Decision Tree
Table of Contents
1. 决策树简介
决策树(Decision Tree)模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。 决策树的主要优点是模型具有可读性(人们容易理解决策的依据),分类速度快。
决策树学习通常包括 3 个步骤:特征选择、决策树的生成和决策树的修剪。 下面是一些著名的决策树学习算法:
(1) 由 Ross Quinlan 在 1986 年提出的 ID3 算法;
(2) 由 Ross Quinlan 在 1993 年提出的 C4.5 算法;
(3) 由 Leo Breiman 等人在 1984 年提出的 Classification and Regression Trees(CART)算法。
参考:
本文主要摘自《统计学习方法,李航著》第 5 章,决策树
1.1. 决策树模型
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分到叶结点的类中。
图 1 是一个决策树的示意图。图中圆和方框分别表示内部结点和叶结点。
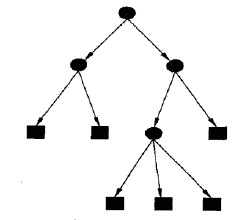
Figure 1: 决策树模型(圆表示特征,方框表示类别)
1.2. 决策树学习
决策树学习,假设给定训练数据集
\[D = \{(\boldsymbol{x_1}, y_1), (\boldsymbol{x_2}, y_2), \cdots, (\boldsymbol{x_N}, y_N)\}\]
其中, \(\boldsymbol{x}_i = (x^{(1)}_i,x^{(2)}_i,\cdots,x^{(n)}_i)^\mathsf{T}\) 为输入实例(特征向量), \(n\) 为特征个数, \(y_i \in \{1, 2, \cdots, K\}\) 为类标记, \(i=1,2,\cdots,N\) , \(N\) 为样本容量。学习的目标是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
决策树学习本质上是从训练数据集中归纳出一组分类规则。与训练数据集不相矛盾的决策树(即能对训练数据进行正确分类的决策树)可能有多个,也可能一个也没有。我们需要的是一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。
2. 特征选择
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。 通常特征选择的准则是“信息增益(Information Gain)”或“信息增益比”。
首先,通过一个例子来说明特征选择问题。
表 1 是一个由 15 个样本组成的贷款申请训练数据。数据包括贷款申请人的 4 个特征:年龄(有 3 个可能值),有工作(有 2 个可能值),有自己的房子(有 2 个可能值),信贷情况(有 3 个可能值)。表的最后一列是类别,是否同意贷款,取 2 个值:是,否。
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
希望通过所给的训练数据学习一个贷款申请的决策树,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用决策树决定是否批准贷款申请。
图 2 表示两个可能的决策树的一部分,分别由两个不同特征的根结点构成。选择哪个特征作为根结点呢?直观上,如果一个特征具有更好的分类能力,那么就应该先选择这个特征。 信息增益能够很好地表示这一直观的准则。
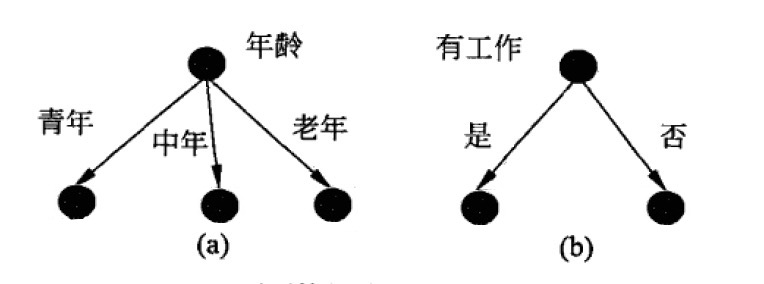
Figure 2: 两个可能的决策树(仅部分),哪个更好呢?
