Threads
Table of Contents
- 1. 线程基本概念
- 2. 线程间共享和不共享的信息
- 3. Linux 中线程的实现模型
- 4. 线程的创建和终止
- 5. Synchronization Objects
- 6. TLS (Thread Local Storage)
- 7. MT-Safe, AS-Safe, AC-Safe 区别
1. 线程基本概念
和进程类似,线程可以使应用程序并行地执行任务。 和进程相比,线程有两个主要的优势:优势一,线程间共享信息更加容易且速度更快;优势二,创建线程比创建进程更快。 本文将重点介绍 POSIX Threads 。
参考:
man 7 pthreads
http://pages.cs.wisc.edu/~travitch/pthreads_primer.html
https://computing.llnl.gov/tutorials/pthreads/
1.1. 多线程程序的内存布局
下图是 Linux/x86-32 中多线程程序的内存布局演示,摘自"The Linux Programming Interface"。
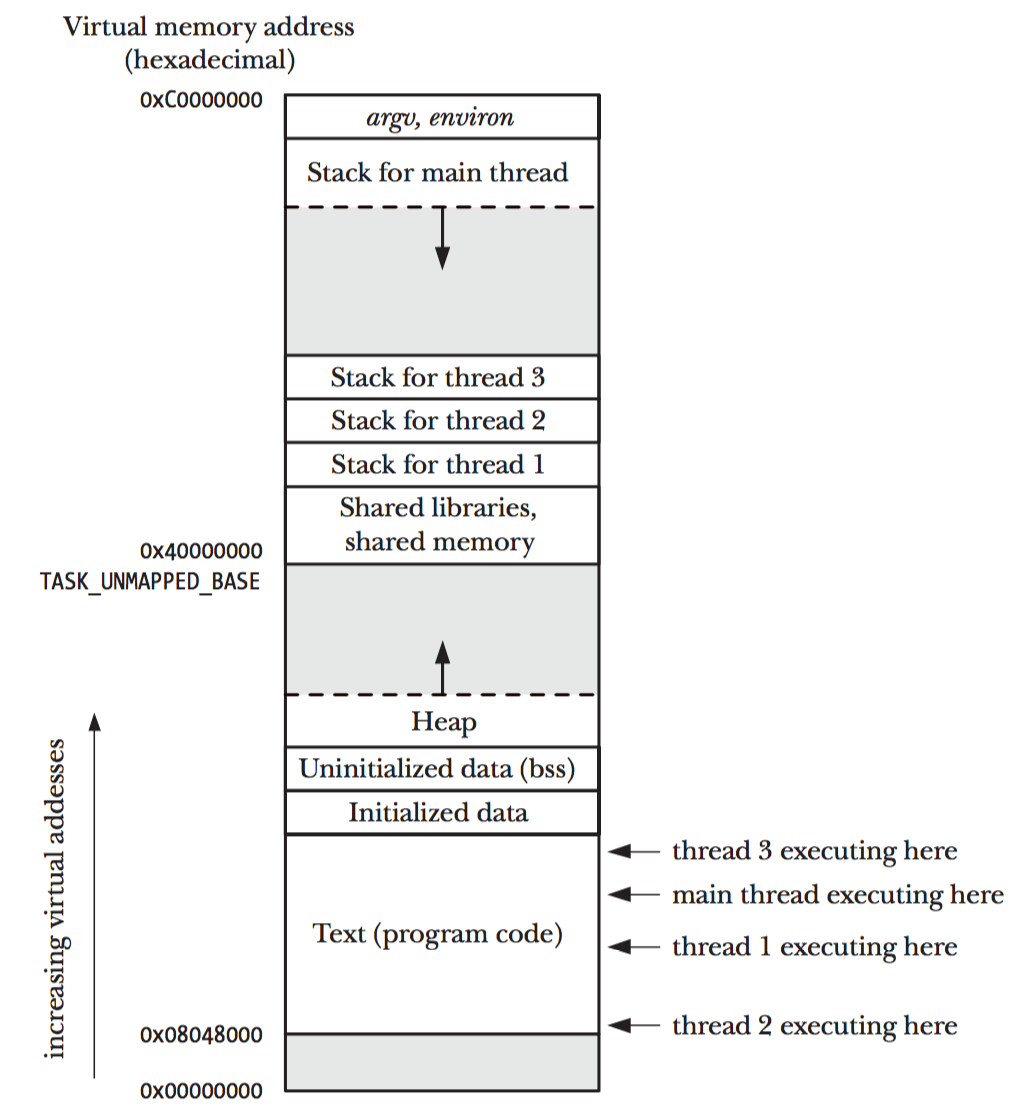
Figure 1: 包含 4 个线程的进程的内存布局(Linux/x86-32)
说明 1:上面仅是一个概念模型,真实布局随内核版本不同,变化可能很大。
说明 2:一般来说,线程的栈大小是固定的(典型值在 2 到 8MB 之间),一旦线程开始运行其栈的大小不能改变。注:GCC 有一个新特性 Split Stacks 允许每个线程的栈动态地增长。
2. 线程间共享和不共享的信息
同一个进程的不同线程间 共享 下面信息:
- 全局内存;
- 堆内存;
- process ID, process group ID, user ID, and group ID;
- open file descriptors;
- record locks created using fcntl();
- signal dispositions;
- file system–related information: umask, current working directory, and root directory;
- interval timers (setitimer()) and POSIX timers (timer_create());
- System V semaphore undo (semadj) values;
- resource limits;
- CPU time consumed (as returned by times());
- resources consumed (as returned by getrusage()); and
- nice value (set by setpriority() and nice()).
