Word Embedding
Table of Contents
1. 词向量
自然语言理解的问题要转化为机器学习的问题,第一步是要找一种方法把这些符号数学化。
在众多表式方法中,最直观、最常用的词表示方法是 One-hot 编码,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
比如:“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …],“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …],等等。每个词都是茫茫 0 海中的一个 1。
由于每个词对应的向量中仅有一位为 1,也可以直接用非零维度的下标表示,比如刚才的例子中,话筒记为 3,麦克记为 8(假设下标从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。
One-hot 表示方法存在下面缺点:
1、“词汇鸿沟”:任意两个词之间都是孤立的。仅从这两个向量中看不出两个词是否有关系,比如“话筒”和“麦克”是同义词,但从它们的 One-hot 编码中体现不出这一点。
2、“维度灾难”:One-hot 每个词对应编码向量中只有一个值为 1,其余都为 0。这在 Deep Learning 中,其复杂度几乎是难以接受的。
Deep Learning 中一般用到的“词向量”并不是刚才提到的用 One-hot 编码所表示的那种很长很长的词向量,而是用 Distributed Representation(注:Distributed representation 最早是 Hinton 在 1986 年的论文《Learning distributed representations of concepts》中提出的),它是一种“低维向量”。 这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …]。维度以 50 维和 100 维比较常见。
Distributed Representation 通常也称为“Word Representation”。生成相应低维向量的过程被称为“Word Embedding”,中文可称为“词嵌入”(表示高维词向量嵌入到一个低维空间)。
2. 词向量的训练
要介绍词向量是怎么训练得到的,就不得不提到“语言模型”。这是因为 所有训练方法都是在训练语言模型的同时,顺便得到词向量的。
2.1. 语言模型
