Distributed transaction, without XA
Table of Contents
1. CAP Theorem
Eric Brewer 于 1998 年提出了 CAP 公理(CAP theorem):分布式系统的三项重要指标,即一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance),在任意时刻,只有两项能同时成立。
下面以“分布式存储系统”为例,介绍一下这三项指标:
- 一致性:大意是存储系统的所有客户端请求,都能得到一个“说的过去”的响应。例如:A 先写入 1 再写入 2,B 不能读到 2 之后又读到 1。
- 可用性:存储系统的所有操作最终都返回成功。我们称系统是可用的。
- 分区容错性:如果集群中的机器被分成了两部分,这两部分不能互相通信,这时系统还能继续正常工作的话,就说系统具有分区容错性。
上面描述的“机器被分成了两部分,这两部分不能互相通信”,这类故障称为网络分区故障(Network Partition Failure)。出现网络分区故障时,我们需要从下面两个选项中做个选择:
- 取消操作,不进行处理,这样会降低可用性,但保证了一致性,即选择 C(一致性);
- 继续操作,这样保障了可用性,但存在不一致的风险,即选择 A(可用性)。
需要说明的是,对于一个分布式系统而言,分区容错性是一个最基本的要求。因为既然是一个分布式系统,那么分布式系统中的组件必然需要被部署到不同的节点,否则也就无所谓分布式系统了,既然是多个节点,就必然可能出现网络分区故障。如果想出现网络分区故障,一种简单的做法是将所有的数据都放在一个节点上。这样的做法虽然无法 100% 地保证系统不会出错,但至少不会碰到由于网络分区带来的负面影响。也就是说,系统退化成了单机系统(系统没有可扩展性了,不再是分布式系统)后,才不用担心网络分区问题,才可以放弃 P(分区容错性)。系统架构设计师往往需要把精力花在如何根据业务特点在 C(一致性)和 A(可用性)之间寻求平衡。
分布式事务规范 XA 中的两阶段提交协议(Two-Phase Commit protocol)选择了 CAP 中的 C(一致性)和 P(分区容错性),而放弃了 A(可用性)。它在高并发场景下,没有可用性,所以高并发系统一般不会使用 XA。
Ebay 的架构师在 2008 年提出了 BASE,它选择了 A(可用性)和 P(分区容错性),而放弃了 C(仅是放弃了强一致性,会最终达到一致)。即系统可能在某个时间点处于不一致的状态,但我们会想办法让系统(在某个时间内,如 5s 或 1 天)最终达到一致。后文将介绍 BASE。
2. BASE (Basically available, Sofe state, Eventually consistent)
BASE (论文中文版 Base: An Acid Alternative)是 Basically available, Sofe state, Eventually consistent 的编写,这个缩写多少有些拼凑的感觉。可能是作者认为它的含义与 ACID 恰好相反。在英文中,Acid 代表酸,而 Base 代表碱。就像这两个单词在化学中的含义一样——ACID 与 BASE 位于 CAP 理论的两端,代表了分布式系统的两种选择。