同一个进程的不同线程间 不共享 下面信息:
- signal mask;
- thread-specific data (errno variable, etc.);
- alternate signal stack (sigaltstack());
- floating-point environment (see fenv(3));
- realtime scheduling policy and priority;
- stack (local variables and function call linkage information).
3. Linux 中线程的实现模型
Several thread implementations are available in the Linux operating system. The following are the widely used.
实现 1. LinuxThreads(已淘汰)
LinuxThreads have been the default thread implementation since Linux kernel 2.0. The LinuxThread has some noncompliant implementations with the POSIX standard. Native POSIX Thread Library (NPTL) is taking the place of LinuxThreads. The LinuxThreads will not be supported in future release of Enterprise Linux distributions.
实现 2. Native POSIX Thread Library (NPTL)(目前使用)
The NPTL was originally developed by Red Hat. NPTL is more compliant with POSIX standards. By taking advantage of enhancements in kernel 2.6 such as the new clone() system call, signal handling implementation, and so on, it has better performance and scalability than LinuxThreads.
NPTL has some incompatibility with LinuxThreads. An application which has a dependence on LinuxThread might not work with the NPTL implementation.
实现 3. Next Generation POSIX Thread (NGPT)(已被放弃)
NGPT is an IBM developed version of POSIX thread library. It is currently under maintenance operation and no further development is planned. NGPT was abandoned in mid-2003, at about the same time when NPTL was released.
3.1. 查看系统当前使用的线程模型
在 Linux 中,可通过 getconf GNU_LIBPTHREAD_VERSION 查看当前使用的线程模型。如:
cig01@debian8:~$ getconf GNU_LIBPTHREAD_VERSION NPTL 2.19
3.2. 选择线程模型(设置 LD_ASSUME_KERNEL 环境变量)
由于 NPTL 和 LinuxThreads 不兼容,如那些比较旧的软件是基于 LinuxThreads 开发的,而较新的系统却使用默认使用的是 NPTL,运行时可能有问题。
为了实现向后兼容,许多 Linux 发行版支持旧的 LinuxThreads 实现以及新的本地 POSIX 线程库(NPTL)。 通过设置 LD_ASSUME_KERNEL 环境变量,动态链接器将假定它是运行在一个特定的内核版本上。
许多 32 位 Linux 系统有 3 个独立的 glibc 版本,每个版本都指定其最低的操作系统的应用程序二进制接口(ABI),包括内核版本和所提供的线程实现模型。一般在如下三个目录:/lib/tls, /lib/i686, /lib 。
/lib/tls/libc.so.6:最低的 ABI = 2.4.20,本机 POSIX 线程库(NPTL)。
/lib/i686/libc.so.6:最低的 ABI = 2.4.1,标准的 LinuxThreads,动态线程栈大小。
/lib/libc.so.6:最低的 ABI = 2.2.5,早期的 LinuxThreads,固定线程栈大小。
注 1:64 位系统不支持旧 2.2.5 LinuxThreads 实现。
注 2:不要设置 LD_ASSUME_KERNEL 环境变量值为 ABI 低于 2.2.5,这样会导致使用了动态链接库的程序无法正常运行。 Versions from 2.2.5 to 2.4.0 will use the DSOs in /lib, versions from 2.4.1 to 2.4.19 will use the DSOs in /lib/i686, versions 2.4.20 and younger will use the DSOs in /lib/tls.
3.2.1. 选择线程模型实例
如 ORACLE 9i FOR LINUX 是在标准的 Linux Threads 下开发的,当在 Redhat Linux(kernel 2.6)中安装的时候,必须设定 LD_ASSUME_KERNEL 为 2.4.0,以让 Redhat Linux 使用标准的 Linux Threads,否则安装进度指示条一直停留在开始处。
4. 线程的创建和终止
| Process primitive | Thread primitive | Description |
|---|---|---|
| fork | pthread_create | create a new flow of control |
| exit | pthread_exit | exit from an existing flow of control |