什么是“语言模型”(Language Model)呢? 语言模型就是评价一句话是不是正常人说出来的。这玩意很有用,比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结果。
一个语言模型通常构建为字符串 \(s\) 的概率分布 \(p(s)\) ,这里 \(p(s)\) 反映的是字符串 \(s\) 作为一个句子出现的频率。例如,在一个刻画口语的语言模型中,如果一个人所说的话语中每 100 个句子里大约有一句是 Okay,则可以认为 \(p(\text{Okay}) \approx 0.01\) 。而对于句子“An apple ate the chicken”我们可以认为其概率为 0,因为几乎没有人会说这样的句子。需要注意的是,与语言学中不同,语言模型与句子是否合乎语法是没有关系的,即使一个句子完全合乎语法逻辑,我们仍然可以认为它出现的概率接近为零。
设 \(w_1, w_2, \cdots, w_t\) 依次表示一句话 \(s\) 中的各个词。那么 \(s=w_1 w_2 \cdots w_t\) 是句子的概率为:
\[\begin{aligned} p(s) &= p(w_1, w_2, \cdots, w_t) \\
&= p(w_1) \times p(w_2 | w_1) \times p(w_3 | w_1, w_2) \times \cdots \times p(w_t | w_1, w_2, \cdots, w_{t-1}) \\
&= \prod_{i=1}^{t}p(w_i | w_1, w_2, \cdots w_{i-1}) \\
\end{aligned}\]
其中,概率 \(p(w_1), p(w_2 | w_1), p(w_3 | w_1, w_2), \cdots, p(w_t | w_1, w_2, \cdots, w_{t-1})\) 就是语言模型的参数。如果这些参数已经全部算出来了,那么给定一个句子 \(s\) ,就可以算出相应的 \(p(s)\) 了。
2.2. n-gram 语言模型
一般地,我们把前 \(i-1\) 个词 \(w_1 w_2 \cdots w_{i-1}\) 称为第 \(i\) 个词 \(w_i\) 的“历史(history)”。
假设句子 \(s\) 中出现在第 \(i\) 个位置上的词 \(w_i\) 与它的“历史”无关,则称为“一元文法”,可记为“uni-gram”。
假设句子 \(s\) 中出现在第 \(i\) 个位置上的词 \(w_i\) 仅与它前面的一个历史词 \(w_{i-1}\) 有关,则称为“二元文法”,可记为“bi-gram”,二元文法模型被称为一阶马尔可夫链(Markov chain)。
