Unconstrained Optimization (Derivative-based methods)
Table of Contents
1. 无约束最优化简介
无约束最优化(Unconstrained Optimization)问题表示如下:
\[\min_{\boldsymbol{x} \in \mathbb{R}^n} f(\boldsymbol{x})\]
即求 \(f(\boldsymbol{x})\) 取极小值时对应的 \(\boldsymbol{x}\) 值。
无约束最优化问题的解法(方法)可以分为两大类:“Derivative-based optimization”和“Derivative-free optimization”(比如 Pattern search, Powell's method 等等)。不过,“Derivative-free optimization”方法的收敛速度一般比较慢,本文不介绍它们。本文的重点是介绍“基于导数”的无约束最优化方法。
参考:
本文主要摘自:最优化理论与算法(第 2 版), 陈宝林
2. Steepest Descent Method
考虑无约束最优化问题: \(\min_{\boldsymbol{x} \in \mathbb{R}^n} f(\boldsymbol{x})\) ,其中函数 \(f(\boldsymbol{x})\) 是 \(\mathbb{R}^n\) 上具有一阶连续偏导数的函数。
梯度下降法(Gradient Descent)是一种迭代算法,选取适当的初值后,不断迭代更新 \(\boldsymbol{x}\) 的值,进行目标函数的极小化,直到收敛。梯度下降法背后的原理是“负梯度方向是使函数值下降最快的方向”,梯度下降法的更新公式为:
\[\boldsymbol{x}_{k+1} = \boldsymbol{x}_k - \lambda \nabla f(\boldsymbol{x}_k)\]
其中, \(\boldsymbol{x}_k\) 为第 \(k\) 次迭代时 \(\boldsymbol{x}\) 的值, \(\lambda\) 是大于零的实数,称为步长。
有很多设置步长 \(\lambda\) 的方法。下面介绍的最速下降法(Steepest Descent)是其中的一种(注:有时我们提到梯度下降法时,指的就是最速下降法)。
2.1. 最速下降法总结
最速下降法每次迭代时都采用不同的 \(\lambda\) 。记 \(\boldsymbol{d}_k \overset{\text{def}}{=} - \nabla f(\boldsymbol{x}_k)\) ,迭代公式可写为:
\[\boldsymbol{x}_{k+1} = \boldsymbol{x}_k + \lambda_k \boldsymbol{d}_k\]
其中 \(\boldsymbol{d}_k\) 是从 \(\boldsymbol{x}_k\) 出发的搜索方向, \(\lambda_k\) 是从 \(\boldsymbol{x}_k\) 出发沿方向 \(\boldsymbol{d}_k\) 进行一维搜索(也称“线搜索”,也就是单变量函数极小化问题)得到的步长,即 \(\lambda_k\) 满足:
\[f(\boldsymbol{x}_k + \lambda_k \boldsymbol{d}_k) = \min_{\lambda \ge 0} f(\boldsymbol{x}_k + \lambda \boldsymbol{d}_k)\]
也就是:
\[\lambda_k = \operatorname{arg} \underset{\lambda \ge 0}{\min} f(\boldsymbol{x}_k + \lambda \boldsymbol{d}_k)\]
最速下降法计算步骤:
(1) 给定初始点 \(\boldsymbol{x}_1 \in \mathbb{R}^n\) ,允许误差 \(\varepsilon\) ,置 \(k=1\) 。
(2) 计算搜索方向 \(\boldsymbol{d}_k = - \nabla f(\boldsymbol{x}_k)\)
(3) 如果 \(\Vert \nabla f(\boldsymbol{x}_k) \Vert \le \varepsilon\) ,则停止迭代,返回 \(\boldsymbol{x}_k\) 作为 \(f(\boldsymbol{x})\) 极小点;否则,从 \(\boldsymbol{x}_k\) 出发,沿 \(\boldsymbol{d}_k\) 进行一维搜索,求 \(\lambda_k\) ,即:
\[\lambda_k = \operatorname{arg} \underset{\lambda \ge 0}{\min} f(\boldsymbol{x}_k + \lambda \boldsymbol{d}_k)\]
(4) 令 \(\boldsymbol{x}_{k+1} = \boldsymbol{x}_k + \lambda_k \boldsymbol{d}_k\) ,转到步骤(2)。
2.2. 最速下降法应用实例
用最速下降法求解下面优化问题(精度 \(\varepsilon = \frac{1}{10}\) ):
\[\min 2x^2 + y^2\]
解:记 \(\boldsymbol{x} = (x, y)^{\mathsf{T}}\) ,目标函数的 \(f(\boldsymbol{x})\) 的梯度为:
\[\nabla f(\boldsymbol{x}) = \left[ \begin{array}{c} 4x \\ 2y \end{array} \right]\]
取初值点 \(\boldsymbol{x}_1 = (1, 1)^{\mathsf{T}}\) 。
第 1 次迭代。 计算搜索方向 \(\boldsymbol{d}_1\) :