| waitpid | pthread_join | get exit status from flow of control |
| atexit | pthread_cancel_push | register function to be called at exit from flow of control |
| getpid | pthread_self | get ID for flow of control |
| abort | pthread_cancel | request abnormal termination of flow of control |
说明:在默认情况下,线程的终止状态会保存到对该线程调用 pthread_join,但如果线程已经处于“分离”状态,则线程底层存储资源可以在线程终止时立即被收回。调用函数 pthread_detach 可以使线程进入“分离”状态。 当我们对线程的终止状态不关心时,可以调用 pthread_detach 使其处于“分离”状态,这样,当线程退出时其底层存储资源会被立即收回,而无需调用 pthread_join 给它收尸。
5. Synchronization Objects
参考:
现代操作系统(原书第 3 版),2.3 节 进程间通信
UNIX 环境高级编程(第 3 版),11.6 节 线程同步
5.1. Mutex locks
互斥量(Mutex)可以看作是信号量的简化版本,它省略了信号量的计数功能。
互斥量的基本原理及使用方法如下:
互斥量是一个可以处于两种状态之一的变量,这两种状态分别代表“解锁”和“加锁”。当一个线程(或进程)需要访问临界区时,它调用方法 mutex_lock,如果互斥量当前处于解锁状态,则调用成功,如果互斥量当前处于加锁状态,则调用线程被阻塞,直到在临界区中的其它线程完成并调用 mutex_unlock。如果多个线程被阻塞在该互斥量上,将随机选择一个线程并允许它获得锁。
| functions | 描述 |
|---|---|
| pthread_mutex_init | 创建一个互斥量 |
| pthread_mutex_destroy | 撤销一个已存在的互斥量 |
| pthread_mutex_lock | 获得一个锁,不成功就阻塞 |
| pthread_mutex_trylock | 获得一个锁,不成功就失败 |
| pthread_mutex_unlock | 释放一个锁 |
5.1.1. 小心死锁
使用互斥量时,应该小心死锁。
当线程 A 占有了互斥量 mutex1,想要占有互斥量 mutex2;而同时,线程 B 占有了互斥量 mutex2,想要占有互斥量 mutex1,这时就会产生死锁。
| Thread A | Thread B |
|---|---|
| pthread_mutex_lock(mutex1); | pthread_mutex_lock(mutex2); |
| ... | ... |
| pthread_mutex_lock(mutex2); | pthread_mutex_lock(mutex1); |
| blocks | blocks |
可以通过仔细控制互斥量加锁的顺序来避免死锁的发生。如上面例子中,如果所有线程总是在对互斥量 mutex2 加锁之前锁住互斥量 mutex1,那么就不会产生死锁。
但有时候,应用程序的结构可能使得对互斥量排序很困难,这时可以使用 pthread_mutex_trylock 来避免死锁。
参考:UNIX 环境高级编程(第 3 版),11.6.2 节 避免死锁
5.2. Read-Write locks(又称“共享—独占锁”,比互斥量并行性更高)
读写锁与互斥量类似,不过 读写锁允许更高的并行性 。
读写锁的基本原理及使用方法如下:
我们知道,互斥量要么处于解锁状态,要么处于加锁状态,而且一次只有一个线程可以对其加锁。和互斥量不同, 读写锁有三种状态:读模式下加锁状态、写模式下加锁和不加锁状态。一次只有一个线程可以占有写模式的读写锁,但是多个线程可以同时占有读模式的读写锁。
当读写锁处于“写模式加锁状态”时,在这个锁被解锁之前,所有试图对这个锁加锁的线程都会被阻塞。当读写锁处于“读模式加锁状态”时,所有试图以读模式对它进行加锁的线程都可以得到访问权,但是如果线程希望以写模式对此锁进行加锁,它必须阻塞直到所有的线程释放读锁(说明:虽然读写锁在实现各不相同,但当读写锁处于“读模式加锁状态”时,如果有另外的线程试图以写模式加锁,读写锁通常会阻塞随后的读模式加锁请求。这样可以避免读写锁长期处于“读模式加锁状态”,而等待的写模式加锁请求一直得不到满足。)
| functions | 描述 |
|---|---|
| pthread_rwlock_init | 创建一个读写锁 |
| pthread_rwlock_destroy | 撤销一个已存在的读写锁 |
| pthread_rwlock_rdlock | 获得读模式锁,不成功就阻塞 |
| pthread_rwlock_tryrdlock | 获得读模式锁,不成功就失败 |
| pthread_rwlock_wrlock | 获得写模式锁,不成功就阻塞 |
| pthread_rwlock_trywrlock | 获得写模式锁,不成功就失败 |
| pthread_rwlock_unlock | 释放一个锁 |
5.3. Condition variables(总和互斥量同时使用,管理获得了锁但无工作可做的线程)
互斥量可以阻止多个线程同时访问某个共享变量。而 条件变量允许一个线程改变了某个共享变量后通知其他线程。
后文将说明, 条件变量总和互斥量同时使用,条件变量用来管理那些获得了锁但却没有工作可做的线程。
5.3.1. 条件变量应用场景
下面用一个实例来说明条件变量为什么有用。实例摘自:The Linux Programming Interface, 30.2.2 Signaling and Waiting on Condition Variables
假设有两个线程,一个线程(设为线程 B)用来生产某种部件,而主线程(设为线程 A)用来消耗它。
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; static int avail = 0; /* 记录当前可用 unit 的数量 */
生产部件线程(线程 B)的主要代码如下所示:
/* 生产某部件的代码省略 */ pthread_mutex_lock(&mtx); avail++; pthread_mutex_unlock(&mtx);
消耗部件的主线程(线程 A)的主要代码如下所示:
for (;;) {
pthread_mutex_lock(&mtx);