下面用论文中的例子来说明 BASE 方案中是如何不用分布式事务(二阶段提交,2PC),而最终也能实现一致性的。
假设一个买卖系统中“买家”和“卖家”之间产生了一笔交易。系统的数据库如图 1 所示。
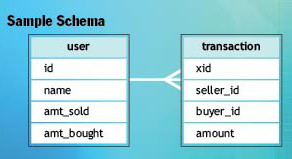
Figure 1: 数据库例子
产生交易后,我们需要更新 transaction 表和 user 表,看起来像图 2 所示。

Figure 2: 分布式事务解决办法(往往是“性能瓶颈”)
为了保证分区容错性,user 表和 transaction 表往往不在一个主机上。所以,上面的事务是一个分布式事务。为了使系统提供更好的可用性,我们应该避免分布式事务。比如把上面过程拆为两个本地事务(一个事务仅访问一个主机上的数据表),如图 3 所示。

Figure 3: 拆为两个本地事务,一致性无法保障
把分布式事务拆为两个本地事务后,一致性无法得到保障(因为在这两个事务之间如果系统出现故障,那么系统就不一致了)。
怎么办?我们可以引入一个“消息队列”,如图 4 所示。

Figure 4: 引入“消息队列”,但第二个事务中还是有 2PC 问题
为了避免第一个事务成为分布式事务,“消息队列”和 transaction 表应该在同一个主机上,但这时“消息队列”没有和 user 表在同一个主机上,从而第二个事务就成为了分布式事务。
一种可能的解决办法是:什么都不做,就让第二个事务是分布式事务,但把它放到后端去处理。 通过把对 user 表的更新操作(第二个事务)解耦到一个单独的后端组件,我们可以保留面向客户的组件的可用性。对业务需求来说,消息处理器(即第二个事务)慢一点可能是可接受的。
其实,我们也可以让第二个事务从分布式事务变为本地事务。请看下文。
2.1. 使用“消息队列”和“消息应用状态表”去除分布式事务
在前面的介绍中,引入了“消息队列”,使得一个分布式事务拆为两个事务:一个本地事务和另一个分布式事务(这个分布式事务可以作为一个后端组件,而不影响面向客户的组件的可用性)。
为了避免前面提到的“第二个事务”成为分布式事务,我们在 user 表所在主机中增加另一个表——“消息应用状态表 updates_applied”,如图 5 所示。
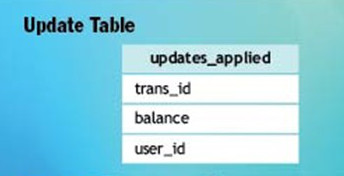
Figure 5: “消息应用状态表”(已经处理过的消息会加到这个表中)
有了上面的表后,我们可以把第二个事务中对消息队列的操作移到事务外部(即不在“Begin transaction”和“End transaction”中间)来做(这样第二个事务就不是分布式事务了),如图 6 所示。

Figure 6: 最终方案——用“消息应用状态表”
说明 1:在上面的实现中,第二个事务开始之前只是“Peek message”,当第二个事务成功后才“Remove message from queue”。
