Linear Algebra and Matrix
Table of Contents
- 1. 矩阵简介
- 2. 方阵的行列式(Determinant)
- 3. 伴随矩阵(Adjoint matrix)
- 4. 逆矩阵
- 5. 矩阵的初等变换(Elementary Transformation)和秩(Rank)
- 6. 方阵的 LU 分解和 Cholesky 分解
- 7. 特征值(Eigenvalue)和特征向量(Eigenvector)
- 8. 向量基本概念
- 9. 向量空间(线性空间)和线性变换
- 10. 正交矩阵(Orthogonal matrix)
- 11. 正定矩阵(Positive-definite matrix)
- 12. 雅可比矩阵(Jacobian Matrix)
1. 矩阵简介
本文主要参考:《工程数学线性代数(第五版),同济大学数学系编》
1.1. 矩阵定义和记法
由 \(m \times n\) 个数 \(a_{ij} (i=1,2, \cdots, m; j=1,2, \cdots, n)\) 排成的 \(m\) 行 \(n\) 列的数表,称为 \(m \times n\) 矩阵(Matrix)。矩阵一般用中括号或者大括号括起来,并可用大写黑体字母表示,记法如下:
\[\mathbf{A} =
\left( \begin{array}{cccc}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{m1} & a_{m2} & \cdots & a_{mn}
\end{array} \right)\]
上面矩阵也可简记为: \((a_{ij})\)
如果两个矩阵的行数相等、列数也相等,则称它们为 同型矩阵 。
行数和列数都为 \(n\) 的矩阵称为 \(n\) 阶方阵(Square matrix)。
1.1.1. 单位矩阵(Identity matrix)
如果 \(n\) 阶方阵主对角线上的元素都是 1,其他元素都是 0,则称它为单位矩阵(Identity matrix),常常记作: \(\mathbf{E}\) 或者 \(\mathbf{I}\)
1.1.2. 对角矩阵(Diagonal matrix)
如果一个方阵,不在主对角线上的元素都是 0,那么这个方阵称为对角矩阵(Diagonal matrix),简称对角阵。如:
\[\boldsymbol{\Lambda} =
\left( \begin{array}{cccc}
\lambda_1 & 0 & \cdots & 0 \\
0 & \lambda_2 & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & \lambda_n
\end{array} \right)\]
对角矩阵也记作:
\[\boldsymbol{\Lambda} = \text{diag}(\lambda_1, \lambda_2, \cdots, \lambda_n)\]
1.2. 矩阵和线性变换(Linear transformations)一一对应
首先介绍一下线性变换的概念。 \(n\) 个变量 \(x_1, x_2, \cdots, x_n\) 与 \(m\) 个变量 \(y_1, y_2, \cdots, y_m\) 之间的下面关系式:
\[\begin{cases}
y_1 = a_{11}x_1 + a_{12}x_2 + \cdots + a_{1n}x_n \\
y_2 = a_{21}x_1 + a_{32}x_2 + \cdots + a_{2n}x_n \\
\cdots \\
y_m = a_{m1}x_1 + a_{m2}x_2 + \cdots + a_{mn}x_n
\end{cases}\]
表示从变量 \(x_1, x_2, \cdots, x_n\) 到变量 \(y_1, y_2, \cdots, y_m\) 的一个 线性变换 。线性变换的系数 \(a_{ij}\) 构成矩阵 \(\mathbf{A}=(a_{ij})\) 。
总结: 矩阵和线性变换之间存在一一对应的关系,可以利用矩阵来研究线性变换,也可以利用线性变换来解释矩阵的含义。
1.2.1. 实例:二维矩阵及其线性变换
1.2.1.1. 投影变换
矩阵 \(\left( \begin{array}{cc} 1 & 0 \\ 0 & 0 \end{array} \right)\) 对应的线性变换为: \(\begin{cases} x_1 = x \\ y_1 = 0 \end{cases}\)
可看作是 \(xOy\) 平面上,把向量 \(\overrightarrow{OP} = \left( \begin{array}{c} x \\ y \end{array} \right)\) 变为向量 \(\overrightarrow{OP_1} = \left( \begin{array}{c} x_1 \\ y_1 \end{array} \right) = \left( \begin{array}{c} x \\ 0 \end{array} \right)\) 的变换。即可看作是下图中点 \(P\) 变为点 \(P_1\) 的变换。这显然是一个 投影变换 。
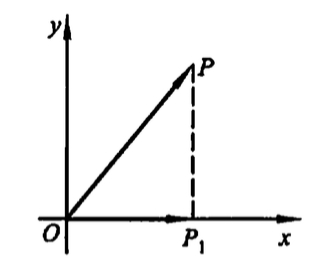
Figure 1: 投影变换
1.2.1.2. 旋转变换
矩阵 \(\left( \begin{array}{cc} \cos{\varphi} & - \sin{\varphi} \\ \sin{\varphi} & \cos{\varphi} \end{array} \right)\) 对应的线性变换为: \(\begin{cases} x_1 = x \cos{\varphi} - y \sin{\varphi} \\ y_1 = x \sin{\varphi} + y \cos{\varphi} \end{cases}\)
把 \(xOy\) 平面上的向量 \(\overrightarrow{OP} = \left( \begin{array}{c} x \\ y \end{array} \right)\) 变为了向量 \(\overrightarrow{OP_1} = \left( \begin{array}{c} x_1 \\ y_1 \end{array} \right)\) 。设 \(\overrightarrow{OP}\) 的长度为 \(r\) ,辐角为 \(\theta\) ,即设 \(x=r\cos{\theta}, y=r\sin{\theta}\) ,那么有:
\[\begin{cases}
x_1 = r ( \cos{\varphi}\cos{\theta} - \sin{\varphi}\sin{\theta}) = r \cos(\varphi + \theta) \\ y_1 = r ( \sin{\varphi}\cos{\theta} + \cos{\varphi}\sin{\theta}) = r \sin({\varphi + \theta}) \end{cases}\]
上式可说明 \(\overrightarrow{OP_1}\) 的长度也为 \(r\) ,而辐角为 \(\varphi + \theta\) 。这显然是如下图所示的 旋转变换 。
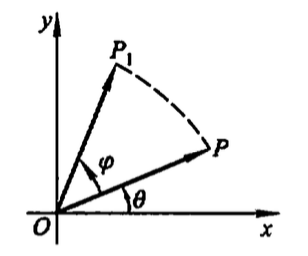
Figure 2: 旋转变换
1.2.1.3. 更多实例
下面实例摘自:2-by-2 matrices with the associated linear maps of R2
其中,蓝色为变换前图形,绿色为变换后图形,中心坐标 (0 0) 用黑点表示。
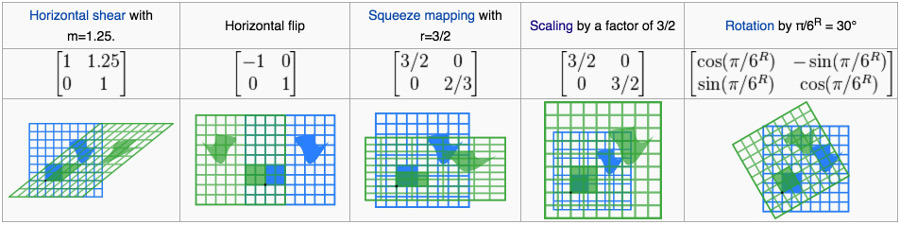
Figure 3: 实例:二维矩阵对应的线性变换
1.3. 矩阵基本运算
1.3.1. 矩阵加法和减法
两个矩阵作加法的结果是两个矩阵中相同位置的元素对应相加组成的矩阵(只有同型矩阵才能进行加减法)。
\[\mathbf{A} + \mathbf{B} =
\left( \begin{array}{cccc}
a_{11} + b_{11} & a_{12} + b_{12} & \cdots & a_{1n} + b_{1n} \\
a_{21} + b_{21} & a_{22} + b_{22} & \cdots & a_{2n} + b_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{m1} + b_{m1} & a_{m2} + b_{m2} & \cdots & a_{mn} + b_{mn}
\end{array} \right)\]
矩阵减法类似。
1.3.2. 数与矩阵相乘
数 \(\lambda\) 与矩阵 \(\mathbf{A}\) 的乘积记为 \(\lambda\mathbf{A}\) 或 \(\mathbf{A}\lambda\) ,有下面规定:
\[\lambda\mathbf{A} = \mathbf{A}\lambda =
\left( \begin{array}{cccc}
\lambda a_{11} & \lambda a_{12} & \cdots & \lambda a_{1n} \\
\lambda a_{21} & \lambda a_{22} & \cdots & \lambda a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
\lambda a_{m1} & \lambda a_{m2} & \cdots & \lambda a_{mn}
\end{array} \right)\]
1.3.3. 矩阵和矩阵相乘
设 \(\mathbf{A} = (a_{ij})\) 是一个 \(m \times s\) 矩阵, \(\mathbf{B} = (b_{ij})\) 是一个 \(s \times n\) 矩阵,那么规定矩阵 \(\mathbf{A}\) 和矩阵 \(\mathbf{B}\) 的乘积是一个 \(m \times n\) 矩阵 \(C=(c_{ij})\) ,\(c_{ij}\) 是 \(\mathbf{A}\) 的第 \(i\) 行与 \(\mathbf{B}\) 的第 \(j\) 列的乘积,即有:
\[c_{ij} = a_{i1}b_{1j} + a_{i2}b_{2j} + \cdots + a_{is}b_{sj} = \sum_{k=1}^{s} a_{ik}b_{kj}\]
记作 \(\mathbf{C} = \mathbf{AB}\) 。
注:只有第一个矩阵(左矩阵)的列数等于第二个矩阵(右矩阵)的行数时,两个矩阵才能相乘。
矩阵乘法实例:已知
\[\mathbf{A} = \left( \begin{array}{cccc}
1 & 0 & 3 & -1 \\
2 & 1 & 0 & 2