while (avail > 0) { /* 在while循环中消耗所有可用的部件 */
/* 消耗部件的代码省略 */
avail--;
}
pthread_mutex_unlock(&mtx);
/* Perhaps do other work here that doesn't require mutex lock */
}
上面的代码可以工作。
但它有一个不足:浪费 CPU 资源。主线程(线程 A)在 for 循环里不停地检查有没有可用的部件(测试变量 avail 是否大于 0),如果此时线程 B 还没有生产出部件,线程 A 可能会一直重复“加锁——发现没有工作可做——解锁”这个过程,这浪费了 CPU 资源。“条件变量”可以解决这个浪费 CPU 资源问题,基本思路是线程 A 发现没有工作可做时就阻塞,直到线程 B 生产出可用部件后通知它。
条件变量总和互斥量一起使用,互斥量用来实现对共享变量的互斥访问,条件变量用来通知共享变量的改变。
下面用条件变量来解决上面问题。
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; + static pthread_cond_t cond = PTHREAD_COND_INITIALIZER; static int avail = 0; /* 记录当前可用 unit 的数量 */
使用条件变量后,生产部件线程(线程 B)的主要代码如下所示:
/* 生产某部件的代码省略 */ pthread_mutex_lock(&mtx); avail++; pthread_mutex_unlock(&mtx); + pthread_cond_signal(&cond); /* 发会通知,唤醒等待在该条件变量上的线程 */
使用条件变量后,消耗部件的主线程(线程 A)的主要代码如下所示:
1: for (;;) { 2: pthread_mutex_lock(&mtx); 3: + while (avail == 0) { 4: + pthread_cond_wait(&cond, &mtx); /* 3个作用:(1) 解锁互斥量mtx */ 5: + /* (2) 阻塞线程直到另外的线程通过条件变量cond唤醒它 */ 6: + /* (3) 再次对互斥量mtx加锁 */ 7: + } 8: while (avail > 0) { /* 在while循环中消耗所有可用的部件 */ 9: /* 消耗部件的代码省略 */ 10: avail--; 11: } 12: pthread_mutex_unlock(&mtx); 13: 14: /* Perhaps do other work here that doesn't require mutex lock */ 15: }
注 1:为什么上面代码中第 3 行使用 while 而不是 if 来检测条件 (avail == 0) 呢?这是为了避免“虚假唤醒”(Spurious wakeup)。在 pthread_cond_wait 的文档中有相关说明:
Spurious wakeups from the pthread_cond_wait() or pthread_cond_timedwait() functions may occur. Since the return from pthread_cond_wait() or pthread_cond_timedwait() does not imply anything about the value of this predicate, the predicate should be re-evaluated upon such return.
不过,就前面的例子来说,第 3 行使用 if 也行,因为后面(即第 8 行)再次对 avail 进行了检测,就算出现了虚假唤醒,也只是浪费了 CPU,不影响逻辑。
注 2:再次强调,函数 pthread_cond_wait(&cond, &mtx)执行三个步骤:
(1) 解锁互斥量 mtx;
(2) 阻塞线程直到另外的线程通过条件变量 cond 唤醒它,例如,其他线程调用 pthread_cond_signal(&cond)或者 pthread_cond_broadcast(&cond);
(3) 再次对互斥量 mtx 加锁。
显然, 在调用 pthread_cond_wait(&cond, &mtx)之前,互斥量 mtx 必须已经被锁定。
参考: man pthread_cond_wait
5.3.2. 条件变量相关 pthread 函数
条件变量相关 pthread 函数如表 5 所示。
| functions | 描述 |
|---|---|
| pthread_cond_init | 创建一个条件变量 |
| pthread_cond_destroy | 撤销一个条件变量 |
| pthread_cond_wait | 阻塞以等待一个信号 |
| pthread_cond_signal | 向另一个线程发信号来唤醒它 |
| pthread_cond_broadcast | 向多个线程发信号来让它们全部唤醒 |
5.4. Semaphores
信号量最初由 Dijkstra 发明,它很强大,既可以实现线程互斥(具有互斥量的功能)又可以实现线程同步(具有条件变量的功能)。
信号量是一个整数,正数表示可供并发进程使用的资源数,负数的绝对值表示等待使用临界区的进程数。
说明 1:信号量既可以用作线程同步,还可以用作进程同步。
说明 2:线程中有互斥量和条件变量,它们足够处理绝大部分的线程同步问题。
| Related Function Description | Operation |
|---|---|
| sem_init | Initialize a semaphore |
| sem_destroy | Destroy the semaphore state |
| sem_post | 信号量原子地加 1 |
| sem_wait | 阻塞当前线程直到信号量大于 0,然后对信号量原子地减 1 |
参考:http://docs.oracle.com/cd/E19253-01/816-5137/sync-11157/index.html
5.4.1. 生产者—消费者问题(信号量解法和条件变量解法)
生产者—消费者问题的信号量解法和条件变量解法如下:
+---------------------------------------------+------------------------------------------------------------------+
