Unicode, UTF-8
Table of Contents
1. Unicode 简介
Unicode 是什么呢?它仅仅是给每个字符提供唯一的数字编号(称为 codepoint)。
1.1. Unicode 历史
Unicode 的历史如表 1 所示。
| Version | Date | Scripts | Total Characters | Notable Additions |
|---|---|---|---|---|
| 1.0.0 | October 1991 | 24 | 7,161 | Initial repertoire covers these scripts: Arabic, Armenian, Bengali, Bopomofo, Cyrillic, Devanagari, Georgian, Greek and Coptic, Gujarati, Gurmukhi, Hangul, Hebrew, Hiragana, Kannada, Katakana, Lao, Latin, Malayalam, Oriya, Tamil, Telugu, Thai, and Tibetan. |
| 1.0.1 | June 1992 | 25 | 28,359 | The initial set of 20,902 CJK Unified Ideographs is defined. |
| 1.1 | June 1993 | 24 | 34,233 | 4,306 more Hangul syllables added to original set of 2,350 characters. Tibetan removed. |
| 2.0 | July 1996 | 25 | 38,950 | Original set of Hangul syllables removed, and a new set of 11,172 Hangul syllables added at a new location. Tibetan added back in a new location and with a different character repertoire. Surrogate character mechanism defined, and Plane 15 and Plane 16 Private Use Areas allocated. |
| 2.1 | May 1998 | 25 | 38,952 | Euro sign and Object Replacement Character added. |
| 3.0 | September 1999 | 38 | 49,259 | Cherokee, Ethiopic, Khmer, Mongolian, Burmese, Ogham, Runic, Sinhala, Syriac, Thaana, Unified Canadian Aboriginal Syllabics, and Yi Syllables added, as well as a set of Braille patterns. |
| 3.1 | March 2001 | 41 | 94,205 | Deseret, Gothic and Old Italic added, as well as sets of symbols for Western music and Byzantine music, and 42,711 additional CJK Unified Ideographs. |
| 3.2 | March 2002 | 45 | 95,221 | Philippine scripts Buhid, Hanunó'o, Tagalog, and Tagbanwa added. |
| 4.0 | April 2003 | 52 | 96,447 | Cypriot syllabary, Limbu, Linear B, Osmanya, Shavian, Tai Le, and Ugaritic added, as well as Hexagram symbols. |
| 4.1 | March 2005 | 59 | 97,720 | Buginese, Glagolitic, Kharoshthi, New Tai Lue, Old Persian, Syloti Nagri, and Tifinagh added, and Coptic was disunified from Greek. Ancient Greek numbers and musical symbols were also added. |
| 5.0 | July 2006 | 64 | 99,089 | Balinese, Cuneiform, N'Ko, Phags-pa, and Phoenician added. |
| 5.1 | April 2008 | 75 | 100,713 | Carian, Cham, Kayah Li, Lepcha, Lycian, Lydian, Ol Chiki, Rejang, Saurashtra, Sundanese, and Vai added, as well as sets of symbols for the Phaistos Disc, Mahjong tiles, and Domino tiles. There were also important additions for Burmese, additions of letters and Scribal abbreviations used in medieval manuscripts. |
| 5.2 | October 2009 | 90 | 107,361 | Avestan, Bamum, Egyptian hieroglyphs (the Gardiner Set, comprising 1,071 characters), Imperial Aramaic, Inscriptional Pahlavi, Inscriptional Parthian, Javanese, Kaithi, Lisu, Meetei Mayek, Old South Arabian, Old Turkic, Samaritan, Tai Tham and Tai Viet added. 4,149 additional CJK Unified Ideographs (CJK-C), as well as extended Jamo for Old Hangul, and characters for Vedic Sanskrit. |