\end{array} \right), \quad \mathbf{B} =
\left( \begin{array}{ccc}
4 & 1 & 0 \\
-1 & 1 & 3 \\
2 & 0 & 1 \\
1 & 3 & 4
\end{array} \right)
\]
则矩阵 \(\mathbf{A}\) 和 \(\mathbf{B}\) 的乘积 \(\mathbf{AB}\) 为:
\[\begin{aligned}
\mathbf{AB} & =
\left( \begin{array}{cccc}
1 & 0 & 3 & -1 \\
2 & 1 & 0 & 2
\end{array} \right) \left( \begin{array}{ccc}
4 & 1 & 0 \\
-1 & 1 & 3 \\
2 & 0 & 1 \\
1 & 3 & 4
\end{array} \right) \\
& =
\left( \begin{array}{ccc}
1 \times 4 + 0 \times (-1) + 3 \times 2 + (-1) \times 1 & 1 \times 1 + 0 \times 1 + 3 \times 0 + (-1) \times 3 & 1 \times 0 + 0 \times 3 + 3 \times 1 + (-1) \times 4 \\
2 \times 4 + 1 \times (-1) + 0 \times 2 + 2 \times 1 & 2 \times 1 + 1 \times 1 + 0 \times 0 + 2 \times 3 & 2 \times 0 + 1 \times 3 + 0 \times 1 + 2 \times 4
\end{array} \right) \\
& =
\left( \begin{array}{ccc}
9 & -2 & -1 \\
9 & 9 & 11
\end{array} \right)
\end{aligned}\]
注:上面例子中,矩阵 \(\mathbf{B}\) 和 \(\mathbf{A}\) 的乘积 \(\mathbf{BA}\) 是不存在的。
1.3.3.1. 矩阵相乘的含义:连续作两个线性变换
设有下面两个线性变换:
\[\begin{cases}
y_1 = a_{11}x_1 + a_{12}x_2 + a_{13}x_3 \\
y_2 = a_{21}x_1 + a_{32}x_2 + a_{23}x_3
\end{cases}\]
\[\begin{cases}
x_1 = b_{11}t_1 + b_{12}t_2 \\
x_2 = b_{21}t_1 + b_{22}t_2 \\
x_3 = b_{31}t_1 + b_{32}t_2
\end{cases}\]
怎么求从 \(t_1, t_2\) 到 \(y_1, y_2\) 的线性变换呢?将上面的第二式代入到第一式中( 即先作第二个线性变换再作第一个线性变换 )可得到:
\[\begin{cases}
y_1 = (a_{11}b_{11} + a_{12}b_{21} + a_{13}b_{31}) t_1 + (a_{11}b_{12} + a_{12}b_{22} + a_{13}b_{32}) t_2 \\
y_2 = (a_{21}b_{11} + a_{22}b_{21} + a_{23}b_{31}) t_1 + (a_{21}b_{12} + a_{22}b_{22} + a_{23}b_{32}) t_2
\end{cases}\]
而我们知道:
\[\left( \begin{array}{ccc}
a_{11} & a_{12} & a_{13} \\
a_{21} & a_{22} & a_{23}
\end{array} \right) \left( \begin{array}{cc}
b_{11} & b_{12} \\
b_{21} & b_{22} \\
b_{31} & b_{32}
\end{array} \right) = \left( \begin{array}{cc}
a_{11}b_{11} + a_{12}b_{21} + a_{13}b_{31} & a_{11}b_{12} + a_{12}b_{22} + a_{13}b_{32} \\
a_{21}b_{11} + a_{22}b_{21} + a_{23}b_{31} & a_{21}b_{12} + a_{22}b_{22} + a_{23}b_{32}
\end{array} \right)\]
所以矩阵乘积 \(\mathbf{AB}\) 相当于连续作两个线性变换:先作 \(\mathbf{B}\) 对应的线性变换,再作 \(\mathbf{A}\) 对应的线性变换。
1.3.4. 矩阵的转置(Transposition)
把矩阵 \(\mathbf{A}\) 的行换成同序数的列得到一个新矩阵,称为 \(\mathbf{A}\) 的转置矩阵,记为 \(\mathbf{A}^{\mathsf{T}}\) 。例如矩阵:
\[\mathbf{A} =
\left( \begin{array}{ccc}
1 & 2 & 0 \\
3 & -1 & 1 \\
\end{array} \right)\]
的转置矩阵为:
\[\mathbf{A}^{\mathsf{T}} =
\left( \begin{array}{cc}
1 & 3 \\
2 & -1 \\
0 & 1
\end{array} \right)\]
矩阵的转置有下面运算规律:
- \((\mathbf{A}^{\mathsf{T}})^{\mathsf{T}} = \mathbf{A}\)
- \((\mathbf{A} + \mathbf{B})^{\mathsf{T}} = \mathbf{A}^{\mathsf{T}} + \mathbf{B}^{\mathsf{T}}\)
- \((\lambda \mathbf{A} )^{\mathsf{T}} = \lambda \mathbf{A}^{\mathsf{T}}\)
- \((\mathbf{A} \mathbf{B})^{\mathsf{T}} = \mathbf{B}^{\mathsf{T}} \mathbf{A}^{\mathsf{T}}\)
1.3.5. 对称矩阵(Symmetric matrix)
设 \(\mathbf{A}\) 为 \(n\) 阶方阵,如果满足 \(\mathbf{A}^{\mathsf{T}} = \mathbf{A}\) ,则称 \(\mathbf{A}\) 为对称矩阵(Symmetric matrix),简称对称阵。
如下面 \(3 \times 3\) 矩阵是对称矩阵:
\[\left( \begin{array}{ccc} 1 & 7 & 3 \\ 7 & 4 & 5 \\ 3 & -5 & 6 \end{array} \right)\]
1.3.5.1. 对称矩阵一定能对角化
对于方阵 \(\mathbf{A}\) ,如果存在一个可逆矩阵 \(\mathbf{P}\) 使得 \(\mathbf{P}^{-1}\mathbf{A}\mathbf{P}\) 是对角矩阵,则就称方阵 \(\mathbf{A}\) 是 可对角化的 。
定理:设 \(\mathbf{A}\) 为 \(n\) 阶对称矩阵,则必有正交矩阵 \(\mathbf{P}\) ,使 \(\mathbf{P}^{-1}\mathbf{A}\mathbf{P} = \mathbf{P}^{\mathsf{T}}\mathbf{A}\mathbf{P} = \Lambda\) ,其中 \(\Lambda\) 是以 \(\mathbf{A}\) 的 \(n\) 个特征值为对角元的对角矩阵。
说明 1:这个定理的证明略。矩阵的特征值、正交矩阵等概念在后文有介绍。
说明 2:对称矩阵对角化的具体步骤略,可以参考:《工程数学线性代数(第五版),同济大学数学系编》 5.4 节 对称矩阵的对角化
如,对称矩阵 \(\mathbf{A} = \left( \begin{array}{ccc} 0 & -1 & 1 \\ -1 & 0 & 1 \\ 1 & 1 & 0 \end{array} \right)\) 可以对角化为:
\[\mathbf{P}^{-1}\mathbf{A}\mathbf{P} = \mathbf{P}^{\mathsf{T}}\mathbf{A}\mathbf{P} = \Lambda = \left( \begin{array}{ccc} -2 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right)\]
其中, \(\mathbf{P} = \left( \begin{array}{ccc} -\frac{1}{\sqrt{3}} & -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{6}} \\ -\frac{1}{\sqrt{3}} & \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{6}} \\ \frac{1}{\sqrt{3}} & 0 & \frac{2}{\sqrt{6}} \end{array} \right)\)
1.3.5.2. 对称矩阵优良性质——求幂简单
由上节内容知,对称矩阵一定能对角化。设 \(\mathbf{A}\) 为对称矩阵,则有 \(\mathbf{P}^{-1}\mathbf{A}\mathbf{P} = \Lambda\) ,于是 \(\mathbf{A} = \mathbf{P} \Lambda \mathbf{P}^{-1}\) ,从而 \(\mathbf{A}^{n} = \mathbf{P} \Lambda \mathbf{P}^{-1}\)
2. 方阵的行列式(Determinant)
下面先介绍行列式(Determinant)的基础知识。
二阶行列式的定义为:
\[\left| \begin{array}{cc}
a_{11} & a_{12} \\
a_{21} & a_{22} \end{array} \right| = a_{11}a_{22} - a_{12}a_{21}\]
三阶行列式的定义为:
\[\left| \begin{array}{ccc}
a_{11} & a_{12} & a_{13} \\
a_{21} & a_{22} & a_{23} \\
a_{31} & a_{32} & a_{33} \end{array} \right|
= a_{11}a_{22}a_{33} + a_{12}a_{23}a_{31} + a_{13}a_{21}a_{32} - a_{11}a_{23}a_{32} - a_{12}a_{21}a_{33} + a_{13}a_{22}a_{31}\]
上面的定义有一种形象的记忆方法,如下所示:

Figure 4: Sarrus' rule (a mnemonic for the 3 × 3 matrix determinant)
依此类推,可得到 \(n\) 阶行列式的定义。
由 \(n\) 阶方阵 \(\mathbf{A}\) 的元素所构成的 \(n\) 阶行列式(各元素位置不变),称为方阵 \(\mathbf{A}\) 的行列式,记作 \(|\mathbf{A}|\) 或者 \(\det{\mathbf{A}}\) 。
2.1. 拉普拉斯展开式(行列式按行或列展开)
介绍拉普拉斯展式前,先介绍“余子式”和“代数余子式”的概念。
在 \(n\) 阶行列式中,把 \((i,j)\) 元 \(a_{ij}\) 所在和第 \(i\) 行和第 \(j\) 列划去后,留下的 \(n-1\) 阶行列式叫做 \((i,j)\) 元 \(a_{ij}\) 的余子式,记作 \(M_{ij}\) 。而 \((i,j)\) 元 \(a_{ij}\) 的 代数余子式(Cofactor) 记作 \(A_{ij}\) ,其定义为:
\[A_{ij} = (-1)^{i+j} M_{ij}\]
拉普拉斯展开(Laplace expansion)定理:行列式等于它的任一行(或列)的各元素与其对应的代数余子式乘积之和。
拉普拉斯展开式实例:
\[\left| \begin{array}{ccc}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9 \end{array} \right| = 1 \times \left| \begin{array}{cc}
5 & 6 \\
8 & 9 \end{array} \right| - 2 \times \left| \begin{array}{cc}
4 & 6 \\
7 & 9 \end{array} \right| + 3 \times \left| \begin{array}{cc}
4 & 5 \\
7 & 8 \end{array} \right| = 1 \times (-3) - 2 \times (-6) + 3 \times (-3) = 0\]
当然,还可以按其它行(或列)进行展开,其结果是相同的。
2.2. 克拉默法则求解线性方程组
如果线性方程组 \(\mathbf{A} \boldsymbol{x} = \boldsymbol{b}\) 的系数行列式 \(\det(\mathbf{A})\) 不等于零,那么线性方程组 \(\mathbf{A} \boldsymbol{x} = \boldsymbol{b}\) 有唯一解 \(\boldsymbol{x}_{i} = \frac{\det(\mathbf{A}_{i})}{\det(\mathbf{A})}\) ,其中 \(\det(\mathbf{A}_{i})\) 是把系数行列式 \(\det(\mathbf{A})\) 中的第 \(i\) 列的元素用列向量 \(\boldsymbol{b}\) 代替后所得到的 \(n\) 阶行列式。这就是克拉默法则(Cramer's rule)。
克拉默法则实例:求解下面线性方程组:
\[\begin{cases}
x + 3y - 2z = 5 \\
3x + 5y + 6z = 7 \\
2x + 4y + 3z = 8
\end{cases}\]
直接应用克拉默法则,可得:
\[x = \frac{\left| \begin{array}{ccc}
5 & 3 & -2 \\
7 & 5 & 6 \\
8 & 4 & 3 \end{array} \right|}{\left| \begin{array}{ccc}
1 & 3 & -2 \\
3 & 5 & 6 \\
2 & 4 & 3 \end{array} \right|}, \quad y = \frac{\left| \begin{array}{ccc}
1 & 5 & -2 \\
3 & 7 & 6 \\
2 & 8 & 3 \end{array} \right|}{\left| \begin{array}{ccc}
1 & 3 & -2 \\
3 & 5 & 6 \\
2 & 4 & 3 \end{array} \right|}, \quad z = \frac{\left| \begin{array}{ccc}
1 & 3 & 5 \\
3 & 5 & 7 \\
2 & 4 & 8 \end{array} \right|}{\left| \begin{array}{ccc}
1 & 3 & -2 \\
3 & 5 & 6 \\
2 & 4 & 3 \end{array} \right|}\]
参考:https://en.wikipedia.org/wiki/System_of_linear_equations#Cramer.27s_rule
3. 伴随矩阵(Adjoint matrix)
行列式 \(\det(\mathbf{A})\) 的各个元素的代数余子式 \(A_{ij}\) 所构成的如下矩阵:
\[\text{adj}(\mathbf{A}) = \left( \begin{array}{cccc}
A_{11} & A_{21} & \cdots & A_{n1} \\
A_{12} & A_{22} & \cdots & A_{n2} \\
\vdots & \vdots & & \vdots \\
A_{1n} & A_{2n} & \cdots & A_{nn} \end{array} \right)\]
称为矩阵(方阵) \(\mathbf{A}\) 的伴随矩阵(Adjoint matrix),记作 \(\text{adj}(\mathbf{A})\) 。
伴随矩阵有下面性质:
\[\mathbf{A} \text{adj}(\mathbf{A}) = \text{adj}(\mathbf{A}) \mathbf{A}\ = \det(A) \mathbf{E}\]
其证明过程可参考:《工程数学线性代数(第五版),同济大学数学系编》2.2 节(矩阵的运算)。
4. 逆矩阵
逆矩阵定义:对于 \(n\) 阶方阵 \(\mathbf{A}\) ,如果有一个 \(n\) 阶方阵 \(\mathbf{B}\) ,使得:
\[\mathbf{AB} = \mathbf{BA} = \mathbf{E}\]
则说矩阵(方阵) \(\mathbf{A}\) 可逆,且称矩阵 \(\mathbf{B}\) 为 \(\mathbf{A}\) 的 逆矩阵 。矩阵 \(\mathbf{A}\) 的逆矩阵记作 \(\mathbf{A}^{-1}\) 。
如果矩阵 \(\mathbf{A}\) 可逆,则它的逆矩阵为(由伴随矩阵的性质可证明):
\[\mathbf{A}^{-1} = \frac{1}{\det(\mathbf{A})} \text{adj}(\mathbf{A})\]
容易得到: 矩阵 \(\mathbf{A}\) 可逆的充分必要条件是 \(\det(\mathbf{A}) \ne 0\)
4.1. 逆矩阵相当于线性变换的逆变换
设从 \(\mathbf{X}\) 到 \(\mathbf{Y}\) 有线性变换:
\[\mathbf{Y} = \mathbf{AX}\]
如果 \(\det(\mathbf{A}) \ne 0\) ,则有:
\[\mathbf{X} = \mathbf{A}^{-1} \mathbf{Y}\]
上式表示从 \(\mathbf{Y}\) 到 \(\mathbf{X}\) 的线性变换。所以逆矩阵相当于线性变换的逆变换。
4.2. 实例:求逆矩阵
已知 \(\det(\mathbf{A}) \ne 0\) ,求二阶矩阵 \(\mathbf{A} = \left( \begin{array}{cc} a & b \\ c & d \end{array} \right)\) 的逆矩阵。
求解过程: \(\det(\mathbf{A}) = ad - bc\) , \(\text{adj}(\mathbf{A}) = \left( \begin{array}{cc} d & -b \\ -c & a \end{array} \right)\) ,所以 \[\mathbf{A}^{-1} = \frac{1}{\det(\mathbf{A})} \text{adj}(\mathbf{A}) = \frac{1}{ad - bc} \left( \begin{array}{cc} d & -b \\ -c & a \end{array} \right)\]
4.3. 奇异方阵(Singular Matrix)和非奇异方阵(Nonsingular Matrix)
如果 \(\det(\mathbf{A}) = 0\) ,则称方阵 \(\mathbf{A}\) 为奇异方阵,否则是非奇异方阵。
4.3.1. 可逆方阵就是非奇异方阵(Nonsingular Matrix)
前面介绍过: 矩阵 \(\mathbf{A}\) 可逆的充分必要条件是 \(\det(\mathbf{A}) \ne 0\) ,所以可逆方阵就是非奇异方阵(Nonsingular Matrix)。
4.4. 逆矩阵 vs 伴随矩阵
所有矩阵(包括不可逆矩阵)都存在伴随矩阵。如果矩阵可逆,那么它的逆矩阵和伴随矩阵之间只差一个系数 \(\frac{1}{\det(\mathbf{A})}\) 。
5. 矩阵的初等变换(Elementary Transformation)和秩(Rank)
下面三种变换称为矩阵的初等行变换(Elementary Row Operations):
- 对调两行(对调 \(i,j\) 两行,记作 \(r_i \leftrightarrow r_j\) );
- 以数 \(k \ne 0\) 乘某一行中的所有元素(第 \(i\) 行乘 \(k\) ,记作 \(r_i \times k\) );
- 把某一行所有元素的 \(k\) 倍加到另一行对应的元素上去(第 \(j\) 行的 \(k\) 倍加到第 \(i\) 行上,记作 \(r_i + kr_j\) )。
相应的,把上面定义中的“行”换成“列”,即得到矩阵的初等列变换。初等行变换和初等列变换统称为 初等变换(Elementary Transformation) 。
5.1. 等价矩阵(Equivalent Matrix)
如果矩阵 \(\mathbf{A}\) 经过有限次初等变换可变成矩阵 \(\mathbf{B}\) ,就称矩阵 \(\mathbf{A}\) 和 \(\mathbf{B}\) 为等价矩阵(Equivalent Matrix),记作: \(\mathbf{A} \sim \mathbf{B}\) 。
5.2. 矩阵的秩(Rank)
对于 \(m \times n\) 矩阵 \(\mathbf{A}\) ,总可以经过初等变换把它化为下面形式(称为标准型,其特点是左上角是一个单位矩阵,其余元素都为 0):
\[\mathbf{F} = \left( \begin{array}{cc} \mathbf{E}_r & \mathbf{O} \\