|Producer-Consumer Problem (Using Semaphores) |Producer-Consumer Problem (Using Condition Variables) |
+---------------------------------------------+------------------------------------------------------------------+
|typedef struct { |typedef struct { |
| char buf[BSIZE]; | char buf[BSIZE]; |
| sem_t occupied; | int occupied; |
| sem_t empty; | int nextin; |
| int nextin; | int nextout; |
| int nextout; | pthread_mutex_t mutex; |
| sem_t pmut; | pthread_cond_t more; |
| sem_t cmut; | pthread_cond_t less; |
|} buffer_t; |} buffer_t; |
| | |
|buffer_t buffer; |buffer_t buffer; |
| | |
|sem_init(&buffer.occupied, 0, 0); | |
|sem_init(&buffer.empty,0, BSIZE); | |
|sem_init(&buffer.pmut, 0, 1); | |
|sem_init(&buffer.cmut, 0, 1); | |
|buffer.nextin = 0; | |
|buffer.nextout = 0; | |
| | |
+---------------------------------------------+------------------------------------------------------------------+
|void producer(buffer_t *b, char item) { |void producer(buffer_t *b, char item) { |
| sem_wait(&b->empty); | pthread_mutex_lock(&b->mutex); |
| sem_wait(&b->pmut); | |
| | while (b->occupied >= BSIZE) |
| b->buf[b->nextin] = item; | pthread_cond_wait(&b->less, &b->mutex); |
| b->nextin++; | |
| b->nextin %= BSIZE; | assert(b->occupied < BSIZE); |
| | |
| sem_post(&b->pmut); | b->buf[b->nextin] = item; |
| sem_post(&b->occupied); | b->nextin++; |
|} | b->nextin %= BSIZE; |
| | b->occupied++; |
| | |
| | /* now: either b->occupied < BSIZE and b->nextin is the index |
| | of the next empty slot in the buffer, or |
| | b->occupied == BSIZE and b->nextin is the index of the |
| | next (occupied) slot that will be emptied by a consumer |
| | (such as b->nextin == b->nextout) */ |
| | |
| | pthread_cond_signal(&b->more); |
| | |
| | pthread_mutex_unlock(&b->mutex); |
| |} |
| | |
+---------------------------------------------+------------------------------------------------------------------+
|char consumer(buffer_t *b) { |char consumer(buffer_t *b) { |
| char item; | char item; |
| | pthread_mutex_lock(&b->mutex); |
| sem_wait(&b->occupied); | while(b->occupied <= 0) |
| sem_wait(&b->cmut); | pthread_cond_wait(&b->more, &b->mutex); |
| | |
| | assert(b->occupied > 0); |
| item = b->buf[b->nextout]; | |
| b->nextout++; | item = b->buf[b->nextout]; |
| b->nextout %= BSIZE; | b->nextout++; |
| | b->nextout %= BSIZE; |
| sem_post(&b->cmut); | b->occupied--; |
| sem_post(&b->empty); | |
| | /* now: either b->occupied > 0 and b->nextout is the index |
| | of the next occupied slot in the buffer, or |
| return(item); | b->occupied == 0 and b->nextout is the index of the next |
|} | (empty) slot that will be filled by a producer (such as |
| | b->nextout == b->nextin) */ |
| | |
| | pthread_cond_signal(&b->less); |
| | pthread_mutex_unlock(&b->mutex); |
| | |
| | return(item); |
| |} |
+---------------------------------------------+------------------------------------------------------------------+