假设句子 \(s\) 中出现在第 \(i\) 个位置上的词 \(w_i\) 仅与它前面的两个历史词 \(w_{i-2}\) 和 \(w_{i-1}\) 有关,则称为“三元文法”,可记为“tri-gram”,三元文法模型被称为二阶马尔可夫链(Markov chain)。
所以,n-gram 模型的基本思想,就是作为一个 \(n-1\) 阶的马尔可夫假设。
关于 n-gram 模型,可以参考《统计自然语言处理(第2版, 宗成庆)》第 5 章,语言模型。
2.2.1. 2-gram 实例
以二元文法模型为例,一个词的概率只依赖于它前面的一个词,那么:
\[p(s) = \prod_{i=1}^{t}p(w_i | w_1, w_2, \cdots w_{i-1}) \approx \prod_{i=1}^{t}p(w_i | w_{i-1})\]
为了使 \(i=1\) 时, \(p(w_i | w_{i-1})\) 有意义,我们在句子开头加上一个句首标记 <BOS>,即假设 \(w_0\) 就是 <BOS>。另外,为了使得所有的字符串的概率之和 \(\sum\limits_s p(s)\) 等于 1,需要在句子结尾再放一个句尾标记 <EOS>,并且使之包含在上面等式的乘积中(如果不做这样的处理,所有给定长度的字符串的概率和为 1,而所有字符串的概率和为无穷大)。例如,要计算概率 \(p(\text{Mark wrote a book})\) ,我们可以这样计算:
\[\begin{aligned} p(\text{Mark wrote a book}) = \; & p(\text{Mark} | \langle\text{BOS})\rangle \times p(\text{wrote} | \text{Mark}) \times p(\text{a} | \text{wrote}) \\
& \times p(\text{book} | \text{a}) \times p(\langle\text{EOS}\rangle | \text{book}) \\
\end{aligned}\]
为了估计 \(p(w_i | w_{i-1})\) 条件概率,可以简单地计算 \(w_{i-1} w_i\) 在某一文本中出现的频率,然后归一化。如果用 \(c(w_{i-1} w_i)\) 表示 \(w_{i-1} w_i\) 在给定文本中的出现次数,我们可以采用下面公式来估计 \(p(w_i | w_{i-1})\) :