\mathbf{O} & \mathbf{O} \end{array} \right)_{m \times n}\]
其中的数 \(r\) 称为矩阵 \(\mathbf{A}\) 的秩(Rank),记作 \(\text{Rank}(\mathbf{A})\) 。显然, “等价矩阵”和“秩相等矩阵”含义相同 。
例如,下面矩阵 \(\mathbf{A}\) 经过初等变换 \(c_3 \leftrightarrow c_4, c_4 + c_1 + c_2, c_5 - 4c_1 - 3c_2 + 3c_3\) 后可变成标准型矩阵 \(\mathbf{F}\) :
\[\mathbf{A} = \left( \begin{array}{ccccc} 1 & 0 & -1 & 0 & 4 \\
0 & 1 & -1 & 0 & 3 \\
0 & 0 & 0 & 1 & -3 \\
0 & 0 & 0 & 0 & 0 \end{array} \right) \sim \left( \begin{array}{ccccc} 1 & 0 & 0 & 0 & 0 \\
0 & 1 & 0 & 0 & 0 \\
0 & 0 & 1 & 0 & 0 \\
0 & 0 & 0 & 0 & 0 \end{array} \right) = \mathbf{F}\]
可知上面矩阵 \(\mathbf{A}\) 的秩为 3。
5.2.1. 用秩描述线性方程组是否有解
设有 \(n\) 个未知数, \(m\) 个方程的线性方程组:
\[\begin{cases}
a_{11}x_1 + a_{12}x_2 + \cdots + a_{1n}x_n = b_1 \\
a_{21}x_1 + a_{32}x_2 + \cdots + a_{2n}x_n = b_2 \\
\cdots \\
a_{m1}x_1 + a_{m2}x_2 + \cdots + a_{mn}x_n = b_m
\end{cases}\]
上式也可以记为 \(n\) 元线性方程组: \(\mathbf{A} \boldsymbol{x} = \boldsymbol{b}\)
它无解的充分必要条件是: \(\text{Rank}(\mathbf{A}) < \text{Rank}(\mathbf{A}, \boldsymbol{b})\)
它有唯一解的充分必要条件是: \(\text{Rank}(\mathbf{A}) = \text{Rank}(\mathbf{A}, \boldsymbol{b}) = n\)
它有无限多个解的充分必要条件是: \(\text{Rank}(\mathbf{A}) = \text{Rank}(\mathbf{A}, \boldsymbol{b}) < n\)
其证明过程可参考:《工程数学线性代数(第五版),同济大学数学系编》3.3 节(线性方程组的解)。
6. 方阵的 LU 分解和 Cholesky 分解
6.1. 方阵的 LU 分解
方阵的 LU 分解(LU decomposition)就是把它分解为一个下三角矩阵和一个上三角矩阵的乘积。 设 \(\mathbf{A}\) 是一个方块矩阵。 \(\mathbf{A}\) 的 LU 分解('LU' stands for 'Lower Upper')是将它分解成如下形式:
\[\mathbf{A} = \mathbf{L}\mathbf{U}\]
其中 \(\mathbf{L}\) 和 \(\mathbf{U}\) 分别是下三角矩阵和上三角矩阵。
方阵 \(\mathbf{A}\) 可以进行 LU 分解的充要条件是:方阵 \(\mathbf{A}\) 的各阶顺序主子式均不为零。
下面是对方阵 \(\mathbf{A}\) 进行 LU 分解的实例:
\[\underbrace{\left( \begin{array}{ccc} 1 & 2 & 3 \\ 2 & 5 & 7 \\ 3 & 5 & 3 \end{array} \right)}_{\mathbf{A}} = \underbrace{\left( \begin{array}{ccc} 1 & 0 & 0 \\ 2 & 1 & 0 \\ 3 & -1 & 1 \end{array} \right)}_{\mathbf{L}} \underbrace{\left( \begin{array}{ccc} 1 & 2 & 3 \\ 0 & 1 & 1 \\ 0 & 0 & -5 \end{array} \right)}_{\mathbf{U}}\]
6.2. 埃尔米特矩阵的 Cholesky 分解
6.2.1. 共轭转置矩阵
方阵 \(\mathbf{A}\) 的共轭转置(Conjugate transpose)矩阵:先对方阵 \(\mathbf{A}\) 中每个元素求共轭运算(实部不变,虚部变为相反数),再对矩阵求转置得到的矩阵。 方阵 \(\mathbf{A}\) 的共轭转置矩阵一般记为 \(\mathbf{A}^{*}\) 。
设有矩阵:
\[\mathbf{A} = \left( \begin{array}{cc} 1 & -2-i \\ 1+i & i \end{array} \right)\]
那么 \(\mathbf{A}\) 的共轭转置矩阵 \(\mathbf{A}^{*}\) 为:
\[\mathbf{A}^{*} = \left( \begin{array}{cc} 1 & 1-i \\ -2+i & -i \end{array} \right)\]
6.2.2. 埃尔米特矩阵及其 Cholesky 分解
一个复数方阵,如果它和其共轭转置矩阵相同,那么这个复数方阵就称为埃尔米特矩阵(Hermitian Matrix)或者自伴随矩阵(Self-adjoint matrix)。
例如,下面矩阵是埃尔米特矩阵(容易验证 \(\mathbf{A}\) 和其共轭转置矩阵 \(\mathbf{A}^{*}\) 相同):
\[\mathbf{A} = \left( \begin{array}{ccc} 2 & 2+i & 4 \\ 2-i & 3 & i \\ 4 & -i & 1 \end{array} \right)\]
显然, 实数对称矩阵都是埃尔米特矩阵。
方阵 \(\mathbf{A}\) 的 Cholesky 分解(Cholesky decomposition)就是把它分解为一个下三角矩阵 \(\mathbf{L}\) 和它的共轭转置 \(\mathbf{L}^{*}\) 的乘积。
如果方阵 \(\mathbf{A}\) 是埃尔米特矩阵,且为正定矩阵,则 \(\mathbf{A}\) 存在 Cholesky 分解,且分解是唯一的。
下面是对方阵 \(\mathbf{A}\) 进行 Cholesky 分解的实例:
\[\underbrace{\left( \begin{array}{ccc} 4 & 12 & -16 \\ 12 & 37 & -43 \\ -16 & -43 & 98 \end{array} \right)}_{\mathbf{A}} = \underbrace{\left( \begin{array}{ccc} 2 & 0 & 0 \\ 6 & 1 & 0 \\ -8 & 5 & 3 \end{array} \right)}_{\mathbf{L}} \underbrace{\left( \begin{array}{ccc} 2 & 6 & -8 \\ 0 & 1 & 5 \\ 0 & 0 & 3 \end{array} \right)}_{\mathbf{L}^{*}}\]
7. 特征值(Eigenvalue)和特征向量(Eigenvector)
设 \(\mathbf{A}\) 是 \(n\) 阶矩阵(方阵),如果数 \(\lambda\) 和 \(n\) 维非零列向量 \(\boldsymbol{x}\) 使关系式
\[\mathbf{A} \boldsymbol{x} = \lambda \boldsymbol{x}\]
成立,那么数 \(\lambda\) 称为矩阵 \(\mathbf{A}\) 的 特征值(Eigenvalue) ,非零向量 \(\boldsymbol{x}\) 称为 \(\mathbf{A}\) 对应于特征值 \(\lambda\) 的 特征向量(Eigenvector) 。
7.1. 特征多项式(Characteristic polynomial)和特征方程(Characteristic equation)
定义矩阵特征值时采用的关系式 \(\mathbf{A} \boldsymbol{x} = \lambda \boldsymbol{x}\) 也可以写为:
\[(\mathbf{A} - \lambda \mathbf{E}) \boldsymbol{x} = \boldsymbol{0}\]
这是 \(n\) 个未知数 \(n\) 个方程的齐次线性方程组(Homogeneous Linear Equations),它有非零解的充分必要条件是系数行列式为 0,即:
\[|\mathbf{A} - \lambda \mathbf{E}| = 0\]
也即:
\[\left| \begin{array}{cccc}
a_{11} - \lambda & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} - \lambda & \cdots & a_{2n} \\
\vdots & \vdots & & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn} - \lambda \end{array} \right| = 0\]
上式是以 \(\lambda\) 为未知数的一元 \(n\) 次方程,称为矩阵 \(\mathbf{A}\) 的特征方程(Characteristic polynomial),其左端的 \(|\mathbf{A} - \lambda \mathbf{E}| = 0\) 是 \(\lambda\) 的 \(n\) 次多项多,称为矩阵 \(\mathbf{A}\) 的特征多项式(Characteristic equation)。
特征方程在复数范围内恒有解。
7.2. 实例:求特征值和特征向量
求矩阵 \(\mathbf{A} = \left( \begin{array}{cc} 3 & -1 \\ -1 & 3 \end{array} \right)\) 的特征值和特征向量。
求解步骤如下:
由矩阵 \(\mathbf{A}\) 的特征方程 \(\left| \mathbf{A} - \lambda \mathbf{E} \right| = \left| \begin{array}{cc}
3 - \lambda & -1 \\
-1 & 3 - \lambda \end{array} \right| = 0\) ,可求得 \(\mathbf{A}\) 的两个特征值为 \(\lambda_1 = 2, \lambda_2 = 4\)