说明:在信号量解法中,结构体 buffer_t 中信号量 pmut 和 cmut 的作用其实就是互斥量(直接使用互斥量效率更高,如果可以确保整个程序中最多只有一个生产者和最多只有一个消费者,则 pmut 和 cmut 相关代码都可以去掉),这里仅仅是为了演示信号量的用法。
5.4.2. 信号量和条件变量区别
一般来说,在线程中用条件变量就足够处理绝大部分的同步问题。
The semaphore uses more memory than the condition variable. The semaphore is easier to use in some circumstances because a semaphore variable operates on state rather than on control.
参考:Multithreaded Programming Guide, Comparing Primitives: http://docs.oracle.com/cd/E19253-01/816-5137/sync-31059/index.html
5.5. Spin locks(自旋锁)
自旋锁是一种 low-level 的同步机制,一般来说在应用中不需要使用它。
自旋锁在请求锁时如果此时锁已经被其它线程占用,则不停地测试(这可能浪费 CPU 资源)直到锁变为可用。所以,使用自旋锁时,每个线程持有锁的时间都应该非常短。
参考:
http://stackoverflow.com/questions/5869825/when-should-one-use-a-spinlock-instead-of-mutex
5.6. Barrier(屏障)
有些应用中划分了若干阶段,并且规定,除非所有线程都就绪准备着手下一阶段,否则任何线程都不能提前进入下一个阶段。这可以可能在每个阶段的末尾安置屏障(Barrier)来实现这种行为。 当一个线程到达屏障时,它就被屏障阻拦,直到所有线程都到达屏障为止。
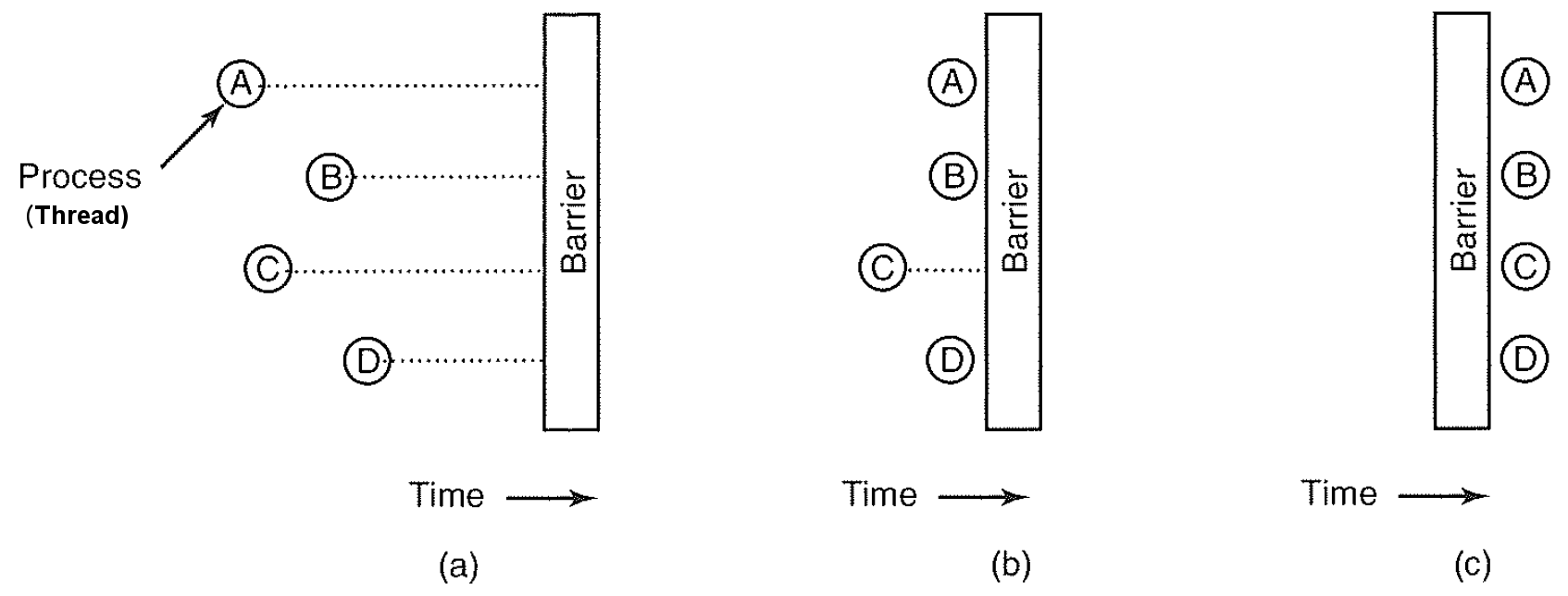
Figure 2: 屏障使用实例:(a)线程接近屏障 (b)除线程 C 外其他线程都被屏障阻塞 (c)最后一个线程到达屏障,所有线程一起通过
参考:现代操作系统(原书第 3 版),2.3.9 屏障
5.7. 线程同步方法总结
表 7 对线程同步方法进行了总结。
| Mutexes | Semaphores | Read/write locks | Spin locks | Barriers | |
|---|---|---|---|---|---|
| Creation | pthread_mutex_init | sem_init | pthread_rwlock_init | pthread_spin_init | pthread_barrier_init |
| Destroy | pthread_mutex_destroy | sem_destroy | pthread_rwlock_destroy | pthread_spin_destroy | pthread_barrier_destroy |
| Waiting | - | - | - | - | pthread_barrier_wait |
| Acquisition | pthread_mutex_lock | sem_wait | pthread_rwlock_wrlock/pthread_rwlock_rdlock | pthread_spin_lock | - |
| Release | pthread_mutex_unlock | sem_post | pthread_rwlock_unlock | pthread_spin_unlock | - |
5.8. Linux 中系统调用 futex
In NPTL, thread synchronization primitives (mutexes, thread joining, etc.) are implemented using the Linux futex system call.
6. TLS (Thread Local Storage)
什么是 TLS?
TLS 是“线程局部存储(Thread Local Storage)”的缩写,顾名思义,这就是局部于唯一的线程、为具体线程所“私有”的存储空间。
注意 TLS 只是对全局量和静态变量才有意义。局部量存在于具体线程的堆栈上,而每个线程都有自己的堆栈,所以局部量本来就是“局部”于具体线程的。至于通过动态分配的缓冲区,则取决于保存着缓冲区指针的变量。如果缓冲区指针是全局量,那么同一进程中的所有线程都能访问这个缓冲区;而若是局部量,则别的线程自然就不得其门而入。
6.1. 什么时候需要 TLS
Perhaps the most common use of TLS is for statistical counting. The general approach is to split the counter across all threads (or CPUs or whatever). To update this split counter, each thread modifies its own counter, and to read out the value requires summing up all threads' counters.
参考:http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2014/n4324.html
TLS is helpful for things like user session context information which is thread specific, but might be used in various unrelated methods. In such situations, TLS is more convenient than passing the information up and down the call stack.
6.1.1. errno 是 TLS
对于 TLS 的用途,Unix/Linux 的 C 程序库 libc 中的全局变量 errno 是个最典型的例子。
if (open (filename, mode) < 0) {
error (0, errno, "%s", infile); //全局变量erron可能被多个线程修改!