\[\boldsymbol{d}_1 = - \nabla f(\boldsymbol{x}_1) = \left[ \begin{array}{c} -4 \\ -2 \end{array} \right]\]
由于 \(\Vert \nabla f(\boldsymbol{x}_1) \Vert = \sqrt{16+4} = 2 \sqrt{5} > \frac{1}{10}\) ,所以要接着迭代计算。
从 \(\boldsymbol{x}_1\) 出发,沿 \(\boldsymbol{d}_1\) 进行一维搜索,求 \(\lambda_1\) ,方法如下:
\[\min_{\lambda \ge 0} \varphi (\lambda) \overset{\text{def}}{=} f(\boldsymbol{x}_1 + \lambda \boldsymbol{d}_1)\]
由于:
\[\boldsymbol{x}_1 + \lambda \boldsymbol{d}_1 =\left[ \begin{array}{c} 1 \\ 1 \end{array} \right] + \lambda \left[ \begin{array}{c} -4 \\ -2 \end{array} \right] = \left[ \begin{array}{c} 1 - 4 \lambda \\ 1 - 2 \lambda \end{array} \right]\]
所以:
\[\varphi (\lambda) = 2(1 - 4 \lambda)^2 + ( 1 - 2 \lambda )^2\]
令:
\[\varphi'(\lambda) = -16 (1 - 4 \lambda) - 4 (1 - 2 \lambda) = 0\]
上式解得的值即为 \(\lambda_1\) :
\[\lambda_1 = \frac{5}{8}\]
由迭代公式有:
\[\boldsymbol{x}_2 = \boldsymbol{x}_1 + \lambda_1 \boldsymbol{d}_1 = \left[ \begin{array}{c} - \frac{1}{9} \\ \frac{4}{9} \end{array} \right]\]
第 2 次迭代。 计算搜索方向 \(\boldsymbol{d}_2\) :
\[\boldsymbol{d}_2 = - \nabla f(\boldsymbol{x}_2) = \left[ \begin{array}{c} \frac{4}{9} \\ - \frac{8}{9} \end{array} \right]\]
由于 \(\Vert \nabla f(\boldsymbol{x}_2) \Vert = \sqrt{(\frac{4}{9})^2 + (- \frac{8}{9})^2} = \frac{4}{5} \sqrt{5} > \frac{1}{10}\) ,所以要接着迭代计算。
从 \(\boldsymbol{x}_2\) 出发,沿 \(\boldsymbol{d}_2\) 进行一维搜索,求 \(\lambda_2\) ,方法如下:
\[\min_{\lambda \ge 0} \varphi (\lambda) \overset{\text{def}}{=} f(\boldsymbol{x}_2 + \lambda \boldsymbol{d}_2)\]
由于:
\[\boldsymbol{x}_2 + \lambda \boldsymbol{d}_2 =\left[ \begin{array}{c} - \frac{1}{9} \\ \frac{4}{9} \end{array} \right] + \lambda \left[ \begin{array}{c} \frac{4}{9} \\ -\frac{8}{9} \end{array} \right] = \left[ \begin{array}{c} -\frac{1}{9} + \frac{4}{9} \lambda \\ \frac{4}{9} - \frac{8}{9} \lambda \end{array} \right]\]
所以:
\[\varphi (\lambda) = \frac{2}{81} (-1 + 4 \lambda)^2 + \frac{16}{81} ( 1 - 2 \lambda )^2\]
令:
\[\varphi'(\lambda) = \frac{16}{81} (-1 + 4 \lambda) - \frac{64}{81} ( 1 - 2 \lambda) = 0\]
上式解得的值即为 \(\lambda_2\) :
\[\lambda_2 = \frac{5}{12}\]
由迭代公式有:
\[\boldsymbol{x}_3 = \boldsymbol{x}_2 + \lambda_2 \boldsymbol{d}_2 = \frac{2}{27} \left[ \begin{array}{c} 1 \\ 1 \end{array} \right]\]
第 3 次迭代。 其过程类似,直接给出结果:
\[\begin{aligned} \boldsymbol{d}_3 & = - \nabla f(\boldsymbol{x}_3) = \frac{4}{27} \left[ \begin{array}{c} -2 \\ - 1 \end{array} \right] \\
\Vert \nabla f(\boldsymbol{x}_3) \Vert & = \frac{4}{27} \sqrt{5} > \frac{1}{10} \\
\lambda_3 & = \frac{5}{18}
\end{aligned}\]
从而有:
\[\boldsymbol{x}_4 = \boldsymbol{x}_3 + \lambda_3 \boldsymbol{d}_3 = \frac{2}{243} \left[ \begin{array}{c} -1 \\ 4 \end{array} \right]\]
这时 \(\Vert \nabla f(\boldsymbol{x}_4) \Vert = \frac{8}{243} \sqrt{5} < \frac{1}{10}\) ,已经满足精度要求,停止迭代,得到近似解:
\[\left[ \begin{array}{c} x \\ y \end{array} \right] = \frac{2}{243} \left[ \begin{array}{c} -1 \\ 4 \end{array} \right]\]
实际上,这个问题的最优解为: \((0, 0)^{\mathsf{T}}\)
3. Newton's Method
在数学中,有两个地方会提到牛顿方法:在微积分领域中,牛顿方法用于求解方程的根;在最优化理论中,牛顿方法用于求解无约束最优化问题。这里介绍的是后者。
参考:https://en.wikipedia.org/wiki/Newton%27s_method_in_optimization
3.1. 一维情况
为简单起见,先介绍牛顿方法求解一维情况下无约束最优化问题(即单变量的极小化问题)。
考虑问题:
\[\min_{x \in \mathbb{R}} f(x)\]
假设 \(x_k\) 是 \(f(x)\) 的极小点的一个估计。我们把 \(f(x)\) 在 \(x_k\) 点处展开为 Taylor 级数 ,并取二阶近似:
\[f(x) \approx \varphi(x) \overset{\text{def}}{=} f(x_k) + f'(x_k) (x - x_k) + \frac{1}{2}f''(x_k) (x - x_k)^2\]
为了求 \(\varphi(x)\) 的驻点(Stationary point),令 \(\varphi'(x) = 0\) ,有: \[\varphi'(x) = f'(x_k) + f''(x_k) (x - x_k) = 0\] 从而有:\[x = x_k - \frac{f'(x_k)}{f''(x_k)}\] 把求得的 \(\varphi(x)\) 驻点记为 \(x_{k+1}\) ,即有: \[x_{k+1} = x_k - \frac{f'(x_k)}{f''(x_k)} \qquad \text{(单变量时牛顿法迭代公式)}\] 由于在点 \(x_{k}\) 附近 \(f(x) \approx \varphi(x)\) ,因此可用函数 \(\varphi(x)\) 的极小点作为目标函数 \(f(x)\) 的极小点的估计。如果 \(x_{k}\) 是 \(f(x)\) 的极小点的一个估计,那么利用上式求得的 \(x_{k+1}\) 是极小点的一个进一步的估计,经过很多次迭代后,一般会收敛于极值点。
3.2. 多维情况
前面介绍了单变量极小化问题的牛顿法,这里推广到一般无约束问题的牛顿法。
设 \(f(\boldsymbol{x})\) 是二次可微实函数, \(\boldsymbol{x} \in \mathbb{R}^n\) 。又设 \(\boldsymbol{x}_k\) 是 \(f(\boldsymbol{x})\) 的极小点的一个估计。我们把 \(f(\boldsymbol{x})\) 在 \(\boldsymbol{x}_k\) 点处展开为 Taylor 级数 ,并取二阶近似:
\[f(\boldsymbol{x}) \approx \varphi(\boldsymbol{x}) \overset{\text{def}}{=} f(\boldsymbol{x}_k) + \nabla f(\boldsymbol{x}_k)^{\mathsf{T}} (\boldsymbol{x} - \boldsymbol{x}_k) + \frac{1}{2} (\boldsymbol{x} - \boldsymbol{x}_k)^{\mathsf{T}} \nabla^2 f(\boldsymbol{x}_k) (\boldsymbol{x} - \boldsymbol{x}_k)\]
为了求 \(\varphi(\boldsymbol{x})\) 的驻点(Stationary point),令 \(\nabla \varphi(\boldsymbol{x}) = \boldsymbol{0}\) ,有:
\[\nabla \varphi(\boldsymbol{x}) = \nabla f(\boldsymbol{x}_k) + \nabla^2 f(\boldsymbol{x}_k) (\boldsymbol{x} - \boldsymbol{x}_k) = \boldsymbol{0}\]
设 \(\nabla^2 f(\boldsymbol{x}_k)\) 可逆(其逆矩阵记为 \(\nabla^2 f(\boldsymbol{x}_k)^{-1}\) ),从而有:
\[\boldsymbol{x} = \boldsymbol{x}_k - \nabla^2 f(\boldsymbol{x}_k)^{-1} \nabla f(\boldsymbol{x}_k)\]
把求得的 \(\varphi(\boldsymbol{x})\) 驻点记为 \(\boldsymbol{x}_{k+1}\) ,即有: \[\boldsymbol{x}_{k+1} = \boldsymbol{x}_k - \nabla^2 f(\boldsymbol{x}_k)^{-1} \nabla f(\boldsymbol{x}_k) \qquad \text{(牛顿法迭代公式)}\]
