Viewstamped Replication
Table of Contents
1. VR 简介
1988 年 Brian Oki 和 Barbara Liskov 在论文 Viewstamped Replication: A New Primary Copy Method to Support Highly-Available Distributed Systems 中提出了 Viewstamped Replication 协议(简称 VR 协议);2012 年,Barbara Liskov 和 James Cowling 在论文 Viewstamped Replication Revisited 中对 VR 协议进行了更新。本文介绍 2012 年更新版本的 VR 协议。
在分布式系统中,为了提高系统的可用性,往往需要把数据复制到多个节点中,每个节点都是一个 replica。replica 又可分为 primary 和 backup,客户端往 primary 发送请求,primary 复制执行日志到 backup,如果大多数 replica 成功,则返回客户端成功。但如果 primary 突然不可用,需要重新选择 primary,且需要处理潜在的不一致的问题。VR 提出了 3 个子协议(参见节 3),以处理正常和异常的情况。
1.1. 仅考虑 Crash,至少要 2f+1 个节点
VR 协议,仅考虑 Crash 错误,不考虑 Byzantine 错误。 也就是假设节点可能会 Crash,但节点不会做恶(节点不会故意发送错误不一致的数据包)。在这个假设前提下,如果系统中有 \(f\) 个 Crash 节点,则总共至少要 \(2f+1\) 个节点系统才能正常工作。
2. Architecture
VR 协议运行时如图 1 所示。客户端在 VR Proxy 上层工作,用户代码调用 VR Proxy 代码和分布式系统进行交互。VR Proxy 和集群通信,并返回结果给客户端。
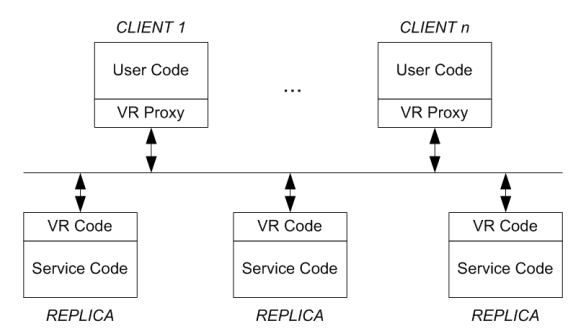
Figure 1: VR Architecture; the figure shows the configuration when \(f = 1\).
3. VR 的 3 个子协议
3.1. Normal Case
在讨论之前,先交待一下,系统中每个节点(包含 primary 和 backup)都有下面状态:
- The configuration. This is a sorted array containing the IP addresses of each of the \(2f + 1\) replicas.
- The replica number. This is the index into the configuration where this replica’s IP address is stored.
- The current view-number, initially 0.
- The current status, either normal, view-change, or recovering.
- The op-number assigned to the most recently received request, initially 0.
- The log. This is an array containing op-number entries. The entries contain the requests that have been received so far in their assigned order.
- The commit-number is the op-number of the most recently committed operation.
- The client-table. This records for each client the number of its most recent request, plus, if the request has been executed, the result sent for that request.