| 6.0 | October 2010 | 93 | 109,449 | Batak, Brahmi, Mandaic, playing card symbols, transport and map symbols, alchemical symbols, emoticons and emoji. 222 additional CJK Unified Ideographs (CJK-D) added. |
| 6.1 | January 2012 | 100 | 110,181 | Chakma, Meroitic cursive, Meroitic hieroglyphs, Miao, Sharada, Sora Sompeng, and Takri. |
| 6.2 | September 2012 | 100 | 110,182 | Turkish lira sign. |
| 6.3 | September 2013 | 100 | 110,187 | 5 bidirectional formatting characters. |
| 7.0 | June 2014 | 123 | 113,021 | Bassa Vah, Caucasian Albanian, Duployan, Elbasan, Grantha, Khojki, Khudawadi, Linear A, Mahajani, Manichaean, Mende Kikakui, Modi, Mro, Nabataean, Old North Arabian, Old Permic, Pahawh Hmong, Palmyrene, Pau Cin Hau, Psalter Pahlavi, Siddham, Tirhuta, Warang Citi, and Dingbats. |
| 8.0 | June 2015 | 129 | 120,737 | Ahom, Anatolian hieroglyphs, Hatran, Multani, Old Hungarian, SignWriting, 5,771 CJK unified ideographs, a set of lowercase letters for Cherokee, and five emoji skin tone modifiers |
| 9.0 | June 2016 | 135 | 128,237 | Adlam, Bhaiksuki, Marchen, Newa, Osage, Tangut, and 72 emoji |
| 10.0 | June 2017 | 139 | 136,755 | Zanabazar Square, Soyombo, Masaram Gondi, Nüshu, hentaigana (non-standard hiragana), 7,494 CJK unified ideographs, and 56 emoji |
1.2. Unicode 术语
参考:Glossary of Unicode Terms: http://unicode.org/glossary/
1.2.1. Codespace (0 ~ 0x10FFFF), Codepoint, Plane
Unicode 定义的 codespace 为 0 ~ 0x10FFFF (也写为 U+0000~U+10FFFF ),理论上它所能表示的字符数约为 111 万(准确值为 1114111+1)。
Codespace 中的每一个值都称为 codepoint(注:不是每个 codepoint 都分配了对应的字符),显然 codepoint 的最大值为 0x10FFFF ,编程语言中用 4 字节的 int 类型足够表示每个 codepoint。
按照 codepoint 的范围,把整个 codespace 分为了 17 个平面(Plane),每个平面的 codepoint 数目相同都为 65536,第 1 个平面称为基本平面,后面 16 个平面称为补充平面,如表 2 所示。
| Plane 编号 | Codepoint 范围(16 进制) | 说明 |
|---|---|---|
| 0 | 0000–FFFF | 基本多文种平面(Basic Multilingual Plane, BMP) |
| 1 | 10000–1FFFF | 多文种补充平面(Supplementary Multilingual Plane, SMP) |
| 2 | 20000–2FFFF | 表意文字补充平面(Supplementary Ideographic Plane, SIP) |
| 3 | 30000–3FFFF | 表意文字第三平面(Tertiary Ideographic Plane, TIP) |
| 4 to 13 | 40000–DFFFF | 尚未使用 |
| 14 | E0000–EFFFF | 特别用途补充平面(Supplementary Special-purpose Plane, SSP) |
| 15 | F0000–FFFFF | 保留作为私人使用区(Private Use Plane) |
| 16 | 100000–10FFFF | 保留作为私人使用区(Private Use Plane) |
1.2.2. Scripts
In Unicode, a script is a collection of letters and other written signs used to represent textual information in one or more writing systems. For example, Russian is written with a subset of the Cyrillic script; Ukranian is written with a different subset. The Japanese writing system uses several scripts.