说明 2:在第二个事务结束后,“Remove message from queue”之前如果系统出故障,系统重新从消息队列中取出这一消息后,通过 updates_applied 表可以检查出来这一消息已经被应用过(此时代码中条件“If processed == 0”不会满足),所以并不会再次应用这个消息。
说明 3:显然,如果消息已经被从消息队列中删除,那么就可以把它从“消息应用状态表”中也删除(当然不删除也没有关系)。
说明 4: 增加“消息应用状态表”的目的是保证第二个事务是“幂等操作”(即:重复调用多次产生的业务结果与调用一次产生的业务结果相同。这很有用,因为在部分失败时,会再调用它,而反复地调用它不会改变系统的最终状态)。
至此,我们没有使用分布式事务,实现了系统的“最终一致性”(系统在某个时间点上可能是不一致的,但最终会达到一个一致的状态)。
总结:
采用 BASE 方案(增加了“消息队列”和“消息应用状态表”),解除了两个数据库之间的紧密耦合,系统性能和可伸缩性大大增强,但使得应用程序的开发变得相对复杂 (采用分布式事务时,应用程序的逻辑是非常简单的,如图 2 所示)。
3. TCC (Try-Cancel/Confirm) 模式
TCC 是另外一种不采用分布式事务的解决方案。TCC 模式需要每个业务服务实现自己的 Try/Cancel/Confirm 三个接口,如图 7 所示。其中 Cancel/Confirm 操作要满足“幂等性”(即重复调用多次产生的业务结果与调用一次产生的业务结果相同),如在前面介绍的 BASE 方案中用“消息应用状态表”实现了“幂等性”。TCC 的工作流程如图 8 所示。
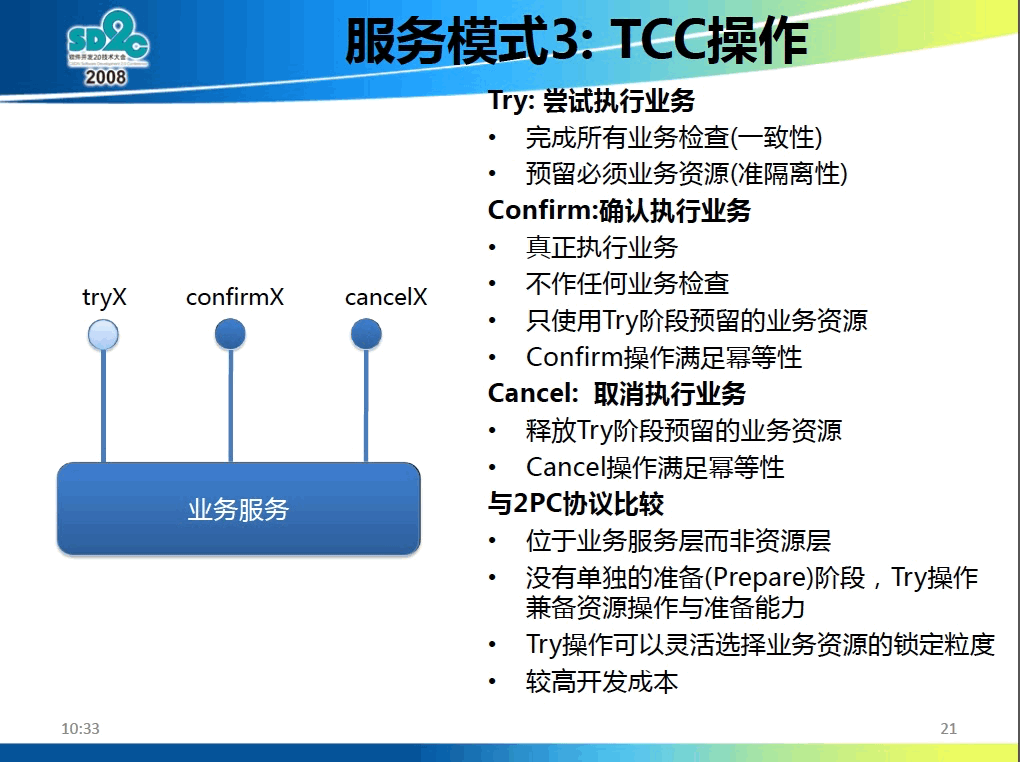
Figure 7: TCC 模式中每个业务需要自己实现三个接口(摘自:大规模 SOA 系统中的分布事务处事,支付宝首席架构师程立)
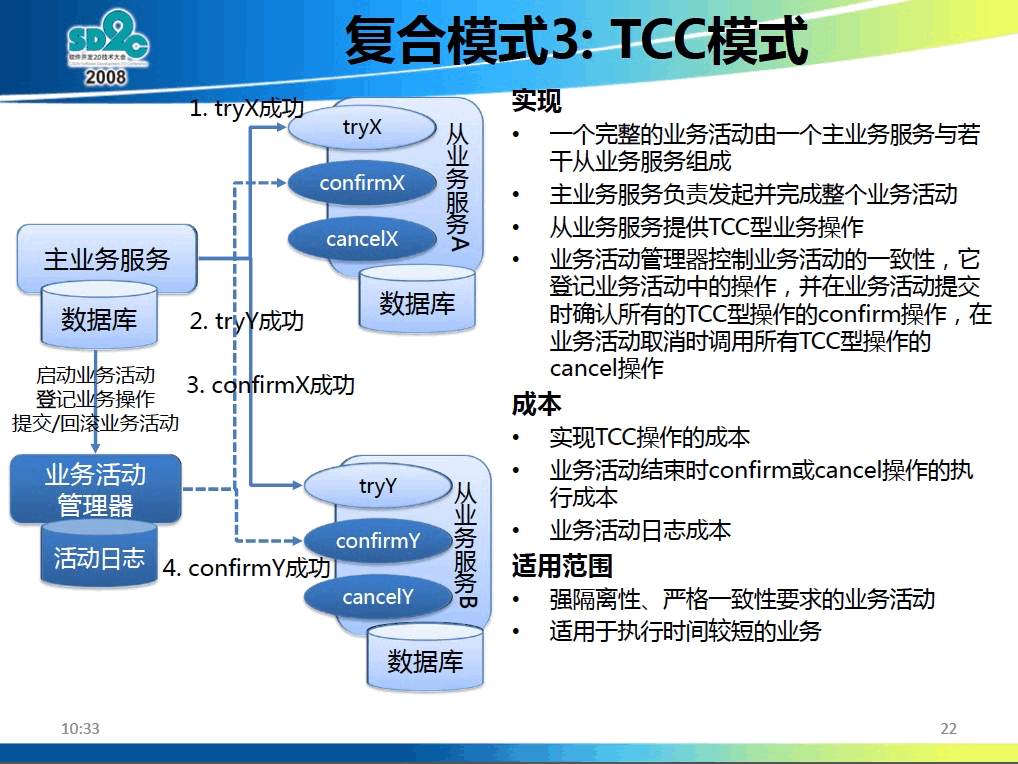
Figure 8: TCC 模式工作流程(摘自:大规模 SOA 系统中的分布事务处事,支付宝首席架构师程立)
一个 TCC 业务分为下面两个阶段:
第一阶段:主业务服务分别调用所有从业务的 try 操作(预留业务资源等),并在活动管理器中登记所有从业务服务。当所有从业务服务的 try 操作都调用成功或者某个从业务服务的 try 操作失败,进入第二阶段。
第二阶段:活动管理器根据第一阶段的执行结果来执行 confirm 或 cancel 操作。如果第一阶段所有 try 操作都成功,则活动管理器调用所有从业务活动的 confirm 操作。否则调用所有从业务服务的 cancel 操作。
从流程上说,TCC 和 XA 的二阶段提交过程非常相似。可以认为 TCC 实际上把数据库层的二阶段提交上放到了应用层来实现。
3.1. TCC 优缺点
TCC 的优点:性能比 XA 要好。TCC 实际上把数据库层的二阶段提交上放到了应用层来实现,对于数据库来说是一阶段提交,规避了数据库层的二阶段提交性能低下问题。
TCC 的缺点:TCC 的 Try、Confirm 和 Cancel 操作功能需业务提供,开发成本高。