2.1. 熵(Entropy)
在介绍信息增益前,我们需要先了解一下熵和条件熵的概念。
在信息论与概率统计中, 熵(entropy)是表示随机变量不确定性的度量。 设 \(X\) 是取有限个值的离散随机变量,其概率分布为: \(P(X=x_i) = p_i, \, i=1,2,\cdots,n\) 。随机变量 \(X\) 的熵记为 \(H(X)\) ,其定义为:
\[H(X) = \sum_{i=1}^{n} p_i \log \frac{1}{p_i} = - \sum_{i=1}^{n} p_i \log p_i\]
在上式中,若 \(p_i=0\) ,则定义 \(0\log0=0\) 。通常,当熵定义中对数以 2 或以 \(e\) 为底时,熵的单位分别称为“比特(bit)”或者“纳特(nat)”。由定义可知,熵只依赖于 \(X\) 的分布,而与 \(X\) 的取值无关,所以也可将 \(X\) 的熵记作 \(H(p)\) ,即:
\[H(p) = - \sum_{i=1}^{n} p_i \log p_i\]
熵越大,随机变量的不确定性就越大。 我们通过一个简单的例子来说明这个结论。
当随机变量只取两个值(例如 1,0),即 \(X\) 的分布(伯努利分布)为:
\[P(X=1)=p, \quad P(X=0)=1-p, \quad 0 \le p \le 1\]
熵为:
\[H(p) = -(p \log_{2}p) - (1-p) \log_{2}(1-p)\]
熵 \(H(p)\) 随概率 \(p\) 变化的曲线如图 3 所示(单位为比特)。
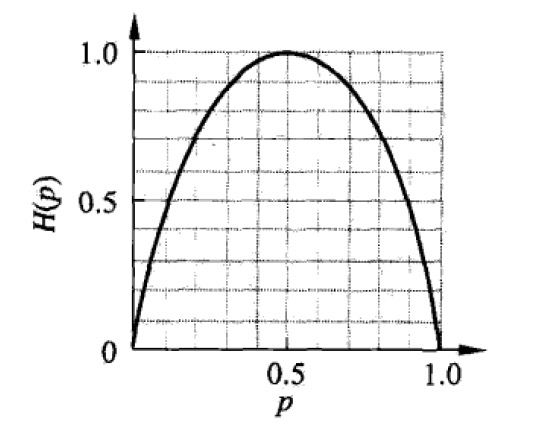
Figure 3: 分布为伯努利分布时熵与概率 \(p\) 的关系
当 \(p=0\) 或者 \(p=1\) 时 \(H(p)=0\) ,随机变量完全没有不确定性;当 \(p=0.5\) 时, \(H(p)=1\) ,熵取值最大,随机变量不确定性最大。
2.2. 条件熵(Conditional Entropy)
设有二维随机变量 \((X,Y)\) ,其联合概率分布为:
\[P(X=x_i,Y=y_j)=p_{ij}, \; i=1,2,\cdots,n; \;j=1,2,\cdots,m\]
条件熵 \(H(Y \mid X)\) 的定义为 \(X\) 给定条件下 \(Y\) 的条件概率分布的熵对 \(X\) 的数字期望,即:
\[H(Y \mid X)= \sum_{i=1}^{n}p_{i\cdot}H(Y \mid X=x_i)\]
其中, \(p_{i\cdot}=P(X=x_i), \, i=1,2,\cdots,n\) 为 \((X,Y)\) 关于 \(X\) 的边缘分布律。 条件熵 \(H(Y \mid X)\) 表示在已知随机变量 \(X\) 的条件下随机变量 \(Y\) 的不确定性。
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到的,所对应的熵与条件熵分别称为“经验熵(empirical entropy)”和“经验条件熵(empirical conditional entropy)”。
2.3. 信息增益
我们可以用信息增益(information gain)表示得知特征 \(X\) 的信息而使得类 \(Y\) 的信息的不确定性减少的程度。
特征 \(A\) 对训练数据集 \(D\) 的信息增益记为 \(g(D,A)\) ,其定义为集合 \(D\) 的经验熵 \(H(D)\) 与特征 \(A\) 给定条件下 \(D\) 的经验条件熵 \(H(D \mid A)\) 之差, 即:
\[g(D,A) = H(D) - H(D \mid A)\]
在决策树学习中,对于给定训练数据集 \(D\) 和特征 \(A\) ,经验熵 \(H(D)\) 表示对数据集 \(D\) 进行分类的不确定性,而经验条件熵 \(H(D \mid A)\) 表示在特征 \(A\) 给定的条件下对数据集 \(D\) 进行分类的不确定性。 它们的差(即信息增益)表示由于特征 \(A\) 而使得对数据集 \(D\) 的分类的不确定性减少的程度。不同的特征往往具有不同的信息增益,信息增益大的特征具有更强的分类能力。
2.3.1. 信息增益计算实例