\[p(w_i | w_{i-1}) = \frac{c(w_{i-1} w_i)}{\sum\limits_{w_i}c(w_{i-1} w_i)}\]
上式是 \(p(w_i | w_{i-1})\) 的 最大似然估计 。
请看下面的例子。假设训练语料库由下面 3 个句子构成:
\[\begin{gathered} \text{BROWN READ HOLY BIBLE} \\
\text{MARK READ A TEXT BOOK} \\
\text{HE READ A BOOK BY DAVID} \end{gathered}\]
用最大似然估计的方法计算概率 \(p(\text{BROWN READ A BOOK})\) 。
先计算下面几个概率:
\[\begin{gathered} p(\text{BROWN} | \langle\text{BOS})\rangle) = \frac { c(\langle\text{BOS})\rangle \text{BROWN}) } { \sum\limits_{w}c(\langle\text{BOS})\rangle \; w)} = \frac{1}{3} \\
p(\text{READ} | \text{BROWN} ) = \frac {c( \text{BROWN READ}) } { \sum\limits_w c( \text{BROWN} \; w ) } = \frac { 1 } { 1 } \\
p(\text{A} | \text{READ} ) = \frac{c(\text{READ A}) } { \sum\limits_w c( \text{READ} \; w ) } = \frac { 2 } { 3 } \\
p(\text{BOOK} | \text{A}) = \frac{c (\text{A BOOK}) } { \sum\limits_w c( \text{A} \; w ) } = \frac { 1 } { 2 } \\
p(\langle\text{EOS})\rangle | \text{BOOK} ) =\frac{c (\text{BOOK} \; \langle\text{EOS})\rangle) } { \sum\limits_w c( \text{BOOK} \; w ) } = \frac { 1 } { 2 } \end{gathered}\]
因此,有:
\[\begin{aligned} & p(\text{BROWN READ A BOOK}) \\
