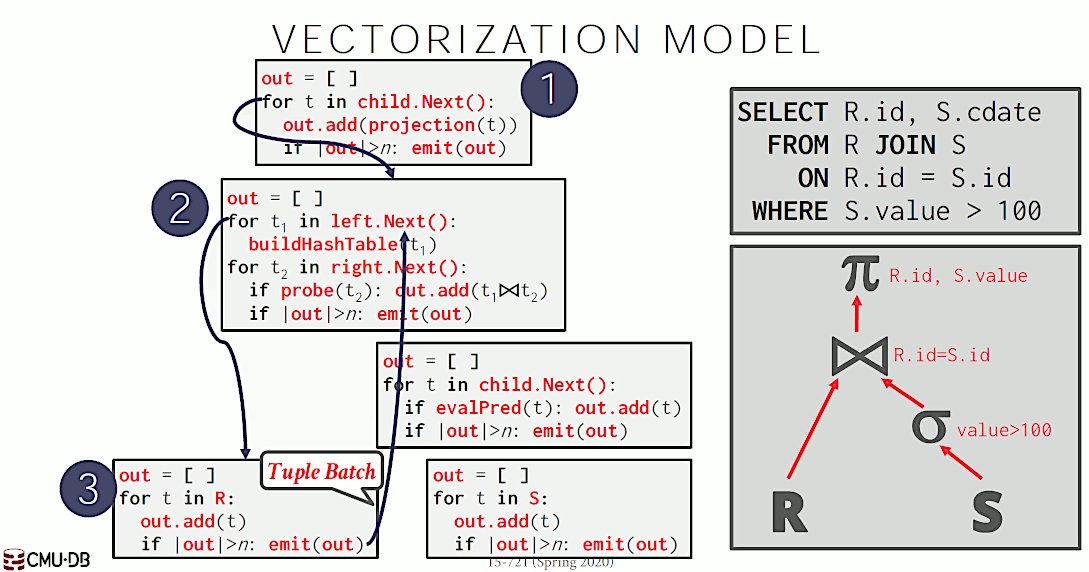
Figure 7: Vectorization Model(其算子的 next 函数返回的是 Tuple Batch,而不是 Single Tuple)
对于 OLAP 场景,Vectorization Model 会显著地减少算子执行次数。此外,算子一般使用向量指令(SIMD)处理其“子算子”返回的数据,以获得更好的性能。
2.2. 并行执行(Parallel Execution)
为提高算子执行效率,可以让算子并行地执行,有下面两种方式(这两种方式不是互斥的,可以同时应用):
- Intra-Operator (Horizontal)
- Inter-Operator (Vertical)
2.2.1. Intra-Operator Parallelism (Horizontal)
Intra-Operator Parallelism 中,在数据的独立子集上同时应用同一种算子,算子中需要插入 exchange 操作符,以合并结果,如图 8 所示。A 被拆分为 A1,A2,A3 被算子同时处理。