求表 1 所给的训练数据集 \(D\) 中的最优特征(信息增益最大的特征)。
首先,计算经验熵 \(H(D)\) :
\[H(D)= -\frac{9}{15} \log_2\frac{9}{15} - \frac{6}{15} \log_2\frac{6}{15} = 0.971\]
然后,分别计算各个特征对数据集 \(D\) 的信息增益,分别以 \(A_1,A_2,A_3,A_4\) 表示年龄、有工作、有自己的房子和信贷情况 4 个特征。则:
\[\begin{aligned} g(D, A_1) & = H(D) - \left[\frac{5}{15}H(D_1) + \frac{5}{15}H(D_2) + \frac{5}{15}H(D_3) \right] \\
&= 0.971 - \left[\frac{5}{15} \left(-\frac{2}{5} \log_2 \frac{2}{5} - \frac{3}{5} \log_2 \frac{3}{5} \right) + \frac{5}{15} \left(-\frac{3}{5} \log_2 \frac{3}{5} - \frac{2}{5} \log_2 \frac{2}{5} \right) + \frac{5}{15} \left(-\frac{4}{5} \log_2 \frac{4}{5} - \frac{1}{5} \log_2 \frac{1}{5} \right) \right] \\
&= 0.971 - 0.888 = 0.083
\end{aligned}\]
上面式子中, \(D_1,D_2,D_3\) 分别是 \(D\) 中 \(A_1\) (年龄)取值为青年、中年和老年的样本子集。
类似地,可以计算其它三个特征 \(A_2,A_3,A_4\) 对数据集 \(D\) 的信息增益。
\[\begin{aligned} g(D, A_2) & = 0.971 - \left[\frac{5}{15} \times 0 + \frac{10}{15} \left( -\frac{4}{10} \log_2 \frac{4}{10} - \frac{6}{10} \log_2 \frac{6}{10} \right) \right] \\
& = 0.324 \\
g(D, A_3) & = 0.971 - \left[\frac{6}{15} \times 0 + \frac{9}{15} \left( -\frac{3}{9} \log_2 \frac{3}{9} - \frac{6}{9} \log_2 \frac{6}{9} \right) \right] \\
& = 0.420 \\
g(D, A_3) & = 0.971 - 0.608 \\
& = 0.363
\end{aligned}\]
最后,比较各特征的信息增益值可知,特征 \(A_3\) (有自己的房子)的信息增益值最大,所以“有自己的房子”是训练数据集 \(D\) 中的最优特征。
2.4. 信息增益比
用信息增益作为划分训练数据集的特征,会偏向于选择取值较多的特征。
为什么呢?假设表 1 样本中“年龄”特征没有分为三类,而是直接给出的具体数字(即多少岁),且假设 15 个样本数据中的年龄都不相同。显然,这时“年龄”特征的取值(15 种可能情况)要远多于其它 3 个特征的取值。我们来计算特征年龄对数据集的信息增益 \(g(D,A) = H(D) - H(D \mid A)\) ,由于每个样本的年龄都不相同,容易验证 \(H(D \mid A)\) 会取最小值 0。这时 \(g(D,A)\) 会取最大值。这个极端例子说明了:用信息增益作为划分训练数据集的特征,会偏向于选择取值较多的特征。
信息增益比是特征选择的另一准则。 信息增益比(Information Gain Ratio)通过引入一个被称作分裂信息(Split Information)的项来惩罚取值较多的特征。
特征 \(A\) 对训练数据集 \(D\) 的信息增益比记为 \(g_R(D,A)\) ,其定义为信息增益 \(g(D,A)\) 与训练数据集 \(D\) 关于特征 \(A\) 的值的熵 \(H_A(D)\) (称为 Split Information)之比,即:
\[g_R(D,A) = \frac{g(D, A)}{SplitInformation(D,A)}\]