当 \(\lambda_1 = 2\) 时,对应的特征向量满足: \(\left( \begin{array}{cc} 3-2 & -1 \\ -1 & 3-2 \end{array} \right) \left( \begin{array}{c} x_1 \\ x_2 \end{array} \right) = \left( \begin{array}{c} 0 \\ 0 \end{array} \right)\) ,可解得 \(x_1 = x_2\) ,所以对应的特征向量可取为:
\[\boldsymbol{p}_1 = \left( \begin{array}{c} 1 \\ 1 \end{array} \right)\]
当 \(\lambda_2 = 4\) 时,可都求得 \(x_1 = -x_2\) ,所以对应的特征向量可取为:
\[\boldsymbol{p}_2 = \left( \begin{array}{c} -1 \\ 1 \end{array} \right)\]
注:若 \(\boldsymbol{p}_i\) 是矩阵 \(\mathbf{A}\) 的对应于特征值 \(\lambda_{i}\) 的特征向量,则 \(k \boldsymbol{p}_i (k \ne 0)\) 也是对应于特征值 \(\lambda_{i}\) 的特征向量。
7.3. 特征值性质
7.3.1. 特征值之和等于主对角线元素和
设 \(n\) 阶矩阵 \(\mathbf{A} = (a_{ij})\) 的特征值为 \(\lambda_1, \lambda_2, \cdots, \lambda_n\) ,有:
\[\lambda_1 + \lambda_2 + \cdots + \lambda_n = a_{11} + a_{22} + \cdots + a_{nn}\]
7.3.2. 特征值之积等于矩阵对应行列式
设 \(n\) 阶矩阵 \(\mathbf{A} = (a_{ij})\) 的特征值为 \(\lambda_1, \lambda_2, \cdots, \lambda_n\) ,有:
\[\lambda_1 \lambda_2 \cdots \lambda_n = \det(\mathbf{A})\]
7.4. 求解特征值的高效算法
通过求解特征方程来得到特征值,这种方法的效率太低,当矩阵的阶数比较大时不可行。
一些高效的求特征值算法可参考:https://en.wikipedia.org/wiki/Eigenvalue_algorithm
8. 向量基本概念
\(n\) 个有序的数 \(x_1, x_2, \cdots, x_n\) 所组成的数组称为 \(n\) 维向量。这 \(n\) 个数称为该向量的 \(n\) 个分量,第 \(i\) 个数 \(x_i\) 称为第 \(i\) 个分量。 \(n\) 维向量可写成一行,也可写成一列,分别称为行向量和列向量。
若干个同维数的列向量(或同维数的行向量)所组成的集合叫做向量组。
8.1. 向量组的线性相关性
给定向量组 \(A : \boldsymbol{a_1}, \boldsymbol{a_2}, \cdots, \boldsymbol{a_m}\) ,如果存在不全为零的数 \(k_1, k_2, \cdots, k_m\) ,使:
\[k_1 \boldsymbol{a_1} + k_2 \boldsymbol{a_2} + \cdots + k_m \boldsymbol{a_m} = \boldsymbol{0}\]
则称向量组 \(A\) 是 线性相关 的,否则称它线性无关。
8.2. 向量能否由向量组线性表示
给定向量组 \(A : \boldsymbol{a_1}, \boldsymbol{a_2}, \cdots, \boldsymbol{a_m}\) 和向量 \(\boldsymbol{b}\) ,如果存在一组数 \(\lambda_1, \lambda_2, \cdots, \lambda_m\) ,使:
\[\boldsymbol{b} = \lambda_1 \boldsymbol{a_1} + \lambda_2 \boldsymbol{a_2} + \cdots + \lambda_m \boldsymbol{a_m}\]
则称向量 \(\boldsymbol{b}\) 能由向量组 \(A\) 线性表示 。
8.3. 向量的内积(Inner product)
设有 \(n\) 维向量:
\[\boldsymbol{x} = \left( \begin{array}{c}
x_1 \\
x_2 \\
\vdots \\
x_n
\end{array} \right), \boldsymbol{y} = \left( \begin{array}{c}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{array} \right)\]
向量 \(\boldsymbol{x}\) 和 \(\boldsymbol{y}\) 的 内积(Inner product) 记为 \(\langle \boldsymbol{x} ,\boldsymbol{y} \rangle\) ,有时也记作 \([\boldsymbol{x}, \boldsymbol{y}]\) ,其定义为:
\[\langle \boldsymbol{x}, \boldsymbol{y} \rangle = x_1 y_1 + x_2 y_2 + \cdots + x_n y_n\]
向量的内积是两个向量的一种运算,其结果是一个实数。
8.4. 向量的正交性
如果 \(\langle \boldsymbol{x}, \boldsymbol{y}\rangle = 0\) ,则称向量 \(\boldsymbol{x}\) 和 \(\boldsymbol{y}\) 正交 。
8.5. 向量的范数(长度)
向量 \(\boldsymbol{x}\) 的范数(或长度)记为 \(\Vert \boldsymbol{x} \Vert\) ,其定义为:
\[\Vert \boldsymbol{x} \Vert = \sqrt{\langle\boldsymbol{x}, \boldsymbol{x}\rangle} = \sqrt{x_1^2 + x_2^2 + \cdots + x_n^2}\]
当 \(\Vert \boldsymbol{x} \Vert = 1\) 时,称 \(\boldsymbol{x}\) 为 单位向量 。
有时,我们会看到无穷范数(Infinity Norm)的记号,它的定义为: \[\Vert \boldsymbol{x} \Vert_{\infty} = \max(|x_1|,|x_2|,\cdots,|x_n|)\] 也就是说,向量的无穷范数是向量元素绝对值的最大值。比如向量 \(\boldsymbol{x}=\left( \begin{array}{c} 2 \\ -3 \\ 5 \\ -7 \end{array} \right)\) ,则 \(\Vert \boldsymbol{x} \Vert_{\infty}= \max(|2|,|-3|,|5|,|-7|) = 7\) 。
8.6. 点积(内积)的几何含义(反映两向量的夹角大小)
在几何中,内积(Inner product)又称为点积(dot product)。两向量点积记作 \(\boldsymbol{x} \cdot \boldsymbol{y}\) ,有: \(\boldsymbol{x} \cdot \boldsymbol{y} = \Vert \boldsymbol{x} \Vert \Vert \boldsymbol{y} \Vert \cos \theta\) ,其中, \(\theta\) 称为两向量的夹角。
如果两向量夹角为 \(90^\circ\) ,则其内积为 \(\boldsymbol{x} \cdot \boldsymbol{y} = 0\) 。
如果两向量夹角为 \(0^\circ\) ,则其内积为 \(\boldsymbol{x} \cdot \boldsymbol{y} = \Vert \boldsymbol{x} \Vert \Vert \boldsymbol{y} \Vert\) 。
总结: 内积(点积)反映着两向量的夹角大小 。
9. 向量空间(线性空间)和线性变换
向量空间(Vector space)又称线性空间,它是线性代数中的基本概念。
9.1. 向量空间的简单定义
设 \(V\) 为 \(n\) 维向量的集合,如果集合 \(V\) 非空,且 集合 \(V\) 对于向量的加法和乘数两种运算封闭,那么就称集合 \(V\) 为向量空间(Vector space) 。
“对于向量的加法和乘数两种运算封闭”的含义是:若 \(\boldsymbol{a} \in V, \boldsymbol{b} \in V\) ,则 \(\boldsymbol{a} + \boldsymbol{b} \in V\) ;若 \(\boldsymbol{a} \in V, \lambda \in \mathbb{R}\) ,则 \(\lambda \boldsymbol{a} \in V\) 。
3 维向量的全体 \(\mathbb{R}^3\) 是一个向量空间。因为任意两个 3 维向量之和仍然是 3 维向量,数 \(\lambda\) 乘 3 维向量也仍然是 3 维向量,它们都属于 \(\mathbb{R}^3\) 。我们可以用有向线段形象地表示 3 维向量,从而向量空间 \(\mathbb{R}^3\) 可形象地看作以坐标原点为起点的全体的有向线段。类似地, \(n\) 维向量的全体 \(\mathbb{R}^n\) 也是一个向量空间,不过当 \(n > 3\) 时,它没有直观的几何意义。
9.1.1. 向量空间实例
实例 1:容易验证集合
\[V = \{ \boldsymbol{x} = (0, x_2, \cdots, x_n)^\mathsf{T} \mid x2, \cdots, x_n \in \mathbb{R} \}\]
是一个向量空间。
实例 2:集合
\[V = \{ \boldsymbol{x} = (1, x_2, \cdots, x_n)^\mathsf{T} \mid x2, \cdots, x_n \in \mathbb{R} \}\]
不是向量空间。因为若 \(\boldsymbol{a} = (1, a_2, \cdots, a_n)^\mathsf{T} \in V\) ,则 \(2 \boldsymbol{a} = (2, 2a_2, \cdots, 2a_n)^\mathsf{T} \notin V\) ,这违反了“对乘数运算封闭”的要求,所以 \(V\) 不是向量空间。
9.1.2. pre-Hilbert space(Inner product space)
如果一个向量空间定义了“内积运算(Inner product)”,则向量空间称为 Inner product space,又称为 pre-Hilbert space.
如何在向量空间中定义“内积运算”呢?