= & p(\text{BROWN} | \langle\text{BOS})\rangle) \times p(\text{READ} | \text{BROWN} ) \times p(\text{BOOK} | \text{A}) \times p(\langle\text{EOS})\rangle | \text{BOOK} ) \\
= & \frac{1}{3} \times 1 \times \frac{2}{3} \times \frac{1}{2} \times \frac{1}{2} \approx 0.06 \\
\end{aligned}\]
2.2.2. n-gram 模型的缺点
n-gram 模型有下面缺点:
第一,需要设计“平滑方法”处理零值。在特定语料库中按照前面公式计算概率时,可能遇到很多的零值。例如,对于前面例子中的训练语料库,计算句子“DAVID READ A BOOK”的概率,有如下公式:
\[p(\text{READ} | \text{DAVID}) = \frac{c (\text{DAVID READ} } { \sum\limits_w c( \text{DAVID} \; w ) } = \frac{0}{1} = 0\]
从而,有 \(p(\text{DAVID READ A BOOK})=0\) 。显然,这是不合理的,因为句子“DAVID READ A BOOK”总有出现的可能,其概率应该大于 0。所以,需要设计各种“平滑方法”来处理这种情况。参考《统计自然语言处理(第2版, 宗成庆)》第 5.3 节,数据平滑(该节中介绍了 6 种数据平滑的算法)。
第二,我们无法把 \(n\) 值取得很大,一般来说 3-gram 比较常见, \(n\) 再变大的话,计算复杂度会指数上升。而如果 \(n\) 比较小的话,就无法体现上下文中较长的依赖关系。
第三,n-gram 模型无法表征词语之间的相似性。
2.3. 神经概率语言模型(Neural Network Language Model)
Bengio 等人在论文“A Neural Probabilistic Language Model. Journal of Machine Learning Research (2003)”中提出了一种“神经概率语言模型”。
既然名为神经概率语言模型,其中当然用到了“神经网络”。Bengio 用了一个三层的神经网络来构建语言模型,如图 1 所示。
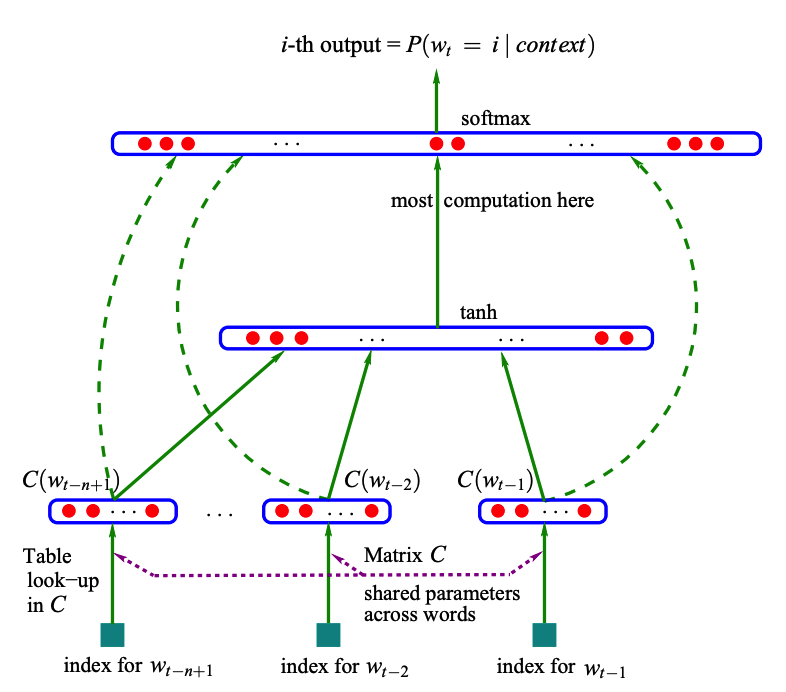
Figure 1: Bengio 用了一个三层的神经网络来构建语言模型