其中, \(SplitInformation(D,A) = H_A(D) = - \sum_{i=1}^{n}\frac{|D_i|}{|D|} \log_2\frac{|D_i|}{|D|}\) , \(n\) 是特征 \(A\) 取值的个数。
3. 决策树的生成
ID3 算法和 C4.5 算法是两种经典的决策树生成算法。
3.1. ID3 算法及实例
ID3算法 的核心是应用信息增益来选择特征,递归地构建决策树。 ID3 算法的具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益,选取信息增益最大的特征作为结点特征,根据此特征对数据进行分类,以此建立不同子结点。再对各个子结点递归地使用同样方法构建决策树,直至所有特征的增益均很小(小于阈值)或没有特征可选择时为止,最终完成决策树的构建。
ID3 算法正式描述如下:
输入:训练集 \(D\) ,特征集 \(A\) ,阈值 \(\varepsilon\) 。
输出:决策树 \(T\) 。
(1) 若 \(D\) 中所有实例属于同一类 \(C_{k}\) ,则 \(T\) 为单结点树,并将 \(C_{k}\) 作为该结点的类标记,返回 \(T\) ;
(2) 若 \(A= \phi\) ,则 \(T\) 为单结点树,并将 \(D\) 中实例数最大的类 \(C_{k}\) 作为该结点的类标记,返回 \(T\) ;
(3) 否则,计算 \(A\) 中各特征对 \(D\) 的信息增益,选择信息增益最大的特征,记为 \(A_{g}\) ;
(4) 如果 \(A_{g}\) 的信息增益小于阈值 \(\varepsilon\) ,则置 \(T\) 为单结点树,并将 \(D\) 中实例最大的类 \(C_{k}\) 作为该结点的类标记,返回 \(T\) ;
(5) 否则,对 \(A_{g}\) 的每一可能值 \(a_{i}\) ,依 \(A_{g}=a_{i}\) 将 \(D\) 分割为若干非空子集 \(D_{i}\) ,将 \(D_{i}\) 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树 \(T\) ,返回 \(T\) ;
(6) 对第 \(i\) 个子结点,以 \(D_{i}\) 为训练集,以 \(A-{A_{g}}\) 为特征集,递归地调用前面 5 个步骤,得到子树 \(T_{i}\) ,返回 \(T_{i}\) 。
下面介绍如何使用 ID3 算法对表 1 所给的训练数据集建立决策树。
在 2.3.1 中,我们已经计算出特征 \(A_3\) (有自己的房子)的信息增益值最大,所以第一步选择特征 \(A_3\) 作为根结点的特征。它将训练数据集 \(D\) 划分为两个子集 \(D_1\) ( \(A_3\) 取值为“是”的训练数据组成)和 \(D_2\) ( \(A_3\) 取值为“否”的训练数据组成)。这个例子中,由于 \(D_1\) 只有同一类的样本点,所以它成为一个叶结点,结点的类标记为“是”。
对于 \(D_2\) 则需要从特征 \(A_1\) (年龄), \(A_2\) (有工作)和 \(A_4\) (信贷情况)中选择新的特征。计算各个特征的信息增益:
\[\begin{aligned} g(D_2, A_1) & = H(D_2) - H(D_2 \mid A_1) = 0.918 - 0.667 = 0.251 \\
g(D_2, A_2) & = H(D_2) - H(D_2 \mid A_2) = 0.918 \\
g(D_2, A_4) & = H(D_2) - H(D_2 \mid A_4) = 0.474 \\
\end{aligned}\]
选择信息增益最大的特征 \(A_2\) (有工作)作为结点的特征。由于 \(A_2\) 有两个可能的取值,从这一结点又可以引出两个子结点:一个对应“是”(有工作)的子结点,它包含 3 个样本,它们属于同一类别“是”(允许贷款),所以这是一个叶结点,标记为“是”;另一个是对应“否”(无工作)的子结点,包含 6 个样本,它们也属于同一类别“否”(“不允许贷款”),所以这也是一个叶结点,类标记为“否”。这样,我们得到了如图 4 所示的决策树。这个决策树只用了两个特征。
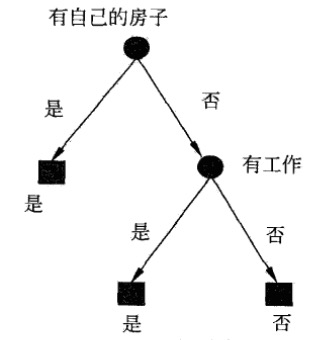