设 \(\boldsymbol{u}, \boldsymbol{v}, \boldsymbol{w}\) 是向量, \(\alpha\) 是一个scalar ,运算 \(\langle \cdot, \cdot \rangle\) 满足下面 4 个条件即可称为内积运算:
(1) \(\langle \boldsymbol{u} + \boldsymbol{v}, \boldsymbol{w}\rangle = \langle \boldsymbol{u} , \boldsymbol{w}\rangle + \langle \boldsymbol{v} , \boldsymbol{w}\rangle\)
(2) \(\langle \alpha \boldsymbol{v} + \boldsymbol{w}\rangle = \alpha \langle \boldsymbol{v}, \boldsymbol{w}\rangle\)
(3) \(\langle \boldsymbol{v}, \boldsymbol{w}\rangle = \langle \boldsymbol{w}, \boldsymbol{v}\rangle\)
(4) \(\langle \boldsymbol{v}, \boldsymbol{v}\rangle \ge 0, \quad \langle \boldsymbol{v}, \boldsymbol{v}\rangle = 0 \;\text{if and only if} \; \boldsymbol{v} = \boldsymbol{0}\)
由上面的定义易知:如果定义 \(\langle x, y \rangle = xy\) ,则实数集 \(\mathbb{R}\) 是一个 pre-Hilbert space;如果定义 \(\langle (x_1, x_2, \cdots, x_n), (y_1, y_2, \cdots, y_n) \rangle = x_1y_1 + x_2y_2 + \cdots x_n y_n\) ,则欧拉空间 \(\mathbb{R}^n\) 是一个 pre-Hilbert space;等等还可以定义很多其它的个 pre-Hilbert space。
参考:
http://mathworld.wolfram.com/InnerProduct.html
https://en.wikipedia.org/wiki/Inner_product_space#Examples
9.1.2.1. 柯西-施瓦兹不等式(Cauchy–Schwarz inequality)
pre-Hilbert space 中的向量 \(\boldsymbol{x}, \boldsymbol{y}\) 满足下面不等式:
\[\langle \boldsymbol{x}, \boldsymbol{y} \rangle^2 \le \langle \boldsymbol{x},\boldsymbol{x} \rangle \langle \boldsymbol{y},\boldsymbol{y} \rangle\]
上式称为Cauchy–Schwarz inequality ,也可以写为下面形式:
\[\left| \langle \boldsymbol{x}, \boldsymbol{y} \rangle \right| \le \Vert \boldsymbol{x} \Vert \Vert \boldsymbol{y} \Vert \]
9.1.3. Hilbert space
完备(complete)的内积空间(inner product space)称为Hilbert space 。
在空间中任取Cauchy sequence ,如果它收敛,且收敛到本空间中的元素,则称该空间是完备的空间。
例如:有理数空间不是完备的,因为存在柯西序列 \(x_0 = 1, x_{n+1} = (x_n + 2/x_n)/2\) ,它收敛到无理数 \(\sqrt{2}\) ,不在有理数空间中。
说明:
关于 Hilbert space 的知识可以从“泛函分析”的相关书籍中找到。
9.2. 向量空间的严格定义
向量空间的严格定义如下:设 \(V\) 是一个非空集合, \(\mathbb{R}\) 为实数域。如果对于任意两个元素 \(\boldsymbol{\alpha}, \boldsymbol{\beta} \in V\) ,总有总有唯一的一个元素 \(\boldsymbol{\gamma} \in V\) 与之对应,称其为 \(\boldsymbol{\alpha}\) 与 \(\boldsymbol{\beta}\) 的和,记作 \(\boldsymbol{\gamma} = \boldsymbol{\alpha} + \boldsymbol{\beta}\) ;又对于任一数 \(\lambda \in \mathbb{R}\) 与任一元素 \(\boldsymbol{\alpha} \in V\) ,总有唯一的一个元素 \(\boldsymbol{\delta} \in V\) 与之对应,称为 \(\lambda\) 与 \(\boldsymbol{\alpha}\) 的积,记作 \(\boldsymbol{\delta} = \lambda \boldsymbol{\alpha}\) 。如果上述两种运算满足以下八条运算规律(设 \(\boldsymbol{\alpha}, \boldsymbol{\beta}, \boldsymbol{\gamma} \in V; \lambda, \mu \in \mathbb{R}\) ):
(i) \(\boldsymbol{\alpha} + \boldsymbol{\beta} = \boldsymbol{\beta} + \boldsymbol{\alpha}\)
(ii) \((\boldsymbol{\alpha} + \boldsymbol{\beta}) + \boldsymbol{\gamma} = \boldsymbol{\beta} + (\boldsymbol{\alpha} + \boldsymbol{\gamma})\)
(iii) 在 \(V\) 中存在零向量 \(\boldsymbol{0} \in V\) ,对于任何 \(\boldsymbol{\alpha} \in V\) ,都有 \(\boldsymbol{\alpha} + \boldsymbol{0} = \boldsymbol{\alpha}\)
(iv) 对任何 \(\boldsymbol{\alpha} \in V\) ,都有 \(\boldsymbol{\alpha}\) 的负元素 \(\boldsymbol{\beta} \in V\) ,使 \(\boldsymbol{\alpha} + \boldsymbol{\beta} = \boldsymbol{0}\)
(v) \(1 \boldsymbol{\alpha} = \boldsymbol{\alpha}\)
(vi) \(\lambda ( \mu \boldsymbol{\alpha}) = (\lambda \mu) \boldsymbol{\alpha}\)
(vii) \((\lambda + \mu) \boldsymbol{\alpha} = \lambda \boldsymbol{\alpha} + \mu \boldsymbol{\alpha}\)
(viii) \(\lambda (\boldsymbol{\alpha} + \boldsymbol{\beta}) = \lambda \boldsymbol{\alpha} + \lambda \boldsymbol{\beta}\)
那么就称 \(V\) 为实数域 \(\mathbb{R}\) 上的向量空间(或线性空间)。
9.3. 向量空间的维数(Dimension)、基(Basis)和坐标(Coordinate)
9.3.1. 维数和基
设 \(V\) 为向量空间,如果 \(r\) 个向量 \(\boldsymbol{a_1}, \boldsymbol{a_2}, \cdots, \boldsymbol{a_r} \in V\) ,且满足:
(i) \(\boldsymbol{a_1}, \boldsymbol{a_2}, \cdots, \boldsymbol{a_r}\) 线性无关;
(ii) \(V\) 中任一个向量都可由 \(\boldsymbol{a_1}, \boldsymbol{a_2}, \cdots, \boldsymbol{a_r}\) 线性表示。
则称向量组 \(\boldsymbol{a_1}, \boldsymbol{a_2}, \cdots, \boldsymbol{a_r}\) 为向量空间的一个 基(Basis) , \(r\) 称为向量空间 \(V\) 的 维数(Dimension) ,并称 \(V\) 为 \(r\) 维向量空间,可记为 \(V_r\) 。
实例:向量空间 \(V = \{ \boldsymbol{x} = (0, x_2, \cdots, x_n)^\mathsf{T} \mid x2, \cdots, x_n \in \mathbb{R} \}\) 的维数是 \(n-1\) ,它的基有 \(n-1\) 个向量,其基可以取为: \(\boldsymbol{e_2} = (0, 1, 0, \cdots, 0)^\mathsf{T}, \cdots, \boldsymbol{e_n} = (0, \cdots , 0, 1)^\mathsf{T}\)
9.3.2. 坐标
如果在向量空间 \(V\) 中取定一个基 \(\boldsymbol{a_1}, \boldsymbol{a_2}, \cdots, \boldsymbol{a_r}\) ,对于任一元素 \(\boldsymbol{a} \in V\) ,总有且仅有一组有序数 \(x_1, x_2, \cdots, x_r\) ,使
\[\boldsymbol{a} = x_1 \boldsymbol{a_1} + x_2 \boldsymbol{a_2} + \cdots + x_r \boldsymbol{a_r}\]
有序数 \(x_1, x_2, \cdots, x_r\) 称为向量 \(\boldsymbol{a}\) 在基 \(\boldsymbol{a_1}, \boldsymbol{a_2}, \cdots, \boldsymbol{a_r}\) 中的 坐标 。
9.3.3. 实数坐标空间的标准基(自然基)
在 \(n\) 维向量空间 \(\mathbb{R}^n\) (即实数坐标空间,Real coordinate space )中取单位坐标向量组 \(\boldsymbol{e_1}, \boldsymbol{e_2}, \cdots, \boldsymbol{e_n}\) 为基,则以 \(x_1, x_2, \cdots, x_n\) 为分量的向量 \(\boldsymbol{x}\) ,可表示为:
\[\boldsymbol{x} = x_1 \boldsymbol{e_1} + x_2 \boldsymbol{e_2} + \cdots + x_n \boldsymbol{e_n}\]
\(\boldsymbol{e_1}, \boldsymbol{e_2}, \cdots, \boldsymbol{e_n}\) 称为 \(\mathbb{R}^n\) 中的标准基(Standard basis),又称自然基。
9.3.4. 内积空间的标准正交基(Orthonormal basis)
在一个定义了“内积”运算的向量空间(称为内积空间)中,如果它的基两两正交,则称该基为正交基;如果正交基的基向量的范数(即长度)都为 1,则称正交基为“标准正交基”或"规范正交基"(Orthonormal basis)。
显然,实数坐标空间的“标准基”同时也是“标准正交基”。
注意,在没有定义“内积”运算的空间中,“正交基”一词没有意义。
9.3.4.1. 实例:标准正交基
下面向量组为实数坐标空间 \(\mathbb{R}^4\) 的一个标准正交基:
\[\boldsymbol{e_1} = \left( \begin{array}{c}
\frac{1}{\sqrt{2}} \\
\frac{1}{\sqrt{2}} \\
0 \\
0