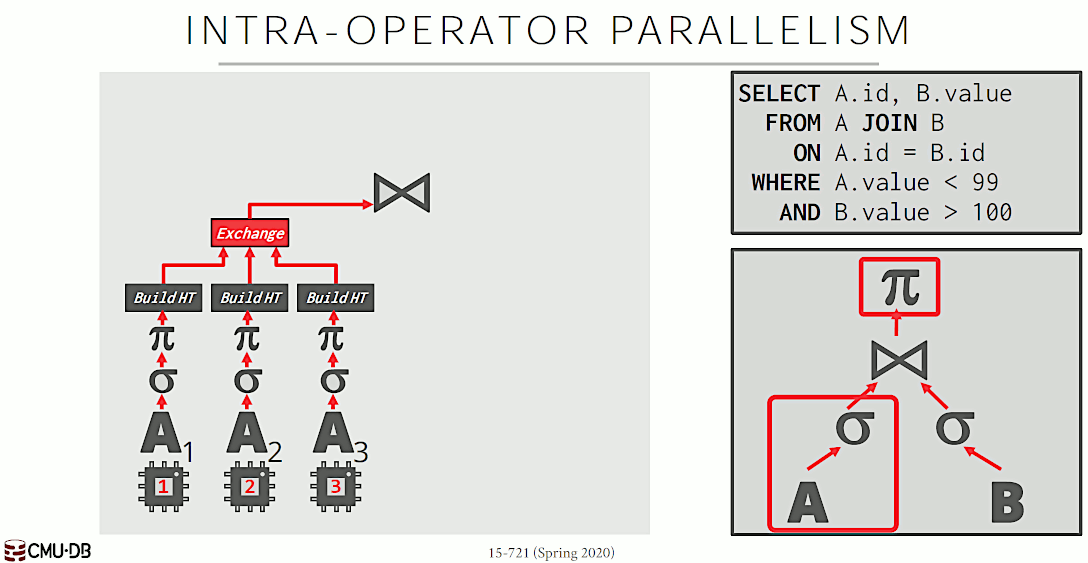
Figure 8: Intra-Operator Parallelism
2.2.2. Inter-Operator Parallelism (Vertical)
Inter-Operator Parallelism 中,同时执行多个不同算子,也称为 Pipelined Parallelism。如图 9 所示。
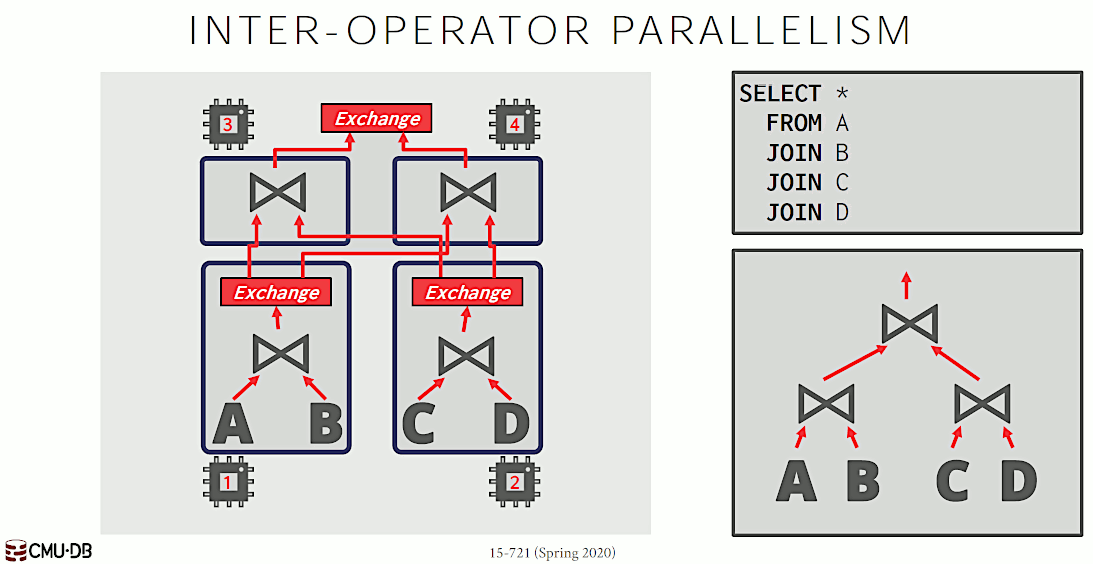
Figure 9: Inter-Operator Parallelism
3. Compilation
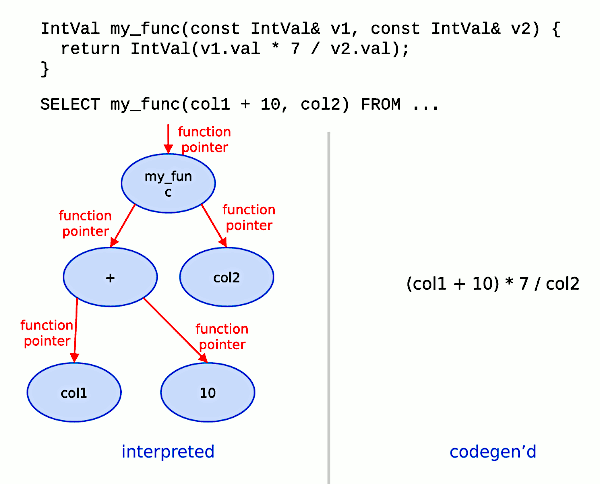
对于图 10 中的 Query 语句,如果要解释执行的话,如图 11 所示。
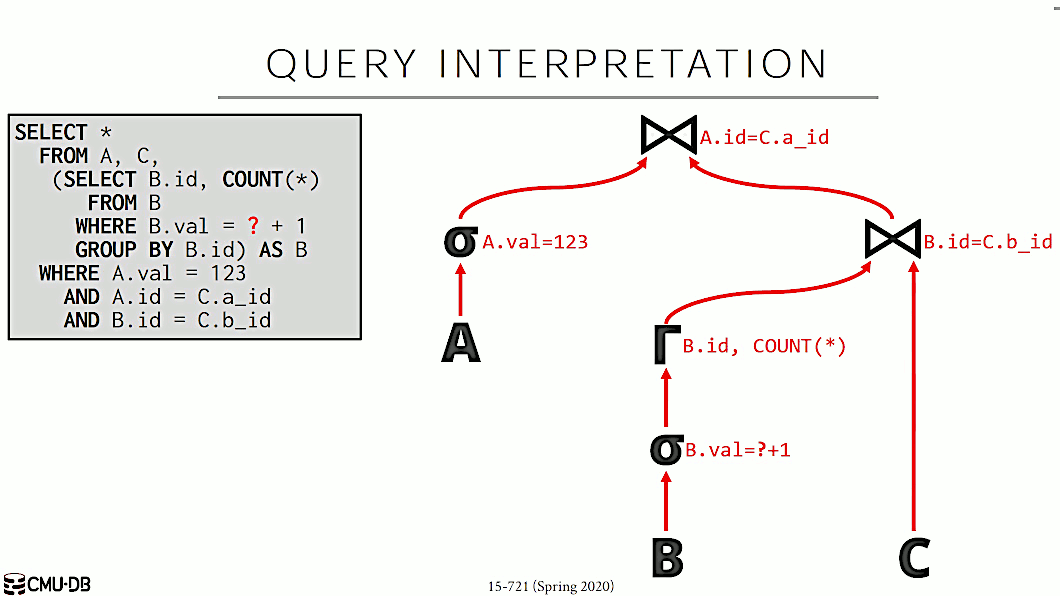
Figure 10: Query Interpretation
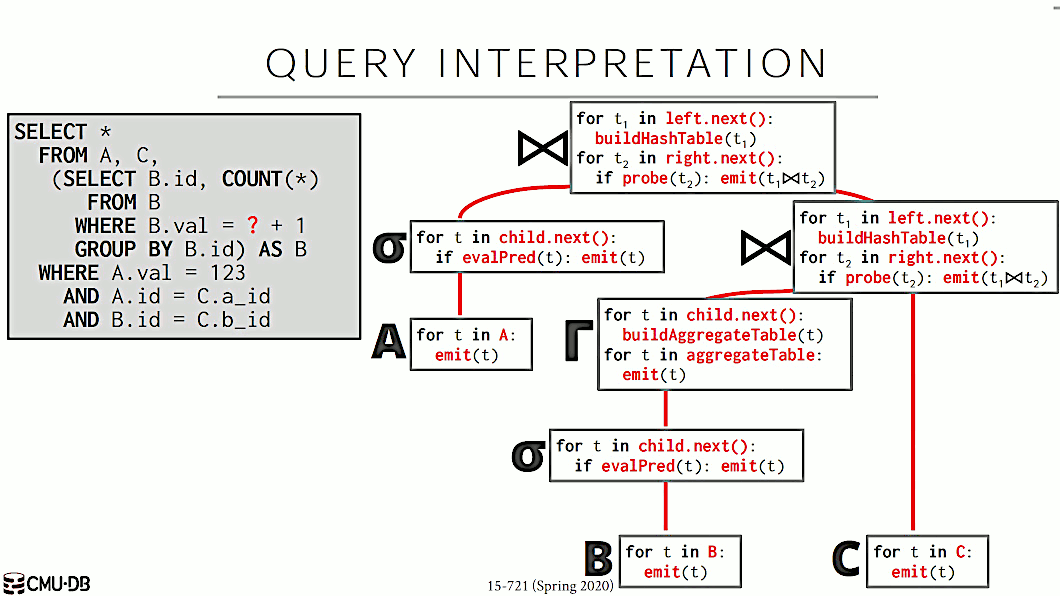
Figure 11: Query Interpretation