Figure 4: 使用 ID3 算法生成的决策树
ID3 算法只有有树的生成(没有剪枝),所以该算法生成的树容易产生过拟合。
4. 决策树的剪枝
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知测试数据却不那么准确,即出现过拟合现象。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化。
在决策树学习中将已生成的树进行简化的过程称为剪枝(pruning)。具体地,剪枝从已生成的树上裁掉一些子树或叶结点,并将其父结点作为新的叶结点,从而简化分类树模型。
本节介绍一种简单的决策树的剪枝算法。
决策树的剪枝往往通过极小化决策树整体的损失函数(loss function)或代价函数(cost function)来实现。 设树 \(T\) 的叶结点个数为 \(|T|\) , \(t\) 是树 \(T\) 的叶结点,该叶结点有 \({N_{t}}\) 个样本点,其中 \(k\) 类( \(k=1,2,\cdots,K\) )的样本点有 \(N_{tk}\) 个,\(H_{t}(T)=-\sum_{k=1}^{K}\frac{N_{tk}}{N_{t}} \log\frac{N_{tk}}{N_{t}}\) 为叶结点 \(t\) 上的经验熵, \(\alpha \ge 0\) 为参数,则 决策树学习的损失函数可以定义为:
\[C_{\alpha}(T)=\sum_{t=1}^{|T|}N_{t}H_{t}(T)+\alpha|T|\]
如果把上式中的第一项记为 \(C(T)\) ,即:
\[C(T)=\sum_{t=1}^{|T|}N_{t}H_{t}(T)=-\sum_{t=1}^{|T|}\sum_{k=1}^{K}N_{tk} \log\frac{N_{tk}}{N_{t}}\]
这时有:
\[C_{\alpha}(T)=C(T)+\alpha|T|\]
前一部分 \(C(T)\) 表示的是模型对训练数据的预测误差,即模型与训练数据的拟合程度,而后一部分 \(|T|\) 表示模型复杂度,参数 \(\alpha \ge 0\) 控制两者之间的影响。 较大的 \(\alpha\) 促使选择较简单的模型(树),较小的 \(\alpha\) 促使选择较复杂的模型(树)。 \(\alpha=0\) 意味着只考虑模型与训练数据的拟合程度(也就是没有剪枝),不考虑模型的复杂度。
下面介绍一个极小化决策树损失函数 \(C_{\alpha}(T)\) 的算法(即决策树的一个剪枝算法)。
输入:生成算法产生的整个树,参数 \(\alpha\) 。
输出:修剪后的子树 \(T_{alpha}\) 。
(1) 计算每个结点的经验熵;
(2) 递归地从树的叶结点向上往回缩,如果回缩后的树的损失函数的值更小,则进行剪枝。设一组叶结点回缩到其父结点之前与之后的整体树分别为 \(T_B\) 与 \(T_A\) ,其对应的损失函数值分别为 \(C_{\alpha}(T_B)\) 与 \(C_{\alpha}(T_A)\) ,如果 \(C_{\alpha}(T_A) \le C_{\alpha}(T_B)\) 则进行剪枝,即将父结点变为新的叶结点。如图 5 所示;
(3) 返回上一步,直到不能继续为止,即可得到损失函数最小的子树。
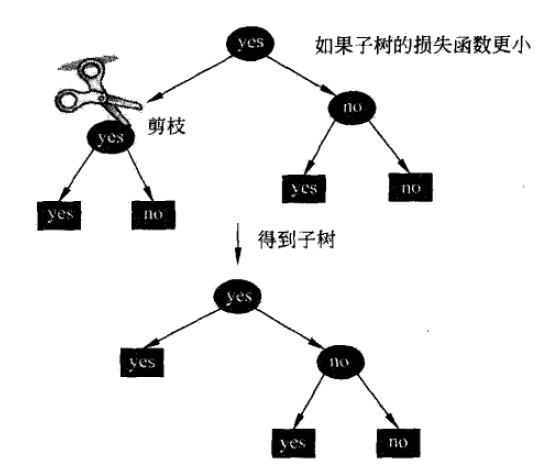
Figure 5: 决策树的剪枝
下面是其它一些剪枝技术:
Reduced-Error Pruning(REP,错误率降低剪枝)
Pesimistic-Error Pruning(PEP,悲观错误剪枝)
Cost-Complexity Pruning(CCP,代价复杂度剪枝)
5. CART 算法
分类与回归树(classification and regression tree, CART)模型由 Breiman 等人在 1984 年提出,是应用广泛的决策树学习方法。CART 同样由特征选择、数的生成和剪枝组成,即可用于分类(预测类别)也可用于回归(预测数值,如温度)。