\end{array} \right), \qquad \boldsymbol{e_2} = \left( \begin{array}{c}
\frac{1}{\sqrt{2}} \\
-\frac{1}{\sqrt{2}} \\
0 \\
0
\end{array} \right), \qquad \boldsymbol{e_3} = \left( \begin{array}{c}
0 \\
0 \\
\frac{1}{\sqrt{2}} \\
\frac{1}{\sqrt{2}}
\end{array} \right), \qquad \boldsymbol{e_4} = \left( \begin{array}{c}
0 \\
0 \\
\frac{1}{\sqrt{2}} \\
-\frac{1}{\sqrt{2}}
\end{array} \right)\]
9.3.5. 基变换公式和坐标变换公式
向量空间中,用一个基表示另一个基的表示式称为 基变换公式 。
向量空间中,向量在两个基中的坐标之间的关系式称为 坐标变换公式 。
9.4. 向量空间同构(Isomorphism)
一般地,设 \(V\) 与 \(U\) 是两个向量空间,如果在它们的元素之间有一一对应关系,且元素线性组合也有相应对应关系,则说 向量空间 \(V\) 与 \(U\) 同构 。
显然,建立坐标以后,任意向量空间中的向量都可以用 \(\mathbb{R}^n\) 中的向量表示了(即表示为它的坐标)。
总结:任何 \(n\) 维线性空间都和 \(\mathbb{R}^n\) 同构,即维数相等的线性空间都同构。
9.5. 线性变换(线性映射/线性算子)的严格定义
前面在介绍矩阵时,简单地介绍过线性变换,并提到过 矩阵和线性变换之间存在一一对应的关系 。
下面给出 线性变换(又称线性映射或线性算子) 的严格定义:
设 \(V_n, U_m\) 分别为 \(n\) 维和 \(m\) 维线性空间, \(T\) 是一个从 \(V_n\) 到 \(U_m\) 的映射,如果映射 \(T\) 满足:
(i) 任一 \(\boldsymbol{\alpha_1}, \boldsymbol{\alpha_2} \in V_n\) (从而 \(\boldsymbol{\alpha_1} + \boldsymbol{\alpha_2} \in V_n\) ),有: \(T(\boldsymbol{\alpha_1} + \boldsymbol{\alpha_2}) = T(\boldsymbol{\alpha_1}) + T(\boldsymbol{\alpha_2})\)
(ii) 任一 \(\boldsymbol{\alpha} \in V_n, \lambda \in \mathbb{R}\) (从而 \(\lambda \boldsymbol{\alpha} \in V_n\) ),有: \(T(\lambda \boldsymbol{\alpha}) = \lambda T(\boldsymbol{\alpha})\)
则称映射 \(T\) 为 \(V_n\) 到 \(U_m\) 的线性映射,又称线性变换或线性算子。
特别地,如果 \(T\) 是一个从线性空间 \(V_n\) 到其自身的线性变换,则称 \(T\) 为线性空间 \(V_n\) 中的线性变换。
9.5.1. 线性变换的核(Kernel)
已经 \(T\) 是 \(V_n\) 到 \(U_m\) 的线性变换,满足 \(T \boldsymbol{\alpha} = \boldsymbol{0}, \boldsymbol{\alpha} \in V_n\) 的所有元素组成的集合也是一个线性空间,称为线性变换 \(T\) 的核(Kernel)。即:
\[\text{ker}(T) = \{ \boldsymbol{\alpha} \mid \boldsymbol{\alpha} \in V_n, T \boldsymbol{\alpha} = \boldsymbol{0}\}\]
9.5.1.1. 实例:线性变换的核
设线性空间 \(\mathbb{R}^3\) 中有线性变换,其对应的矩阵为:
\[\mathbf{A} =
\left( \begin{array}{cc}
2 & 3 & 5 \\
-4 & 2 & 3
\end{array} \right)\]
这个线性变换的核是满足下面式子的所有向量组成的集合:
\[\left( \begin{array}{cc}
2 & 3 & 5 \\
-4 & 2 & 3
\end{array} \right) \left( \begin{array}{c}
x \\
y \\
z
\end{array} \right) = \left( \begin{array}{c}
0 \\
0
\end{array} \right), \qquad \left( \begin{array}{c}
x \\
y \\
z
\end{array} \right) \in \mathbb{R}^3\]
利用高斯消去法(Gaussian elimination)求解 \(\left( \begin{array}{cc} 2 & 3 & 5 \\ -4 & 2 & 3 \end{array} \right) \left( \begin{array}{c} x \\ y \\ z \end{array} \right) = \left( \begin{array}{c} 0 \\ 0 \end{array} \right)\) 后,可得到 \(\left( \begin{array}{c} x \\ y \\ z \end{array} \right) = c \left( \begin{array}{c} -1 \\ -26 \\ 16 \end{array} \right)\) ,其中 \(c\) 是自由变量。
9.6. 向量空间和线性变换的应用
在图像处理时,一般把图像当作向量(线性)空间来对待。
10. 正交矩阵(Orthogonal matrix)
在矩阵论中,正交矩阵(Orthogonal matrix)是一个元素为实数的方阵,它的各行是单位向量且两两正交,各列也是单位向量且两两正交。 正交矩阵往往记为 \(\mathbf{Q}\)
正交矩阵还有下面等价的定义:
如果矩阵的逆矩阵就是其转置矩阵,即有: \(\mathbf{Q}^{-1} = \mathbf{Q}^{\mathsf{T}}\) ,则 \(\mathbf{Q}\) 为正交矩阵。
10.1. 奇异值分解(Singular value decomposition, SVD)
对于 \(m \times n\) 阶矩阵 \(\mathbf{A}\) ,一定存在 \(m\) 阶正交矩阵 \(\mathbf{U}\) 和 \(n\) 阶正交矩阵 \(\mathbf{V}\) ,使得:
\[\mathbf{A} = \mathbf{U} \Sigma \mathbf{V}^{\mathsf{T}}\]
式中:
\[\Sigma = \left( \begin{array}{cc}
\Sigma_1 & \mathbf{O} \\
\mathbf{O} & \mathbf{O}
\end{array} \right)\]
且 \(\Sigma_1 = \text{diag}(\sigma_1, \sigma_2, \cdots, \sigma_r)\) ,其对角线上元素由大而小排列:
\[\sigma_1 \ge \sigma_2 \ge \cdots \ge \sigma_r > 0, \qquad r = \text{Rank}(A)\]
这样的分解就称作矩阵 \(\mathbf{A}\) 的奇异值分解。 \(\sigma_1, \sigma_2, \cdots, \sigma_r\) 称为奇异值。
参考:https://zh.wikipedia.org/wiki/%E5%A5%87%E5%BC%82%E5%80%BC%E5%88%86%E8%A7%A3
10.2. QR 分解(QR decomposition)
实数 \(m \times n\) 阶矩阵 \(\mathbf{A}\) 的 QR 分解(QR decomposition)为:
\[\mathbf{A} = \mathbf{Q} \mathbf{R}\]
其中 \(\mathbf{Q}\) 是 \(m\) 阶正交矩阵,而 \(\mathbf{R}\) 是 \(m \times n\) 阶上三角矩阵。
即 QR 分解是把矩阵分解成一个正交矩阵与一个上三角矩阵的积。 QR 分解经常用来解决线性最小二乘法问题。
10.3. 特征分解(又称谱分解,Spectral decomposition)
特征分解(Eigendecomposition),又称谱分解(Spectral decomposition)是将矩阵分解为由其特征值和特征向量表示的矩阵之积的方法。需要注意只有“可对角化矩阵”才可以施以特征分解。
参考:https://zh.wikipedia.org/wiki/%E7%89%B9%E5%BE%81%E5%88%86%E8%A7%A3
11. 正定矩阵(Positive-definite matrix)
一个 \(n \times n\) 的实对称矩阵 \(\mathbf{M}\) 是 正定矩阵(Positive-definite matrix) ,当且仅当对于所有 \(n\) 维非零向量 \(\boldsymbol{x}\) ,都有 \(\boldsymbol{x}^{\mathsf{T}} \mathbf{M} \boldsymbol{x} > 0\) 。
此外,如果满足的是 \(\boldsymbol{x}^{\mathsf{T}} \mathbf{M} \boldsymbol{x} \ge 0\) 则 \(\mathbf{M}\) 称为 半正定矩阵(Positive-semidefinite matrix) 。类似地,还可以定义负定矩阵(Negative definite matrix),半负定矩阵(Negative semi-definite matrix)。特别地,当 \(\boldsymbol{x}^{\mathsf{T}} \mathbf{M} \boldsymbol{x}\) 可能为正也可能为负时,则称 \(\mathbf{M}\) 是不定(indefinite)的或未定的。
例如,单位矩阵都是正定矩阵。不失一般性,假设 \(n=2, \boldsymbol{x} = (a,b)^{\mathsf{T}}\) ,则当 \(\boldsymbol{x}\) 为非零向量时, \(\boldsymbol{x}^{\mathsf{T}} \mathbf{M} \boldsymbol{x} = ( \begin{array}{cc} a & b \end{array} ) \left( \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right) \left( \begin{array}{c} a \\ b \end{array} \right) = a^2 + b^2\) 恒大于零。
又如,矩阵 \(\mathbf{M} = \left( \begin{array}{ccc} 2 & -1 & 0 \\ -1 & 2 & -1 \\ 0 & -1 & 2 \end{array} \right)\) 也是正定矩阵。容易证明它,设 \(\boldsymbol{x} = (a,b,c)^{\mathsf{T}}\) ,当 \(\boldsymbol{x}\) 为非零向量时,可得:
\[\begin{aligned} \boldsymbol{x}^{\mathsf{T}} \mathbf{M} \boldsymbol{x} & = ( \begin{array}{ccc} a & b & c \end{array} ) \left( \begin{array}{ccc} 2 & -1 & 0 \\ -1 & 2 & -1 \\ 0 & -1 & 2 \end{array} \right) \left( \begin{array}{c} a \\ b \\c \end{array} \right) \\
& = 2a^2 - 2ab + 2b^2 -2bc + 2c^2 \\
& = a^2 + (a-b)^2 + (b-c)^2 + c^2 > 0