经过上面公式多次迭代后,得到的序列 \(\boldsymbol{x}_1, \boldsymbol{x}_2, \cdots, \boldsymbol{x}_k, \boldsymbol{x}_{k+1}, \cdots\) ,在适当条件下,会收敛于极值点。
3.3. 牛顿法应用实例
用牛顿法求解下列问题:
\[\min (x - 1)^4 + {y}^2\]
解:记 \(\boldsymbol{x} = (x, y)^{\mathsf{T}}\) ,目标函数 \(f(\boldsymbol{x})\) 的梯度和 Hessian 矩阵分别为:
\[\begin{aligned} \nabla f(\boldsymbol{x}) & = \left[ \begin{array}{c} 4(x-1)^3\\ 2y \end{array} \right] \\
\nabla^2 f(\boldsymbol{x}) & = \left[ \begin{array}{cc} 12(x-1)^2 & 0 \\ 0 & 2 \end{array} \right]
\end{aligned}\]
取初值点 \(\boldsymbol{x}_1 = (0, 1)^{\mathsf{T}}\) 。
第 1 次迭代:
\[\begin{aligned} \nabla f(\boldsymbol{x}_1) & = \left[ \begin{array}{c} -4 \\ 2 \end{array} \right] \\
\nabla^2 f(\boldsymbol{x}_1) & = \left[ \begin{array}{cc} 12 & 0 \\ 0 & 2 \end{array} \right]
\end{aligned}\]
由牛顿法迭代公式有:
\[\boldsymbol{x}_2 = \boldsymbol{x}_1 - \nabla^2 f(\boldsymbol{x}_1)^{-1} \nabla f(\boldsymbol{x}_1) = \left[ \begin{array}{c} 0 \\ 1 \end{array} \right] - \left[ \begin{array}{cc} 12 & 0 \\ 0 & 2 \end{array} \right]^{-1} \left[ \begin{array}{c} -4 \\ 2 \end{array} \right] = \left[ \begin{array}{c} \frac{1}{3} \\ 0 \end{array} \right]\]
第 2 次迭代:
\[\begin{aligned} \nabla f(\boldsymbol{x}_2) & = \left[ \begin{array}{c} -\frac{32}{27} \\ 0 \end{array} \right] \\
\nabla^2 f(\boldsymbol{x}_2) & = \left[ \begin{array}{cc} \frac{48}{9} & 0 \\ 0 & 2 \end{array} \right]
\end{aligned}\]
由牛顿法迭代公式有:
\[\boldsymbol{x}_3 = \boldsymbol{x}_2 - \nabla^2 f(\boldsymbol{x}_2)^{-1} \nabla f(\boldsymbol{x}_2) = \left[ \begin{array}{c} \frac{1}{3} \\ 0 \end{array} \right] - \left[ \begin{array}{cc} \frac{48}{9} & 0 \\ 0 & 2 \end{array} \right]^{-1} \left[ \begin{array}{c} - \frac{32}{27} \\ 0 \end{array} \right] = \left[ \begin{array}{c} \frac{5}{9} \\ 0 \end{array} \right]\]
继续迭代下去,得到:
\[\boldsymbol{x}_4 = \left[ \begin{array}{c} \frac{19}{27} \\ 0 \end{array} \right], \; \boldsymbol{x}_5 = \left[ \begin{array}{c} \frac{65}{81} \\ 0 \end{array} \right], \cdots\]
这个问题的最优解为 \(\boldsymbol{x}^{*} = (1,0)^{\mathsf{T}}\) 。从迭代进展情况看,牛顿法收敛比较快。
3.4. 牛顿法优缺点
牛顿方法的优点是 收敛速度很快 ,经过较少的迭代次数即可接近极小值点。
牛顿方法的缺点:
(1) 需要计算 \(\nabla^2 f(\boldsymbol{x}_{k})^{-1}\) ,它的计算量过程比较复杂。为此,人们提出了拟牛顿法(寻找更容易计算的矩阵来近似 \(\nabla^2 f(\boldsymbol{x}_{k})^{-1}\) ),后文将介绍它。
(2) 运用牛顿法时,牛顿方向 \(\boldsymbol{d}_k \overset{\text{def}}{=} - \nabla^2 f(\boldsymbol{x}_k)^{-1} \nabla f(\boldsymbol{x}_k)\) 不一定是下降方向,经迭代,目标函数值可能上升。此外,即使目标函数值下降,得到的点 \(\boldsymbol{x}_{k+1}\) 也不一定是沿牛顿方向的最好点或极小点。为此,人们提出了阻尼牛顿法,后文将介绍它。
(3) 运用牛顿法时,初始点的选择十分重要。如果初始点远离极小点,牛顿法可能不收敛。如优化问题 \(\min x^4 + xy + (1+y)^2\) ,当取初始点为 \((0, 0)^{\mathsf{T}}\) 时,用原始牛顿法或者阻尼牛顿法都不会收敛。人们提出了一些修正算法来确保从任意初始点开始迭代都能得到极小值点,本文不介绍这些修正算法。参考《最优化理论与算法(第 2 版), 陈宝林》10.2.3 节