CART 算法总是使用二叉决策树(ID3 决策树,CHAID决策树 等没有限制使用二叉树),内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征(如果特征有多个选项,也要把它二分,比如特征有 3 个选项“青年/中年/老年”,则我们可找到 3 个“二值切分点”,把它二分为“青年/非青年”或者“中年/非中年”或者“老年/非老年”)。
CART 算法由以下两步组成:
(1) 决策树生成:基于训练数据生成决策树,生成的决策树要尽量大;
(2) 决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
5.1. CART 生成
决策树的生成就是递归地构建二叉决策树的过程。CART 算法即可用于“分类”也可用于“回归”。对于回归树,CART 算法采用“平方误差最小化”准则,生成的树也称为“最小二乘回归树”,这里不介绍,可参考:《统计学习方法,李航著》5.5.1 节。
我们重点介绍 CART 算法生成分类树的过程。 CART 分类树用“基尼指数”选择最优特征,同时决定该特征的最优二值切分点。
5.1.1. 基尼指数(Gini Index)
分类问题中,假设有 \(K\) 个类,样本点属于第 \(k\) 类的概率为 \(p_{k}\) ,则概率分布的基尼指数定义为:
\[Gini(p)=\sum_{k=1}^{K}p_{k}(1-p_{k})=1-\sum_{k=1}^{K}p_{k}^2\]
对于给定的样本集合 \(D\) ,其基尼指数为:
\[Gini(D)=1-\sum_{k=1}^{K} \left( \frac{|C_{k}|}{|D|} \right)^2\]
上式中, \(C_{k}\) 是 \(D\) 中属于第 \(k\) 类的样本子集, \(K\) 是类的个数。
如果样本集合 \(D\) 根据特征 \(A\) 是否取某一可能值 \(a\) 被分割为 \(D_{1}\) 和 \(D_{2}\) 两部分,即:
\[D_{1}=\{(x,y) \in D \, | \,A(x)=a\} ,\quad D_{2}= D-D_{1}\]
则在特征 \(A\) 的条件下,集合 \(D\) 的基尼指数定义为:
\[Gini(D,A)=\frac{|D_{1}|}{|D|}Gini(D_{1})+\frac{|D_{2}|}{|D|}Gini(D_{2})\]
基尼指数 \(Gini(D)\) 表示集合 \(D\) 的不确定性,基尼指数 \(Gini(D,A)\) 表示经 \(A=a\) 分割后集合 \(D\) 的不确定性。 基尼指数越大,样本集合的不确定性也就越大,这一点和熵相似。
对于二类分类(伯努利分布)问题,记样本点属于第 1 个类的概率是 \(p\) ,则伯努利分布的基尼指数为 \(Gini(p)=2p(1-p)\) 。图 6 显示了二类分类问题中基尼指数和熵(单位为比特)之半 \(\frac{1}{2}H(p)\) 的关系。可以看出基尼指数和熵之半的曲线很接近。
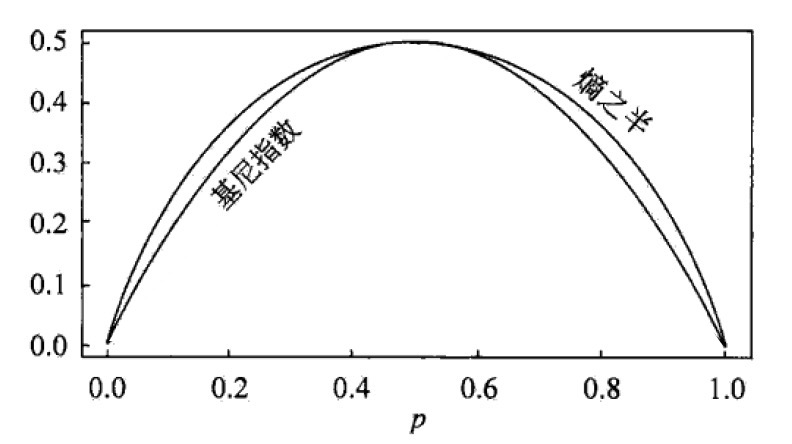
Figure 6: 二类分类中基尼指数和熵之半的关系
5.1.2. CART 决策树生成算法及实例
CART 决策树生成算法如下:
输入:训练数据集 \(D\) ,停止计算的条件。
输出:CART 决策树。
根据训练数据集,从根结点开始,递归地对每个结点进行以下操作,构建二叉决策树:
(1) 设结点的训练数据集为 \(D\) ,计算现有特征对该数据集的基尼指数。此时,对每一特征 \(A\) ,对其可能取的每个值 \(a\) ,根据样本点对 \(A=a\) 的测试为“是”或“否”分割为 \(D_{1}\) 和 \(D_{2}\) 两部分,计算 \(A=a\) 时的基尼指数。
(2) 在所有可能的特征 \(A\) 以及他们所有可能的切分点 \(a\) 中,选择基尼系数最小的特征及其对应的切分点作为最优特征与最优切分点。依最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
(3) 对两个子结点递归地调用(1),(2),直至满足停止条件。
(4) 生成 CART 决策树。
算法停止计算的条件是结点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值(样本基本属于同一类),或者没有更多特征。
实例:根据表 2 (它和表 1 相同,为查看方便复制在此)所给的训练数据集,应用 CART 算法生成决策树。