\end{aligned}\]
参考:
正定矩阵的性质及其应用:http://wenku.baidu.com/view/8b8d06e77c1cfad6195fa772.html
11.1. 正定矩阵的充分必要条件
11.1.1. 特征值都大于零的对称矩阵
对称矩阵 \(\mathbf{A}\) 为正定矩阵的一个充分必要条件是: \(\mathbf{A}\) 的所有特征值都大于零。
11.1.2. 各阶主子式都为正
对称矩阵 \(\mathbf{A}\) 为正定矩阵的一个充分必要条件是: \(\mathbf{A}\) 的各阶主子式(Principal minors)都为正,即:
\[a_{11} > 0, \left| \begin{array}{cc}
a_{11} & a_{12} \\
a_{21} & a_{22} \end{array} \right| > 0, \cdots, \left| \begin{array}{ccc}
a_{11} & \cdots & a_{1n} \\
\vdots & & \vdots \\
a_{n1} & \cdots & a_{nn} \end{array} \right| > 0\]
另外,对称矩阵 \(\mathbf{A}\) 为负定矩阵的一个充分必要条件是: \(\mathbf{A}\) 的奇数阶主子式为负,而偶数阶主子式为正,即:
\[(-1)^r \left| \begin{array}{ccc}
a_{11} & \cdots & a_{1r} \\
\vdots & & \vdots \\
a_{r1} & \cdots & a_{rr} \end{array} \right| > 0, (r = 1,2,\cdots,n)\]
上面结论是判断正定矩阵或负定矩阵的常用方法。
11.2. 正定矩阵应用:通过 Hessian matrix 判断凸函数
11.2.1. 海森矩阵(Hessian matrix)
首先介绍海森矩阵(Hessian matrix)的概念。
假设 \(n\) 元函数 \(f(\boldsymbol{x}) = f(x_1,x_2,\cdots,x_n)\) 在定义域内二阶连续可导。则由下面二阶偏导数组成的矩阵就是 Hessian 矩阵(有时记作: \(\nabla^2 f(\boldsymbol{x})\) ):
\[\mathbf{H} = \nabla^2 f(\boldsymbol{x}) = \left( \begin{array}{cccc} \frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \\
\frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} & \cdots & \frac{\partial^2 f}{\partial x_2 \partial x_n} \\
\vdots & \vdots & \ddots & \vdots \\
\frac{\partial^2 f}{\partial x_n \partial x_1} & \frac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n^2} \\
\end{array} \right)\]
由于混合偏导数和求导的顺序无关,所以 Hessian 矩阵是一个对称矩阵。
例如,已知 \(f(x_1, x_2) = x_1^2 + 2 x_1 x_2 + 3 x_2^2 + 7 x_1 + 8 x_2 + 9\) ,则它的 Hessian 矩阵可求得为: \(\mathbf{H} = \left( \begin{array}{cc} 2 & 2 \\ 2 & 6 \end{array} \right)\) 。显然,由计算过程容易知道, 二次函数(quadratic function)的 Hessian 矩阵是一个常数矩阵。
又如,已知 \(f(x_1, x_2, x_3) = x_1 + x_2^2 + x_3^3 - x_1 x_2\) ,则它的 Hessian 矩阵可求得为: \(\mathbf{H} = \left( \begin{array}{ccc} 0 & -1 & 0 \\ -1 & 2 & 0 \\ 0 & 0 & 6x_3 \end{array} \right)\) ,显然它不是一个常数矩阵。
11.2.2. 开凸集上的函数是凸函数等价于其 Hessian 矩阵半正定
设 \(n\) 元函数 \(f(\boldsymbol{x}) = f(x_1,x_2,\cdots,x_n)\) 在开凸集(open convex set) \(S\) 上二阶连续可导。那么有下面结论:
(1) \(\nabla^2 f(\boldsymbol{x})\) is positive semi-definite for all \(\boldsymbol{x} \in S\) ⇔ f is convex in \(S\)
(2) \(\nabla^2 f(\boldsymbol{x})\) is negative semi-definite for all \(\boldsymbol{x} \in S\) ⇔ f is concave in \(S\)
(3) \(\nabla^2 f(\boldsymbol{x})\) is positive definite for all \(\boldsymbol{x} \in S\) ⇒ f is strictly convex in \(S\)
(4) \(\nabla^2 f(\boldsymbol{x})\) is negative definite for all \(\boldsymbol{x} \in S\) ⇒ f is strictly concave in \(S\)
说明: \(S = \mathbb{R}^n\) 是一个开凸集。 \(S = \{ (x_1, x_2, x_3): x_1 > 0, x_2 > 0 , x_3 > 0 \} \in \mathbb{R}^3\) 也是开凸集(但如果约束不等式中把 \(>\) 号都改为 \(\ge\) ,则不是开凸集,而变成了闭凸集)。
11.2.3. 实例:判断多元函数是否为凸函数
实例:请判断函数 \(f(x,y,z) = x^2 + 2y^2 + 3z^2 + 2 xy + 2 xz + 3\) 的凹凸性。
解:函数 \(f(x,y,z)\) 对应的 Hessian 矩阵为:
\[ \nabla^2 f = \left( \begin{array}{ccc} 2 & 2 & 2 \\
2 & 4 & 0 \\
2 & 0 & 6 \\
\end{array} \right)\]
它的各阶主子式 \(D_1 = 2, D_2 = 4, D_3 = 8\) 均大于零,所以 Hessian 矩阵是正定矩阵。
由上节的结论知, \(f(x,y,z)\) 是凸函数,而且还是严格凸函数。
12. 雅可比矩阵(Jacobian Matrix)
假设 \(\boldsymbol{f}: \mathbb{R}^n \to \mathbb{R}^m\) 是一个从 \(n\) 维欧氏空间映射到到 \(m\) 维欧氏空间的函数(其输入输出都是向量)。即有:
\[\boldsymbol{f}(\boldsymbol{x}) = \left( \begin{array}{c} f_1(x_1, \cdots, x_n) \\
f_2(x_1, \cdots, x_n) \\
\vdots \\
f_m(x_1, \cdots, x_n) \end{array} \right)\]
则,这些函数的一阶偏导数组成的下面矩阵就是所谓的 雅可比矩阵(Jacobian Matrix) :
\[J_f = \left( \begin{array}{ccc} \frac{\partial{f_1}}{\partial x_1} & \cdots & \frac{\partial{f_1}}{\partial x_n} \\
\vdots & \ddots & \vdots \\
\frac{\partial{f_m}}{\partial x_1} & \cdots & \frac{\partial{f_m}}{\partial x_n} \end{array} \right)\]
雅可比矩阵可以记为 \(J_f(x_1, \cdots, x_n)\) 或者 \(\frac{{\partial ({f_1}, \cdots ,{y_m})}}{{\partial ({x_1}, \cdots ,{x_n})}}\)
参考:https://zh.wikipedia.org/wiki/%E9%9B%85%E5%8F%AF%E6%AF%94%E7%9F%A9%E9%98%B5
12.1. 实例:雅可比矩阵
设向量值函数:
\[f(\boldsymbol{x}) = f(x_1, x_2) = \left( \begin{array}{c} \sin x_1 + \cos x_2 \\
e^{2x_1 + x_2} \\
2 x_1^2 + x_1 x_2 \end{array} \right)\]
则 \(f(\boldsymbol{x})\) 在任一点 \((x_1, x_2)\) 的雅可比矩阵为:
\[J_f(x_1, x_2) = \left( \begin{array}{cc} \cos x_1 & - \sin x_2 \\
2e^{2x_1 + x_2} & e^{2x_1 + x_2} \\
4x_1 + x_2 & x_1 \end{array} \right)\]
12.2. 雅可比矩阵和切平面(“最优线性逼近”)
如果 \(\boldsymbol{p}\) 是 \(\mathbb{R}^{n}\) 中的一点, \(f\) 在 \(\boldsymbol{p}\) 点可微分,根据高等微积分, \(J_f(\boldsymbol{p})\) 是在这点的导数。在此情况下, \(J_f(\boldsymbol{p})\) 是这个线性映射(即 \(f\) )在点 \(\boldsymbol{p}\) 附近的最优线性逼近,也就是说当 \(\boldsymbol{x}\) 足够靠近点 \(\boldsymbol{p}\) 时,有:
\[\boldsymbol{f}(\boldsymbol{x})\approx f(\boldsymbol{p}) + J_{f}(\boldsymbol{p}) \cdot (\boldsymbol{x} - \boldsymbol{p})\]
下面观察几个特例。
对于最简单的情况( \(n = m = 1\) 时), \(y=f(x)\) 在 \(x_0\) 处的最优线性逼近(切线方程)可表达为: \(y = f(x_0) + f'(x_0) (x - x_0)\)
当 \(n = 2, m = 1\) 时, \(x=f(x,y)\) 在点 \((x_0, y_0)\) 处的最优线性逼近(切平面方程)可表达为: \(z = f(x_0, y_0) + f'_x(x_0, y_0) (x - x_0) + f'_y(x_0, y_0)(y - y_0)\)
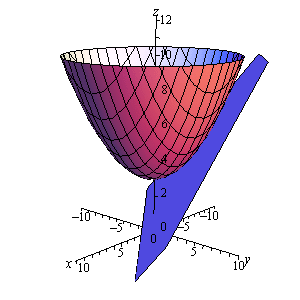
Figure 5: Tangent Plane(摘自http://tutorial.math.lamar.edu/Classes/CalcIII/TangentPlanes.aspx)
总结: 雅可比矩阵表达的是切平面的 Orientation(或切线的斜率)。
12.3. 雅可比行列式
如果 \(m=n\) ,那么 \(f\) 是从 \(n\) 维空间到 \(n\) 维空间的函数,且它的雅可比矩阵是一个方块矩阵。于是我们可以取它的行列式,称为雅可比行列式。
在某个给定点的雅可比行列式提供了 \(f\) 在接近该点时的表现的重要信息。例如,如果连续可微函数 \(f\) 在 p 点的雅可比行列式不是零,那么它在该点附近具有反函数。这称为反函数定理。更进一步, 如果 p 点的雅可比行列式是正数,则 \(f\) 在 p 点的取向不变;如果是负数,则 \(f\) 的取向相反。 而从雅可比行列式的绝对值,就可以知道函数 \(f\) 在 p 点的缩放因子;这就是为什么它出现在换元积分法中。
参考:
雅可比行列式 wikipedia