Kademlia (DHT)
Table of Contents
1. Kademlia 简介
2. 博文转载
博文:易懂分布式 | Kademlia算法 写得简单易懂,转载如下。
Kademlia 算法是一种分布式存储及路由的算法。什么是分布式存储?试想一下,一所 1000 人的学校,现在学校突然决定拆掉图书馆(不设立中心化的服务器),将图书馆里所有的书都分发到每位学生手上(所有的文件分散存储在各个节点上)。即是所有的学生,共同组成了一个分布式的图书馆。如图 1 所示。
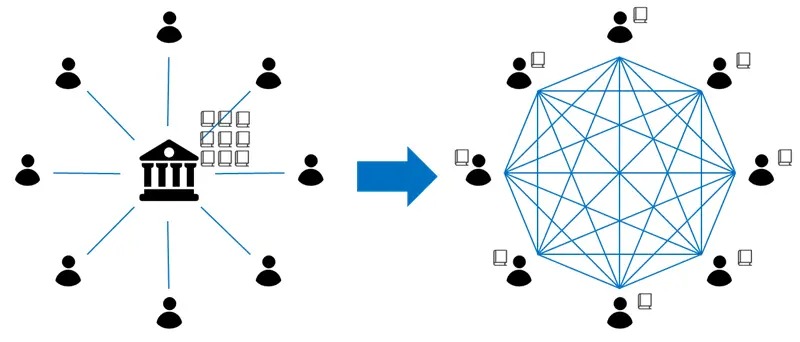
Figure 1: 由中心图书馆到分布式图书馆
2.1. 关键问题
在这种场景下,有几个关键的问题需要回答:
- 每个同学手上都分配哪些书。即如何分配存储内容到各个节点,新增/删除内容如何处理。
- 当你需要找到一本书,譬如《分布式算法》的时候,如何知道哪位同学手上有《分布式算法》(对 1000 个人挨个问一遍,“你有没有《分布式算法》?”,显然是个不经济的做法),又如何联系上这位同学。即一个节点如果想获取某个特定的文件,如何找到存储文件的节点。如图 2 所示。
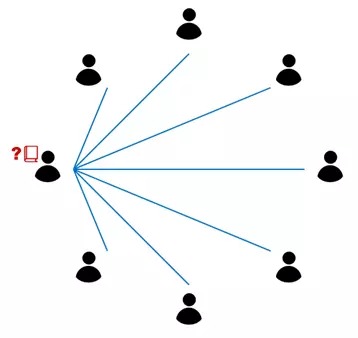
Figure 2: 如何寻找需要的书籍
接下来,让我们来看看 Kademlia 算法如何巧妙地解决这些问题。
2.2. 节点的要素
首先我们来看看每个同学(节点)都有哪些属性:
- 学号(Node ID,二进制,160 位)
- 手机号码(节点的 IP 地址及端口)
每个同学会维护以下内容:
- 从图书馆分发下来的书本(被分配到需要存储的内容),每本书当然都有书名和书本内容(内容以 key-value 对的形式存储,可以理解为文件名和文件内容);
- 一个通讯录,包含一小部分(不是全部)其他同学的学号和手机号,通讯录按学号分层(一个路由表,称为“k-bucket”,按 Node ID 分层,记录有限个数的其他节点的 ID 和 IP 地址及端口)。
根据上面那个类比,可以看看得到表格 1 。
| 协议概念 | 类比概念 |
|---|---|
| Node ID | 学生的学号 |
| IP Address, Port | 学生的手机号 |
| Key | 书名的 hash |
| Value | 书 |
| 路由表(k-bucket) | 每人手上维护的一份通讯录,通讯录里面记录着部分同学的学号和手机号 |
注:为什么不让每个同学都有全量通讯录(每个节点都维护全量路由信息)呢?在分布式系统中,节点的进入和退出是相当频繁的,每次有变动时都全网广播通讯录更新,通讯量会很大。
2.3. 文件的存储及查找
原来收藏在图书馆里,按索引号码得整整齐齐的书,以一种什么样的方式分发到同学们手里呢?大致的原则,包括:1)书本能够比较均衡地分布在同学们的手里,不会出现部分同学手里书特别多、而大部分同学连一本书都没有的情况;2)同学想找一本特定的书的时候,能够一种相对简单的索引方式找到这本书。
Kademlia 作了下面这种安排:
- 假设《分布式算法》这本书的书名的 hash 值是 00010000,那么这本书就会被要求存在学号为 00010000 的同学手上(这要求“hash 算法的值域与 Node ID 的值域”一致。Kademlia 的 Node ID 是 160 位二进制。这里的示例对 Node ID 进行了简略)
- 但还得考虑到会有同学缺勤。万一 00010000 今天没来上学(节点没有上线或彻底退出网络),那《分布式算法》这本书岂不是谁都拿不到了?那算法要求 “这本书不能只存在一个同学手上,而是被要求同时存储在学号最接近 00010000 的 k 位同学手上”,即 00010001、00010010、00010011…等同学手上都会有这本书。
当你需要找《分布式算法》这本书时,将书名 hash 一下,得到 00010000,这个便是索书号,你就知道该找哪(几)位同学了。剩下的问题,就是找到这(几)位同学的手机号。如图 3 所示。
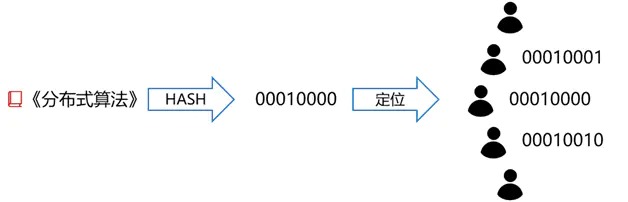
Figure 3: 书籍搜索定位
2.4. 节点的异或距离
由于你手上只有一部分同学的通讯录,你很可能并没有 00010000 的手机号(IP 地址)。那如何联系上目标同学呢?
一个可行的思路就是在你的通讯录里找到一位拥有目标同学的联系方式的同学。前面提到,每位同学手上的通讯录都是按距离分层的。 算法的设计是,如果一个同学离你越近,你手上的通讯录里存有他的手机号码的概率越大。而算法的核心的思路就可以是:当你知道目标同学 Z 与你之间的距离,你可以在你的通讯录上先找到一个你认为与同学 Z 最相近的同学 B,请同学 B 再进一步去查找同学 Z 的手机号。 如图 4 所示。

Figure 4: 通讯录上并没有目标同学的情况
上文提到的距离,就是学号(Node ID)之间的“异或距离”(XOR distance)。异或含义是二进制“相同为 0,不同为 1”,下面是“异或距离”计算的两个例子:
01010000 与 01010010 的异或距离为 00000010(换算为十进制即为 2);
01000000 与 00000001 的异或距离为 01000001(换算为十进制即为 65)。
那通讯录是如何按距离分层呢?下面的示例会告诉你,按异或距离分层,基本上可以理解为按位数分层。设想以下情景:
- 以 0000110 为基础节点,如果一个节点的 ID,前面所有位数都与它相同,只有最后 1 位不同,这样的节点只有 1 个(即 0000111),与基础节点的异或值为 0000001,即距离为 1;对于 0000110 而言,这样的节点归为“k-bucket 1”;
- 如果一个节点的 ID,前面所有位数相同,从倒数第 2 位开始不同,这样的节点只有 2 个:0000101、0000100,与基础节点的异或值为 0000011 和 00000 10,即距离范围为 3 和 2;对于 0000110 而言,这样的节点归为“k-bucket 2”;
- 依此类推;
- 如果一个节点的 ID,前面所有位数相同,从倒数第 n 位开始不同,这样的节点只有 \(2^{i-1}\) 个,与基础节点的距离范围为 \([2^{i-1}, 2^i)\) ;对于 0000110 而言,这样的节点归为 “k-bucket i”;如图 5 所示。