图 11 所示的代码容易理解,但包含大量的 for 循环和 if 语句,其执行效率不高。
在 OLAP 场景下,Query Plan 的算子可能会执行超过千万次。解释执行或编译执行 Query Plan 时,采取合适的优化措施可以大大加快整个 Query Plan 的执行。
参考:查询编译综述
3.1. Expression Compilation

3.2. Operator Compilation

3.3. Pipeline Compilation
在“Efficiently Compiling Efficient Query Plans for Modern Hardware”一文中,Hyper 提出了 Pipelined Operators 的思路:对 Operator 进行分类,把可以流水化执行的 Operator 内联到一起。图 10 中的 Query Plan 优化后如图 15 所示,它显然比图 11 执行的代码更少,效果更高。
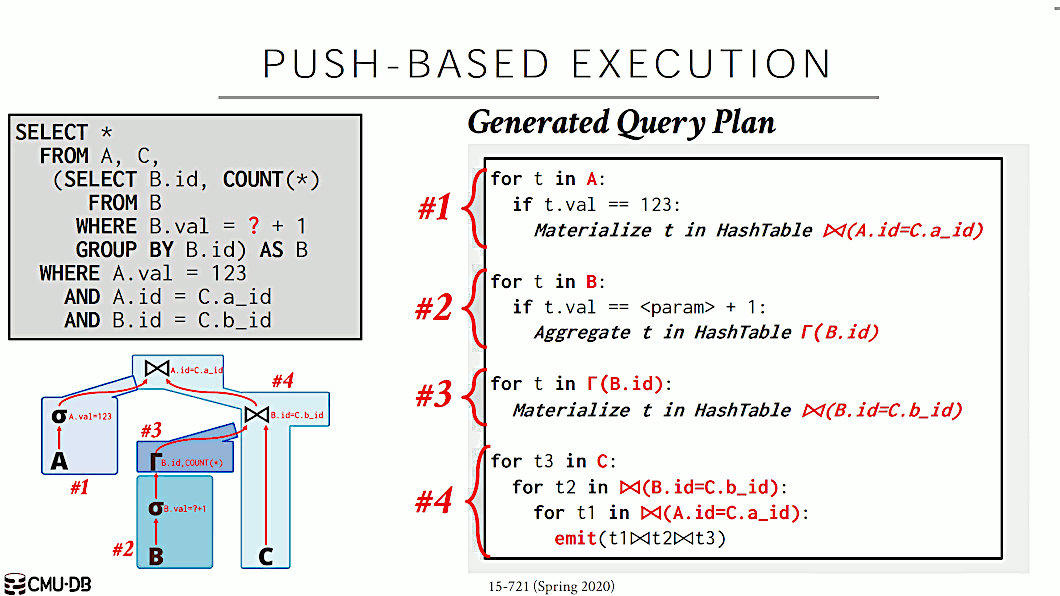
Figure 15: Generated Plan
为了实现 Hyper 提出的理念,需要对 Volcano Model 进行改造:Volcano Model 是 Operator-Centric,也就是数据在 Operator 之间流动;这一方式需要转变成 Data-Centric,让数据在寄存器中,所有计算围绕着数据展开。此外,需要把 Volcano Model 的 Pull 模式(数据从上往下拉)改变成 Push 模式:数据从下往上推,在一个 Pipeline 内部没有数据传递。
3.4. JIT 优点
前面介绍的这些优化措施属于 JIT (Just-In-Time Compilation),使用 JIT 可以根据运行时信息做特化,可以生成更少的代码,从而执行效率得到提高。
4. Vectorization VS. Compilation
“向量化”(参见节 2.1.3 )和“运行时代码生成”(参见节 3)两种技术都可以提高 SQL 查询语句的执行效率。
文章“Vectorization vs. Compilation in Query Execution”提到:要获得更好的执行效率,最好同时使用这两种技术。