3.5. 阻尼牛顿法(Damped Newton's Method)
阻尼牛顿法与原始牛顿法的区别在于增加了沿牛顿方向的一维搜索,阻尼牛顿法的迭代公式为:
\[\boldsymbol{x}_{k+1} = \boldsymbol{x}_k - \lambda_k \nabla^2 f(\boldsymbol{x}_k)^{-1} \nabla f(\boldsymbol{x}_k) \qquad \text{(阻尼牛顿法迭代公式)}\] 其中 \(\lambda_k\) 是由一维搜索得到的步长。记牛顿方向 \(\boldsymbol{d}_k \overset{\text{def}}{=} - \nabla^2 f(\boldsymbol{x}_k)^{-1} \nabla f(\boldsymbol{x}_k)\) ,则 \(\lambda_k\) 由下式求得:
\[f(\boldsymbol{x}_k + \lambda_k \boldsymbol{d}_k) = \min_{\lambda \ge 0} f(\boldsymbol{x}_k + \lambda \boldsymbol{d}_k)\]
由于阻尼牛顿法含有一维搜索,因此 每次迭代时目标函数值一般会有所下降(绝不会上升)。
阻尼牛顿法是对原始牛顿法非常小的一个改进。 有时,当我们提到牛顿法时,就是指阻尼牛顿法。
4. Quasi-Newton Method
4.1. 动机
运用牛顿法(阻尼牛顿法)时,需要 计算目标函数的 Hessian 矩阵的逆矩阵,这个计算过程比较复杂。
\[\boldsymbol{x}_{k+1} = \boldsymbol{x}_{k} - \lambda_k \underbrace{\nabla^2 f(\boldsymbol{x}_{k})^{-1}}_{\substack{\text{这是 Hessian 矩阵的逆矩阵} \\ \text{拟牛顿法思路:} \\ \text{寻找易计算的矩阵来近似它}}} \nabla f(\boldsymbol{x}_k) \qquad \qquad \text{(阻尼牛顿法迭代公式)}\]
为了解决这个问题,人们提出了拟牛顿法(Quasi-Newton Method),其基本思想是 用不包含二阶导数的矩阵来近似牛顿法中的 Hessian 矩阵的逆矩阵。 由于构造近似矩阵的方法不同,因而出现了不同的拟牛顿法。
4.2. 拟牛顿条件
为了构造 \(\nabla^2 f(\boldsymbol{x}_{k})^{-1}\) 的近似矩阵,我们先分析 \(\nabla^2 f(\boldsymbol{x}_{k})^{-1}\) 和一阶导数的关系。
设在第 \(k\) 次迭代后,得到点 \(\boldsymbol{x}_{k+1}\) ,我们将目标函数 \(f(\boldsymbol{x})\) 在点 \(\boldsymbol{x}_{k+1}\) 处展开为 Taylor 级数,并取二阶近似,有:
\[f(\boldsymbol{x}) \approx f(\boldsymbol{x}_{k+1}) + \nabla f(\boldsymbol{x}_{k+1})^{\mathsf{T}} (\boldsymbol{x} - \boldsymbol{x}_{k+1}) + \frac{1}{2} (\boldsymbol{x} - \boldsymbol{x}_{k+1})^{\mathsf{T}} \nabla^2 f(\boldsymbol{x}_{k+1}) (\boldsymbol{x} - \boldsymbol{x}_{k+1})\]
对上式两个求偏导有:
\[\nabla f(\boldsymbol{x}) \approx \nabla f(\boldsymbol{x}_{k+1}) + \nabla^2 f(\boldsymbol{x}_{k+1}) (\boldsymbol{x} - \boldsymbol{x}_{k+1})\]
令 \(\boldsymbol{x} = \boldsymbol{x}_k\) ,则:
\[\nabla f(\boldsymbol{x}_k) \approx \nabla f(\boldsymbol{x}_{k+1}) + \nabla^2 f(\boldsymbol{x}_{k+1}) (\boldsymbol{x}_k - \boldsymbol{x}_{k+1})\]
定义下面两个符号:
\[\begin{aligned} \Delta \boldsymbol{x}_k & \overset{\text{def}}{=} \boldsymbol{x}_{k+1} - \boldsymbol{x}_k \\
\boldsymbol{y}_k & \overset{\text{def}}{=} \nabla f(\boldsymbol{x}_{k+1}) - \nabla f(\boldsymbol{x}_{k})
\end{aligned}\]
前面的式子可写为:
\[\boldsymbol{y}_k \approx \nabla^2 f(\boldsymbol{x}_{k+1}) \Delta \boldsymbol{x}_k\]
设矩阵 \(\nabla^2 f(\boldsymbol{x}_{k+1})\) 可逆,则:
\[\Delta \boldsymbol{x}_k \approx \nabla^2 f(\boldsymbol{x}_{k+1})^{-1} \boldsymbol{y}_k\]