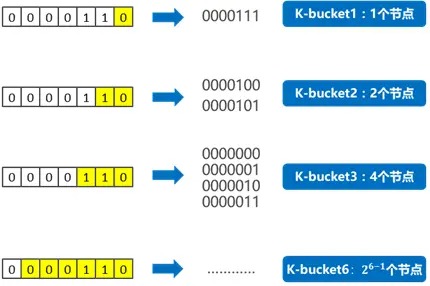
Figure 5: 按位数区分 k-bucket(这里是以 0000110 为当前节点,不同节点的 k-bucket 是不同的)
对上面描述的另一种理解方式:如果将整个网络的节点梳理为一个按节点 ID 排列的二叉树,树最末端的每个叶子便是一个节点,则图 6 就比较直观的展现出,节点之间的距离的关系。
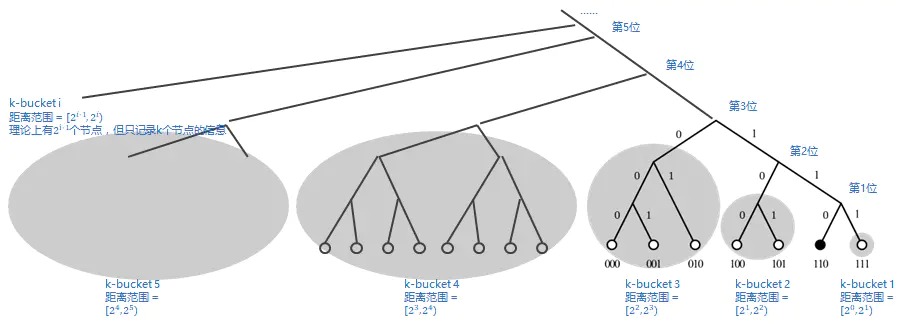
Figure 6: k-bucket 示意图(以 0000110 为当前节点)
回到我们的类比。每个同学只维护一部分的通讯录,这个通讯录按照距离分层(可以理解为按学号与自己的学号从第几位开始不同而分层),即 k-bucket 1, k-bucket 2, k-bucket 3 等等,虽然每个 k-bucket 中实际存在的同学人数逐渐增多,但 每个同学在它自己的每个 k-bucket 中只记录 k 位同学的手机号(k 个节点的地址与端口,这里的 k 是一个可调节的常量参数)。
由于学号(节点的 ID)有 160 位,所以每个同学的通讯录中共分 160 层(节点共有 160 个 k-bucket)。整个网络最多可以容纳 \(2^{160}\) 个同学(节点),但是每个同学(节点)最多只维护 \(160 \times k\) 行通讯录(其他节点的地址与端口)。
2.5. 节点定位
我们现在来阐述一个完整的索书流程。
1、A 同学(学号 00000110)想找《分布式算法》,A 首先需要计算书名的哈希值,hash(《分布式算法》) = 00010000。那么 A 就知道他需要找到 00010000 号同学(命名为 Z 同学)或学号与 Z 邻近的同学。
2、Z 的学 00010000 与自己的异或距离为 00010110,距离范围在 \([24, 25)\) ,所以这个 Z 同学可能在 k-bucket 5 中(或者说,Z 同学的学号与 A 同学的学号从第 5 位开始不同,所以 Z 同学可能在 k-bucket 5 中)。
3、然后 A 同学看看自己的 k-bucket 5 有没有 Z 同学:
3.1、如果有,那就直接联系 Z 同学要书;
3.2、如果没有,在 k-bucket 5 里随便找一个 B 同学(注意任意 B 同学,它的学号第 5 位肯定与 Z 相同,即它与 Z 同学的距离会小于 \(2^4\) ,相当于比 Z、A 之间的距离缩短了一半以上),请求 B 同学在它自己的通讯录里按“同样的查找方式”找一下 Z 同学:
3.2.1、如果 B 知道 Z 同学,那就把 Z 同学的手机号告诉 A;
3.2.2、如果 B 也不知道 Z 同学,那 B 按同样的搜索方法,可以在自己的通讯录里找到一个离 Z 更近的 C 同学(Z、C之间距离小于 \(2^3\) ),把 C 同学推荐给 A;A 同学请求 C 同学进行下一步查找。
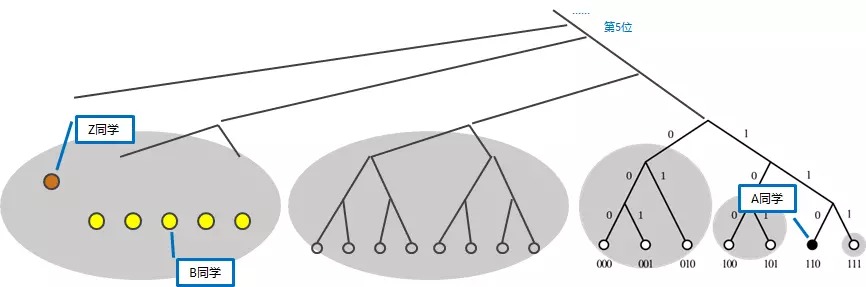
Figure 7: 查询方式示意