2. UTF-16 编码
UCS-2 编码使用固定 2 字节长度来编码 Unicode 字符(直接使用 codepoint 作为 UCS-2 编码值),由于它仅使用 2 字节,所以它只能对第 1 个平面(即 BMP)中的字符进行编码。为了解决 UCS-2 无法编码其它 16 个平面中字符的问题,出现了 UTF-16。
在介绍 UTF-16 前,先介绍一个知识点: Codepoint 范围 U+D800 ~ U+DFFF (共 2048 个 codepoints)是为 UTF-16 编码保留的,不能用来表示字符,它们被称为 Surrogate Code Points,其中 U+D800 ~ U+DBFF 又称为高代理区(High Surrogate Area),而 U+DC00 ~ U+DFFF 又称为低代理区(Low Surrogate Area)。
2.1. UTF-16 编码规则
UTF-16 编码使用 2 字节或者 4 字节来编码 Unicode 字符,编码规则如下:
1、如果 codepoint 在 U+0000 ~ U+FFFF 之间,则用 2 字节对其 codepoint 直接编码(注:和 ASCII 编码不兼容,在 UTF-16 编码中 ASCII 字符占 2 字节,只是有 1 字节都为 0);
2、如果 codepoint 在 U+10000 ~ U+10FFFF 之间,则用 4 字节对其编码,编码过程为(如图 1 所示,图片改编自 https://blog.csdn.net/zxhoo/article/details/38819517 ):
2.1、将 codepoint 减去 0x10000 ,得到的数会在 0x0 ~ 0xFFFFF 之间,正好可以用 20 个 bit 来表示,分解为高 10bit 和低 10bit;
2.2、将高位的 10 个 bit 和 0xD800 (即 0b1101100000000000 )相加,将低位的 10 个 bit 和 0xDC00 (即 0b1101110000000000 )相加,把它们组合在一起得到 4 字节编码。
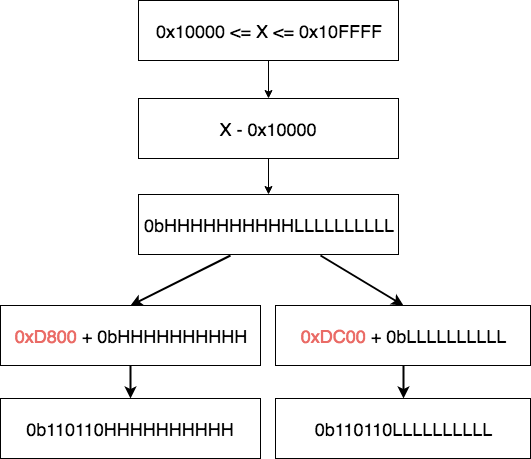
Figure 1: UTF-16 对 U+10000 ~ U+10FFFF 之间 codepoint 的编码过程
2.2. UTF-16 编码实例
图 2 是 UTF-16 编码实例(摘自https://en.wikipedia.org/wiki/UTF-16#Examples)。

Figure 2: UTF-16 编码实例
注:如果 UTF-16 文件的头两个字节是 FE FF ,就表示该文件采用 Big endian 方式;如果头两个字节是 FF FE ,就表示该文件采用 Little endian 方式。
3. UTF-8 编码
UTF-8 编码是一种变长编码(1 至 4 个字节),它可以编码 Unicode 中的所有 codepoint(前面介绍过 codepoint 的范围为 0 ~ 0x10FFFF )。
3.1. UTF-8 编码规则
UTF-8 编码规则如表 3 所示。
| 字节数 | 第 1 字节 | 第 2 字节 | 第 3 字节 | 第 4 字节 | Codepoint 的比特位数 | Codepoint 范围 |
|---|---|---|---|---|---|---|
| 1 | 0xxxxxxx | 7 | U+0000 - U+007F | |||
| 2 | 110xxxxx | 10xxxxxx | 11 | U+0080 - U+07FF | ||
| 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | 16 | U+0800 - U+FFFF | |
| 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 21 | U+10000 - U+10FFFF |
UTF-8 编码的规则很简单:如果第 1 个字节的第 1 位是 0,则它是一个单字节编码;如果第 1 个字节的第 1 位是 1,则连续有多少个 1,就表示当前字符占用多少个字节;后续字节以 10 打头。
3.2. UTF-8 编码实例
下面以汉字“人”(其 codepoint 为 U+4EBA )为例,介绍 UTF-8 的编码过程:
步骤 1:确定采用几个字节进行编码。由于 U+4EBA 在范围 U+0800 ~ U+FFFF 中,所以采用 3 个字节进行编码。
步骤 2:确定每一字节的编码。 4EBA 的二进制有 15 位 100111010111010 ,在左边补 1 个 0,补齐 16 位,把这 16 位按表 3 中指定的规则依次分配给 3 个字节(第 1 字节分配 4 位,第 2/3 字节都分配 6 位),从而第 1 字节为 1110 0100 (0xE4),第 2 字节为 10 111010 (0xBA),第 3 字节为 10 111010 (0xBA),最终可得“人”的 UTF-8 编码为 0xE4BABA。
注:常见基本汉字的 Unicode codepoint 范围为 U+4E00 ~ U+9FA5 ,从表 3 中可知它们在 UTF-8 中需要用3个字节来编码。