这样,计算出 \(\Delta \boldsymbol{x}_k\) 和 \(\boldsymbol{y}_k\) 后,可以根据上式估计在 \(\boldsymbol{x}_{k+1}\) 处的 \(\nabla^2 f(\boldsymbol{x}_{k+1})^{-1}\) 。因此,为了用不包含二阶导数的矩阵(记为 \(H_{k+1}\) )取代牛顿法中的 \(\nabla^2 f(\boldsymbol{x}_{k+1})^{-1}\) ,有理由令 \(H_{k+1}\) 满足: \[\Delta \boldsymbol{x}_k = H_{k+1} \boldsymbol{y}_k \qquad \text{(拟牛顿条件)}\] 上式称为 拟牛顿条件,满足这个条件的 \(H_{k+1}\) 都可以作为 \(\nabla^2 f(\boldsymbol{x}_{k+1})^{-1}\) 的近似代替。
4.3. Davidon-Fletcher-Powell (DFP)
DFP(Davidon-Fletcher-Powell)著名的拟牛顿法,它由 William C. Davidon 首先提出,后来被 Roger Fletcher 和 Michael J. D. Powell 改进。
DFP 方法采用下面公式(这里直接给出结论,不推导)迭代计算拟牛顿条件中的 \(H_{k+1}\) (即 \(\nabla^2 f(\boldsymbol{x}_{k+1})^{-1}\) 的近似): \[H_{k+1} = H_{k} + \frac{\Delta \boldsymbol{x}_k \Delta \boldsymbol{x}_k^{\mathsf{T}}}{\Delta \boldsymbol{x}_k^{\mathsf{T}} \boldsymbol{y}_k} - \frac{H_k \boldsymbol{y}_k \boldsymbol{y}_k^{\mathsf{T}} H_k}{\boldsymbol{y}_k^{\mathsf{T}} H_k \boldsymbol{y}_k} \qquad \text{(DFP formula)}\] 初始时, \(H_1\) 通常选择 \(n\) 阶单位矩阵 \(I\) 。上面的公式中,只用到了一阶偏导数信息,并不需要二阶偏导数相关信息。
4.3.1. DFP 算法总结
输入:目标函数 \(f(\boldsymbol{x})\) ,精度 \(\varepsilon\)
输出: \(f(\boldsymbol{x})\) 的极小点 \(\boldsymbol{x}^{*}\) 。
DFP 方法计算步骤如下:
(1) 选定初始点 \(\boldsymbol{x}_1 \in \mathbb{R}^n\)
(2) 置 \(H_1 = I_n\) (单位矩阵),计算出在 \(\boldsymbol{x}_1\) 处的梯度 \(\nabla f(\boldsymbol{x}_1)\) 。如果 \(\Vert \nabla f(\boldsymbol{x}_1) \Vert < \varepsilon\) ,则停止计算,极小点 \(\boldsymbol{x}^{*}\) 的近似值就是初始点 \(\boldsymbol{x}_1\) ;否则,置 \(k=1\) ,接着执行下面步骤。
(3) 令 \(\boldsymbol{d}_k = - H_k \nabla f(\boldsymbol{x}_k)\)
(4) 求步长 \(\lambda_k\) (阻尼牛顿法中的步长),使它满足:
\[f(\boldsymbol{x}_k + \lambda_k \boldsymbol{d}_k) = \min_{\lambda \ge 0} f(\boldsymbol{x}_k + \lambda \boldsymbol{d}_k)\]
(5) 置 \(\boldsymbol{x}_{k+1} = \boldsymbol{x}_k + \lambda_k \boldsymbol{d}_k\)
(6) 计算 \(\nabla f(\boldsymbol{x}_{k+1})\) ,如果 \(\Vert \nabla f(\boldsymbol{x}_{k+1}) \Vert < \varepsilon\) ,则停止迭代,得到近似解 \(\boldsymbol{x}^{*} = \boldsymbol{x}_{k+1}\) ;否则,令 \(\Delta \boldsymbol{x}_k = \boldsymbol{x}_{k+1} - \boldsymbol{x}_k, \; \boldsymbol{y}_k = \nabla f(\boldsymbol{x}_{k+1}) - \nabla f(\boldsymbol{x}_{k})\) ,按下式计算 \(H_{k+1}\) : \[H_{k+1} = H_{k} + \frac{\Delta \boldsymbol{x}_k \Delta \boldsymbol{x}_k^{\mathsf{T}}}{\Delta \boldsymbol{x}_k^{\mathsf{T}} \boldsymbol{y}_k} - \frac{H_k \boldsymbol{y}_k \boldsymbol{y}_k^{\mathsf{T}} H_k}{\boldsymbol{y}_k^{\mathsf{T}} H_k \boldsymbol{y}_k} \qquad \text{(DFP formula)}\]
(7) 置 \(k=k+1\) ,返回步骤(3)
4.3.2. DFP 算法应用实例
用 DFP 方法求解下列问题:
\[\min 2x^2 + y^2 - 4 x + 2\]
解:记 \(\boldsymbol{x} = (x, y)^{\mathsf{T}}\) ,目标函数 \(f(\boldsymbol{x})\) 的梯度为:
\[\nabla f(\boldsymbol{x}) = \left[ \begin{array}{c} 4(x-1) \\ 2y \end{array} \right]\]