Kademlia 的这种查询机制,有点像是将一张纸不断地对折来收缩搜索范围(如图 8 所示),保证对于任意 n 个学生,最多只需要查询 \(log_2(n)\) 次,即可找到获得目标同学的联系方式(即在对于任意一个有 \([2^{n−1}, 2^n)\) 个节点的网络,最多只需要 n 步搜索即可找到目标节点)。
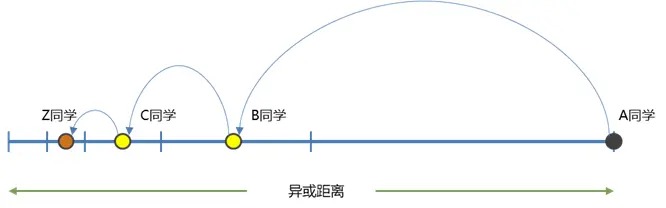
Figure 8: 每次搜索都将距离至少收缩一半
以上便是 Kademlia 算法的基本原理。以下再简要介绍协议中的技术细节。
2.6. 算法的三个参数:keyspace,k 和 α
参数 keyspace:
-- 即 ID 有多少位
-- 决定每个节点的通讯录有几层
参数 k:
-- 每个一层 k-bucket 里装 k 个 node 的信息,即 <Node ID, IP Adress, Port>
-- 每次查找 node 时,返回 k 个 node 的信息
-- 对于某个特定的 data,离其 key 最近的 k 个节点被会要求存储这个 data
参数 α
-- 每次向其他 node 请求查找某个 node 时,会向 α 个 node 发出请求
2.7. 节点的指令
Kademlia 算法中,每个节点只有 4 个指令:
1、PING:测试一个节点是否在线;
2、STORE:要求一个节点存储一份数据;
3、FIND_NODE:根据节点 ID 查找一个节点;
4、FIND_VALUE:根据 KEY 查找一个数据,实则上跟 FIND_NODE 非常类似。
2.8. k-bucket 的维护及更新机制
k-bucket 的维护及更新机制如下:
1、每个 bucket 里的节点都按最后一次接触的时间倒序排列;
2、每次执行四个指令中的任意一个都会触发更新;
3、当一个节点与自己接触时,检查它是否在 k-bucket 中;
3.1、如果在,那么将它挪到 k-bucket 列表的最底(最新);
3.2、如果不在,PING 一下列表最上面(最旧)的一个节点;
3.2.1、如果 PING 通了,将旧节点挪到列表最底,并丢弃新节点;
3.2.2、如果 PING 不通,删除旧节点,并将新节点加入列表。
该机制保证了任意节点加入和离开都不影响整体网络。
2.9. 总结
Kademlia 是分布式哈希表(Distributed Hash Table, DHT)的一种。而 DHT 是一类去中心化的分布式系统。在这类系统中,每个节点(node)分别维护一部分的存储内容以及其他节点的路由/地址,使得网络中任何参与者(即节点)发生变更(进入/退出)时,对整个网络造成的影响最小。DHT 可以用于构建更复杂的应用,包括分布式文件系统、点对点技术文件分享系统、合作的网页高速缓存、域名系统以及实时通信等。
Kademlia 算法在 2002 年由 Petar Maymounkov 和 David Mazières 所设计,“以异或距离来对哈希表进行分层”是其特点。Kademlia 后来被 eMule、BitTorrent 等 P2P 软件采用作为底层算法。Kademlia 可以作为信息安全技术的奠基之一。
Kademlia 的优点在于:
对于任意一个有 \([2^{n−1}, 2^n)\) 个节点的网络,最多只需要 n 步搜索即可找到目标节点;
K-bucket 的更新机制一定程度上保持了网络的活性和安全性。