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
解:首先计算各特征的基尼指数,选择最优特征以及最优切分点。分别以 \(A_1,A_2,A_3,A_4\) 表示“年龄”、“有工作”、“有自己的房子”和“信贷情况”4 个特征,并以 1,2,3 表示年龄的值为青年、中年和老年,以 1,2 表示有工作和有自己的房子的值是和否,以 1,2,3 表示信贷情况的值为非常好、好和一般。
求特征 \(A_1\) 的基尼指数:
\[\begin{aligned} Gini(D, A_1=1) & = \frac{5}{15} \left( 2 \times \frac{2}{5} \times \left(1 - \frac{2}{5} \right) \right) + \frac{10}{15} \left( 2 \times \frac{7}{10} \times \left(1 - \frac{7}{10} \right) \right) = 0.44 \\
Gini(D, A_1=2) & = 0.48 \\
Gini(D, A_1=3) & = 0.44
\end{aligned}\]
由于 \(Gini(D,A_1=1)\) 和 \(Gini(D,A_1=3)\) 相等,且最小,所以 \(A_1=1\) 和 \(A_1=3\) 都可以选作 \(A_1\) 的最优切分点。
类似地,求特征 \(A_2\) 和 \(A_3\) 的基尼指数(由于 \(A_2\) 只有两个可能情况, \(Gini(D, A_2=1)\) 和 \(Gini(D, A_2=2)\) 一定会相等,只用求一个即可。同样地,也只用求 \(Gini(D, A_3=1)\) ):
\[\begin{aligned} Gini(D, A_2=1) & = \frac{5}{15} \left( 2 \times \frac{5}{5} \times \left(1 - \frac{5}{5} \right) \right) + \frac{10}{15} \left( 2 \times \frac{4}{10} \times \left(1 - \frac{4}{10} \right) \right) = 0.32 \\
Gini(D, A_3=1) & = 0.27
\end{aligned}\]
由于 \(A_2\) 和 \(A_3\) 只有一个切分点,所以它们就是最优切分点。
求特征 \(A_4\) 的基尼指数:
\[\begin{aligned} Gini(D, A_4=1) & = 0.36 \\
Gini(D, A_4=2) & = 0.47 \\
Gini(D, A_4=3) & = 0.32
\end{aligned}\]
\(Gini(D, A_4=3)\) 最小,所以 \(A_4=3\) 为 \(A_4\) 的最优切分点。
经过上面一轮的计算,我们知道在 \(A_1,A_2,A_3,A_4\) 几个特征中, \(Gini(D, A_3=1)=0.27\) 最小,所以选择特征 \(A_3\) 为最优特征, \(A_3=1\) 为其最优切分点。于是根结点生成两个子结点,一个是叶结点(因为 \(A_3=1\) 的所有样本恰好属于同一类)。对另一个结点继续使用以上方法在 \(A_1,A_2,A_4\) 中选择最优特征及其最优切分点,结果是 \(A_2=1\) (过程略)。依此计算得知,所得结点都是叶结点。
对于本问题,按照 CART 算法所生成的决策树与按照 ID3 算法所生成的决策树完全一致。
5.2. CART 剪枝
CART 剪枝算法可参考:《统计学习方法,李航著》5.5.2 节,这里不介绍。
6. 决策树的优缺点
决策树优点:
(1) 决策树算法中学习简单的决策规则建立决策树模型的过程非常容易理解,决策树模型可以可视化,非常直观。
(2) 应用范围广,可用于分类和回归,而且非常容易做多类别的分类。
决策树缺点:
(1) 很容易在训练数据中生成复杂的树结构,造成过拟合。剪枝可以缓解过拟合的负作用,常用方法是限制树的高度、叶子结点中的最少样本数量。
(2) 学习一棵最优的决策树被认为是NP-Complete问题。实际中的决策树是基于启发式的贪心算法建立的,这种算法不能保证建立全局最优的决策树。