初始点 \(\boldsymbol{x}_1\) 和初始矩阵 \(H_1\) 分别取为:
\[\boldsymbol{x}_1 = \left[ \begin{array}{c} 2 \\ 1 \end{array} \right], \; H_1 = \left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right]\]
第 1 次迭代,在点 \(\boldsymbol{x}_1\) 处的梯度:
\[\nabla f(\boldsymbol{x}_1) = \left[ \begin{array}{c} 4 \\ 2 \end{array} \right]\]
令搜索方向:
\[\boldsymbol{d}_1 = -H_1 \nabla f(\boldsymbol{x}_1) = \left[ \begin{array}{c} -4 \\ -2 \end{array} \right]\]
求 \(\lambda_1\) ,即从 \(\boldsymbol{x}_1\) 出发沿 \(\boldsymbol{d}_1\) 作一维搜索,即求解:
\[f(\boldsymbol{x}_1 + \lambda_1 \boldsymbol{d}_1) = \min_{\lambda \ge 0} f(\boldsymbol{x}_1 + \lambda \boldsymbol{d}_1)\]
得到 \(\lambda_1 = \frac{5}{18}\) 。令
\[\boldsymbol{x}_2 = \boldsymbol{x}_1 + \lambda_1 \boldsymbol{d}_1 = \left[ \begin{array}{c} 2 \\ 1 \end{array} \right] + \frac{5}{18} \left[ \begin{array}{c} -4 \\ -2 \end{array} \right] = \left[ \begin{array}{c} \frac{8}{9} \\ \frac{4}{9} \end{array} \right]\]
计算 \(\nabla f(\boldsymbol{x}_2)\) :
\[\nabla f(\boldsymbol{x}_2) = \left[ \begin{array}{c} 4 \left( \frac{8}{9} - 1 \right) \\ 2 \cdot \frac{4}{9} \end{array} \right] = \left[ \begin{array}{c} - \frac{4}{9} \\ \frac{8}{9} \end{array} \right]\]
第 2 次迭代。
\[\begin{aligned} \Delta \boldsymbol{x}_1 & = \boldsymbol{x}_{2} - \boldsymbol{x}_1 = \left[ \begin{array}{c} - \frac{10}{9} \\ - \frac{5}{9} \end{array} \right] \\
\boldsymbol{y}_1 & = \nabla f(\boldsymbol{x}_{2}) - \nabla f(\boldsymbol{x}_1) = \left[ \begin{array}{c} - \frac{40}{9} \\ - \frac{10}{9} \end{array} \right]
\end{aligned}\]
计算矩阵:
\[\begin{aligned} H_2 & = H_1 + \frac{\Delta \boldsymbol{x}_1 \Delta \boldsymbol{x}_1^{\mathsf{T}}}{\Delta \boldsymbol{x}_1^{\mathsf{T}} \boldsymbol{y}_1} - \frac{H_1 \boldsymbol{y}_1 \boldsymbol{y}_1^{\mathsf{T}} H_1}{\boldsymbol{y}_1^{\mathsf{T}} H_1 \boldsymbol{y}_1} \\
& = \left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right] + \frac{1}{18} \left[ \begin{array}{cc} 4 & 2 \\ 2 & 1 \end{array} \right] - \frac{1}{17} \left[ \begin{array}{cc} 16 & 4 \\ 4 & 1 \end{array} \right] \\
& = \frac{1}{306} \left[ \begin{array}{cc} 86 & -38 \\ -38 & 305 \end{array} \right]
\end{aligned}\]
令:
\[\boldsymbol{d}_2 = -H_2 \nabla f(\boldsymbol{x}_2) = -\frac{1}{306} \left[ \begin{array}{cc} 86 & -38 \\ -38 & 305 \end{array} \right] \left[ \begin{array}{c} - \frac{4}{9} \\ \frac{8}{9} \end{array} \right] = \frac{12}{51} \left[ \begin{array}{c} 1 \\-4 \end{array} \right]\]
求 \(\lambda_2\) ,即从 \(\boldsymbol{x}_2\) 出发沿 \(\boldsymbol{d}_2\) 作一维搜索,即求解:
\[f(\boldsymbol{x}_2 + \lambda_2 \boldsymbol{d}_2) = \min_{\lambda \ge 0} f(\boldsymbol{x}_2 + \lambda \boldsymbol{d}_2)\]
得到 \(\lambda_2 = \frac{17}{36}\) 。令
\[\boldsymbol{x}_3 = \boldsymbol{x}_2 + \lambda_2 \boldsymbol{d}_2 = \left[ \begin{array}{c} \frac{8}{9} \\ \frac{4}{9} \end{array} \right] + \frac{17}{36} \cdot \frac{12}{51} \left[ \begin{array}{c} 1 \\ -4 \end{array} \right] = \left[ \begin{array}{c} 1 \\ 0 \end{array} \right]\]
这时有:
\[\nabla f(\boldsymbol{x}_3) = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]\]
驻点为零的点就是极值点。因此得到的最优解为:
\[(x, y) = (1, 0)\]
4.4. Broyden-Fletcher-Goldfarb-Shanno (BFGS)
BFGS(Broyden–Fletcher–Goldfarb–Shanno)方法另一种拟牛顿法。
BFGS 方法采用下面公式(这里直接给出结论,不推导)迭代计算拟牛顿条件中的 \(H_{k+1}\) (即 \(\nabla^2 f(\boldsymbol{x}_{k+1})^{-1}\) 的近似): \[H_{k+1} = \left(I - \frac{\Delta \boldsymbol{x}_k \boldsymbol{y}_k^{\mathsf{T}}}{\boldsymbol{y}_k^{\mathsf{T}} \Delta \boldsymbol{x}_k} \right) H_k \left(I - \frac{\boldsymbol{y}_k \boldsymbol{x}_k^{\mathsf{T}}}{\boldsymbol{y}_k^{\mathsf{T}} \Delta \boldsymbol{x}_k} \right) + \frac{\Delta \boldsymbol{x}_k \Delta \boldsymbol{x}_k^{\mathsf{T}}}{\boldsymbol{y}_k^{\mathsf{T}} \Delta \boldsymbol{x}_k} \qquad \text{(BFGS formula)}\]
BFGS 算法和 DFP 算法的具体步骤是一样的,仅仅只是计算 \(H_{k+1}\) 的迭代公式不同。 数值计算经验表明,使用 BFGS 公式比使用 DFP 公式还要快,目前 BFGS 方法得到广泛应用。
4.4.1. BFGS 公式和 DFP 公式的关系
在 BFGS 公式和 DFP 公式中, \(H_{k+1}\) 是 \(\nabla^2 f(\boldsymbol{x}_{k+1})^{-1}\) 的近似,如果记 \(B_{k+1}\) 为 \(\nabla^2 f(\boldsymbol{x}_{k+1})\) 的近似,则有图 1 (摘自 https://en.wikipedia.org/wiki/Quasi-Newton_method )所示结论。有时, BFGS 公式也称为 DFP 公式的对偶公式。
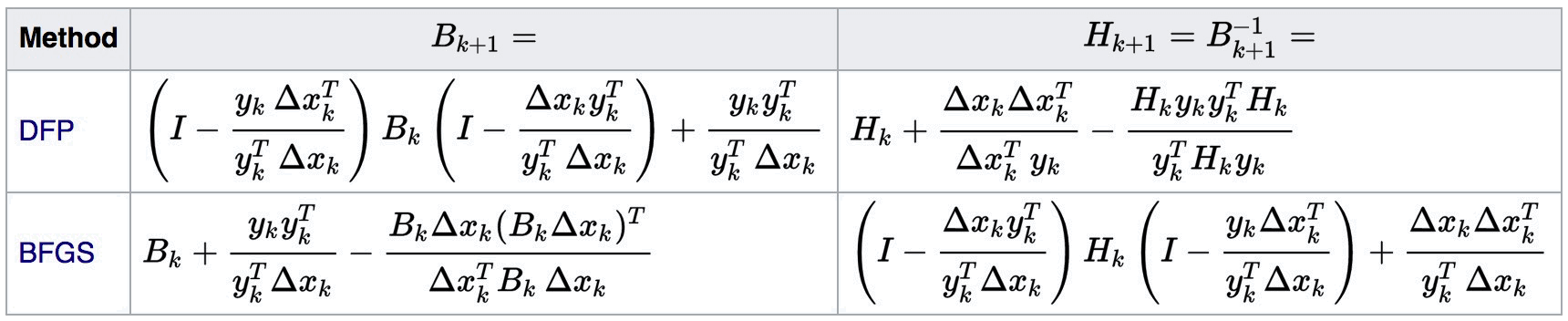
Figure 1: BFGS 公式和 DFP 公式的关系
4.4.2. Limited-memory BFGS (L-BFGS)
假设原始优化问题 \(f(\boldsymbol{x})\) 有 \(n\) 个变量( \(\boldsymbol{x}\) 为 \(n\) 维向量 ),则在 BFGS 公式中, \(H_k\) 的规模为 \(n \times n\) ,当 \(n\) 很大时,存储这个 \(n \times n\) 矩阵会很占计算机资源,Limited-memory BFGS (L-BFGS)是在受限内存时的一种 BFGS 近似算法。
4.4.3. 使用 SciPy 库进行最优化
Python 的 SciPy 库实现了常见的最优化算法,参考:https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html
下面是使用 BFGS 算法求解最优化问题 \(\min (x - 1)^4 + {y}^2\) (这个问题我们在节 3.3 中求解过)的演示:
>>> from scipy import optimize
>>> def f(x):
... return (x[0] - 1)**4 + x[1]**2
...
>>> optimize.minimize(f, [0, 0], method='BFGS')
status: 0
success: True
njev: 15
nfev: 60
hess_inv: array([[ 1.04206844e+03, 1.26935227e+00],
[ 1.26935227e+00, 5.33941376e-01]])
fun: 1.0776982563563174e-09
x: array([ 1.00570151e+00, -4.58021983e-06])
message: 'Optimization terminated successfully.'
jac: array([ 7.41364167e-07, -9.14553849e-06])
上面输出中,倒数第 3 行就是求得的极小值点:
x: array([ 1.00570151e+00, -4.58021983e-06])