// other code
}
当系统调用从内核返回用户空间时,如果 EAX 的值为 0xfffff001 至 0xffffffff 之间即为出错,取其负值(2 的补码)就是出错代码。此时将出错代码写入一个全局量 errno,以供进一步查验,并将 EAX 的值改成-1。这就是从 Unix 时代初期就定下的对于返回整数的系统调用的约定。其好处是写程序时可以略微方便一些,不用每次都在函数中定义一个局部变量 err,再写成“if ((err=open(filename, mode)) < 0”、并因为系统调用出错返回的几率毕竟很小。
在线程的概念出现之前,或者说在一个进程只含有一个线程的时代,这样安排不会有什么问题。这是因为,从启动系统调用的 C 库函数把出错代码写入全局量 errno 以后,到调用者发现返回值为-1、因而从 errno 获取出错代码的这一段时间中 errno 的值不可能改变。即使在这中间发生了中断、并且导致进 程调度,从当事进程的角度看也只是时间上的短暂停滞,却不会有谁来改变 errno 的内容;因为全局量 errno 是归进程所有,别的进程不会来打扰。
但是,有了多线程的概念和技术以后,情况就不一样了。因为同一进程中的多个线程是共享一个用户空间的,如果几个线程的程序中都引用全局量 errno,那么它们在运行中实际访问的就是同一个地址。为说明问题,我们且假定线程 T1 和 T2 属于同一进程,再来考察下述的假想情景:
- T1 先通过 C 库函数 open() 进行系统调用,但是因为所给定的文件名实际上是个目录,所以内核返回出错代码 EISDIR。这个出错代码被写入了全局量 errno。
- T1 发现 open() 的返回值为-1,因而需要以 errno 当时的值、即出错代码为参数调用 error();但是,在 T1 还没有来得及从 errno 读出之前就发生了中断,而且导致线程调度,调度的结果是线程 T2 获得运行;
- T2 通过 C 库函数 signal() 启动另一次系统调用,但是因为使用参数不当而出错,内核返回的出错代码为 EINVAL,表示参数无效。这个出错代码也被写入全局量 errno,于是 errno 的值变成了 EINVAL。
- T2 从全局量 errno 读取出错代码,并依此进行相应的(正确)处理。但是 errno 的值仍保持为 EINVAL,此后 T2 没有再进行系统调用。
- 一段时间之后,T1 又被调度运行,继续其原有的处理,即从 errno 读出、并以 errno 的值为参数调用 error()。但是,errno 的值原来是 EISDIR,而现在已变成 EINVAL。
由此可见,在多线程的环境下,对于某些应用,由多个线程共享一个同名的全局量是有问题的。
怎么解决呢?使用局部量当然是个办法,例如改成“if ((err=open(filename, mode)) < 0”,这似乎轻而易举地就解决了问题。可是,不幸的是,这就要求改变几乎所有 C 库函数的调用接口,而 C 库函数的调用接口早已成为标准。那么另外再定义一个新的 C 程序库怎么样?这也很成问题,新开发的软件固然可以改用新的界面,但是这么多已经存在的代码就都需要重新加以修改了。所以,这是不太现实的。
显然,就 errno 而言,比较好的解决方案是维持原有的代码和接口不变,但是让每个线程都有自己的 errno,或者说都有一个专用的 errno 副本。这就是“线程局部存储”,即 TLS。
于是,使用 TLS 就是自然的选择了。实际上,现在的 C 库函数不是把出错代码写入全局量 errno,而是通过一个函数 __errno_location() 获取一个地址,再把出错代码写入该地址,其意图就是让不同的线程使用不同的出错代码存储地点,这就是 TLS。而 errno,现在一般已经变成了一个宏定义:
#define errno (*__errno_location())
这样,原来代码中的“extern int errno;”就变成了“extern int (*__errno_location());”,这是一种挺巧妙的方案。
相比之下,Win32 API 的调用方式就不同了:
Status = NtOpenFile(...);
if(!NT_SUCCESS(Status)) {
// error handle
}
当然,这里的 Status 是个局部变量,所以就不存在前述的问题了。这倒不是因为微软的人特别高明、早就预见到了可能发生的问题,而是因为时代不同,须知 Unix 的 C 库程序调用界面比 W32 API 的出现要早十多年。不过,尽管 Windows 对于系统调用的出错代码这个具体的数据没有线程局部存储的要求,这并不意味着在 Windows 系统中就不需要 TLS。事实上,Windows 也需要 TLS,这里不介绍它们了。
参考:https://wenku.baidu.com/view/2d442dd184254b35eefd344f.html
6.2. 怎么创建 TLS
POSIX Threads 中可以用下面方法创建:
方法一:pthread_key_create/pthread_setspecific/pthread_getspecific/pthread_key_delete
方法二:使用__thread 修饰符修饰变量, 如: __thread int test = 2222;
Windows 系统中可以用下面方法创建:
方法一:TlsAlloc/TlsGetValue/TlsSetValue/TlsFree
方法二:用__declspec 来声明一个 thread 变量,如: __declspec(thread) int tls_i = 1;
参考:
https://msdn.microsoft.com/en-us/library/aa908826.aspx
http://msdn.microsoft.com/en-us/library/6yh4a9k1.aspx
6.3. 编程语言对 TLS 的支持
在 C++11 中引入了关键字 thread_local,参见 Section 3.7.2 in C++11 standard
其它语言对 Thread Local Storage 的支持,请参见:
http://en.wikipedia.org/wiki/Thread-Specific_Storage
6.4. Linux 用 FS,GS 寄存器来访问 TLS
Linux 的 glibc 使用 GS 寄存器来访问 TLS,也就是说,GS 寄存器指示的段指向本线程的 TEB(Windows 的术语),也就是 TLS,这么做有个好处,那就是可以高效的访问 TLS 里面存储的信息而不用一次次的调用系统调用,当然使用系统调用的方式也是可以的。之所以可以这么做,是因为 Intel 对各个寄存器的作用的规范规定的比较松散,因此你可以拿 GS,FS 等段寄存器来做几乎任何事,当然也就可以做 TLS 直接访问了,最终 glibc 在线程启动的时候首先将 GS 寄存器指向 GDT 的第 6 个段,完全使用段机制来支持针对 TLS 的寻址访问,后续的访问 TLS 信息就和访问用户态的信息一样高效了。
在线程启动的时候,可以通过 sys_set_thread_area 来设置该线程的 TLS 信息。
In x86-64 there are 3 TLS entries, two of them accesible via FS and GS, FS is used internally by glibc (in IA32 apparently FS is used by Wine and GS by glibc).