在语料库中词 \(w_t\) 的前 \(n-1\) 个词是已知的,训练的过程就是“根据前 \(n-1\) 个词预测下一个词 \(w_t\) 的过程”。图 1 中最下方的 \(w_{t-n+1}, \cdots, w_{t-2}, w_{t-1}\) 就是前 \(n-1\) 个词。输入是词的 one-hot 编码, \(C(w)\) 表示词 \(w\) 所对应的词向量,存在矩阵 \(C\) (一个 \(|V| \times m\) 的矩阵)中。其中 \(|V|\) 表示词表的大小(语料中的总词数), \(m\) 表示词向量的维度。
网络的第一层(输入层)是将 \(C(w_{t-n+1}), \cdots, C(w_{t-2}), C(w_{t-1})\) 这 \(n−1\) 个向量首尾相接拼起来,形成一个 \((n−1)m\) 维的向量,下面记为 \(x\) 。
网络的第二层(隐藏层)就如同普通的神经网络,直接使用 \(d+Hx\) 计算得到。 \(d\) 是一个偏置项。在此之后,使用 \(\tanh\) 作为激活函数。
网络的第三层(输出层)一共有 \(|V|\) 个节点,每个节点 \(y_i\) 表示下一个词为 \(i\) 的未归一化 log 概率。最后使用 softmax 激活函数将输出值 \(y\) 归一化成概率。最终, \(y\) 的计算公式为:
\[y = b + Wx + U\tanh(d+Hx)\]
式子中的 \(U\) (一个 \(|V| \times h\) 的矩阵)是隐藏层到输出层的参数,整个模型的多数计算集中在 \(U\) 和隐藏层的矩阵乘法中。
式子中还有一个矩阵 \(W\) (一个 \(|V|\times(n-1)m\) 的矩阵),这个矩阵包含了从输入层到输出层的直连边。如果不需要直连边的话,将 \(W\) 置为 0 就可以了。在最后的实验中,Bengio 发现直连边虽然不能提升模型效果,但是可以少一半的迭代次数。
训练结束后,得到了语言模型的同时,也得到了参数 \(C\) ,即各个词对应的向量(词向量)。一个词可以表征为一个向量形式是 Bengio 在该论文中的主要贡献,这启发了后来的 word2vec 的工作。
2.3.1. 神经概率语言模型的优点
神经概率语言模型克服了 n-gram 模型有三个缺点。
1、神经概率语言模型自带平滑,无需传统 n-gram 模型中那些复杂的平滑算法。
2、神经概率语言模型能够对更长的依赖关系进行建模。
3、神经概率语言模型可以表征词语之间的相似性,“相似的”词对应的词向量也是相似的。
3. word2vec