下面是正常情况下的处理流程:
- client 发送请求消息
<Request op, c, s>给 primary 节点,这里op是具体的操作(包含参数),c是client-id,s是关联的一个 request-number。 - 当 primary 收到请求后,查询 client-table,检查请求中 request-number 是否是历史记录中的要大,如果新收到 request-number 比 client-table 中记录的要大,则正常处理;如果小(说明已经执行过了),则丢弃。
- primary 递增本地的 op-number,将请求追加到 log 末尾,更新 client-table 中记录的请求编号为
s。发送消息<Prepare v, m, n, k>给所有的 backup,这里v是 view-number(当前成员组的编号),m是从 client 中收到的消息,n是 op-number(当前请求的编号),k是 commit-number。 - backup 总是“有序地”处理 Prepare 消息, 通过检查收到的
n来确认自己的 log 中已经包含所有前面的请求(即按顺序接收 log entry),若前面有缺失则继续等待(或请求其它节点补齐数据),否则将请求追加到 log 末尾,并给 primary 回复<PrepareOK v, n, i>消息。 - primary 收到
f个 PrepareOK 消息后,就认为当前的操作及所有之前的操作都是 commmitted 状态了,primary 递增本地的 commit-number, 然后将<Replay v, s, x>作为应答消息发送给 client,这里v是 view-number,s是 client 发出 Request 时指定的,x是请求的业务结果。
上面过程如图 2 所示。
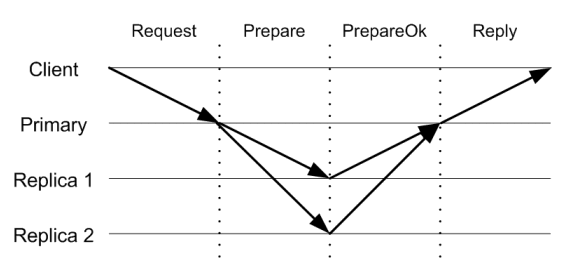
Figure 2: Normal case processing in VR for a configuration with \(f = 1\).
注:primary 确认操作处于 commmitted 状态后,会递增本地的 commit-number,primary 如何告诉 backups 这个新的 commit-number 呢?答案是有两种方式。 方式一、每一个 Prepare 消息中都会携带 commit-number,从而这次的 commit-number 会在下次 Prepare 消息中顺便带给 backups;方式二、如果客户端没有请求时,也就不会有 Prepare 消息,这时 primary 也会周期性发送 <Commit v, k> 消息给 backup 节点,以便 commit-number 能够尽快通知到 backup。 下面介绍 backup 收到 commit-number 的处理,backup 会确认 log 中包含对应的 entry,如果有缺失则继续等待(或请求其它节点补齐数据),然后递增本地的 commit-number,更新本地的 client-table。
3.2. 重新选择 primary
在某一时刻,系统的状态是有一个 primary 与几个 backup 提供服务(未必是所有的 backup),这种状态称为 View。如果 primary 出现故障,则会重新选择 primary,这里旧的 view 就会被打破,从而形成新的 view,这个过程称为 View Change。
primary 出现故障,Backup 是容易发现的。我们知道 primary 在没有客户端请求时会周期性给 backup 发送 Commit 消息,从而如果 backup 超时未收到 Commit 或者 Prepare 消息,则可认为 primary 异常,发起 View Change。
View Change 协议需要确保旧 view 中的 committed entry 能够按原有顺序出现在新 view 中,这一点通过两个多数派一定有交集来保证,即在旧 view 中达成多数派的 entry,一定存在于至少 \(f+1\) 个节点上。
这里不介绍完整的 View Change 协议,仅列出一些要点(摘自:https://zhuanlan.zhihu.com/p/66427412 ):
- 旧 view 可能有一些还未达成多数派的 entry,这些 entry 的 slot 在 new view 生效后,可能会被新的 primary 覆盖写,因此在某一时刻,同一个 slot 在不同节点可能具备不同的 entry,但这两个 entry 的 view-number 一定不同,此时需要以较大的 view-number 为准。
- 新的 primary 上任之前,会从 \(f+1\) 个投票消息中,选取最新、最长的 log 作为自己的 log(先比较 view-number,再比较 op-number),之后再发给所有 backup。
- backup 收到 new primary 的 log 时,也要替换掉本地的 log。
3.3. Recovery
节点宕机重启后,首先将自己置为 Recovering 状态,Recovering 状态下不会参与投票。
Recovery 协议如下:
- 正在恢复的节点
i发送<Recovery i, x>给其它所有 replica,这里x是个 nonce 值。 - 处于 normal 状态的副本
j响应该请求,回复<RecoveryResponse v, x, l, n, k, j>给节点 \(i\) ,这里v是 view-number,x是 Recovery 消息中的 nonce,l是 log,n是 op-number,k是 commit-number。 - 节点
i收到至少 \(f+1\) 个 RecoveryResponse 消息,且其中要包含 primary 发来的消息,然后更新本地 log,切换自己状态为 normal,至此 recovery 过程结束。