Glibc makes its TLS entry point to a struct pthread that contains some internal structures for threading. Glibc usually refers to a struct pthread variable as pd, presumably for pthread descriptor.
参考:
关于 Linux 线程的线程栈以及 TLS:http://blog.csdn.net/dog250/article/details/7704898
http://stackoverflow.com/questions/6611346/amd64-fs-gs-registers-in-linux
7. MT-Safe, AS-Safe, AC-Safe 区别
MT-Safe, AS-Safe, AC-Safe 可分别称为线程安全,异步信号安全,异步取消安全。
The GNU C Library Reference Manual 中对函数的说明中明确了其对应的安全级别。
参考:http://www.gnu.org/software/libc/manual/html_node/POSIX-Safety-Concepts.html#POSIX-Safety-Concepts
7.1. MT-Safe
多线程安全函数。一个函数被多个并发线程 反复调用时,它会一直产生正确的结果 ,则该函数是多线程安全函数。
7.2. AS-Safe
先介绍一下可重入函数的概念。
进程捕捉到信号并对其进行处理时,进程正在执行的指令序列就被信号处理程序临时中断,它首先执行该信号处理程序中的指令。如果从信号处理程序返回(例如没有调用 exit 或 longjmp),则继续执行在捕捉到信号时进行正在执行的正常指令序列(这类似于发生硬件中断时所做的)。但在信号处理程序中,不能判断捕捉到信号时进程在何处执行。如果进程正在执行 malloc,在其堆中分配另外的存储空间,而此时由于捕捉到信号而插入执行该信号处理程序,其中又调用 malloc,这时会发生什么?可能会对进程造成破坏,因为 malloc 通常为它所分配的存储区维护一个链接表,而插入执行信号处理程序时,进行可能正在更改此链接表。
若在信号处理程序中调用一个不可重入函数,则其结果是不可预见的。
摘自:APUE, 10.6 可重入函数
A function is said to be reentrant if it can safely be simultaneously executed by multiple threads of execution in the same process. In this context, "safe" means that the function achieves its expected result, regardless of the state of execution of any other thread of execution.
可重入函数符合下面条件:
1、不在函数内部使用静态或全局数据。
2、不返回静态或全局数据,所有数据都由函数的调用者提供。
3、不调用不可重入函数。
An AS-Safe (async-signal-safe) function is one that the implementation guarantees to be safe when called from a signal handler.
参考:The Linux Programming Interface, by Michael Kerrisk, 21.1 Designing Signal Handlers
注:异步信号安全函数和可重入函数可以理解为从不同角度的描述同一事情。
7.2.1. 可重入函数和多线程安全函数关系
可重入函数更加严格。可重入函数一定是多线程安全函数,多线程安全函数不一定是可重入函数。
7.3. AC-Safe
AC-Safe or Async-Cancel-Safe functions are safe to call when asynchronous cancellation is enabled. AC in AC-Safe stands for Asynchronous Cancellation.
The POSIX standard defines only three functions to be AC-Safe, namely pthread_cancel, pthread_setcancelstate, and pthread_setcanceltype.
异步取消安全,是和线程取消相关的概念。
默认地,给某线程发送一个取消请求,期待被取消的线程还会继续运行直到到达某个取消点。取消点是线程检查是否被取消并按照请求进行动作的一个位置。POSIX.1 规定了线程调用某些函数时取消点会出现(参考 APUE 12.7 节)。这种线程取消的类型被称为延迟取消(PTHREAD_CANCEL_DEFERRED),还有一种是异步取消(PTHREAD_CANCEL_ASYNCHRONOUS)。
7.3.1. 线程异步取消
使用异步取消时,线程可以在任意时间取消,而不是非得遇到取消点才能被取消。
As a general principle, an asynchronously cancelable thread can’t allocate any resources or acquire any mutexes, semaphores, or locks. This precludes the use of a wide range of library functions, including most of the Pthreads functions. (SUSv3 makes exceptions for pthread_cancel(), pthread_setcancelstate(), and pthread_setcanceltype(), which are explicitly required to be async-cancel-safe; that is, an implementation must make them safe to call from a thread that is asynchronously cancelable.) In other words, there are few circumstances where asynchronous cancellation is useful. One such circumstance is canceling a thread that is in a compute-bound loop.
参考:The Linux Programming Interface, by Michael Kerrisk, Section 32.6 Asynchronous Cancelability.
一句话总结,只有 AC-Safe 的函数才能在可异步取消的线程中被调用。
假如一个可异步取消的线程正在调用一个不是 AC-Safe 的函数(如 malloc)时,其它线程向它发送了一个取消请求,它马上取消了,此时 malloc 函数还没有返回,这可能导致 malloc 函数内部的链表结构不一致。