word2vec 是 Google 于 2013 年开源推出的一个用于生成“词向量”的工具包。word2vec 背后的模型是 CBOW (Continuous Bag-of-Words) 或者 Skip-gram,并且使用了 Hierarchical Softmax 或者 Negative Sampling 优化方法。
用 word2vec 生成词向量时,可以选择 CBOW 模型或者 Skip-gram 模型,这两个模型都属于前面介绍的“神经概率语言模型”。
word2vec 原始论文不是很易懂,更推荐 Xin Rong 的论文:word2vec Parameter Learning Explained
3.1. CBOW (Continuous Bag-of-Words)
CBOW (Continuous bag-of-words) 模型如图 2 所示。
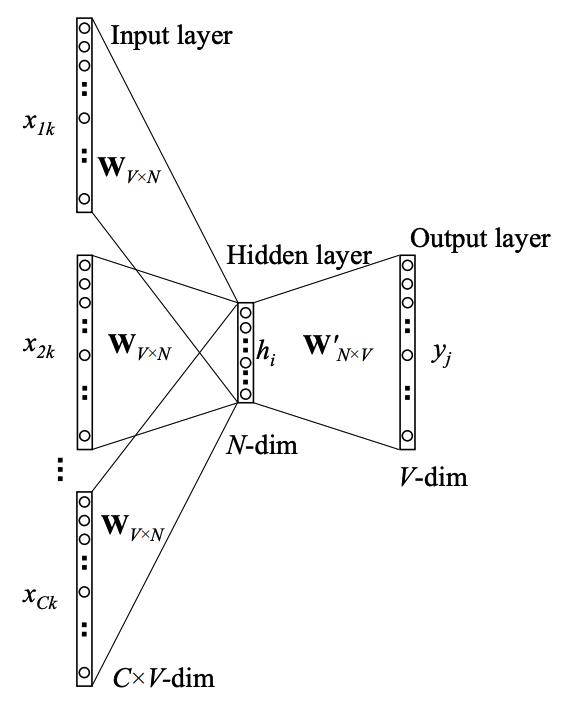
Figure 2: Continuous bag-of-words model
CBOW 模型的训练原理是由上下文单词来估计当前单词,其输入层是“上下文单词”的 One-hot,输出是当前单词。 如图 3 所示。
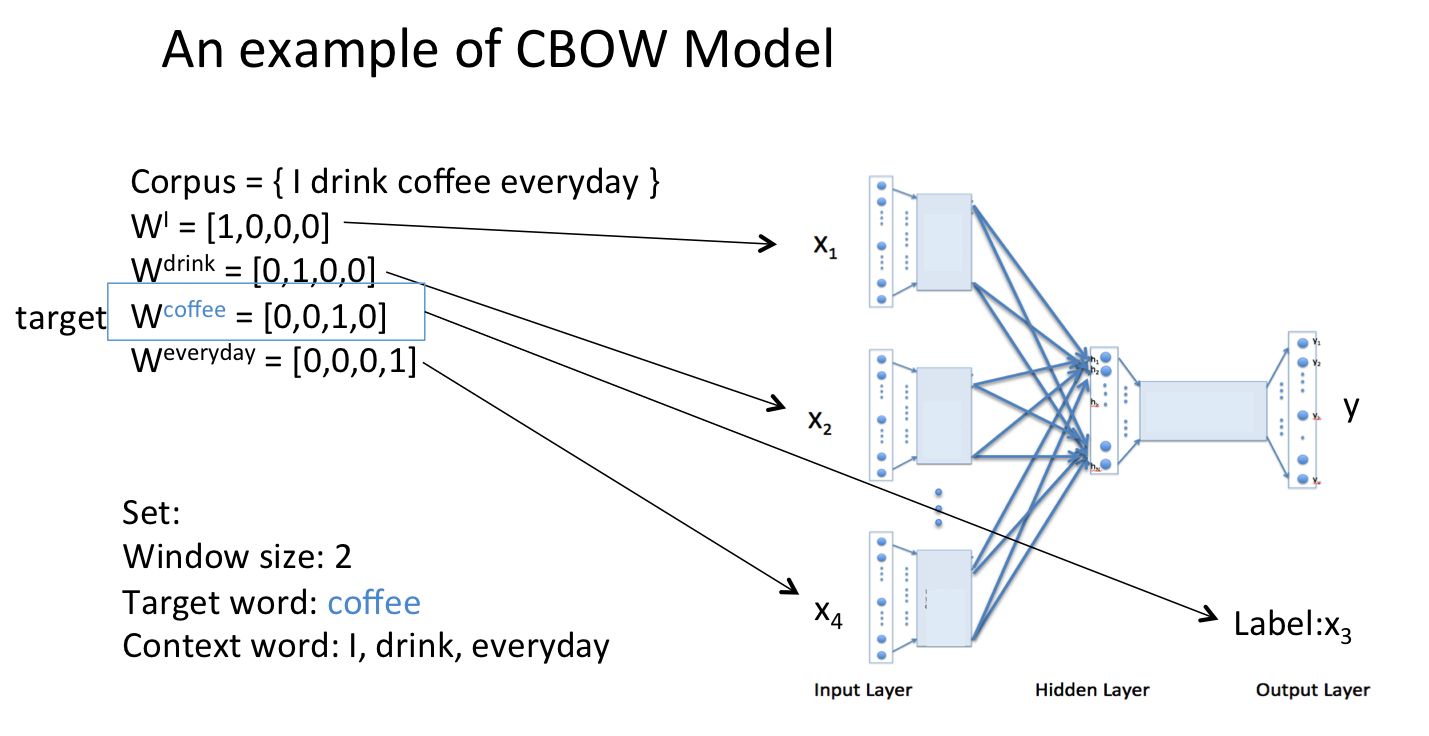
Figure 3: An example of CBOW model
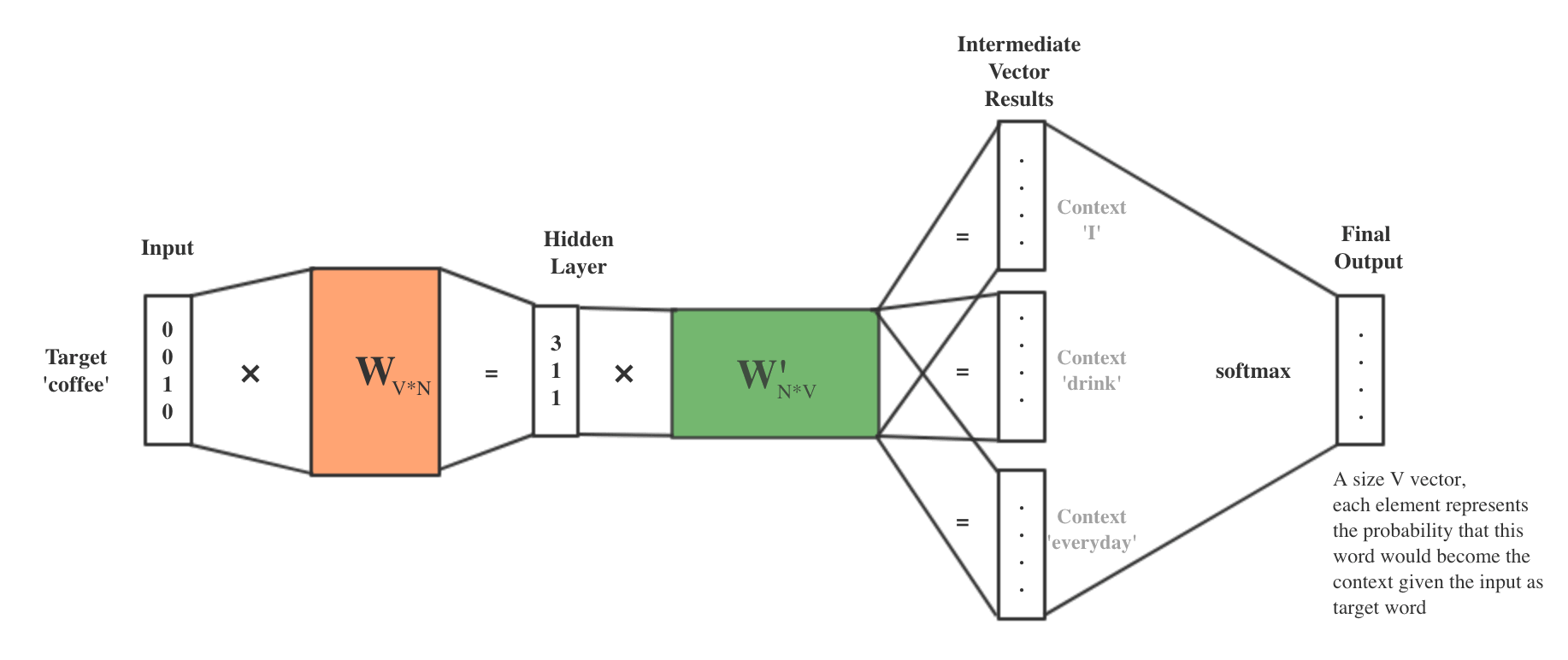
假设训练结束(也就是说参数已经得到),现在要计算句子“I drink XXX everyday”中的 XXX 最可能是什么?会得到图 4 所示结果,也就是说最可能为“coffee”。
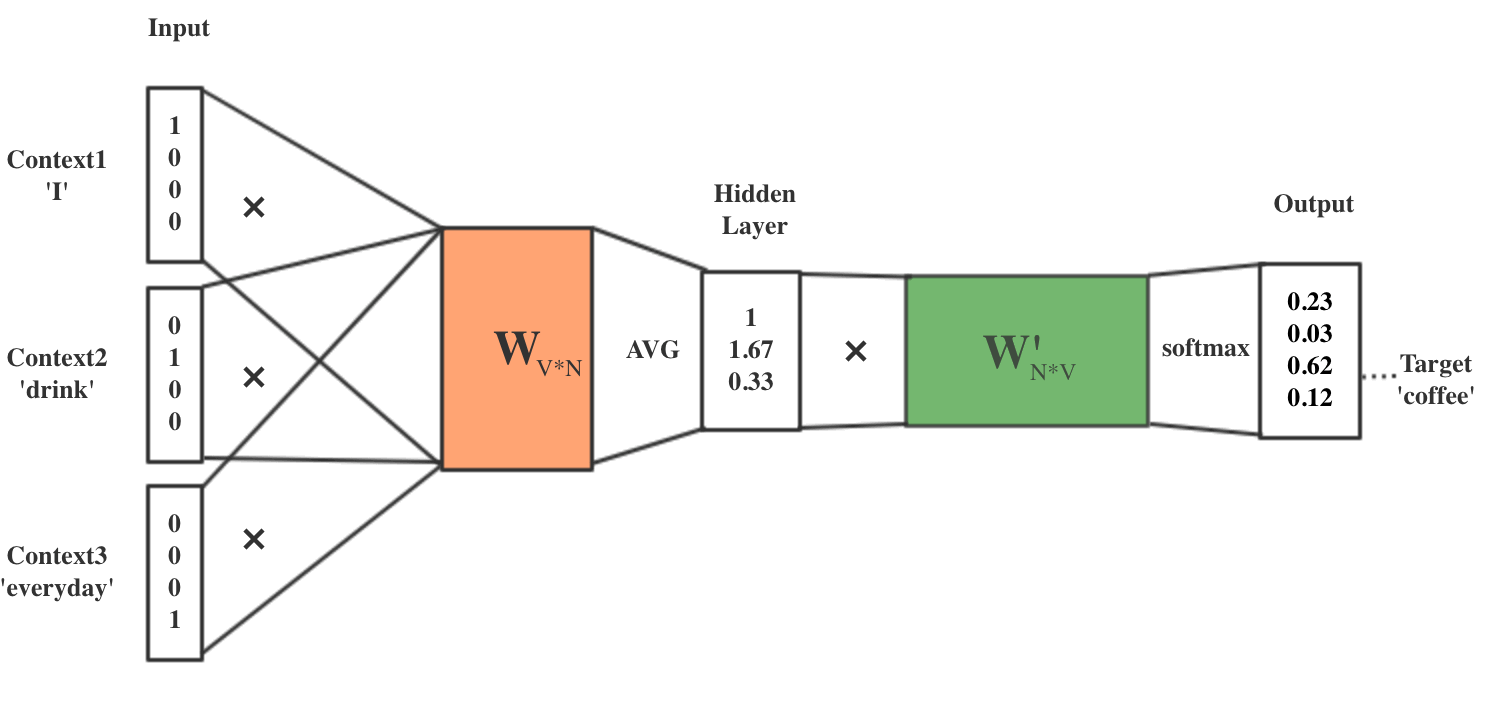
Figure 4: I drink XXX everyday
训练结束后,输入层的每个单词与矩阵 \(W\) 相乘得到的向量的就是每个单词对应的“词向量”,也就是说词向量就是神经网络的隐藏层参数。
参考:
https://www.zhihu.com/question/44832436/answer/266068967
https://yanpuli.github.io/posts/2018/12/blog-post-17/
3.2. Skip-gram
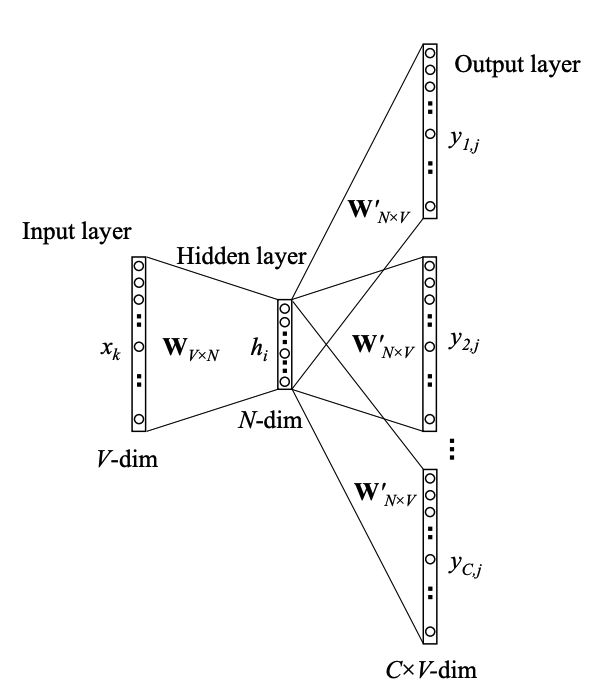
3.3. word2vec 实践
spark 中的 word2vec 采用的是 skip-gram 模型(没有采用 CBOW 模型)。训练得到模型后,spark 提供了查找“相似词”(findSynonyms)等基本功能。